Pointeurs de service BI ; Maximisation des performances et du TCO
Un guide complet de la pile de services BI Databricks — de la disposition physique aux métriques gouvernées en passant par la matérialisation consciente des agrégats
par Chris Koester
- Structurez votre couche physique avec des schémas en étoile, le clustering liquide et l'optimisation prédictive pour accélérer les requêtes BI.
- Définissez une seule fois les métriques métier gouvernées avec les vues de métriques Unity Catalog — une couche sémantique sans tête qui dessert tous les outils BI, les espaces Genie et les agents IA à partir d'une source unique de vérité.
- Activez la matérialisation consciente des agrégats pour obtenir des performances de type OLAP pré-agrégées sans avoir à construire et maintenir des tables agrégées séparées.
Vos tableaux de bord BI sont lents et leur optimisation coûte trop cher en temps et en argent.
C'est un schéma familier. Une requête de tableau de bord prend 30 secondes, alors quelqu'un crée une table agrégée pour l'accélérer. Cette table a besoin d'un pipeline de rafraîchissement. Le pipeline a besoin d'une surveillance. Ensuite, un deuxième outil BI a besoin des mêmes données sous une forme légèrement différente, alors quelqu'un crée une autre table agrégée en utilisant une table agrégée distincte. En fin de compte, vous gérez une prolifération d'agrégats, d'extraits et de couches sémantiques spécifiques à l'outil — chacune avec sa propre fenêtre d'actualité, ses propres lacunes en matière de gouvernance et sa propre ligne sur la facture de calcul.
Les charges de travail BI sont différentes des autres charges de travail analytiques. Elles sont hautement concurrentes, sensibles à la latence et répétitives dans leurs modèles de requête. Cette combinaison exige une approche délibérée pour modéliser, stocker, optimiser et servir les données. La bonne nouvelle : Databricks fournit une pile complète pour le service BI — de la disposition physique des données à une couche sémantique gouvernée — et chaque couche amplifie les gains de performance de la couche inférieure.
Ce post présente cette pile de bas en haut, avec des conseils pratiques sur les points sur lesquels se concentrer pour obtenir les plus grandes améliorations en termes de performances des requêtes et de coûts.
La pile de service BI
Avant de plonger dans chaque couche, voici l'image complète :
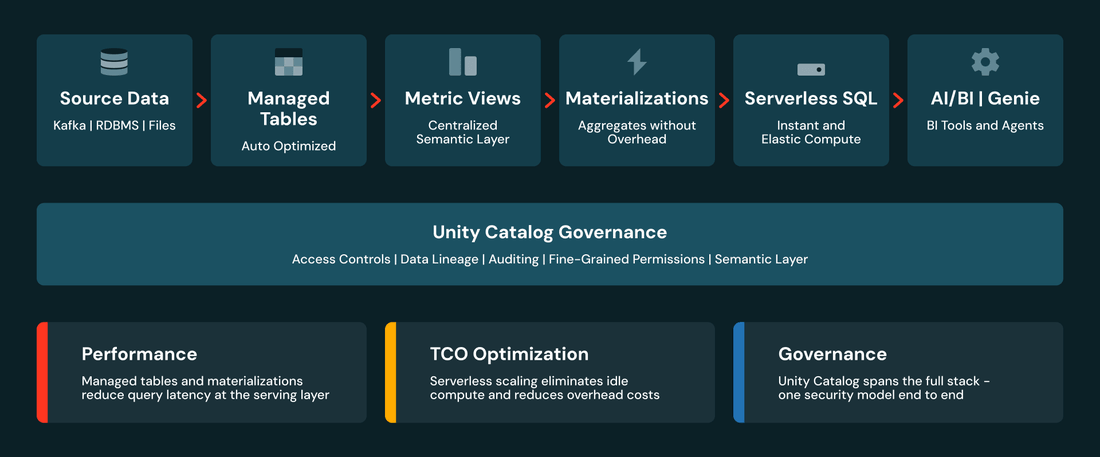
Unity Catalog assure la gouvernance tout au long du processus — lignage et contrôle d'accès des données brutes aux sémantiques en passant par la consommation. Chaque couche aborde un aspect différent de la performance et du coût. Examinons-les.
Optimiser la couche physique
La couche physique est là où la plupart des performances BI sont gagnées ou perdues. Si vous la réussissez, chaque requête en bénéficie — avant même d'avoir touché la couche sémantique.
Commencer par la modélisation dimensionnelle
Les schémas en étoile restent la référence absolue pour les performances des requêtes BI. Des tables de dimensions larges et dénormalisées jointes à des tables de faits via des clés substituts donnent à l'optimiseur de requêtes des chemins de jointure clairs et prévisibles.
Databricks prend entièrement en charge les constructions de modélisation relationnelle dont vous avez besoin : contraintes de clé primaire et étrangère (avec RELY pour les indices de l'optimiseur), colonnes d'identité pour les clés substituts, et contraintes CHECK et NOT NULL. Si vous suivez une architecture médaillon, conservez vos modèles normalisés ou Data Vault dans Silver et créez des schémas en étoile dénormalisés dans Gold pour la consommation BI.
Pour des modèles d'implémentation détaillés — gestion des types SCD 1 et 2, ETL de tables de faits avec MERGE, dimensions arrivant tardivement — consultez la série de blogs Implémentation d'un entrepôt de données dimensionnel dans Databricks SQL.
Utiliser les tables gérées
Les tables gérées d'Unity Catalog sont le fondement de tout le reste dans cette pile. Unity Catalog gère toutes les responsabilités de lecture, d'écriture, de stockage et d'optimisation pour les tables gérées. Cela débloque des fonctionnalités automatiques que vous n'obtenez pas avec les tables externes : l'Optimisation prédictive (abordée ci-dessous) est activée par défaut. Le clustering liquide automatique sélectionne des clés de clustering qui s'adaptent à l'évolution des modèles de requête. La mise en cache des métadonnées est toujours activée, réduisant les requêtes de stockage cloud et accélérant la planification des requêtes.
Utilisez des tables gérées dans toute la plateforme — pas seulement pour le service BI, mais dans toutes les couches Bronze, Silver et Gold. Elles sont le type de table par défaut dans Unity Catalog, et les avantages en termes de performances et de gouvernance se multiplient avec chaque autre optimisation de cette pile.
Appliquer le clustering liquide
Le clustering liquide remplace le partitionnement statique et le Z-ORDER manuel — et contrairement à ces approches, vous pouvez redéfinir les clés de clustering sans réécrire les données existantes. Ajoutez CLUSTER BY (col1, col2) lors de la création de la table ou utilisez ALTER TABLE sur les tables existantes. Si vous n'êtes pas sûr des colonnes à choisir, CLUSTER BY AUTO permet à l'Optimisation prédictive de sélectionner les clés en fonction des modèles de requête observés.
Pour les charges de travail BI, regroupez vos colonnes de filtre et de jointure les plus courantes — clés de date, région, catégorie de produit. Vous pouvez sélectionner jusqu'à quatre colonnes, et si deux colonnes sont très corrélées, n'en incluez qu'une. Lorsque les tableaux de bord filtrent sur les colonnes de clustering, le clustering liquide améliore les performances des requêtes grâce au saut de données.
Laisser l'Optimisation prédictive gérer le reste
L'Optimisation prédictive exécute automatiquement OPTIMIZE, VACUUM et la collecte de statistiques sur les tables qui bénéficieraient de ces opérations — vous n'avez donc pas besoin de planifier ces tâches vous-même. Elle collecte les statistiques de saut de données Delta et les statistiques de l'optimiseur de requêtes lors des écritures Photon, et remplit les statistiques pour les tables existantes. Dans les charges de travail observées, cela a entraîné une amélioration moyenne des performances de 22 %. Pour les charges de travail BI avec des modèles de filtre répétitifs, l'impact est particulièrement significatif — de meilleures statistiques signifient un meilleur saut de données et des plans de requête plus efficaces.
Activez l'Optimisation prédictive au niveau du catalogue et laissez-la fonctionner. L'utilisation de l'Optimisation prédictive est l'une des optimisations à plus fort rendement et à plus faible effort que vous puissiez faire.
Le résultat : les requêtes BI scannent moins de données, joignent plus efficacement et coûtent moins cher à exécuter — et vous n'avez pas encore touché à la couche sémantique.
Vues métriques : Définir vos métriques une seule fois
C'est là que les choses deviennent intéressantes. La plupart des organisations ont les mêmes métriques commerciales définies à plusieurs endroits — un calcul de revenus dans un outil BI, un légèrement différent dans un autre, une troisième variante dans un notebook SQL que quelqu'un a écrit le trimestre dernier. Chaque définition dérive indépendamment. Personne n'est sûr de laquelle est la bonne.
Les vues métriques dans Unity Catalog résolvent ce problème en fournissant une couche BI sans tête — une couche sémantique unique et gouvernée où vous définissez votre modèle de données et vos KPI une seule fois, indépendamment de tout outil BI spécifique. Vous les définissez centralement en SQL ou dans l'interface utilisateur en point-clic de l'Explorateur Unity Catalog. Les tableaux de bord IA/BI, Genie, les notebooks SQL et les outils BI tiers résolvent les métriques à partir des mêmes définitions. Définissez une métrique une fois, et chaque consommateur — humain ou IA — obtient la même réponse.
Les vues métriques vont au-del�à des définitions de métriques centralisées — les métadonnées sémantiques sont ce qui les distingue. Des champs comme display_name, comment et synonyms donnent aux systèmes d'IA le contexte dont ils ont besoin pour interpréter correctement les questions commerciales. Lorsqu'un utilisateur demande à Genie « quel était notre chiffre d'affaires la semaine dernière ? », ces annotations sont la façon dont Genie associe le langage naturel à la bonne mesure et aux bonnes dimensions. Pas de prompts personnalisés, pas de glossaire séparé. Il en va de même pour les agents IA construits sur Databricks — tout agent ayant accès à Unity Catalog peut découvrir et interroger les métriques gouvernées via la couche sémantique au lieu d'un SQL codé en dur. Plus vos métadonnées sont riches, plus l'IA fournit la bonne réponse avec précision.
Voici un exemple utilisant une table système, car tous les clients Databricks y ont accès — mais le même modèle s'applique aux KPI commerciaux comme les revenus, le volume de commandes ou la rétention client. Cette vue métrique calcule les métriques de l'entrepôt DBSQL :
Les consommateurs interrogent la vue métrique en utilisant MEASURE() pour référencer les définitions de métriques gouvernées :
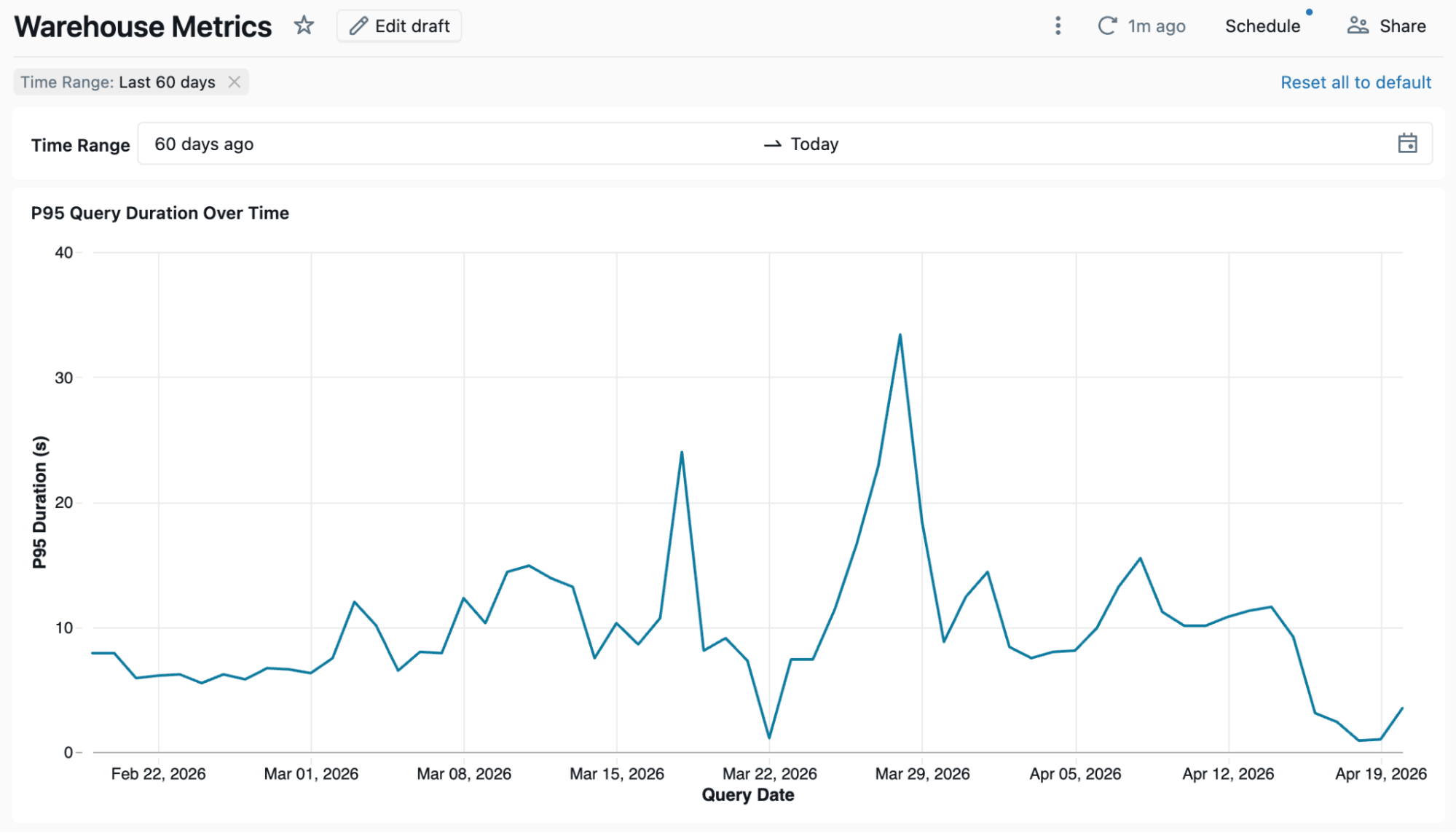
Les métriques sont définies une seule fois dans la vue métrique. Chaque tableau de bord, espace Genie ou notebook qui interroge metv_dbsql_metrics obtient le même résultat. Ci-dessous, un tableau de bord utilisant la vue métrique comme source.
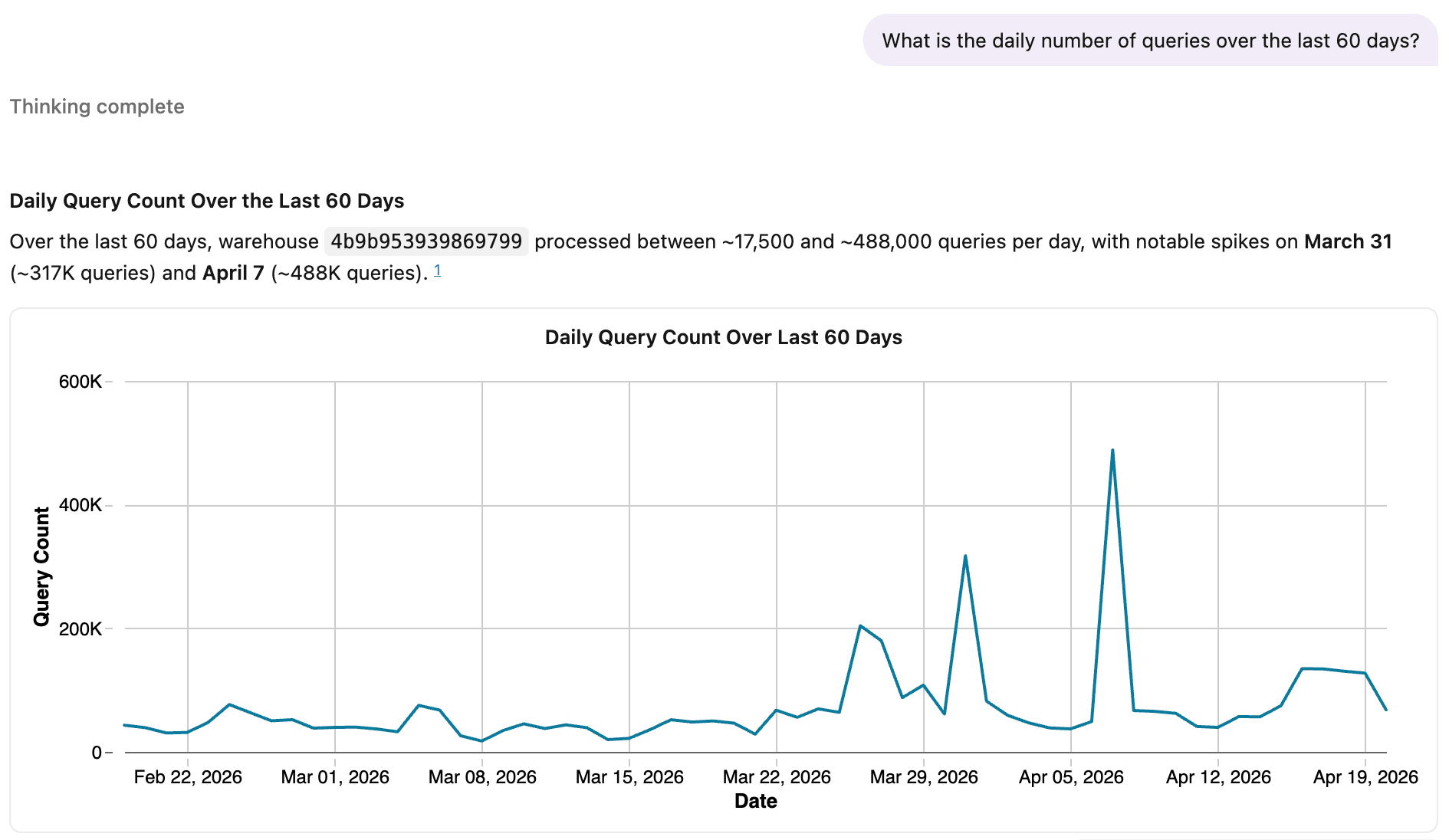
Voici Genie utilisant la même vue métrique.
Pour les équipes dont les définitions de métriques sont dispersées dans plusieurs outils de BI, les vues métriques offrent un moyen de consolider la couche sémantique dans Databricks. Au lieu de maintenir une logique métrique distincte dans chaque outil, vous la définissez une fois dans Unity Catalog et connectez vos outils de BI à cette source gouvernée.
L'implémentation principale est open-source dans Apache Spark™ (SPARK-54119), avec un support OSS pour Unity Catalog à venir — vous construisez ainsi sur une norme ouverte sans dépendance vis-à-vis d'un fournisseur. Cette ouverture est d'autant plus importante que l'IA prend en charge une plus grande partie de la charge de travail de BI. Les agents interrogeant vos données ont besoin d'une définition cohérente et lisible par machine de ce que signifie chaque métrique, et une norme ouverte permet à tout outil ou agent — pas seulement ceux spécifiques à un fournisseur — de raisonner sur les mêmes métriques gouvernées.
Matérialisation des vues métriques : performances OLAP sans la surcharge
Traditionnellement, lorsque les tableaux de bord de BI étaient trop lents, la solution consistait à créer des tables d'agrégats. Vous créiez des vues matérialisées ou des tables de pré-agrégation personnalisées au-dessus de votre schéma en étoile, mettiez en place des pipelines de rafraîchissement et re-pointiez vos outils de BI vers les nouvelles tables. Cela fonctionnait, mais ajoutait toute une couche d'objets et de pipelines à maintenir — et chaque fois que la logique d'agrégation changeait, vous deviez mettre à jour les requêtes des outils de BI pour qu'elles correspondent.
La matérialisation des vues métriques offre une alternative plus simple. Lorsque vous activez la matérialisation sur une vue métrique, la plateforme maintient automatiquement les résultats pré-agrégés derrière les mêmes définitions de métriques que celles que vos outils de BI interrogent déjà — pas de tables d'agrégats distinctes à construire, pas de requêtes d'outils de BI à refactoriser. Voici ce qui se passe en coulisses :
- Pré-agrégation automatique : les résultats des métriques sont pré-calculés et stockés
- Rafraîchissement incrémental : les métriques restent à jour sans recalcul complet
- Réécriture intelligente des requêtes : le moteur achemine les requêtes vers la meilleure matérialisation disponible
- Routage transparent : les utilisateurs interrogent les métriques de la même manière — le système fournit le chemin le plus rapide
Les requêtes de tableaux de bord qui scannaient auparavant des tables de faits complètes accèdent désormais à des matérialisations pré-agrégées — avec une latence réduite et un coût de calcul moindre. Les exemples de tableaux de bord et de Genie ci-dessus ont tous deux interrogé la même vue métrique, et leurs requêtes ont été acheminées de manière transparente vers une matérialisation. Le plan de requête ci-dessous de Genie le montre en action.
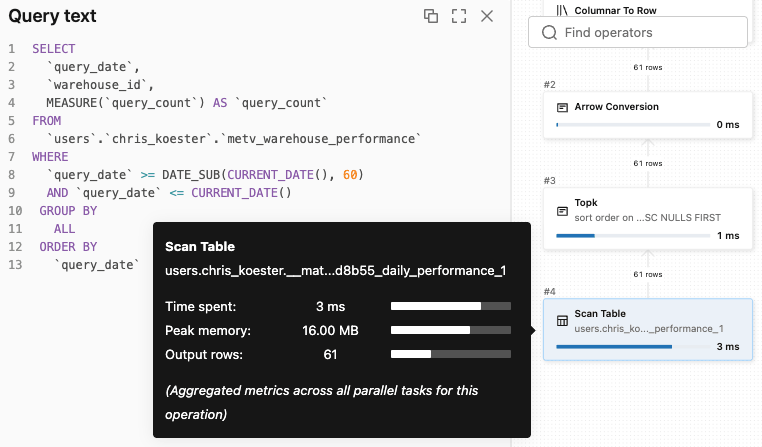
Pistes pratiques pour le coût total de possession
Des requêtes plus rapides et un coût réduit ne sont pas des objectifs concurrents — chaque optimisation qui réduit les données scannées réduit également le calcul pour lequel vous payez. Et chaque optimisation dans la pile se cumule. Le clustering liquide et de meilleures statistiques améliorent le saut de données et les plans de requête. Les matérialisations peuvent être rafraîchies de manière incrémentale, réduisant ainsi le calcul dont les entrepôts SQL ont besoin pour servir les tableaux de bord. Voici quelques autres moyens de réduire les coûts :
- Dimensionnez correctement votre entrepôt SQL. Utilisez des entrepôts SQL serverless avec mise à l'échelle automatique pour les rafales de concurrence de BI. Vous payez pour ce que vous utilisez, pas pour la capacité de pointe.
- Tirez parti des niveaux de mise en cache de DBSQL. Le cache disque conserve les données chaudes localement à l'entrepôt, et le cache de résultats de requête (QRC) sert les requêtes répétées sans ré-exécution. Pour les tableaux de bord avec des modèles de requête cohérents, la mise en cache transforme de nombreuses requêtes en réponses à latence milliseconde à un coût de calcul quasi nul.
- Éliminez les mouvements de données redondants. Servez la BI directement à partir du lakehouse via DirectQuery ou des connexions en direct, plutôt que d'utiliser des extraits ou des importations.
- Surveillez avec les tables système. Des tables système telles que
system.billing.usageetsystem.query.historypeuvent être utilisées pour suivre l'utilisation de la BI par tableau de bord, utilisateur et entrepôt. Créez des vues métriques et un tableau de bord IA/BI sur les tables système pour obtenir une visibilité sur votre utilisation de la BI.
Commencer
Vous n'avez pas besoin de mettre en œuvre toute la pile en une seule fois. Commencez là où vous obtiendrez le plus d'impact :
- Créez (ou validez) votre schéma en étoile de couche Gold avec des tables gérées, des clés primaires/étrangères et le clustering liquide
- Activez l'optimisation prédictive sur votre catalogue pour gérer automatiquement
OPTIMIZE,VACUUMet la collecte de statistiques - Définissez des vues métriques pour vos KPI commerciaux principaux — commencez avec SQL ou l'interface utilisateur UC Explorer
- Activez la matérialisation des vues métriques pour vos métriques les plus fréquemment consultées
- Surveillez les résultats — pointez les tableaux de bord vers les vues métriques et suivez les performances des requêtes via les tables système
Databricks fournit des optimisations à chaque niveau de la pile de service de BI. Les tables gérées, le clustering liquide et l'optimisation prédictive minimisent les données scannées et le calcul dépensé. Les vues métriques centralisent votre logique métier dans une couche sémantique gouvernée qui sert les tableaux de bord, Genie et les agents IA de manière cohérente. La matérialisation offre des performances de requête inférieures à la seconde sans pipelines de pré-agrégation manuels. Ensemble, ces couches se cumulent — réduisant à la fois la latence des requêtes et le coût total de possession.
Commencez par définir votre première vue métrique sur une table de couche Gold existante et activez la matérialisation. Consultez les ressources ci-dessous pour commencer.
- Vue d'ensemble des vues métriques Unity Catalog
- Affichage des vues métriques dans IA/BI
- Interrogation des vues métriques à partir d'un éditeur SQL
- Mise en œuvre d'un entrepôt de données dimensionnel dans Databricks SQL
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.