Implémentation d'un entrepôt de données dimensionnel avec Databricks SQL : Partie 1
Définir les objets de données
par Bryan Smith, Lorenz Verzosa, Krishna Satyavarapu, Peyman Mohajerian et Jesse Heravi
- Implémentez des entrepôts de données dimensionnels dans Databricks SQL pour optimiser les performances des requêtes.
- La structure du modèle physique dans Databricks SQL, y compris la création de tables de dimensions et de faits, se fait avec des instructions SQL CREATE TABLE.
- Il est important d'ajouter des commentaires descriptifs aux tables et aux colonnes pour une meilleure gestion des métadonnées.
De plus en plus d'organisations migrent leurs charges de travail d'entrepôt de données vers Databricks. La nature élastique de la plateforme et les améliorations significatives de son moteur d'exécution de requêtes ont permis à Databricks d'établir des records mondiaux en matière de performance des requêtes d'entrepôt de données et de performance des coûts, ce qui en fait une option de plus en plus attrayante pour la consolidation de l'infrastructure analytique.
Pour soutenir ces efforts, nous avons précédemment publié des articles sur la manière dont Databricks prend en charge diverses approches de conception d'entrepôts de données. Dans cette série d'articles, nous voulons examiner de plus près l'une des approches les plus populaires de l'entreposage de données, la modélisation dimensionnelle, un modèle de conception caractérisé par des schémas en étoile et en flocon de neige, et plonger dans les modèles d'extraction, de transformation et de chargement (ETL) standardisés largement adoptés pour soutenir cette approche.
Pour rendre cela largement accessible à la communauté de la modélisation dimensionnelle, nous adhérerons étroitement aux modèles classiques associés à cette approche de modélisation. Ces informations seront réparties dans les articles de blog suivants :
- Partie 1 : Définition des objets de données (dimensionnels) (ce post)
- Partie 2 : Construction des flux de travail ETL de dimension
- Partie 3 : Construction des flux de travail ETL de faits
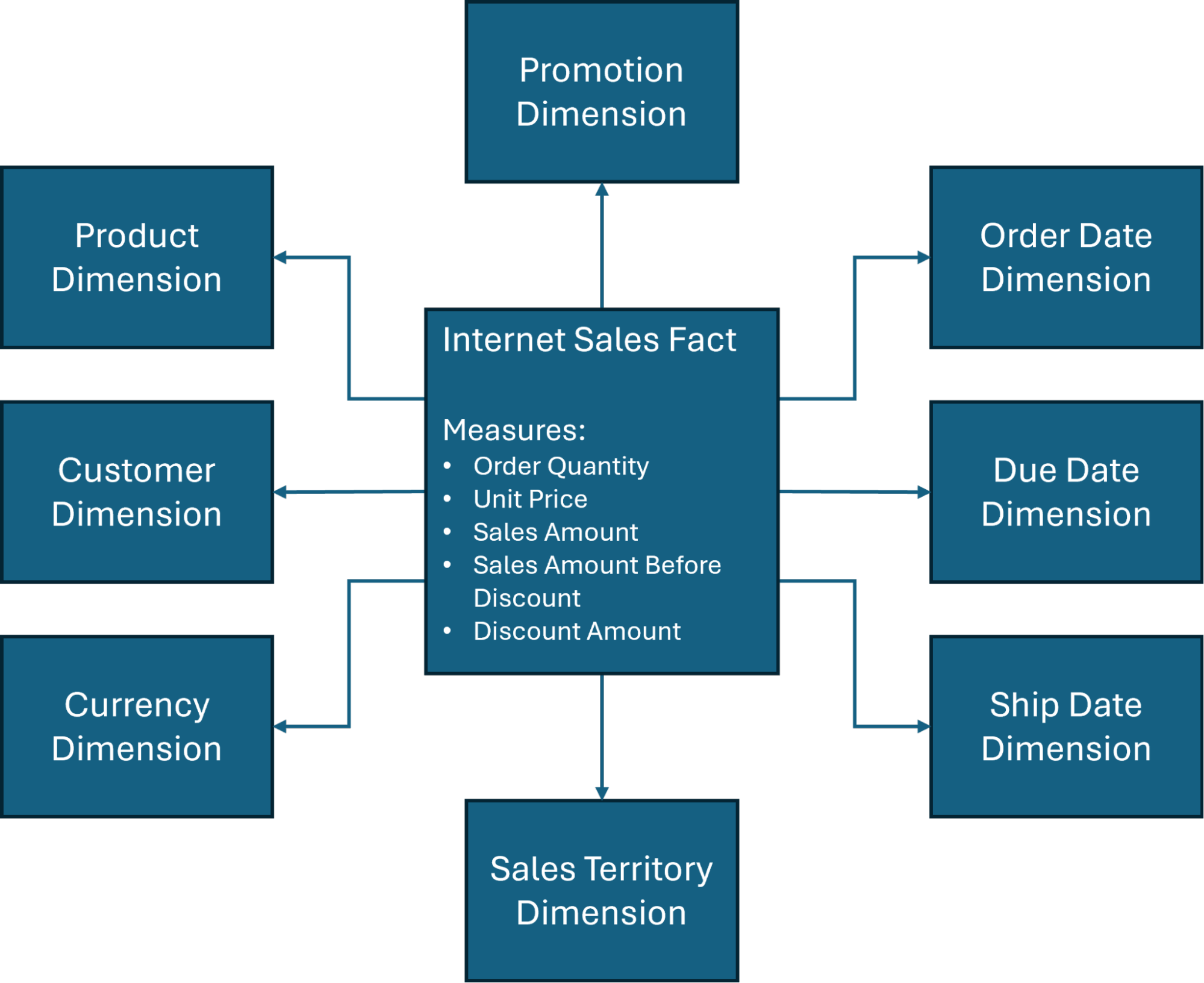
De plus, nous centrerons nos discussions de conception autour de l'un des schémas en étoile les plus couramment utilisés (Figure 1) dans la base de données AdventureWorksDW, une base de données d'exemple créée par Microsoft et largement utilisée à des fins de formation sur l'entreposage de données et la Business Intelligence.
Qu'est-ce que la modélisation dimensionnelle dans l'entreposage de données ?
La modélisation dimensionnelle optimise le stockage des données pour des performances de requête rapides. En structurant les données en faits et dimensions, vous pouvez facilement analyser les données sous plusieurs perspectives. Elle vous permet également d'explorer les données sous différents angles simultanément (analyse multidimensionnelle).
Quelles sont les quatre dimensions d'un entrepôt de données ?
Comme l'indique la figure 1, plusieurs dimensions sont impliquées dans le schéma en étoile de l'entreposage de données, mais les quatre dimensions principales de l'entreposage de données comprennent généralement les suivantes :
Temps : Cela fournit un cadre de suivi historique et est essentiel pour évaluer les tendances ou effectuer des comparaisons. Vous pouvez catégoriser les données en fonction d'intervalles de temps spécifiques – jours, semaines, années – pour optimiser les changements saisonniers de l'activité ou la gestion des stocks.
Client : Les organisations ont besoin d'informations précises sur qui achète leurs produits. Des informations telles que le nom, les coordonnées et les données démographiques peuvent offrir une segmentation utile du marché et déterminer des décisions telles que les dépenses publicitaires ou les stratégies marketing globales.
Produit : Cette dimension définit les biens ou services analysés, et peut être utile pour effectuer une analyse des performances afin de déterminer la quantité vendue, le taux de ventes et les opportunités de croissance future.
Emplacement : La contextualisation de l'endroit où les événements se sont produits – que ce soit géographiquement ou opérationnellement – peut aider les organisations à prendre des décisions critiques en fonction de l'endroit où leurs clients sont susceptibles de résider.
Le mod�èle physique
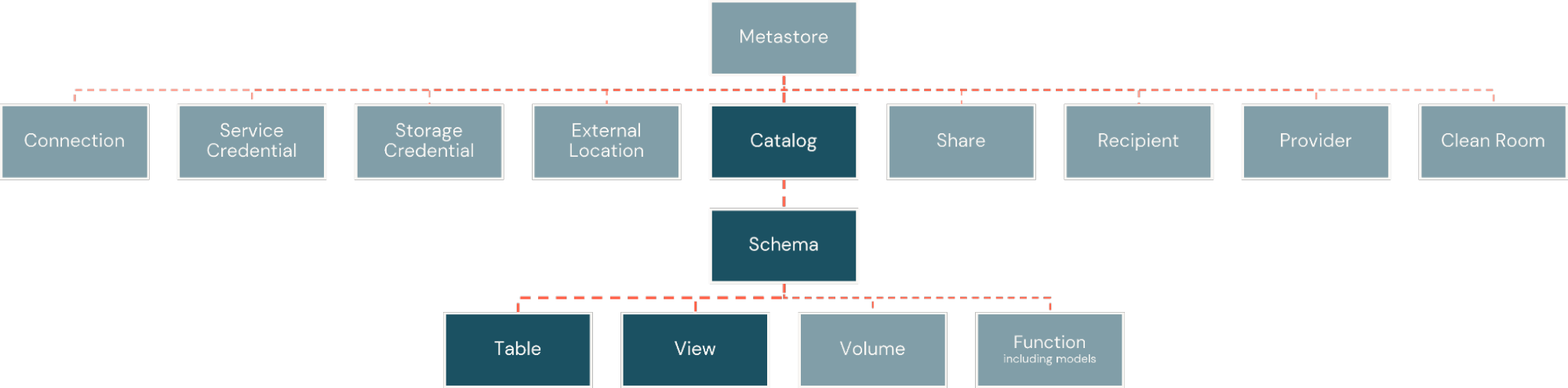
Au sein de la plateforme Databricks, les faits et les dimensions sont implémentés sous forme de tables physiques. Celles-ci sont organisées au sein de catalogues, similaires aux bases de données, mais avec une plus grande flexibilité pour l'étendue des actifs d'information que la plateforme prend en charge. Les catalogues sont ensuite subdivisés en schémas, créant des limites logiques et de sécurité autour de sous-ensembles d'objets dans le catalogue (Figure 2).
Tables de dimension
Les tables de dimension adhèrent à un ensemble relativement rigide de modèles structurels. Un identifiant séquentiel, une clé substitut, est généralement défini pour prendre en charge une liaison stable et efficace entre les tables de faits et la dimension. Les identifiants uniques des systèmes opérationnels (souvent appelés clés naturelles ou clés métier), ainsi qu'une collection dénormalisée d'attributs métier connexes, suivent généralement. Derrière les identifiants se trouvent généralement une série de colonnes de métadonnées destinées à prendre en charge les processus ETL en cours. Au sein de la plateforme Databricks, nous pouvons implémenter une table de dimension à l'aide de l'instruction CREATE TABLE, comme le montre cet exemple pour la dimension client :
Colonnes d'identité
Dans cet exemple, pour la colonne de clé substitut, CustomerKey, nous utilisons une colonne d'identité qui crée automatiquement une valeur séquentielle BIGINT pour le champ lors de l'insertion de lignes. Que nous utilisions l'option ALWAYS ou BY DEFAULT avec la colonne d'identité dépend si nous voulons interdire ou autoriser l'insertion de nos propres valeurs pour ce champ.
Entrée de membre manquant
Un modèle courant implémenté avec les tables de dimension consiste à créer une entrée de membre manquant. Cette entrée est utilisée dans les scénarios où les enregistrements de faits arrivent avec une liaison manquante ou inconnue à une dimension et peut être créée avec une valeur de clé substitut prédéterminée, comme illustré ici lorsque l'option BY DEFAULT est utilisée :
Champs d'identité
Par meilleure pratique, lors de l'insertion de valeurs dans un champ d'identité, il est préférable de s'assurer que les métadonnées du champ d'identité sont mises à jour à l'aide d'une instruction ALTER TABLE avec l'option SYNC IDENTITY utilisée :
Types de données
Pour la clé métier/naturelle et les autres champs liés aux données des systèmes sources, nous devrons aligner les types de données des systèmes sources avec les types de données pris en charge par la plateforme Databricks (Tableau 1). Pour les champs de métadonnées où une valeur binaire est utilisée, comme 0 ou 1, veuillez noter que nous utilisons souvent un type de données INT au lieu des types de données BOOLEAN ou TINYINT pour faciliter la gestion des littéraux.
|
BIGINT |
DECIMAL |
INTERVAL |
TIMESTAMP |
MAP |
|
BINARY |
DOUBLE |
VOID |
TIMESTAMP_NTZ |
STRUCT |
|
BOOLEAN |
FLOAT |
SMALLINT |
TINYINT |
VARIANT |
|
DATE |
INT |
STRING |
ARRAY |
OBJECT |
Tableau 1. Les types de données pris en charge par la plateforme Databricks
Tables de faits
Les tables de faits suivent également leurs conventions structurelles. Composées principalement de mesures et de références de clés étrangères aux dimensions associées, les tables de faits peuvent également inclure des identifiants uniques pour les enregistrements transactionnels (ou d'autres attributs descriptifs dans une relation presque un à un avec les enregistrements de faits), appelés dimensions dégénérées. Elles peuvent également inclure des champs de métadonnées pour prendre en charge le chargement incrémental (également appelé extraction delta) des données des systèmes sources. Au sein de la plateforme Databricks, nous pourrions implémenter une table de faits en utilisant l'instruction CREATE TABLE, similaire à ce qui est montré ici pour la table de faits des ventes Internet :
Clés étrangères référencées
Comme mentionné dans la section précédente sur les tables de dimension, les types de données dans l'environnement Databricks sont mappés de manière flexible à ceux utilisés par les systèmes sources. Les références de clés étrangères entre les tables de faits et de dimensions peuvent également être explicitées à l'aide de l'instruction ALTER TABLE comme montré ici :
Note : Si vous préférez définir les contraintes de clé étrangère dans le cadre de l'instruction CREATE TABLE, vous pouvez simplement ajouter une liste de clauses FOREIGN KEY séparées par des virgules (sous la forme FOREIGN KEY (foreign_key) REFERENCES table_name (primary_key) juste après la liste des définitions de colonnes.
Métadonnées et autres considérations
L'attrait du modèle dimensionnel réside dans son accessibilité relative pour les analystes métier. Dans cette optique, de nombreuses organisations adoptent des conventions de nommage pour les faits et les dimensions, telles que les préfixes Fact et Dim dans les exemples ci-dessus, et encouragent l'utilisation de noms longs et explicites pour les tables et les champs, qui s'écartent souvent considérablement des noms utilisés dans les systèmes sources opérationnels.
Dans cette optique, il est important de noter les limitations de Databricks sur le nommage des objets. Celles-ci incluent :
- Les noms d'objets ne peuvent pas dépasser 255 caractères
- Les caractères spéciaux suivants ne sont pas autorisés :
- Point (.)
- Espace ( )
- Barre oblique (/)
- Tous les caractères de contrôle ASCII (00-1F hex)
- Le caractère DELETE (7F hex)
De plus, il est important de noter que les noms d'objets ne sont pas sensibles à la casse et sont, en fait, stockés dans le dépôt de métadonnées en minuscules. Si cela peut poser des problèmes de lisibilité des objets, vous pourriez envisager d'adopter une convention snake case pour améliorer la lisibilité de certains noms d'objets.
Indépendamment de vos conventions de nommage, il est conseillé de définir des commentaires descriptifs pour tous les objets et champs dans l'entrepôt de données. Ceci est fait grâce à l'utilisation de l'instruction COMMENT ON pour les objets table et l'instruction ALTER TABLE pour les champs individuels, comme démontré ici :
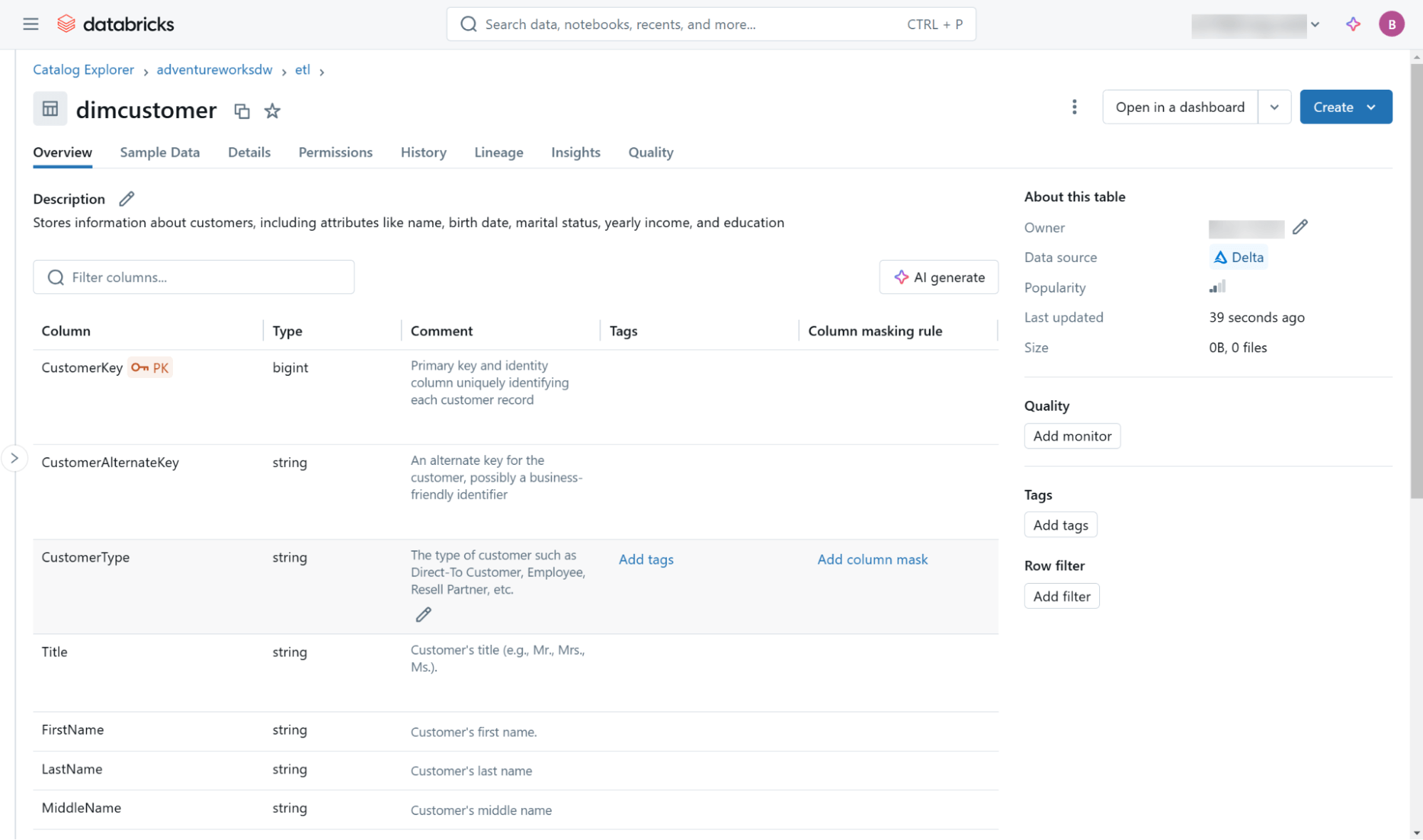
Ces métadonnées et d'autres (y compris les informations de lignage) sont accessibles via l'interface utilisateur Databricks Catalog Explorer (Figure 3) et via les objets dans le schéma d'information intégré trouvé dans chaque catalogue.
Enfin, ce blog aborde la création de tables de faits et de dimensions purement du point de vue de l'adhésion aux principes de conception dimensionnelle. Si vous souhaitez explorer des options supplémentaires pour la définition de tables qui prennent en compte les optimisations de performance et de maintenance, veuillez consulter ce blog sur l'optimisation des performances du schéma en étoile.
Prochaines étapes : implémentation de l'ETL des tables de dimension
Après avoir abordé les bases de la création de tables de faits et de dimensions, nous nous tournerons dans le prochain article vers l'implémentation des modèles ETL prenant en charge les tables de dimensions, avec un accent particulier sur les modèles de dimensions à changement lent (SCD) de type 1 et de type 2, en utilisant Python et SQL. Enfin, la partie 3 couvrira la manière dont l'ETL pour ces tables peut être implémenté.
Pour en savoir plus sur Databricks SQL, visitez notre site web ou consultez la documentation. Vous pouvez également découvrir la visite guidée du produit pour Databricks SQL. Si vous souhaitez migrer votre entrepôt existant vers un entrepôt de données sans serveur et haute performance, offrant une excellente expérience utilisateur et un coût total réduit, Databricks SQL est la solution — essayez-le gratuitement.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.