Implémenter un schéma en étoile dans Databricks en cinq étapes simples avec Delta Lake
Une méthode actualisée pour obtenir systématiquement les meilleures performances des bases de données en schéma en étoile utilisées dans les data warehouse et les datamarts avec Delta Lake
par Cary Moore, Lucas Bilbro et Brenner Heintz
- Utilisez les tables Delta pour créer vos tables de faits et de dimensions.
- Utilisez le clustering Liquid pour obtenir la meilleure taille de fichier.
- Utilisez le clustering Liquid sur vos tables de faits.
Nous mettons à jour ce blog pour montrer aux développeurs comment tirer parti des dernières fonctionnalités de Databricks et des avancées de Spark.
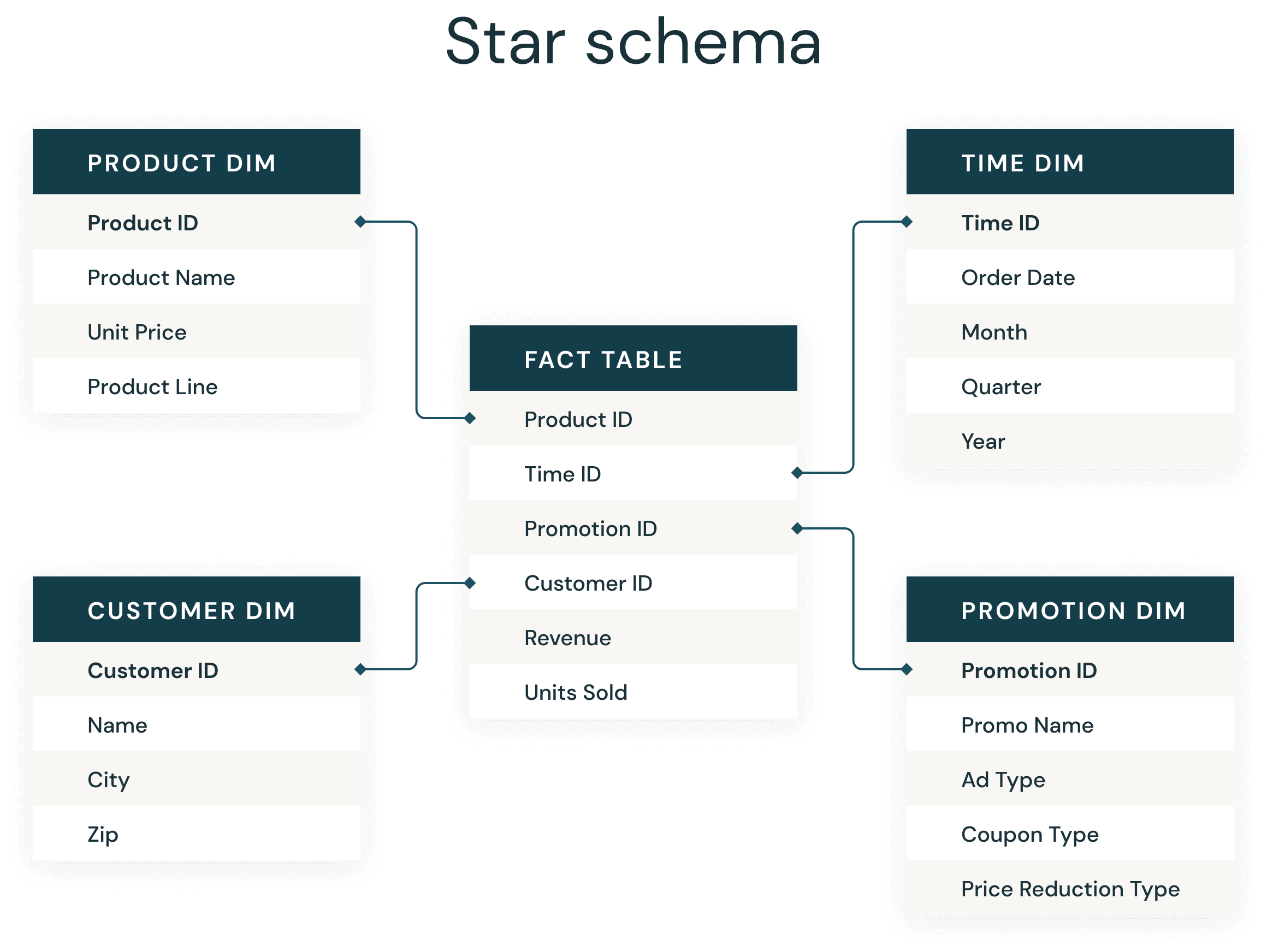
La plupart des développeurs de data warehouse connaissent très bien le schéma en étoile omniprésent. Introduit par Ralph Kimball dans les années 1990, un schéma en étoile est utilisé pour dénormaliser les données métier en dimensions (comme le temps et le produit) et en faits (comme les transactions en montants et en quantités). Un schéma en étoile stocke efficacement les données, conserve l'historique et met à jour les données en réduisant la duplication des définitions métier répétitives, ce qui le rend rapide à agréger et à filtrer.
L'implémentation courante d'un schéma en étoile pour prendre en charge les applications de Business Intelligence est devenue si routinière et si réussie que de nombreux modélisateurs de données peuvent la réaliser pratiquement les yeux fermés. Chez Databricks, nous avons produit de très nombreuses applications de données et nous recherchons constamment des approches de bonnes pratiques qui servent de règle empirique, une implémentation de base qui nous garantit d'obtenir un excellent résultat.
Tout comme dans un data warehouse traditionnel, il existe quelques règles de base simples à suivre sur Delta Lake qui amélioreront considérablement les jointures de votre schéma en étoile Delta.
Voici les étapes de base pour réussir :
- Utilisez les Delta Tables pour créer vos tables de faits et de dimensions
- Utilisez le Liquid Clustering pour obtenir la meilleure taille de fichier
- Utilisez le Liquid Clustering sur vos tables de faits
- Utilisez le Liquid Clustering sur les clés et les prédicats probables de votre plus grande table de dimensions.
- Tirez parti de l'Optimisation prédictive pour maintenir les tables et collecter des statistiques
1. Utilisez les Delta Tables pour créer vos tables de faits et de dimensions
Delta Lake est une couche de format de stockage ouvert qui facilite les insertions, les mises à jour et les suppressions, et qui ajoute des transactions ACID à vos tables de data lake, simplifiant ainsi la maintenance et les révisions. Delta Lake offre également la possibilité d'effectuer un élagage dynamique des fichiers pour accélérer les requêtes SQL.
La syntaxe est simple sur Databricks Runtimes 8.x et les versions plus récentes (l'environnement d'exécution actuel avec support à long terme est maintenant 15.4), où Delta Lake est le format de table par défaut. Vous pouvez créer une table Delta en utilisant SQL comme suit :
CREATE TABLE MY_TABLE (COLUMN_NAME STRING) CLUSTER BY (COLUMN_NAME);
Avant le runtime 8.x, Databricks exigeait la création de la table avec la USING DELTA syntaxe.
Avant le runtime 8.x, Databricks exigeait la création de la table avec la syntaxe USING DELTA.
2. Utilisez Liquid Clustering pour obtenir la meilleure taille de fichier
Dans une requête Apache Spark™, le temps passé à lire les données à partir du stockage cloud et la nécessité de lire tous les fichiers sous-jacents sont deux des facteurs qui consomment le plus de temps. Grâce au data skipping sur Delta Lake, les requêtes peuvent lire de manière sélective uniquement les fichiers Delta contenant les données pertinentes, ce qui permet de gagner un temps considérable. Le data skipping peut faciliter l'élagage de fichiers statiques, l'élagage de fichiers dynamiques, l'élagage de partitions statiques et l'élagage de partitions dynamiques.
Avant le Liquid Clustering, il s'agissait d'un paramètre manuel. Il existait des règles empiriques pour s'assurer que les fichiers avaient une taille appropriée et étaient efficaces pour l'interrogation. Désormais, avec le Liquid Clustering, les tailles de fichiers sont automatiquement déterminées et maintenues avec les routines d'optimisation.
Si vous lisez cet article (ou si vous avez lu la version précédente) et que vous avez déjà créé des tables avec ZORDER, vous devrez recréer les tables avec le Liquid Clustering.
De plus, le clustering Liquid effectue une optimisation pour éviter les fichiers trop petits ou trop grands (asymétrie et équilibre) et met à jour la taille des fichiers à mesure que de nouvelles données sont ajoutées afin de maintenir vos tables optimisées.
3. Utilisez les clusters Liquid sur vos tables de faits
Pour améliorer la vitesse des requêtes, Delta Lake prend en charge la possibilité d'optimiser la disposition des données stockées dans le stockage cloud avec le Liquid Clustering. Le clustering par les colonnes que vous utiliseriez dans des situations similaires à celles des index clusterisés dans le monde des bases de données, bien qu'il ne s'agisse pas en réalité d'une structure auxiliaire. Une table clusterisée avec Liquid Clustering regroupera les données dans la définition CLUSTER BY de sorte que les lignes ayant des valeurs de colonne similaires de la définition CLUSTER BY soient colocalisées dans l'ensemble optimal de fichiers.
La plupart des systèmes de base de données ont introduit l'indexation comme moyen d'améliorer les performances des requêtes. Les index sont des fichiers et, par conséquent, à mesure que la taille des données augmente, ils peuvent devenir un autre problème de big data à résoudre. À la place, Delta Lake ordonne les données dans les fichiers Parquet pour rendre la sélection de plages sur le stockage d'objets plus efficace. Combinées au processus de collecte de statistiques et au data skipping, les tables à clustering Liquid sont similaires aux Opérations de recherche (seek) par rapport aux Opérations d'analyse (scan) dans les bases de données, ce que les index ont résolu, sans créer un autre goulot d'étranglement de compute pour trouver les données qu'une query recherche.
Pour les tables à clustering Liquid, la meilleure pratique consiste à limiter le nombre de colonnes dans la clause CLUSTER BY aux 1 à 4 meilleures. Nous avons choisi les clés étrangères (clés étrangères par utilisation, et non des clés étrangères réellement appliquées) des 3 plus grandes dimensions qui étaient trop volumineuses pour être diffusées aux workers.
Enfin, le clustering Liquid remplace la nécessité de ZORDER et du partitionnement. Par conséquent, si vous l'utilisez, vous n'avez plus ni le besoin ni la possibilité de partitionner explicitement les tables avec Hive.
4. Utilisez le Liquid Clustering sur les clés de votre plus grande dimension et les prédicats probables
Puisque vous lisez ce blog, vous avez probablement des dimensions et une clé de substitution ou une clé primaire existe sur vos tables de dimensions. Une clé qui est un grand entier (big integer), validée et censée être unique. Après le databricks runtime 10.4, les colonnes d'identité sont devenues généralement disponibles et font partie de la syntaxe CREATE TABLE.
Databricks a également introduit des clés primaires et étrangères non contraignantes dans le Runtime 11.3 et elles sont visibles dans les clusters et les espaces de travail activés pour Unity Catalog.
L'une des dimensions sur lesquelles nous travaillions contenait plus d'un milliard de lignes et a bénéficié du file skipping et de l'élagage de fichiers dynamique après l'ajout de nos prédicats dans les tables clusterisées. Nos plus petites dimensions ont été clusterisées sur le champ de la clé de dimension et diffusées dans la jointure aux faits. Comme pour les tables de faits, limitez le nombre de colonnes dans le Cluster By à 1 à 4 champs dans la dimension qui sont les plus susceptibles d'être inclus dans un filtre en plus de la clé.
En plus du data skipping et de la facilité de maintenance, les clusters Liquid vous permettent d'ajouter plus de colonnes que ZORDER et sont plus flexibles que le partitionnement de style Hive.
5. Analyser la table pour collecter des statistiques pour Adaptive Query Execution Optimizer et activer Predictive Optimization
L'une des avancées majeures d'Apache Spark™ 3.0 a été l'Adaptive Query Execution, ou AQE en abrégé. Depuis Spark 3.0, AQE intègre trois fonctionnalités majeures, notamment la fusion des partitions post-brassage, la conversion des jointures par tri-fusion en jointures par diffusion et l'optimisation des jointures asymétriques. Ensemble, ces fonctionnalités permettent d'accélérer les performances des modèles dimensionnels dans Spark.
Pour qu'AQE sache quel plan choisir pour vous, nous devons collecter des statistiques sur les tables. Pour ce faire, exécutez la commande ANALYZE TABLE. Des clients ont signalé que la collecte de statistiques sur les tables a considérablement réduit l'exécution des requêtes pour les modèles dimensionnels, y compris les jointures complexes.
ANALYZE TABLE MY_BIG_DIM COMPUTE STATISTICS FOR ALL COLUMNS
Vous pouvez toujours utiliser la table ANALYZE dans le cadre de vos routines de chargement, mais il est maintenant préférable d'activer simplement l'optimisation prédictive sur votre compte, votre catalogue et votre schéma.
ALTER CATALOG [catalog_name] {ENABLE | DISABLE} PREDICTIVE OPTIMIZATION;
ALTER {SCHEMA | DATABASE} schema_name {ENABLE | DISABLE} PREDICTIVE OPTIMIZATION;
L'optimisation prédictive élimine la nécessité de gérer manuellement les opérations de maintenance pour les tables gérées par Unity Catalog sur Databricks.
Avec l'optimisation prédictive activée, Databricks identifie automatiquement les tables qui bénéficieraient d'opérations de maintenance et les exécute pour l'utilisateur. Les opérations de maintenance ne sont exécutées que lorsque c'est nécessaire, ce qui élimine les exécutions inutiles et la charge associée au suivi et à la résolution des problèmes de performance.
Actuellement, les optimisations prédictives effectuent les opérations Vacuum et Optimize sur les tables. Surveillez les mises à jour de l'optimisation prédictive et restez à l'écoute pour savoir quand la fonctionnalité intégrera l'analyse des tables et la collecte de statistiques, en plus de l'application automatique des clés de clustering Liquid.
Conclusion
En suivant les directives ci-dessus, les organisations peuvent réduire les temps de requête. Dans notre exemple, nous avons amélioré les performances des requêtes de 9 fois sur le même cluster. Les optimisations ont considérablement réduit les E/S et ont garanti que nous ne traitions que les données requises. Nous avons également bénéficié de la structure flexible de Delta Lake, car elle permet à la fois une montée en charge et la gestion des types de queries qui seront envoyées ad hoc depuis les outils de Business Intelligence.
Depuis la première version de ce blog, Photon est désormais activé par défaut pour notre Databricks SQL Warehouse et est disponible sur les clusters All Purpose et Jobs. En savoir plus sur Photon et l'amélioration des performances qu'il apportera à toutes vos requêtes Spark SQL avec Databricks.
Les clients peuvent s'attendre à une amélioration des performances de leurs requêtes ETL/ELT et SQL en activant Photon dans le Databricks Runtime. En combinant les meilleures pratiques décrites ici avec le Databricks Runtime compatible avec Photon, vous pouvez vous attendre à obtenir des performances de requête à faible latence, capables de surpasser les meilleurs data warehouses cloud.
Créez votre base de données en schéma en étoile avec Databricks SQL dès aujourd'hui
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.