Intégrez Databricks dans l'IDE Kiro grâce à la puissance de l'AI Dev Kit
Deux manières de connecter Kiro IDE à la Databricks Data Intelligence Platform : les quatre serveurs MCP gérés par Databricks pour un accès en 10 minutes, ou le nouveau Databricks AI Dev Kit Power pour un périmètre fonctionnel complet.
- Deux voies pour connecter Kiro IDE à Databricks : les quatre serveurs MCP gérés par Databricks (Genie, SQL, Unity Catalog Functions, Vector Search) pour une configuration de 10 minutes basée sur un PAT, ou le nouveau Databricks AI Dev Kit Power — un clic, tous les outils et compétences essentiels, quatre options d'authentification.
- Un développement assisté par l'IA basé sur les métadonnées réelles de l'espace de travail : les deux voies héritent des autorisations basées sur les lignes, les colonnes et les balises de Unity Catalog, de sorte que l'assistant écrit du SQL avec vos colonnes réelles et ne voit que ce que vous pouvez voir — pas d'hallucinations, pas de lectures non autorisées.
- Choisissez selon le périmètre fonctionnel : la Voie A est la configuration la plus légère pour les analystes et les concepteurs orientés SQL ; la Voie B ouvre l'intégralité de la plateforme Databricks (pipelines, jobs, Mosaic AI, Agent Bricks, Lakebase, Asset Bundles) au sein de l'IDE.
Pourquoi c'est important
Le développement assisté par AI s'effondre dès que l'assistant doit deviner les noms de colonnes, la structure des tables ou les catalogues que vous pouvez lire. La solution est l'ancrage (grounding) : connectez l'assistant aux métadonnées actives de l'espace de travail via le Model Context Protocol (MCP), et le SQL qu'il écrit utilisera vos colonnes réelles, les modèles dbt joindront de vraies tables, et chaque requête héritera des autorisations Unity Catalog déjà en place. Rien ne quitte la plateforme. L'AI ne voit que ce que vous pouvez voir.
Deux étapes majeures viennent d'être franchies pour rendre cela concret dans Kiro IDE :
Premièrement, le Databricks AI Dev Kit a ajouté le support de Kiro en amont dans la PR #511. L'installateur unifié traite kiro comme une cible de premier ordre aux côtés de claude, cursor, copilot, codex et gemini. Une seule commande, et Kiro récupère l'ensemble de la boîte à outils à l'adresse ~/.kiro/skills/ et ~/.kiro/settings/mcp.json.
Deuxièmement, le Databricks AI Dev Kit Power a été publié dans le catalogue Kiro Powers dans la PR #129. Ouvrez le panneau Powers, cliquez sur Essayer, et le Power exécute l'intégralité du processus d'intégration : installateur, connexion MCP, détection de l'authentification et chargement des compétences.
Combiné avec les quatre serveurs MCP distants gérés par Databricks déjà intégrés à la plateforme, vous disposez de deux façons de connecter Kiro à Databricks. Les deux partagent un résultat commun : les développeurs déploient des analyses, des pipelines et des workflows d'agents plus rapidement lorsque l'assistant hérite des autorisations réelles de l'espace de travail au lieu de deviner les schémas, les colonnes et les droits d'accès.
Pourquoi choisir Databricks pour le développement assisté par AI
Les deux étapes clés ci-dessus rendent l'association Kiro × Databricks concrète. Ce qui importe vraiment, c'est ce qui se cache en dessous. Trois éléments font de Databricks le socle de choix pour le développement assisté par AI, quel que soit le chemin choisi.
Unity Catalog est la seule couche de gouvernance qui ancre l'AI au niveau des données. Chaque appel MCP — Chemin A ou Chemin B — hérite des autorisations basées sur les lignes, les colonnes et les balises (tags). L'assistant ne dispose pas d'une vue privilégiée sur vos données ; il voit exactement ce que vous pouvez voir. Il n'y a pas de couche de contrôle d'accès distincte à gérer, et aucun risque que l'AI n'écrive des requêtes sur des tables dont elle ne devrait même pas soupçonner l'existence.
Une seule copie des données, un seul ensemble de définitions. Parce que Databricks est un lakehouse, la table que l'assistant interroge via databricks-sql est la même table dans laquelle votre modèle dbt écrit, la même table que votre espace Genie expose, et la même table que votre tableau de bord AI/BI lit. Il n'y a pas de synchronisation entre l'entrepôt de données (warehouse) et le lac (lake) susceptible de s'interrompre, ni de couche sémantique distincte à maintenir synchronisée. Lorsque l'assistant s'ancre dans samples.tpch.lineitem, il s'appuie sur la même définition que tous les autres outils utilisent.
L'ensemble de la suite AI est intégré, et non simplement greffé. Mosaic AI Gateway achemine les appels de modèles. Agent Bricks orchestre les workflows multi-agents. MLflow suit les expériences et les évaluations. Vector Search propulse la recherche sémantique. Lakebase gère l'état transactionnel. Tout cela apparaît dans le Power, le tout sur le même UC. Vous n'assemblez pas de nombreux produits différents ; vous utilisez une seule et unique plateforme.
Il y a un quatrième point qui mérite d'être mentionné : le Power lui-même est conçu par Databricks. Aucune autre plateforme de données ne propose de Power IDE en un clic pour Kiro, Cursor, Claude, Copilot, Codex et Gemini. La couche MCP est ouverte, le protocole est ouvert, l'intégration est ouverte — mais l'expérience globale est conçue par Databricks spécifiquement pour la façon dont nos clients développent.
Aperçu des deux chemins
Dimension | Chemin A : Serveurs MCP gérés | Chemin B : Databricks AI Dev Kit Power |
|---|---|---|
Périmètre d'action | 4 serveurs : Genie, SQL, UC Functions, Vector Search | Tous les outils et compétences Databricks essentiels |
Ce que vous obtenez | SQL en langage naturel, recherche sémantique, exécution gouvernée de fonctions | Le périmètre du Chemin A plus les pipelines, les jobs, les tableaux de bord, Lakebase, Mosaic AI, Agent Bricks, Asset Bundles, MLflow, le service de modèles (model serving) et les Apps |
Hébergement | Géré par Databricks (HTTPS distant) | Serveur MCP Python local via l'installateur AI Dev Kit |
Authentification | PAT dans l'environnement du shell | OAuth U2M (recommandé), OAuth M2M, profil .databrickscfg ou PAT |
Configuration | Modifier | Installation du Power en un clic et flux d'authentification guidé |
Idéal pour | Les analystes et les développeurs axés sur le SQL qui souhaitent un moyen rapide (10 minutes) de poser une question à leur entrepôt de données | Les ingénieurs de données et les concepteurs de plateformes qui ont besoin de l'ensemble du périmètre Databricks dans un seul IDE |
Aperçu de l'architecture d'intégration
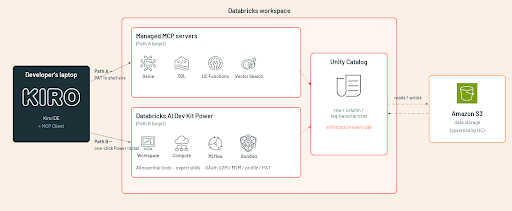
Les deux chemins partagent le même back-end : l'application des règles de Unity Catalog et l'identité de l'espace de travail Databricks. Ils diffèrent par leur périmètre d'action et leur modèle d'authentification.
Chemin A : se connecter aux quatre serveurs MCP gérés
C'est la configuration la plus légère. Un fichier mcp.json, un jeton d'accès personnel Databricks (PAT) et une modification du profil de shell. En moins de 10 minutes, Kiro communique avec Genie, SQL, Unity Catalog Functions et Vector Search.
Prérequis
- Un espace de travail Databricks sur AWS avec Unity Catalog activé.
- Un jeton d'accès personnel Databricks (PAT) ou un jeton OAuth limité aux serveurs MCP que vous prévoyez d'utiliser (
sql,unity-catalog,genie,vector-search). Les PAT inutilisés expirent automatiquement après 90 jours. - Kiro installé et lancé au moins une fois pour que
~/.kiro/existe. - Le nom d'hôte de votre espace de travail au format
<workspace>.cloud.databricks.com.
Générer un PAT Databricks
Dans l'espace de travail Databricks, accédez à Paramètres, Développeur, Jetons d'accès, Gérer, Générer un nouveau jeton. Définissez une date d'expiration conforme à la politique de rotation de votre équipe. Sélectionnez uniquement les portées d'API dont vous avez besoin ; le principe du moindre privilège l'emporte sur la commodité du « tout autoriser ». Copiez immédiatement le jeton. Databricks ne l'affichera plus.
Où Kiro stocke la configuration MCP
Kiro lit la configuration MCP à partir de fichiers JSON dans deux portées ; celle de l'espace de travail prévaut sur celle de l'utilisateur.
- Portée utilisateur :
~/.kiro/settings/mcp.jsons'applique à chaque espace de travail. - Portée espace de travail :
$PWD/.kiro/settings/mcp.jsons'applique uniquement à l'espace de travail actuel et remplace l'entrée de portée utilisateur ayant la même clé.
Installation en un clic depuis le répertoire des serveurs Kiro
Ouvrez kiro.dev/docs/mcp/servers/, trouvez la ligne Databricks, puis cliquez sur Add to Kiro. Le navigateur lance Kiro et ouvre une boîte de dialogue de confirmation avec une configuration pré-remplie. Confirmez pour écrire l'entrée databricks-sql dans ~/.kiro/settings/mcp.json. L'entrée fait référence à deux variables d'environnement qui n'existent pas encore ; nous les définirons ensuite.
Vérifier (ou ajouter) l'entrée databricks-sql
Définir les variables d'environnement
Dans le profil de shell qui lance Kiro (généralement ~/.zshrc sur macOS) :
Exécutez le profil (source ~/.zshrc) avant de lancer Kiro. Quittez complètement Kiro (Cmd+Q sur macOS) et rouvrez-le. L'option Reload Window ne relit pas les variables d'environnement ; seul un redémarrage du processus le permet.
Ajouter Genie, UC Functions et Vector Search
Les quatre serveurs gérés par Databricks se connectent en tant que MCP HTTP distants. La phase d'initialisation (handshake) réussit même avec une URL temporaire ; le serveur ne valide la ressource que lorsqu'un outil est appelé. Un état « connecté mais défaillant », où tools/call renvoie RESOURCE_DOES_NOT_EXIST ou PERMISSION_DENIED, est le mode de défaillance le plus courant. Effectuez d'abord ces vérifications préalables :
- Genie : confirmez qu'un espace Genie existe et que vous pouvez l'ouvrir. L'ID de l'espace apparaît dans l'URL.
- Fonctions UC : confirmez que la fonction existe et que vous disposez de
EXECUTE. Listez les fonctions avecSELECT * FROM system.information_schema.routines WHERE routine_type = 'FUNCTION'. - Vector Search : confirmez qu'un point de terminaison avec au moins un index accessible existe sous Catalogue, Vector Search.
- Portée du PAT : un PAT limité à l'espace de travail peut toujours atteindre
PERMISSION_DENIEDsur les espaces Genie ou les index vectoriels si l'utilisateur ne dispose pas de l'autorisation Can View sur la ressource spécifique. Les espaces Genie sont partagés individuellement.
Ajoutez les variables d'environnement supplémentaires (DATABRICKS_GENIE_MCP_URL, DATABRICKS_UC_FUNCTIONS_MCP_URL, DATABRICKS_VECTOR_SEARCH_MCP_URL) et mettez à jour mcp.json avec la configuration complète :
Formats d'URL par serveur :
Serveur | Modèle d'URL |
|---|---|
databricks-genie | https:// |
databricks-sql | https:// |
databricks-uc-functions | https:// |
databricks-vector-search | https:// |
Quittez et relancez à nouveau Kiro. Ouvrez la section MCP SERVERS du panneau Kiro ; les quatre entrées databricks-* apparaissent avec des indicateurs d'état verts. Cliquez sur reconnecter pour tout élément en rouge et vérifiez à nouveau le pre-flight. Essayez une première requête à faible risque dans le panneau de chat : "Listez les catalogues auxquels j'ai accès."
Voie B : installer le Databricks AI Dev Kit Power
Les quatre serveurs gérés couvrent le SQL, la recherche sémantique et l'analyse en langage naturel, ce qui est suffisant pour de nombreux développeurs. Si votre flux de travail englobe des pipelines, des jobs, le model serving, Lakebase, les Asset Bundles, Mosaic AI, Agent Bricks, les tableaux de bord AI/BI, MLflow ou les Databricks Apps, la configuration à quatre serveurs vous obligera à faire des copiers-collers toute la journée vers l'UI de l'espace de travail.
Le Databricks AI Dev Kit Power résout ce problème. Une seule installation. Tous les outils et compétences essentiels, quatre options d'auth, le tout chargeable à la demande.
Ce que vous obtenez
Domaine | Couverture |
|---|---|
SQL & Calcul | Exécuter du SQL sur des warehouses ; exécuter du Python ou du Scala sur des clusters ; gérer le cycle de vie du calcul |
Pipelines & Jobs | Spark Declarative Pipelines (tables de streaming, CDC, SCD Type 2, Auto Loader) ; DAG de jobs multi-tâches |
Unity Catalog | Tables, volumes, privilèges (grants), étiquettes (tags), identifiants de stockage, tables système, vues métriques, External Iceberg Reads |
Tableaux de bord AI/BI | Visualisations, KPI, tableaux de bord analytiques |
Espaces Genie | Exploration de données en langage naturel sur des ensembles de données gouvernés |
Agent Bricks | Assistants de connaissances (RAG) et superviseurs multi-agents |
Vector Search | Recherche sémantique et RAG avec des index gérés |
Model Serving | Modèles de ML, agents d'IA et API de modèles de fondation (FMAPI) payables au jeton, acheminables via AI Gateway |
MLflow | Expériences, évaluations, instrumentation de trace, requêtes de métriques |
Lakebase | PostgreSQL géré provisionné et avec mise à l'échelle automatique pour les charges de travail OLTP |
Databricks Apps | Applications web full-stack sur le Lakehouse |
Asset Bundles | Infrastructure-as-code pour les ressources Databricks |
Installer en un clic
Dans Kiro, ouvrez le panneau Powers, recherchez databricks et cliquez sur Try. Le Power exécute l'installateur officiel du Databricks AI Dev Kit en mode Kiro non interactif :
L'installateur télécharge le serveur MCP, crée un environnement virtuel uv et extrait la bibliothèque de compétences expertes dans ~/.kiro/skills/. Le Power copie les compétences dans son propre répertoire steering/ afin qu'elles se chargent à la demande en fonction de la tâche à accomplir. Aucun contenu n'est intégré dans le Power lui-même ; tout est récupéré en amont, de sorte que les compétences restent à jour.
Les quatre options d'auth
Le flux d'intégration du Power détecte les identifiants existants et vous guide vers le bon choix. Les quatre options sont documentées en ligne :
Option | Description | Idéal pour |
|---|---|---|
A : OAuth U2M (recommandé pour une utilisation interactive) | La CLI Databricks ouvre un navigateur, vous vous authentifiez en tant que vous-même, le SDK s'actualise automatiquement toutes les heures | Un développeur unique sur un poste de travail. Le flux interactif le plus sûr, sans risque de fuite de secret à longue durée de vie |
B : OAuth M2M | Un principal de service Databricks s'authentifie avec | Agents autonomes (headless), CI/CD ou de production |
C : Profil | Pointez le Power vers un profil que vous utilisez déjà pour la CLI Databricks ou d'autres outils | Vous disposez déjà d'un profil fonctionnel et ne souhaitez pas reconfigurer l'auth |
D : Jeton d'accès personnel (PAT) (hérité) | Jeton Bearer dans le bloc d'environnement | Outils qui ne prennent pas en charge OAuth, ou espaces de travail sans OAuth U2M activé |
Le mcp.json du Power est livré avec disabled: true jusqu'à ce que vous choisissiez une option ; rien ne se connecte tant que vous n'avez pas explicitement choisi et configuré vos identifiants. Le flux de détection des identifiants est neutre. Si plusieurs identifiants sont détectés, les quatre options sont présentées dans l'ordre, sans option par défaut ni réutilisation silencieuse.
Vérifier l'installation
Redémarrez Kiro, ouvrez le panneau MCP SERVERS et confirmez que l'entrée databricks est connectée (vert). Demandez au chat : "Obtenir mon utilisateur Databricks actuel." Ce simple appel teste l'auth, la résolution des variables d'environnement et l'activation du serveur. Si cela fonctionne, l'ensemble de la chaîne est opérationnel.
Comment choisir entre les deux voies
Un arbre de décision simple :
- Vous souhaitez simplement exécuter du SQL, poser des questions en langage naturel sur des ensembles de données gouvernés via Genie et effectuer des recherches dans des index vectoriels ? Utilisez la voie A. Les quatre serveurs gérés font exactement cela, et la configuration ne prend que 10 minutes.
- Créer des pipelines, gérer des tâches, déployer des Asset Bundles, travailler avec Lakebase, concevoir des Databricks Apps ou appeler Mosaic AI / Agent Bricks ? Utilisez la voie B. L'ensemble d'outils complet représente une surface trop vaste pour être greffé sous forme de serveurs MCP distants ponctuels.
- Hybride ? Exécutez les deux. La voie A et la voie B ne sont pas en conflit. Le Power écrit sa propre entrée
mcpServers.databricks, tandis que les quatre serveurs de la voie A (databricks-genie,databricks-sql,databricks-uc-functions,databricks-vector-search) sont des clés distinctes. Kiro les présente tous dans le panneau MCP.
Pour les développeurs qui prévoient d'utiliser Kiro au quotidien pour leurs charges de travail Databricks, la voie B est la meilleure solution à long terme. La voie A est la bonne réponse si vous disposez de 10 minutes et d'un SQL warehouse avec lequel vous souhaitez échanger.
Du point de vue du développeur
Les deux voies s'abordent différemment selon la personne qui utilise l'IDE. Quatre profils, quatre points de friction, quatre réponses.
L'ingénieur analytique. Vous passez la moitié de votre journée à interroger des tables que vous n'avez jamais vues et l'autre moitié à faire des copiers-coller entre votre éditeur et l'interface utilisateur de l'espace de travail. La voie A résout ce problème en 10 minutes. Les serveurs Genie et SQL basent chaque requête sur des métadonnées de schéma réelles ; l'assistant écrit en fonction de vos colonnes réelles, sans deviner ; et chaque résultat hérite de vos autorisations Unity Catalog. Vous arrêtez de passer d'un onglet à l'autre.
L'ingénieur de données. Votre quotidien est rythmé par les pipelines, les tâches, les Asset Bundles et les promotions inter-environnements qui les accompagnent. Rédiger manuellement le fichier databricks.yml et exécuter databricks bundle deploy depuis la barre latérale du terminal est la méthode lente. La voie B est la méthode rapide. Les compétences du Power en matière de pipelines, de tâches et d'Asset Bundles produisent, valident et déploient l'IaC à partir d'une seule conversation. Spark Declarative Pipelines, CDC, SCD Type 2, Auto Loader — le tout généré par rapport à vos tables UC réelles et prêt à être validé.
Le concepteur d'IA / d'agents. Vous connectez les appels de modèles, l'évaluation, la gouvernance et l'orchestration d'agents à travers trois ou quatre outils qui ne s'accordent pas tout à fait sur le schéma. La voie B couvre l'ensemble de l'offre Databricks AI — Mosaic AI Gateway pour le routage et les solutions de repli, Agent Bricks pour les superviseurs multi-agents et les assistants de connaissances, MLflow pour l'évaluation, Vector Search pour la recherche — le tout régi par UC de bout en bout. Votre agent hérite des mêmes autorisations que son appelant, et vos traces d'évaluation arrivent dans le même espace de travail que vos exécutions d'entraînement.
Le concepteur de plateforme. Vous gérez les ressources Databricks en tant que code, effectuez des promotions entre dev/stage/prod et répondez chaque semaine à la question « y a-t-il eu une dérive ? ». La compétence Asset Bundles de la voie B, combinée aux compétences de gestion d'Unity Catalog, génère le bundle complet, le valide par rapport à l'état réel de votre espace de travail et détecte la dérive avant qu'elle ne pose problème. Vous arrêtez de maintenir manuellement un ensemble de fichiers YAML d'un côté et un autre dans un document.
Un flux de travail que vous pouvez exécuter dès aujourd'hui
Quelle que soit la voie choisie, cet exercice base l'assistant sur de réelles métadonnées d'espace de travail à l'aide du catalogue samples.tpch, disponible dans chaque espace de travail Databricks.
Vous demandez : « Quels sont les colonnes et les types de samples.tpch.lineitem, et quelle est la distribution des données par année l_shipdate ? »
Kiro renvoie le schéma réel et un histogramme à partir d'une seule requête exécutée par MCP. Des noms de colonnes réels, une distribution réelle, aucune hallucination.
Vous demandez : « Rédige un modèle dbt qui joint lineitem à orders et agrège les revenus par pays et par trimestre. »
Kiro produit du code SQL en utilisant les noms de colonnes réels (l_extendedprice, l_discount, o_orderdate) au lieu de deviner. Comme il a d'abord interrogé le schéma, il connaît les types exacts et le niveau de granularité.
Vous demandez : « Exécute ma nouvelle agrégation sur samples.tpch et compare le nombre de lignes �à l'instantané de la semaine dernière dans poc.gold.revenue_by_nation_qtr. »
Kiro exécute les deux requêtes et affiche les différences. Si un chiffre semble incorrect, « Montre-moi le lignage de gold.revenue_by_nation_qtr » extrait les tables en amont de system.access.table_lineage. Une fois vérifié, Kiro génère le fichier JSON de la tâche Databricks pour le modèle et répertorie les catalogues et schémas qu'il touche.
Sur la voie B, ce même flux de travail s'étend à « Générer l'Asset Bundle pour cette tâche et le déployer en staging », ou « Créer un tableau de bord AI/BI basé sur cette agrégation », ou encore « Connecter cela à un point de terminaison Mosaic AI Gateway avec un modèle de repli », le tout sans quitter l'IDE.
Bonnes pratiques, quelle que soit la voie
- Authentification par moindre privilège. Générez un PAT distinct par poste de travail et par ensemble de portées. Sur la voie B, préférez OAuth U2M aux PAT pour une utilisation interactive.
- Ne validez jamais d'identifiants. Stockez
DATABRICKS_ACCESS_TOKENdans votre profil de shell ou dans un gestionnaire de secrets. Ne le placez jamais dansmcp.jsonintégré au contrôle de version. - Portée par projet. Conservez les ID d'espace Genie et les chemins d'index Vector Search dans
$PWD/.kiro/settings/mcp.jsonafin que chaque projet conserve ses propres liaisons de ressources. - Faites confiance aux autorisations UC. Toutes les voies appliquent les autorisations basées sur les lignes, les colonnes et les balises de Unity Catalog. L'IA hérite de vos autorisations effectives à chaque appel. Il n'y a pas de couche de contrôle d'accès distincte à gérer.
- Redémarrez, ne rechargez pas. Kiro lit les variables d'environnement une seule fois au démarrage du processus. Après avoir modifié votre profil de shell ou ajouté une authentification, quittez complètement (Cmd+Q sur macOS) et rouvrez.
Dépannage
« Serveur introuvable » ou statut rouge sur une entrée MCP.
Voie A : vérifiez echo $DATABRICKS_SQL_MCP_URL dans le shell qui a lancé Kiro. Une valeur vide signifie que Kiro ne peut pas résoudre l'URL. Confirmez que le mcp.json à portée d'espace de travail ne masque pas votre configuration à portée d'utilisateur. Vérifiez que le PAT est toujours valide dans Paramètres, Développeur, Jetons d'accès.
Voie B : accédez à nouveau au flux de détection des identifiants depuis le processus d'intégration du Power. Si le serveur MCP renvoie Invalid access token ou 401, le mécanisme de récupération 401 intégré du Power suspend les appels d'outils et affiche à nouveau les options d'authentification.
Connecté au MCP mais les appels d'outils renvoient RESOURCE_DOES_NOT_EXIST ou PERMISSION_DENIED.
L'échec le plus courant de la voie A. L'établissement de liaison d'initialisation réussit avec une URL générique car le serveur diffère la validation des ressources jusqu'à l'appel. Réexécutez les vérifications préalables pour le serveur spécifique (l'espace Genie existe et est partagé avec vous, la fonction existe et vous disposez de EXECUTE, l'index vectoriel existe et vous disposez de l'autorisation Afficher).
Essayez-le dès aujourd'hui. Le Databricks AI Dev Kit Power est le moyen le plus rapide de bénéficier de l'ensemble de la plateforme — pipelines, tâches, Lakebase, Mosaic AI, Agent Bricks et tout ce qui est mentionné ci-dessus — au sein de Kiro. Installez-le directement depuis le catalogue Kiro Powers à l'adresse github.com/kirodotdev/powers, ou visitez github.com/databricks-solutions/ai-dev-kit pour installer la boîte à outils sous-jacente pour Kiro ou tout autre IDE pris en charge (Claude, Cursor, Copilot, Codex, Gemini). Pour les quatre serveurs MCP gérés par Databricks, l'installation en un clic est disponible sur kiro.dev/docs/mcp/servers/.
Vous avez des commentaires ou vous rencontrez un problème ? Signalez-le sur databricks-solutions/ai-dev-kit — nous les lisons tous.
Les opinions et idées partagées ici sont les nôtres et ne constituent pas une politique officielle de Databricks.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.