Construction, amélioration et déploiement de systèmes RAG de graphes de connaissances sur Databricks
par Andrea Santurbano, Chandhana Padmanabhan, Jiayi Wu et Dan Pechi
- Aperçu de GraphRAG : Le blog explore comment les systèmes de génération augmentée par récupération (RAG) peuvent être améliorés avec des bases de données graphes comme Neo4j, permettant des sorties d'IA plus précises en capturant les relations sémantiques entre les entités dans des données structurées.
- Cas d'utilisation et avantages : GraphRAG peut être appliqué en cybersécurité pour la détection des menaces, ainsi que dans des secteurs comme la fabrication pour la maintenance prédictive et la gestion de la chaîne d'approvisionnement, fournissant des informations plus approfondies à partir de jeux de données complexes.
- Implémentation sur Databricks : Le blog décrit comment construire et déployer un système GraphRAG sur Databricks en utilisant Neo4j, présentant l'intégration des LLM, des Delta Tables et du Agent Bricks Custom Agents pour un déploiement de bout en bout.
Comprendre GraphRAG
Qu'est-ce qu'un graphe de connaissances ?
Pour comprendre pourquoi on pourrait utiliser un graphe de connaissances (KG) plutôt qu'une autre représentation de données structurées, il est important de reconnaître qu'il met l'accent sur les relations explicites entre les entités—telles que les entreprises, les personnes, les machines ou les clients—et leurs attributs ou caractéristiques associés. Contrairement aux embeddings ou à la recherche vectorielle, qui privilégient la similarité dans des espaces de haute dimension, un graphe de connaissances excelle dans la représentation des connexions sémantiques et du contexte entre les points de données. Une unité de base d'un graphe de connaissances est un fait. Les faits peuvent être représentés sous forme de triplet de l'une des manières suivantes :
- HRT : <tête, relation, queue>
- SPO : <sujet, prédicat, objet>
Deux exemples simples de KG sont présentés ci-dessous. L'exemple de gauche d'un fait pourrait être <Andrea, aime, Irène>. Vous pouvez voir que le KG n'est rien d'autre qu'une collection de plusieurs faits de ce type. Mais comme vous pouvez le remarquer, les graphes ont une sémantique car l'exemple de gauche NE décrit PAS une relation romantique entre deux personnes, tandis que l'exemple de droite DÉCRIT une relation romantique entre deux personnes.

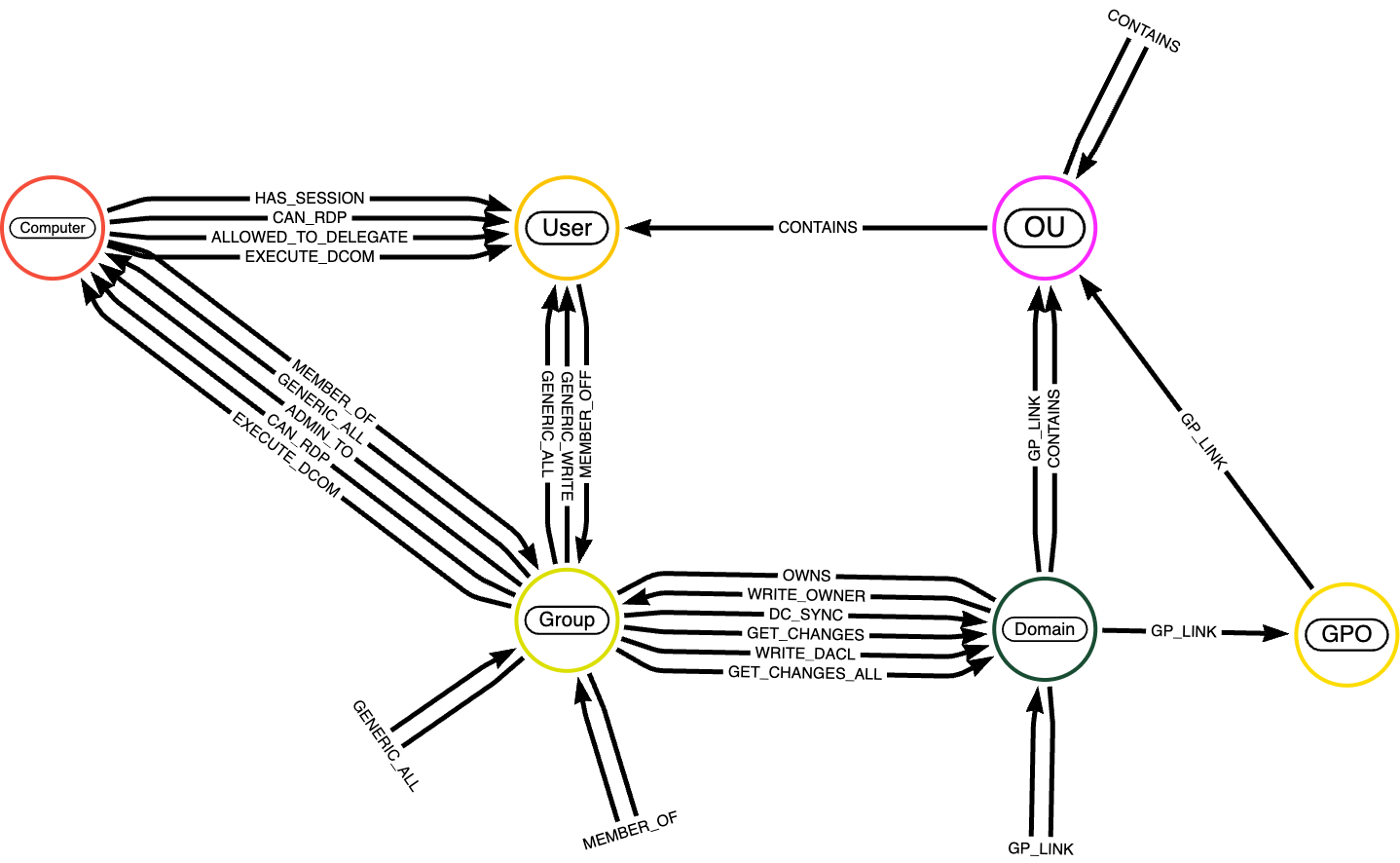
Maintenant que vous comprenez l'importance de la sémantique dans les graphes de connaissances, présentons-nous le jeu de données que nous utiliserons dans les prochains exemples de code : le jeu de données BloodHound. BloodHound est un jeu de données spécialisé conçu pour analyser les relations et les interactions au sein des environnements Active Directory. Il est largement utilisé pour l'audit de sécurité, l'analyse des chemins d'attaque et la compréhension des vulnérabilités potentielles dans les structures réseau.
Les nœuds dans le jeu de données BloodHound représentent des entités dans un environnement Active Directory. Il s'agit généralement de :
- Utilisateurs : représente les comptes d'utilisateurs individuels dans le domaine.
- Groupes : représente les groupes de sécurité ou de distribution qui agrègent des utilisateurs ou d'autres groupes pour l'attribution des autorisations.
- Ordinateurs : représente les machines individuelles du réseau (stations de travail ou serveurs).
- Domaines : représente le domaine Active Directory qui organise et gère les utilisateurs, les ordinateurs et les groupes.
- Unités d'organisation (OU) : représente les conteneurs utilisés pour structurer et gérer des objets tels que les utilisateurs ou les groupes.
- GPO (Objets de stratégie de groupe) : représente les stratégies appliquées aux utilisateurs et aux ordinateurs du domaine.
Une description détaillée des entités de nœuds est disponible ici. Les relations dans le graphe définissent les interactions, les appartenances et les permissions entre les nœuds ; une description complète des arêtes est disponible ici.
Quand choisir GraphRAG plutôt que RAG traditionnel
L'avantage principal de GraphRAG par rapport au RAG standard réside dans sa capacité à effectuer une correspondance exacte lors de l'étape de récupération. Ceci est rendu possible en partie par la préservation explicite de la sémantique des requêtes en langage naturel dans le langage de requête de graphe en aval. Bien que les techniques de récupération dense basées sur la similarité cosinus excellent à capturer la sémantique floue et à récupérer des informations connexes même lorsque la requête n'est pas une correspondance exacte, il existe des cas où la précision est essentielle. Cela rend GraphRAG particulièrement précieux dans les domaines où l'ambiguïté est inacceptable, tels que la conformité, le droit ou les ensembles de données hautement organisés.
Cela dit, les deux approches ne s'excluent pas mutuellement et sont souvent combinées pour tirer parti de leurs forces respectives. La récupération dense peut lancer un large filet pour la pertinence sémantique, tandis que le graphe de connaissances affine les résultats avec des correspondances exactes ou un raisonnement sur les relations.
Quand choisir RAG traditionnel plutôt que GraphRAG
Bien que GraphRAG présente des avantages uniques, il comporte également des défis. Un obstacle majeur est de définir correctement le problème—toutes les données ou tous les cas d'utilisation ne se prêtent pas bien à un graphe de connaissances. Si la tâche implique du texte hautement non structuré ou ne nécessite pas de relations explicites, la complexité ajoutée peut ne pas en valoir la peine, entraînant des inefficacités et des résultats sous-optimaux.
Un autre défi est de structurer et de maintenir le graphe de connaissances. La conception d'un schéma efficace nécessite une planification minutieuse pour équilibrer le détail et la complexité. Une mauvaise conception du schéma peut avoir un impact sur les performances et la scalabilité, tandis que la maintenance continue exige des ressources et une expertise.
Les performances en temps réel sont une autre limitation. Les bases de données de graphes comme Neo4j peuvent avoir du mal avec les requêtes en temps réel sur de grands ensembles de données ou des ensembles de données fréquemment mis à jour en raison de traversées complexes et de requêtes multi-sauts, ce qui les rend plus lentes que les systèmes de récupération dense. Dans de tels cas, une approche hybride—utilisant la récupération dense pour la vitesse et le raffinement du graphe pour l'analyse post-requête—peut fournir une solution plus pratique.
GraphDB et embeddings
Les bases de données de graphes comme Neo4j offrent souvent également des capacités de recherche vectorielle via des index HNSW. La différence ici est la manière dont elles utilisent cet index pour fournir de meilleurs résultats par rapport aux bases de données vectorielles. Lorsque vous effectuez une requête, Neo4j utilise l'index HNSW pour identifier les embeddings correspondants les plus proches en fonction de mesures telles que la similarité cosinus ou la distance euclidienne. Cette étape est cruciale pour trouver un point de départ dans vos données qui correspond sémantiquement à la requête, en tirant parti de la sémantique implicite donnée par la recherche vectorielle.
Ce qui distingue les bases de données de graphes, c'est leur capacité à combiner cette récupération initiale basée sur les vecteurs avec leurs puissantes capacités de parcours. Après avoir trouvé le point d'entrée à l'aide de l'index HNSW, Neo4j exploite la sémantique explicite définie par les relations dans le graphe de connaissances. Ces relations permettent à la base de données de parcourir le graphe et de recueillir un contexte supplémentaire, en découvrant des connexions significatives entre les nœuds. Cette combinaison de sémantique implicite provenant des embeddings et de sémantique explicite provenant des relations de graphe permet aux bases de données de graphes de fournir des réponses plus précises et plus riches en contexte que ce que chaque approche pourrait réaliser seule.
GraphRAG de bout en bout dans Databricks
GraphRAG est un excellent exemple de systèmes d'IA composés en action, où plusieurs composants d'IA travaillent ensemble pour rendre la récupération plus intelligente et plus consciente du contexte. Dans cette section, nous examinerons de manière générale comment tout s'articule.
Architecture GraphRAG
Ci-dessous, un diagramme d'architecture démontrant comment les questions en langage naturel d'un analyste peuvent récupérer des informations d'un graphe de connaissances Neo4j.
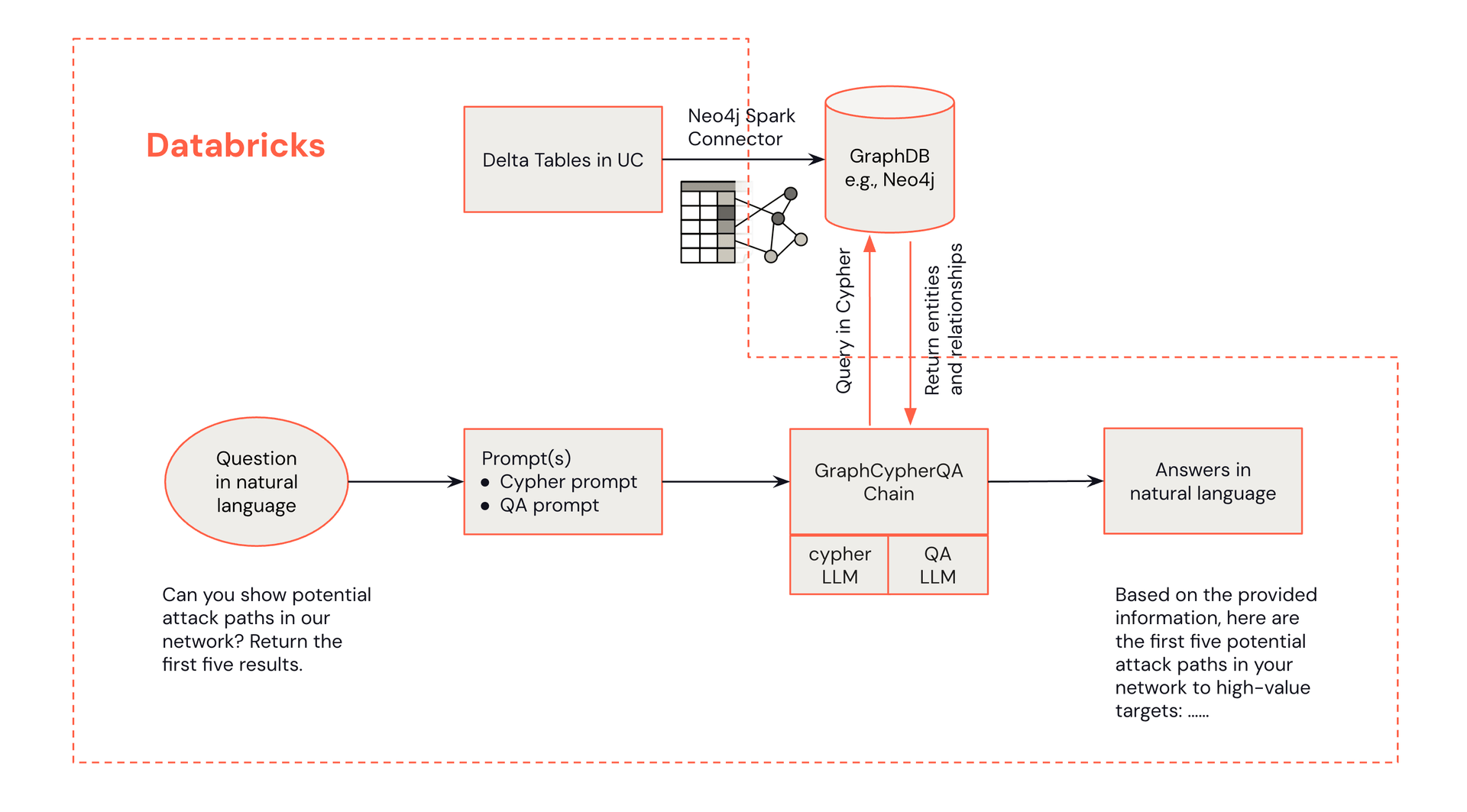
L'architecture de détection de menaces alimentée par GraphRAG combine les forces de Databricks et de Neo4j :
- Interface du Centre des opérations de sécurité (SOC) : Les analystes interagissent avec le système via Databricks, initiant des requêtes et recevant des recommandations d'alertes.
- Traitement Databricks : Databricks gère le traitement des données, l'intégration des LLM et sert de hub central pour la solution.
- Graphe de connaissances Neo4j : Neo4j stocke et gère le graphe de connaissances en cybersécurité, permettant des requêtes de relations complexes.
Aperçu de l'implémentation
Pour ce blog, nous sautons les détails du code—consultez le dépôt GitHub pour l'implémentation complète. Passons en revue les étapes clés pour construire et déployer un agent GraphRAG.
- Construire un graphe de connaissances à partir de tables Delta : Dans le notebook, nous avons discuté de scénarios impliquant des données structurées et non structurées. Le connecteur Spark Neo4j offre un moyen très simple de transformer les données de Unity Catalog en entités de graphe (nœuds/relations).
- Déployer des LLM pour les requêtes Cypher et QA : GraphRAG nécessite des LLM pour la génération de requêtes et la synthèse. Nous avons démontré comment déployer gpt-4o, llama-3.x, un modèle text2cypher affiné à partir de HuggingFace et les servir à l'aide d'un point de terminaison à débit provisionné.
- Créer et tester la chaîne GraphRAG : Nous avons démontré comment utiliser différents LLM pour les LLM Cypher et QA ainsi que des invites via GraphCypherQAChain. Cela nous permet d'affiner davantage avec des résultats de traçage en boîte blanche à l'aide du traçage MLflow.
- Déployez l'agent avec le framework d'agents Databricks : Utilisez le framework d'agents Databricks et MLflow pour déployer l'agent. Dans le notebook, le processus comprend l'enregistrement du modèle, son enregistrement dans Unity Catalog, son déploiement sur un point de terminaison de service et le lancement d'une application d'examen pour la discussion.

Conclusion
GraphRAG est une approche puissante mais hautement personnalisable pour construire des agents qui fournissent des résultats d'IA plus déterministes et contextuellement pertinents. Cependant, sa conception est spécifique à chaque cas, nécessitant une architecture réfléchie et un réglage spécifique au problème. En intégrant des graphes de connaissances à l'infrastructure et aux outils évolutifs de Databricks, vous pouvez construire des systèmes d'IA Compound AI de bout en bout qui combinent de manière transparente des données structurées et non structurées pour générer des informations exploitables avec une compréhension contextuelle plus approfondie.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.