Protection contre l'exfiltration de données avec Azure Databricks
Découvrez comment configurer une architecture Azure Databricks sécurisée pour prévenir l'exfiltration de données
Dernière mise à jour le : 30 octobre 2025
Lecture essentielle
Avant de commencer, assurez-vous de connaître ces sujets
- Calcul Serverless Azure Databricks Architecture
- Terminologie clé de Databricks
- Qu'est-ce que le Private Link Azure Databricks (PL) Front et Back-end ?
- Exigences d'un espace de travail activé pour le Private Link
- Qu'est-ce que les stratégies de points de terminaison de service pour les espaces de travail Azure
- Liste d'accès IP du contrôleur d'entrée
- Connectivité sécurisée des clusters
- Réseau Databricks
- Unity Catalog
La plateforme Lakehouse Azure Databricks fournit un ensemble unifié d'outils pour construire, déployer, partager et maintenir des solutions de données de niveau entreprise à grande échelle. Databricks s'intègre au stockage cloud et à la sécurité de votre compte cloud, et gère et déploie l'infrastructure cloud en votre nom.
L'objectif principal de cet article est d'atténuer les risques suivants :
- Accès aux données depuis un navigateur sur Internet ou un réseau non autorisé à l'aide de l'application Web Databricks.
- Accès aux données depuis un client sur Internet ou un réseau non autorisé à l'aide de l'API Databricks.
- Accès aux données depuis un client sur Internet ou un réseau non autorisé à l'aide d'Azure Private Link ou des points de terminaison de service.
- Une charge de travail compromise sur le cluster Azure Databricks écrivant des données sur une ressource de stockage non autorisée sur Azure ou sur Internet.
Azure Databricks est un service de première partie et prend en charge les outils et services natifs d'Azure qui aident à protéger les données en transit et au repos. Azure Databricks prend en charge les contrôles de sécurité réseau, tels que les routes définies par l'utilisateur, les règles de pare-feu et les groupes de sécurité réseau.
En plus des objectifs techniques de ce blog, nous voulons également nous assurer que les concepts que nous présentons tiennent compte de :
- Simplicité : toute conception de sécurité doit être bien comprise et maintenable, et correspondre aux compétences de votre organisation. Une solution de sécurité qui est mise en œuvre sans être pleinement comprise peut être compromise par inadvertance.
- Coût opérationnel de la solution : il doit toujours être pris en compte. Si une conception de sécurité est abandonnée parce que le coût est trop élevé, alors la solution n'a pas été efficace. La sécurité doit être soucieuse des coûts et durable.
Nous soulignerons les domaines d'économies ou les préoccupations de coûts tout en essayant de clarifier pourquoi et comment les choses fonctionnent chaque fois que nous le pouvons.
Avant de commencer, jetons un coup d'œil rapide à l'architecture de déploiement Azure Databricks ici :
Azure Databricks est structuré pour faciliter la collaboration sécurisée entre les équipes, tout en gérant de nombreux services backend, vous permettant de vous concentrer sur la science des données, l'analyse des données et l'ingénierie des données.
Azure Databricks est structuré autour de deux composants clés : le plan de contrôle et le plan de calcul.
Plan de contrôle :
Le plan de contrôle Azure Databricks, géré par Databricks au sein de son propre compte Azure, agit comme l'intelligence centrale de la plateforme. Il fournit les services backend pour l'authentification des utilisateurs, l'orchestration des clusters et des travaux, et la gestion de l'espace de travail, offrant l'interface Web et les points de terminaison API pour l'interaction avec le service.
Bien qu'il orchestre le cycle de vie des ressources de calcul, il ne traite pas directement les données. Au lieu de cela, le plan de contrôle dirige le traitement des données vers le plan de calcul séparé, qui fonctionne soit dans l'abonnement Azure du client, soit dans le locataire Databricks pour les déploiements serverless. Les commandes de notebook et de nombreuses autres configurations d'espace de travail sont stockées dans le plan de contrôle et chiffrées au repos.
Plan de calcul :
Le plan de calcul est responsable du traitement de vos données. Le type spécifique de calcul utilisé, serverless ou classique, dépend des ressources de calcul et de la configuration de l'espace de travail que vous avez choisies. Les calculs serverless et classiques partagent certaines ressources telles que le stockage par défaut de l'espace de travail (dbfs) et les identités managées qui sont liées à votre locataire Azure.
Calcul Serverless
Pour le calcul serverless, les ressources fonctionnent dans un plan de calcul Azure géré par Databricks. Azure Databricks gère la quasi-totalité de l'infrastructure sous-jacente, y compris le provisionnement, la mise à l'échelle et la maintenance. Cette approche offre :
- Opérations simplifiées : Les utilisateurs peuvent se concentrer sur les tâches d'ingénierie et de science des données sans avoir à gérer les clusters ou les machines virtuelles.
- Efficacité des coûts : Les utilisateurs ne sont facturés que pour les ressources de calcul activement consommées pendant l'exécution des charges de travail, éliminant ainsi les coûts associés aux clusters inactifs.
Les ressources serverless sont disponibles à la demande, réduisant les coûts de temps d'inactivité. Elles s'exécutent également dans une limite réseau sécurisée dans le compte Azure Databricks, avec plusieurs couches de sécurité et de contrôles réseau.
Calcul classique Azure Databricks
Avec le calcul classique Azure Databricks, les ressources sont situées dans votre locataire Azure Cloud. Cela fournit un calcul géré par le client, où les clusters Databricks s'exécutent sur des ressources au sein de votre abonnement Azure, et non du locataire Databricks. Cela offre :
- Isolation naturelle : Les opérations se déroulent au sein de votre propre abonnement Azure et réseau virtuel.
- Connexions sécurisées : Permet des connexions sécurisées à d'autres services Azure via des points de terminaison de service ou des points de terminaison privés que vous gérez et contrôlez.
Note importante : Les clusters classiques, y compris les entrepôts SQL classiques, peuvent connaître des temps de démarrage plus longs par rapport aux options serverless en raison de la nécessité de provisionner des ressources à partir de votre abonnement Azure.
Déploiement d'espace de travail Databricks uniquement serverless (nouveau) : Les espaces de travail uniquement serverless sont des espaces de travail qui ne peuvent exécuter que du calcul serverless. Il n'y a pas de calcul classique, donc toutes les ressources système sont gérées par Azure Databricks, qui gère la quasi-totalité de l'infrastructure sous-jacente, y compris le stockage par défaut de l'espace de travail.
Architecture de haut niveau
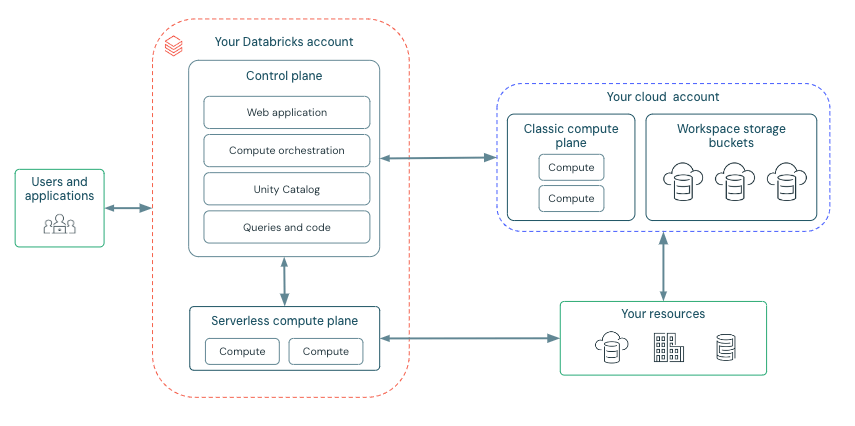
Chemin de communication réseau
Comprenons le chemin de communication que nous souhaitons sécuriser. Azure Databricks peut être utilisé par les utilisateurs et les applications de nombreuses manières, comme montré ci-dessous :
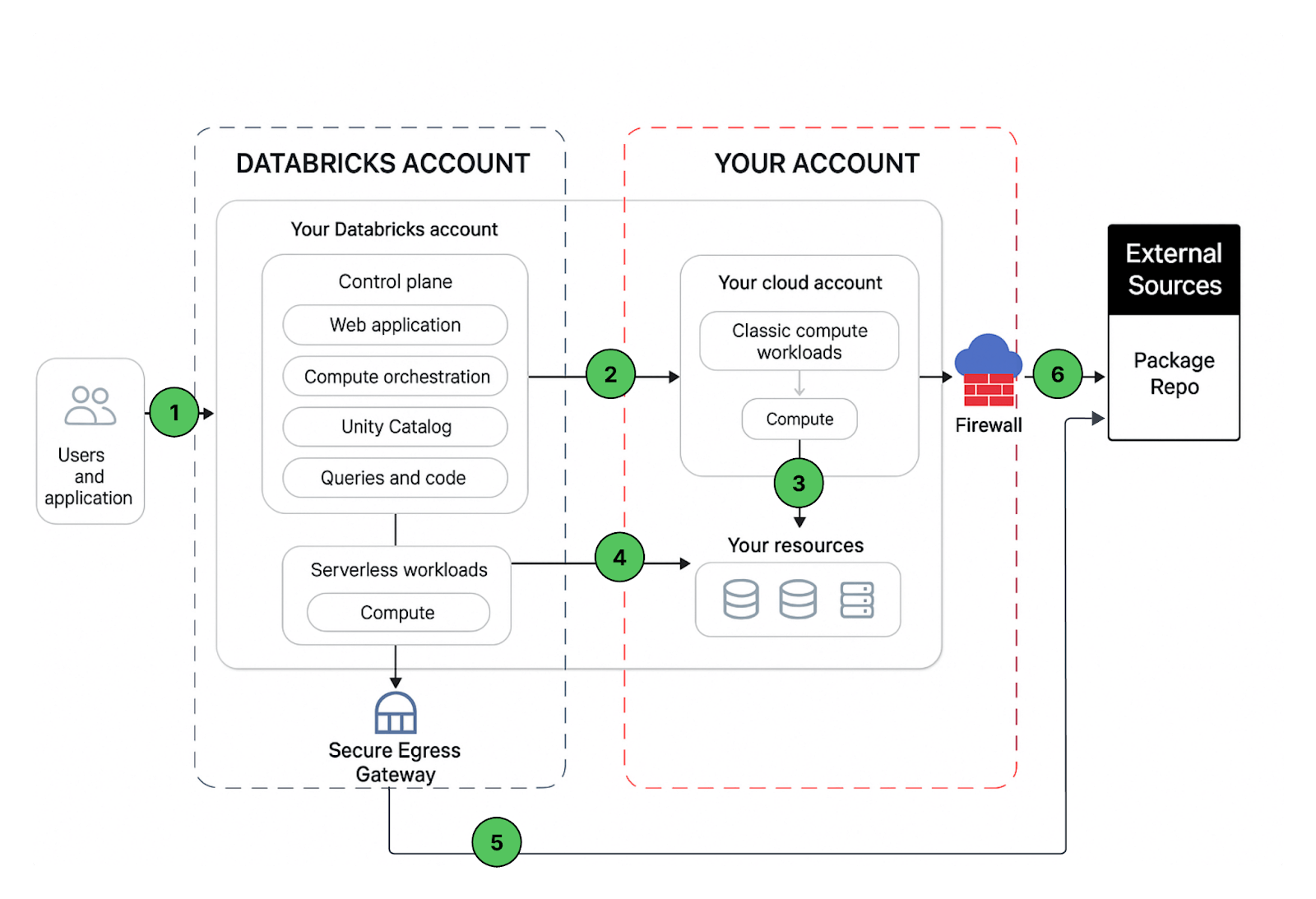
Un déploiement d'espace de travail Databricks comprend les chemins réseau suivants que vous pourriez sécuriser :
- Utilisateur ou Applications vers l'application Web Azure Databricks, alias espace de travail ou API REST Databricks
- Réseau virtuel du plan de calcul classique Azure Databricks vers le service du plan de contrôle Azure Databricks. Cela inclut le relais de connectivité sécurisée des clusters et la connexion de l'espace de travail aux points de terminaison de l'API REST.
- Plan de calcul classique vers vos services de stockage (par exemple, ADLS gen2, base de données SQL)
- Plan de calcul serverless vers vos services de stockage (par exemple, ADLS gen2, base de données SQL)
- Sortie sécurisée du plan de calcul serverless via des stratégies réseau (pare-feu de sortie) vers des sources de données externes, par exemple des dépôts de paquets comme pypi ou maven
- Sortie sécurisée du plan de calcul classique via un pare-feu de sortie vers des sources de données externes, par exemple des dépôts de paquets comme pypi ou maven (cela pourrait être n'importe quel appareil de sortie exécuté sur Azure, par exemple Palo Alto)
Du point de vue de l'utilisateur final, l'élément 1 nécessite des contrôles d'entrée, et les éléments 2 à 6 nécessitent des contrôles de sortie.
Dans cet article, notre domaine d'intérêt est de sécuriser le trafic de sortie de vos charges de travail Databricks, de fournir au lecteur des conseils prescriptifs sur l'architecture de déploiement proposée et, pendant que nous y sommes, nous partagerons les meilleures pratiques pour sécuriser également le trafic d'entrée (utilisateur/client vers Databricks).
Options de déploiement d'espace de travail
Il existe plusieurs options pour créer un espace de travail Azure Databricks sécurisé accessible depuis des connexions sur site ou VPN (sans accès Internet). Comme meilleure pratique, nous recommandons de sécuriser l'accès à l'espace de travail en utilisant des points de terminaison privés (Private Link), soit via un déploiement standard, soit via un déploiement simplifié. L'option recommandée est le déploiement standard. L'espace de travail peut être déployé via le portail Azure ou via les modèles ARM tout-en-un, ou en utilisant les modèles Terraform de l'Architecture de Référence de Sécurité (SRA), qui permettent le déploiement d'espaces de travail Databricks et d'infrastructures cloud configurés selon les meilleures pratiques de sécurité.
Private Link Front End vs Back End : Private Link Front End, également appelé connexion utilisateur à espace de travail. Private Link Back End, également appelé plan de calcul vers plan de contrôle :
Déploiement standard (recommandé) : Pour une sécurité améliorée, Databricks vous recommande d'utiliser un point de terminaison privé distinct pour vos connexions front-end (client) à partir d'un VNet de transit séparé. Vous pouvez implémenter des connexions Private Link front-end et back-end, ou uniquement la connexion back-end. Utilisez un VNet séparé pour encapsuler l'accès utilisateur, distinct du VNet que vous utilisez pour vos ressources de calcul dans le plan de données classique. Créez des points de terminaison Private Link séparés pour l'accès back-end et front-end. Suivez les instructions dans Activer Azure Private Link en tant que déploiement standard.
Une considération supplémentaire est nécessaire pour l'accès au stockage système, à la messagerie et aux métadonnées depuis le plan de calcul, car ces services ne sont pas accessibles via le point de terminaison privé back-end.
Comptes de stockage gérés par le système (plan de calcul classique uniquement) : Ces comptes de stockage sont nécessaires pour démarrer et surveiller les clusters Databricks. Ces comptes de stockage se trouvent dans le locataire Databricks et doivent être autorisés via des politiques de point de terminaison de service (recommandé). Les alternatives seraient d'utiliser des balises de service de stockage qui ont tendance à être trop larges et facilitent l'exfiltration de données, ou l'ajout à une liste d'autorisation individuelle du FQDN ou des adresses IP (non recommandé) :
- Artefact : Images Databricks Runtime en lecture seule > 11 Go / nœud de cluster
- Journalisation : Messagerie intensive en lecture/écriture, y compris la journalisation d'audit.
- Tables système : Données d'audit, UC et système en lecture seule.
Stockage par défaut de l'espace de travail (DBFS) : Système de fichiers distribué commun utilisé pour l'espace temporaire, les services, les résultats SQL temporaires (récupération cloud), les pilotes. Peut être sécurisé via des points de terminaison privés en utilisant la fonctionnalité DBFS privée pour le calcul classique et le point de terminaison de service ou le point de terminaison privé pour le calcul serverless.
Messagerie : (Event Hub, plan de calcul classique uniquement) Il s'agit d'une ressource publiquement accessible utilisée pour le suivi de lignage et d'autres communications légères. Peut être autorisée via la balise de service EventHub au niveau de l'UDR et/ou du pare-feu.
Métadonnées : (SQL, plan de calcul classique uniquement) Il s'agit d'une ressource publiquement accessible utilisée pour le trafic de métastore Hive hérité.
Accès au compte de stockage utilisateur : Comptes ALDS et Blob Storage utilisés pour les données client par opposition aux données système.
Ressources de première partie : Cosmos DB, Azure SQL, DataFactory, etc…
Ressources externes : S3, BigQuery, Snowflake, etc…
Architecture de protection contre l'exfiltration de données de haut niveau
Nous recommandons une architecture de référence hub and spoke. Dans ce modèle, le réseau virtuel hub héberge l'infrastructure partagée nécessaire pour se connecter aux sources validées et, éventuellement, aux environnements sur site. Les réseaux virtuels spoke sont appairés avec le hub et contiennent des espaces de travail Azure Databricks isolés pour différentes unités commerciales ou équipes.
Cette architecture hub-and-spoke permet la création de plusieurs VNet spoke adaptés à divers usages et équipes. L'isolation peut également être obtenue en créant des sous-réseaux séparés pour différentes équipes au sein d'un seul grand réseau virtuel. Dans ces cas, vous pouvez établir plusieurs espaces de travail Azure Databricks isolés, chacun dans sa propre paire de sous-réseaux, et déployer Azure Firewall dans un sous-réseau séparé au sein du même réseau virtuel.
Prérequis
| Élément | Détails |
|---|---|
| Réseau virtuel |
|
| Sous-réseaux | Trois sous-réseaux : Hôte (Public), Conteneur (Privé) et Sous-réseau de point de terminaison privé (pour héberger les points de terminaison privés pour le stockage, DBFS et d'autres services Azure que vous pourriez utiliser) |
| Tables de routage | Canaliser le trafic sortant des sous-réseaux Databricks vers l'appliance réseau, Internet ou les sources de données sur site |
| Azure Firewall | Inspecter tout le trafic sortant et prendre des mesures conformément aux politiques d'autorisation/refus |
| Zones DNS privées | Fournir un service DNS fiable et sécurisé pour gérer et résoudre les noms de domaine dans un réseau virtuel (peuvent être créées automatiquement dans le cadre du déploiement si elles ne sont pas disponibles) |
| Politiques de point de terminaison de service | Politiques pour autoriser l'accès à tous les comptes de stockage ne nécessitant pas de point de terminaison privé, y compris le stockage système pour le compte de stockage de l'espace de travail (dbfs), le stockage d'artefacts et de journaux, et les tables système. |
| Azure Key Vault | Stocke la CMK pour le chiffrement de DBFS, des disques managés et des services managés. |
| Connecteur d'accès Azure Databricks | Requis si Unity Catalog est activé. Pour connecter des identités managées à un compte Azure Databricks afin d'accéder aux données enregistrées dans Unity Catalog |
| Liste des services Azure Databricks à autoriser sur le pare-feu | Veuillez suivre cette documentation publique et dresser une liste de toutes les adresses IP et noms de domaine pertinents pour votre déploiement Databricks |
Architecture de déploiement
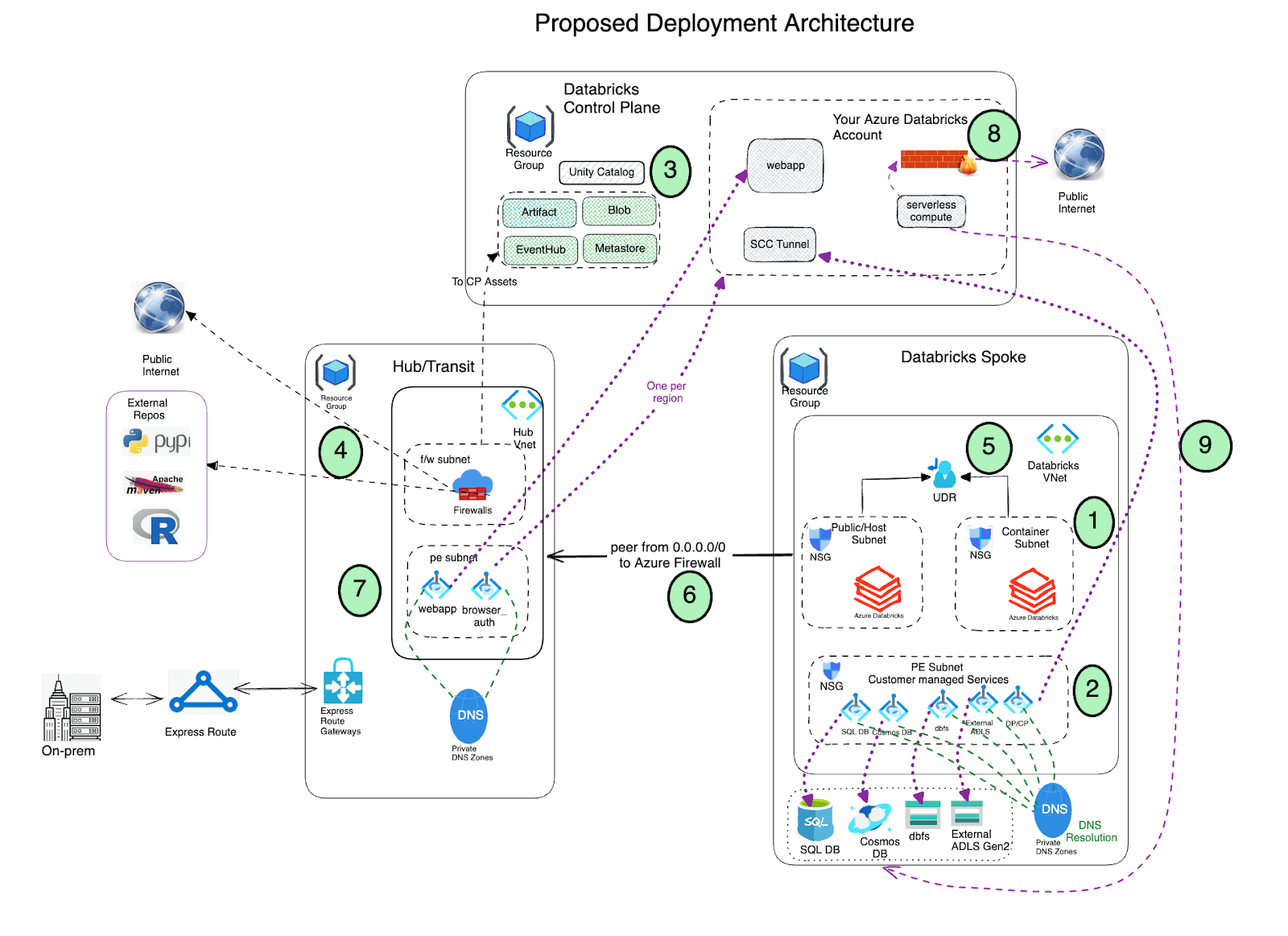
- Déployez Azure Databricks avec la connectivité de cluster sécurisée (SCC) activée dans un réseau virtuel spoke en utilisant l'injection de VNet et Private Link.
- Le réseau virtuel doit inclure deux sous-réseaux dédiés à chaque espace de travail Azure Databricks : un sous-réseau privé et un sous-réseau public (n'hésitez pas à utiliser une autre nomenclature). Notez qu'il existe une relation un-à-un entre ces sous-réseaux et un espace de travail Azure Databricks. Vous ne pouvez pas partager plusieurs espaces de travail sur la même paire de sous-réseaux, et vous devez utiliser une nouvelle paire de sous-réseaux pour chaque espace de travail différent.
- Azure Databricks crée un stockage blob par défaut (également appelé stockage racine) lors du processus de déploiement, qui est utilisé pour stocker les journaux et la télémétrie. Bien que l'accès public soit activé sur ce stockage, l'affectation de refus créée sur ce stockage interdit tout accès externe direct au stockage ; il ne peut être accédé que via l'espace de travail Databricks. Les déploiements Azure Databricks prennent désormais en charge la connectivité privée au compte de stockage de l'espace de travail par défaut (DBFS).
- Important : Comme meilleure pratique, il est NON recommandé de stocker des données d'application dans le conteneur racine (DBFS). L'accès au conteneur racine DBFS peut maintenant être désactivé et nous recommandons à la place d'utiliser les volumes Unity Catalog. Les volumes Unity Catalog offrent une gouvernance et une sécurité modernes par rapport au stockage racine DBFS.
- Configurez des points de terminaison Private Link pour vos services de données Azure (comptes de stockage, Eventhub, bases de données SQL, etc.) dans un sous-réseau distinct au sein du réseau virtuel spoke d'Azure Databricks. Cela garantirait que toutes les données de charge de travail sont accessibles de manière sécurisée sur le réseau dorsal d'Azure, avec une protection par défaut contre l'exfiltration de données (voir ce blog pour plus de détails). De plus, il est tout à fait acceptable de déployer ces points de terminaison dans un autre réseau virtuel qui est appairé à celui hébergeant l'espace de travail Azure Databricks. Notez que les points de terminaison privés entraînent des coûts supplémentaires et qu'il est acceptable d'utiliser (conformément aux politiques de sécurité de votre organisation) des points de terminaison de service au lieu de points de terminaison privés pour accéder aux services de données Azure, en particulier en utilisant des stratégies de point de terminaison de service pour un accès sécurisé aux comptes de stockage
- Utilisez Azure Databricks Unity Catalog pour une solution de gouvernance unifiée.
Déployez Azure Firewall (ou une autre appliance virtuelle réseau) dans un réseau virtuel hub. Avec Azure Firewall, vous pouvez configurer :
- Règles d'application qui définissent les noms de domaine complets (FQDN) accessibles via le pare-feu. Il est fortement recommandé d'utiliser des règles d'application pour les ressources du plan de contrôle d'Azure Databricks contrôle plane, par exemple le plan de contrôle, l'application web et le relais SCC.
- Règles réseau qui définissent l'adresse IP, le port et le protocole pour les points de terminaison qui ne peuvent pas être configurés à l'aide de FQDN. Une partie du trafic Azure Databricks requis doit être mise sur liste blanche à l'aide des règles réseau.
Si vous utilisez un appareil de pare-feu tiers au lieu d'Azure Firewall, cela fonctionne également. Veuillez noter que chaque produit a ses propres particularités et qu'il est préférable de faire appel aux équipes de support produit et de sécurité réseau concernées pour résoudre tout problème pertinent.
- Le tag de service AzureDatabricks n'est pas requis si des points de terminaison privés sont activés pour l'espace de travail.
- Lors de l'utilisation de stratégies de point de terminaison de service, il n'est pas nécessaire de configurer des règles réseau pour les comptes de stockage gérés par Databricks (artefacts, journaux et tables système) dans le pare-feu. De plus, aucun tag de service de stockage n'est nécessaire ni recommandé.
- Azure Databricks effectue également des appels supplémentaires aux services NTP, CDN, Cloudflare, aux pilotes GPU et aux stockages externes pour les jeux de données de démonstration qui doivent être mis sur liste blanche de manière appropriée.
Le trafic réseau non local des sous-réseaux du plan de calcul Databricks doit être acheminé via un appareil de sortie tel qu'Azure Firewall à l'aide d'une route définie par l'utilisateur (par exemple, une route par défaut 0.0.0.0/0). Cela garantit que tout le trafic sortant est inspecté. Cependant, la sortie vers le plan de contrôle, utilisant des points de terminaison privés, contournera ces tables de routage et ces appareils de sortie. D'autres composants du plan de contrôle, tels que SQL, Event Hubs et le stockage, seront cependant acheminés via votre appareil de sortie.
- Pour les comptes de stockage de service Databricks (artefacts, journaux et tables système), vous pouvez envisager de contourner votre appareil de sortie (NVA ou pare-feu) pour éviter les limitations potentielles et réduire les coûts de transfert de données. L'accès au stockage d'artefacts seul peut représenter jusqu'à 11 Go téléchargés par nœud de cluster. Nous recommandons d'utiliser des points de terminaison de service pour le stockage en conjonction avec des stratégies de point de terminaison de service. Ces stratégies garantissent que l'espace de travail ne peut accéder qu'aux comptes de stockage d'artefacts, de journaux et de tables système désignés inclus dans sa stratégie attachée via son sous-réseau. Les stratégies de point de terminaison de service sont également compatibles avec d'autres accès aux comptes de stockage sans liaison privée. Avec les stratégies de point de terminaison de service, aucun tag de service de stockage n'est nécessaire ni recommandé.
- Alternativement, le trafic de sortie vers les actifs du plan de contrôle peut être acheminé directement vers Internet en ajoutant des règles de tag de service à la table de routage, contournant ainsi le pare-feu. Cela peut aider à éviter les limitations et les coûts de transfert de données supplémentaires associés aux appareils virtuels réseau.
Considération importante : Veuillez noter que cela permettra la sortie vers des comptes de stockage et des services dans toute la région, et pas seulement vers ceux auxquels vous avez l'intention d'accéder. C'est un facteur critique à considérer attentivement lors de la conception de votre architecture de sécurité.
- Configurez l'appairage de réseaux virtuels entre les réseaux virtuels spoke d'Azure Databricks et hub Azure Firewall.
- Déployez des points de terminaison privés pour le frontal et l'authentification par navigateur (pour le SSO) sur le VNet Hub (sous-réseau de point de terminaison privé).
- Configurez les stratégies réseau de calcul serverless pour régir le trafic réseau sortant. Notez que le calcul serverless est lié à votre compte Azure Databricks.
- Configurez la Configuration de connectivité réseau (NCC) d'Azure Databricks pour établir une connexion sécurisée entre vos ressources de calcul serverless et vos services de stockage Azure (tels qu'ADLS Gen2 et SQL Database) à l'aide d'Azure Private Link.
Questions fréquentes sur l'architecture de protection contre l'exfiltration de données
Puis-je utiliser des points de terminaison de service pour sécuriser la sortie des données vers les services de données Azure ?
Oui, les points de terminaison de service fournissent une connectivité sécurisée et directe aux services Azure détenus et gérés par les clients (par exemple, ADLS gen2, Azure KeyVault ou EventHub) via un itinéraire optimisé sur le réseau dorsal d'Azure. Les points de terminaison de service peuvent être utilisés pour sécuriser la connectivité aux ressources Azure externes uniquement à votre réseau virtuel.
Puis-je utiliser des stratégies de point de terminaison de service avec les services de stockage gérés par Databricks ?
Oui, les stratégies de point de terminaison de service sont disponibles en aperçu public à partir du 01/10/2025. Voir : Configurer les stratégies de point de terminaison de service de réseau virtuel Azure pour l'accès au stockage à partir du calcul classique
Puis-je utiliser un appareil virtuel réseau (NVA) autre qu'Azure Firewall ?
Oui, vous pouvez utiliser un NVA tiers tant que les règles de trafic réseau sont configurées comme indiqué dans cet article. Veuillez noter que nous avons testé cette configuration uniquement avec Azure Firewall, bien que certains de nos clients utilisent d'autres appareils tiers. Il est idéal de déployer l'appareil dans le cloud plutôt que sur site.
Puis-je avoir un sous-réseau de pare-feu dans le même réseau virtuel qu'Azure Databricks ?
Oui, vous le pouvez. Conformément à l'architecture de référence Azure, il est conseillé d'utiliser une topologie de réseau virtuel hub-spoke pour mieux planifier l'avenir. Si vous choisissez de créer le sous-réseau Azure Firewall dans le même réseau virtuel que les sous-réseaux de l'espace de travail Azure Databricks, vous n'aurez pas besoin de configurer l'appairage de réseaux virtuels comme mentionné à l'étape 6 ci-dessus.
Puis-je filtrer le trafic IP du relais SCC du plan de contrôle Azure Databricks via Azure Firewall ?
Oui, vous le pouvez, mais nous aimerions que vous gardiez ces points à l'esprit :
- Lorsque vous utilisez des points de terminaison privés pour le plan de contrôle Databricks, le trafic entre les clusters Azure Databricks (plan de données) et le service SCC Relay reste privé sur le réseau Azure et ne transite pas par Internet public. Il s'agit principalement d'un trafic de gestion pour s'assurer que l'espace de travail Azure Databricks fonctionne correctement.
- Lorsque vous utilisez un accès sans liaison privée au plan de contrôle Databricks, les plages CIDR SCC Relay et WebUI sont couvertes par le tag de service AzureDatabricks. Pour d'autres types de pare-feu / NVA, reportez-vous à la dernière version des adresses IP et domaines pour les services et actifs Azure Databricks. Nous recommandons fortement d'utiliser un FQDN de règle d'application pour le tunnel SCC dans vos configurations de règles de pare-feu.
- Le service SCC Relay et le plan de données nécessitent une communication réseau stable et fiable. Avoir un pare-feu ou un appareil virtuel entre eux introduit un point de défaillance unique, par exemple en cas de mauvaise configuration d'une règle de pare-feu ou d'une interruption planifiée, ce qui peut entraîner des retards excessifs dans le démarrage du cluster (problème de pare-feu transitoire) ou empêcher la création de nouveaux clusters, ou affecter la planification et l'exécution des tâches.
Puis-je analyser le trafic accepté ou bloqué par Azure Firewall ?
Oui, nous vous recommandons d'utiliser les journaux et métriques d'Azure Firewall pour cette exigence.
Puis-je mettre à niveau un déploiement Databricks géré existant non-NPIP vers un espace de travail activé NPIP ou PL ?
Oui, le déploiement Databricks géré peut être mis à niveau vers un espace de travail injecté dans un VNet.
Pourquoi avons-nous besoin de deux sous-réseaux par espace de travail ?
Un espace de travail nécessite deux sous-réseaux, populairement connus sous le nom de sous-réseau « hôte » (également appelé « public ») et « conteneur » (également appelé « privé »). Chaque sous-réseau fournit une adresse IP à l'hôte (VM Azure) et au conteneur (runtime Databricks aka dbr) qui s'exécute à l'intérieur de la VM.
Le sous-réseau public ou hôte a-t-il des IP publiques ?
Non, lorsque vous créez un espace de travail en utilisant la connectivité de cluster sécurisée aka SCC, aucun des sous-réseaux de Databricks n'a d'adresses IP publiques. C'est juste que le nom par défaut du sous-réseau hôte est public-subnet. SCC garantit qu'aucun trafic réseau provenant de l'extérieur de votre réseau n'entre, par exemple, par SSH dans l'une des instances de calcul de l'espace de travail Databricks.
Est-il possible de redimensionner/modifier les tailles de sous-réseau après le déploiement ?
Oui, il est possible de redimensionner ou de modifier les tailles de sous-réseau après le déploiement. Il est également possible de modifier le réseau virtuel ou de changer les noms de sous-réseau. (aperçu public limité). Veuillez contacter le support Azure et soumettre un cas de support pour le redimensionnement des sous-réseaux.
Est-il possible d'échanger/modifier les réseaux virtuels après le déploiement ?
Oui, veuillez vous référer à la documentation publique.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.