Databricks Lakehouse et Data Mesh, partie 1
par Sharon Richardson, Bernhard Walter, Pawarit Laosunthara, Guillermo Schiava D'Albano, Fran Medina Castro et Amr Ali
Ceci est le premier article d'une série en deux parties. Dans cet article, nous présenterons le concept de data mesh et les capacités de Databricks disponibles pour implémenter un data mesh. Le deuxième article examinera différentes options de data mesh et fournira des détails sur l'implémentation d'un data mesh basé sur le Databricks Lakehouse.
Le data mesh est un paradigme qui décrit un ensemble de principes et une architecture logique pour la mise à l'échelle des plateformes d'analyse de données. L'objectif est de tirer davantage de valeur des données en tant qu'actif à grande échelle. L'expression « data mesh » a été introduite par Zhamak Dehghani en 2019 et développée dans son article de 2020 Data Mesh Principles and Logical Architecture.
Au cœur de l'architecture logique du data mesh se trouvent quatre principes :
- Propriété des domaines : adoption d'une architecture distribuée où les équipes de domaine – producteurs de données – conservent la pleine responsabilité de leurs données tout au long de leur cycle de vie, de la capture à la curation en passant par l'analyse et la réutilisation
- Données en tant que produit : application des principes de gestion de produit au cycle de vie de l'analyse des données, garantissant que des données de qualité sont fournies aux consommateurs de données qui peuvent se trouver à l'intérieur et au-delà du domaine du producteur
- Plateforme d'infrastructure en libre-service : adoption d'une approche indépendante des domaines pour le cycle de vie de l'analyse des données, en utilisant des outils et des méthodes communs pour construire, exécuter et maintenir des produits de données interopérables
- Gouvernance fédérée : garantie d'un écosystème de données qui respecte les règles organisationnelles et les réglementations de l'industrie par la standardisation
Les produits de données sont un concept important pour le data mesh. Ils ne sont pas destinés à être de simples ensembles de données, mais des données traitées comme un produit : ils doivent être découvrables, fiables, auto-descriptifs, adressables et interopérables. Outre les données et les métadonnées, ils peuvent contenir du code, des tableaux de bord, des fonctionnalités, des modèles et d'autres ressources nécessaires à la création et à la maintenance du produit de données.
De nombreux clients demandent : « Pouvons-nous créer un data mesh avec Databricks Lakehouse ? » La réponse est oui ! Plusieurs des plus grands clients de Databricks dans le monde ont adopté le data mesh en utilisant le Lakehouse comme fondation technologique.
Databricks Lakehouse est une plateforme de données, d'analyse et d'IA native dans le cloud qui combine les performances et les fonctionnalités d'un entrepôt de données avec le faible coût, la flexibilité et l'évolutivité d'un lac de données moderne. Pour une introduction, veuillez lire Qu'est-ce qu'un Lakehouse ?
Le Lakehouse répond à une préoccupation fondamentale des lacs de données qui a conduit aux principes du data mesh – qu'un lac de données monolithique peut devenir un marais de données ingérable. Le Databricks Lakehouse est une architecture ouverte qui offre une flexibilité dans la manière dont les données sont organisées et structurées, tout en fournissant une infrastructure de gestion unifiée pour toutes les charges de travail de données et d'analyse.
L'unité d'organisation principale au sein de la plateforme Databricks Lakehouse qui correspond au concept de domaines dans un data mesh est l'« espace de travail ». Un Databricks Lakehouse peut avoir un ou plusieurs espaces de travail, chaque espace de travail permettant une propriété locale des données et un contrôle d'accès.
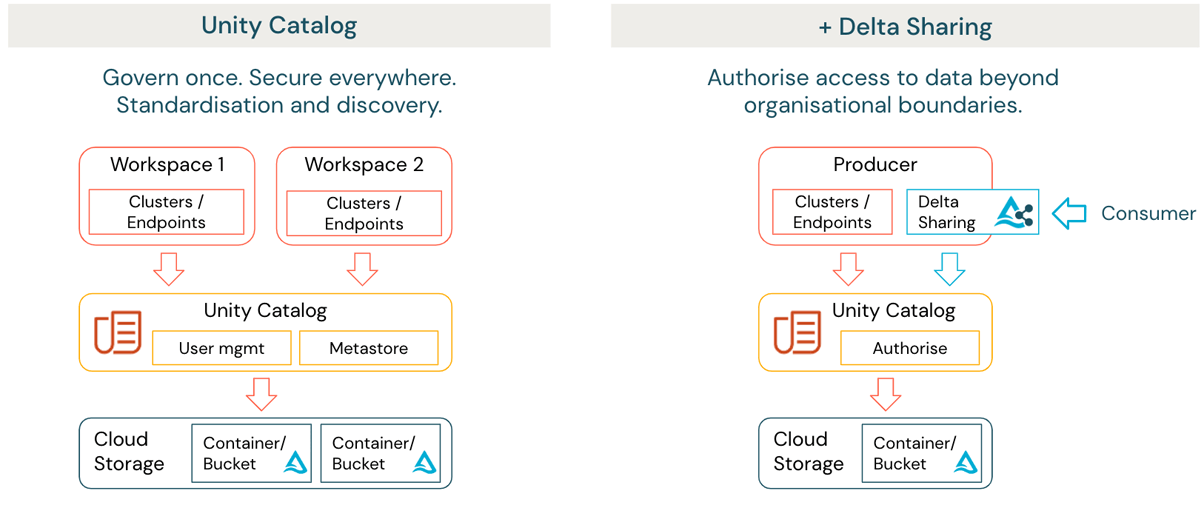
{kind=link}
Chaque espace de travail encapsule un ou plusieurs domaines, sert de lieu de collaboration et permet au(x) domaine(s) de gérer ses produits de données à l'aide d'une infrastructure commune en libre-service et indépendante des domaines. Cela peut inclure l'automatisation du provisionnement de l'environnement et l'orchestration des pipelines de données à l'aide de services intégrés tels que Databricks Workflows, et l'automatisation du déploiement à l'aide du fournisseur Terraform de Databricks. Unity Catalog fournit une gouvernance fédérée, la découverte et la lignée en tant que service centralisé au niveau du compte de l'organisation exécutant Databricks. (figure 1 côté gauche).
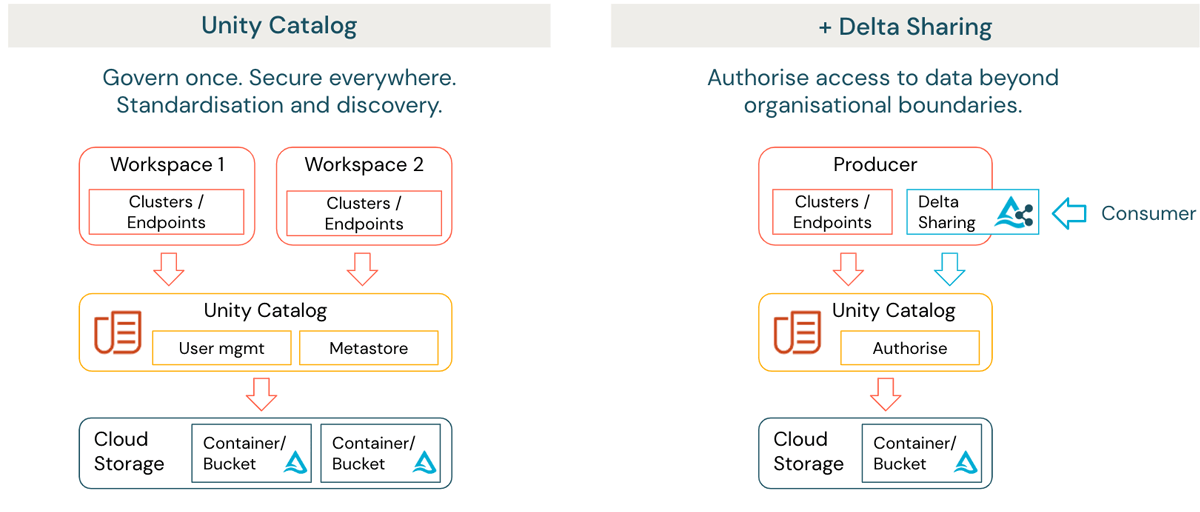
Pour de nombreuses organisations, il est nécessaire d'envisager comment les données peuvent être partagées en toute sécurité avec des parties externes au-delà d'une frontière de gouvernance. Cela peut également s'appliquer aux domaines internes hébergés sur différents fournisseurs de cloud et régions. Databricks Lakehouse offre une solution sous la forme de Delta Sharing (figure 1 côté droit). Delta Sharing permet aux organisations de partager des données en toute sécurité avec des parties externes, quelle que soit la plateforme de calcul. Les données n'ont pas besoin d'être dupliquées et l'accès est automatiquement audité et enregistré.
Delta Sharing fournit également la base pour une gamme plus large d'activités de partage de données externes. Cela inclut la publication ou l'acquisition de données via une place de marché de données telle que la Databricks Marketplace, et la collaboration sécurisée sur les données au-delà des frontières organisationnelles et techniques, activée au sein de la plateforme Databricks en tant que Databricks Clean Rooms.
La combinaison de Unity Catalog et Delta Sharing signifie que la plateforme Databricks Lakehouse offre une flexibilité quant à la manière dont une organisation choisit d'organiser et de gérer les données et l'analyse à grande échelle, y compris les déploiements qui couvrent plusieurs fournisseurs de cloud, différentes régions géographiques et les déploiements qui nécessitent la capacité de partager des actifs de données avec des entités externes. Avec Databricks Lakehouse, les données peuvent être organisées dans un data mesh, mais peuvent également être organisées selon toute architecture appropriée, du entièrement centralisé au entièrement distribué.
La deuxième partie de cet article examinera différentes options de data mesh et fournira des détails sur la manière d'implémenter un data mesh basé sur Databricks Lakehouse.
Pour en savoir plus sur les capacités de Databricks Lakehouse mentionnées dans cet article :
- Qu'est-ce qu'un Lakehouse
- Qu'est-ce que Databricks Lakehouse
- Présentation de Databricks Unity Catalog
- Présentation de Databricks Delta Sharing
- Présentation de Databricks Clean Rooms
- Présentation de Databricks Marketplace
- Fournisseur Terraform Databricks
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.