Databricks à SIGMOD 2026
par Indrajit Roy
- Découvrez comment Databricks innove dans la prochaine génération d'ingénierie de données avec Spark Declarative Pipelines (SDP), simplifiant les charges de travail ETL et de streaming complexes.
- Obtenez une analyse approfondie d'Enzyme, notre moteur de maintenance incrémentale des vues, qui a remporté une mention honorable à la conférence SIGMOD.
- Rencontrez nos ingénieurs à la conférence pour discuter de ces innovations leaders de l'industrie.
Databricks continue de montrer la voie en matière d'innovation en ingénierie, repoussant constamment les limites de ce qui est possible dans l'espace des Données et de l'IA. Nous sommes ravis d'annoncer que notre travail sur Spark Declarative Pipelines sera présenté à SIGMOD 2026 et a reçu une mention honorable lors de la conférence. Nous nous rendons à SIGMOD, du 1er au 5 juin, en tant que sponsor Platine. SIGMOD aura lieu à Bangalore, en Inde, qui est également un important centre de R&D de Databricks.
Nos prochains articles sur l'ingénierie des données montrent comment Databricks a simplifié le traitement incrémental pour les clients. Il existe deux façons d'écrire des programmes incrémentaux dans Spark Declarative Pipelines (SDP), et les clients peuvent les mélanger et les assortir au sein d'un pipeline :
- Les ingénieurs de données peuvent spécifier des Vues Matérialisées pour les transformations. Le moteur Enzyme les maintient de manière incrémentale à mesure que de nouvelles données arrivent. Toute la complexité du traitement incrémental est complètement masquée aux créateurs des vues matérialisées. L'article SIGMOD 2026, « Enzyme : Incremental View Maintenance for Data Engineering », aborde certaines de ces idées.
- Les ingénieurs de données qui maîtrisent le traitement de flux peuvent plutôt utiliser le moteur de flux de SDP pour traiter les données de manière incrémentale. Les API de flux offrent une grande variété de constructions - des opérateurs stateful aux watermarks, ce qui facilite l'expression de logiques métier complexes comme les agrégations personnalisées. Les idées clés de notre produit de flux apparaîtront dans l'article VLDB 2026, « A Decade of Apache Spark Structured Streaming: How We Evolved the Architecture To Meet Real-world Needs ».
Voici un aperçu de l'article Enzyme et de ce sur quoi l'équipe a travaillé :
Enzyme à SIGMOD 2026
Maintenance incrémentale des vues
Supposons que vous soyez un analyste dans une entreprise et que vous souhaitiez analyser le nombre total de commandes vendues dans une région. La vue matérialisée ci-dessous fournit la réponse.
CREATE MATERIALIZED VIEW order_report as
SELECT region, sum(orders)
FROM customer_and_order_table
GROUP by region
À mesure que de nouvelles commandes sont ajoutées, vous vous attendez à ce que la vue matérialisée reste à jour. Cette maintenance des données est essentiellement le problème de la maintenance incrémentale des vues. Bien que la mise à jour de la MV jouet ci-dessus semble simple, imaginez si la MV devait joindre des données de plusieurs tables, avait des fonctions de fenêtre ou faisait des appels à des fonctions LLM.
Innovations d'Enzyme
Les vues matérialisées (MV) sont populaires pour l'accélération des requêtes - accélérant les tableaux de bord sur les données résidant dans les entrepôts de données. Lors de la création de Spark Declarative Pipelines, nous avons décidé d'aller au-delà de l'accélération des requêtes et d'appliquer les vues matérialisées aux cas d'utilisation ETL (extract-transform-load). Notre observation clé est que si les MV peuvent être maintenues efficacement et de manière incrémentale, cela simplifiera considérablement les charges de travail ETL qui, autrement, nécessiteraient l'écriture de code personnalisé complexe.
Enzyme s'ajoute à la riche littérature sur la maintenance incrémentale des vues matérialisées et démontre comment adapter ces techniques aux charges de travail de production. Voici quelques-unes des innovations sur lesquelles l'équipe a travaillé :
- Prise en charge de modèles MV étendus : Enzyme maintient de manière incrémentale des MV complexes en production, y compris celles avec des jointures, des fonctions de fenêtre, des agrégations et leurs combinaisons. Contrairement à d'autres solutions industrielles, Enzyme prend également en charge les fonctions non déterministes telles que current_date() et les fonctions spécifiques à l'IA.
- Prise en charge multilingue : Alors que la plupart des solutions industrielles se concentrent uniquement sur SQL, Enzyme prend également en charge les MV spécifiées en Python. Python est maintenant le langage de choix pour la plupart des charges de travail d'ingénierie de données et d'IA. Enzyme résout de nombreux défis intéressants que la prise en charge multilingue implique, tels que la détection précise des modifications dans la définition de la MV.
- Optimisations des performances : Enzyme dispose de plusieurs optimisations pour réduire la quantité de données à traiter, y compris des techniques qui déterminent automatiquement si les mises à jour doivent être appliquées au niveau de la partition plutôt qu'au niveau de la ligne, réduisant ainsi les surcoûts de réécriture. Il met en cache sélectivement les résultats intermédiaires pour réduire les coûts d'E/S. Il utilise un modèle de coûts qui exploite les informations de plan et les exécutions antérieures pour déterminer la stratégie d'incrémentalisation la plus efficace.
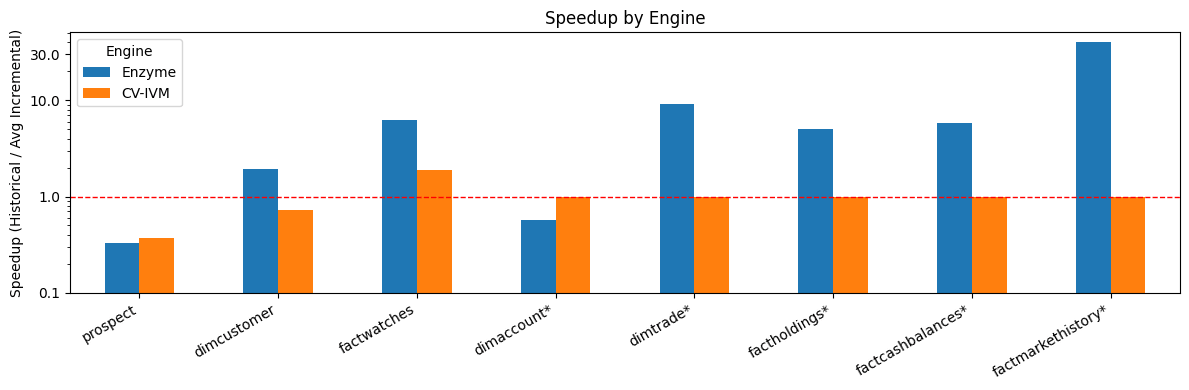
Figure 1 : Enzyme a des performances significativement meilleures qu'une autre solution industrielle concurrente (nom anonymisé en CV-IVM pour des raisons de restrictions de licence).
Vous souhaitez en savoir plus ? Consultez l'article et si vous êtes à SIGMOD, assistez à notre présentation pour plus de détails.
Rencontrez l'équipe à SIGMOD :
Passez à notre stand pour rencontrer l'équipe et en savoir plus sur l'innovation qui se déroule chez Databricks. De plus, ne manquez pas l'occasion d'entendre directement Ritwik Yadav lors de sa présentation à SIGMOD !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.