Delta UniForm : un format universel pour l'interopérabilité du lakehouse
par Bilal Obeidat, Sirui Sun, Adam Wasserman, Susan Pierce, Fred Liu, Ryan Johnson et Himanshu Raja
Mise à jour : BigQuery prend désormais en charge nativement Delta Lake via BigLake. Consultez la documentation pour plus d'informations.
L'un des principaux défis auxquels les organisations sont confrontées lors de l'adoption du lakehouse de données ouvert est la sélection du format optimal pour leurs données. Parmi les options disponibles, Linux Foundation Delta Lake, Apache Iceberg et Apache Hudi sont tous d'excellents formats de stockage qui permettent la démocratisation et l'interopérabilité des données. Chacun de ces formats est préférable à l'utilisation d'un format propriétaire. Cependant, choisir un seul format de stockage pour se standardiser peut être une tâche ardue, ce qui peut entraîner une fatigue décisionnelle et la peur de conséquences irréversibles.
Delta UniForm (abréviation de Delta Lake Universal Format) offre une unification simple, facile à implémenter et transparente des formats de table sans créer de copies de données ou de silos supplémentaires. Dans ce blog, nous aborderons les points suivants :
- Introduction à Delta UniForm et ses avantages
- Lecture de Delta UniForm en tant que tables Iceberg à l'aide de
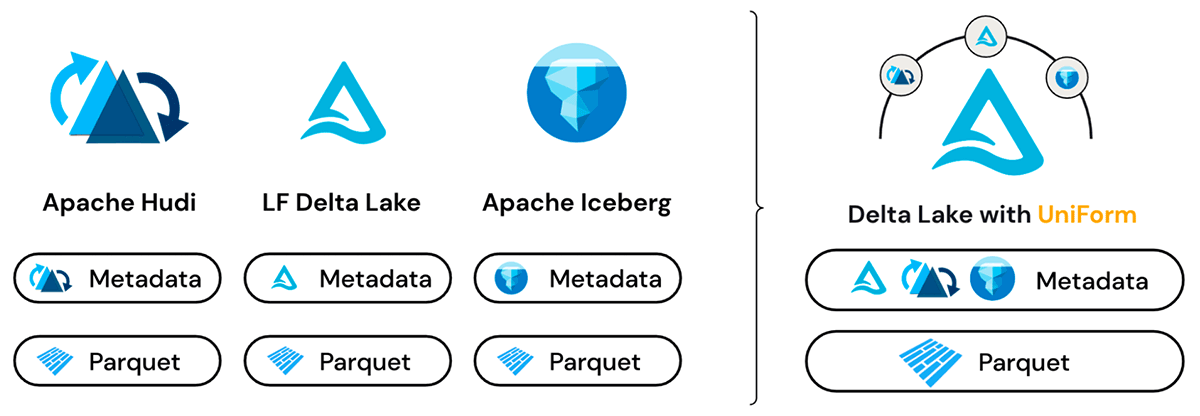
Formats multiples, copie unique des données
Delta UniForm tire parti du fait que Delta Lake, Iceberg et Hudi sont tous construits sur des fichiers de données Apache Parquet. La principale différence entre les formats réside dans la couche de métadonnées, et même là, les différences sont subtiles. Les métadonnées des trois formats servent le même objectif et contiennent des ensembles d'informations qui se chevauchent.
Avant la sortie de Delta UniForm, les méthodes pour passer d'un format de table ouvert à un autre étaient basées sur la copie ou la conversion et ne fournissaient qu'une vue ponctuelle des données. En revanche, Delta UniForm répond aux besoins d'interopérabilité de manière plus élégante en fournissant une vue en direct des données pour tous les lecteurs, quel que soit le format.
Sous le capot, Delta UniForm fonctionne en générant automatiquement les métadonnées pour Iceberg et Hudi aux côtés de Delta Lake - le tout sur une seule copie des données Parquet. Par conséquent, les équipes peuvent utiliser l'outil le plus adapté à chaque charge de travail de données et toutes opèrent sur une source de données unique, avec une interopérabilité parfaite entre les trois écosystèmes différents.
Configuration rapide, surcharge minimale
Delta UniForm est extrêmement facile à configurer, et une fois activé, il fonctionne de manière transparente et automatique.
Pour commencer, créons une table Delta UniForm pour générer les métadonnées Iceberg :
Avec les tables Delta UniForm, les métadonnées pour les formats supplémentaires sont automatiquement créées lors de la création de la table et mises à jour chaque fois que la table est modifiée. Cela signifie qu'il n'est pas nécessaire d'exécuter des commandes de rafraîchissement manuelles ou d'utiliser des ressources de calcul inutiles pour traduire les formats de table. Par exemple, écrivons une ligne dans cette table :
Cette commande déclenche un commit Delta Lake, qui génère ensuite automatiquement et de manière asynchrone les métadonnées Iceberg pour cette table. Ce faisant, Delta UniForm garantit que les pipelines de données ne sont pas interrompus, permettant un accès transparent aux informations les plus récentes pour tous les lecteurs.
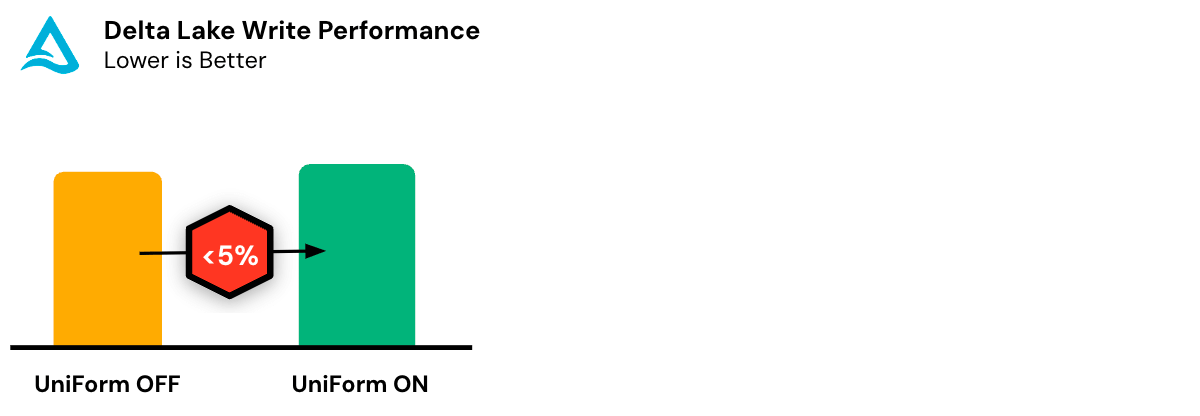
Delta UniForm a une surcharge de performance et de ressources négligeable, garantissant une utilisation optimale des ressources de calcul. Même pour les tables à l'échelle du pétaoctet, les métadonnées ne représentent généralement qu'une infime fraction de la taille des fichiers de données. De plus, Delta UniForm est capable de générer incrémentalement des métadonnées limitées aux changements depuis le dernier commit.
Lecture de Delta UniForm en tant qu'Iceberg
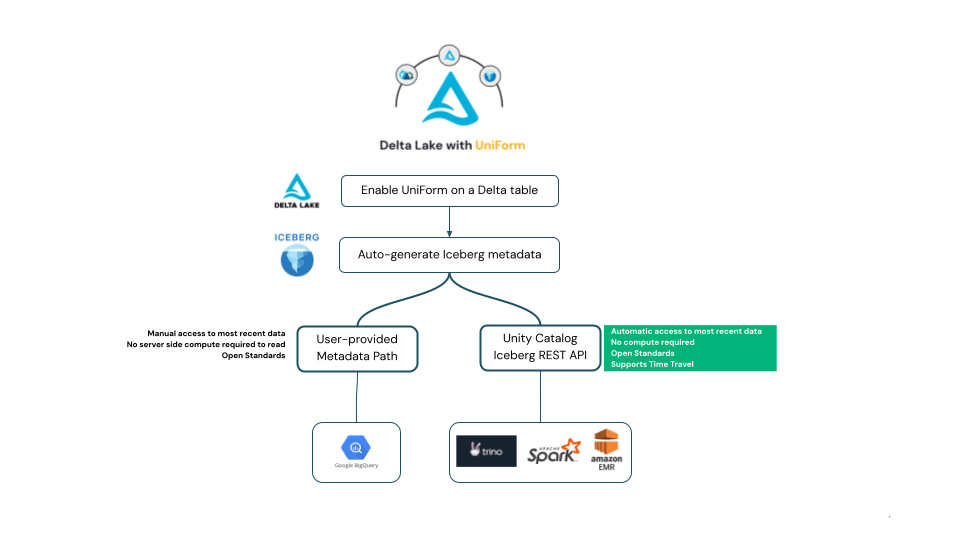
Delta UniForm génère des métadonnées Iceberg conformément à la spécification Apache Iceberg, ce qui signifie que lorsque des données sont écrites dans une table Delta UniForm, la table peut être lue en tant qu'Iceberg par n'importe quel client de l'écosystème Iceberg qui adhère à la spécification open source Iceberg.
Conformément à la spécification Iceberg, les clients lecteurs doivent déterminer quelles métadonnées Iceberg représentent la version la plus récente et la plus à jour de la table Iceberg. Dans l'écosystème Iceberg, nous avons observé que les clients adoptent deux approches différentes, toutes deux prises en charge par UniForm. Nous expliquerons les différences ici, puis fournirons des exemples dans la section suivante.
Certains lecteurs Iceberg exigent que les utilisateurs fournissent le chemin d'accès à un fichier de métadonnées représentant le dernier instantané de la table Iceberg. Cette approche peut être fastidieuse pour les clients, car elle oblige les utilisateurs à fournir des chemins de fichiers de métadonnées mis à jour chaque fois que la table change.
Alternativement, la communauté Iceberg recommande d'utiliser l'API REST de catalogue. Le client communique avec le catalogue pour obtenir le dernier état de la table, permettant aux utilisateurs de lire le dernier état d'une table Iceberg sans rafraîchissements manuels ni souci des chemins de métadonnées.
Unity Catalog implémente désormais l'API ouverte REST de catalogue Iceberg conformément à la spécification Apache Iceberg. Ceci est aligné avec l'engagement de Unity Catalog à prendre en charge les API ouvertes, et s'appuie sur l'élan du support de l'API HMS de Unity Catalog. L'API REST Iceberg de Unity Catalog offre un accès ouvert aux tables UniForm au format Iceberg sans frais de calcul Databricks, tout en permettant l'interopérabilité et la prise en charge du rafraîchissement automatique pour accéder aux données les plus récentes. En conséquence, cela devrait permettre à d'autres catalogues de se fédérer vers Unity Catalog et de prendre en charge les tables Delta UniForm.
Les bibliothèques clientes Apache Iceberg sont pré-empaquetées avec la capacité d'interfacer avec le catalogue API REST Iceberg - ce qui signifie que tout client qui implémente entièrement la norme Apache Iceberg et prend en charge la configuration des points de terminaison de catalogue devrait être en mesure d'accéder facilement au catalogue API REST Iceberg de Unity Catalog et de récupérer les dernières métadonnées de ses tables. Cela élimine la tâche de gestion des métadonnées de table.
Dans la section suivante, nous passerons en revue des exemples de la prise en charge de Delta UniForm pour les approches de chemin de métadonnées et d'API REST de catalogue Iceberg.
Exemple : lire Delta Lake en tant qu'Iceberg dans BigQuery en fournissant l'emplacement des métadonnées
Lors de la lecture d'Iceberg dans un catalogue existant, BigQuery vous demande de fournir un pointeur vers le fichier JSON représentant le dernier instantané Iceberg (documentation BigQuery), comme suit :
Dans BigQuery :
Delta UniForm avec Unity Catalog vous permet de trouver facilement le chemin du fichier de métadonnées Iceberg requis. Unity Catalog expose un certain nombre de propriétés de table Delta Lake, y compris ce chemin. Vous pouvez récupérer l'emplacement des métadonnées de votre table Delta UniForm via l'interface utilisateur ou l'API.
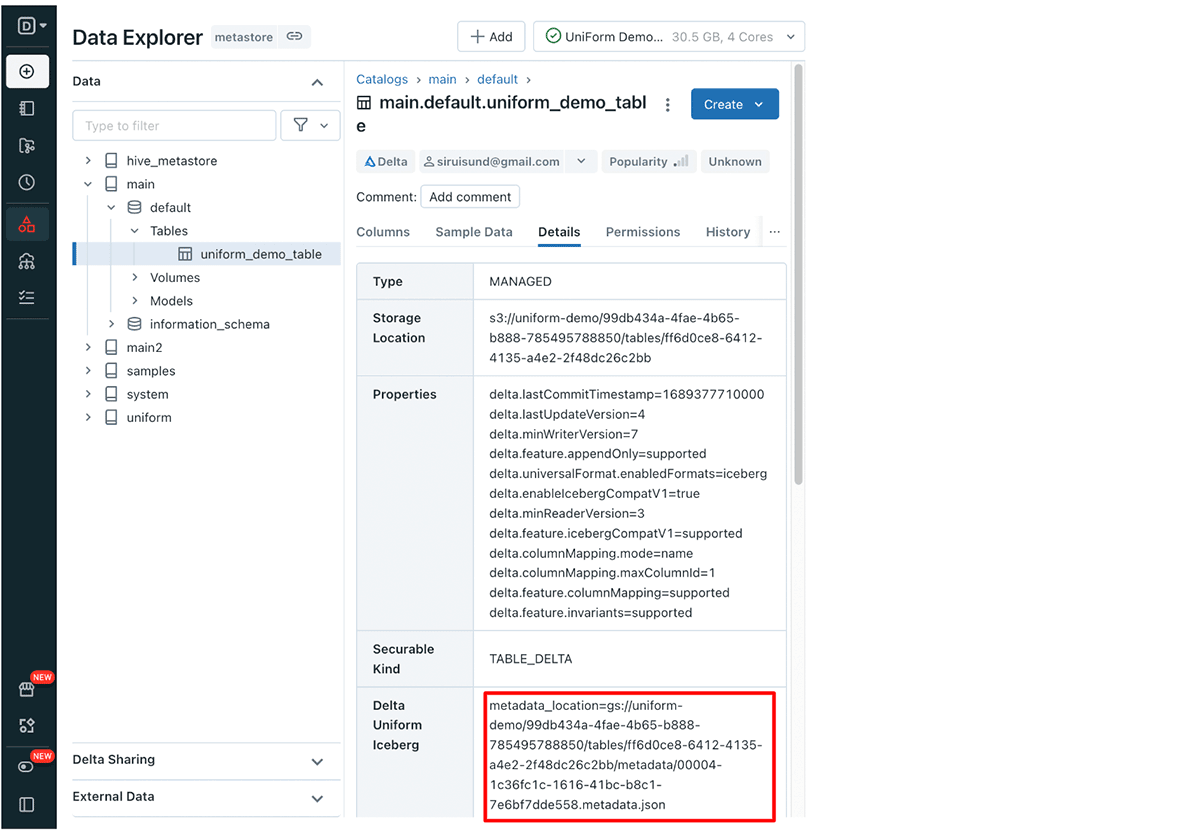
Récupération du chemin des métadonnées Iceberg Delta UniForm via l'interface utilisateur :
Accédez à votre table Delta UniForm dans l'explorateur de données Databricks, puis cliquez sur l'onglet Détails. Ici, vous trouverez la ligne Delta UniForm Iceberg contenant le chemin des métadonnées.
Dans Databricks :
Récupération de l'emplacement des métadonnées Iceberg Delta UniForm via l'API :
Depuis l'outil de votre choix, soumettez la requête GET suivante pour récupérer l'emplacement des métadonn�ées Iceberg de votre table Delta UniForm.
Le champ delta_uniform_iceberg.metadata_location dans la réponse contient l'emplacement des métadonnées pour le dernier instantané Iceberg.
Collez simplement l'emplacement de l'interface utilisateur ou des méthodes d'API décrites ci-dessus dans la commande BigQuery susmentionnée, et BigQuery lira le snapshot en tant qu'Iceberg.
Si votre table est mise à jour, vous devrez fournir à BigQuery l'emplacement des métadonnées mis à jour pour lire les données les plus récentes. Pour les cas d'utilisation en production, vous devez ajouter une étape dans votre pipeline d'ingestion qui met à jour BigQuery avec le ou les derniers chemins de métadonnées Iceberg chaque fois que vous écrivez dans la table Delta UniForm. Notez que le besoin de mises à jour du chemin des métadonnées est une limitation générale de cette approche, et n'est pas spécifique à UniForm.
Exemple : Lire Delta Lake comme Iceberg dans Trino via l'API REST du catalogue
Lisons maintenant la même table Delta UniForm que nous avons créée précédemment via Trino en utilisant l'API REST du catalogue Iceberg d'Unity Catalog.
Remarque : UniForm n'est pas nécessaire pour lire les tables Delta avec Trino car Trino prend directement en charge les tables Delta. Ceci est juste pour illustrer comment UniForm étend davantage l'interopérabilité dans l'écosystème open source.
Après avoir configuré Trino, vous pouvez ajuster les propriétés Iceberg en mettant à jour le fichier etc/catalog/iceberg.properties pour configurer Trino afin d'utiliser le point de terminaison du catalogue de l'API REST Iceberg d'Unity Catalog :
Où :
- UNITY_CATALOG_ICEBERG_URL - l'URL du point de terminaison de l'API REST Iceberg d'Unity Catalog - elle prend la forme : https://{DATABRICKS_WORKSPACE_URL}/api/2.1/unity-catalog/iceberg
- DATABRICKS_WORKSPACE_URL - l'URL de votre espace de travail Databricks, que vous pouvez trouver en naviguant vers votre espace de travail Databricks dans un navigateur Web ; elle prend la forme : mydatabricksworkspace.cloud.databricks.com/?o=1231231231231231
- PERSONAL_ACCESS_TOKEN - un jeton d'accès personnel Databricks qui peut être généré dans un espace de travail Databricks conformément à ces instructions
Une fois votre fichier de propriétés configuré, vous pouvez exécuter la CLI Trino et émettre une requête Iceberg vers la table Delta UniForm :
Comme Trino implémente l'API REST du catalogue Apache Iceberg, nous n'avons créé aucune table externe, ni eu besoin de fournir le chemin vers les derniers fichiers de métadonnées Iceberg. Trino récupère automatiquement les dernières métadonnées Iceberg de UC, puis lit les dernières données de la table Delta UniForm.
Il est important de noter que, du point de vue de Trino, rien de spécifique à Delta UniForm ne se passe ici. Il lit une table Iceberg, dont les métadonnées ont été générées selon les spécifications, et récupère ces métadonnées avec un appel API REST standard à un catalogue Iceberg.
C'est la simplicité de Delta UniForm. Pour les écrivains et lecteurs Delta Lake, la table Delta UniForm est une table Delta Lake. Pour les lecteurs Iceberg, la table Delta UniForm est une table Iceberg - le tout sur un seul ensemble de fichiers de données sans copies inutiles de données et de tables.
Impact de Delta UniForm
Tout au long de sa préversion, nous avons déjà aidé de nombreux clients à accélérer l'interopérabilité du lakehouse de données ouvert avec Delta UniForm. Les organisations peuvent écrire une fois dans Delta Lake, puis accéder à ces données de quelque manière que ce soit, en atteignant des performances optimales, une rentabilité et une flexibilité des données pour diverses charges de travail telles que ETL, BI et IA - le tout sans le fardeau de migrations coûteuses et complexes.
"Chez Instacart, notre vision est d'avoir un lakehouse de données ouvert avec une seule copie de données qui est interopérable avec toutes les plateformes de calcul. Delta UniForm est essentiel à cet objectif. Avec Delta UniForm, nous pouvons générer rapidement et facilement des tables qui peuvent être lues comme Delta Lake ou Iceberg, débloquant ainsi l'interopérabilité avec tous les outils de notre écosystème." —Doug Hyde, ingénieur logiciel principal chez Instacart, a partagé son expérience avec Delta UniForm
La mission de Databricks est d'aider les équipes de données à résoudre les problèmes les plus difficiles du monde, et cela commence par la possibilité d'utiliser le bon outil pour le bon travail sans avoir à faire de copies de vos données. Nous sommes enthousiasmés par les améliorations de l'interopérabilité apportées par Delta UniForm et continuerons d'investir dans ce domaine pour les années à venir.
Delta UniForm est disponible dans le cadre de la version candidate de préversion pour Delta Lake 3.0. Les clients Databricks peuvent également prévisualiser Delta UniForm avec la version 13.2 de Databricks Runtime ou le canal de préversion Databricks SQL 2023.35.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.