Réglage fin efficace avec LoRA : Un guide pour la sélection optimale des paramètres pour les grands modèles linguistiques
Avec l'avancement rapide des techniques basées sur les réseaux neuronaux et la recherche sur les grands modèles de langage (LLM), les entreprises s'intéressent de plus en plus aux applications d'IA pour la génération de valeur. Elles emploient diverses approches d'apprentissage automatique, à la fois génératives et non génératives, pour relever les défis liés au texte tels que la classification, la résumé, les tâches de séquence à séquence et la génération de texte contrôlée. Les organisations peuvent opter pour des API tierces, mais l'affinement des modèles avec des données propriétaires offre des résultats spécifiques au domaine et pertinents, permettant des solutions rentables et indépendantes déployables dans différents environnements de manière sécurisée.
Assurer une utilisation efficace des ressources et une rentabilité est crucial lors du choix d'une stratégie d'affinement. Ce blog explore ce qui est sans doute la variante la plus populaire et la plus efficace de ces méthodes à paramètres efficaces, l'adaptation de rang faible (LoRA), avec un accent particulier sur QLoRA (une variante encore plus efficace de LoRA). L'approche ici consistera à prendre un grand modèle de langage ouvert et à l'affiner pour générer des descriptions de produits fictives lorsqu'il est invité avec un nom de produit et une catégorie. Le modèle choisi pour cet exercice est OpenLLaMA-3b-v2, un grand modèle de langage ouvert avec une licence permissive (Apache 2.0), et l'ensemble de données choisi est Red Dot Design Award Product Descriptions, tous deux téléchargeables depuis le HuggingFace Hub aux liens fournis.
Affinement, LoRA et QLoRA
Dans le domaine des modèles de langage, l'affinement d'un modèle de langage existant pour effectuer une tâche spécifique sur des données spécifiques est une pratique courante. Cela implique l'ajout d'une tête spécifique à la tâche, si nécessaire, et la mise à jour des poids du réseau neuronal par rétropropagation pendant le processus d'entraînement. Il est important de noter la distinction entre ce processus d'affinement et l'entraînement à partir de zéro. Dans ce dernier scénario, les poids du modèle sont initialisés aléatoirement, tandis que dans l'affinement, les poids sont déjà optimisés dans une certaine mesure pendant la phase de pré-entraînement. La décision de quels poids optimiser ou mettre à jour, et lesquels garder figés, dépend de la technique choisie.
L'affinement complet implique l'optimisation ou l'entraînement de toutes les couches du réseau neuronal. Bien que cette approche donne généralement les meilleurs résultats, elle est également la plus gourmande en ressources et la plus longue.
Heureusement, il existe des approches d'affinement efficaces en termes de paramètres qui se sont avérées efficaces. Bien que la plupart de ces approches aient donné des performances moindres, l'adaptation de rang faible (LoRA) a inversé cette tendance en surpassant même l'affinement complet dans certains cas, en conséquence de l'évitement de l'oubli catastrophique (un phénomène qui se produit lorsque les connaissances du modèle pré-entraîné sont perdues pendant le processus d'affinement).
LoRA est une méthode d'affinement améliorée où, au lieu d'affiner tous les poids qui constituent la matrice de poids du grand modèle de langage pré-entraîné, deux matrices plus petites qui approximent cette matrice plus grande sont affinées. Ces matrices constituent l'adaptateur LoRA. Cet adaptateur affiné est ensuite chargé dans le modèle pré-entraîné et utilisé pour l'inférence.
QLoRA est une version encore plus efficace en mémoire de LoRA où le modèle pré-entraîné est chargé dans la mémoire GPU sous forme de poids quantifiés sur 4 bits (comparé à 8 bits dans le cas de LoRA), tout en conservant une efficacité similaire à LoRA. L'exploration de cette méthode, la comparaison des deux méthodes si nécessaire, et la détermination de la meilleure combinaison d'hyperparamètres QLoRA pour atteindre des performances optimales avec le temps d'entraînement le plus rapide seront l'objet de cette discussion.
LoRA est implémenté dans la bibliothèque Hugging Face Parameter Efficient Fine-Tuning (PEFT), offrant une facilité d'utilisation, et QLoRA peut être exploité en utilisant bitsandbytes et PEFT ensemble. La bibliothèque HuggingFace Transformer Reinforcement Learning (TRL) offre un entraîneur pratique pour l'affinement supervisé avec une intégration transparente pour LoRA. Ces trois bibliothèques fourniront les outils nécessaires pour affiner le modèle pré-entraîné choisi afin de générer des descriptions de produits cohérentes et convaincantes une fois invité avec une instruction indiquant les attributs souhaités.
Préparation des données pour l'affinement supervisé
Pour sonder l'efficacité de QLoRA pour l'affinement d'un modèle pour le suivi d'instructions, il est essentiel de transformer les données dans un format adapté à l'affinement supervisé. L'affinement supervisé, en substance, entraîne davantage un modèle pré-entraîné pour générer du texte conditionné par une invite fournie. Il est supervisé en ce sens que le modèle est affiné sur un ensemble de données qui contient des paires invite-réponse formatées de manière cohérente.
Un exemple d'observation de notre ensemble de données choisi du Hugging Face hub se présente comme suit :
|
produit |
catégorie |
description |
texte |
|
"Produits Biamp Rack" |
"Processeurs Audio Numériques" |
"« Valeur de reconnaissance élevée, esthétique uniforme et évolutivité pratique – ceci a été réalisé de manière impressionnante avec le langage de marque Biamp…" |
"Nom du produit : Produits Biamp Rack ; Catégorie de produit : Processeurs Audio Numériques ; Description du produit : « Valeur de reconnaissance élevée, esthétique uniforme et évolutivité pratique – ceci a été réalisé de manière impressionnante avec le langage de marque Biamp…
|
Aussi utile que soit cet ensemble de données, il n'est pas bien formaté pour l'affinement d'un modèle de langage pour le suivi d'instructions de la manière décrite ci-dessus.
L'extrait de code suivant charge l'ensemble de données du Hugging Face hub en mémoire, transforme les champs nécessaires en une chaîne formatée de manière cohérente représentant l'invite, et insère la réponse (c'est-à-dire la description), immédiatement après. Ce format est connu sous le nom de « format Alpaca » dans les cercles de recherche sur les grands modèles de langage, car c'était le format utilisé pour affiner le modèle LlaMA original de Meta afin d'obtenir le modèle Alpaca, l'un des premiers grands modèles de langage suivant les instructions largement distribués (bien que non sous licence pour un usage commercial).
Les invites résultantes sont ensuite chargées dans un ensemble de données Hugging Face pour l'affinement supervisé. Chaque invite a le format suivant.
Pour faciliter l'expérimentation rapide, chaque exercice d'ajustement fin sera effectué sur un sous-ensemble de 5000 observations de ces données.
Test des performances du modèle avant l'ajustement fin
Avant tout ajustement fin, il est judicieux de vérifier les performances du modèle sans ajustement fin afin d'obtenir une base de référence pour les performances du modèle pré-entraîné.
Le modèle peut être chargé en 8 bits comme suit et sollicité avec le format spécifié dans la carte du modèle sur Hugging Face.
Le résultat obtenu n'est pas tout à fait ce que nous voulons.
La première partie du résultat est en fait satisfaisante, mais le reste est plutôt un fouillis décousu.
De même, si le modèle est sollicité avec le texte d'entrée au « format Alpaca » comme discuté précédemment, le résultat devrait être tout aussi sous-optimal :
Et effectivement, c'est le cas :
Le modèle fait ce pour quoi il a été entraîné, il prédit le prochain jeton le plus probable. L'objectif de l'ajustement fin supervisé dans ce contexte est de générer le texte désiré de manière contrôlable. Veuillez noter que dans les expériences suivantes, bien que QLoRA utilise un modèle chargé en 4 bits avec les poids figés, le processus d'inférence pour examiner la qualité de la sortie est effectué une fois que le modèle a été chargé en 8 bits, comme indiqué ci-dessus pour des raisons de cohérence.
Les leviers d'ajustement
Lors de l'utilisation de PEFT pour entraîner un modèle avec LoRA ou QLoRA (notez que, comme mentionné précédemment, la principale différence entre les deux est que dans ce dernier cas, les modèles pré-entraînés sont figés en 4 bits pendant le processus d'ajustement fin), les hyperparamètres du processus d'adaptation à faible rang peuvent être définis dans une configuration LoRA comme indiqué ci-dessous :
Deux de ces hyperparamètres, r et target_modules, sont empiriquement démontrés comme affectant significativement la qualité de l'adaptation et feront l'objet des tests qui suivent. Les autres hyperparamètres sont maintenus constants aux valeurs indiquées ci-dessus pour des raisons de simplicité.
r représente le rang des matrices de faible rang apprises pendant le processus d'ajustement fin. À mesure que cette valeur est augmentée, le nombre de paramètres à mettre à jour pendant l'adaptation à faible rang augmente. Intuitivement, un r plus faible peut conduire à un processus d'entraînement plus rapide et moins intensif en calcul, mais peut affecter la qualité du modèle ainsi produit. Cependant, augmenter r au-delà d'une certaine valeur peut ne pas produire d'augmentation discernable de la qualité de la sortie du modèle. La manière dont la valeur de r affecte la qualité de l'adaptation (ajustement fin) sera bientôt mise à l'épreuve.
Lors de l'ajustement fin avec LoRA, il est possible de cibler des modules spécifiques dans l'architecture du modèle. Le processus d'adaptation ciblera ces modules et leur appliquera les matrices de mise à jour. De même que pour "r", cibler davantage de modules pendant l'adaptation LoRA entraîne une augmentation du temps d'entraînement et une plus grande demande en ressources de calcul. Ainsi, il est courant de ne cibler que les blocs d'attention du transformeur. Cependant, des travaux récents, comme le montre l'article QLoRA de Dettmers et al., suggèrent que le ciblage de toutes les couches linéaires améliore la qualité de l'adaptation. Cela sera également exploré ici.
Les noms des couches linéaires du modèle peuvent être facilement ajoutés à une liste avec l'extrait de code suivant :
Optimiser l'ajustement fin avec LoRA
L'expérience des développeurs en matière d'ajustement fin des grands modèles linguistiques s'est considérablement améliorée au cours de la dernière année environ. La dernière abstraction de haut niveau de Hugging Face est la classe SFTTrainer de la bibliothèque TRL. Pour effectuer QLoRA, il suffit de procéder comme suit :
1. Charger le modèle en mémoire GPU en 4 bits (bitsandbytes permet ce processus).
2. Définir la configuration LoRA comme discuté ci-dessus.
3. Définir les divisions d'entraînement et de test des données préparées de suivi d'instructions en objets Dataset Hugging Face.
4. Définir les arguments d'entraînement. Ceux-ci incluent le nombre d'époques, la taille du lot (batch size) et d'autres hyperparamètres d'entraînement qui seront maintenus constants pendant cet exercice.
5. Passer ces arguments à une instance de SFTTrainer.
Ces étapes sont clairement indiquées dans le fichier source du dépôt associé à ce blog.
La logique d'entraînement réelle est joliment abstraite comme suit :
Si l'autologging MLflow est activé dans l'espace de travail Databricks, ce qui est fortement recommandé, tous les paramètres d'entraînement et les métriques sont automatiquement suivis et enregistrés avec le serveur de suivi MLflow. Cette fonctionnalité est inestimable pour le suivi des tâches d'entraînement de longue durée. Inutile de dire que le processus d'ajustement fin est effectué à l'aide d'un cluster de calcul (dans ce cas, un nœud unique avec un seul GPU A100) créé à l'aide du dernier runtime Databricks Machine avec support GPU.
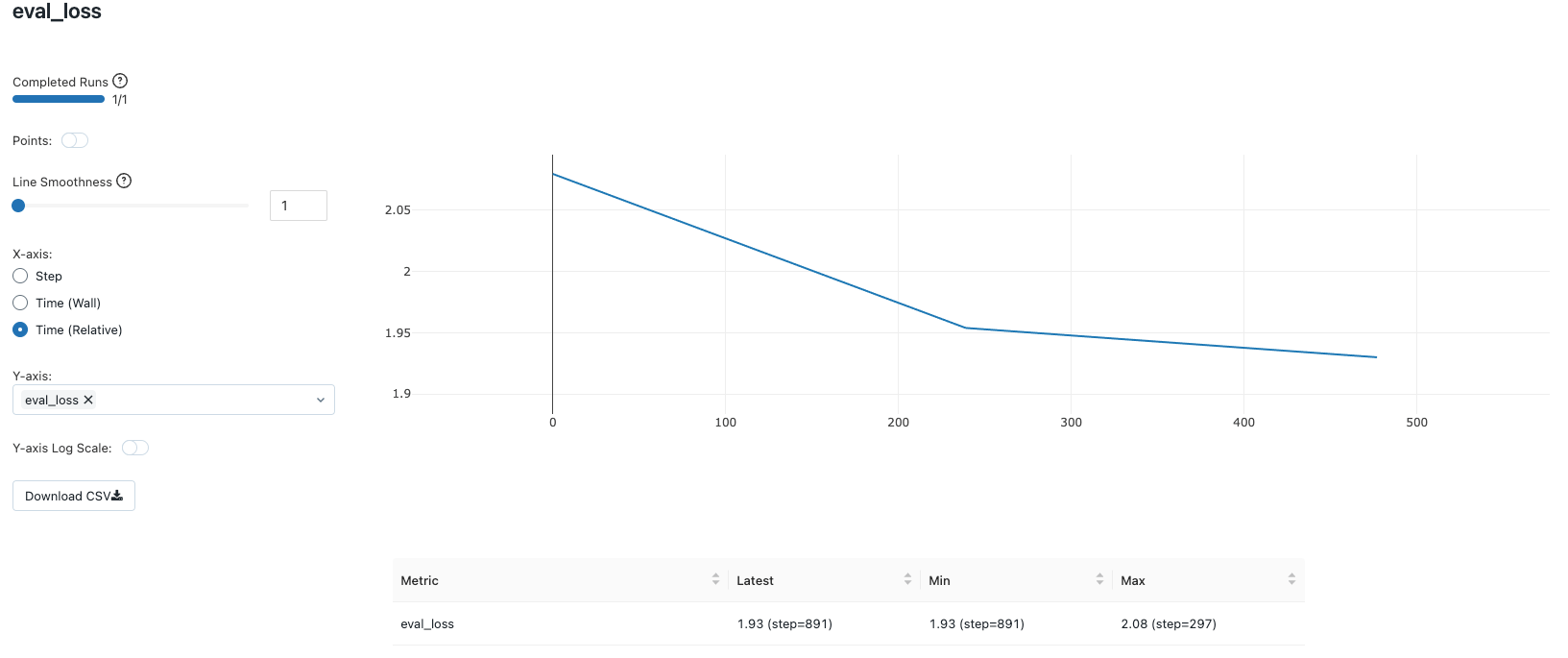
Combinaison d'hyperparamètres n°1 : QLoRA avec r=8 et ciblant « q_proj », « v_proj »
La première combinaison d'hyperparamètres QLoRA tentée est r=8 et cible uniquement les blocs d'attention, à savoir « q_proj » et « v_proj » pour l'adaptation.
Les extraits de code suivants donnent le nombre de paramètres entraînables :
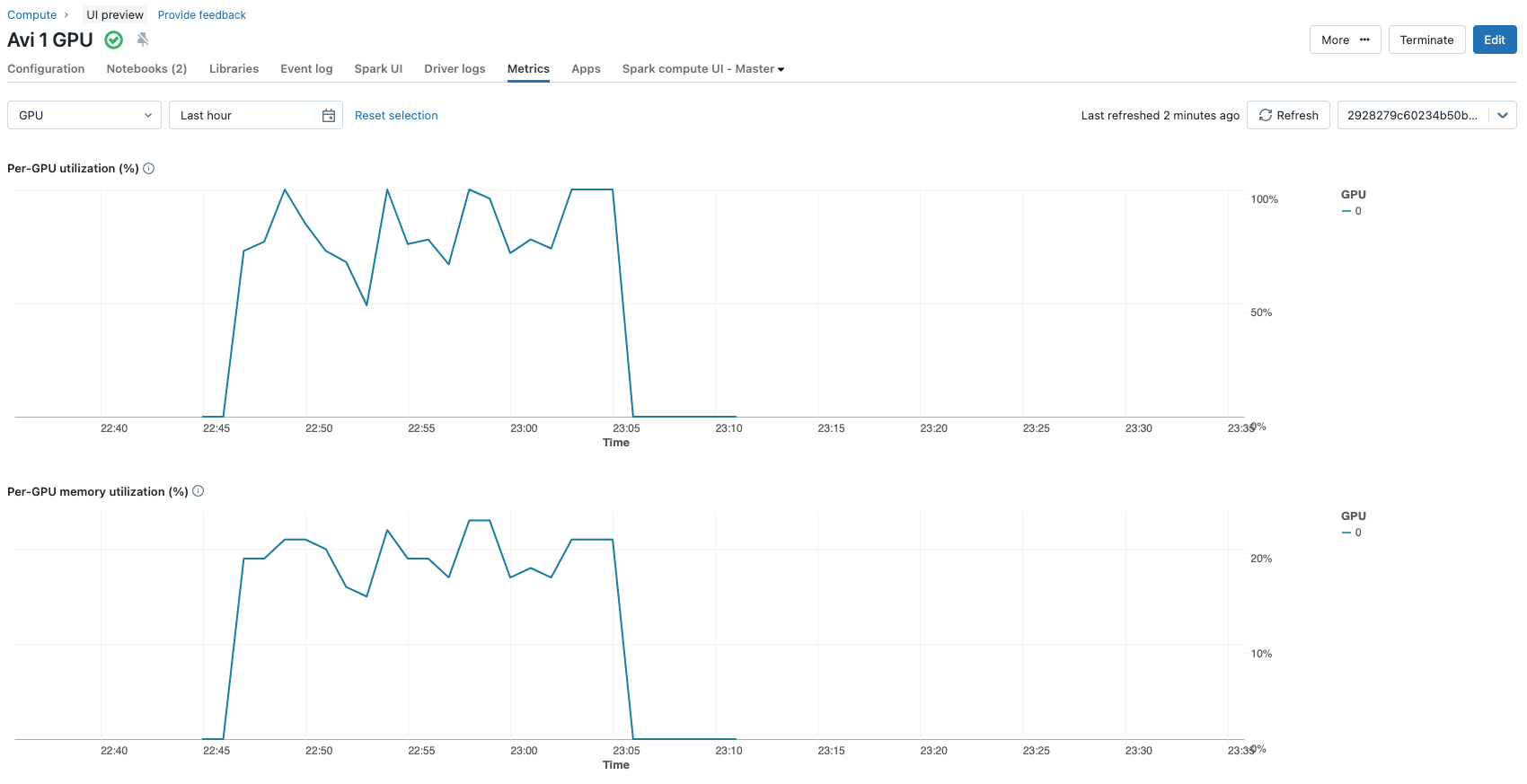
Ces choix entraînent la mise à jour de 2 662 400 paramètres pendant le processus de fine-tuning (environ 2,6 millions) sur un total d'environ 3,2 milliards de paramètres que le modèle contient. Cela représente moins de 0,1 % des paramètres du modèle. L'ensemble du processus de fine-tuning sur une seule Nvidia A100 avec 80 Go de GPU pendant 3 époques ne prend qu'environ 12 minutes. Les métriques d'utilisation du GPU peuvent être facilement consultées dans l'onglet des métriques des configurations de cluster.
À la fin du processus d'entraînement, le modèle fine-tuné est obtenu en chargeant les poids de l'adaptateur dans le modèle pré-entraîné comme suit :
Ce modèle peut maintenant être utilisé pour l'inférence comme n'importe quel autre modèle.
Évaluation qualitative
Quelques exemples de paires prompt-réponse sont listés ci-dessous
Prompt (passé au modèle au format Alpaca, non affiché ici pour des raisons de concision) :
Créez une description détaillée pour le produit suivant : Corelogic Smooth Mouse, appartenant à la catégorie : Souris optique
Réponse :
Prompt :
Créez une description détaillée pour le produit suivant : Hoover Lightspeed, appartenant à la catégorie : Aspirateur sans fil
Réponse :
Le modèle a clairement été adapté pour générer des descriptions plus cohérentes. Cependant, la réponse au premier prompt concernant la souris optique est assez courte et la phrase suivante « L'aspirateur est équipé d'un bac à poussière qui peut être vidé via un bac à poussière » est logiquement erronée.
Combinaison d'hyperparamètres n°2 : QLoRA avec r=16 et ciblant toutes les couches linéaires
Il est certain que les choses peuvent être améliorées ici. Il est intéressant d'explorer l'augmentation du rang des matrices de faible rang apprises pendant l'adaptation à 16, c'est-à-dire de doubler la valeur de r à 16 et de garder tout le reste identique. Cela double le nombre de paramètres entraînables à 5 324 800 (environ 5,3 millions).
Évaluation qualitative
La qualité de la sortie, cependant, reste inchangée pour les mêmes prompts exacts.
Prompt :
Créez une description détaillée pour le produit suivant : Corelogic Smooth Mouse, appartenant à la catégorie : Souris optique
Réponse :
Prompt :
Créez une description détaillée pour le produit suivant : Hoover Lightspeed, appartenant à la catégorie : Aspirateur sans fil
Réponse :
Le même manque de détails et les mêmes défauts logiques persistent là où des détails sont disponibles. Si ce modèle fine-tuné est utilisé pour la génération de descriptions de produits dans un scénario réel, ce n'est pas un résultat acceptable.
Combinaison d'hyperparamètres n°3 : QLoRA avec r=8 et ciblant toutes les couches linéaires
Étant donné que doubler r ne semble pas entraîner d'augmentation perceptible de la qualité de la sortie, il est utile de modifier l'autre paramètre important, c'est-à-dire de cibler toutes les couches linéaires au lieu des seuls blocs d'attention. Ici, les hyperparamètres LoRA sont r=8 et les target_layers sont 'q_proj','k_proj','v_proj','o_proj','gate_proj','down_proj','up_proj' et 'lm_head'. Cela augmente le nombre de paramètres mis à jour à 12 994 560 et augmente le temps d'entraînement à environ 15,5 minutes.
Évaluation qualitative
L'interrogation du modèle avec les mêmes prompts donne les résultats suivants :
Prompt :
Créez une description détaillée pour le produit suivant : Corelogic Smooth Mouse, appartenant à la catégorie : Souris optique
Réponse :
Prompt :
Créez une description détaillée pour le produit suivant : Hoover Lightspeed, appartenant à la catégorie : Aspirateur sans fil
Réponse :
Il est maintenant possible de voir une description cohérente un peu plus longue de la souris optique fictive et il n'y a pas de défauts logiques dans la description de l'aspirateur. Les descriptions de produits sont non seulement logiques, mais pertinentes. Pour rappel, ces résultats de qualité relativement élevée sont obtenus en fine-tunant moins de 1 % des poids du modèle avec un ensemble de données total de 5000 paires prompt-description formatées de manière cohérente.
Combinaison d'hyperparamètres n°4 : LoRA avec r=8 et ciblant toutes les couches de transformateur linéaires
Il est également intéressant d'explorer si la qualité de la sortie du modèle s'améliore si le modèle pré-entraîné est gelé en 8 bits au lieu de 4 bits. En d'autres termes, reproduire le processus exact de fine-tuning en utilisant LoRA au lieu de QLoRA. Ici, les hyperparamètres LoRA sont maintenus les mêmes qu'auparavant, dans la nouvelle configuration optimale, c'est-à-dire r=8 et ciblant toutes les couches de transformateur linéaires pendant le processus d'adaptation.
Évaluation qualitative
Les résultats pour les deux prompts utilisés tout au long de l'article sont les suivants :
Prompt :
Créez une description détaillée pour le produit suivant : Corelogic Smooth Mouse, appartenant à la catégorie : Souris optique
Réponse :
Prompt :
Créez une description détaillée pour le produit suivant : Hoover Lightspeed, appartenant à la catégorie : Aspirateur sans fil
Réponse :
Encore une fois, il n'y a pas beaucoup d'amélioration dans la qualité du texte de sortie.
Observations clés
Sur la base de l'ensemble des essais ci-dessus, et d'autres preuves détaillées dans l'excellente publication présentant QLoRA, il peut être déduit que la valeur de r (le rang des matrices mises à jour pendant l'adaptation) n'améliore pas la qualité de l'adaptation au-delà d'un certain point. La plus grande amélioration est observée en ciblant toutes les couches linéaires dans le processus d'adaptation, par opposition aux seuls blocs d'attention, comme cela est couramment documenté dans la littérature technique détaillant LoRA et QLoRA. Les essais exécutés ci-dessus et d'autres preuves empiriques suggèrent que QLoRA ne souffre en effet d'aucune réduction discernable de la qualité du texte généré, par rapport à LoRA.
Considérations supplémentaires pour l'utilisation des adaptateurs LoRA en déploiement
Il est important d'optimiser l'utilisation des adaptateurs et de comprendre les limites de cette technique. La taille de l'adaptateur LoRA obtenu par affinage (fine-tuning) n'est généralement que de quelques mégaoctets, tandis que le modèle de base pré-entraîné peut représenter plusieurs gigaoctets en mémoire et sur disque. Pendant l'inférence, l'adaptateur et le LLM pré-entraîné doivent être chargés, de sorte que les exigences en mémoire restent similaires.
De plus, si les poids du LLM pré-entraîné et de l'adaptateur ne sont pas fusionnés, il y aura une légère augmentation de la latence d'inférence. Heureusement, avec la bibliothèque PEFT, le processus de fusion des poids avec l'adaptateur peut être effectué avec une seule ligne de code, comme illustré ici :
La figure ci-dessous décrit le processus, de l'affinage (fine-tuning) d'un adaptateur au déploiement du modèle.

Bien que le modèle d'adaptateur offre des avantages significatifs, la fusion des adaptateurs n'est pas une solution universelle. L'un des avantages du modèle d'adaptateur est la capacité de déployer un seul grand modèle pré-entraîné avec des adaptateurs spécifiques à la tâche. Cela permet une inférence efficace en utilisant le modèle pré-entraîné comme épine dorsale pour différentes tâches. Cependant, la fusion des poids rend cette approche impossible. La décision de fusionner les poids dépend du cas d'utilisation spécifique et de la latence d'inférence acceptable. Néanmoins, LoRA/QLoRA reste une méthode très efficace pour l'affinage (fine-tuning) économe en paramètres et est largement utilisée.
Conclusion
L'adaptation de rang faible (Low Rank Adaptation) est une technique d'affinage (fine-tuning) puissante qui peut donner d'excellents résultats si elle est utilisée avec la bonne configuration. Le choix de la valeur de rang correcte et des couches de l'architecture du réseau neuronal à cibler pendant l'adaptation pourrait déterminer la qualité de la sortie du modèle affiné. QLoRA permet des économies de mémoire supplémentaires tout en préservant la qualité de l'adaptation. Même lorsque l'affinage est effectué, il y a plusieurs considérations d'ingénierie importantes pour s'assurer que le modèle adapté est déployé de la bonne manière.
En résumé, un tableau concis indiquant les différentes combinaisons de paramètres LoRA tentées, la qualité de sortie du texte et le nombre de paramètres mis à jour lors de l'affinage (fine-tuning) d'OpenLLaMA-3b-v2 pendant 3 époques sur 5000 observations sur un seul A100 est présenté ci-dessous.
|
r |
modules cibles |
Poids du modèle de base |
Qualité de la sortie |
Nombre de paramètres mis à jour (en millions) |
|
8 |
Blocs d'attention |
4 |
faible |
2.662 |
|
16 |
Blocs d'attention |
4 |
faible |
5.324 |
|
8 |
Toutes les couches linéaires |
4 |
élevée |
12.995 |
|
8 |
Toutes les couches linéaires |
8 |
élevée |
12.995 |
Essayez ceci sur Databricks ! Clonez le dépôt GitHub associé au blog dans un Repo Databricks pour commencer. Des exemples plus détaillés pour l'affinage (fine-tuning) de modèles sur Databricks sont disponibles ici.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.