Le moyen le plus rapide de fédérer les données SAP HANA en temps réel dans Databricks à l'aide de Spark JDBC
La récente annonce par SAP d'un partenariat stratégique avec Databricks a suscité un vif intérêt chez les clients SAP. Databricks, les experts en données et IA, offre une opportunité intéressante d'exploiter les capacités d'analyse et de ML/IA en intégrant SAP HANA avec Databricks. Compte tenu de l'immense intérêt suscité par cette collaboration, nous sommes ravis de nous lancer dans une série de blogs approfondie.
Dans de nombreux scénarios clients, un système SAP HANA sert d'entité principale pour la fondation de données provenant de divers systèmes sources, y compris SAP CRM, SAP ERP/ECC, SAP BW. Désormais, la possibilité passionnante d'intégrer de manière transparente ce système secondaire analytique robuste SAP HANA avec Databricks se présente, améliorant ainsi les capacités de données de l'organisation. En connectant SAP HANA (avec une licence HANA Enterprise Edition) à Databricks, les entreprises peuvent tirer parti des capacités avancées d'analyse et d'apprentissage automatique (comme MLflow, AutoML, MLOps) de Databricks tout en exploitant les données riches et consolidées stockées dans SAP HANA. Cette intégration ouvre un monde de possibilités aux organisations pour découvrir des informations précieuses et favoriser la prise de décision basée sur les données dans leurs systèmes SAP.
Plusieurs approches sont disponibles pour fédérer les tables SAP HANA, les vues SQL et les vues de calcul dans Databricks. Cependant, le moyen le plus rapide est d'utiliser SparkJDBC. L'avantage le plus significatif est que SparkJDBC prend en charge les connexions JDBC parallèles des nœuds workers Spark au point de terminaison HANA distant.
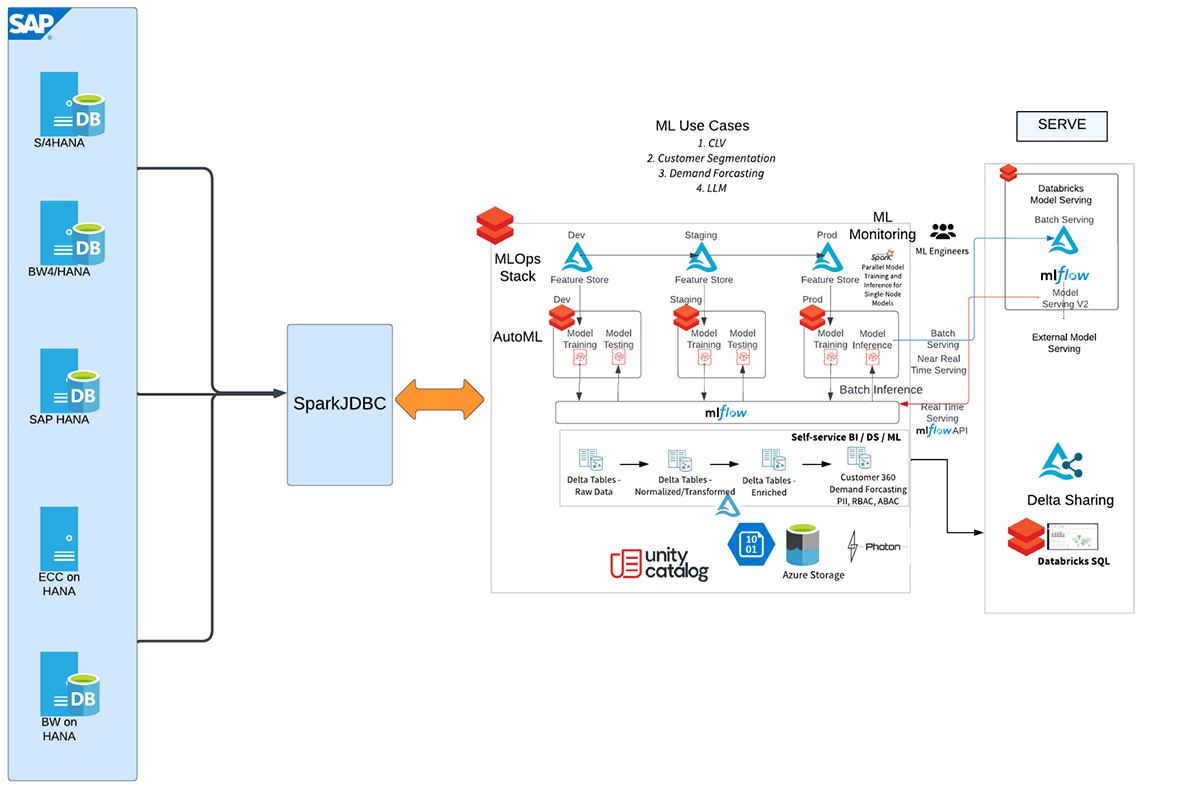
Commençons par l'intégration SAP HANA et Databricks
Tout d'abord, SAP HANA 2.0 est installé dans le cloud Azure et nous avons testé l'intégration avec Databricks.
Informations SAP HANA installées dans Azure :
| version | 2.00.061.00.1644229038 |
| branch | fa/hana2sp06 |
| Système d'exploitation | SUSE Linux Enterprise Server 15 SP1 |
Voici le flux de travail de haut niveau décrivant les différentes étapes de cette intégration.
Veuillez consulter le notebook ci-joint pour des instructions plus détaillées sur l'extraction de données des vues de calcul et des tables SAP HANA dans Databricks à l'aide de SparkJDBC.

Configurez le JAR JDBC SAP HANA (ngdbc.jar) comme indiqué dans l'image ci-dessous
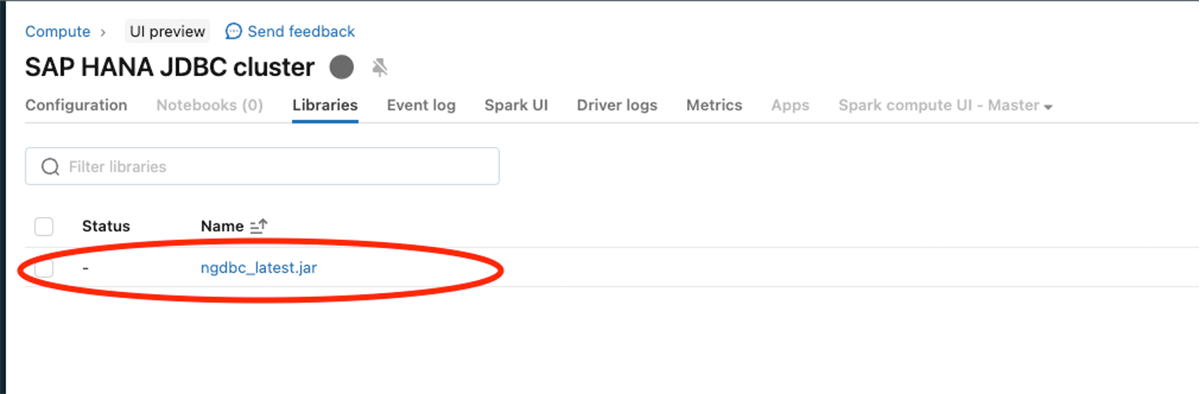
Une fois les étapes ci-dessus effectuées, effectuez une lecture Spark en utilisant le serveur SAP HANA et le port JDBC.
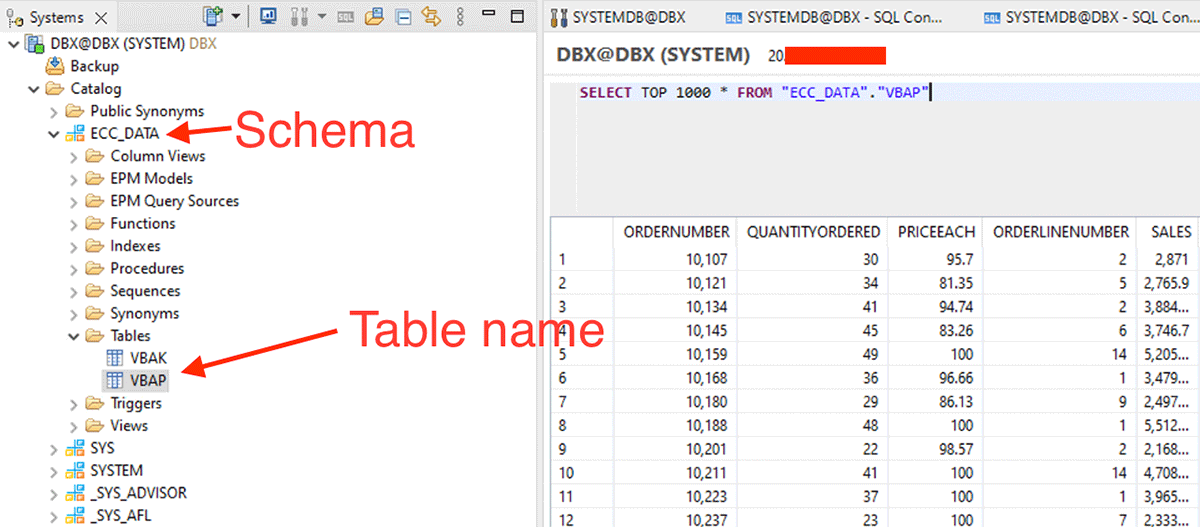
Commencez à créer les dataframes en utilisant l'image ci-dessous avec le schéma, le nom de la table.
De plus, nous pouvons effectuer un filtrage en amont en passant des instructions SQL dans l'option dbtable.
Pour obtenir des données à partir de la vue de calcul, nous devons procéder comme suit :
Par exemple, cette vue de calcul XS-classic est créée dans le schéma interne "_SYS_BIC".
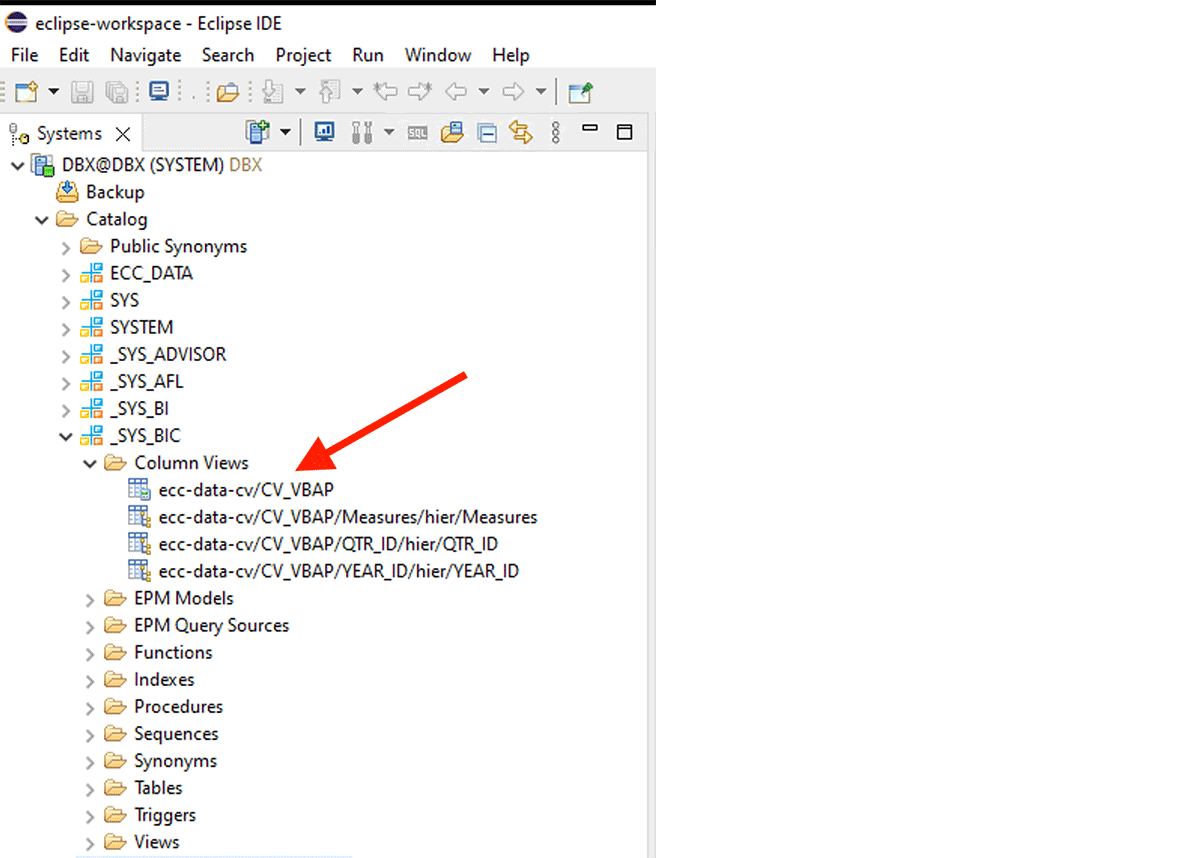
Ce fragment de code crée un dataframe PySpark nommé "df_sap_ecc_hana_cv_vbap" et le peuple à partir d'une vue de calcul du système SAP HANA (dans ce cas, CV_VBAP).
Après avoir généré le dataframe PySpark, exploitez les capacités infinies de Databricks pour l'analyse exploratoire des données (EDA) et l'apprentissage automatique/intelligence artificielle (ML/AI).
Résumé des dataframes ci-dessus :
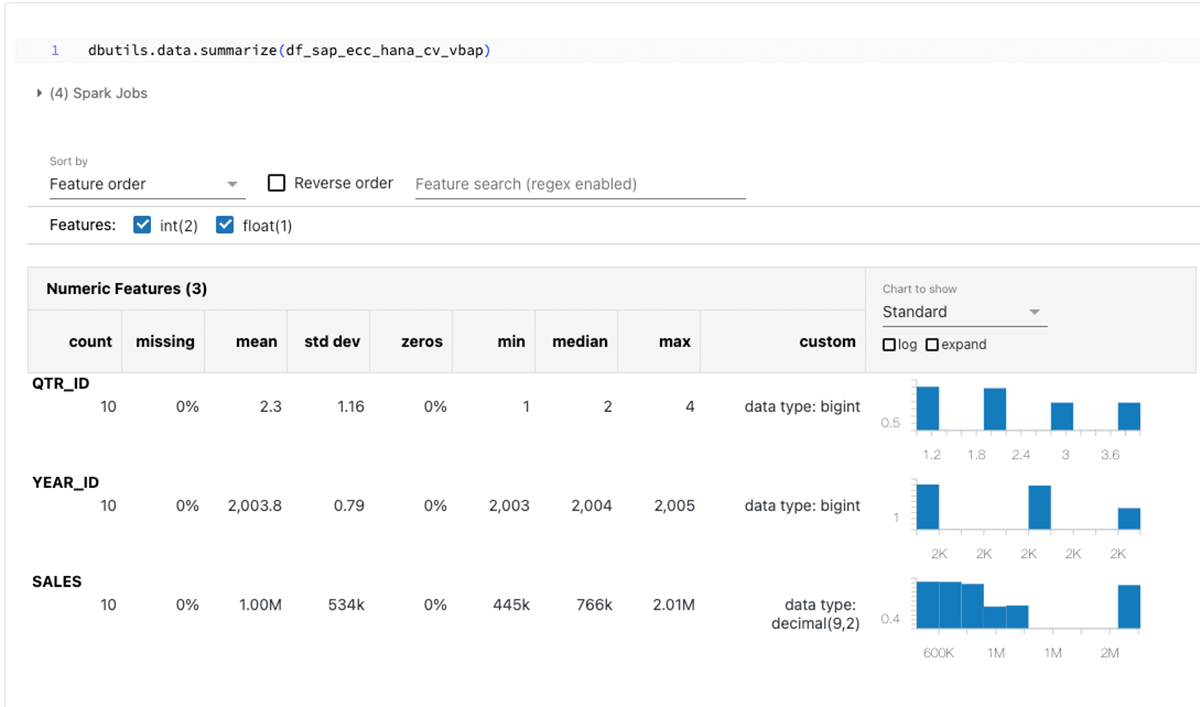
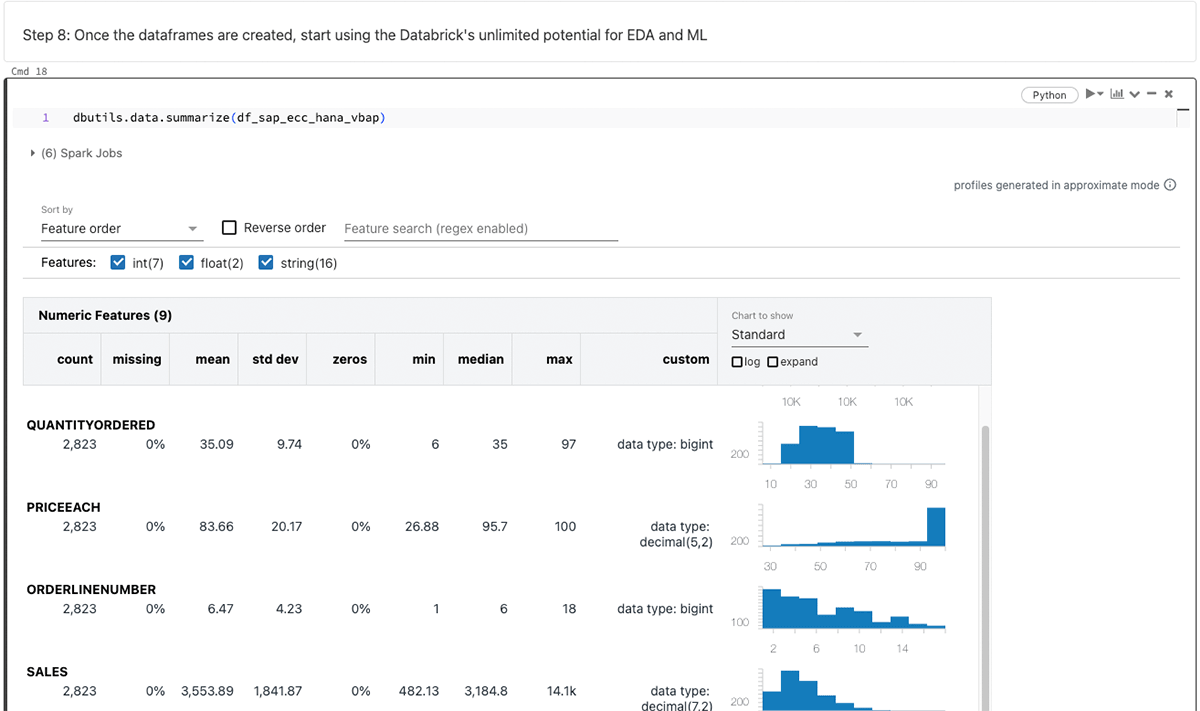
L'objectif de ce blog tourne autour de SparkJDBC pour SAP HANA, mais il convient de noter que des méthodes alternatives telles que FedML, hdbcli et hana_ml sont disponibles à des fins similaires.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.