Comment les System Tables de Databricks aident les ingénieurs de données à atteindre une observabilité avancée
Les tables système fournissent l'étendue et la profondeur dont les ingénieurs de données ont besoin pour suivre simplement l'état de leurs pipelines de données à grande échelle, pour des charges de travail plus rentables et fiables.
par Theresa Hammer
- Découvrez comment les tables système exposent la télémétrie de la plateforme sous forme de tables interrogeables, y compris les métadonnées et les insights d'exécution pour les Lakeflow jobs et les pipelines Lakeflow.
- Utilisez des exemples de queries pour transformer cette télémétrie en insights sur les opportunités de fiabilité, de coût et d'efficacité à grande échelle pour les tâches Lakeflow.
- Centralisez ces insights dans une vue opérationnelle partagée et quotidienne pour les équipes de Data Engineering avec le modèle de tableau de bord Lakeflow.
Le problème de 3 heures du matin
Il est 3 heures du matin et quelque chose a planté. Le tableau de bord n'est pas à jour, un SLA n'a pas été respecté et tout le monde essaie de deviner quelle partie de la plateforme a dévié. Peut-être qu'un job a tourné pendant des heures sans délai d'attente. Peut-être qu'un pipeline a mis à jour une table que personne n'a lue depuis des mois. Peut-être qu'un cluster utilise encore un ancien runtime. Peut-être que la seule personne qui connaît le propriétaire du job est en vacances.
Voici les schémas qui épuisent les équipes de données : compute gaspillé par des pipelines inutilisés, lacunes de fiabilité dues à des règles de santé manquantes, problèmes d'hygiène liés à des runtimes vieillissants et retards causés par une propriété peu claire. Ils apparaissent discrètement, se développent lentement, puis deviennent soudainement ce qui empêche l'ingénieur d'astreinte de dormir.
Databricks System Tables fournissent une couche cohérente pour repérer ces problèmes à un stade précoce en exposant les métadonnées des jobs, les chronologies des tâches, le comportement d'exécution, l'historique de configuration, le lignage, les signaux de coût et la propriété en un seul endroit.
Avec les nouvelles System Tables pour les Jobs Lakeflow, vous avez désormais accès à des schémas étendus qui fournissent des détails d'exécution et des signaux de métadonnées plus riches et permettent une observabilité plus avancée.
Une visibilité plus approfondie et centralisée de toutes vos données, facilitée par les Tables système
Que sont les System Tables ?
Les tables système Databricks sont un ensemble de tables en lecture seule, gérées par Databricks, dans le catalogue system, qui fournissent des données opérationnelles et d'observabilité pour votre compte. Elles sont disponibles d'emblée et couvrent un large éventail de données, notamment les Jobs, les pipelines, les clusters, la facturation, le lignage, etc.
Catégorie | Éléments suivis |
Tâches Lakeflow | Configurations de jobs, définitions de tâches, chronologies d'exécution |
Lakeflow Spark Declarative Pipelines | Métadonnées du pipeline, historique des mises à jour |
Facturation | Utilisation, attribution des coûts par charge de travail |
Traçabilité | Dépendances de lecture/�écriture au niveau de la table |
Clusters | Compute configs, utilisation |
Pourquoi les System Tables sont importantes pour l'observabilité
Les System Tables prennent en charge l'analyse inter-espaces de travail au sein d'une région, permettant aux équipes d'ingénierie des données d'analyser facilement tout comportement de charge de travail et tout modèle opérationnel à grande échelle à partir d'une interface unique et interrogeable. Grâce à ces tables, les professionnels des données peuvent surveiller de manière centralisée la santé de tous leurs pipelines, détecter les opportunités de réduction des coûts et identifier rapidement les défaillances pour une meilleure fiabilité.
Certaines tables système utilisent la sémantique SCD de type 2, en préservant l'historique complet des modifications par l'insertion d'une nouvelle ligne à chaque mise à jour. Cela permet d'auditer la configuration et d'effectuer une analyse historique de l'état de la plateforme au fil du temps.
Tables système Lakeflow
Tables système Lakeflow contiennent des données pour les 365 derniers jours et se composent des tables suivantes.
Pour obtenir la liste complète des tables système et de leurs relations, consultez la documentation.
Tables d'observabilité des tâches (Disponibilité générale)
system.lakeflow.jobs– Métadonnées SCD2 pour les jobs, y compris la configuration et les balises. Utile pour l'inventaire, la gouvernance et l'analyse de la drift de configuration.system.lakeflow.job_tasks– Table SCD2 décrivant toutes les tâches des jobs, leurs définitions et leurs dépendances. Utile pour comprendre les structures de tâches à monter en charge.system.lakeflow.job_run_timeline– Chronologie immuable des exécutions de tâches avec leur état, leur compute et leur durée. Idéal pour l'analyse des SLA et des tendances de performance.system.lakeflow.job_task_run_timeline– Chronologie des exécutions de tâches individuelles au sein de chaque tâche. Aide à identifier les goulots d'étranglement et les problèmes au niveau des tâches.
Tables d'observabilité des pipelines (Préversion publique)
system.lakeflow.pipelines– Table de métadonnées SCD2 pour les pipelines SDP, permettant une visibilité des pipelines sur plusieurs espaces de travail et le suivi des modifications.system.lakeflow.pipeline_update_timeline– Journaux d'exécution immuables pour les mises à jour de pipelines, prenant en charge le débogage et l'optimisation historiques.
Les tables système Lakeflow ont connu une croissance rapide en popularité, avec des dizaines de millions de requêtes exécutées chaque jour, marquant une augmentation de 17x d'une année sur l'autre. Cette forte augmentation souligne la valeur que les data engineers tirent des tables système Lakeflow, qui sont devenues un composant essentiel de l'observabilité au quotidien pour de nombreux clients de Databricks Lakeflow.
Examinons les cas d'usage désormais possibles grâce aux Jobs System Tables récemment étendues et maintenant disponibles pour tous.
Les tables système en pratique : santé opérationnelle des Lakeflow Jobs
En tant que data engineer au sein d'une équipe de plateforme centrale, vous êtes responsable de la gestion de centaines de jobs pour plusieurs équipes. Votre objectif est de maintenir la plateforme de données rentable, fiable et performante, tout en veillant à ce que les équipes suivent les meilleures pratiques en matière de gouvernance et d'opérations.
Pour ce faire, vous avez décidé d'auditer vos Lakeflow jobs et pipelines selon quatre objectifs principaux :
- Optimisez les coûts : identifiez les jobs qui mettent à jour des datasets qui ne sont jamais utilisés en aval.
- Garantir la fiabilité : Appliquer des délais d'attente et des seuils d'exécution pour éviter les tâches incontrôlées et les violations de SLA.
- Assurer la maintenance : vérifiez la cohérence des versions d'exécution et des normes de configuration.
- Attribuer les responsabilités : identifiez les propriétaires de tâches pour simplifier les suivis et les corrections.
Modèle 1 : Rechercher les tâches produisant des données inutilisées
Le problème� : Les jobs planifiés s'exécutent fidèlement, mettant à jour des tables qu'aucun consommateur en aval ne lit jamais. Il s'agit souvent des économies les plus faciles à réaliser, si vous parvenez à les trouver.
L'approche : Joindre les tables Lakeflow Jobs avec les tables de lignage et de facturation pour identifier les producteurs sans consommateurs, classés par coût.
Étapes suivantes : examinez les tâches les plus problématiques avec leurs propriétaires. Certaines peuvent être mises en pause immédiatement et en toute sécurité. D'autres peuvent nécessiter un plan de dépréciation si des systèmes externes en dépendent en dehors de Databricks.
Modèle 2 : Rechercher des jobs sans timeouts ni seuils de durée
Le problème : les tâches sans délai d'expiration peuvent s'exécuter indéfiniment. Une tâche bloquée consomme du compute pendant des heures, voire des jours, avant que quelqu'un ne s'en aperçoive. En plus d'augmenter les coûts, cela peut également entraîner des violations de SLA. Vous devez donc repérer les dépassements rapidement et prendre des mesures avant que les échéances ou les processus en aval ne soient affectés.
L'approche : query les configurations de jobs actuelles pour trouver les paramètres de délai d'attente et de threshold de durée manquants.
Prochaines étapes : Effectuez une comparaison croisée avec les temps d'exécution historiques de job_run_timeline pour définir des seuils réalistes. Un job qui s'exécute généralement en 20 minutes pourrait justifier un délai d'attente d'une heure et un seuil de durée de 30 minutes. Un job dont la durée varie considérablement peut nécessiter une analyse au préalable.
Modèle 3 : Détecter les versions d'exécution héritées
Le problème : Les environnements d'exécution obsolètes ne bénéficient pas des correctifs de sécurité et des améliorations de performances, et sont soumis à des échéances de fin de vie (EOL) imminentes. Mais avec des centaines de Jobs, il est fastidieux de savoir qui utilise encore les anciennes versions.
L'approche : Interrogez les configurations des tâches de job pour connaître les versions de runtime et signalez tout ce qui est inférieur à votre seuil.
Prochaines étapes : hiérarchisez les mises à niveau en fonction des échéances de fin de vie (EOL). Partagez cette liste avec les propriétaires de jobs et suivez la progression dans les requêtes de suivi.
Modèle 4 : Identifier les propriétaires de jobs pour remédiation
Le problème : lorsqu'un job échoue ou n'est pas configuré correctement, vous devez savoir qui contacter pour résoudre le problème.
L'approche : Query les tables système pour identifier facilement les propriétaires des jobs pour chaque action à entreprendre.
Étapes suivantes : contactez les propriétaires des tâches pour attribuer la propriété des problèmes qui nécessitent une action.
Ensemble, ces modèles vous aident à optimiser les coûts, à maintenir les données à jour, à appliquer des garde-fous de fiabilité et à attribuer une responsabilité claire pour la remédiation. Ils constituent le fondement de l'observabilité opérationnelle.
Synthèse : opérationnaliser les insights avec les tableaux de bord
L'exécution de ces requêtes ad hoc est utile. Mais pour les opérations quotidiennes, vous avez besoin d'une vue partagée que toute votre équipe peut consulter.
Le tableau de bord Lakeflow me donne une vue d'ensemble des Jobs dans tous mes Workspaces, non seulement au niveau des coûts, mais aussi pour l'hygiène et les Opérations des pipelines : suivi des dépenses, identification des pipelines obsolètes, monitoring des échecs et repérage des opportunités d'optimisation - Zoe Van Noppen, architecte de solutions de données, Cubigo
Pour commencer, importez le tableau de bord dans votre espace de travail. Pour obtenir des instructions détaillées, consultez la documentation officielle.
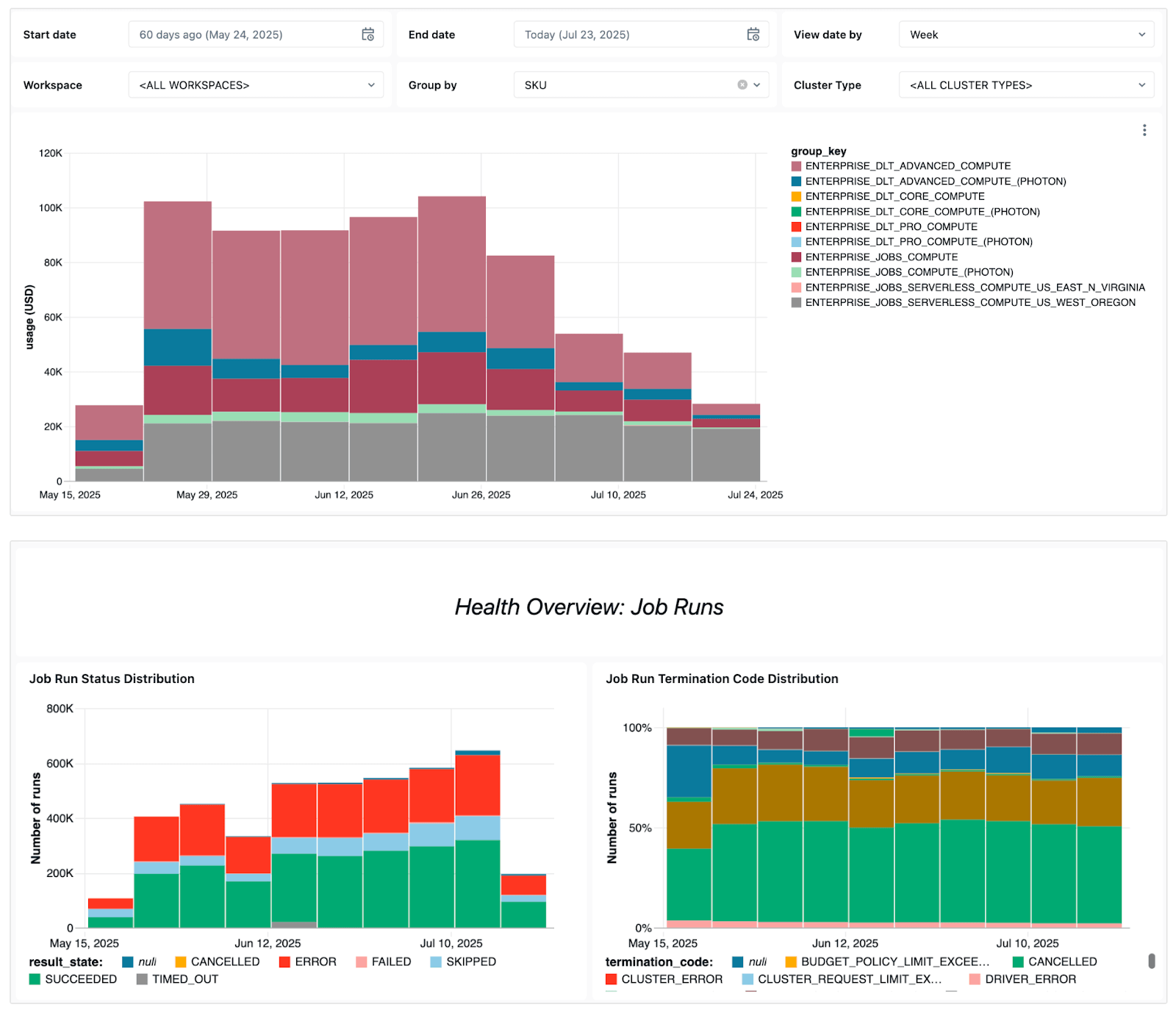
Le tableau de bord met en évidence plusieurs signaux opérationnels clés, notamment :
- Tendances des échecs - pour vous permettre de voir quels Jobs échouent le plus souvent, les tendances générales des erreurs et les messages d'erreur courants.
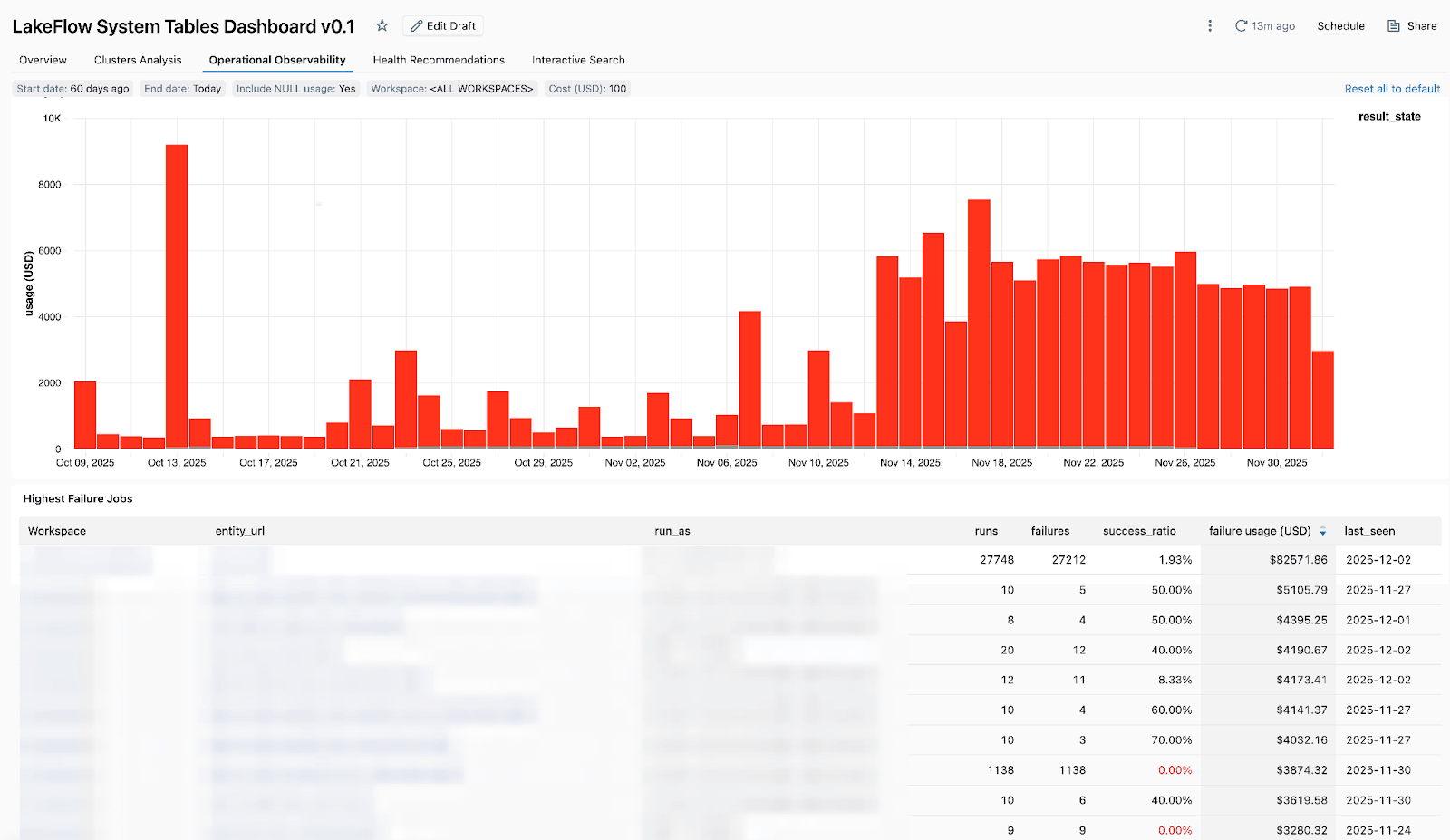
- Jobs à coût élevé - afin que vous puissiez identifier les jobs et les exécutions de jobs individuelles les plus coûteuses au cours des 30 derniers jours ou au fil du temps. Le tableau ci-dessous est trié par jobs les plus coûteux sur la période sélectionnée et affiche leurs tendances de coût au fil du temps.
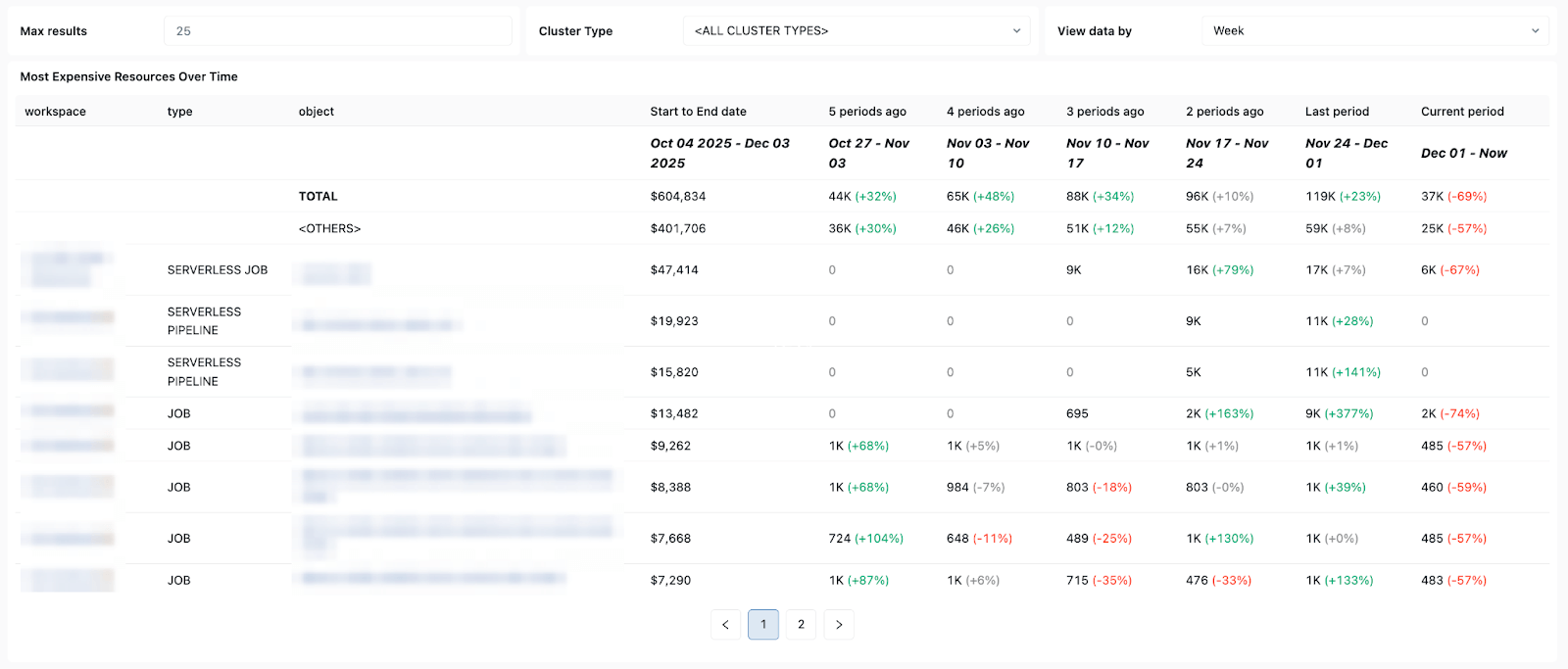
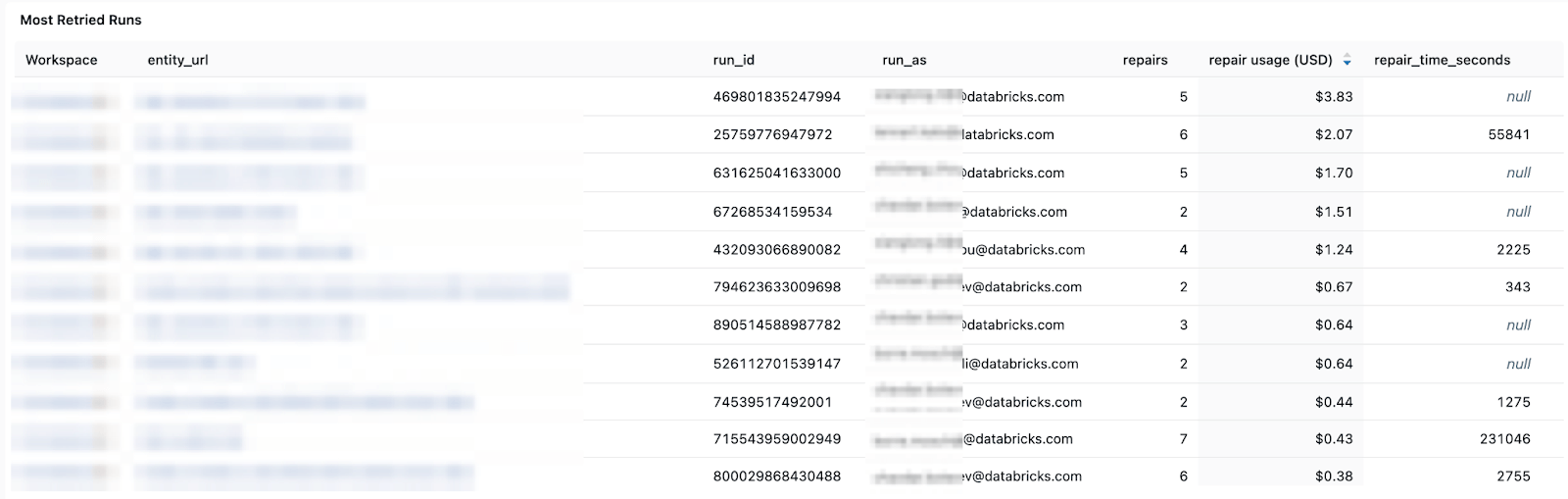
Modèles de coût et de nouvelle tentative - vous aidant à suivre les tendances de coût et l'impact des nouvelles tentatives ou des exécutions de réparation sur les dépenses totales.
- Configuration insight - vous permettant de vérifier l'efficacité du cluster, les règles de santé, les délais d'attente et les versions d'exécution pour une bonne maintenance opérationnelle.
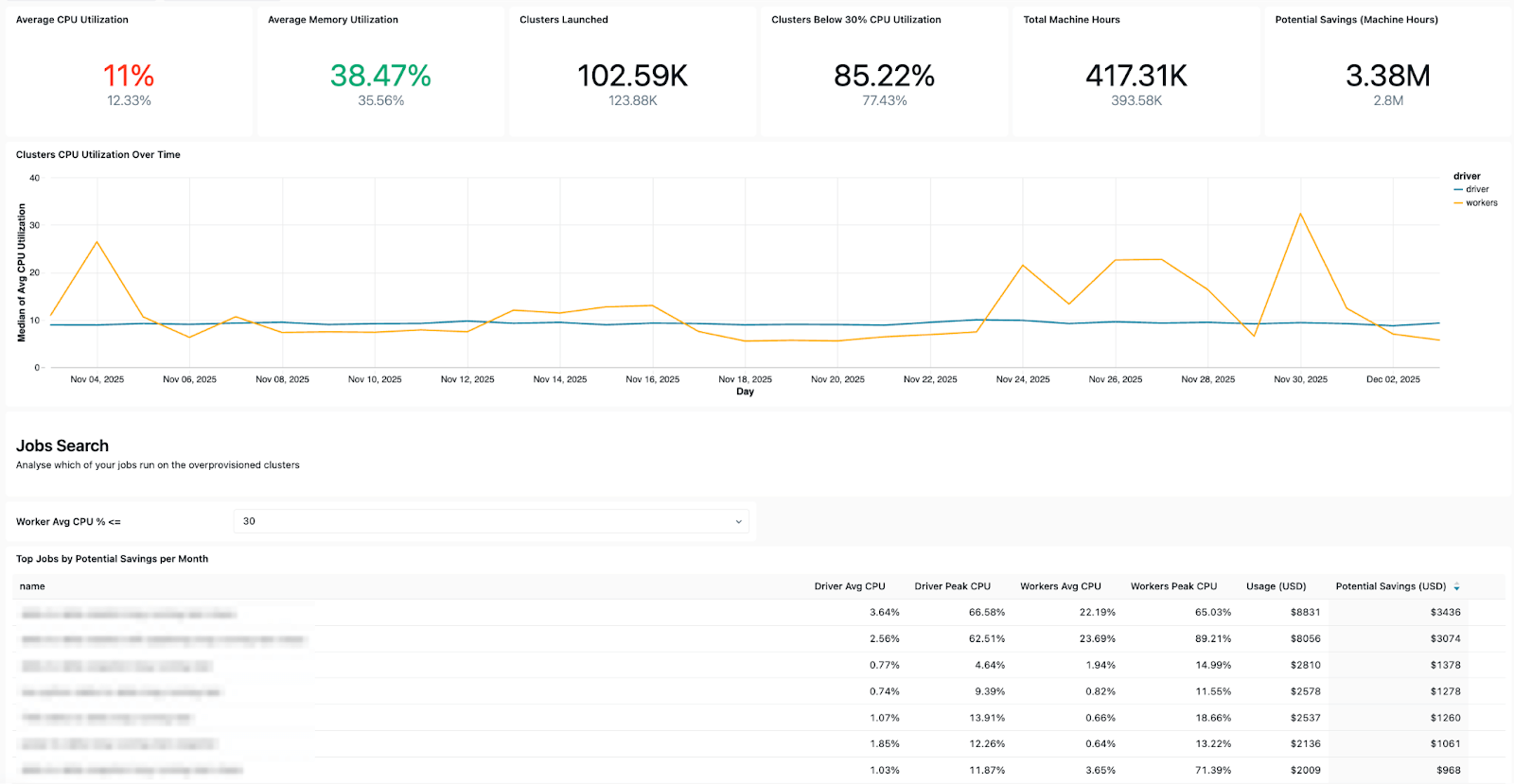
- Détails de propriété - pour que vous puissiez facilement trouver les utilisateurs « exécuter en tant que » et les créateurs de jobs afin de savoir qui contacter.
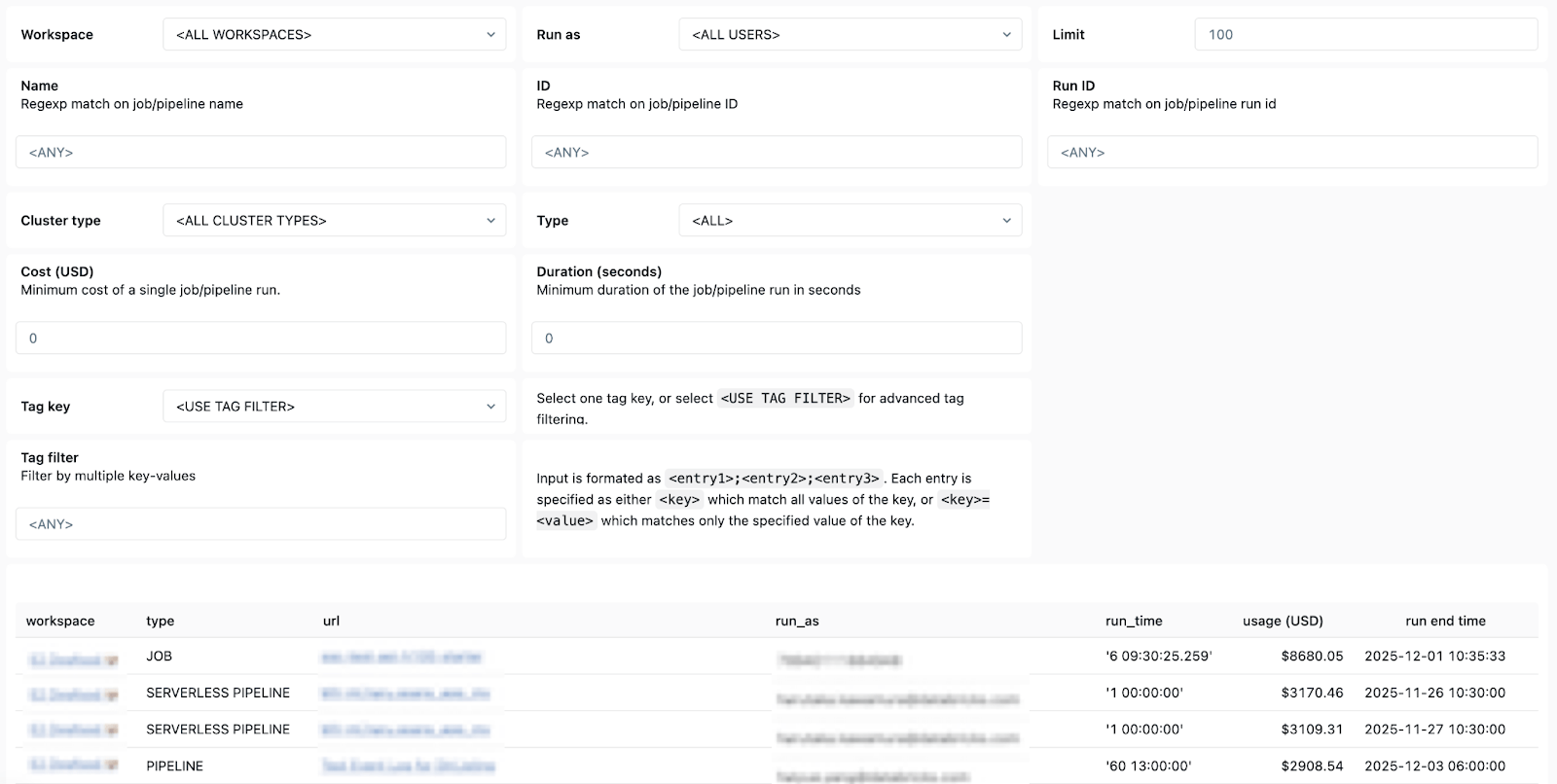
En bref, les System Tables de Databricks facilitent le suivi, l'audit et le dépannage des LakeFlow Jobs de manière efficace, à l'échelle et dans tous les Workspaces. Grâce aux visuels clairs, simples et accessibles de vos Jobs et pipelines disponibles dans le template de tableau de bord, chaque data engineer utilisant Lakeflow peut atteindre une observabilité avancée et garantir de manière constante des pipelines fiables, rentables et prêts pour la production.
Les System Tables transforment la télémétrie de votre plateforme en une ressource interrogeable. Au lieu de rassembler les signaux de cinq outils différents, vous écrivez du SQL sur un schéma unifié et obtenez des réponses en quelques secondes.
Votre « vous » de 3 h du matin vous remerciera.
Pour en savoir plus sur les System Tables, consultez les ressources suivantes :
Vous découvrez Databricks ? Essayez Databricks gratuitement dès aujourd'hui !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.