Comment l'architecture lakehouse reste résiliente aux pannes cloud
par Jasraj Dange et Hans Norheim
- Les charges de travail des agents remodèlent les exigences de fiabilité du cloud. Les agents créent des bases de données 4 fois plus rapidement que les humains, exigent une infrastructure serverless et auto-évolutive, et traitent les opérations du plan de contrôle (comme le démarrage d'une base de données) comme un travail critique du plan de données. Dans Lakebase, nous démarrons désormais des dizaines de millions de bases de données par jour.
- L'architecture Lakebase est conçue pour la résilience, pas pour y remédier. Le calcul Postgres sans état sur un stockage redondant par zone signifie que les instances peuvent être remplacées instantanément sans réplication à chaud ni récupération après incident. Nous séparons les opérations du plan de contrôle à chemin rapide dans un service dédié, minimisons les dépendances vis-à-vis du fournisseur de cloud et compartimentons chaque région en cellules autonomes.
- Nous prouvons la fiabilité par des tests et des mesures, pas par des promesses. Chaque version passe par des tests de chaos avec injection de fautes aux niveaux processus, nœud et zone de disponibilité, validés par des outils open-source comme SqlLancer. Nous suivons la disponibilité par base de données (pas les moyennes de flotte) par rapport à un objectif mensuel de 99,99 %, avec une réalisation publiée de manière transparente.
Au cours de la dernière année, les agents ont poussé les limites de l'infrastructure cloud avec de nouveaux modèles d'utilisation :
- Débit plus élevé des opérations de plan de contrôle : Les agents créent et gèrent par programme des bases de données, du stockage, du calcul et d'autres composants d'infrastructure à des vitesses beaucoup plus élevées que les humains. Dans Databricks Lakebase, les agents créent 4 fois plus de bases de données que les humains.
- Plus de demande à la demande : L'infrastructure serverless, autoscaling et auto-suspend est la nouvelle norme. Si l'agent se met en veille, pourquoi payer pour une infrastructure provisionnée ?
- Pénurie de capacité : La demande de calcul, de GPU et d'infrastructure cloud augmente. L'idée que le cloud a une capacité « infinie » montre des fissures.
C'est un défi pour les constructeurs de plateformes et les fournisseurs de cloud. Les plans de contrôle voient une augmentation significative du volume de requêtes pour la création, la gestion et la mise à l'échelle de l'infrastructure, ce qui met à rude épreuve la fiabilité. L'allocation de nouvelle capacité cloud ne réussira pas toujours. Dans le même temps, les charges de travail agentiques exigent une fiabilité au niveau du plan de données pour les opérations clés du plan de contrôle dans le cadre de leurs flux opérationnels. Au cours des derniers mois, nous avons constaté que les agents entraînaient une augmentation exponentielle des démarrages de bases de données, et nous démarrons maintenant des dizaines de millions de bases de données chaque jour.
La série d'échecs et d'incidents qui en résultent parmi les services cloud nous a appris des leçons qui éclairent notre feuille de route en matière de fiabilité, et nous voulons partager comment nous rendons l'architecture et la conception de Lakebase plus résilientes aux pannes cloud. Certains éléments sont déjà en production, d'autres sont en cours.
Architecture haute disponibilité
À la base se trouve notre architecture de calcul et de stockage séparés, où la haute disponibilité (HA) est un principe de conception fondamental du système et non un ajout.
Calcul Postgres sans état
Contrairement à de nombreuses configurations de services de bases de données Postgres dans le cloud qui sont monolithiques et ont un calcul avec état, Postgres dans l'architecture Lakebase est sans état. Toutes les données durables résident dans un service de stockage distant, de sorte que le processus de calcul ne conserve aucun état durable sur le disque local. Si Postgres ou le matériel sur lequel il s'exécute tombe en panne, il peut être remplacé instantanément sans répliquer les données vers une réplique active ni exécuter la récupération après incident habituelle de Postgres. Une réplique active dans une configuration monolithique nécessite une copie complète des données (pas gratuite), tandis que la récupération après incident doit rejouer le journal des transactions écrites (WAL) depuis le dernier point de contrôle, ce qui évolue avec le taux d'écriture au moment de la panne et peut prendre des dizaines de minutes, selon la configuration. Étant donné que le contenu de la base de données est stocké dans notre service de stockage résilient aux zones, une instance Postgres à calcul unique dans Lakebase a une disponibilité considérablement améliorée par rapport à une instance Postgres unique avec état, sans le coût d'une instance de calcul supplémentaire en réplique active.
Pour les bases de données qui nécessitent les plus hauts niveaux de disponibilité, vous pouvez configurer la haute disponibilité. Cela provisionne des calculs dédiés sur plusieurs zones de disponibilité pour votre base de données, garantissant que votre base de données reste disponible même si le fournisseur de cloud manque de capacité pendant (ou à la suite de) l'événement de défaillance. Ces calculs peuvent en outre être utilisés pour mettre à l'échelle les lectures.
Stockage redondant par zone pour tous
Les configurations Postgres monolithiques sont généralement sauvegardées par des périphériques de bloc locaux qui sont rarement redondants par zone. Cela nécessite une réplication physique et des répliques actives coûteuses dans plusieurs zones de disponibilité. Dans Lakebase et Neon, toutes les bases de données, quel que soit leur niveau et leur configuration, sont sauvegardées par un stockage distribué, redondant par zone et hautement disponible. Les données sont stockées dans un stockage d'objets hautement durable et redondant par zone, et les performances sont accélérées par des caches SSD NVMe dans plusieurs zones de disponibilité sans coût supplémentaire pour vous.
Le plan de contrôle est le nouveau plan de données
Dans l'architecture monolithique des services de bases de données cloud, le plan de données est la partie critique du service. Il est conçu pour une disponibilité de 99,99 % et une stabilité statique. Le plan de contrôle n'est important que pour les opérations de gestion. Avec les charges de travail agentiques et à la demande, la partie du plan de contrôle qui démarre les bases de données est effectivement le plan de données. Cela a changé notre façon de penser notre architecture. Actuellement, notre plan de contrôle gère tout, du démarrage des bases de données à la facturation. Le premier est clairement plus critique. Nous avons eu des pannes où les opérations de maintenance en arrière-plan ont affamé en ressources les démarrages de bases de données à la demande - ce n'est clairement pas acceptable.
Nous travaillons actuellement d'arrache-pied pour séparer les parties critiques du plan de contrôle dans un service de contrôleur de plan de données qui gère uniquement les opérations de chemin critique (démarrage/suspension). Ce service a moins de logique métier, un ensemble strict et minimal de dépendances externes (voir la section suivante), et est conçu dès le départ en gardant à l'esprit la résilience, la dégradation gracieuse et la défense en profondeur.
Pour illustrer à quel point le plan de contrôle est central pour le trafic des bases de données, nous pouvons analyser la durée de vie des sessions de calcul (le temps entre la reprise automatique due à une connexion entrante et l'arrêt dû à l'inactivité). Dans Neon, 90 % des sessions de calcul pour les bases de données en suspension automatique durent moins de 10 minutes.
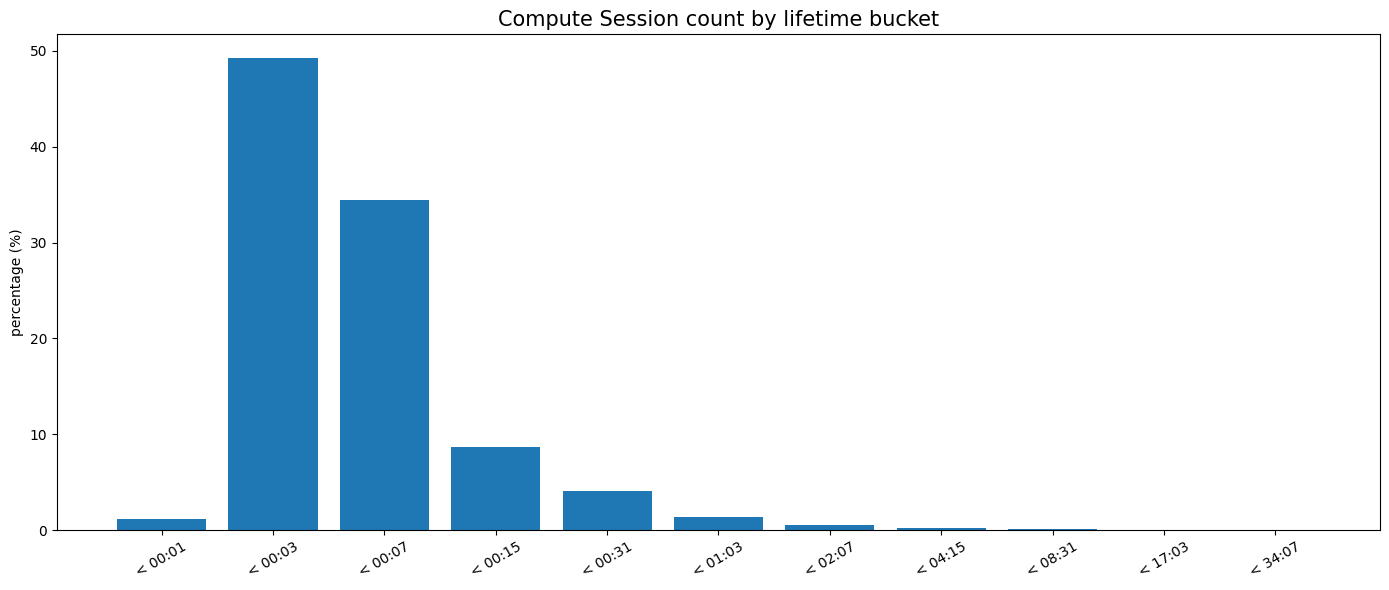
Considérez attentivement les dépendances du chemin critique, y compris les plans de contrôle des fournisseurs de cloud
Servir les charges de travail agentiques signifie que la création et la reprise des bases de données doivent être hautement fiables. La fiabilité est fortement corrélée à la chaîne de dépendances et à la quantité de machinerie impliquée dans le flux. Dans une configuration traditionnelle avec Postgres dans des VM de fournisseurs de cloud, cela va bien au-delà du plan de données :
- Plan de contrôle de calcul du fournisseur de cloud pour provisionner des VM
- Capacité de VM disponible (où le fournisseur de cloud contrôle la politique de qui l'obtient)
- Plan de contrôle de stockage de bloc du fournisseur de cloud pour provisionner le stockage local
- Plan de contrôle réseau du fournisseur de cloud pour allouer des adresses IP, configurer des pare-feu et des routes réseau vers la nouvelle VM
- Si vous utilisez Kubernetes (K8s) - une dépendance supplémentaire sur les services système K8s.
Dans Lakebase, nous adoptons une approche différente qui réduit considérablement la quantité de machinerie du plan de contrôle impliquée dans les flux de bases de données critiques :
- Nous allouons un pool de grosses instances (souvent bare metal) du fournisseur de cloud. Nous maintenons des tampons pour supporter les pannes de provisionnement du fournisseur de cloud.
- Nous avons construit notre propre couche de virtualisation autoscaling verticale qui planifie plusieurs instances Postgres sur ces instances cloud.
- Nous ne dépendons pas des périphériques de stockage de bloc du cloud, mais stockons les données dans notre propre stockage résilient aux zones qui est finalement sauvegardé dans des stockages d'objets comme S3 ou Azure Blob storage.
De nombreux autres services chez Databricks rencontrent les mêmes défis de fiabilité. C'est là que Lakebase bénéficie de faire partie de Databricks : Databricks a les moyens et investit massivement dans la construction d'une plateforme commune pour améliorer la fiabilité de tous les produits sur les trois principaux clouds.
Compartimenter et contenir le rayon d'explosion
Plutôt que d'exécuter un déploiement régional monolithique unique, Lakebase compose une région à partir d'une ou plusieurs cellules de forme identique. Une cellule est une tranche complète et autonome de la pile Neon et Lakebase : Kubernetes, plan de contrôle, calcul et stockage.
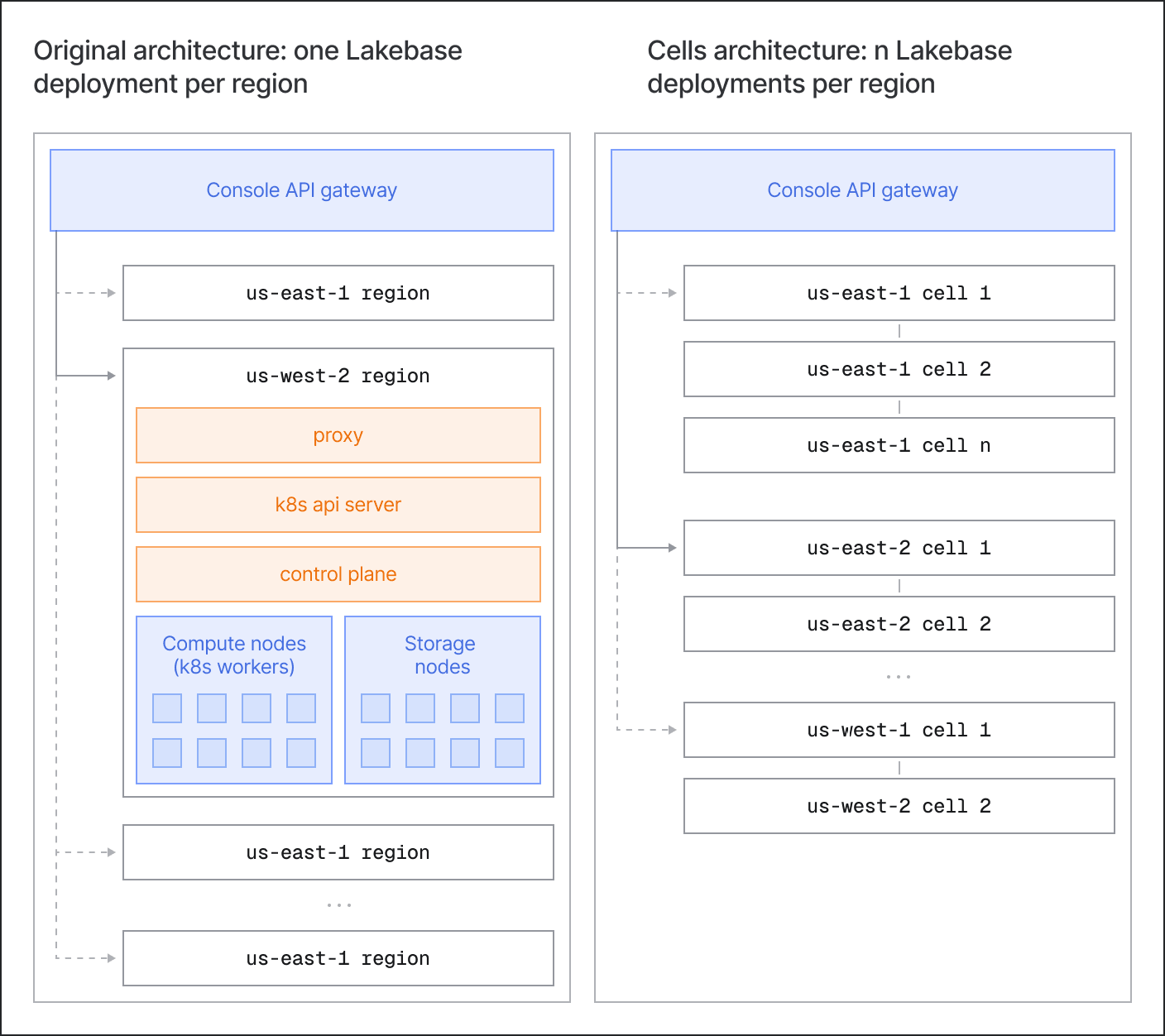
Cela aide de deux manières :
- Mise à l'échelle : Pour agrandir une région, nous ajoutons une autre cellule. Lorsqu'une cellule existante approche des limites de mise à l'échelle de Kubernetes et du plan de contrôle, la création de nouveaux projets est acheminée vers une cellule fraîchement provisionnée. Les cellules sont rapidement démarrées à mesure que la demande augmente.
- Confinement du rayon d'explosion : Même avec des tests approfondis et des protections intégrées, des problèmes surviennent toujours en production - problèmes du plan de contrôle/services système Kubernetes, régressions de code ou de configuration, situations d'attaque par déni de service (DoS), etc. La frontière de la cellule isole les défaillances et empêche la situation de se propager, laissant les autres cellules de la région servir le trafic normalement.
Ensemble, cela permet à notre plateforme de faire évoluer une région de manière élastique tout en limitant le rayon d'explosion de toute défaillance unique. Lors d'un incident le 8 mai 2026, lorsque AWS a rencontré des problèmes avec une zone de disponibilité dans us-east-1, l'une des cellules a eu des difficultés à basculer sur des nœuds sains. L'impact a été contenu dans cette cellule. Les sept autres cellules de la région ont basculé correctement, l'incident n'a donc affecté qu'environ 13 % des bases de données de la région. Dans ce cas, l'architecture basée sur les cellules a réduit l'impact d'environ un ordre de grandeur.
Simulation et injection de défaillances
L'architecture de redondance et les principes ne valent pas grand-chose s'ils ne fonctionnent pas en pratique. On peut réfléchir à tous les modes de défaillance possibles, mais la loi de Murphy est bien vivante, et les systèmes complexes trouvent toujours un moyen de vous surprendre. Chaque version de Lakebase passe par une injection de défaillance et des tests de chaos avant d'être mise en production. Nous déployons la version sur un cluster réel, l'exécutons avec un mélange de charges de travail OLTP et OLAP agentiques et non-agentiques à une concurrence de niveau stress, puis nous commençons à casser des choses en dessous. Nous tuons des processus, arrêtons des nœuds, injectons des défaillances réseau, effaçons le contenu des disques et redémarrons des composants en boucle, tout cela pendant que la charge de travail continue de fonctionner. Nous utilisons des points de défaillance (failpoints) abondamment dans notre code pour injecter des erreurs difficiles à reproduire, comme un crash au pire moment possible. Ceci est piloté par un framework interne d'injection de défaillance qui peut cibler un seul processus ou coordonner des défaillances à l'échelle du cluster dans une cellule entière.
Notre seuil de réussite est plus strict que "le test n'a pas généré d'erreur". Nous utilisons des outils open source comme SqlLancer et SqlSmith, ainsi que des outils internes similaires, pour vérifier le comportement correct de Postgres. Pendant que l'injection de défaillance s'exécute, nous validons la cohérence interne des données, qu'aucune transaction validée n'est perdue et que chaque composant récupère de manière autonome dans un état cohérent.
Nous allons maintenant passer au niveau supérieur, du chaos au niveau des composants aux simulations de pannes de zone de disponibilité complètes. Dans un cluster réel avec des charges de travail en cours d'exécution, nous déconnectons par programme le réseau d'une zone de disponibilité du reste du cluster et observons comment le système réagit : à quelle vitesse le stockage bascule vers les répliques survivantes, à quelle vitesse les calculs sont basculés vers des zones de disponibilité saines, comment la couche de proxy redirige les connexions, et combien de temps une base de données individuelle subit une interruption. Notre objectif est qu'aucune charge de travail ne soit indisponible pendant plus de 30 secondes.
Mesurer, mesurer, mesurer
Lord Kelvin a dit : « Si vous ne pouvez pas le mesurer, ce n'est pas de la science ». Nous incarnons la même chose, et nous faisons de la mesure de la disponibilité et de la fiabilité une science. L'état visible par l'utilisateur que vous voyez sur https://neonstatus.com/ est une vue d'ensemble. En interne, nous mesurons les indicateurs de niveau de service (SLI) et fixons des cibles (SLO) pour tous les composants du système et les opérations majeures, en particulier celles orientées utilisateur. Par exemple, nous mesurons :
- Disponibilité de la base de données : Pourcentage de temps pendant lequel chaque base de données individuelle est disponible. Nous ne mesurons pas seulement la disponibilité globale de la flotte, car un client individuel ne se soucie pas si la flotte avait une grande disponibilité si sa base de données était en panne.
- Temps de démarrage de la base de données : Vitesse à laquelle une base de données suspendue devient disponible lorsque vous vous connectez, ou vitesse à laquelle une base de données toute neuve démarre.
- Commutation/basculement de base de données : Fréquence et latence. Aussi rarement que possible, et aussi rapidement que possible lorsque cela se produit.
- Stockage : Disponibilité et latence des lectures de pages et des écritures durables de Postgres vers le stockage. Celles-ci nous indiquent si votre charge de travail obtient ce dont elle a besoin.
- API du plan de contrôle : Taux de réussite et latence des opérations importantes telles que le branchement (branching).
Notre objectif est que chaque base de données dépasse 99,99 % de disponibilité chaque mois. Nous mesurons à quel point nous nous rapprochons de cet objectif avec l'atteinte : Quel pourcentage des bases de données de la flotte a atteint l'objectif. Ci-dessous, l'atteinte de la disponibilité de Neon jusqu'à présent en 2026 pour les bases de données actives mensuelles.
Mois | Bases de données atteignant 99,95 % | Bases de données atteignant 99,99 % |
2026-01 | 99,96 % | 99,85 % |
2026-02 | 99,95 % | 99,84 % |
2026-03 | 99,96 % | 99,81 % |
2026-04 | 99,93 % | 99,75 % |
Une fiabilité et une disponibilité de premier ordre sont d'une importance capitale dans les systèmes opérationnels. Nous travaillons dur pour bâtir votre confiance dans notre service de base de données.
L'équipe
Le travail de fiabilité ci-dessus est mené par des personnes qui ont consacré leur carrière à la construction et à l'exploitation de bases de données relationnelles. Quelques-unes d'entre elles :
- Jasraj Dange - Responsable de l'ingénierie chez Lakebase, a précédemment dirigé les travaux sur les performances et la scalabilité d'Azure SQL Database et a fait d'Azure SQL Database une plateforme robuste pour les applications.
- Hans Norheim - Spécialisé dans la disponibilité et la fiabilité de Lakebase, a passé 13 ans chez Microsoft sur SQL Server et Azure SQL Database, y compris la technologie de mise à jour à chaud (hot patching) qui permet de mettre à jour SQL Server sans interruption, et l'orchestration des mises à niveau qui maintient Azure SQL Database à son SLA de disponibilité de 99,995 %.
- Stas Kelvich - Travaille maintenant sur Lakebase après avoir co-fondé Neon. Avant Neon, il a travaillé sur les internes de Postgres chez Postgres Professional pendant cinq ans, y compris la réplication multi-maître tolérante aux pannes avec commit par quorum, l'isolation de snapshot inter-nœuds utilisant des horloges faiblement synchronisées, et des améliorations du commit en deux phases et de la réplication logique.
- John Spray - Dirige le stockage Lakebase. A précédemment dirigé le stockage et le calcul, apportant des améliorations clés pour la mise à l'échelle comme le partitionnement (sharding). Avant cela, il a travaillé sur le stockage et les systèmes distribués chez Redpanda, Red Hat (Ceph) et Intel.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.