Une nouvelle ère pour les bases de données : Lakebase
par Ali Ghodsi, Stas Kelvich, Heikki Linnakangas, Nikita Shamgunov, Arsalan Tavakoli-Shiraji, Patrick Wendell, Reynold Xin et Matei Zaharia
Pendant des décennies, les bases de données ont été l'épine dorsale des logiciels : elles alimentent discrètement tout, des flux de paiement du commerce électronique à la planification des ressources d'entreprise. Chaque élément logiciel au monde, chaque application, chaque flux de travail, chaque ligne de code générée par l'IA dépend en fin de compte d'une base de données sous-jacente. En cours de route, nous avons complètement réinventé la façon dont les applications sont construites, mais les bases de données sous-jacentes ont très peu changé depuis les années 1980. Elles s'appuient largement sur des architectures qui précèdent le cloud moderne et souffrent des problèmes suivants :
- Opérations fragiles et coûteuses : Les bases de données traditionnelles sont considérées comme l'une des infrastructures les plus délicates, et leur exploitation fiable nécessite généralement une armée de spécialistes pour « marcher sur des œufs ». Elles regroupent le calcul et le stockage en une unité monolithique rigide. Cela oblige les équipes à provisionner pour une capacité maximale, ce qui entraîne des ressources inactives coûteuses. Lorsque la charge dépasse la capacité provisionnée, les bases de données peuvent devenir non réactives. Pire encore, des tâches de maintenance simples comme la création d'un instantané d'une base de données ou l'exécution d'une requête de nettoyage RGPD peuvent potentiellement faire planter toute la base de données.
- Expérience de développement laborieuse : Les bases de données traditionnelles se heurtent aux flux de travail de développement modernes et agiles. Pour le code, il faut moins d'une seconde pour créer une branche git pour le développement, qui est un clone entièrement isolé de la base de code. Pour les bases de données, il faut de nombreuses minutes, voire des heures, pour en provisionner une, et prendre un clone haute fidélité de la base de données de production est très coûteux et risque de faire planter la base de données de production. La montée en puissance du développement piloté par l'IA n'a fait qu'intensifier cette pression. Les agents IA ont besoin de créer instantanément des environnements temporaires et isolés pour l'expérimentation.
- Verrouillage fournisseur extrême : Les migrations de bases de données sont l'un des projets techniques les plus effrayants dans toute organisation. L'architecture monolithique signifie que la seule façon d'entrer ou de sortir des données est de passer par le moteur de base de données lui-même. Cela impose un verrouillage fournisseur important, rendant les organisations profondément dépendantes du fournisseur spécifique.
Il est temps que les bases de données évoluent.
Qu'est-ce qu'une Lakebase ?
De nouveaux systèmes commencent à émerger pour remédier aux limites des bases de données traditionnelles. Une Lakebase est une nouvelle architecture ouverte qui combine les meilleurs éléments des bases de données transactionnelles avec la flexibilité et l'économie du data lake. Les Lakebases sont rendues possibles par une conception fondamentalement nouvelle : séparer le calcul du stockage et placer les données de la base de données directement dans un stockage cloud peu coûteux (« lake ») dans des formats ouverts, tout en permettant à la couche de calcul transactionnel de fonctionner indépendamment par-dessus.
Cette séparation est la percée essentielle. Les bases de données traditionnelles regroupent le CPU et le stockage dans un système monolithique unique qui doit être provisionné, géré et payé comme une seule grosse machine. La Lakebase sépare ces couches. Les données résident ouvertement dans le lac, tandis que le moteur de base de données devient une couche de calcul entièrement gérée et sans serveur (par exemple, Postgres) qui peut évoluer instantanément. Cette architecture élimine une grande partie du coût, de la complexité et du verrouillage qui ont défini les bases de données pendant des décennies, et elle est particulièrement puissante pour les charges de travail modernes d'IA et pilotées par des agents, où les développeurs veulent lancer de nombreuses instances, expérimenter librement et ne payer que pour ce qu'ils utilisent.
Une Lakebase possède les caractéristiques clés suivantes :
Le stockage est séparé du calcul : Les données sont stockées à faible coût dans des stockages d'objets cloud (« lake »), tandis que le calcul s'exécute indépendamment et élastiquement. Cela permet une échelle massive, une concurrence élevée et la capacité de réduire l'échelle jusqu'à zéro en moins d'une seconde (ce qui n'est pas possible dans les anciens systèmes de bases de données), éliminant ainsi le besoin de maintenir des machines de base de données coûteuses en veille.
Stockage illimité, peu coûteux et durable : Avec les données résidant dans le lac, le stockage devient essentiellement infini et considérablement moins cher que les systèmes de bases de données traditionnels qui nécessitent une infrastructure à capacité fixe. Et son stockage est soutenu par la durabilité du stockage d'objets cloud (par exemple, S3), offrant 99,999999999 % de durabilité par défaut. C'est bien supérieur à la configuration traditionnelle des bases de données qui utilise des répliques pour la redondance du stockage (le plus souvent mises à jour de manière asynchrone, ce qui signifie qu'il y a un risque de perte de données dans de nombreuses configurations en cas de double défaillance).
Calcul Postgres élastique et sans serveur : Lakebase fournit Postgres sans serveur entièrement géré qui s'adapte instantanément à la demande et se réduit lorsqu'il est inactif. Les coûts sont directement alignés sur l'utilisation, ce qui en fait l'idéal pour les charges de travail intermittentes, les environnements de développement et les agents IA qui lancent des instances temporaires.
Branches, clonage et récupération instantanés : Les bases de données peuvent être branchées et clonées comme les développeurs branchifient le code. Même des bases de données de plusieurs pétaoctets peuvent être copiées en quelques secondes, permettant une expérimentation rapide, des rollbacks sûrs et une restauration instantanée sans surcharge opérationnelle.
Charges de travail transactionnelles et analytiques unifiées : Lakebase s'intègre de manière transparente avec le Lakehouse, partageant la même couche de stockage pour OLTP et OLAP. Cela permet d'exécuter des analyses en temps réel, du machine learning et des optimisations pilotées par l'IA directement sur les données transactionnelles sans les déplacer ni les dupliquer.
Ouvert et multicloud par conception : Les données stockées dans des formats ouverts évitent le verrouillage propriétaire et permettent une véritable portabilité sur AWS, Azure et au-delà. La flexibilité multicloud intégrée prend en charge la reprise après sinistre, la liberté à long terme et une meilleure économie au fil du temps.
Ce sont les attributs clés de Lakebase. Les systèmes transactionnels de niveau entreprise nécessitent des capacités supplémentaires telles que la sécurité, la gouvernance, l'audit et la haute disponibilité — mais avec une Lakebase, ces fonctionnalités n'ont besoin d'être implémentées et gérées qu'une seule fois, sur une seule fondation ouverte. Lakebase représente la prochaine évolution des bases de données : des systèmes transactionnels reconstruits pour le cloud, pour les développeurs et pour l'ère de l'IA.
Évolution de l'architecture des bases de données
Pour comprendre pourquoi une nouvelle ère est nécessaire, il est utile d'examiner comment l'architecture des bases de données a évolué au cours des cinquante dernières années. Nous considérons cette évolution en trois générations distinctes :
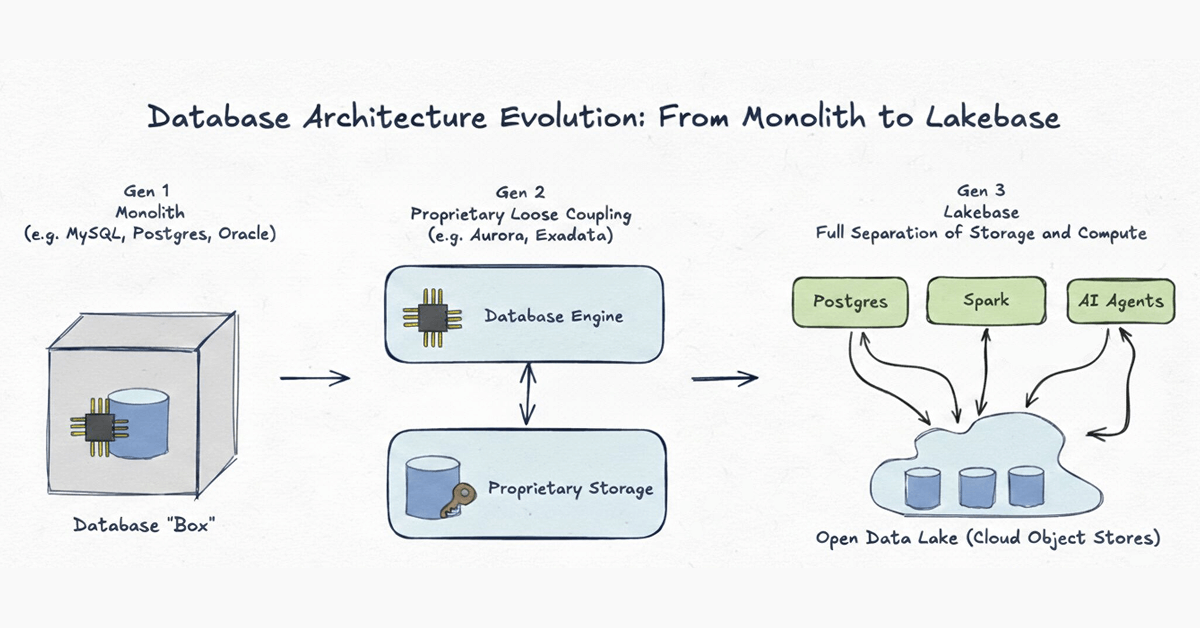
Génération 1 : Monolithe
Exemples : MySQL, Postgres, Oracle classique
Les systèmes de bases de données ont commencé comme des monolithes absolus. À l'ère pré-cloud, le réseau était la partie la plus lente de tout système. La seule façon de concevoir une base de données haute performance était de lier étroitement le calcul (CPU/RAM) et le stockage (disque) ensemble à l'intérieur d'une seule machine physique. Bien que cela ait eu du sens pour les limitations matérielles des années 1980, cela a créé une cage rigide où les données étaient piégées dans des formats propriétaires et où la mise à l'échelle signifiait acheter une machine plus grosse.
Génération 2 : Couplage lâche propriétaire du stockage
Exemples : Aurora, Oracle Exadata
Alors que l'infrastructure cloud s'améliorait, les fournisseurs ont séparé physiquement le stockage du calcul, déplaçant le stockage vers des niveaux backend propriétaires. Ces systèmes étaient des merveilles d'ingénierie qui ont repoussé les limites du débit. Cependant, ils ne sont pas allés assez loin. La séparation était purement une optimisation interne. Parce que les données restent enfermées dans un format propriétaire accessible uniquement par un seul moteur, les systèmes de génération 2 souffrent d'impasses structurelles :
- Goulot d'étranglement du moteur unique : Les données ne sont accessibles que via le moteur de base de données principal, qui devient le goulot d'étranglement. Il est difficile pour les agents IA ou les moteurs analytiques d'accéder aux données à grande échelle.
- Friction analytique : Comme vous ne pouvez pas avoir de moteurs OLAP distincts accédant directement aux fichiers de la base de données à grande échelle, l'exécution de requêtes analytiques reste difficile et nécessite généralement un ETL complexe pour déplacer les données.
- Verrouillage cloud : La couche de stockage est souvent étroitement liée à l'infrastructure propriétaire du fournisseur de cloud spécifique. Cela rend l'interopérabilité multicloud difficile et rend impossible une haute disponibilité et une reprise après sinistre (HADR) inter-cloud réelles. Si la région du fournisseur tombe en panne, vos données sont bloquées.
Nous pensons que ces systèmes sont dans un état de transition vers la 3ème génération ultime.
Génération 3 : Lakebase - Stockage ouvert sur le lac
Une Lakebase pousse l'architecture découplée à sa conclusion logique ultime. Comme la génération 2, elle sépare le calcul du stockage, mais avec une différence cruciale : l'infrastructure de stockage et les formats de données sont complètement ouverts.
En s'appuyant sur cette architecture, elle peut résoudre les 3 défis mentionnés précédemment :
- Meilleure fiabilité et coût réduit grâce à des opérations simplifiées : Les opérations courantes telles que le provisionnement, la mise à l'échelle (montée et descente), la création de branches, la capture d'instantanés et la récupération peuvent être effectuées en quelques secondes. Les requêtes coûteuses peuvent être exécutées sur différentes instances de calcul élastiques sans impacter le trafic de production.
- Expérience développeur similaire à Git : Il devient plus rapide d'expérimenter et de développer des applications, en se basant sur une branche de haute fidélité des bases de données de production. Pour les développeurs et les agents IA, cela signifie que la base de données évolue aussi vite que leur code.
- Résout le verrouillage fournisseur extrême : Avec des données dans des formats ouverts stockées dans des magasins d'objets cloud, vous êtes beaucoup moins verrouillé. Vous possédez vos données, indépendamment du moteur.
À bien des égards, une Lakebase est ce que vous construiriez si vous deviez redessiner les bases de données OLTP aujourd'hui, maintenant que le stockage d'objets bon marché et fiable et l'élasticité du cloud sont disponibles. Alors que les organisations accélèrent en adoptant le cloud et l'IA, nous nous attendons à ce que ce modèle devienne une base standard pour la construction de systèmes transactionnels.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.