Comment Superhuman et Databricks ont créé ensemble une plateforme d'inférence à 200 000 QPS
Superhuman et les ingénieurs Databricks expliquent comment ils ont conjointement migré les charges de travail de correction orthographique et grammaticale vers la plateforme Databricks Model Serving, desservant plus de 200k QPS, avec des gains de...
par Christoph Stüber, Wai Wu, Arjun DCunha, Amine El Helou, Tian Ouyang et Alex Coleman
- Superhuman est passé d'une pile vLLM DIY à Databricks FMAPI Provisioned Throughput, desservant désormais un LLM personnalisé à plus de 200K QPS avec une latence P99 inférieure à la seconde. Cela a permis à l'équipe d'ingénierie Superhuman de se concentrer sur la création et l'amélioration de son produit, tout en déléguant à la plateforme Databricks la gestion de l'échelle et de l'infrastructure.
- Les optimisations conjointes d'ingénierie ont permis un gain de débit de 60 % par GPU (750 → 1 200 QPS par pod H100) et ont réduit les coûts de service grâce à la quantification FP8, à l'élimination de la surcharge côté CPU, et à l'optimisation des noyaux d'attention sur l'architecture Hopper, le tout réalisé sans régression de qualité.
- Databricks FMAPI s'adapte de manière fiable à plus de 250 GPU grâce à un équilibrage de charge de qualité production, à l'autoscaling et à un démarrage rapide des conteneurs ; des tests de stress de montée en charge pré-production garantissant que les objectifs de disponibilité et de latence p99 sont atteints avant que le trafic n'atteigne la production.
De partenaires d'analyse à partenaires d'inférence en temps réel
Superhuman, la plateforme de productivité qui comprend Superhuman, Coda, Superhuman Mail et Superhuman Go, dessert plus de 40 millions d'utilisateurs quotidiens dans des dizaines de langues. L'assistance à la communication par IA de Superhuman fournit des suggestions en temps réel pour la correction, la clarté, le ton et le style sur toutes les plateformes où les gens écrivent.
Databricks et Superhuman sont partenaires depuis des années. L'équipe Superhuman a historiquement utilisé la plateforme Databricks Data Intelligence comme base pour l'analyse. Mais l'analyse n'était qu'une partie de l'équation.
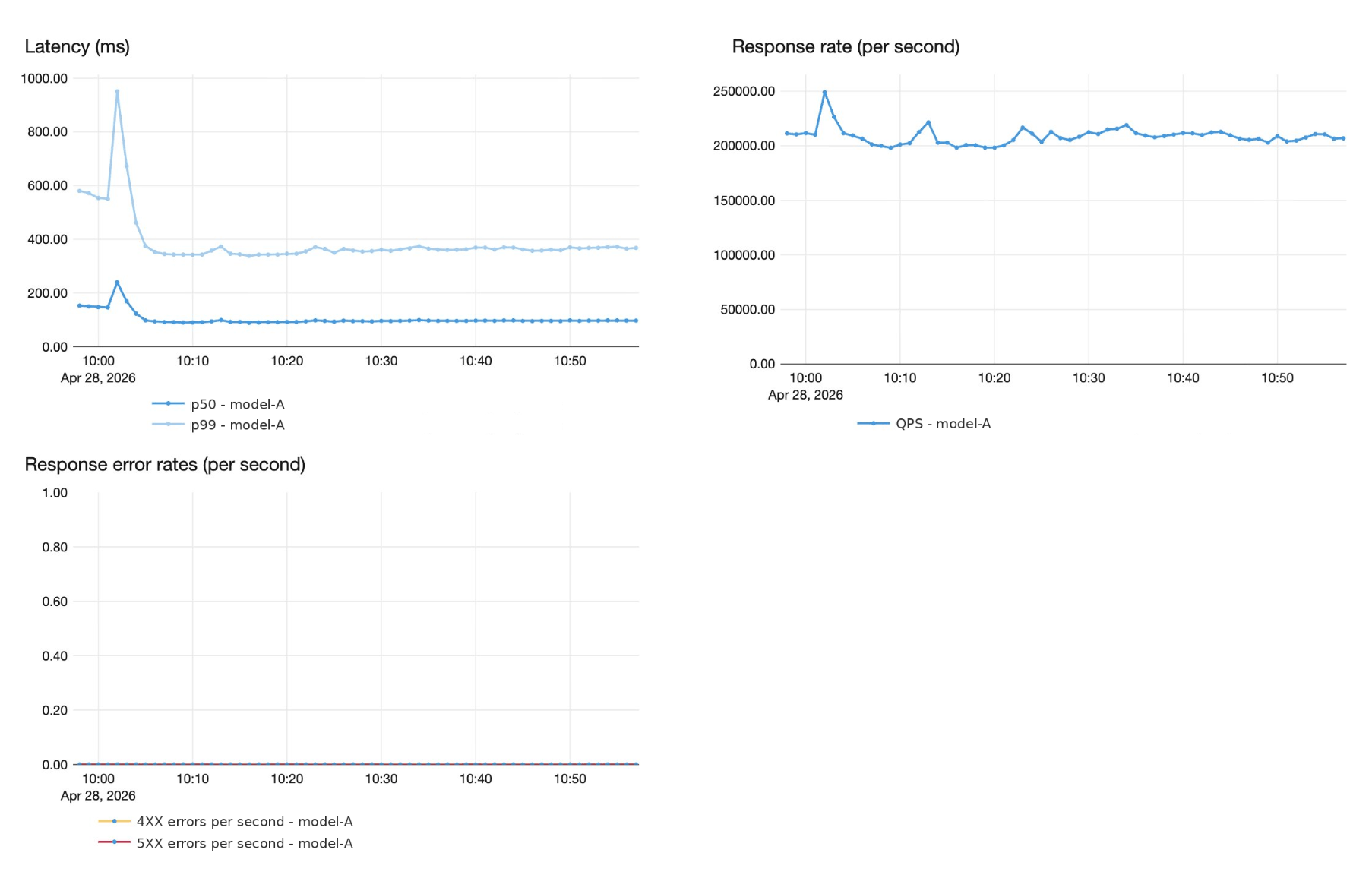
Derrière bon nombre des suggestions en temps réel de Superhuman se cache un modèle d'IA personnalisé très sophistiqué, servi à grande échelle. Superhuman exécute ce modèle avec un trafic de pointe de plus de 200 000 requêtes par seconde, avec une latence de bout en bout inférieure à 1 seconde à P99, et des garanties de fiabilité strictes de 4 neufs. Superhuman a modernisé sa pile de service pour les grands modèles de langage en tirant parti du service de modèles Databricks, ce qui a nécessité un nouveau type de partenariat, basé sur un travail conjoint sur les produits et l'ingénierie.
Comment Superhuman a modernisé sa pile de service
Avant cette migration, Superhuman exploitait une pile de service DIY basée sur vLLM, ainsi que des outils internes pour la formation et la gestion des modèles. Une équipe interne d'infrastructure ML maintenait cette pile, qui prenait en charge une échelle massive, mais plusieurs points de friction s'accumulaient lors du service des grands modèles de langage.
Le modèle d'IA personnalisé alimente la correction des erreurs grammaticales à un volume énorme, plus de 200 000 QPS de pointe avec environ 50 jetons d'entrée et 50 jetons de sortie par requête. Il poussait les limites de ce que la pile basée sur les GPU L40S pouvait offrir. Chaque nouvelle itération du modèle nécessitait des mois de réglage manuel des performances pour être intégrée. Pendant ce temps, le fardeau opérationnel augmentait, la planification de la capacité, le réglage des performances et la mise à l'échelle automatique consommant le temps d'une équipe restreinte qui devait se concentrer sur la qualité du modèle et les innovations produit.
Superhuman avait besoin d'un partenaire plateforme qui pourrait s'engager sur les SLA de performance et de latence de la pile de service, et qui co-investirait dans l'ingénierie nécessaire pour les respecter. Les deux équipes ont défini à l'avance les SLO de latence en temps réel cibles : latence p99 inférieure à la seconde et aucune régression de qualité sur les outils d'évaluation internes de Superhuman.
Respect des SLA en temps réel sur l'infrastructure de la plateforme
Atteindre les objectifs de latence sur un seul pod est nécessaire mais pas suffisant. Servir plus de 200 000 QPS de manière fiable nécessite une infrastructure capable d'équilibrer la charge, de s'adapter dynamiquement et d'absorber les pics. Obtenir cela a nécessité une collaboration étroite entre les deux équipes.
Optimisation de l'équilibrage de charge : choix de la puissance de deux
Le trafic du point de terminaison de correction grammaticale de Superhuman présente de forts modèles diurnes avec des augmentations rapides pendant certaines périodes, dépassant souvent 200 000 QPS. Bien que l'équilibreur de charge round robin par défaut de Kubernetes soit suffisant à faible QPS, nos tests ont révélé que ses performances se dégradent à QPS plus élevé, la distribution inégale des requêtes créant des points chauds qui font exploser la latence des queues.
Au cœur de notre approche se trouve le service de découverte de points de terminaison (EDS) - un plan de contrôle léger qui surveille en permanence l'API Kubernetes pour les changements dans les Services et les EndpointSlices. L'EDS pilote un algorithme d'équilibrage de charge personnalisé basé sur le choix de la puissance de deux (citation). Pour chaque requête, deux pods candidats sont échantillonnés et le trafic est acheminé vers celui qui a le moins de requêtes actives, évitant ainsi les points chauds que le round robin crée à QPS élevé (voir le blog).
Pour maintenir la plateforme rentable pour des modèles de trafic variables, le système s'adapte dynamiquement à la demande des clients. Le système de mise à l'échelle automatique suit la concurrence_requete moyennée sur les pods, avec des cibles de concurrence par pod dérivées de l'évaluation du RPS maximum durable par réplique. La stratégie de mise à l'échelle est intentionnellement asymétrique : la montée en charge est agressive et réactive, tandis que la descente en charge est conservatrice, pour éviter le battement qui provoque des pics de latence. Grâce aux tests fantômes conjoints entre Superhuman et Databricks, nous avons identifié des cas limites et résolu des problèmes lors du réglage des paramètres de l'autoscaler, y compris quand monter en charge agressivement, quand rester stable, et à quel point être conservateur lors de la descente en charge.
Optimisation du démarrage des conteneurs via l'accélération d'images
Lorsque le trafic du point de terminaison de Superhuman passe de la période creuse au pic, le système de mise à l'échelle automatique doit ajouter des dizaines de pods. Si chaque pod prend plusieurs minutes pour télécharger son image de conteneur et démarrer, les utilisateurs subissent des pics de latence pendant la montée en charge. Réduire le temps de démarrage des pods se traduit directement par une montée en charge plus rapide et une latence plus fluide pendant les pics de trafic.
L'équipe de service de modèles Databricks a adopté le travail d'accélération d'images initialement conçu pour le calcul serverless (blog) pour éviter les démarrages à froid. L'approche convient bien aux modèles relativement petits que nous servions pour Superhuman.
Lors de la création d'une image de conteneur, nous ajoutons une étape supplémentaire pour convertir le format d'image standard basé sur gzip au format basé sur un périphérique de bloc adapté au chargement paresseux. Cela permet à l'image de conteneur d'être représentée comme un périphérique de bloc indexable avec des secteurs de 4 Mo en production.
Lors du téléchargement des images de conteneurs, notre runtime de conteneur personnalisé récupère uniquement les métadonnées nécessaires pour configurer le répertoire racine du conteneur, y compris la structure du répertoire, les noms de fichiers et les autorisations, et crée un périphérique de bloc virtuel en conséquence. Il monte ensuite le périphérique de bloc virtuel dans le conteneur afin que l'application puisse commencer à s'exécuter immédiatement.
Lorsque l'application lit un fichier pour la première fois, la requête d'E/S sur le périphérique de bloc virtuel déclenche un rappel vers le processus de récupération d'image, qui récupère le contenu réel du bloc du registre de conteneurs distant. Le contenu du bloc récupéré est également mis en cache localement pour éviter les allers-retours réseau répétés vers le registre de conteneurs, réduisant ainsi l'impact de la latence réseau variable sur les lectures futures.
Ce système de fichiers de conteneur à chargement paresseux élimine le besoin de télécharger l'intégralité de l'image du conteneur avant de démarrer l'application, réduisant le temps de démarrage du conteneur de plusieurs minutes à quelques secondes seulement.
Optimisations du runtime : 60 % de débit en plus par pod
La couche plateforme gérant l'échelle de la flotte, la question suivante était de savoir combien de QPS chaque pod pouvait supporter et à quel coût.
Dans cette section, nous présentons les optimisations qui ont augmenté le débit par pod de 750 QPS à 1 200 QPS sur les GPU H100, soit une amélioration de 60 %, tout en maintenant zéro régression de qualité.
Quantification FP8
La quantification FP8 a été la plus grande amélioration du débit, atteignant jusqu'à 30 % d'augmentation des QPS par pod.
L'équipe ML de Superhuman a pré-quantifié le checkpoint en FP8 à l'aide de la bibliothèque de quantification en ligne de vLLM, produisant un checkpoint au format tenseur compressé que Databricks a chargé pour le service. Dans la configuration finale, les projections d'attention (Q, K, V et sortie) et les projections MLP ont toutes été exécutées via le chemin FP8, tandis que la quantification du cache KV a été laissée désactivée, car la quantification des poids était la source des gains de débit et la quantification du cache KV introduisait ses propres compromis de qualité qui ne valaient pas la peine d'être poursuivis pour cette charge de travail.
Avant de finaliser la configuration, les deux équipes ont itéré sur les couches à quantifier. Les projections MLP ont été quantifiées dès le départ, et la question ouverte était de savoir s'il fallait quantifier les couches d'attention. Le service de modèles Databricks avait conçu le moteur de service pour prendre en charge l'inférence en précision mixte dès le départ, de sorte que si un groupe de couches s'avérait trop sensible à la qualité sous quantification, nous pouvions le conserver dans une précision plus élevée sans modifier l'architecture de service globale. Nous avons publié un indicateur qui nous a permis d'activer et de désactiver la quantification de l'attention, afin que les deux équipes puissent mesurer directement son impact. L'expérience s'est déroulée sans problème, la quantification des projections Q/K/V et de sortie n'a produit aucune dégradation mesurable de la qualité sur les évaluations de Superhuman.
L'autre considération était la granularité de la quantification. Les noyaux prêts à l'emploi utilisaient une mise à l'échelle par tenseur (un seul facteur d'échelle FP8 pour un tenseur de poids entier). Les noyaux Databricks utilisent une mise à l'échelle par canal, calculant un facteur d'échelle distinct par canal de sortie de chaque couche linéaire. Cela préserve la plage dynamique là où elle est importante, maintient l'erreur de quantification de la couche MLP bien en dessous du seuil où elle apparaît dans les évaluations. Combinée à des améliorations au niveau du noyau, la quantification par canal a égalé ou dépassé d'autres bases de code open source à un débit identique.
Élimination des goulots d'étranglement côté CPU
Pour les modèles petits et rapides, les performances sont souvent limitées par le CPU – pas par le GPU. L'équipe Databricks avait déjà étudié l'élimination des goulots d'étranglement CPU dans son travail sur le service PEFT rapide et y a appliqué des optimisations CPU similaires directement à la charge de travail de Superhuman.
Plus précisément, l'équipe a introduit un serveur runtime multiprocessus. Pour la plupart des charges de travail de service de modèles, un seul processus est suffisamment rapide pour saturer le GPU, car le GPU est le goulot d'étranglement, pas le CPU. Mais avec un modèle petit et rapide, le GPU termine sa passe avant plus rapidement qu'un seul processus ne peut préparer le lot suivant, inversant le goulot d'étranglement vers le CPU.
L'équipe a résolu ce problème en exécutant plusieurs processus serveur RPC. En ayant plusieurs processus CPU qui préparent et distribuent le travail au GPU en parallèle, nous avons éliminé le goulot d'étranglement de sérialisation d'un seul processus. Cela a permis d'augmenter le débit de 20 % supplémentaires.
D'autres optimisations côté CPU ont amélioré les performances de quelques points de pourcentage.
- Réduction de la surcharge Python. Nous avons remplacé le découpage, la copie et le remplissage de tenseurs au niveau Python au début de chaque étape de décodage de graphe CUDA par un seul appel C++. Nous avons également exploré des stratégies parallèles (ThreadPool, OpenMP), mais le C++ mono-thread était optimal en raison de la surcharge de synchronisation CUDA. Cela a légèrement réduit l'inactivité du GPU par passe avant.
- Planification asynchrone pour un meilleur chevauchement du travail CPU-GPU. Nous avons retiré le post-traitement côté CPU du chemin critique afin qu'il s'exécute simultanément avec la prochaine passe avant GPU. Plutôt que de terminer tout le post-traitement du lot N avant de lancer le lot N+1, le planificateur distribue immédiatement N+1 et gère le post-traitement de N en parallèle. Le post-traitement itère également uniquement sur le sous-ensemble pertinent de requêtes plutôt que sur le lot complet. Cela a permis de démarrer la passe avant suivante plus tôt.
Et ensuite
Ce travail est la base d'un partenariat plus large. Superhuman migre désormais des modèles supplémentaires vers Databricks, couvrant différentes tailles de modèles, types de tâches et exigences de latence — et adopte plus largement la plateforme d'IA pour les flux de travail d'entraînement, le suivi des expériences, les évaluations (ML classique, Deep-Learning et IA Générative/Agents), le registre de modèles et de juges (LLM) et l'ingestion à grande échelle des traces d'agents.
La construction de cette plateforme à grande échelle a été un effort d'entreprise des deux côtés, et une expérience d'apprentissage extraordinaire. Un grand merci aux équipes ML et infrastructure de Superhuman pour leur collaboration approfondie, leur volonté d'itérer ouvertement sur des compromis difficiles et la rigueur qu'elles ont apportée à chaque barre de qualité et test de charge. Le manuel d'ingénierie que nous avons construit ensemble est autant le leur que le nôtre, et nous sommes ravis d'apporter le même niveau de partenariat à chaque charge de travail qui suit.
Points clés à retenir
L'utilisation d'un service d'inférence géré ne signifie pas nécessairement renoncer au contrôle. Superhuman conserve la pleine propriété de l'entraînement des modèles, de la quantification et des normes de qualité, tandis que Databricks maintient les performances d'exécution et la fiabilité de la plateforme. Cette division des responsabilités fonctionne bien avec des SLO partagés, une validation de qualité conjointe et des tests de charge progressifs lors de l'intégration à la plateforme Databricks.
Prêt à servir vos modèles personnalisés à grande échelle ? Découvrez comment l'API Databricks Foundation Model peut répondre à vos SLA d'inférence les plus exigeants — et donner à votre équipe un véritable partenaire d'ingénierie, pas seulement un service géré. Contactez-nous à https://www.databricks.com/company/contact pour intégrer votre cas d'utilisation de service de modèles à haute QPS.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.