Comment transformer les flux de travail d'activation de documents avec Genie et Agent Bricks
Transformez vos documents en informations commerciales précieuses avec Databricks
par Elena Tesser
-Les flux de travail manuels d'extraction de documents dans des secteurs tels que les médias, les communications et les jeux ralentissent les équipes, entraînant des pertes de revenus et augmentant les risques de conformité.
-Les entreprises peuvent réunir AI/BI Genie, Agent Bricks et Unity Catalog pour établir un flux de travail rigoureux multi-agents capable de convertir des documents clés dans les domaines du marketing, du juridique, de la finance, des RH, etc. en données gouvernées, consultables et exploitables.
-En passant de l'extraction à l'orchestration multi-agents et à la réécriture du système, les organisations peuvent passer de manière transparente du traitement à la lecture, puis à l'activation de leurs documents.
Il existe un manque de renseignement documentaire dans les entreprises d'aujourd'hui
Les organisations fonctionnent sur des montagnes de documents, des contrats aux accords d'emploi, en passant par les accords de talents et les accords de non-divulgation, jusqu'aux bons de commande publicitaires et aux accords-cadres de services, et plus encore. Chaque document contient des informations précieuses sur les revenus potentiels, les risques et les obligations, pourtant la façon dont la plupart des organisations les traitent n'a guère changé depuis des décennies.
Pourtant, aujourd'hui, même si les organisations intègrent de plus en plus l'IA pour les aider à avancer plus rapidement, de nombreuses équipes s'appuient encore sur des humains pour lire des PDF, copier des champs dans des feuilles de calcul et ressaisir des données dans les systèmes ERP, CRM et de planification. Tout cela crée des risques importants ; les flux de travail de traitement manuel entraînent des retards et des pertes de revenus potentielles dues à des erreurs humaines, tandis que le manque de gouvernance signifie que les équipes ne peuvent pas auditer de manière fiable leurs rapports.
Les outils ponctuels et les architectures héritées sont insuffisants
Les dirigeants comprennent que l'automatisation par l'IA peut les aider à surmonter ces défis. Cependant, beaucoup hésitent à intégrer pleinement l'IA dans leurs flux de travail, car les premiers investissements tels que les moteurs OCR, les systèmes de gestion du cycle de vie des contrats et les solutions ponctuelles spécifiques à un domaine ont souvent sous-performé. Même lorsque les organisations expérimentent avec GenAI, de nombreuses équipes financières, juridiques et opérationnelles signalent encore peu de valeur réalisée grâce aux investissements en IA. Le problème, cependant, n'est pas l'automatisation par l'IA elle-même, mais les fondations de données fragmentées et incomplètes sur lesquelles reposent ces premiers outils.
Sans une fondation de données unifiée et bien gouvernée, elles manquent de contexte sectoriel et organisationnel, sont isolées des systèmes d'entreprise clés, sont uniquement conçues pour la lecture, pas pour l'activation. Pire encore, lorsque vous tentez de construire un flux de travail d'agent par-dessus, vous obtenez une expérience décousue, incohérente et impossible à mettre à l'échelle.
Adopter une approche plateforme pour l'activation des documents
Le moment décisif pour le renseignement documentaire survient lorsqu'une entreprise passe de la gestion des flux de travail avec des solutions d'outils ponctuels à leur construction sur une fondation de données unifiée et gouvernée. Ce changement ouvre la porte à une expérience multi-agents véritablement unifiée et évolutive qui permet aux utilisateurs techniques et non techniques de requêter leurs données commerciales structurées et non structurées, puis d'agir sur ces données.
Trois capacités principales de Databricks rendent cela possible :
- AI/BI Genie : une expérience BI native de l'IA qui permet aux utilisateurs professionnels de poser des questions en langage naturel sur des tables Delta gouvernées, sans écrire de SQL.
- Agent Bricks : des blocs de construction réutilisables pour des agents de haute qualité, prêts pour la production, y compris l'extraction d'informations, les assistants de connaissance et l'orchestration, qui sont construits et optimisés sur vos données plutôt que comme des prototypes uniques.
- Unity Catalog : gouvernance unifiée, lignage et contrôle d'accès granulaire sur les données, les agents IA et même les serveurs MCP, du document source à la réponse de l'agent et à la réécriture du système.
Le flux de travail d'activation de documents multi-agents
Au-dessus de cette fondation, nous mettons en œuvre un flux de travail d'activation de documents en phases que les équipes techniques et non techniques peuvent adopter et reproduire étape par étape.
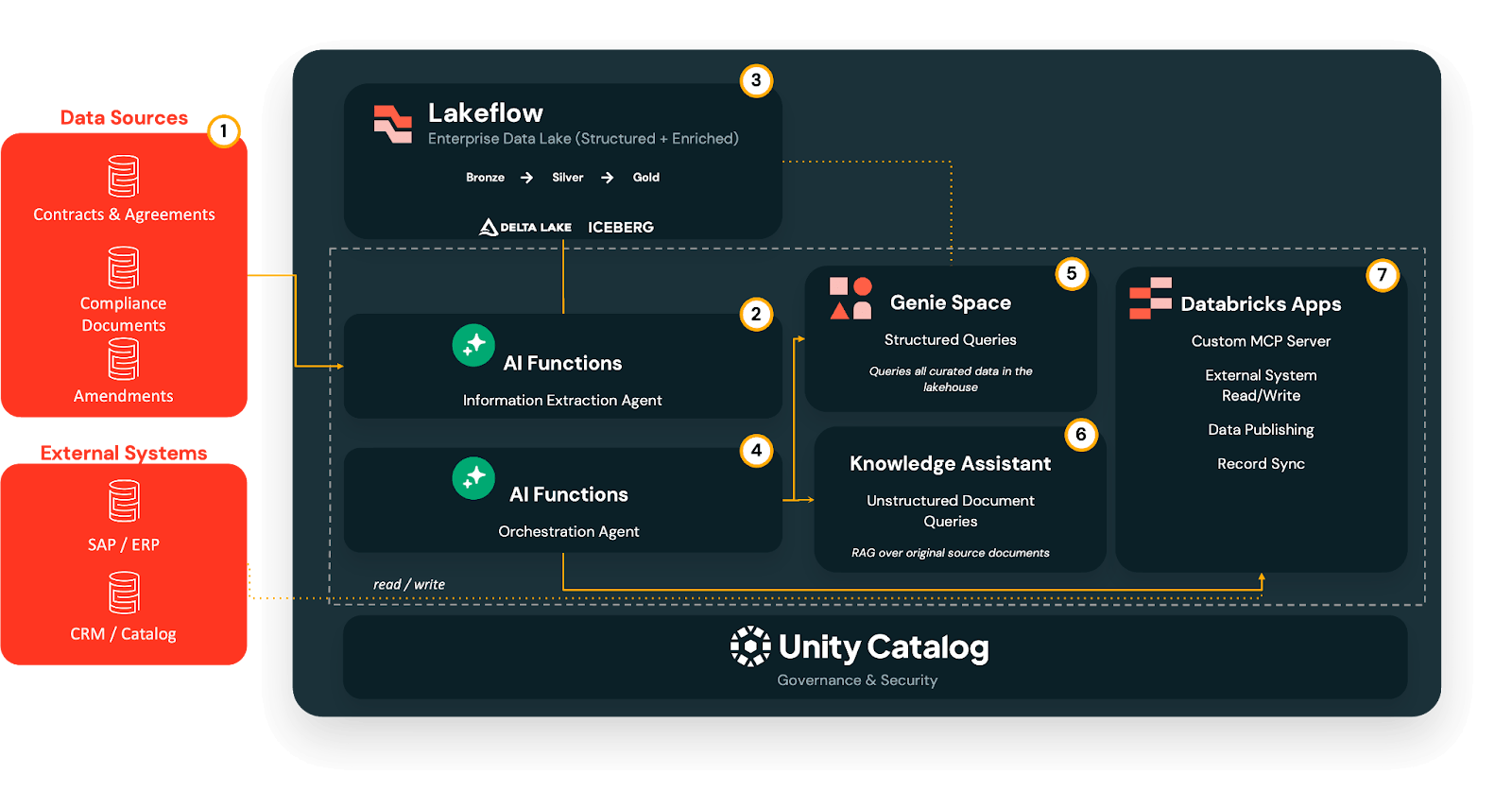
Phase 1 - Extraire : des PDF aux tables Delta gouvernées
Dans la phase 1, l'agent d'extraction d'informations Information Extraction Agent utilise l'extraction basée sur LLM pour convertir les documents non structurés (PDF, DOC/DOCX, PPT/PPTX, images) en champs structurés, sans construire de pipelines OCR personnalisés ni d'analyseurs uniques.
Les sorties brutes arrivent dans un pipeline Lakeflow medallion :
- Bronze : champs extraits bruts tels quels.
- Silver : valeurs nettoyées et standardisées, avec des ID canoniques résolus et des codes normalisés.
- Gold : tables prêtes à l'emploi, optimisées pour les requêtes et l'analyse.
Cette extraction s'exécute au moment de l'ingestion, pas au moment de la requête, de sorte que tout ce qui suit s'appuie sur une fondation de données cohérente et gouvernée.
Phase 2 : Requêter - Analyse en libre-service avec Genie
Une fois les termes clés structurés dans des tables Delta, AI/BI Genie offre aux utilisateurs professionnels une interface en libre-service pour poser des questions en anglais simple.
Pointez Genie vers les tables de la couche or, et les utilisateurs peuvent poser des questions telles que « Quels contrats expirent au prochain trimestre en EMEA ? » ou « Quels accords d'éditeur ont des paliers de partage des revenus qui s'activent au-dessus d'un certain seuil de dépenses ? » Genie traduit ensuite ces requêtes en SQL, applique les permissions d'Unity Catalog et renvoie des résultats tabulaires ou visuels, éliminant le goulot d'étranglement de l'analyste tout en maintenant la gouvernance de l'accès aux données.
Phase 3 : Comprendre - Réponses au niveau des clauses avec Knowledge Assistant
Certaines questions ne peuvent pas être répondues uniquement à partir d'agrégats. Les équipes juridiques, de droits et de conformité ont souvent besoin de savoir exactement ce que dit une clause spécifique.
Ici, un Knowledge Assistant, un agent conversationnel basé sur RAG, s'exécute directement sur les documents sources originaux stockés dans les volumes d'Unity Catalog.
Il peut répondre à des questions telles que : « Quelles sont les restrictions de sous-licence dans l'accord Warner ? » ou « Avons-nous des droits SVOD pour le Spectacle X en France en 2027, et sont-ils exclusifs ? » L'assistant renvoie ensuite des extraits au niveau des clauses avec des citations vers les PDF d'origine, en maintenant une traçabilité complète.
Phase 4 : Orchestrer — une seule porte d'entrée avec un superviseur multi-agents
Lorsque vous ajoutez plus d'agents, vous ne voulez pas que les utilisateurs décident quel outil ouvrir pour chaque question.
Le Multi-Agent Supervisor agit comme un point d'entrée conversationnel unique qui analyse chaque requête et la dirige vers le bon spécialiste :
- Questions structurées → Espaces Genie
- Questions au niveau des clauses → Knowledge Assistant
- Actions système → Connecteurs basés sur MCP et flux en aval
Les utilisateurs posent simplement leur question et le superviseur sélectionne le bon chemin, en combinant le contexte non structuré et structuré si nécessaire.
Phase 5 : Agir — de l'information aux mises à jour du système avec MCP
Enfin, les serveurs MCP transforment la compréhension des documents en actions en encapsulant les API des systèmes externes (ERP, HRIS, CRM, plateformes publicitaires, systèmes de droits, Slack) comme des outils que le superviseur peut appeler.
Cela vous permet de prendre la meilleure mesure en fonction des données extraites et du contexte organisationnel. Les exemples incluent :
- Intégrer des données de droits validées dans SAP et les synchroniser avec un catalogue de titres ou un CRM.
- Mettre à jour les droits et les bundles dans les systèmes de facturation et de service client en fonction des termes extraits.
- Déclencher des flux de travail dans des outils de ticketing ou de gestion de projet lorsque des délais réglementaires ou des obligations de compensation sont détectés.
Enfin, comme tout cela est régi par Unity Catalog, chaque champ reste traçable jusqu'au document dont il provient, avec un lignage et des pistes d'audit à travers les agents et la réécriture du système.
Cas d'utilisation spécifiques à l'industrie dans les médias, les agences, l'ad tech et les télécommunications
Ce flux de travail d'activation de documents peut s'appliquer à un large éventail d'industries et de cas d'utilisation. Cependant, il peut avoir un impact particulièrement important pour des industries telles que les télécommunications et les médias et le divertissement, où les clients disposent d'énormes quantités de données structurées et non structurées en constante évolution dans leurs documents. Quel que soit le besoin métier ou le persona, il existe une application pour transformer les documents pertinents en informations claires et gouvernées et en la prochaine action appropriée.
- Éditeurs et studios de médias
- Suivre les contrats de droits et de licences, répondre à des questions telles que « Avons-nous les droits de streaming pour le Titre X en Allemagne jusqu'en 2027 ? » et signaler de manière proactive les contrats expirant dans les 90 prochains jours.
- Extraire les termes de partage des revenus et de distribution dans des tables structurées et intégrer les chiffres validés dans les systèmes ERP et de planification.

- Agences médias
- Extrayez les barèmes de prix, les seuils AVB et les déclencheurs de facturation des contrats d'achat de médias, et rapprochez-les automatiquement de la livraison et des dépenses.
- Structurez les briefs clients et les rapports de recherche en données réutilisables pour les systèmes de planification et l'analyse des campagnes.
- Plateformes Ad Tech
- Activez les réglementations sur la confidentialité et les documents de politique publicitaire pour répondre à la question « Quelles réglementations actives nécessitent des mécanismes d'opt-out pour le ciblage comportemental ? » et appliquez des contrôles dans les moteurs de consentement et de politique.
- Suivez les licences de données et les conditions des API pour empêcher l'entraînement ou l'activation de modèles non conformes.
- Fournisseurs de télécommunications
- Gérez les accords de service et de gros, les conditions des accords d'itinérance et d'interconnexion, et les baux de tours, avec une visibilité claire sur les SLA, les escalades et les fenêtres de renouvellement.
- Gouvernez les droits clients et les bundles de bout en bout, en synchronisant les droits validés avec les systèmes de facturation, CRM et de support.
Dans tous ces scénarios, les clients constatent des améliorations telles qu'une clôture de fin de mois plus rapide, des revenus récupérés, une réduction des fuites et un risque opérationnel plus faible, tout en réduisant l'effort manuel pour les équipes financières, juridiques, opérationnelles et marketing.
Prochaines étapes
Si vos équipes dépendent encore de flux de travail documentaires manuels et d'outils déconnectés, il est temps de moderniser l'intelligence documentaire sur une plateforme de données et d'IA gouvernée.
- Explorez Databricks pour les médias et le divertissement et les télécommunications pour voir comment les contrats, les politiques et les accords s'intègrent dans votre stratégie de données globale.
- Parlez à votre équipe de compte Databricks d'une preuve de valeur d'activation documentaire ciblée, en commençant par un cas d'utilisation à fort impact et une seule ligne de métier.
- Plongez dans les témoignages clients tels que SEGA, First American, et Vale pour voir comment les organisations transforment déjà les documents non structurés en données gouvernées et exploitables à grande échelle.
En unifiant l'extraction, l'interrogation, le RAG, l'orchestration et la réécriture système sur Databricks, vous pouvez aller au-delà de la simple « lecture de documents » pour les activer, débloquant ainsi de nouveaux revenus, réduisant les risques et libérant vos équipes pour qu'elles se concentrent sur un travail à plus forte valeur ajoutée.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.