Comment les tables gérées Unity Catalog automatisent les performances à grande échelle
Les optimisations IA intégrées offrent jusqu'à 50 % de réduction des coûts et des requêtes 20 fois plus rapides, sans réglage manuel
par Elizabeth Bowman
- Découvrez les fonctionnalités qui font des tables gérées par Unity Catalog (UC) la meilleure pratique standard pour la gestion des données
- Réduisez les coûts de plus de 50 % et améliorez les performances des requêtes de plus de 20x grâce à l'optimisation prédictive sur les tables gérées par UC
- Économisez du temps d'ingénierie des données grâce à des optimisations de données intelligentes et automatiques qui s'adaptent aux modèles d'utilisation
Unity Catalog (UC) tables gérées combinent une gouvernance robuste avec une interopérabilité transparente entre les outils. Les données étant stockées dans le cloud public appartenant au client, les organisations conservent le contrôle total de leur emplacement physique, tout en bénéficiant de l'intelligence et de l'automatisation intégrées de Databricks.
Aujourd'hui, les tables gérées UC sont le type de table le plus couramment utilisé dans Databricks ; deux tables UC sur trois sont gérées. Cette adoption reflète sa capacité à simplifier les opérations, à réduire les coûts et à améliorer les performances à grande échelle.
Avec les tables gérées UC, les organisations peuvent être sûres d'utiliser toujours les dernières fonctionnalités des tables. Ces tables sont automatiquement mises à niveau et, contrairement à d'autres types de tables, elles comprennent les modèles d'utilisation, ce qui permet d'activer de nouvelles capacités de manière sûre et progressive, sans intervention manuelle.
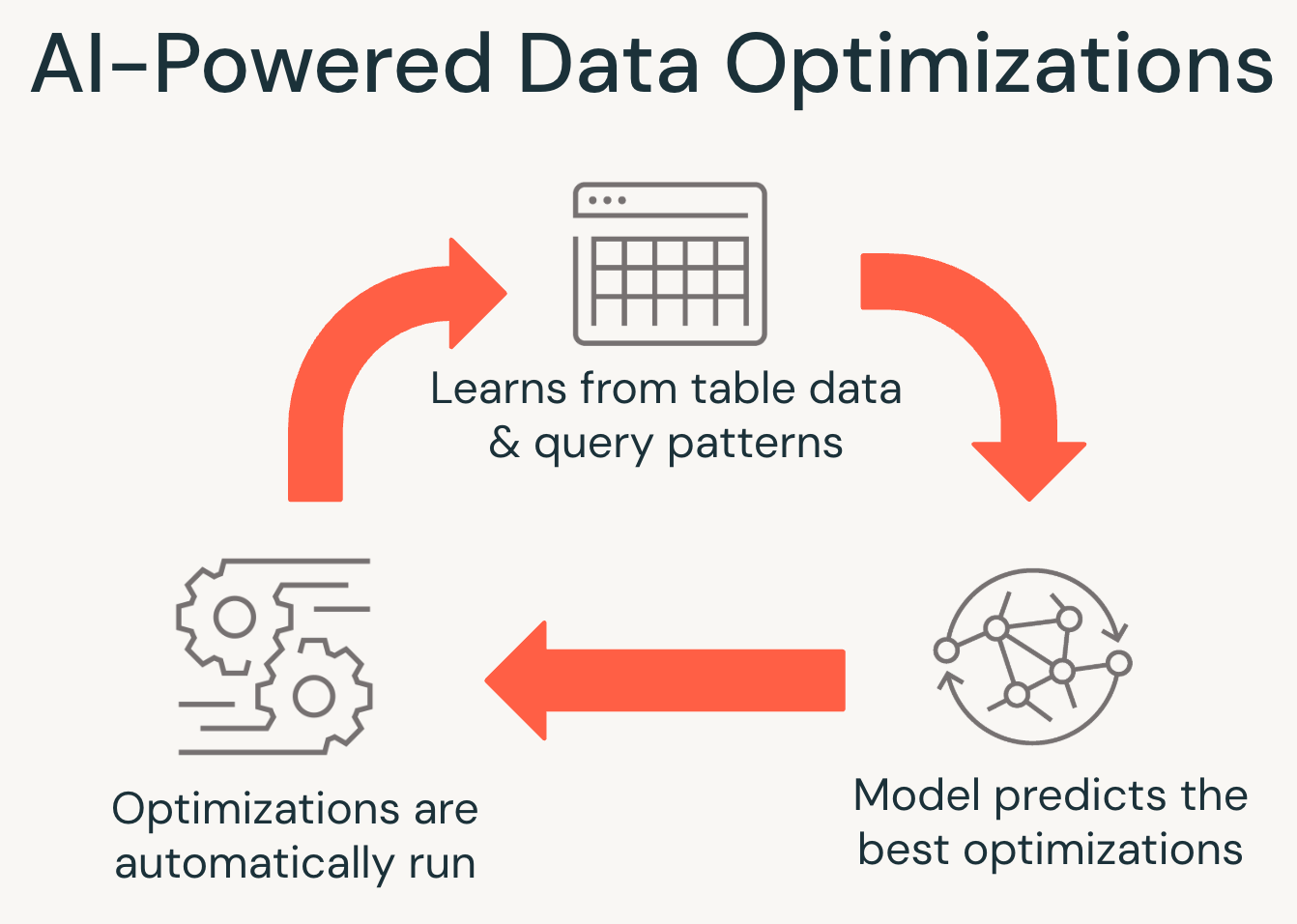
La structure des tables gérées UC permet également des capacités d'IA avancées qui n'étaient pas possibles auparavant. Comme toutes les lectures et écritures passent par Unity Catalog, Databricks peut optimiser intelligemment les données en fonction de l'utilisation réelle, améliorant ainsi les performances des requêtes, réduisant les coûts de stockage et éliminant la maintenance de routine.
Les principaux avantages incluent :
- Mises à niveau automatiques avec les dernières fonctionnalités
- Auto-maintenance avec compaction, clustering et vacuuming
- Économies sur les coûts de stockage et de calcul grâce à l'optimisation intelligente
- Accès sécurisé via des API ouvertes, même pour les clients non-Databricks
- Requêtes plus rapides sur tous les clients, pas seulement dans Databricks
Dans ce blog, nous examinerons en détail les fonctionnalités qui rendent les tables gérées UC efficaces, ainsi que les améliorations récentes et un aperçu de ce qui est prévu.
« Les optimisations automatiques des tables gérées Unity Catalog nous ont fait économiser plus d'un million de dollars par an en coûts de stockage, tout en éliminant le besoin d'efforts manuels fastidieux au quotidien. » —Abhinav Raghuvanshi, Associate Director of Data Engineering chez Zepto
Quels sont les avantages des tables gérées Unity Catalog ?
Les tables gérées UC sont optimisées par défaut, sans réglage manuel requis. Elles s'adaptent en permanence en fonction des charges de travail des requêtes pour améliorer les performances, réduire les coûts de stockage et rationaliser la gestion du cycle de vie.
Les tables gérées UC simplifient également les opérations avec des fonctionnalités intégrées telles que le vacuuming automatique, la compaction des fichiers et la mise en cache des métadonnées. Parce qu'elles sont construites sur des formats ouverts comme Delta et Iceberg, les tables gérées UC s'intègrent facilement avec les outils et moteurs tiers.
Les optimisations intelligentes génèrent des gains de coûts et de performances
Les tables gérées UC appliquent un ensemble de techniques basées sur l'IA pour offrir jusqu'à 50 % d'économies de coûts et des requêtes jusqu'à 20 fois plus rapides :
Clustering liquide automatique
Les tables gérées UC regroupent automatiquement les données en fonction des modèles de requête observés, sans nécessiter de configuration manuelle. En revanche, les tables externes UC nécessitent que les ingénieurs de données exécutent des commandes OPTIMIZE et définissent manuellement des clés de clustering. Avec les tables gérées, Predictive Optimization gère le clustering dynamiquement, améliorant les performances des requêtes et réduisant les coûts de stockage sans effort supplémentaire. [En savoir plus]

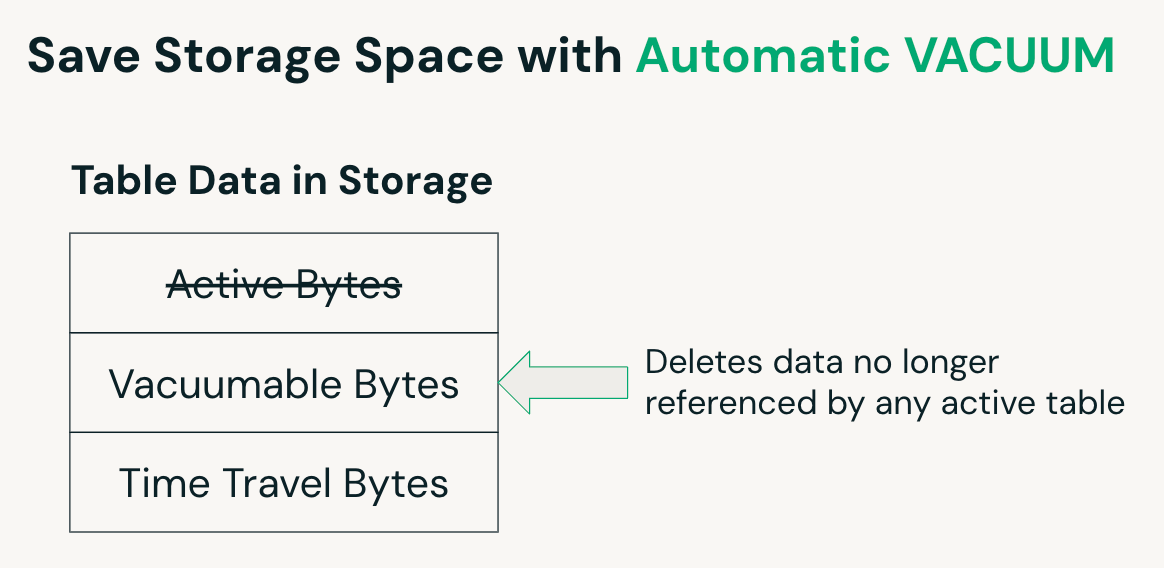
VACUUM automatique
Sur les tables gérées UC, Predictive Optimization identifie automatiquement quand une opération VACUUM est bénéfique et la planifie en conséquence. VACUUM supprime les fichiers associés aux lignes supprimées après une période de rétention définie, aidant à réduire l'utilisation du stockage. Pour les tables externes UC, ce processus doit être géré manuellement en exécutant la commande VACUUM.
DROP différé avec nettoyage automatique
Lorsqu'une table gérée UC est supprimée, les données sous-jacentes dans le stockage cloud sont automatiquement supprimées après 7 jours, aidant à réduire les coûts de stockage et à éviter les fichiers orphelins. En revanche, la suppression d'une table externe UC ne supprime pas les données ; les utilisateurs doivent supprimer manuellement les fichiers de leur compartiment de stockage. Si cette étape est omise, les données persistent, entraînant une utilisation inutile du stockage. Voir la section feuille de route pour les améliorations à venir de ce comportement.
Collecte automatique de statistiques
Les tables gérées UC collectent automatiquement des statistiques qui améliorent les performances des requêtes grâce à un meilleur saut de données et une meilleure planification des jointures. Les métriques clés, telles que les valeurs minimales et maximales des colonnes, aident le système à identifier et à ignorer les fichiers non pertinents pendant l'exécution des requêtes, réduisant ainsi la surcharge de calcul. Alors que les tables externes UC génèrent des statistiques sur les 32 premières colonnes par défaut, les tables gérées UC priorisent dynamiquement les colonnes les plus pertinentes pour les charges de travail de requête réelles. [En savoir plus]

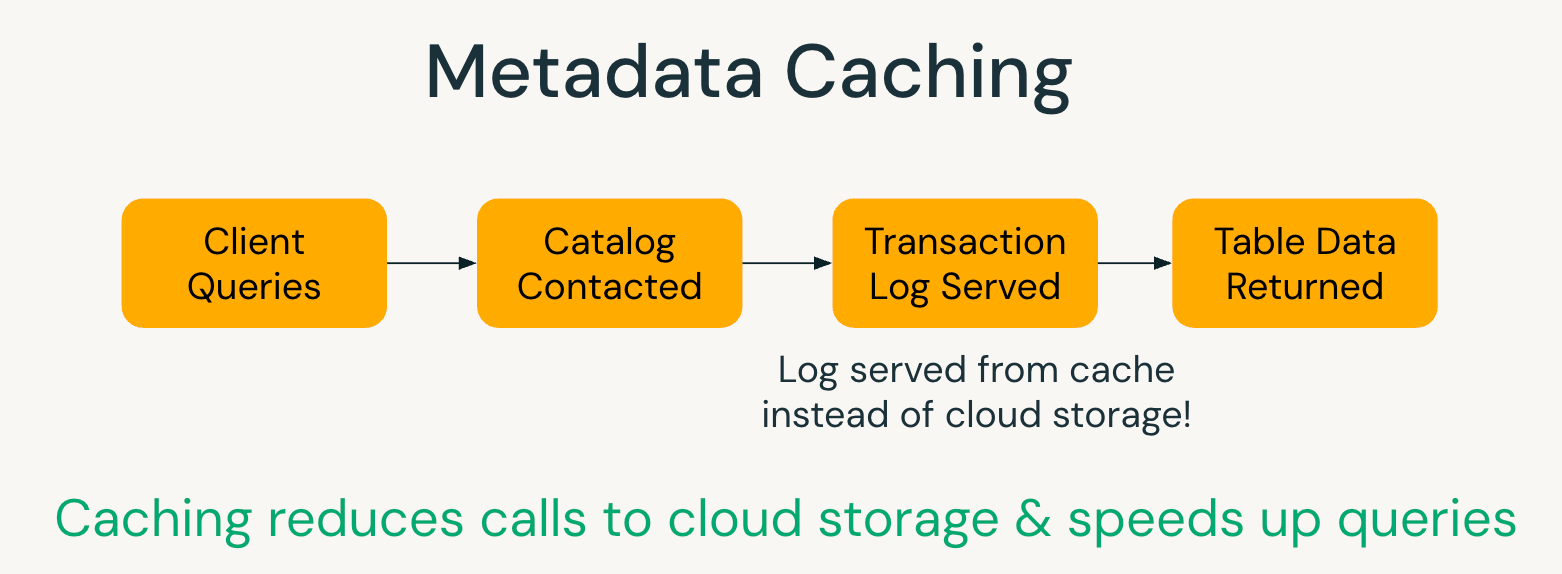
Mise en cache des métadonnées
Les tables gérées UC utilisent la mise en cache en mémoire des métadonnées de transaction pour réduire l'accès aux journaux de transaction basés sur le cloud. Cela réduit les coûts de calcul et améliore les performances de planification des requêtes. La fonctionnalité est exclusive aux tables gérées UC, où Databricks peut suivre toutes les écritures et garantir que les métadonnées mises en cache restent cohérentes avec l'état actuel.
Optimisation de la taille des fichiers
Databricks utilise l'IA pour compacter automatiquement les fichiers à des tailles optimales, en fonction des modèles appris de milliers de déploiements réels. Cette optimisation se produit lors de l'écriture des données et contribue à améliorer les performances des requêtes en réduisant la fragmentation des fichiers et la surcharge de lecture. [Lire la suite]

Ouvertes et interopérables par conception
Les tables gérées UC sont construites sur des formats ouverts comme Delta et Iceberg, permettant une large compatibilité avec l'écosystème de données moderne. Elles peuvent être accédées par n'importe quel moteur qui prend en charge ces formats, y compris Trino, DuckDB, Apache Spark™, Daft, et les outils intégrés au catalogue REST Iceberg, tels que Dremio.
L'accès sécurisé est rendu possible grâce aux API ouvertes et à la distribution de jetons d'authentification, permettant aux outils externes d'interagir avec les données gouvernées sans les dupliquer. Cela simplifie l'architecture et permet une source unique de vérité pour les charges de travail d'analyse et d'IA.
La prise en charge des écritures tierces s'étend également. En préversion privée, les tables gérées UC acceptent désormais les écritures des clients Delta non-Databricks, tels qu'Apache Spark, ce qui facilite l'intégration avec les frameworks de traitement externes tout en maintenant la gouvernance Unity Catalog.
Delta Sharing, le seul protocole de partage ouvert de l'industrie, améliore encore l'interopérabilité en permettant un accès sécurisé en lecture seule aux données sous-jacentes, même pour les destinataires n'utilisant pas Databricks. Ces capacités permettent d'étendre l'accès aux données gouvernées sur les plateformes, les partenaires et les applications.
Comme ces optimisations s'appliquent au niveau de la disposition des données, les gains de performance sont universels. Les outils externes bénéficient de la même disposition groupée, des fichiers compactés et des statistiques riches, ce qui se traduit par des requêtes plus rapides et des lectures plus efficaces, quel que soit le moteur.
Ce qui est prévu
Plusieurs nouvelles fonctionnalités seront bientôt disponibles pour rendre les tables gérées par UC encore plus puissantes et flexibles :
Observabilité au niveau de la table
Obtenez une visibilité sur les tables inutilisées, les fenêtres de rétention, les tendances de taille des tables et les métadonnées personnalisées, ce qui facilite la gestion des coûts et l'application des meilleures pratiques.
Périodes UNDROP configurables
Personnalisez la fenêtre de rétention pour les tables supprimées, y compris la prise en charge de la suppression immédiate pour réduire encore davantage les coûts de stockage.
Outils de réorganisation de schémas et de catalogues
Commandes pour déplacer des tables entre les catalogues et les schémas, aidant les équipes à maintenir les jeux de données logiquement organisés à mesure que les environnements évoluent.
Transactions multi-instructions et multi-tables (aperçu privé)
Prise en charge des validations atomiques sur plusieurs tables. Si une opération échoue, l'ensemble de la transaction est annulé, améliorant la fiabilité des opérations de données complexes.
Premiers pas avec les tables gérées par UC
Les tables gérées par UC sont activées par défaut et faciles à adopter, que vous créiez de nouvelles tables ou convertissiez des tables existantes.
Créer une nouvelle table gérée
Pour les nouvelles charges de travail, les tables gérées par UC sont créées sans avoir besoin de spécifier un emplacement de stockage. Databricks gère automatiquement le chemin d'accès aux données dans le stockage cloud détenu par le client :
CREATE OR REPLACE TABLE catalog.schema.my_managed_table
Convertir une table externe UC existante en table gérée
Les organisations qui cherchent à convertir leurs tables en tables gérées peuvent utiliser la commande suivante pour convertir des tables externes UC :
ALTER TABLE catalog.schema.my_external_table SET MANAGED
Consultez la documentation et demandez l'accès à l'aperçu public limité en utilisant ce formulaire.
Convertir des tables étrangères (non-UC)
Pour les équipes qui migrent depuis des types de tables étrangères, la conversion en tables gérées par UC est disponible en aperçu privé. Cela facilite la consolidation de la gouvernance et de l'optimisation sous Unity Catalog. Vous pouvez demander l'accès à l'aperçu limité en utilisant ce formulaire.
Essayer les fonctionnalités avancées en aperçu
Pour expérimenter des fonctionnalités telles que les écritures tierces dans les tables gérées, les transactions multi-tables ou la réorganisation de schémas, contactez votre équipe de compte Databricks pour rejoindre les programmes d'aperçu pertinents.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.