How Unity Catalog Managed Tables Automate Performance at Scale
Built-in AI optimizations deliver up to 50%+ cost savings and 20x faster queries—no manual tuning required
- Learn about the features that make Unity Catalog (UC) managed tables the standard best practice for data management
- Reduce costs by 50%+ and enhance query performance by 20x+ with Predictive Optimization on UC managed tables
- Save data engineering time with automatic, intelligent data optimizations that adapt to usage patterns
Unity Catalog (UC) managed tables combine strong governance with seamless interoperability across tools. Since the data sits in the customer-owned cloud storage, organizations retain full control over its physical location, while benefiting from Databricks’ built-in intelligence and automation.
Today, UC managed tables are the most commonly used table type in Databricks; two out of every three UC tables are managed. This adoption reflects its ability to simplify operations, reduce costs, and improve performance at scale.
With UC managed tables, organizations can be confident they are always using the latest table features. These tables are automatically upgraded, and unlike other table types, they understand usage patterns, allowing new capabilities to be enabled safely and incrementally, without manual intervention.
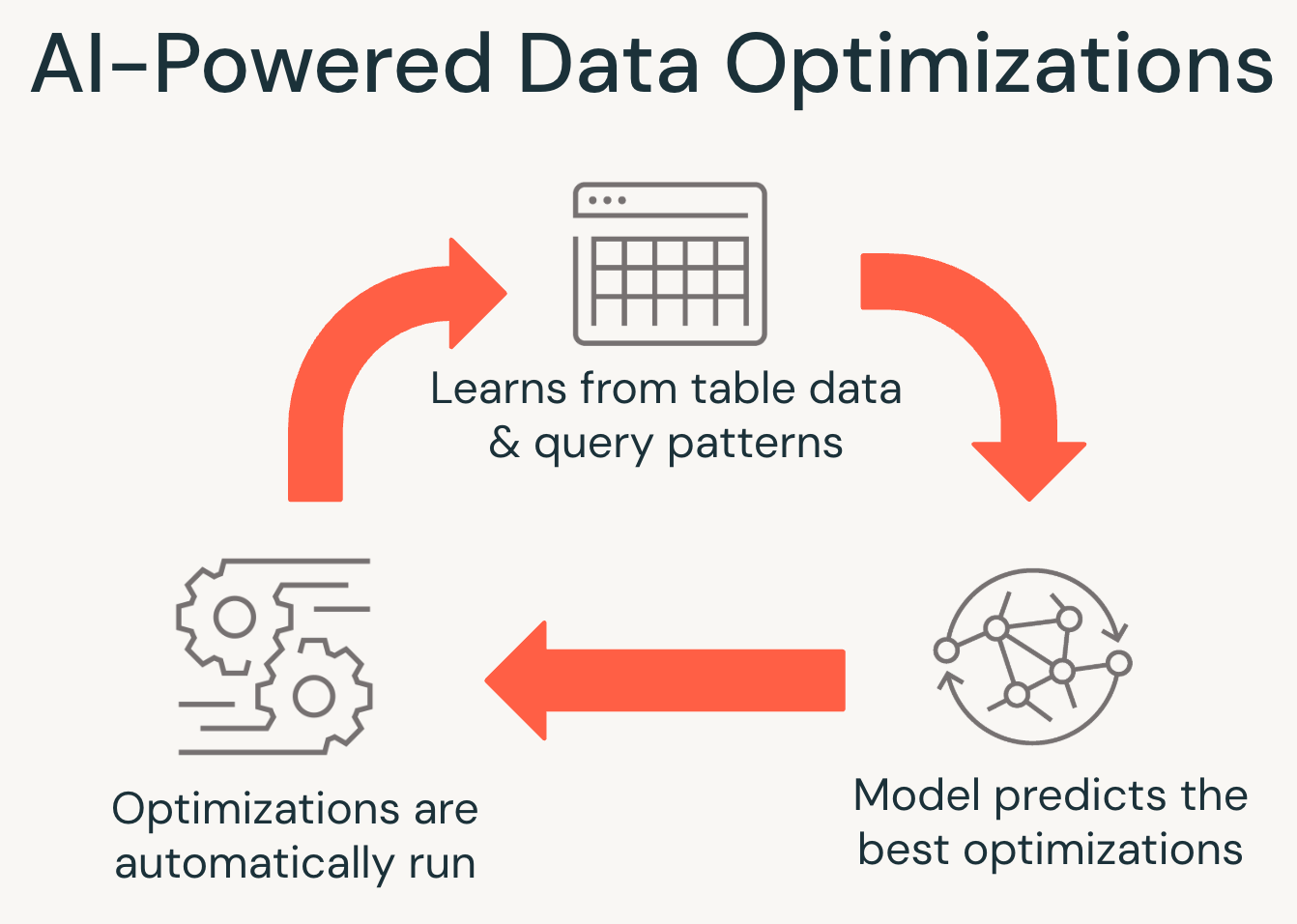
The structure of UC managed tables also enables advanced AI capabilities that weren’t possible before. Since all reads and writes route through Unity Catalog, Databricks can intelligently optimize data based on actual usage, improving query performance, reducing storage costs, and eliminating routine maintenance.
Key benefits include:
- Automatic upgrades with the latest features
- Self-maintenance with compaction, clustering, and vacuuming
- Storage and compute cost savings through intelligent optimization
- Secure access via Open APIs, even for non-Databricks clients
- Faster queries across all clients, not just in Databricks
In this blog, we will provide a deep dive into features that make UC managed tables effective, along with recent enhancements and a preview of what’s on the roadmap.
"Unity Catalog managed tables' automatic optimizations saved us over $1 million annually in storage costs while eliminating the need for tedious manual effort on a daily basis." —Abhinav Raghuvanshi, Associate Director of Data Engineering at Zepto
What are the benefits of Unity Catalog managed tables?
UC managed tables are optimized by default, with no manual tuning required. They continuously adapt based on query workloads to improve performance, reduce storage costs, and streamline lifecycle management.
UC managed tables also simplify operations with built-in features like automatic vacuuming, file compaction, and metadata caching. Because they’re built on open formats like Delta and Iceberg, UC managed tables integrate easily with third-party tools and engines.
Intelligent Optimizations Drive Cost and Performance Gains
UC managed tables apply a set of AI-driven techniques to deliver up to 50%+ cost savings and 20x+ faster queries:
Automatic Liquid Clustering
UC managed tables automatically cluster data based on observed query patterns, without requiring any manual configuration. In contrast, UC external tables require data engineers to run OPTIMIZE commands and manually define clustering keys. With managed tables, Predictive Optimization handles clustering dynamically, improving query performance and reducing storage costs without additional effort. [Read more]

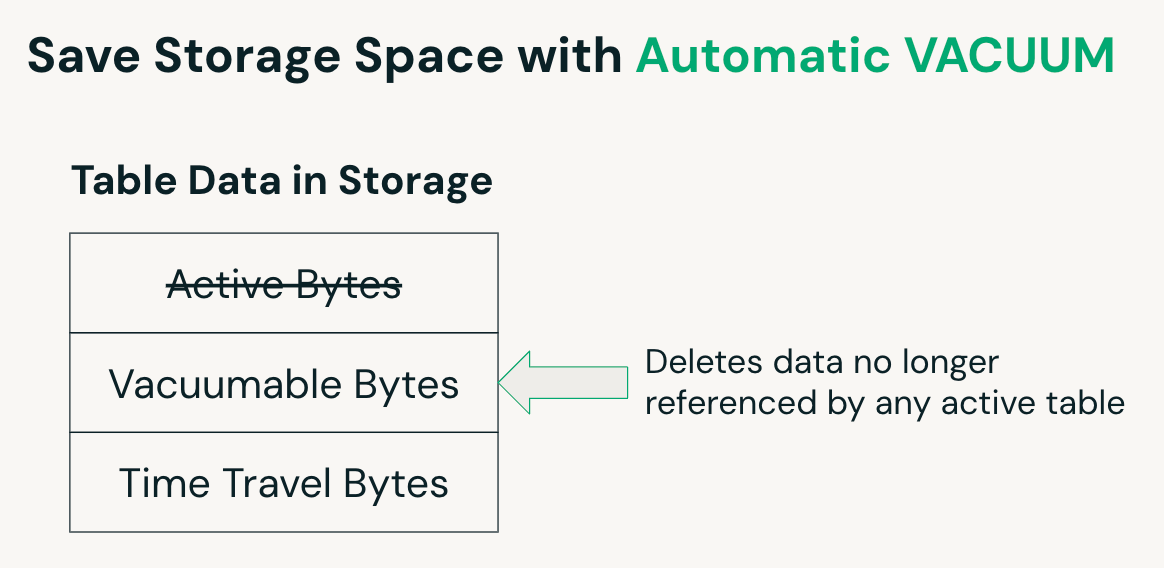
Automatic VACUUM
On UC managed tables, Predictive Optimization automatically identifies when a VACUUM operation is beneficial and schedules it accordingly. VACUUM removes files associated with deleted rows after a defined retention period, helping reduce storage usage. For UC-external tables, this process must be managed manually by running the VACUUM command.
Deferred DROP with Auto Cleanup
When a UC managed table is dropped, the underlying data in cloud storage is automatically deleted after 7 days, helping reduce storage costs and avoid orphaned files. In contrast, dropping a UC external table does not delete the data; users must manually remove the files from their storage bucket. If this step is missed, the data remains, leading to unnecessary storage usage. See the roadmap section for upcoming enhancements to this behavior.
Automatic Statistics Collection
UC managed tables automatically collect statistics that improve query performance through smarter data skipping and join planning. Key metrics, such as minimum and maximum column values, help the system identify and skip irrelevant files during query execution, reducing compute overhead. While UC external tables generate statistics on the first 32 columns by default, UC managed tables dynamically prioritize the columns most relevant to actual query workloads. [Read more]

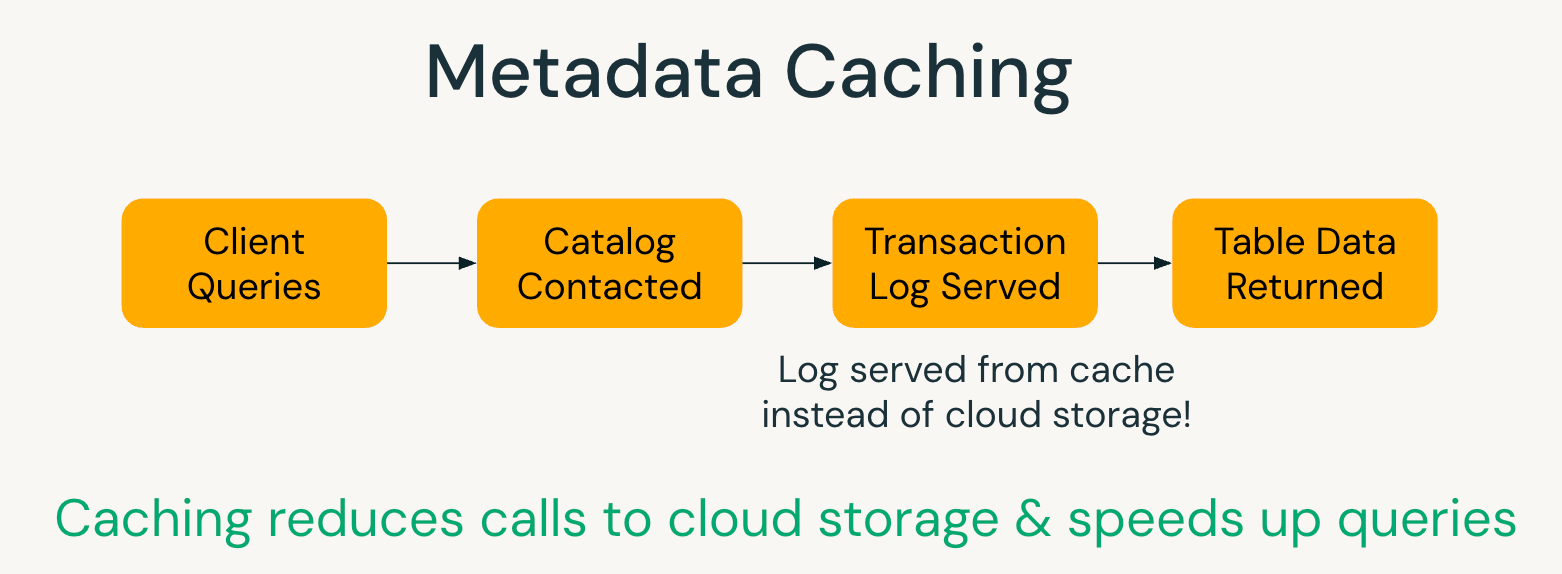
Metadata Caching
UC managed tables use in-memory caching of transaction metadata to reduce access to cloud-based transaction logs. This lowers compute costs and improves query planning performance. The feature is exclusive to UC managed tables, where Databricks can track all writes and ensure the cached metadata remains consistent with the current state.
File Size Optimization
Databricks uses AI to automatically compact files to optimal sizes, based on patterns learned from thousands of real-world deployments. This optimization occurs as data is written and helps improve query performance by reducing file fragmentation and scan overhead. [Read More]

Open and Interoperable by Design
UC managed tables are built on open formats like Delta and Iceberg, enabling broad compatibility across the modern data ecosystem. They can be accessed by any engine that supports these formats, including Trino, DuckDB, Apache Spark™, Daft, and tools integrated with the Iceberg REST catalog, such as Dremio.
Secure access is made possible through Open APIs and credential vending, allowing external tools to interact with governed data without duplicating it. This simplifies architecture and enables a single source of truth across analytics and AI workloads.
Support for third-party writes is also expanding. In Private Preview, UC managed tables now accept writes from non-Databricks Delta clients—such as Apache Spark—making it easier to integrate with external processing frameworks while maintaining Unity Catalog governance.
Delta Sharing, the industry’s only open sharing protocol, further enhances interoperability by allowing secure, read-only access to underlying data, even for recipients not using Databricks. These capabilities help extend governed data access across platforms, partners, and applications.
Because these optimizations apply at the data layout level, performance gains are universal. External tools benefit from the same clustered layout, compacted files, and rich statistics, resulting in faster queries and more efficient reads, no matter the engine.
What’s on the Roadmap
Several new features are coming soon that will make UC managed tables even more powerful and flexible:
Table-Level Observability
Gain visibility into unused tables, retention windows, table size trends, and custom metadata, making it easier to manage costs and enforce best practices.
Configurable UNDROP Periods
Customize the retention window for dropped tables, including support for immediate deletion to reduce storage costs even further.
Schema and Catalog Reorganization Tools
Commands to move tables across catalogs and schemas, helping teams keep datasets logically organized as environments evolve.
Multi-Statement and Multi-Table Transactions (Private Preview)
Support for atomic commits across multiple tables. If any operation fails, the entire transaction rolls back, improving reliability for complex data operations.
Getting Started with UC managed tables
UC managed tables are enabled by default and easy to adopt, whether creating new tables or converting existing ones.
Create a new managed table
For new workloads, UC managed tables are created without needing to specify a storage location. Databricks automatically manages the data path in customer-owned cloud storage:
CREATE OR REPLACE TABLE catalog.schema.my_managed_table
Convert an existing UC external table to managed
Organizations looking to convert to managed tables can use the following command to convert external UC tables:
ALTER TABLE catalog.schema.my_external_table SET MANAGED
View documentation and request access to the gated public preview using this form.
Convert foreign tables (non-UC)
For teams migrating from foreign table types, conversion to UC managed tables is available in Private Preview. This makes it easier to consolidate governance and optimization under Unity Catalog. You can request access to the gated preview using this form.
Try advanced features in preview
To experiment with features like third-party writes to managed tables, multi-table transactions, or schema reorganization, contact your Databricks account team to join relevant preview programs.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.