How Databricks improved query performance by up to 2.2x by automatically optimizing file sizes
An inside look at how Databricks constantly improves performance without sacrificing simplicity.
by Sirui Sun, Himanshu Raja, Vijayan Prabhakaran, Terry Kim, Bart Samwel, Rahul Mahadev, Rajesh Parangi Sharabhalingappa, Rahul Potharaju and Kam Cheung Ting
Optimizing tables has long been a necessary but complicated task for data engineers. One particularly thorny area has been getting to the optimal file sizes. Getting to the right file sizes for your tables unlocks significant performance improvements, but tackling this has traditionally required in-depth expertise and significant time investment.
Recently, we announced the Predictive I/O feature for Databricks SQL, which makes point lookups faster and more cost-effective. Building on that work, today we're excited to announce additional AI-powered capabilities that automatically optimize file sizes for Unity Catalog managed tables.
By learning from data collected from thousands of production deployments and determining file sizes behind the scenes, these updates result in notable query performance improvements without requiring any user intervention. The combination of AI-driven file size optimization and Predictive I/O results in significantly faster time-to-insight on Unity Catalog without the need for manual tuning.
Results
Starting early this year, these updates were rolled out for Unity Catalog Managed tables. If you're currently using Unity Catalog Managed Tables, you automatically get these improvements out-of-the-box - no configuration required. Soon, all Delta tables in Unity Catalog will get these optimizations.
Here's the before-and-after results when benchmarked on Databricks SQL:
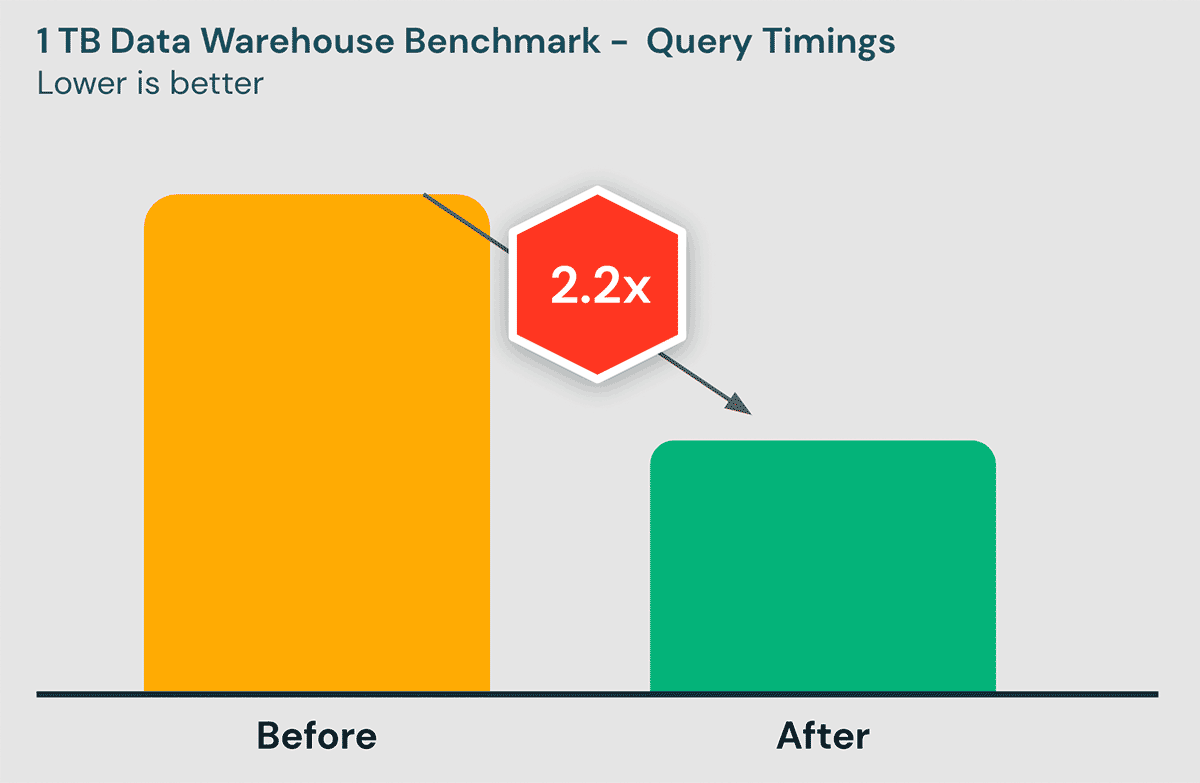
We took measures to ensure that these benchmarks were as realistic as possible:
- The benchmark was designed to be representative of customers' data warehousing workloads
- We use a 1 TB dataset because such tables are less likely to enjoy the benefits of customized tuning. Note however that the improvements should apply equally to larger tables as well.
- We incrementally ingest the dataset with small files, matching the common ingestion patterns we see across our customers.
The technical challenge of file size optimization
The size of the data files backing your Delta tables plays a key role in performance. If file sizes are too small, you end up with too many files, resulting in performance degradation due to processing overheads caused by metadata processing and API rate limits from cloud provider storage services. If your file sizes are too large, operations like task-level parallelism and data skipping become more difficult and expensive. Like Goldilocks, the challenge is getting to a file size that is just right.
Selecting the ideal file size is just half the battle. The other half is ensuring that your files are actually that size in practice. We found that across our customers' workloads, files were, on average, far too small - in fact, a large portion of files were <1MB!
Deep-dive: how Databricks automatically optimizes file sizes
Using the data collected from thousands of production deployments, in conjunction with rigorous experimentation, we built a model of "just right" file sizes, based on inputs like table size and read/write behavior. For example, our model found that for a typical customer table in the 1 TB size range, the ideal file size was between 64 - 100 MB.
Once our model determines the ideal file size, we took a multi-pronged approach to get actual file sizes to match the ideal. First, we improved how we write files. In partitioned tables, we shuffled data so that executors were writing to fewer, larger files. In unpartitioned tables, we found that we could coalesce tasks for larger files. And in both cases, we were careful to enable these only when the impact to write performance was negligible. Following our rollout, we've seen the average ingested file increase in size by 6x - getting much closer to the ideal.
Second, we created a background process that compacts too-small files into files that are just right. This method provides defense-in-depth, addressing files that were still too small despite our write improvements. Unlike the previous auto-compaction capability, this new capability runs asynchronously to avoid impact on write performance, runs only on your clusters' idle time, and is better at handling situations with concurrent writers. So far, we've run tens of millions of compactions, with each run compacting dozens files into one, on average.
Getting started
Nothing is needed to get started with these performance improvements. As long as your Delta tables meet the following requirements, you're already seeing the benefits of our AI-first advancements today!
- Using DB SQL or DBR 11.3 and later
- Using Unity Catalog Managed Tables (external table support coming soon)
With these improvements in place, you no longer have to worry about tuning for optimal file sizes. This is just one example of the many enhancements Databricks is implementing which leverage Databricks' data and AI capabilities to free up your time and energy so that you can focus on maximizing business value.
Join us at the Data + AI Summit for many more AI-powered announcements to come!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.