Comment utiliser Lakebase comme couche de données transactionnelle pour les applications Databricks
- Créez des applications complètes sur Databricks en utilisant Lakebase pour le stockage et Databricks Apps pour l'interface utilisateur.
- Suivez un exemple concret : Un outil de demande de congés qui stocke et met à jour les données dans Lakebase.
- Obtenez des instructions étape par étape : Configurez la base de données, connectez-la à votre application et créez le frontend.
Introduction
La création d'outils internes ou d'applications basées sur l'IA de manière « traditionnelle » plonge les développeurs dans un labyrinthe de tâches répétitives et sujettes aux erreurs. Tout d'abord, ils doivent configurer une instance Postgres dédiée, gérer la mise en réseau, les sauvegardes et la surveillance, puis passer des heures (ou des jours) à intégrer cette base de données au framework front-end qu'ils utilisent. En plus de cela, ils doivent écrire des flux d'authentification personnalisés, mapper des autorisations granulaires et maintenir ces contrôles de sécurité synchronisés entre l'interface utilisateur, la couche API et la base de données. Chaque composant d'application réside dans un environnement différent, d'un service cloud géré à une VM auto-hébergée. Cela oblige les développeurs à jongler avec des pipelines de déploiement, des variables d'environnement et des magasins d'identifiants disparates. Il en résulte une pile fragmentée où un seul changement, comme une migration de schéma ou un nouveau rôle, se répercute sur plusieurs systèmes, nécessitant des mises à jour manuelles, des tests approfondis et une coordination constante. Tout ce temps supplémentaire détourne les développeurs de la véritable valeur ajoutée : la création des fonctionnalités principales et de l'intelligence du produit.
Avec Databricks Lakebase et Databricks Apps, l'ensemble de la pile applicative se trouve au même endroit, à côté du lakehouse. Lakebase est une base de données Postgres entièrement gérée qui offre des lectures et des écritures à faible latence, intégrée aux mêmes tables du lakehouse sous-jacentes qui alimentent vos charges de travail d'analyse et d'IA. Databricks Apps fournit un runtime serverless pour l'interface utilisateur, avec une authentification intégrée, des autorisations fines et des contrôles de gouvernance qui sont automatiquement appliqués aux mêmes données que celles servies par Lakebase. Cela facilite la création et le déploiement d'applications qui combinent état transactionnel, analyse et IA sans avoir à assembler plusieurs plateformes, synchroniser des bases de données, répliquer des pipelines ou réconcilier des politiques de sécurité entre les systèmes.
Pourquoi Lakebase + Databricks Apps
Lakebase et Databricks Apps travaillent ensemble pour simplifier le développement full-stack sur la plateforme Databricks :
- Lakebase vous offre une base de données Postgres entièrement gérée avec des lectures, écritures et mises à jour rapides, ainsi que des fonctionnalités modernes comme le branching et la récupération à un instant T.
- Databricks Apps fournit le runtime serverless pour le frontend de votre application, avec une identité intégrée, un contrôle d'accès et une intégration avec Unity Catalog et d'autres composants du lakehouse.
En combinant les deux, vous pouvez créer des outils interactifs qui stockent et mettent à jour l'état dans Lakebase, accèdent aux données gouvernées dans le lakehouse et servent le tout via une interface utilisateur sécurisée et serverless, le tout sans gérer d'infrastructure séparée. Dans l'exemple ci-dessous, nous montrerons comment créer une application simple d'approbation de demandes de congés en utilisant cette configuration.
Démarrage : Créer une application transactionnelle avec Lakebase
Ce tutoriel montre comment créer une application Databricks simple qui aide les gestionnaires à examiner et approuver les demandes de congés de leur équipe. L'application est construite avec Databricks Apps et utilise Lakebase comme base de données backend pour stocker et mettre à jour les demandes.

Voici ce que la solution couvre :
- Provisionner une base de données Lakebase
Configurez une base de données OLTP Postgres serverless en quelques clics. - Créer une application Databricks
Créez une application interactive à l'aide d'un framework Python (comme Streamlit ou Dash) qui lit et écrit dans Lakebase. - Configurer le schéma, les tables et les contrôles d'accès
Créez les tables nécessaires et attribuez des autorisations fines à l'application en utilisant l'ID client de l'application. - Se connecter et interagir en toute sécurité avec Lakebase
Utilisez le SDK Databricks et SQLAlchemy pour lire et écrire en toute sécurité dans Lakebase depuis le code de votre application.
Le tutoriel est conçu pour vous permettre de démarrer rapidement avec un exemple minimal fonctionnel. Plus tard, vous pourrez l'étendre avec une configuration plus avancée.
Étape 1 : Provisionner Lakebase
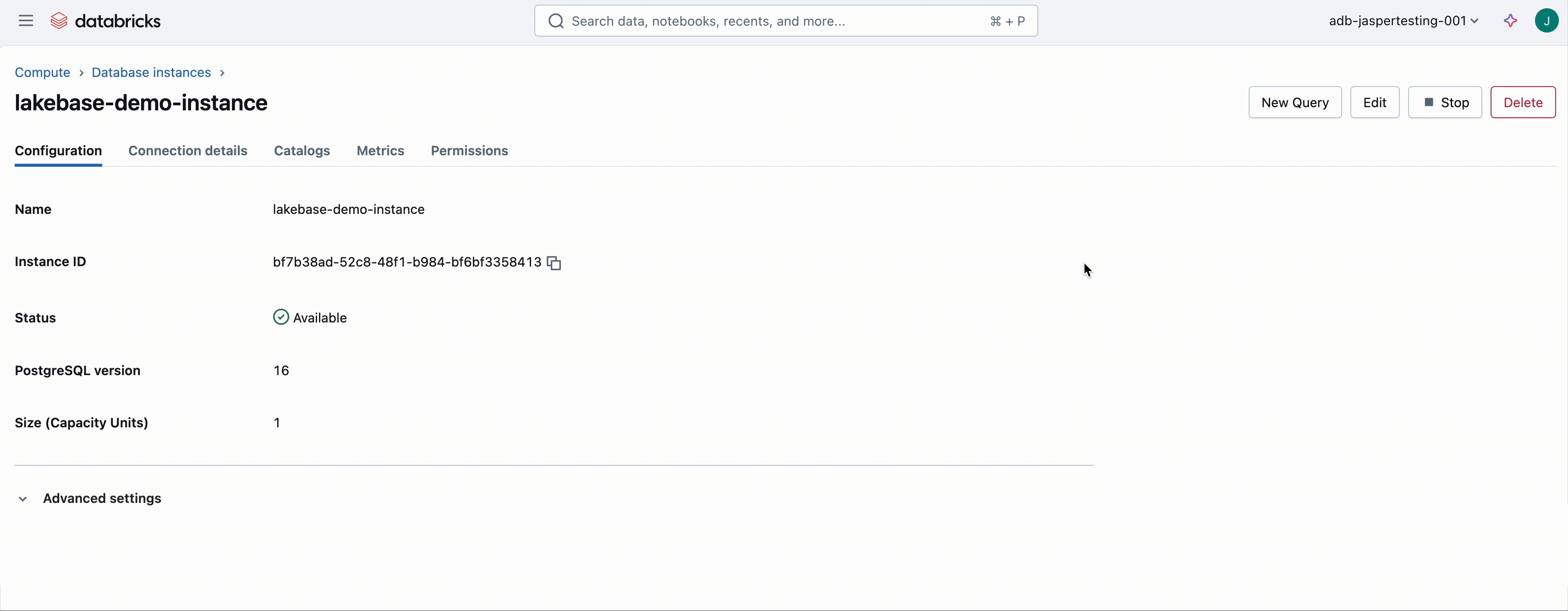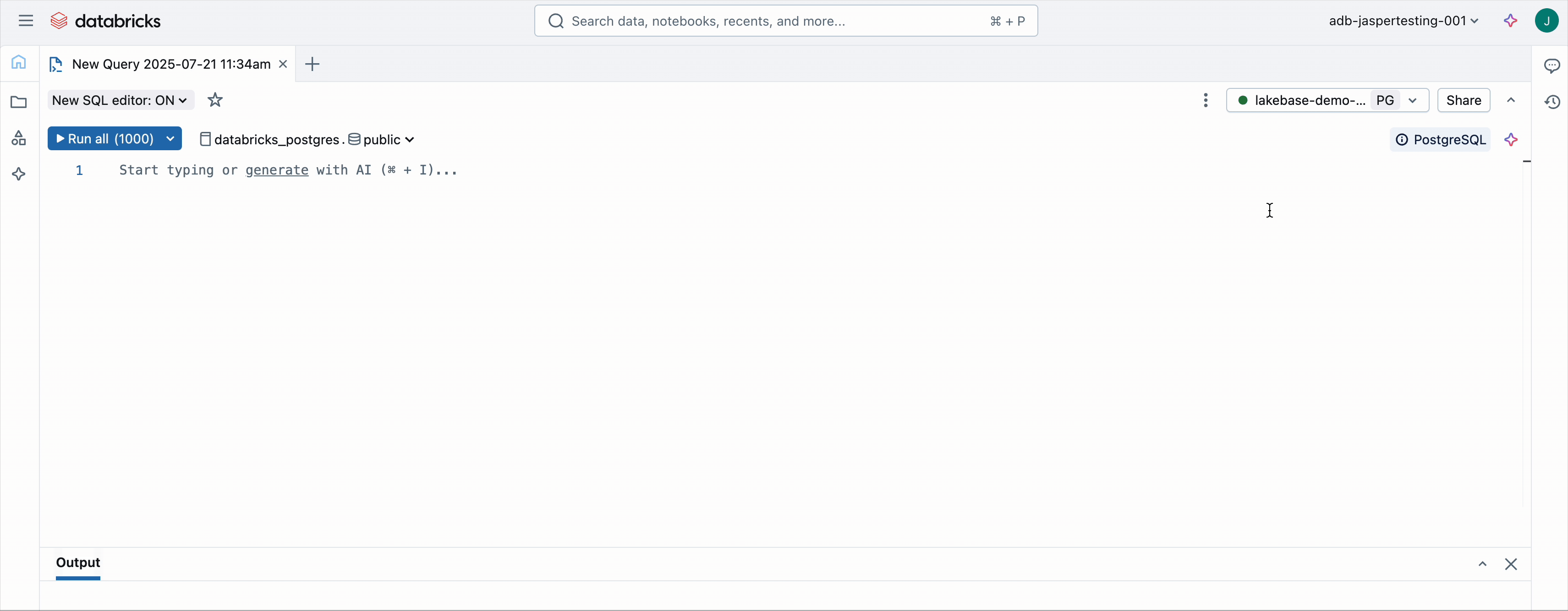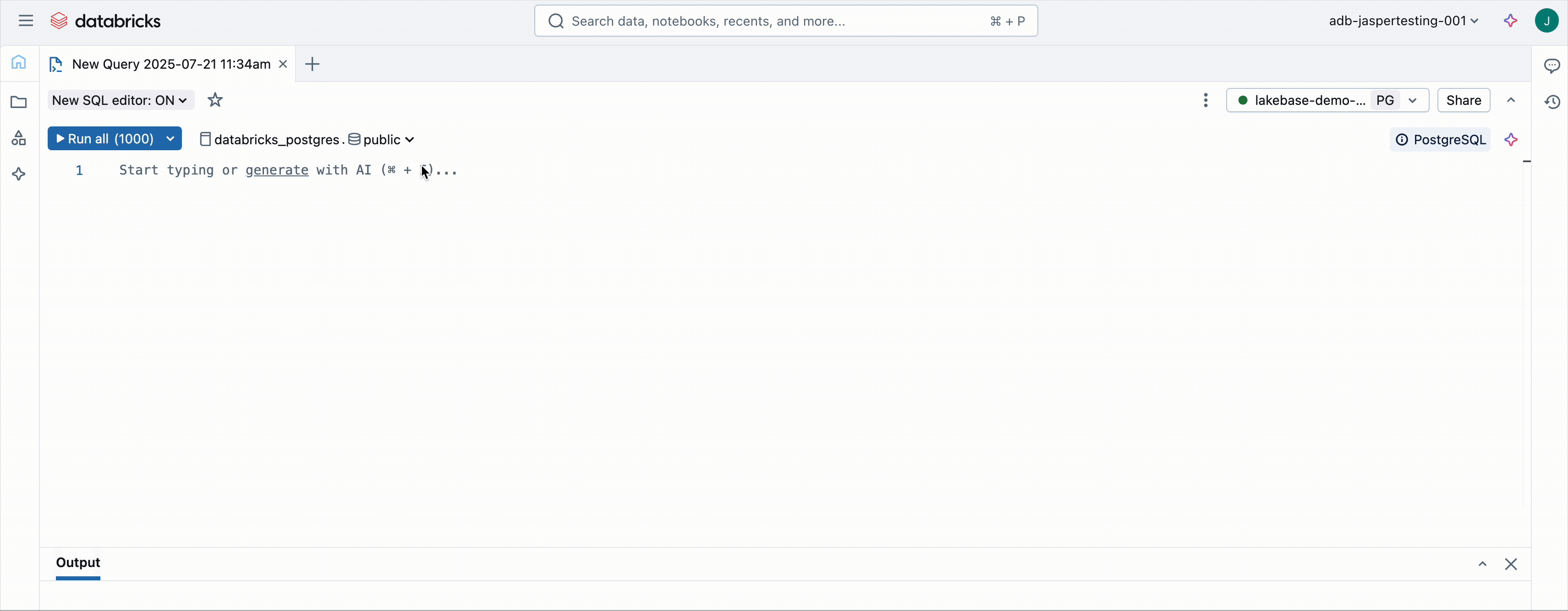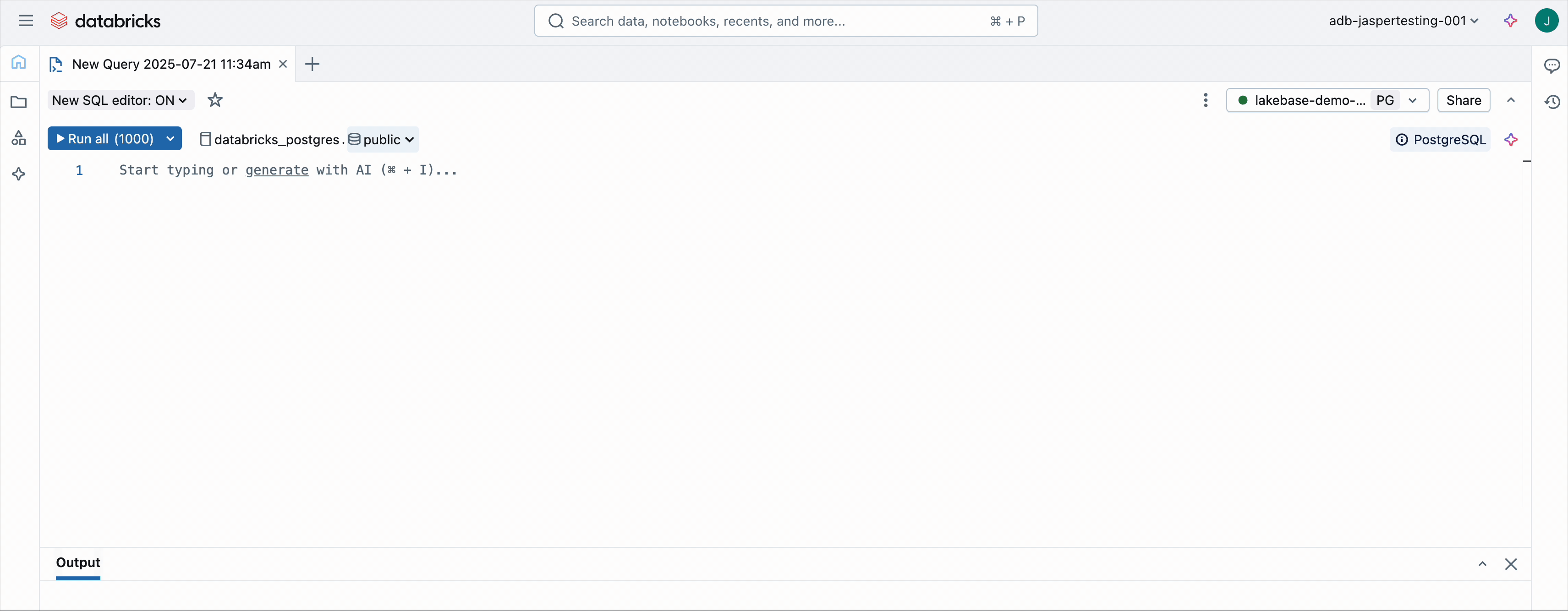
Avant de créer l'application, vous devrez créer une base de données Lakebase. Pour ce faire, allez dans l'onglet Compute, sélectionnez OLTP Database, et fournissez un nom et une taille. Cela provisionne une instance Lakebase serverless. Dans cet exemple, notre instance de base de données s'appelle lakebase-demo-instance.

Étape 2 : Créer une application Databricks et ajouter l'accès à la base de données
Maintenant que nous avons une base de données, créons l'application Databricks qui s'y connectera. Vous pouvez partir d'une application vierge ou choisir un modèle (par exemple, Streamlit ou Flask). Après avoir nommé votre application, ajoutez la Database comme ressource. Dans cet exemple, la base de données pré-créée databricks_postgres est sélectionnée.
L'ajout de la ressource Database permet automatiquement :
- D'accorder à l'application les privilèges CONNECT et CREATE
- De créer un rôle Postgres lié à l'ID client de l'application
Ce rôle sera utilisé plus tard pour accorder un accès au niveau de la table.

Étape 3 : Créer un schéma, une table et définir les autorisations
La base de données étant provisionnée et l'application connectée, vous pouvez maintenant définir le schéma et la table que l'application utilisera.
1. Récupérer l'ID client de l'application
Depuis l'onglet Environment de l'application, copiez la valeur de la variable DATABRICKS_CLIENT_ID. Vous en aurez besoin pour les instructions GRANT.
2. Ouvrir l'éditeur SQL de Lakebase
Accédez à votre instance Lakebase et cliquez sur New Query. Cela ouvre l'éditeur SQL avec le point de terminaison de la base de données déjà sélectionné.
3. Exécutez le SQL suivant :
Veuillez noter que bien que l'utilisation de l'éditeur SQL soit un moyen rapide et efficace d'effectuer ce processus, la gestion des schémas de base de données à grande échelle est mieux gérée par des outils dédiés qui prennent en charge la gestion des versions, la collaboration et l'automatisation. Des outils comme Flyway et Liquibase vous permettent de suivre les modifications de schéma, de vous intégrer aux pipelines CI/CD et de garantir que la structure de votre base de données évolue en toute sécurité parallèlement au code de votre application.
Étape 4 : Créer l'application
Une fois les autorisations en place, vous pouvez créer votre application. Dans cet exemple, l'application récupère les demandes de congés de Lakebase et permet à un responsable de les approuver ou de les rejeter. Les mises à jour sont renvoyées dans la même table.

Étape 5 : Se connecter en toute sécurité à Lakebase
Utilisez SQLAlchemy et le SDK Databricks pour connecter votre application à Lakebase avec une authentification sécurisée basée sur des jetons. Lorsque vous ajoutez la ressource Lakebase, PGHOST et PGUSER sont exposés automatiquement. Le SDK gère la mise en cache des jetons.
Étape 6 : Lire et mettre à jour les données
Les fonctions suivantes lisent et mettent à jour la table des demandes de congés :
Les extraits de code ci-dessus peuvent être utilisés en combinaison avec des frameworks tels que Streamlit, Dash et Flask pour extraire les données de Lakebase et les visualiser dans votre application. Pour vous assurer que toutes les dépendances nécessaires sont installées, ajoutez les packages requis à votre fichier requirements.txt. Les packages utilisés dans les extraits de code sont listés ci-dessous.
Extension du Lakehouse avec Lakebase
Lakebase ajoute des capacités transactionnelles au lakehouse en intégrant une base de données OLTP entièrement gérée directement dans la plateforme. Cela réduit le besoin de bases de données externes ou de pipelines complexes lors de la création d'applications nécessitant des lectures et des écritures.

Comme il est nativement intégré à Databricks, y compris la synchronisation des données, l'authentification des identités et la sécurité réseau — tout comme les autres actifs de données dans le lakehouse. Vous n'avez pas besoin d'ETL personnalisé ou d'ETL inversé pour déplacer des données entre les systèmes. Par exemple :
- Vous pouvez servir des fonctionnalités analytiques aux applications en temps réel (disponible aujourd'hui) en utilisant le Online Feature Store et les tables synchronisées.
- Vous pouvez synchroniser les données opérationnelles avec les tables Delta, par exemple pour l'analyse de données historiques (en aperçu privé).
Ces capacités facilitent la prise en charge de cas d'utilisation de niveau production tels que :
- Mise à jour de l'état dans les agents IA
- Gestion des workflows en temps réel (par exemple, approbations, routage des tâches)
- Alimentation de données en direct dans des systèmes de recommandation ou des moteurs de tarification
Lakebase est déjà utilisé dans diverses industries pour des applications telles que les recommandations personnalisées, les applications de chatbot et les outils de gestion de workflow.
Prochaines étapes
Si vous utilisez déjà Databricks pour l'analyse et l'IA, Lakebase facilite l'ajout d'interactivité en temps réel à vos applications. Avec la prise en charge des transactions à faible latence, la sécurité intégrée et une intégration étroite avec Databricks Apps, vous pouvez passer du prototype à la production sans quitter la plateforme.
Résumé
Lakebase fournit une base de données Postgres transactionnelle qui fonctionne de manière transparente avec Databricks Apps et offre une intégration facile avec les données du Lakehouse. Il simplifie le développement d'applications de données et d'IA full-stack en éliminant le besoin de systèmes OLTP externes ou d'étapes d'intégration manuelles.
Dans cet exemple, nous avons montré comment :
- Configurer une instance Lakebase et configurer l'accès
- Créer une Databricks App qui lit et écrit dans Lakebase
- Utiliser une authentification sécurisée basée sur des jetons avec une configuration minimale
- Construire une application de base pour gérer les demandes de congés en utilisant Python et SQL
Lakebase est maintenant en aperçu public. Vous pouvez l'essayer dès aujourd'hui directement depuis votre espace de travail Databricks. Pour plus de détails sur l'utilisation et la tarification, consultez la documentation Lakebase et Apps.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.