Comment nous déboguons des milliers de bases de données avec l'IA chez Databricks
Leçons tirées de la construction d'une plateforme de débogage de bases de données assistée par IA
par Annie Zhou, Madhav Ramesh et A Kishore Kumar
- Chez Databricks, nous gérons des milliers d'instances OLTP dans des centaines de régions sur AWS, Azure et GCP.
- Nous avons construit une plateforme agentique qui unifie les métriques, les outils et l'expertise pour aider nos ingénieurs à gérer leurs bases de données à cette échelle.
- Cette plateforme agentique est maintenant utilisée dans toute l'entreprise, réduisant le temps de débogage jusqu'à 90 % et la courbe d'apprentissage pour l'exploitation de notre infrastructure.
Chez Databricks, nous avons remplacé les opérations manuelles de base de données par l'IA, réduisant le temps passé au débogage jusqu'à 90 %.
Notre agent IA interprète, exécute et débogue en récupérant les métriques et journaux clés, et en corrélant automatiquement les signaux. Il fonctionne sur une flotte de bases de données déployées sur chaque cloud majeur et dans presque chaque région cloud.
Cette nouvelle capacité d'agent a permis aux ingénieurs de répondre couramment à des questions en langage naturel sur la santé et les performances de leur service, sans avoir à contacter les ingénieurs d'astreinte des équipes de stockage.
Ce qui a commencé comme un petit projet de hackathon pour simplifier le flux d'investigation a depuis évolué en une plateforme intelligente adoptée par toute l'entreprise. Voici notre parcours.
Avant l'IA : Tout fonctionnait, mais rien ne fonctionnait ensemble
Lors d'une enquête typique sur un incident MySQL, un ingénieur aurait souvent
- Vérifié les métriques dans Grafana
- Basculé vers un tableau de bord Databricks pour comprendre la charge de travail du client
- Exécuté des commandes CLI pour inspecter l'état InnoDB, un instantané de l'état interne de MySQL contenant des informations telles que l'historique des transactions, les opérations d'E/S et les détails de blocage
- S'est connecté à une console cloud pour télécharger les journaux de requêtes lentes
Chaque outil fonctionnait bien individuellement, mais ensemble, ils ne parvenaient pas à former un flux de travail cohérent ou à fournir une vision de bout en bout. Un ingénieur MySQL expérimenté pouvait assembler une hypothèse en naviguant entre les onglets et les commandes dans la bonne séquence ; cependant, cela consomme un budget SLO et du temps précieux. Un ingénieur plus récent ne savait souvent pas par où commencer.
Ironiquement, cette fragmentation de nos outils internes reflétait le défi même que Databricks aide nos clients à surmonter.
La plateforme Databricks Data Intelligence Platform unifie les données, la gouvernance et l'IA, permettant aux utilisateurs autorisés de comprendre leurs données et d'agir sur celles-ci. En interne, nos ingénieurs ont besoin de la même chose : une plateforme unifiée qui consolide les données et les flux de travail qui sous-tendent notre infrastructure. Avec cette base, nous pouvons appliquer l'intelligence en utilisant l'IA pour interpréter les données et guider les ingénieurs vers la prochaine étape appropriée.
Notre parcours : du Hackathon aux Agents Intelligents
Nous n'avons pas commencé par une initiative importante de plusieurs trimestres. Au lieu de cela, nous avons testé l'idée lors d'un hackathon à l'échelle de l'entreprise. En deux jours, nous avons construit un prototype simple qui a unifié quelques métriques et tableaux de bord de base de données essentiels en une seule vue. Ce n'était pas parfait, mais cela a immédiatement amélioré les flux de travail d'investigation de base. Cela a établi notre principe directeur : avancer rapidement et rester obsédé par le client.
Construire des Plateformes avec une Obsession Client
Avant d'écrire plus de code, nous avons interrogé les équipes de service pour comprendre leurs points faibles en matière de débogage. Les thèmes étaient cohérents : les ingénieurs juniors ne savaient pas par où commencer, et les ingénieurs seniors trouvaient les outils fragmentés et encombrants.
Pour constater la douleur de première main, nous avons suivi des sessions d'astreinte et observé les ingénieurs déboguer des problèmes en temps réel. Trois schémas se sont démarqués :
- Outils fragmentés
Les ingénieurs jonglaient entre les tableaux de bord, les CLIs et les étapes manuelles pour l'investigation et les opérations comme les redémarrages ou les restaurations. Chaque outil fonctionnait isolément, mais le manque d'intégration rendait le flux de travail lent et sujet aux erreurs. - Temps perdu à recueillir du contexte
La majeure partie du travail consistait à déterminer ce qui avait changé, à quoi ressemblait la « normale », et qui avait le bon contexte pour aider, mais pas à réellement atténuer l'incident. - Instructions peu claires sur l'atténuation sûre
Pendant les incidents, les ingénieurs n'étaient souvent pas sûrs des actions qui étaient sûres ou efficaces. Sans runbooks clairs ou automatisation, ils se rabattaient sur des investigations longues ou attendaient des experts.
Avec le recul, les post-mortems révélaient rarement cette lacune : les équipes ne manquaient pas de données ou d'outils ; elles manquaient de débogage intelligent pour interpréter le flot de signaux et les guider vers des actions sûres et efficaces.
Itérer vers l'Intelligence
Nous avons commencé petit, avec l'investigation de base de données comme premier cas d'utilisation. Notre v1 était un flux de travail agentique statique qui suivait une procédure opérationnelle standard de débogage, mais ce n'était pas efficace — les ingénieurs voulaient un rapport de diagnostic avec des informations immédiates, pas une checklist manuelle.
Nous avons réorienté notre attention sur l'obtention des bonnes données et la superposition de l'intelligence. Cette stratégie a conduit à la détection d'anomalies, qui a mis en évidence les bonnes anomalies, mais n'a toujours pas fourni les prochaines étapes claires.
La véritable percée est venue avec un assistant de chat qui code les connaissances de débogage, répond aux questions de suivi et transforme les investigations en un processus interactif. Cela a transformé la façon dont les ingénieurs déboguent les incidents de bout en bout.
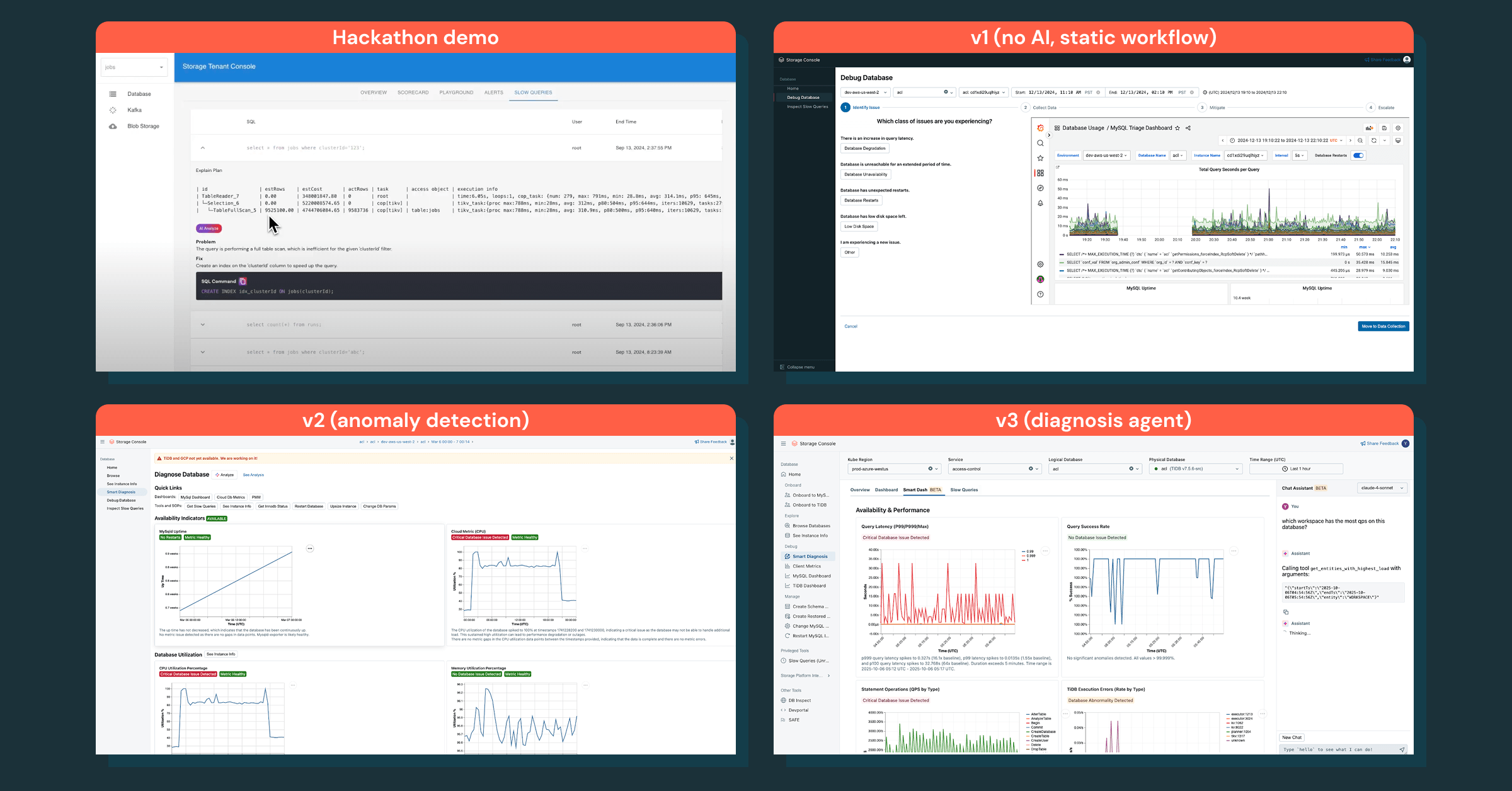
Une Fondation : Abstraction et Centralisation
En prenant du recul, nous avons réalisé que si notre cadre existant pouvait unifier les flux de travail et les données dans une seule interface, notre écosystème n'était pas conçu pour que l'IA raisonne sur notre paysage opérationnel. Tout agent devrait gérer la logique spécifique à la région et au cloud. Et sans contrôles d'accès centralisés, il deviendrait soit trop restrictif pour être utile, soit trop permissif pour être sûr.
Ces problèmes sont particulièrement difficiles à résoudre chez Databricks, car nous exploitons des milliers d'instances de bases de données dans des centaines de régions, huit domaines réglementaires et trois clouds. Sans une base solide qui abstrait les différences de cloud et de réglementation, l'intégration de l'IA se heurterait rapidement à un ensemble d'obstacles inévitables :
- Fragmentation du contexte : Les données de débogage se trouvaient à différents endroits, ce qui rendait difficile pour un agent de construire une image cohérente.
- Limites de gouvernance floues : Sans autorisation centralisée et application des politiques, il devient difficile de s'assurer que l'agent (et les ingénieurs) restent dans les bonnes permissions.
- Boucles d'itération lentes : Des abstractions incohérentes rendent difficile le test et l'évolution du comportement de l'IA, ralentissant considérablement l'itération au fil du temps.
Pour rendre le développement de l'IA sûr et évolutif, nous nous sommes concentrés sur le renforcement des fondations de la plateforme autour de trois principes :
- Architecture shardée « central-first », où une instance Storex globale coordonne les shards régionaux, fournissant une interface unique tout en gardant les données sensibles locales et conformes.
- Contrôle d'accès granulaire, appliqué aux niveaux de l'équipe, des ressources et des RPC, garantissant que les ingénieurs et les agents opèrent en toute sécurité dans les bonnes permissions.
- Orchestration unifiée, où notre plateforme intègre les services d'infrastructure existants, permettant des abstractions cohérentes entre les clouds et les régions.
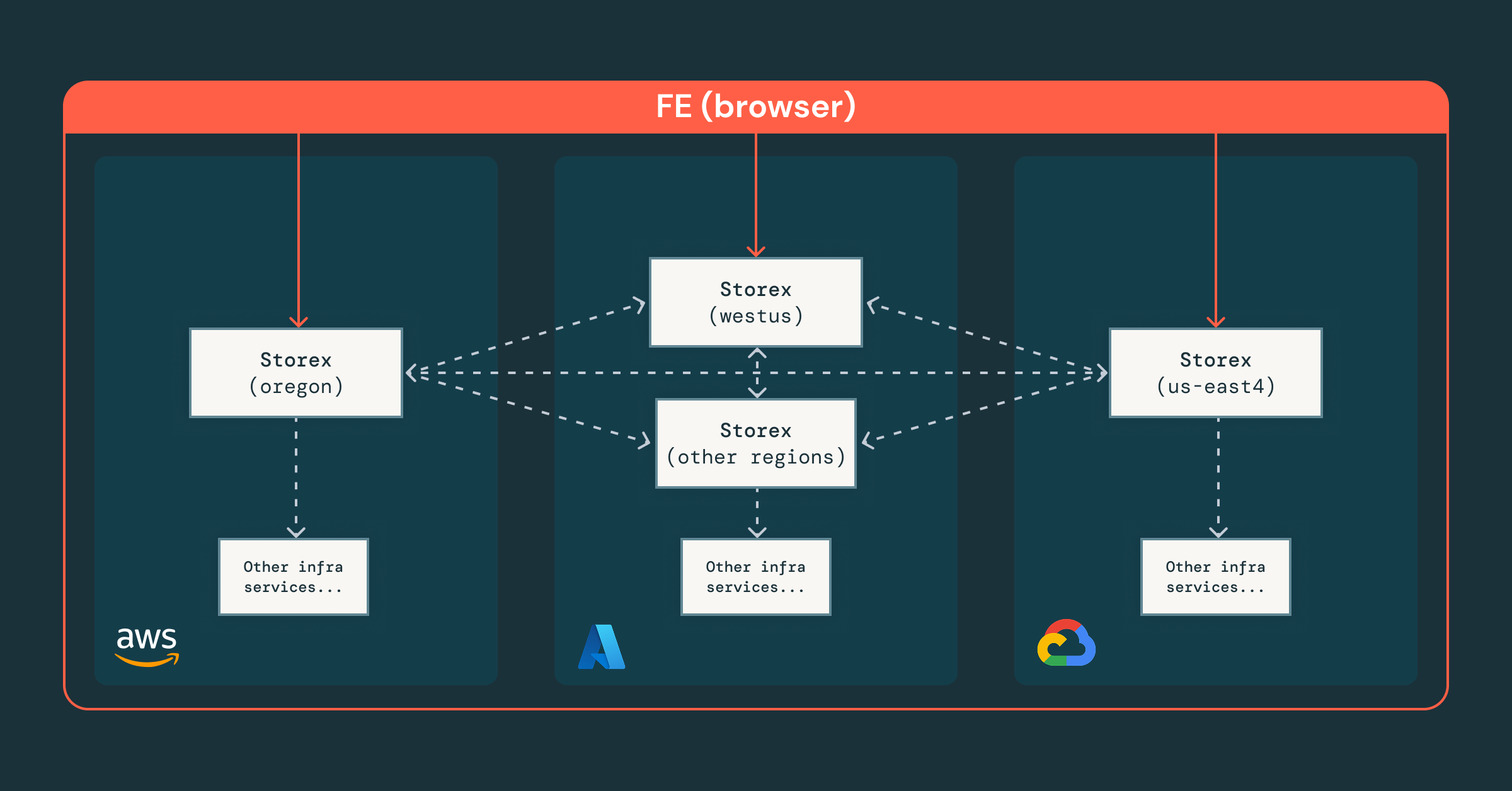
Avec les données et le contexte centralisés, l'étape suivante est devenue claire : comment rendre la plateforme non seulement unifiée, mais intelligente ?
De la Visibilité à l'Intelligence
Avec une base unifiée en place, la mise en œuvre et l'exposition de fonctionnalités telles que la récupération des schémas de base de données, des métriques ou des journaux de requêtes lentes à l'agent IA étaient simples. En quelques semaines, nous avons construit un agent capable d'agréger des informations de base de données, de raisonner à leur sujet et de les présenter à l'utilisateur.
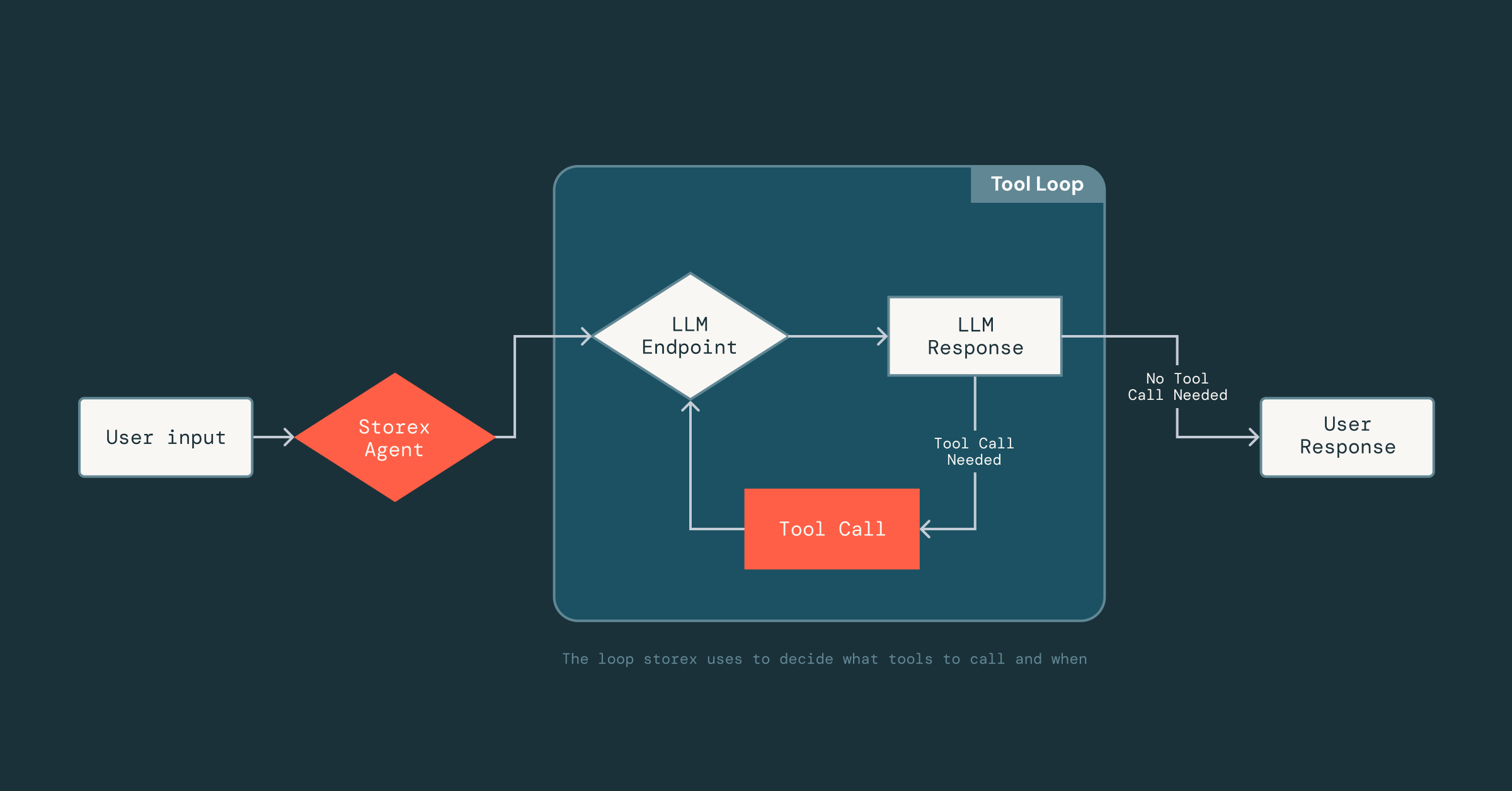
Maintenant, la partie difficile était de rendre l'agent fiable : étant donné que les LLM ne sont pas déterministes, nous ne savions pas comment il réagirait aux outils, aux données et aux invites auxquels il avait accès. Obtenir cela correctement a nécessit�é beaucoup d'expérimentation pour comprendre quels outils étaient efficaces et quel contexte inclure (ou exclure) dans les invites.
Pour permettre cette itération rapide, nous avons construit un framework léger inspiré des technologies d'optimisation de prompts de MLflow qui exploite DsPy, qui découple le prompting de l'implémentation des outils. Les ingénieurs peuvent définir des outils comme des classes Scala normales et des signatures de fonctions, et simplement ajouter une courte docstring décrivant l'outil. À partir de là, le LLM peut déduire le format d'entrée de l'outil, la structure de sortie et comment interpréter les résultats. Ce découplage nous permet d'avancer rapidement : nous pouvons itérer sur les prompts ou échanger des outils dans et hors de l'agent sans changer constamment l'infrastructure sous-jacente qui gère le parsing, les connexions LLM ou l'état de la conversation.
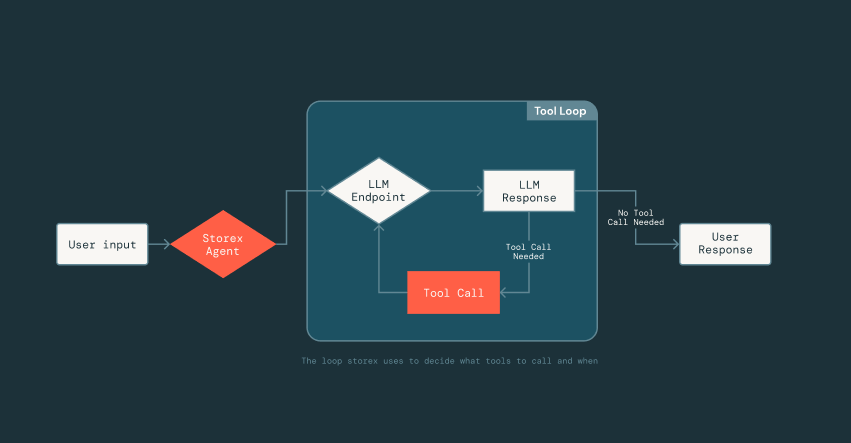{kind=link}
Au fur et à mesure de nos itérations, comment prouver que l'agent s'améliore sans introduire de régressions ? Pour résoudre ce problème, nous avons créé un framework de validation qui capture des instantanés de l'état de production et les rejoue à travers l'agent, en utilisant un LLM « juge » séparé pour évaluer les réponses en termes de précision et d'utilité à mesure que nous modifions les prompts et les outils.
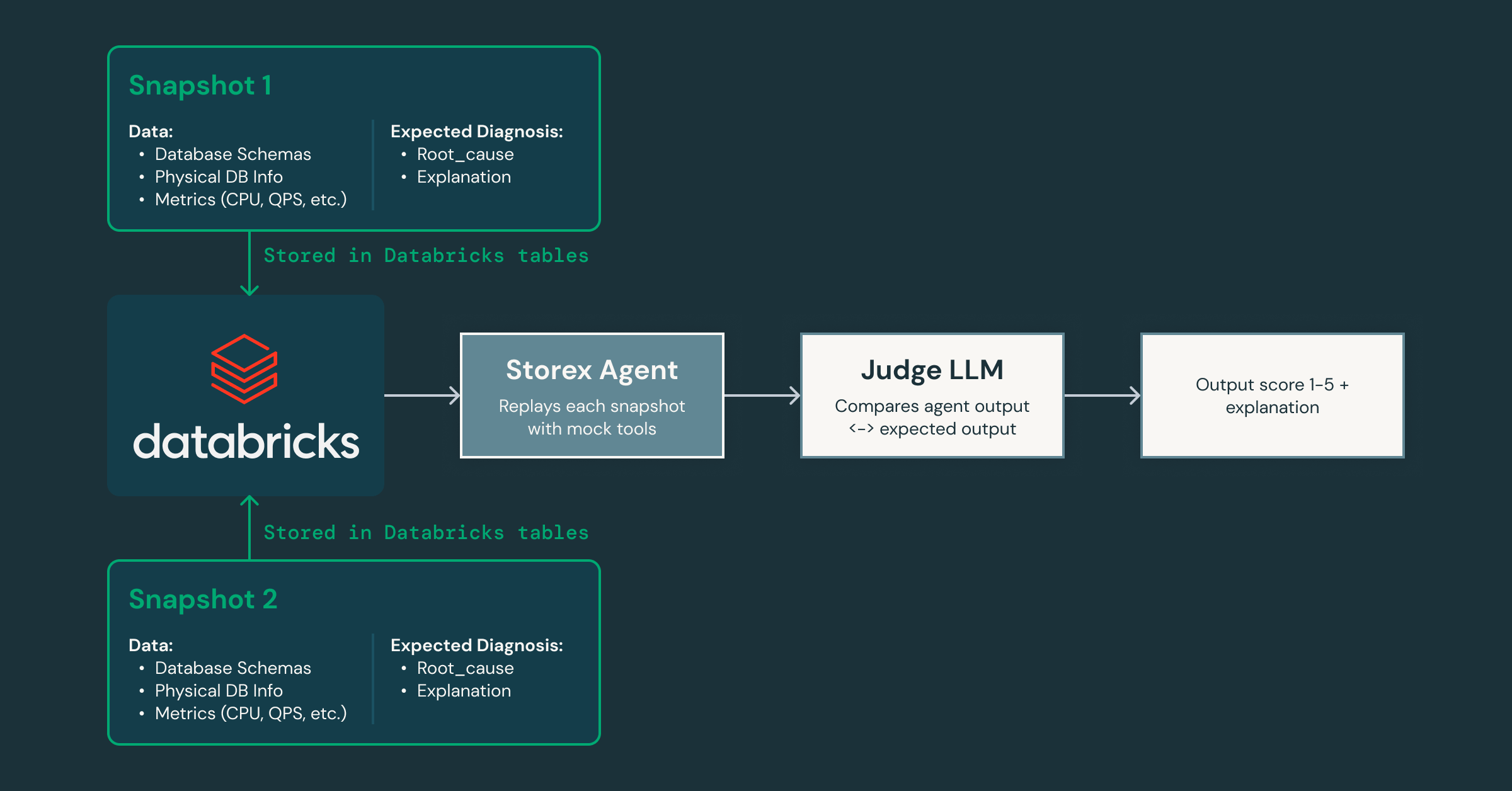
Comme ce framework nous permet d'itérer rapidement, nous pouvons facilement créer des agents spécialisés pour différents domaines : l'un axé sur les problèmes de système et de base de données, un autre sur les modèles de trafic côté client, et ainsi de suite. Cette décomposition permet à chaque agent de développer une expertise approfondie dans son domaine tout en collaborant avec d'autres pour fournir une analyse plus complète des causes profondes. Elle ouvre également la voie à l'intégration d'agents IA dans d'autres parties de notre infrastructure, au-delà des bases de données.
Avec à la fois les connaissances expertes et le contexte opérationnel codifiés dans son raisonnement, notre agent peut extraire des informations significatives et guider activement les ingénieurs à travers les investigations. En quelques minutes, il met en évidence les logs et les métriques pertinents que les ingénieurs n'auraient peut-être pas envisagé d'examiner. Il relie les symptômes entre les couches, comme l'identification de l'espace de travail générant une charge inattendue et la corrélation des pics d'IOPS avec des migrations de schéma récentes. Il explique même la cause et l'effet sous-jacents, et recommande les prochaines étapes pour l'atténuation.
Ensemble, ces éléments marquent notre passage de la visibilité à l'intelligence. Nous sommes passés de la visibilité des outils et des métriques à une couche de raisonnement qui comprend nos systèmes, applique les connaissances expertes et guide les ingénieurs vers des atténuations sûres et efficaces. C'est une base sur laquelle nous pouvons continuer à construire, non seulement pour les bases de données, mais aussi pour la manière dont nous opérons l'infrastructure dans son ensemble.
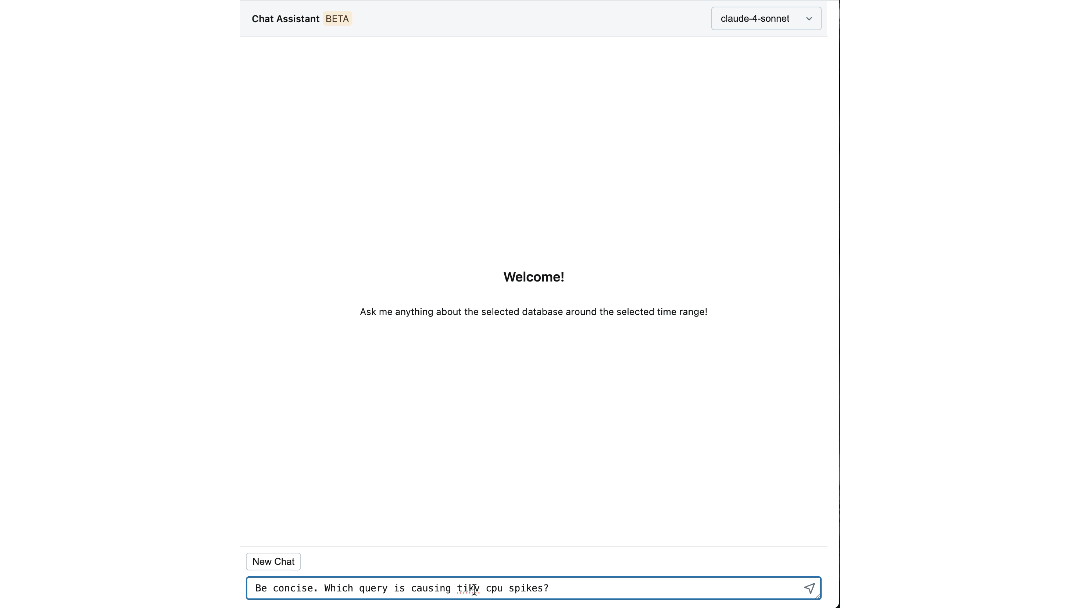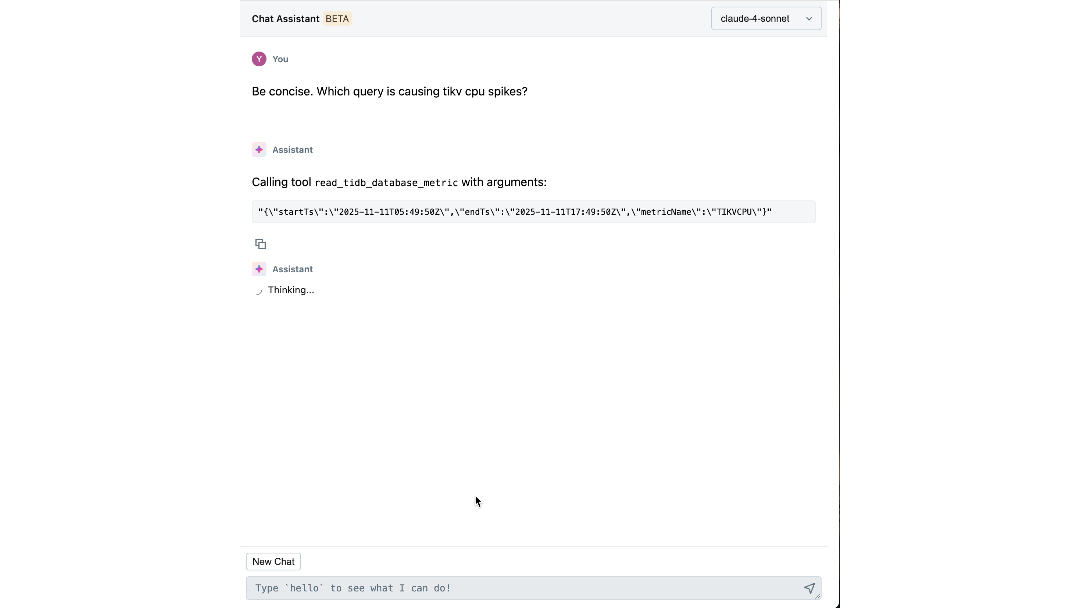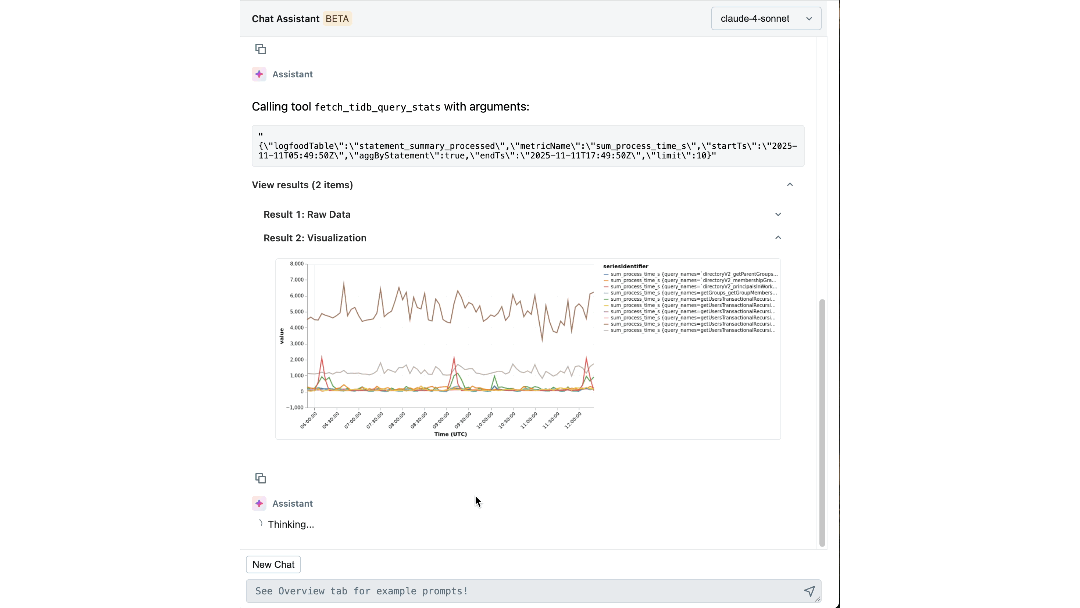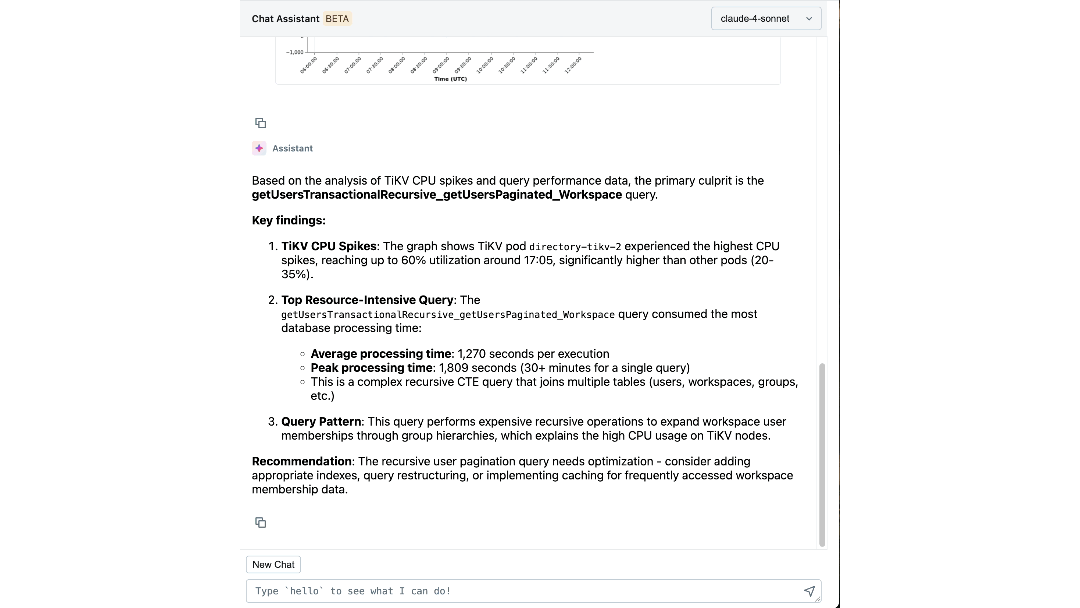
L'impact : Redéfinir notre façon de construire et d'opérer à grande échelle
La plateforme a changé la façon dont les ingénieurs Databricks interagissent avec leur infrastructure. Les étapes individuelles qui nécessitaient auparavant de passer d'un tableau de bord à l'autre, de CLI et de SOP peuvent maintenant être facilement répondues par notre assistant de chat, réduisant le temps passé jusqu'à 90 %.
La courbe d'apprentissage de notre infrastructure pour les nouveaux ingénieurs a également chuté de façon spectaculaire. Les nouveaux arrivants sans aucun contexte peuvent maintenant démarrer rapidement une investigation de base de données en moins de 5 minutes, ce qui aurait été presque impossible auparavant. Et nous avons reçu d'excellents retours depuis le lancement de cette plateforme :
L'assistant de base de données me fait vraiment gagner beaucoup de temps, je n'ai pas besoin de me souvenir où se trouvent tous mes tableaux de bord de requêtes. Je peux simplement lui demander quel espace de travail génère la charge. Meilleur outil jamais vu !—Yuchen Huo, Staff Engineer
Je suis un utilisateur assidu et je n'arrive pas à croire que nous vivions auparavant sans lui. Le niveau de finition et d'utilité est très impressionnant. Merci l'équipe, c'est un changement majeur dans l'expérience développeur.—Dmitriy Kunitskiy, Staff Engineer
J'aime particulièrement la façon dont nous apportons des informations alimentées par l'IA au débogage des problèmes d'infrastructure. J'apprécie à quel point l'équipe a été avant-gardiste dans la conception de cette console dès le départ.—Ankit Mathur, Senior Staff Engineer
Architecturalement, la plateforme pose les bases de la prochaine évolution : les opérations de production assistées par l'IA. Avec les données, le contexte et les garde-fous unifiés, nous pouvons maintenant explorer comment l'agent peut aider aux restaurations, aux requêtes de production et aux mises à jour de configuration : la prochaine étape vers un flux de travail opérationnel assisté par l'IA.
Mais l'impact le plus significatif n'a pas été seulement la réduction du travail pénible ou l'accélération de l'intégration : ce fut un changement d'état d'esprit. Notre objectif est passé de l'architecture technique aux parcours utilisateurs critiques (CUJ) qui définissent la façon dont les ingénieurs expérimentent nos systèmes. Cette approche centrée sur l'utilisateur est ce qui permet à nos équipes d'infrastructure de créer des plateformes sur lesquelles nos ingénieurs peuvent construire des produits gagnants dans leur catégorie.
Points à retenir
Au final, notre parcours s'est résumé à trois points :
- L'itération rapide est essentielle au développement d'agents : Les agents s'améliorent grâce à l'expérimentation rapide, la validation et le raffinement. Notre framework inspiré de DsPy a permis cela en nous permettant d'évoluer rapidement les prompts et les outils.
- La vitesse d'itération est limitée par la fondation sous-jacente : Les données unifiées, les abstractions cohérentes et le contrôle d'accès granulaire ont supprimé nos plus grands goulots d'étranglement, rendant la plateforme fiable, évolutive et prête pour l'IA.
- La vitesse n'a d'importance que lorsqu'elle a la bonne direction : Nous n'avons pas entrepris de construire une plateforme d'agents. Chaque itération a simplement suivi les retours des utilisateurs et nous a rapprochés de la solution dont les ingénieurs avaient besoin.
La construction de plateformes internes est trompeusement difficile. Même au sein de la même entreprise, les équipes produit et plateforme opèrent sous des contraintes très différentes. Chez Databricks, nous comblons cet écart en construisant avec une obsession client, en simplifiant par des abstractions et en améliorant par l'intelligence, en traitant nos clients internes avec le même soin et la même rigueur que nous apportons à nos clients externes.
Rejoignez-nous
Alors que nous regardons vers l'avenir, nous sommes impatients de continuer à repousser les limites de la façon dont l'IA peut façonner les systèmes de production et rendre l'infrastructure complexe sans effort. Si vous êtes passionné par la construction de la prochaine génération de plateformes internes alimentées par l'IA, rejoignez-nous !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.