Au sein de l'un des premiers déploiements en production de Lakebase : le moteur de gouvernance de flux de travail agentifs de LangGuard
Les flux de travail d'agents d'entreprise couvrent des dizaines d'agents, des centaines d'outils et plus de 15 systèmes d'enregistrement. Les contrôler et les exploiter en temps réel nécessite une infrastructure qui n'existait pas avant Lakebase.
par Venkat Raghavan, Jason Keirstead, Ravi Srinivasan, Nina Williams et Amelia Westberg
- Moins de 10 % des entreprises ont déployé avec succès des agents IA autonomes à grande échelle, principalement parce que les agents contournent les contrôles de sécurité traditionnels en générant leur propre logique à l'exécution, créant ainsi un écart de gouvernance invisible.
- Databricks fournit une gouvernance unifiée pour les données, les modèles et les politiques d'accès via Unity Catalog et AI Gateway. LangGuard étend ces contrôles au niveau de la plateforme avec une couche d'application des règles à l'exécution pour les flux de travail d'agents — surveillant et appliquant les politiques sur la chaîne complète des actions, décisions, outils et identifiants. Il utilise un tissu de données GRAIL™ en instance de brevet qui capture chaque action d'agent dans un graphe de connaissances en direct et évalue chaque décision de politique en temps réel, sans impacter les performances de l'agent.
- Databricks Lakebase, la première base de données Postgres entièrement gérée et sans serveur de l'industrie construite sur le lakehouse, rend cela possible, offrant une puissance de calcul élastique évolutive à zéro, une exécution de requêtes à faible latence pour les données opérationnelles chaudes et une ramification instantanée de la base de données pour tester en toute sécurité les politiques de gouvernance.
Le problème invisible de l'IA agentique
La plupart des entreprises expérimentent avec des agents IA autonomes. Très peu les déploient en toute sécurité à grande échelle. Selon l'enquête "The State of AI in 2025" de McKinsey (novembre 2025), aucune fonction commerciale n'a vu plus de dix pour cent des entreprises déployer des agents IA en production. L'échec est rarement un manque d'ambition ; c'est un manque de visibilité.
Contrairement aux logiciels traditionnels, les agents autonomes génèrent leur propre logique à la volée. Ils contournent les moniteurs de sécurité conventionnels, invoquent des outils et accèdent à des données d'une manière difficile à auditer a posteriori, et opèrent dans des flux de travail multi-agents complexes où une seule autorisation mal configurée ou une lacune dans la politique peut dégénérer en un incident de sécurité majeur. Ce dont les entreprises ont besoin, c'est d'une nouvelle catégorie d'infrastructure de contrôle : une qui opère au moment où une décision est prise, pas après que les dégâts sont faits.
C'est le problème que LangGuard a été conçu pour résoudre.
L'application en temps réel rencontre la gouvernance de plateforme
LangGuard agit comme une couche d'application en temps réel pour les flux de travail agentiques, surveillant et appliquant les politiques sur la chaîne complète d'actions, de décisions, d'outils, d'identifiants et d'intentions qui couvre chaque système qu'un agent touche. Databricks fournit une gouvernance unifiée via Unity Catalog et AI Gateway — le système d'enregistrement des données, des modèles et des politiques d'accès. À mesure que les entreprises déploient des agents en production, le flux de travail lui-même a également besoin d'une couche d'application en temps réel qui étend ces contrôles au niveau de la plateforme à chaque étape de l'exécution de l'agent. C'est là que LangGuard intervient. Le moteur de gouvernance de LangGuard, le tissu de données GRAIL™ (Governance AI Run-time Links), capture chaque action de l'agent sous forme de données de trace multidimensionnelles et construit un graphe de connaissances en direct du comportement et du contexte du flux de travail. Lorsqu'un agent tente d'invoquer un outil, d'accéder à un jeu de données ou d'appeler un modèle, LangGuard évalue cette action par rapport à la politique avant son exécution, sur tous les systèmes que le flux de travail touche, quel que soit l'endroit où il s'exécute.
L'échelle d'un déploiement d'agents d'entreprise en production rend cela vraiment difficile. Un seul flux de travail peut impliquer des dizaines d'agents coordonnés, des centaines d'invocations d'outils, plusieurs modèles fondamentaux et des politiques gérées sur quinze systèmes d'enregistrement d'entreprise ou plus, y compris des systèmes de ticketing IT comme ServiceNow, des plateformes IAM et IDP, des systèmes CRM comme Salesforce, des plateformes RH comme Workday, des plateformes de sécurité cloud comme Wiz et CrowdStrike, des plateformes de centre de contact comme TalkDesk, des passerelles MCP et des passerelles API. Gouverner cela en temps réel, sans impacter les performances de l'agent, exige une infrastructure spécialement conçue pour le problème.
Pourquoi nous avons choisi Lakebase
L'équipe LangGuard a passé des années à construire IBM QRadar, un leader multi-récompensé du Gartner Magic Quadrant et l'une des plateformes SIEM d'entreprise les plus déployées au monde. QRadar ingère et corrèle des pétaoctets de télémétrie de sécurité par jour sous des exigences strictes de latence et de fiabilité. Cette expérience nous a enseigné une leçon difficile : l'architecture de la base de données est le destin. Lorsque nous avons conçu le moteur de gouvernance de flux de travail de LangGuard, nous avons été confrontés au même défi que nous avions résolu auparavant : des données de sécurité opérationnelles qui arrivent par rafales imprévisibles et de haute intensité, où chaque milliseconde de latence de décision compte et où les dépenses d'infrastructure inactive sont inacceptables. Les bases de données traditionnelles qui couplent le calcul et le stockage vous obligent à provisionner pour la charge maximale et à payer pour cette capacité 24h/24 et 7j/7. Le modèle serverless de Lakebase, qui découple entièrement le calcul du stockage et se met à l'échelle à zéro entre les rafales, était la réponse dont nous avions toujours eu besoin mais à laquelle nous n'avions pas accès lorsque nous construisions QRadar. Il correspondait exactement au problème.
Ce qui fait de Lakebase le bon choix
Lakebase est une nouvelle catégorie d'architecture de base de données opérationnelle qui désagrège le calcul du stockage, permettant au calcul de s'adapter élastiquement à la demande de la charge de travail tandis que l'état durable réside indépendamment dans une couche de stockage répliquée. Construit sur la fondation ouverte de PostgreSQL, l'architecture lakebase préserve tout ce sur quoi les développeurs s'appuient dans une base de données relationnelle éprouvée tout en éliminant les contraintes d'infrastructure qui font des SGBDR monolithiques traditionnels le mauvais choix pour la vitesse et l'échelle dont les applications modernes, les agents et l'IA ont besoin.
Autoscaling serverless et scale-to-zero
Le comportement des agents est notoirement intermittent. Un flux de travail d'agent peut être complètement dormant pendant des heures, puis générer soudainement des centaines d'écritures de trace et de lectures d'application en quelques secondes. Lakebase provisionne dynamiquement les ressources de calcul au moment exact où ces traces inondent notre système, et s'arrête complètement lorsque l'activité cesse. Comme l'état durable réside dans la couche de stockage, pas dans le nœud de calcul, le démarrage d'une nouvelle instance de calcul ne nécessite aucun déplacement de données. Il se connecte simplement à l'historique de la base de données existante et commence à servir les requêtes immédiatement.
Pour une startup opérant à l'échelle de l'entreprise, c'est la différence entre une infrastructure qui correspond à l'utilisation réelle et une infrastructure qui vous pénalise pour les périodes calmes. Nos coûts opérationnels restent parfaitement alignés sur les charges de travail que nous servons réellement.
Latence de lecture en millisecondes pour les données opérationnelles chaudes
La préoccupation naturelle avec toute base de données désagrégée est la latence de lecture. Lakebase aborde cela grâce à une couche de mise en cache entre le calcul et le stockage qui maintient les données chaudes à proximité du calcul.
Pour les requêtes d'application de LangGuard, des recherches indexées serrées sur le contexte GRAIL™ et les tables de politiques, nous nous attendons à ce que l'ensemble de travail actif tienne confortablement dans la mémoire locale du calcul. Cette architecture nous donne la confiance que les décisions de gouvernance peuvent être appliquées à la vitesse du flux de travail, sans ajouter de latence significative à l'exécution de l'agent.
Branchement instantané de base de données pour les tests de politiques de gouvernance
Le branchement instantané de base de données de Lakebase est l'une de ses capacités opérationnellement les plus précieuses pour un produit de gouvernance. Lorsque nous créons une branche, aucune donnée n'est physiquement copiée. La branche diverge de l'état actuel de la base de données en utilisant la sémantique copy-on-write, ne consommant du stockage que pour les données nouvelles ou modifiées. Nos développeurs peuvent créer une réplique isolée et exacte de nos données de trace de production en quelques secondes, tester de nouvelles politiques de gouvernance par rapport au comportement réel de l'agent et valider la logique d'application sans risquer la stabilité de l'environnement en direct.
PostgreSQL : une fondation éprouvée
Lakebase est construit sur PostgreSQL, la base de données relationnelle open-source la plus avancée au monde, avec des décennies de durcissement en production dans toutes les industries. Pour LangGuard, cela signifie une compatibilité totale avec les outils, les bibliothèques et les extensions que notre équipe connaît déjà, sans langage de requête propriétaire ni risque de migration.
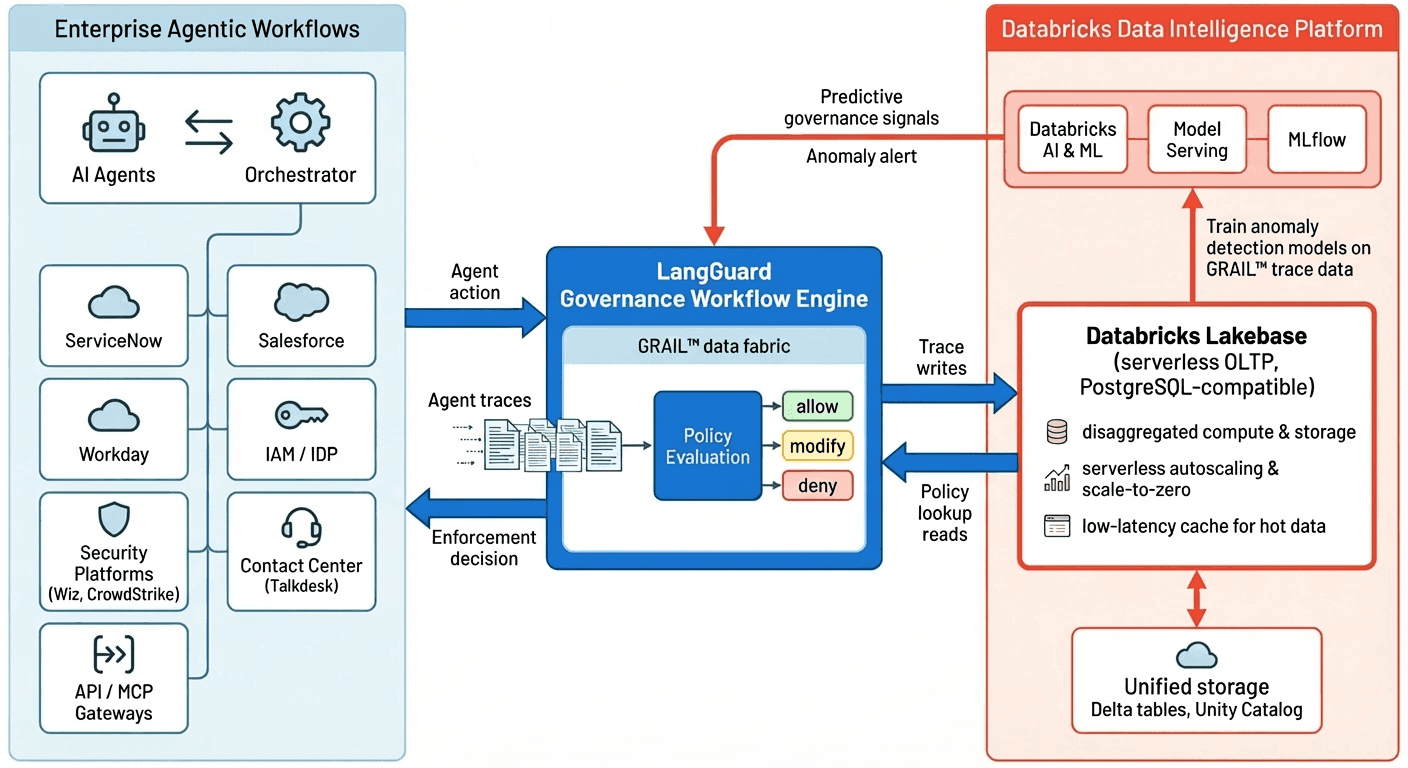
Comment LangGuard et Databricks travaillent ensemble
L'architecture conjointe LangGuard et Databricks est conçue pour gouverner les flux de travail agentiques d'entreprise de bout en bout tout en gardant toutes les données opérationnelles sur une seule plateforme de données et d'IA de confiance. Sur la gauche de l'architecture se trouvent les flux de travail agentiques d'entreprise eux-mêmes : agents IA et leurs orchestrateurs interagissant avec des dizaines de systèmes d'enregistrement tels que la gestion des services informatiques, le CRM, les RH, l'identité, la sécurité, le centre de contact et les passerelles API/MCP. Chaque action de l'agent, invocation d'outil et demande d'accès aux données génère des événements de trace riches qui affluent vers LangGuard en temps réel.
Au centre du diagramme se trouve le moteur de flux de travail de gouvernance LangGuard, alimenté par le tissu de données GRAIL™ en attente de brevet. GRAIL capture chaque action de l'agent sous forme de données de trace multidimensionnelles et construit un graphe de connaissances en direct du comportement et du contexte du flux de travail. Lorsqu'un agent tente d'appeler un outil, d'accéder à un jeu de données ou d'invoquer un modèle, LangGuard effectue une évaluation de politique par rapport à ce contexte en direct et aux règles de gouvernance pertinentes, renvoyant une décision autoriser/refuser/modifier avant que l'action ne s'exécute. Cela donne aux entreprises un point de contrôle unique pour appliquer les politiques sur tous les systèmes que le flux de travail touche, quel que soit l'endroit où les agents sous-jacents s'exécutent.
Sur la droite, Databricks Lakebase sert de système d'enregistrement opérationnel pour les données de trace et de politique de LangGuard. L'architecture serverless et PostgreSQL de Lakebase désagrège le calcul du stockage, permettant un autoscaling élastique et un scale-to-zero entre les rafales d'activité des agents tout en maintenant les données opérationnelles chaudes dans un cache à faible latence à proximité du calcul. LangGuard écrit en continu des événements de trace dans Lakebase et effectue des lectures à faible latence pour les recherches de politiques de gouvernance et les requêtes contextuelles, garantissant que les décisions d'application peuvent être prises à la vitesse du flux de travail sans surprovisionner la capacité de la base de données.
Étant donné que les données opérationnelles de LangGuard résident nativement dans Lakebase, elles sont immédiatement disponibles pour la plateforme plus large de Data Intelligence de Databricks pour l'analyse et l'IA sans ETL supplémentaire. Databricks AI, Model Serving et MLflow peuvent entraîner et déployer des modèles de détection d'anomalies directement sur les données de trace GRAIL pour identifier les agents qui s'écartent de leur ligne de base comportementale établie. Ces signaux prédictifs sont renvoyés au moteur de gouvernance LangGuard, bouclant la boucle entre l'application en temps réel et la surveillance prédictive, et permettant aux entreprises de passer de contrôles réactifs à une gouvernance IA proactive basée sur le comportement sur une seule plateforme.
Ce qui vient ensuite : gouvernance prédictive pour les flux de travail agentiques
Le moteur de LangGuard applique aujourd'hui les politiques établies à l'exécution sur l'ensemble du flux de travail. La prochaine évolution est prédictive : entraînement de modèles comportementaux sur des données historiques de traces GRAIL pour détecter les comportements anormaux des agents avant qu'ils ne se manifestent par une violation de politique.
Étant donné que nos données de traces opérationnelles résident déjà dans l'écosystème Databricks, comme décrit ci-dessus, nous pouvons passer directement de l'application à la prédiction sans construire de pipelines ETL distincts ni mettre en place une seconde plateforme d'analyse.
Si un agent commence à agir de manière erratique ou à s'écarter de sa base de référence établie, ces modèles le signaleront comme une anomalie avant que tout dommage ne soit causé. Cette convergence de l'application en temps réel et de l'apprentissage automatique prédictif est l'avenir de la gouvernance de l'IA d'entreprise, et c'est l'architecture que nous construisons aujourd'hui.
| POINT CLÉ |
|---|
| LangGuard est l'une des premières startups à construire une infrastructure de production sur Databricks Lakebase. Le choix a été motivé par un ensemble spécifique d'exigences non négociables : application à faible latence, gestion des pics élastiques et test des politiques de gouvernance par rapport à des données réelles. Seule une base de données OLTP sans serveur pouvait toutes les satisfaire. Lakebase est la première base de données à répondre à toutes ces exigences. |
| Pour les entreprises qui ont besoin de gouverner les flux de travail des agents de bout en bout, à travers chaque agent, outil, identifiant et système d'enregistrement de la chaîne, cette architecture signifie une application qui fonctionne à la vitesse du flux de travail, s'adapte à la complexité du déploiement et évolue vers une sécurité comportementale prédictive sans nécessiter de plateforme de données distincte. |
Prêt à gouverner vos flux de travail des agents de bout en bout ? Visitez langguard.ai pour découvrir comment LangGuard sécurise, contrôle et exploite les flux de travail des agents d'entreprise avec une conformité totale aux politiques, ou explorez Databricks Lakebase pour voir comment l'infrastructure OLTP sans serveur alimente la gouvernance de l'IA en temps réel à grande échelle.
En savoir plus sur LangGuard Explorer Databricks Lakebase
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.