Présentation de Spatial SQL dans Databricks : plus de 80 fonctions pour l'analyse géospatiale haute performance
Le meilleur « entrepôt » de données est un lakehouse
par Kent Marten et Michael Johns
- Accélérez vos requêtes géospatiales à grande échelle avec plus de 80 fonctions Spatial SQL, désormais disponibles en préversion publique.
- Stockez de manière transparente les données planaires et géodésiques à l'aide des types de données natifs GEOMETRY et GEOGRAPHY.
- Améliorez votre analyse spatiale avec des jointures spatiales haute performance, et oubliez l'indexation manuelle.
Chaque jour, des milliards de points de données sont liés à des lieux sur la carte. Les itinéraires de livraison, les visites en magasin, les réseaux routiers, les antennes relais et les champs agricoles, tous apportent un contexte important pour la prise de décisions commerciales. Le problème est que l'analyse de ces données à grande échelle a été difficile. Les systèmes spatiaux hérités sont lents, nécessitent un indexation manuelle et enferment souvent les informations dans des formats propriétaires.
Aujourd'hui, nous introduisons Spatial SQL dans Databricks. Spatial SQL apporte l'analyse géospatiale directement sur la plateforme Databricks. Vous pouvez désormais travailler avec les types de données natifs GEOMETRY et GEOGRAPHY, utiliser plus de 80 fonctions SQL, et exécuter des jointures spatiales à haute vitesse et performance, tout en gardant vos données ouvertes et prêtes pour le passage à l'échelle.
Les données de localisation jouent un rôle dans presque toutes les industries, et Spatial SQL facilite l'utilisation de ces informations.
Voici quelques exemples :
- Les opérations de vente au détail peuvent comprendre d'où viennent leurs clients en analysant les zones et le trafic piétonnier
- Les analystes des transports peuvent améliorer la sécurité et l'expérience client en analysant les incidents de véhicules et la connectivité des réseaux cellulaires
- Les compagnies d'énergie peuvent optimiser le déploiement des équipes lors des pannes et trouver des emplacements idéaux pour les parcs éoliens et solaires
- Les opérateurs agricoles peuvent appliquer des techniques d'agriculture de précision pour réduire les coûts et améliorer l'efficacité des rendements
- Les analystes d'assurance peuvent comprendre les risques en analysant les adresses des assurés dans les zones d'inondation, d'incendie et d'ouragan
- Les organisations de santé peuvent comparer et prédire les résultats sanitaires en analysant les facteurs environnementaux à travers les zones géographiques
- Et bien plus encore !
Spatial SQL aide déjà les clients à accélérer les performances et à réduire les coûts :
« Databricks Spatial SQL a redéfini la façon dont nous exécutons des jointures spatiales à grande échelle. En intégrant les fonctions Spatial SQL dans nos pipelines de traitement, nous avons constaté des performances plus de 20 fois plus rapides et des coûts inférieurs de plus de 50 % sur les mêmes charges de travail. Cette avancée permet d'intégrer et de fournir des données riches de réseaux routiers à une échelle et une vitesse qui n'étaient tout simplement pas réalisables auparavant. »
– Laxmi Duddu, Sr. Manager, Autonomy Data Platform & Analytics, Rivian Automotive
Les clients ont précédemment lutté pour gérer et adapter les charges de travail spatiales avec des systèmes hérités, des bibliothèques tierces ou en recourant à des stratégies d'indexation manuelles. Avec Spatial SQL, les clients bénéficient d'une simplicité et d'une scalabilité prêtes à l'emploi.
« Spatial SQL nous permet de faire évoluer l'ETL géospatial comme jamais auparavant. Au lieu de surcharger les serveurs PostGIS avec des requêtes lourdes, nous déplaçons la charge vers Databricks et profitons du traitement distribué, des jointures spatiales rapides et de la gestion efficace des données vectorielles. C'est une approche plus efficace, résiliente et évolutive pour gérer des jeux de données géospatiaux volumineux et complexes. »
— Pierre Chenaux, Tech Leader du département Géospatial, TotalEnergies
Un moteur majeur de performance est la prise en charge des types de données géospatiales de première classe. Au lieu de stocker les données géo dans des colonnes de type chaîne, binaire ou décimale, vous pouvez désormais utiliser les types de données natifs GEOMETRY et GEOGRAPHY. Ces types incluent des statistiques de boîte englobante que Databricks utilise lors de l'exécution des requêtes pour ignorer les données non pertinentes et accélérer les jointures. Spatial SQL fournit également des fonctions d'import pour les formats standard tels que Well Known Text, Well Known Binary, GeoJSON et des valeurs de latitude ou longitude simples.
Ces types de données sont entièrement ouverts dans Parquet, Iceberg, et Delta. L'équipe Databricks a contribué à façonner les spécifications proposées, garantissant qu'il n'y a pas de verrouillage propriétaire avec les entrepôts de données. Avec le SPIP Apache Spark™ approuvé, GEOMETRY et GEOGRAPHY seront bientôt des types de données de première classe dans le moteur open source également.
Que pouvez-vous faire avec Spatial SQL ?
Spatial SQL est plus qu'un ensemble de nouvelles fonctions. Il vous donne les éléments constitutifs pour gérer l'ensemble du cycle de vie des données spatiales, du stockage et de l'importation à l'analyse et à la transformation. En travaillant avec des types de données natifs et des opérations efficaces, vous pouvez intégrer la localisation dans les requêtes quotidiennes sans ajouter de complexité.
Voici quelques-unes des choses essentielles que vous pouvez faire :
- Stocker des données spatiales nativement avec GEOMETRY et GEOGRAPHY
- Importer et exporter dans des formats tels que WKT, WKB, GeoJSON et GeoHash
- Créer de nouveaux objets avec des constructeurs comme ST_Point ou ST_MakeLine
- Calculer des mesures à l'aide de fonctions comme ST_Distance et ST_AREA
- Effectuer des jointures spatiales à l'aide de relations comme ST_Contains et ST_Intersects
- Transformer entre les systèmes de coordonnées avec ST_Transform
- Modifier, valider et combiner des objets spatiaux à l'aide de ST_ISVALID ou ST_UNION_AGG
- Et bien plus encore !
Ces fonctionnalités vous offrent une boîte à outils complète pour l'analyse spatiale directement en SQL, également disponible avec les API Python et Scala. Lorsque vous les combinez, elles débloquent des flux de travail réels qui comptent en pratique, ce que nous allons détailler dans la section suivante.
Exemples de Spatial SQL en pratique
Les données géospatiales sont partout et en croissance. Les traces GPS avec latitudes et longitudes sont émises par un nombre croissant d'appareils, de capteurs et de véhicules chaque seconde de la journée. Le monde est constamment catalogué et mis à jour, avec des lieux, des routes, des réseaux et des frontières modélisés comme des points, des lignes et des polygones. Dans toutes les industries – vente au détail, transport et logistique, énergie, climat et sciences naturelles, agriculture, secteur public, services financiers, immobilier, assurance, télécommunications – la localisation est importante pour chaque décideur qui a besoin de comprendre le « où » dans ses données.
Nous avons préparé quatre exemples courts pour commencer à travailler avec les nouveaux types de données et expressions spatiales, avec les objectifs suivants.
- Préparer les données pour un traitement efficace en utilisant le nouveau type GEOMETRY
- Effectuer un enrichissement de données en combinant deux jeux de données spatiaux à l'aide d'une jointure spatiale
- Transformer les données dans un système de référence spatiale approprié pour améliorer la précision des mesures de distance
- Mesurer la distance entre deux villes
Dans ces exemples, nous utiliserons les jeux de données d'adresses, de bâtiments et de divisions de OvertureMaps.org. Ces jeux de données sont proposés en téléchargement de diverses manières, par exemple en GeoParquet.
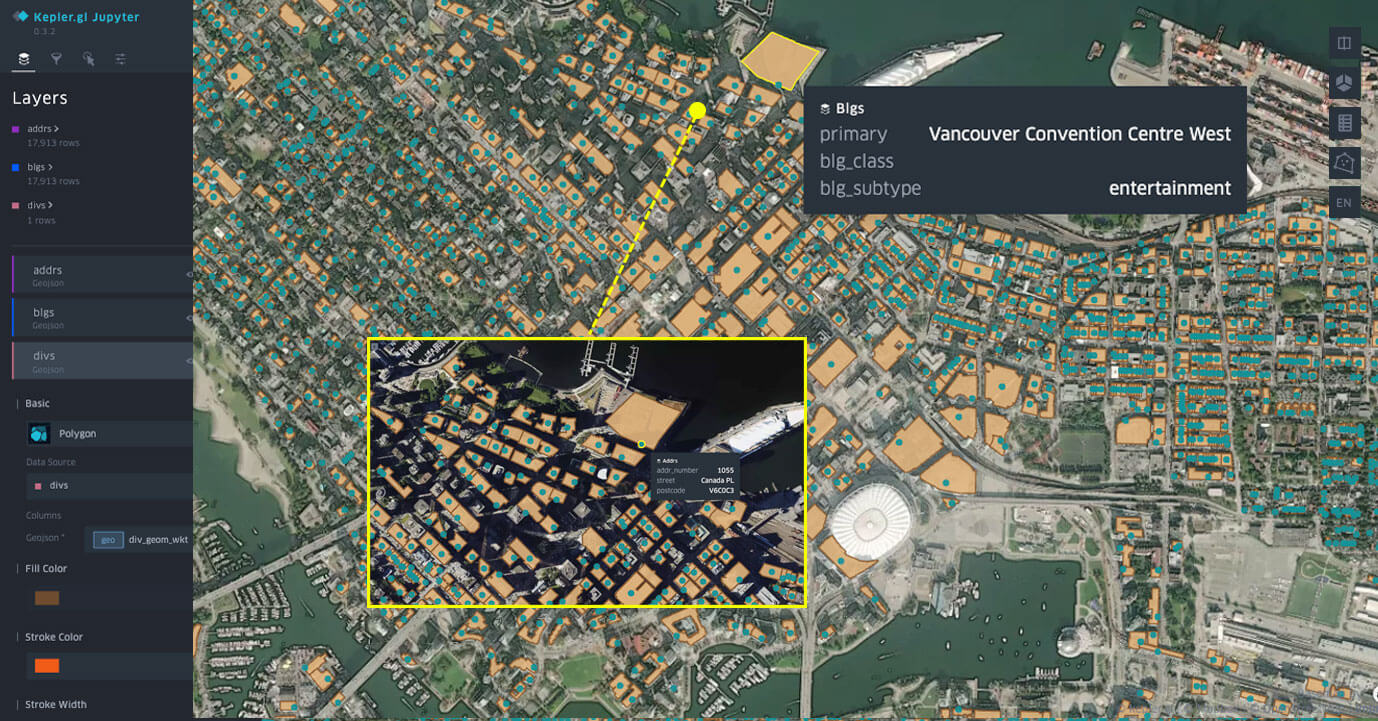
Jeux de données Overture Maps visualisés dans un notebook Databricks avec kepler.gl.
1. Création d'une colonne GEOMETRY
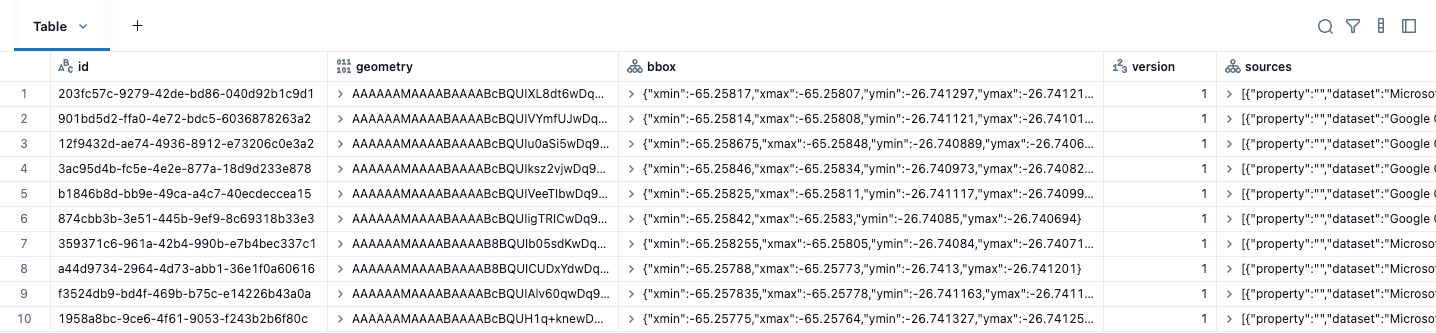
La première étape avant d'effectuer toute analyse spatiale consiste à convertir vos données pour utiliser les types de données GEOMETRY ou GEOGRAPHY. Après avoir téléchargé les données Overture Maps, nous devons simplement créer une colonne GEOMETRY native à partir de la colonne de géométrie WKB fournie et supprimer les autres colonnes inutiles comme bbox. Une boîte englobante est le plus petit rectangle qui contient une géométrie. Dans les requêtes spatiales, les boîtes englobantes accélèrent les requêtes en écartant rapidement les données qui ne peuvent pas se chevaucher. Si deux boîtes englobantes ne s'intersectent pas, les géométries qu'elles contiennent ne le font certainement pas, de sorte que la base de données peut ignorer la vérification d'intersection coûteuse et réduire la quantité de données traitées. Nous n'avons pas besoin du champ bbox car ces informations sont désormais gérées dans les statistiques de colonne. Pour ces jeux de données, les adresses sont des POINTS, tandis que les bâtiments et les divisions sont des POLYGONES / MULTI-POLYGOES. Voici les données de bâtiments initialement téléchargées, montrant les cinq premières colonnes.
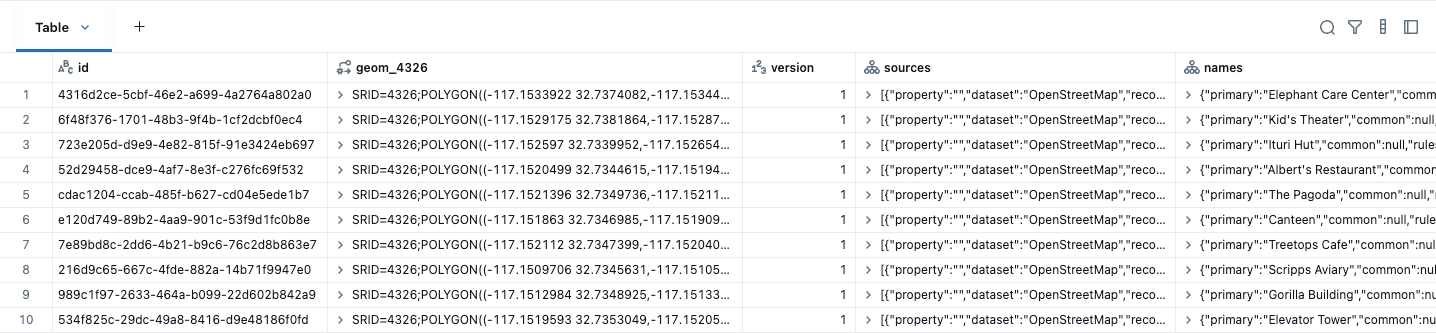
Ce jeu de données peut être facilement converti en une table Lakehouse avec des données GEOMETRY natives à l'aide de ST_GeomFromWKB, comme illustré dans l'exemple ci-dessous pour les bâtiments. Nous savons que nos données sont en WGS84 (EPSG:4326), nous le spécifions donc lors de la création du type spatial. Un SRID identifie le système de coordonnées de vos données spatiales, qui définit les unités (comme les degrés ou les mètres) utilisées dans les calculs tels que la distance et la surface. Vous devez définir un SRID valide lors de la création d'une colonne de géométrie, sinon la requête renverra une erreur. Notez également que nos types natifs s'affichent dans un format convivial (EWKT).
En plus du WKB, les données spatiales peuvent également être importées directement dans nos types natifs à partir des formats d'échange les plus courants :
- Coordonnées de latitude et longitude à l'aide de ST_POINT
- WKT à l'aide de ST_GeomFromWKT ou ST_GeomFromText
- WKB à l'aide de ST_GeomFromWKB ou ST_GeomFromBinary
- GeoJSON �à l'aide de ST_GeomFromGeoJSON
- GeoHash à l'aide de ST_PointFromGeoHash
De même, les données spatiales peuvent être exportées dans plusieurs formats :
- WKT à l'aide de ST_AsWKT ou ST_AsText
- WKB à l'aide de ST_AsWKB ou ST_AsBinary
- GeoJSON à l'aide de ST_AsGeoJSON
- WKT étendu à l'aide de ST_AsEWKT
- WKB étendu à l'aide de ST_AsEWKB
- GeoHash à l'aide de ST_GeoHash
Remarque : nous avons également des expressions d'importation et d'exportation pour les types GEOGRAPHY.
2. Jointure spatiale de plusieurs jeux de données
Les jointures spatiales sont parmi les opérations les plus importantes et les plus utilisées dans le traitement des données géospatiales. Elles vous permettent de combiner des attributs de différents jeux de données et d'effectuer des agrégations ou des enrichissements de données en fonction de leurs relations spatiales, telles que le confinement, l'intersection et la proximité. Cela rend les jointures spatiales essentielles pour répondre à des questions du monde réel telles que l'identification des bâtiments situés dans une zone inondable, l'attribution de données démographiques de recensement aux adresses des clients et l'analyse des véhicules connectés dans les zones de couverture cellulaire. Étant donné qu'une grande partie de l'analyse géospatiale dépend de l'intégration de plusieurs jeux de données, les jointures spatiales sont souvent une première étape dans l'analyse spatiale exploratoire, la modélisation spatiale et la prise de décision basée sur la localisation.
Ensuite, nous allons joindre les tables d'adresses et de divisions à l'aide d'une jointure spatiale. Quiconque a travaillé avec des sources de données d'adresses sait que les adresses peuvent être des données désordonnées (une cause fréquente est que différents pays utilisent des systèmes d'adressage différents). De plus, la table d'adresses n'inclut pas de hiérarchie administrative complète (c'est-à-dire pas d'informations de comté pour les adresses américaines). Nous utiliserons donc la table de divisions pour valider les informations de ville et les enrichir en ajoutant des informations équivalentes au comté.
Ce processus de validation et d'enrichissement des données serait différent à résoudre sans jointure spatiale. Pour ce faire, nous devons trouver l'adresse dans la division. Nous utiliserons ST_Contains pour effectuer une jointure spatiale de type point dans polygone, laissant Databricks gérer les détails internes de l'opération, sans indexation spatiale à faire soi-même.
Nous pouvons maintenant plus facilement standardiser la ville, l'état, le comté et le pays corrects, par exemple remplacer les villes manquantes dans les adresses par celles fournies dans la table des divisions.
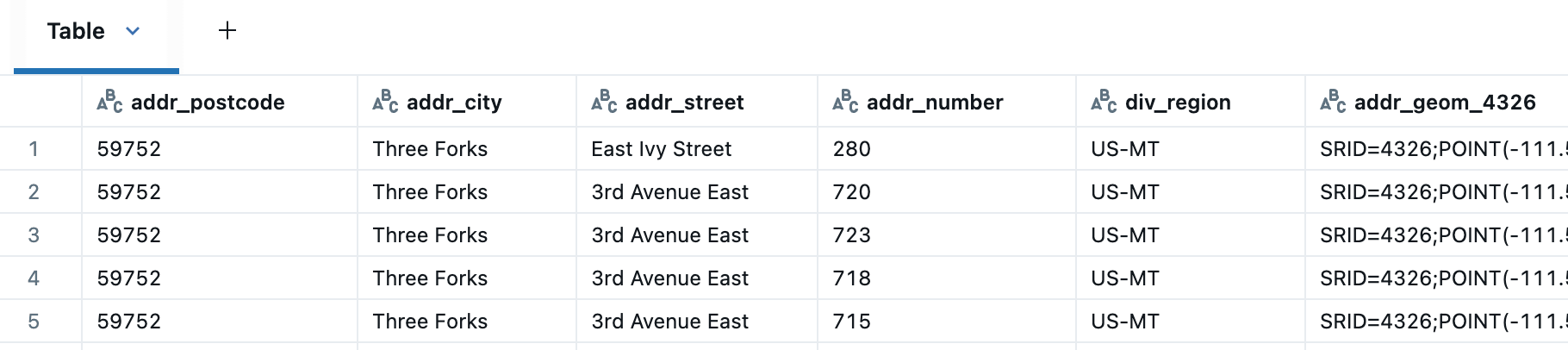
Après avoir validé les adresses, nous avons suivi une approche similaire pour joindre les adresses aux bâtiments à l'aide de ST_Intersects afin d'enrichir la table Buildings avec des informations d'adresse. Pour les États-Unis, cette jointure spatiale a fait correspondre 44 millions d'adresses à des bâtiments, avec 55 millions de bâtiments restants non correspondants. Dans l'exemple suivant, voyons comment nous pouvons utiliser la proximité pour identifier potentiellement les bâtiments qui n'ont pas été associés à une adresse.
3. Transformation des données vers des systèmes de référence spatiale spécifiques
Les jeux de données géospatiaux sont souvent créés dans différents systèmes de référence de coordonnées (SRC), tels que latitude-longitude (WGS84) ou des systèmes projetés comme UTM, en fonction de leur source et de leur objectif. Bien que chaque SRC définisse comment la surface courbe de la Terre est représentée sur une carte plane, l'utilisation de jeux de données avec des projections incompatibles peut entraîner un désalignement des entités, une distorsion des distances ou des jointures et des mesures spatiales incorrectes. Un magasin situé dans une zone inondable ne correspondra pas lors d'une jointure spatiale si des systèmes de coordonnées différents sont utilisés. Pour une analyse précise, qu'il s'agisse de calculer des surfaces, de joindre des couches ou de visualiser des relations spatiales, il est essentiel de s'assurer que tous les jeux de données sont transformés dans la même projection afin qu'ils partagent une référence spatiale cohérente.
Pour identifier les adresses à proximité des 55 millions de bâtiments non correspondants restants aux États-Unis, projetons nos données GEOMETRY WGS84 en Conus Albers (EPSG:5070) pour l'Amérique du Nord, ce qui nous donne des unités en mètres. Ceci est réalisé avec la fonction ST_Transform.
Appliquons ST_DWithin entre nos bâtiments et adresses américains non correspondants, en utilisant une valeur de distance de seulement 2 mètres.
La valeur de distance peut être augmentée si nécessaire pour rassembler un ensemble de correspondances d'adresses potentielles ; de plus, une CTE récursive peut être utile pour itérer sur plusieurs distances. Pour cet exemple, un polygone de filtre nous permet d'isoler facilement notre recherche dans le voisinage de Saint Petersburg, en Floride. Le polygone est initialement préparé à partir de WKT à l'aide de ST_GeomFromWKT, puis transformé en SRID 5070 pour correspondre aux données d'adresse et de bâtiment.
Pour préparer les jeux de données pour la CTE récursive, nous appliquons un filtre spatial sur nos données en intersectant les bâtiments et les adresses avec le polygone de recherche, en montrant les bâtiments ci-dessous (les adresses sont traitées de manière similaire).
La CTE récursive ci-dessous itère sur les bâtiments pour identifier les candidats adresses dans un rayon de 5, 10 et 15 mètres. La table de résultats supprime les adresses en double sur des distances successives à l'aide de l'expression de fenêtre suivante : QUALIFY RANK() OVER (PARTITION BY blg_id,addr_id ORDER BY dwithin) = 1.
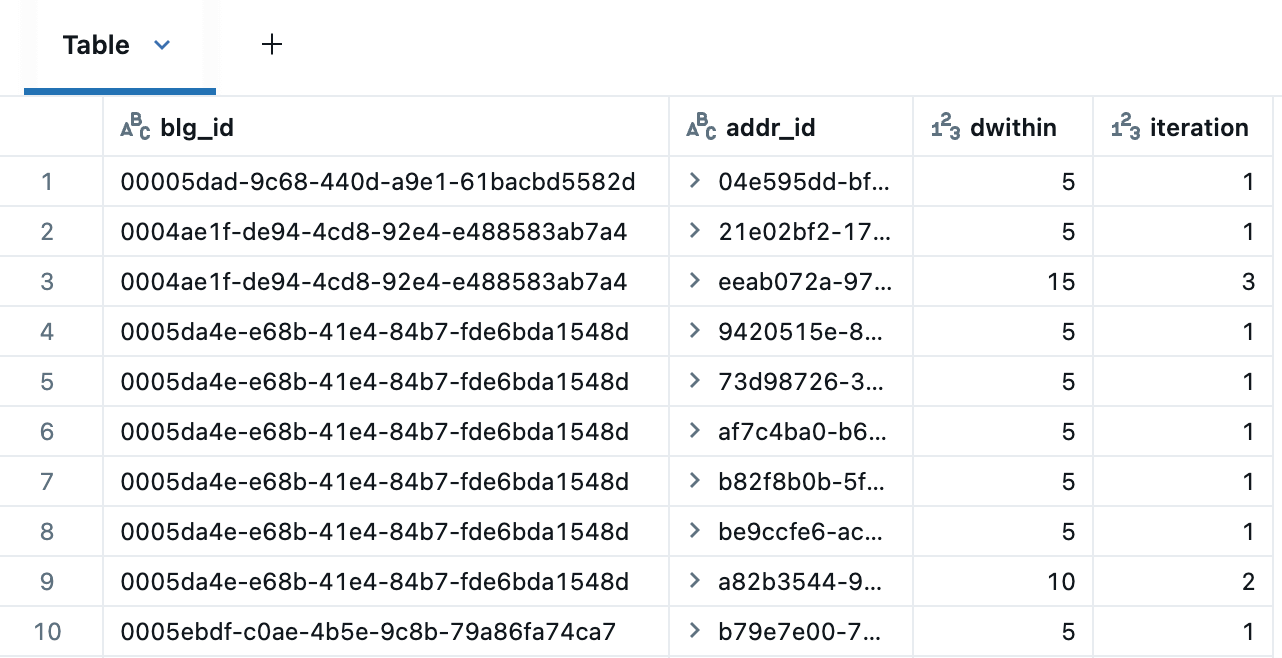
Voici les candidats d'adresses autour de l'un des bâtiments, montrant les correspondances à 5 m (bleu), 10 m (orange) et 15 m (vert). Ceci est rendu à l'aide des Marker Maps intégrés de Databricks en mode clustering, qui répartiront les points proches pour une meilleure visualisation. Lors de la création d'un tableau de bord, nous aurions également pu utiliser les AI/BI Point Maps, qui prennent en charge le filtrage croisé et le forage.
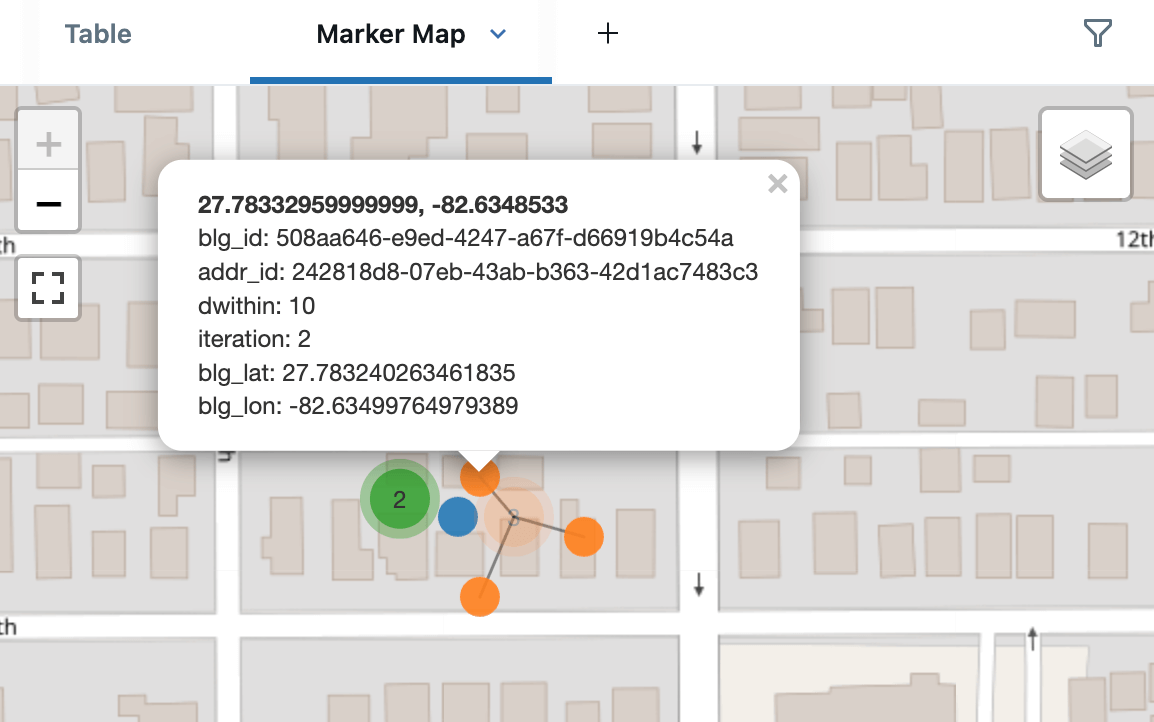
Il existe de nombreuses utilisations alternatives des CTE récursives pour le traitement spatial, par exemple, l'implémentation de l'algorithme de Prim pour construire un arbre couvrant minimum de vos points de livraison.
4. Mesurer les distances entre les emplacements
La proximité est un concept central dans l'analyse spatiale, car la distance détermine souvent la force ou la pertinence des relations entre les emplacements. Qu'il s'agisse d'identifier l'hôpital le plus proche, d'analyser la concurrence entre les magasins ou de cartographier les habitudes des navetteurs, comprendre la proximité des entités les unes par rapport aux autres fournit un contexte essentiel.
En poursuivant avec notre jeu de données d'exemple, nous avons effectué la même opération de transformation Conus Albers sur nos villes de Floride pour mesurer leurs distances. Nous mesurons à partir du centre géométrique des villes, généré à l'aide de la fonction : ST_Centroid.
Lors du calcul de la distance entre deux GEOMETRIES, plusieurs fonctions différentes sont à considérer :
- ST_Distance - Renvoie la distance cartésienne dans les unités des GEOMETRIES fournies, calculant le chemin en ligne droite basé sur leurs coordonnées x et y, comme si la Terre était plate.
- ST_DistanceSphere - Renvoie la distance sphérique (toujours en mètres) entre deux GEOMETRIES ponctuelles, mesurée sur le rayon moyen de l'ellipsoïde WGS84 de la Terre, les points de coordonnées étant supposés avoir des unités de degrés, par exemple, SRID 4326 serait valide mais pas SRID 5070.
- ST_DistanceSpheroid - Renvoie la distance géodésique (toujours en mètres) entre deux GEOMETRIES ponctuelles sur l'ellipsoïde WGS84 de la Terre ; de même, les points de coordonnées sont supposés avoir des unités de degrés. Encore une fois, SRID 4326, ou tout autre SRID avec des unités en degrés, serait une entrée valide pour cet exemple.
Les différents calculs de distance sont appliqués entre city1 et city2 avec ST_Distance pour les GEOMETRIES en 5070, puis ST_DistanceSphere et ST_DistanceSpheroid pour les GEOMETRIES en 4326.
Parmi les fonctions de distance, nous nous attendrions à ce que ST_DistanceSpheriod (mesures basées sur la forme ellipsoïdale de la Terre) soit la plus précise dans ce cas, suivie de ST_DistanceSphere (les mesures supposent que la Terre est une sphère parfaite). Notez que ST_Distance est plus utile lorsque vous travaillez sur des systèmes de coordonnées de référence projetés ou lorsque la courbure de la Terre peut être ignorée. Même si SRID 5070 est en mètres, nous pouvons voir les effets des calculs cartésiens sur de plus grandes distances. ST_Distance ne serait généralement pas un choix approprié pour SRID 4326, étant donné que la distance couverte par un degré de longitude change considérablement lorsque vous vous déplacez de l'équateur vers les pôles, par exemple, 1 degré de longitude diffère jusqu'à 6 km rien qu'à l'intérieur de l'État de Floride.
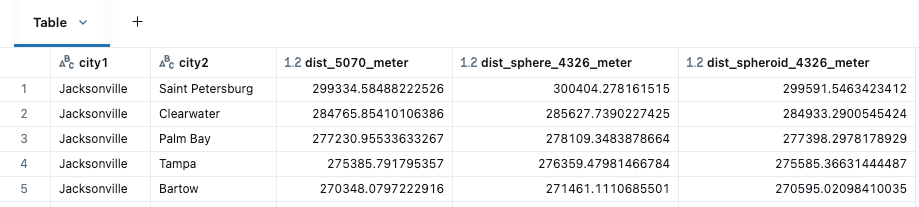
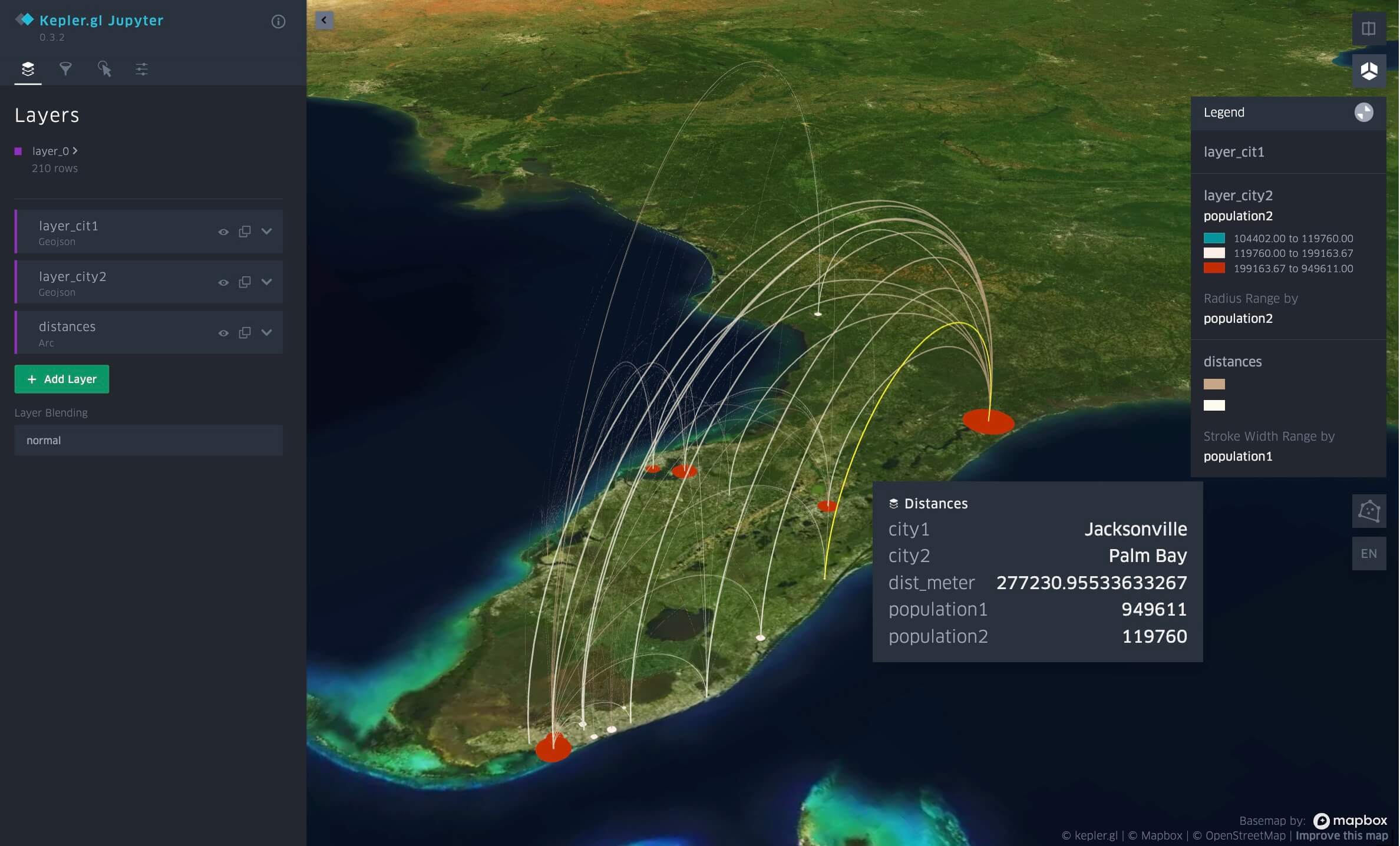
Proximité par distance entre les villes de Floride, visualisée dans Databricks Notebook avec kepler.gl.
Spatial SQL comprend plus de 80 fonctions, permettant aux clients d'effectuer des opérations courantes sur les données spatiales avec simplicité et à grande échelle. Grâce à Spatial SQL, les clients commencent maintenant à modifier leur approche de gestion et d'intégration avec les systèmes SIG :
« Les données spatiales sont au cœur de tout ce que nous faisons chez OSPRI, qu'il s'agisse de traçabilité du bétail, d'éradication des maladies ou de gestion des ravageurs. Databricks Spatial SQL nous permet d'intégrer pleinement Databricks à tout notre travail. Ces avancées nous permettent de déplacer de grandes tâches de modélisation spatiale basées sur le bureau vers une plateforme où elles sont plus proches des données et peuvent être exécutées en parallèle, à grande vitesse. Des semaines d'itérations entre les limites opérationnelles peuvent être confortablement exécutées en un jour ou deux, réduisant notre temps de décision. Ces nouvelles fonctions nous permettent également de faire de Databricks la couche d'intégration entre nos systèmes transactionnels et notre plateforme SIG, garantissant qu'elle peut être informée par des données de toute l'organisation sans compromis. » - Campbell Fleury, Manager, Data and Information Products, OSPRI New Zealand
Et ensuite ?
Il y a tellement de choses que vous pouvez faire avec Spatial SQL dans Databricks, et d'autres à venir, y compris de nouvelles expressions et des jointures spatiales plus rapides. Si vous souhaitez partager les expressions ST supplémentaires dont vous avez besoin, veuillez remplir ce court sondage.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.