Introduction à la prévision des séries temporelles avec l'IA générative
par Ryuta Yoshimatsu , Puneet Jain et Bryan Smith
Introduction à la prévision de séries temporelles avec l'IA générative
La prévision de séries temporelles est une pierre angulaire de la planification des ressources d'entreprise depuis des décennies. Les prédictions sur la demande future guident des décisions critiques telles que le nombre d'unités à stocker, le personnel à embaucher, les investissements en capital dans l'infrastructure de production et de fulfillment, et la tarification des biens et services. Des prévisions de demande précises sont essentielles pour ces décisions commerciales et bien d'autres.
Cependant, les prévisions sont rarement parfaites, voire jamais. Au milieu des années 2010, de nombreuses organisations confrontées à des limitations informatiques et à un accès limité à des capacités de prévision avancées signalaient des précisions de prévision de seulement 50 à 60 %. Mais avec l'adoption plus large du cloud, l'introduction de technologies beaucoup plus accessibles et l'amélioration de l'accès aux sources de données externes telles que les données météorologiques et événementielles, les organisations commencent à constater des améliorations.
Alors que nous entrons dans l'ère de l'IA générative, une nouvelle classe de modèles appelés transformeurs de séries temporelles semble capable d'aider les organisations à obtenir encore plus d'améliorations. Similaires aux grands modèles linguistiques (comme ChatGPT) qui excellent à prédire le mot suivant dans une phrase, les transformeurs de séries temporelles prédisent la valeur suivante dans une séquence numérique. Avec une exposition à de grands volumes de données de séries temporelles, ces modèles deviennent experts pour détecter des modèles subtils de relations entre les valeurs de ces séries avec un succès démontré dans une variété de domaines.
Dans ce blog, nous fournirons une introduction de haut niveau à cette classe de modèles de prévision, destinée à aider les gestionnaires, les analystes et les scientifiques des données à acquérir une compréhension de base de leur fonctionnement. Nous donnerons ensuite accès à une série de notebooks construits autour de jeux de données publiquement disponibles démontrant comment les organisations qui hébergent leurs données dans Databricks peuvent facilement exploiter plusieurs des modèles les plus populaires pour leurs besoins de prévision. Nous espérons que cela aidera les organisations à exploiter le potentiel de l'IA générative pour améliorer la précision des prévisions.
Comprendre les transformeurs de séries temporelles
Les modèles d'IA générative sont une forme de réseau neuronal profond, un modèle d'apprentissage automatique complexe dans lequel un grand nombre d'entrées sont combinées de diverses manières pour aboutir à une valeur prédite. La mécanique de la manière dont le modèle apprend à combiner les entrées pour parvenir à une prédiction précise est appelée l'architecture d'un modèle.
La percée dans les réseaux neuronaux profonds qui a donné naissance à l'IA générative a été la conception d'une architecture de modèle spécialisée appelée transformeur. Bien que les détails exacts de la façon dont les transformeurs diffèrent des autres architectures de réseaux neuronaux profonds soient assez complexes, le fait simple est que le transformeur est très bon pour détecter les relations complexes entre les valeurs dans de longues séquences.
Pour entraîner un transformeur de séries temporelles, un réseau neuronal profond correctement architecturé est exposé à un grand volume de données de séries temporelles. Après avoir eu l'opportunité de s'entraîner sur des millions, voire des milliards de valeurs de séries temporelles, il apprend les modèles complexes de relations trouvés dans ces jeux de données. Lorsqu'il est ensuite exposé à une série temporelle inédite, il peut utiliser cette connaissance fondamentale pour identifier où des modèles de relations similaires existent dans la série temporelle et prédire de nouvelles valeurs dans la séquence.
Ce processus d'apprentissage des relations à partir de grands volumes de données est appelé pré-entraînement. Parce que les connaissances acquises par le modèle pendant le pré-entraînement sont hautement généralisables, les modèles pré-entraînés appelés modèles de fondation peuvent être employés sur des séries temporelles inédites sans entraînement supplémentaire. Cela dit, un entraînement supplémentaire sur les données propriétaires d'une organisation, un processus appelé fine-tuning, peut dans certains cas aider l'organisation à atteindre une précision de prévision encore meilleure. Quoi qu'il en soit, une fois que le modèle est jugé satisfaisant, l'organisation doit simplement lui présenter une série temporelle et demander : que vient-il ensuite ?
Résoudre les défis courants des séries temporelles
Bien que cette compréhension générale d'un transformeur de séries temporelles puisse sembler logique, la plupart des praticiens de la prévision auront probablement trois questions immédiates. Premièrement, bien que deux séries temporelles puissent suivre un schéma similaire, elles peuvent fonctionner à des échelles complètement différentes, comment un transformeur surmonte-t-il ce problème ? Deuxièmement, au sein de la plupart des modèles de séries temporelles, il existe des modèles de saisonnalité quotidiens, hebdomadaires et annuels qui doivent être pris en compte, comment les modèles savent-ils rechercher ces modèles ? Troisièmement, de nombreuses séries temporelles sont influencées par des facteurs externes, comment ces données peuvent-elles être incorporées dans le processus de génération des prévisions ?
Le premier de ces défis est abordé en standardisant mathématiquement toutes les données de séries temporelles à l'aide d'un ensemble de techniques appelées mise à l'échelle. La mécanique de cela est interne à l'architecture de chaque modèle, mais essentiellement, les valeurs entrantes de la série temporelle sont converties à une échelle standard qui permet au modèle de reconnaître les modèles dans les données en fonction de ses connaissances fondamentales. Les prédictions sont faites, puis ces prédictions sont renvoyées à l'échelle d'origine des données d'origine.
Concernant les modèles saisonniers, au cœur de l'architecture du transformeur se trouve un processus appelé auto-attention. Bien que ce processus soit assez complexe, fondamentalement, ce mécanisme permet au modèle d'apprendre le degré auquel des valeurs antérieures spécifiques influencent une valeur future donnée.
Bien que cela semble être la solution pour la saisonnalité, il est important de comprendre que les modèles diffèrent dans leur capacité à détecter des modèles de saisonnalité de bas niveau en fonction de la manière dont ils divisent les entrées de séries temporelles. Grâce à un processus appelé tokenisation, les valeurs d'une série temporelle sont divisées en unités appelées tokens. Un token peut être une seule valeur de série temporelle ou une courte séquence de valeurs (souvent appelée patch).
La taille du token détermine le niveau de granularité le plus bas auquel les modèles saisonniers peuvent être détectés. (La tokenisation définit également la logique pour traiter les valeurs manquantes.) Lors de l'exploration d'un modèle particulier, il est important de lire les informations parfois techniques sur la tokenisation pour comprendre si le modèle est approprié pour vos données.
Enfin, concernant les variables externes, les transformeurs de séries temporelles emploient une variété d'approches. Dans certains cas, les modèles sont entraînés sur des données de séries temporelles et des variables externes associées. Dans d'autres, les modèles sont architecturés pour comprendre qu'une seule série temporelle peut être composée de plusieurs séquences parallèles et liées. Quelle que soit la technique précise employée, un soutien limité pour les variables externes peut être trouvé avec ces modèles.
Un bref aperçu de quatre transformeurs de séries temporelles populaires
Avec une compréhension générale des transformeurs de séries temporelles en main, prenons un moment pour examiner quatre modèles populaires de transformeurs de séries temporelles de fondation :
Chronos
Chronos est une famille de modèles de prévision de séries temporelles open-source pré-entraînés d'Amazon. Ces modèles adoptent une approche relativement naïve de la prévision en interprétant une série temporelle comme un langage spécialisé avec ses propres modèles de relations entre les tokens. Malgré cette approche relativement simpliste qui inclut la prise en charge des valeurs manquantes mais pas des variables externes, la famille de modèles Chronos a démontré des résultats impressionnants en tant que solution de prévision à usage général (Figure 1).

Figure 1. Métrique d'évaluation pour Chronos et divers autres modèles de prévision appliqués à 27 ensembles de données de référence (provenant de https://github.com/amazon-science/chronos-forecasting)
TimesFM
TimesFM est un modèle de fondation open-source développé par Google Research, pré-entraîné sur plus de 100 milliards de points de séries temporelles réels. Contrairement à Chronos, TimesFM inclut des mécanismes spécifiques aux séries temporelles dans son architecture qui permettent à l'utilisateur d'exercer un contrôle granulaire sur la manière dont les entrées et les sorties sont organisées. Cela a un impact sur la façon dont les modèles saisonniers sont détectés, mais aussi sur les temps de calcul associés au modèle. TimesFM s'est avéré être un outil de prévision de séries temporelles très puissant et flexible (Figure 2).
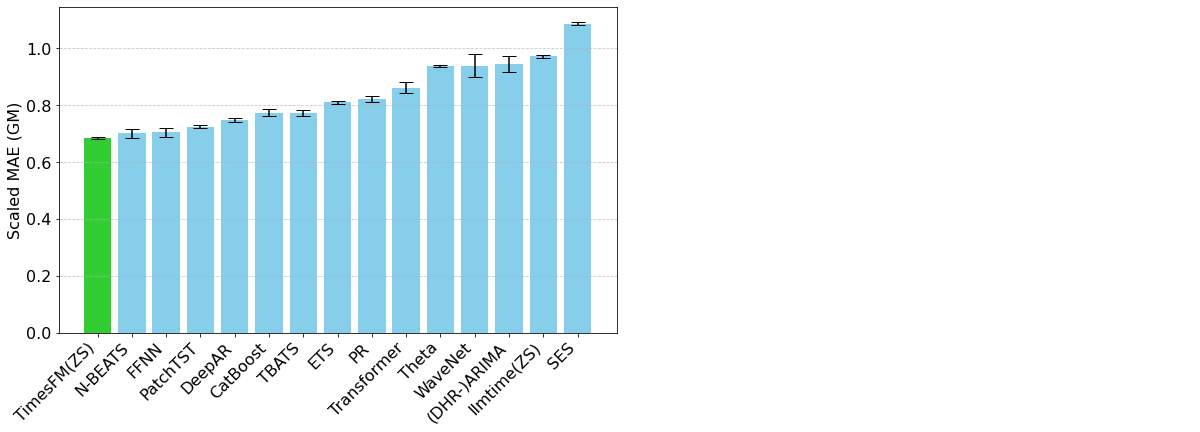
Figure 2. Métrique d'évaluation pour TimesFM et divers autres modèles par rapport au jeu de données Monash Forecasting Archive (de https://research.google/blog/a-decoder-only-foundation-model-for-time-series-forecasting/)
Moirai
Moirai, développé par Salesforce AI Research, est un autre modèle fondamental open-source pour la prévision de séries temporelles. Entraîné sur "27 milliards d'observations couvrant 9 domaines distincts", Moirai est présenté comme un prévisionniste universel capable de prendre en charge à la fois les valeurs manquantes et les variables externes. Les tailles de patch variables permettent aux organisations d'ajuster le modèle aux modèles saisonniers de leurs jeux de données et, lorsqu'ils sont appliqués correctement, ont démontré de très bonnes performances par rapport à d'autres modèles (Figure 3).

Figure 3. Métrique d'évaluation pour Moirai et divers autres modèles par rapport au Monash Time Series Forecasting Benchmark (de https://blog.salesforceairesearch.com/moirai/)
TimeGPT
TimeGPT est un modèle propriétaire prenant en charge les variables externes (exogènes) mais pas les valeurs manquantes. Axé sur la facilité d'utilisation, TimeGPT est hébergé via une API publique qui permet aux organisations de générer des prévisions avec une seule ligne de code. En comparant le modèle à 300 000 séries uniques à différents niveaux de granularité temporelle, le modèle a produit des résultats impressionnants avec une latence de prévision très faible (Figure 4).
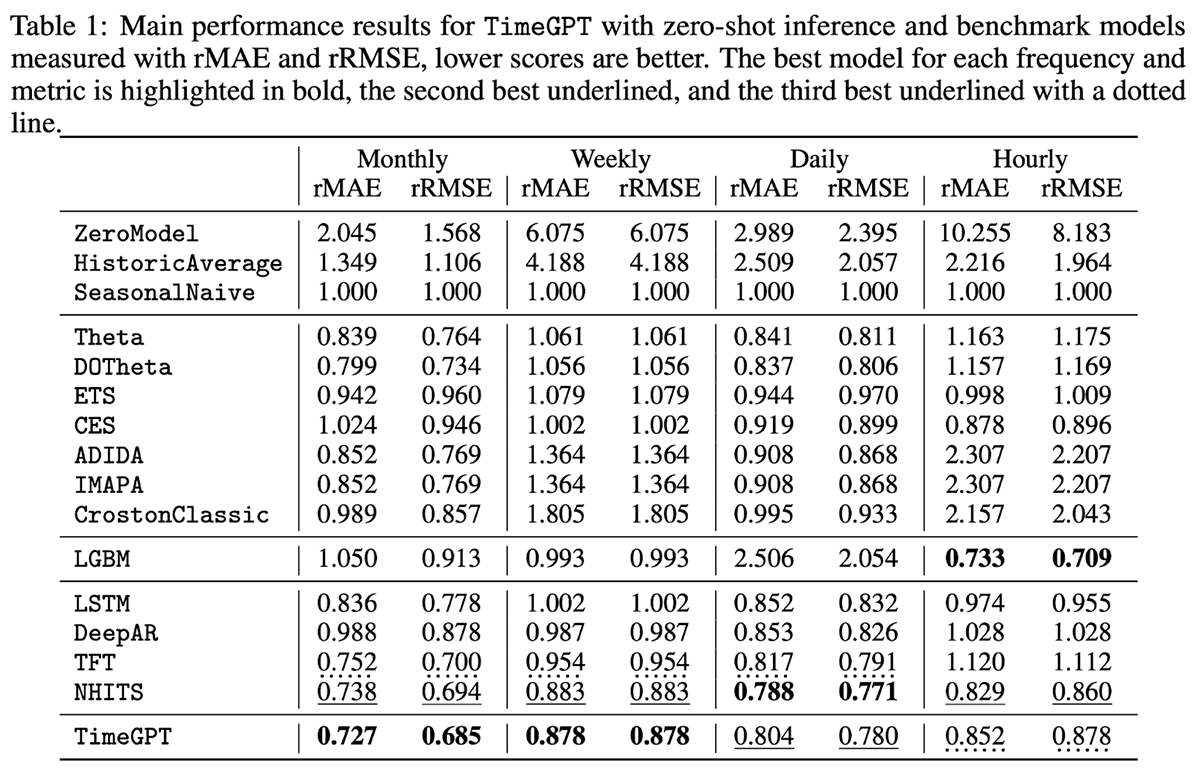
Figure 4. Métrique d'évaluation pour TimeGPT et divers autres modèles par rapport à 300 000 séries uniques (de https://arxiv.org/pdf/2310.03589)
Démarrer avec la prévision Transformer sur Databricks
Avec autant d'options de modèles et d'autres à venir, la question clé pour la plupart des organisations est : comment commencer à évaluer ces modèles en utilisant leurs propres données propriétaires ? Comme pour toute autre approche de prévision, les organisations utilisant des modèles de prévision de séries temporelles doivent présenter leurs données historiques au modèle pour créer des prédictions, et ces prédictions doivent être soigneusement évaluées et éventuellement déployées dans des systèmes en aval pour les rendre exploitables.
En raison de la scalabilité de Databricks et de son utilisation efficace des ressources cloud, de nombreuses organisations l'utilisent depuis longtemps comme base pour leurs travaux de prévision, produisant des dizaines de millions de prévisions quotidiennement, voire à une fréquence plus élevée, pour gérer leurs opérations commerciales. L'introduction d'une nouvelle classe de modèles de prévision ne change pas la nature de ce travail, elle offre simplement à ces organisations plus d'options pour le faire dans cet environnement.
Cela ne veut pas dire qu'il n'y a pas de nouvelles subtilités avec ces modèles. Basés sur une architecture de réseau neuronal profond, nombre de ces modèles fonctionnent mieux lorsqu'ils sont utilisés avec un GPU, et dans le cas de TimeGPT, ils peuvent nécessiter des appels d'API à une infrastructure externe dans le cadre du processus de génération de prévisions. Mais fondamentalement, le schéma consistant à héberger les données de séries temporelles historiques d'une organisation, à présenter ces données à un modèle et à capturer la sortie dans une table interrogeable reste inchangé.
Pour aider les organisations à comprendre comment elles peuvent utiliser ces modèles dans un environnement Databricks, nous avons assemblé une série de notebooks démontrant comment les prévisions peuvent être générées avec chacun des quatre modèles décrits ci-dessus. Les praticiens peuvent télécharger librement ces notebooks et les utiliser dans leur environnement Databricks pour se familiariser avec leur utilisation. Le code présenté peut ensuite être adapté à d'autres modèles similaires, offrant aux organisations utilisant Databricks comme base pour leurs efforts de prévision des options supplémentaires pour utiliser l'IA générative dans leurs processus de planification des ressources.
Commencez dès aujourd'hui avec Databricks pour la modélisation prédictive grâce à cette série de notebooks.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.