Démarrez rapidement votre modélisation des données avec les modèles de données sectoriels Databricks
Des modèles de données préconstruits, validés par des règles et prêts pour la couche Silver pour les 40 plus grands secteurs au monde — prêts à être déployés et gouvernés sur la plateforme Databricks.
par Amr Ali, Drew Triplett, Franco Patano et Shelley Shaffery
- Plus de 40 modèles de données sectoriels, prêts dès aujourd'hui. Des modèles de couche Silver préconstruits et validés par des règles pour 40 secteurs, dans deux portées (MVM et ECM) — à déployer tels quels ou à personnaliser.
- Un ensemble complet d'artefacts gouvernés. Livré sous la forme d'un seul fichier model.json (plus SQL DDL, DBML, ontologie) qui se déploie dans Unity Catalog avec des tables Delta, des clés étrangères, des balises de classification et des vues de métriques.
- Déployez en quelques heures. Pointez model.json vers un Unity Catalog, choisissez un style de catalogage et obtenez une couche Silver classifiée et validée par FK.
Le problème des modèles de données sectoriels
Depuis trois décennies, on vend le même raccourci aux secteurs réglementés et riches en données : acheter un modèle de données sectoriel. ACORD pour l'assurance. FHIR et HL7 pour la santé. ARTS pour le commerce de détail. Des centaines — parfois des milliers — de tables, publiées par un organisme de normalisation ou un fournisseur, présentées comme un an de travail condensé dans une seule licence.
L'argument est séduisant. La réalité est plus douloureuse. Un modèle de données sectoriel est la moyenne de toutes les entreprises d'un secteur. Il ne connaît pas vos gammes de produits, vos zones géographiques, vos contraintes réglementaires, vos systèmes existants, vos habitudes de nommage ou la structure de votre organisation — il ne sait pas ce qui différencie votre entreprise. Les équipes héritent de centaines de tables qu'elles ne rempliront jamais, de conventions de nommage qui ne correspondent pas à leur terminologie et de relations dont leurs charges de travail n'ont pas besoin. La majeure partie de la valeur de l'achat d'un modèle est consacrée à le nettoyer, le renommer et le réorganiser — ce qui est exactement le travail que le modèle était censé éviter.
Un modèle de données analytique solide, de ceux qui exécutent réellement des analyses en production et du ML, a historiquement nécessité des mois, voire des années de développement.
Nous publions quelque chose de différent. Une bibliothèque de modèles de données sectoriels Lakehouse pré-intégrés, disponible dès aujourd'hui dans un dépôt public, prête à être déployée en tant que couche Silver de votre Databricks pour les 40 plus grands secteurs au monde. Chaque modèle de données sectoriel est proposé en deux versions et repose sur un ensemble de règles structurelles strictes comprenant plus de 200 règles réparties dans 14 domaines de modélisation différents, ce qui rend le résultat opérationnel pour la production dès le premier jour. De plus, ces modèles de données ne sont ni rigides ni figés : vous pouvez les faire évoluer et les personnaliser pour les adapter aux besoins de votre organisation.
Où se situent ces modèles de données dans le Lakehouse
Dans une architecture médaillon Databricks, le niveau Bronze contient les données brutes, le niveau Silver contient le modèle de base analytique conforme auquel se connectent tous les analystes, outils de BI et data scientists, et le niveau Gold contient les métriques dérivées, les KPI et les agrégats.
Ces modèles de données de base constituent la couche Silver. Lakeflow et Auto Loader gèrent l'ingestion. Chaque modèle est fourni avec des métriques précalculées telles que churn_score ou monthly_revenue_summary. Le modèle de base est le fondement analytique : l'endroit où les concepts de l'entreprise se transforment en tables fiables, prêtes pour les outils de BI, les pipelines de fonctionnalités et les agrégats en aval.
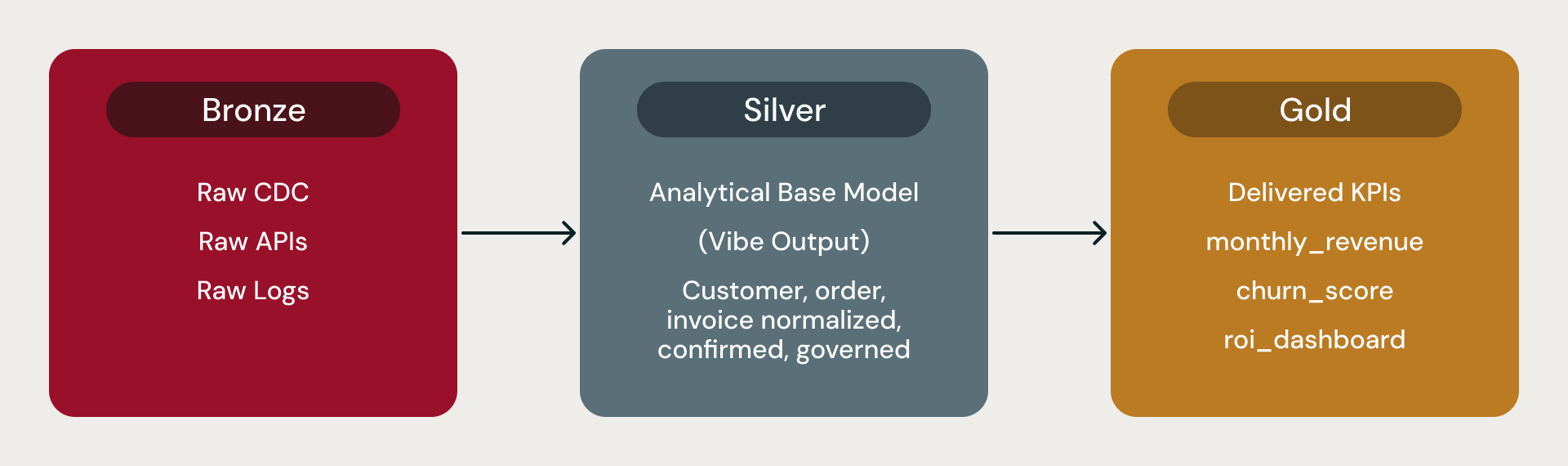
Bronze, Silver, Gold
Deux portées : MVM et ECM
Chaque modèle de base est publié dans deux portées. Les deux se déploient à partir du même fichier logique model.json, suivent les mêmes règles et présentent la même profondeur d'attributs par table. La différence réside dans la largeur de couverture.
Minimum Viable Model (MVM). Trente à cinquante pour cent du nombre de tables de l'ECM. Fonctions métier essentielles uniquement. Idéal pour les SMB, les déploiements rapides, les preuves de concept et les MVP. Un MVM n'est pas un squelette ou un jouet de démonstration — chaque table possède la même richesse d'attributs que son équivalent ECM. La légèreté provient d'un nombre réduit de domaines et de tables, jamais de tables simplifiées.
Expanded Coverage Model (ECM). Couverture complète. Toutes les divisions, y compris le back-office de l'entreprise. Tous les domaines qu'un modèle Fortune 100 exigerait. Largeur de couverture maximale.
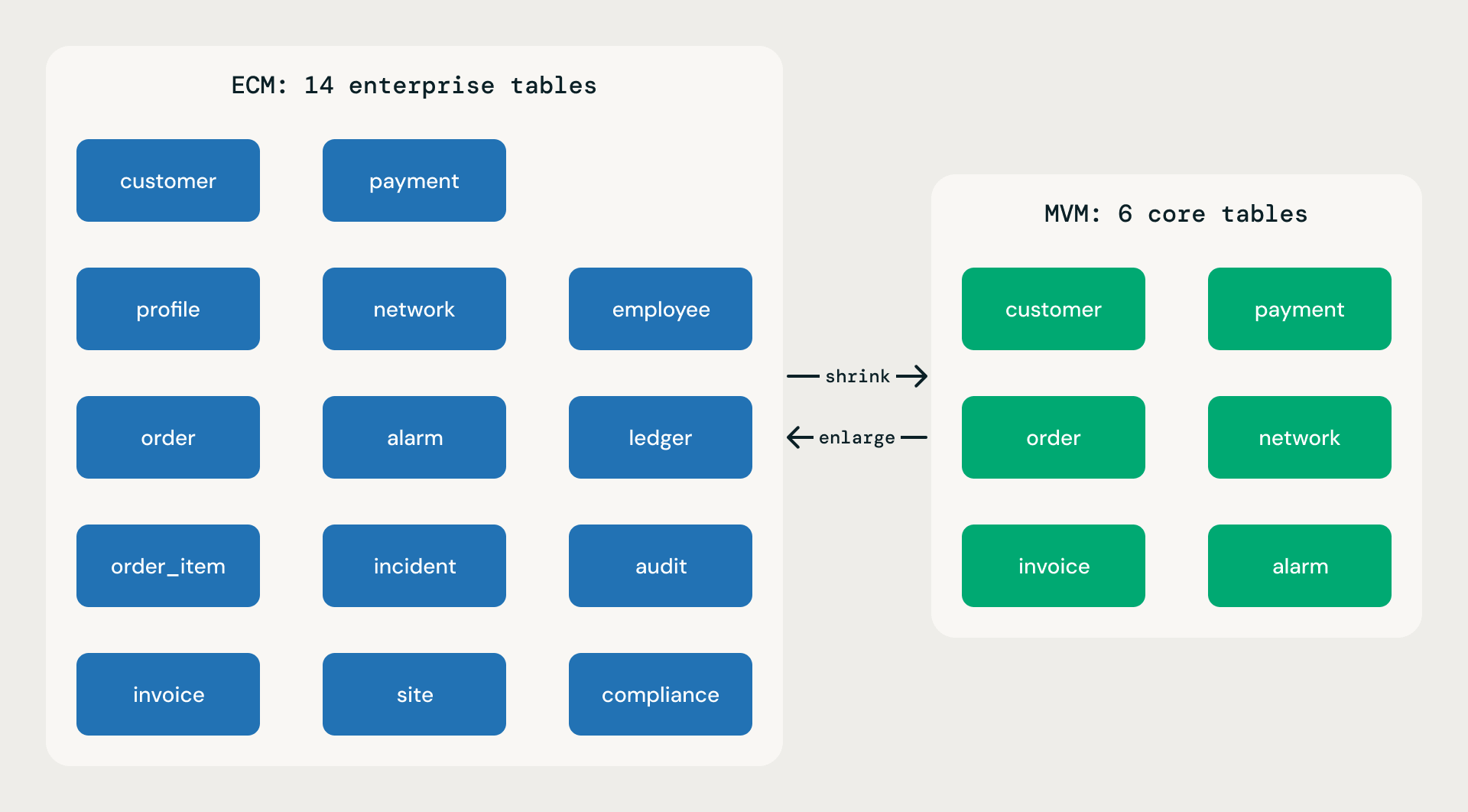
Portée MVM vs ECM
Pourquoi ces deux portées sont-elles importantes ? L'objectif n'est pas que les organisations passent du temps à adapter le modèle à leurs données métier, mais plutôt de démarrer rapidement les analyses sur le Lakehouse. Choisir la bonne portée dès le départ permet donc de gagner un temps précieux.
Les deux portées ne constituent pas des lignes de maintenance distinctes. L'une peut être dérivée de l'autre via une seule transformation : shrink ecm produit un sous-ensemble MVM qui protège les produits de base et conserve les clés étrangères essentielles ; enlarge mvm fait l'inverse. Aucune version n'est jamais écrasée — les deux opérations créent une nouvelle version numérotée aux côtés de l'originale.
Ce qui différencie ces modèles
Les modèles de base que nous publions ne sont pas de simples modèles sectoriels standards renommés par un comité. Ils sont produits par un agent IA rigoureux et guidé par des règles, qui garantit la qualité structurelle à chaque étape de la modélisation. Voici quelques points forts :
Dimensionnement par niveau sectoriel. Chaque modèle est dimensionné en fonction de la complexité réelle de son secteur. Le classificateur utilise sept dimensions — la densité réglementaire, la complexité des parties prenantes, la profondeur de la hiérarchie des produits, la gestion des infrastructures, le modèle canonique du secteur, la complexité des transactions et le paysage des systèmes opérationnels — pour classer chaque secteur dans l'un des cinq niveaux, ce qui détermine ensuite le nombre de domaines, de produits par domaine et la profondeur des attributs.
| Niveau | Label | Caractéristiques | Domaines MVM | Produits/Domaine ECM |
|---|---|---|---|---|
| tier_1 | Ultra-complexe | Banque, assurance, grande pharma | 15–22 | 14–28 |
| tier_2 | Complexe | Télécoms, énergie, santé | 12–18 | 14–26 |
| tier_3 | Modéré | Manufacture, commerce de détail | 10–15 | 12–24 |
| tier_4 | Standard | Logistique, agriculture | 8–12 | 10–20 |
| tier_5 | Simple | Conseil, SaaS, médias | 5–8 | 8–18 |
Jargon spécifique au secteur. Chaque modèle utilise la terminologie réellement employée dans son secteur. Les télécoms obtiennent msisdn, arpu, imsi, cdr. L'exploitation minière obtient rom, cut_off_grade, jorc. La santé obtient icd, cpt, drg. La banque obtient iban. Ce ne sont pas des détails secondaires : ils façonnent le nom des colonnes, les conventions de clés primaires et la structure des balises de gouvernance.
La structure en trois divisions. Chaque modèle est organisé en trois cercles concentriques :
- Operations représente l'activité physique de l'entreprise — réseau, flotte, usine, infrastructure.
- Business représente ceux qu'elle sert et comment elle génère des revenus — client, facturation, produit, ventes.
- Corporate représente la structure de soutien — HR, finance, conformité.
Le ratio est imposé par des règles (règle G06-R001) : Operations plus Business doivent représenter au moins 80 % de tous les domaines ; Corporate est limité à 20 %. Cela évite l'écueil le plus courant de la modélisation non contrainte — des modèles composés à moitié de HR, de finance et de juridique, et trop légers sur le cœur opérationnel qui fait réellement tourner l'entreprise.
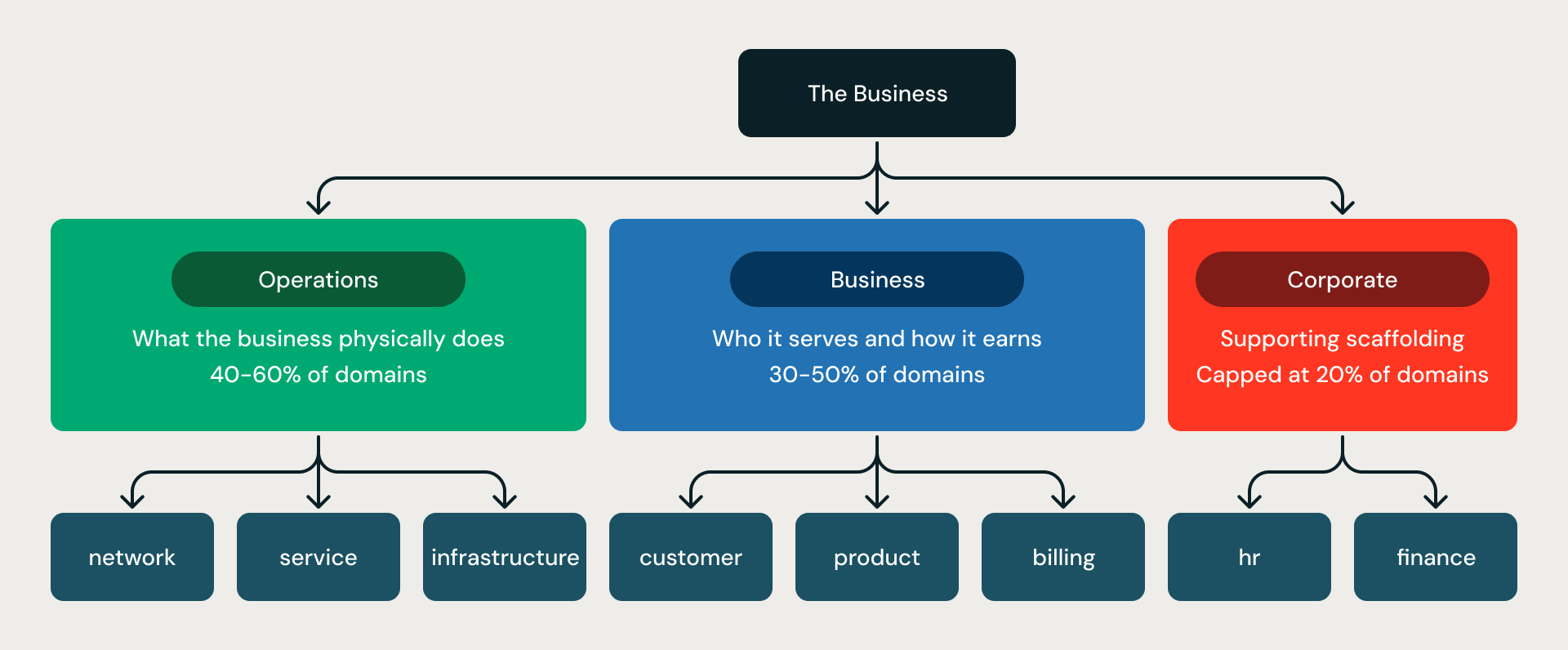
Les trois divisions
La hiérarchie à six niveaux. Chaque modèle suit la même structure stricte : Organisation → Division → Domaine → Sous-domaine → Produit → Attribut. La hiérarchie n'est pas une simple suggestion ; elle est imposée par des règles structurelles, par deux niveaux de révision par des architectes et par une analyse statique à la fin de chaque pipeline.
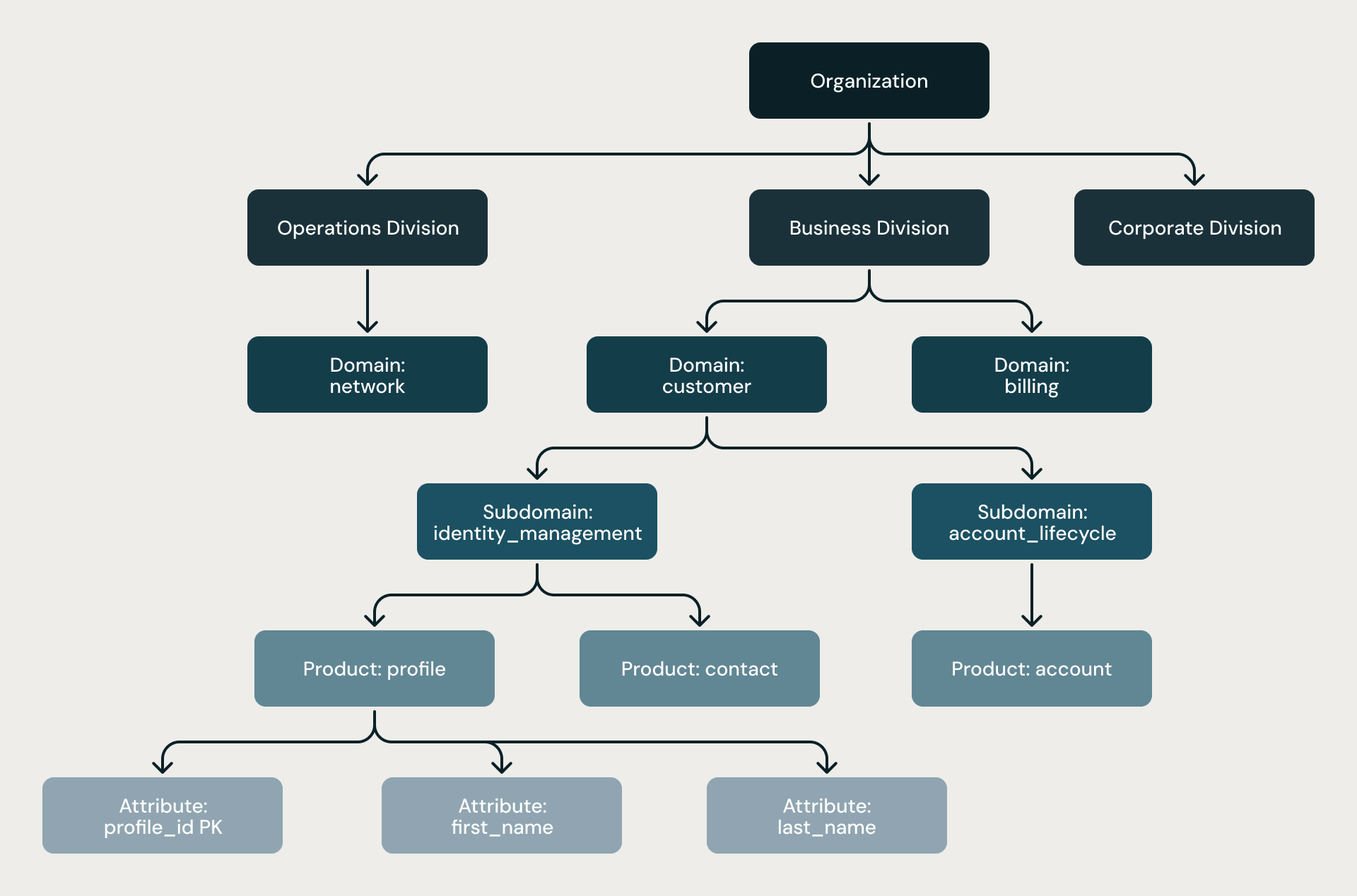
Hiérarchie à quatre niveaux
Plus de 200 règles applicables. Chaque modèle de base est validé par rapport à plus de 200 règles organisées en plus de 14 groupes — conventions de nommage, déduplication sémantique, clés étrangères, clés primaires, normalisation, structure de domaine, types de données, balises de classification, application des relations/DAG, qualité, conception de produit, contraintes d'ambiance, déploiement de schéma physique et dimensionnement des sous-domaines. Chaque table doit avoir une clé primaire. Chaque clé étrangère doit pointer vers une cible réelle. Chaque domaine doit passer le test de l'organigramme : « Un vrai département ou une vraie équipe portant ce nom pourrait-il exister dans l'organisation ? » Pas de cycles. Pas de silos, et un respect strict du principe de Single Source Of Truth (SSOT).
Un modèle logique, trois configurations physiques. Chaque modèle de base est fourni sous la forme d'un fichier model.json unique, indépendant de l'environnement. Le même modèle logique se déploie proprement dans Unity Catalog selon trois styles de catalogage : un seul catalogue (limite de gouvernance unique), un catalogue par division (Operations / Business / Corporate isolés) ou un catalogue par domaine (adapté au data mesh). Le redéploiement vers un style différent ne modifie en rien le modèle logique.
Exemple concret : le modèle ECM pour le secteur aérien v1
Pour rendre cela concret, voici l'ECM pour le secteur aérien disponible dès aujourd'hui dans le dépôt.
| Métrique | Valeur |
|---|---|
| Portée du modèle | ECM v1 |
| Nombre total de domaines | 19 |
| Nombre total de sous-domaines | 60 |
| Nombre total de produits | 420 |
| Nombre total d'attributs | 17 278 |
| Clés primaires | 420 |
| Clés étrangères | 2 877 |
| Nombre moyen d'attributs/produit | 41,1 |
| Vues de métriques | 203 |
Visualisé sous forme de graphique, le DAG complet ressemble à ceci (chaque rectangle est un domaine, chaque petit cercle est une table et chaque ligne est un lien FK) :

Airline ECM v1 en tant que DAG connecté
Les dix-neuf domaines se répartissent clairement entre les trois divisions. Operations contient airport, crew, fleet, flight, inventory, maintenance et route. Business contient ancillary, cargo, loyalty, passenger, reservation, revenue, service et ticket. Corporate contient compliance, finance, safety et workforce.

Domaines aériens par division
Explorez un seul domaine — flight operations — et la structure devient lisible au niveau opérationnel. Les sous-domaines pour le chargement des ressources, les opérations aériennes et les services aux passagers contiennent les produits qu'un analyste des opérations utilise réellement : leg, flight_plan, oooi_event, atc_clearance, dispatch_release, notam_brief, tech_log, weight_balance, fuel_uplift, pax_segment. (chaque cercle est une table, chaque ligne est une relation FK)

Domaine Flight
Allez plus loin, jusqu'à un seul produit de données — la lettre de transport aérien (awb) au sein du domaine cargo — et vous pourrez voir exactement comment fonctionnent les liens inter-domaines. awb se connecte à corporate_account dans le domaine passenger, station dans airport, leg dans flight, profit_center, ledger_account et company_code dans finance, et screening_result dans compliance. Ce sont les jointures qu'un analyste des revenus cargo exécute chaque jour, et elles sont présentes parce que le DAG inter-domaines a été conçu pour les prendre en charge.

Produit de données Air Waybill
Ce que vous obtenez lors du déploiement
Chaque modèle de base est livré avec un ensemble complet d'artefacts.
Artefacts logiques. Un seul fichier model.json (le format d'échange principal), un fichier readme.md lisible par l'homme, des exportations plates de domaines, de produits et d'attributs, des exportations Excel et CSV, des fichiers SQL DDL (un par domaine plus un fichier FK inter-domaines), un diagramme de schéma DBML et une ontologie RDF/Turtle.
Artefacts physiques lors du déploiement sur un Unity Catalog. Des schémas Unity Catalog (un par domaine ou par sous-domaine, selon le style de catalogage), des tables Delta pour chaque produit, des contraintes de clé étrangère appliquées dans l'ordre des dépendances, des balises de classification Unity Catalog (PII, restreint, public), des vues de métriques Databricks pour des définitions de KPI réutilisables, et des données d'échantillon synthétiques avec des références FK valides pour une exploration immédiate.
Le fichier model.json est la monnaie d'échange. Enregistrez-le dans git. Comparez deux versions (diff). Partagez-le entre plusieurs environnements. Transmettez-le à un réviseur de sécurité sans donner d'accès à la production. Redéployez-le en dev, staging et prod sous trois styles de catalogage différents et obtenez trois environnements dont le contenu logique est rigoureusement identique au niveau de l'octet.
Les points forts de cette approche
- Rapidité. Les fondations de la couche Silver qui prenaient auparavant des mois se résument désormais à une étape de déploiement.
- Spécificité. Les modèles utilisent le langage du secteur — son jargon, son cadre réglementaire, sa réalité opérationnelle.
- Couverture des règles. Plus de 200 règles applicables garantissent une cohérence que la plupart des modèles écrits à la main n'atteignent jamais.
- Gouvernance. Chaque colonne contenant des données sensibles est classifiée et balisée. Chaque PK/FK suit une convention unique. Chaque style de catalogage est reproductible.
- Double nature. Le même artefact est à la fois un schéma relationnel, un diagramme DBML, une ontologie de graphe de connaissances et un déploiement physique Unity Catalog.
- Séparation logique-physique. Un seul fichier model.json, trois styles de catalogage. Redéployez avec zéro retravail.
Aspects à prendre en compte
Les modèles de base sont un point de départ, pas un livrable final. L'expertise du domaine reste essentielle — l'examen par des experts améliorera toujours un modèle d'une manière que seul un professionnel travaillant au sein de cette entreprise peut percevoir. Les sous-verticales très étroites sont moins adaptées d'emblée que les grands secteurs d'activité. Et les organisations dotées de comités stricts d'approbation des modèles de données doivent toujours soumettre les résultats à un examen ; ce qui change, c'est la rapidité de l'artefact, pas l'obligation de le gouverner.
Nous pensons que ce compromis est le bon. Un modèle de base qui se déploie en quelques heures et qui est structurellement solide constitue un meilleur point de départ qu'un modèle type qui prend un an à adapter.
Essayez-le dès aujourd'hui
Le dépôt des 40 modèles de données sectoriels Lakehouse est disponible à l'adresse https://github.com/databricks-industry-solutions/databricks-industry-data-models Chaque secteur est livré avec un MVM et un ECM. Choisissez la portée qui convient à votre organisation, pointez-la vers un Unity Catalog, et vous disposerez d'une couche Silver déployée, classifiée et validée par FK, prête pour l'analyse.
À venir
Un modèle de base est un point de départ ; c'est pourquoi tous les modèles en sont à la version v1, et ce n'est pas leur forme finale. Chaque organisation possède une terminologie, des divisions et des processus métier que même le meilleur modèle générique ne pourra pas appréhender parfaitement. Dans un prochain article, nous expliquerons comment personnaliser et faire évoluer les modèles v1 à l'aide d'un agent de modélisation IA en langage naturel — en décrivant les changements souhaités en langage naturel et en produisant une version sur mesure (v2, v3, etc.), tout en préservant la rigueur structurelle de l'original.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.