Du monolithe au Lakebase, puis au LTAP : repenser la base de données depuis le stockage
par Reynold Xin
- Presque toutes les bases de données traditionnelles conservent leur journal d'écriture anticipée (write-ahead log) et leurs fichiers de données sur le disque d'une seule machine, ce qui est la cause principale du risque de perte de données, de réplicas de lecture et de clones HA coûteux, ainsi que de requêtes analytiques qui ralentissent les transactions.
- Lakebase rend le calcul Postgres sans état (stateless) en externalisant le journal et les fichiers de données vers des services cloud indépendants (SafeKeeper et PageServer), libérant ainsi un stockage illimité, un calcul élastique, des écritures durables, une HA plus simple et un branching instantané, le tout sans latence supplémentaire significative.
- LTAP va plus loin en stockant les données opérationnelles une seule fois dans des formats colonnaires ouverts que les moteurs Postgres et Lakehouse lisent tous deux, de sorte que les analyses s'exécutent sur les mêmes données fraîches que les transactions viennent d'écrire, sans pipeline CDC, sans seconde copie et sans ralentissement de la charge de travail transactionnelle. Contrairement à HTAP, qui tente d'unifier les deux charges de travail dans un seul moteur, LTAP unifie au niveau de la couche de stockage et conserve le meilleur moteur pour chaque tâche.
Lorsque j'ai commencé mon doctorat à l'UC Berkeley il y a 16 ans, mon directeur de thèse m'a dit : « Les bases de données OLTP sont un problème résolu. Elles fonctionnent. Concentre-toi sur l'analyse de données. » Nous n'en étions qu'aux prémices de la collecte de volumes de données bien plus importants, structurées et non structurées, et de l'application de l'apprentissage automatique (que nous appelons aujourd'hui « AI »). J'ai donc suivi ce conseil et j'ai rejoint mes cofondateurs sur le projet de recherche qui est devenu Apache Spark, avant de fonder Databricks plus tard.
En développant Databricks, nous avons commencé à utiliser différentes bases de données existantes, et nous nous sommes rendu compte que les bases de données OLTP étaient loin d'être un problème résolu : elles étaient lourdes, difficiles à mettre à l'échelle et incroyablement fragiles. À un moment donné, notre frustration était telle que nous nous sommes demandé à quoi ressemblerait une base de données OLTP si nous devions la concevoir aujourd'hui. Cette question nous a menés à Lakebase, notre base de données Postgres serverless.
Cet article propose une analyse approfondie de l'architecture OLTP de Lakebase. Nous commencerons par la couche de stockage d'une base de données monolithique traditionnelle pour comprendre d'où viennent les difficultés, puis nous verrons comment Lakebase réorganise ces mêmes éléments en services indépendants et externalisés. Enfin, nous nous intéresserons à LTAP, où cette même architecture permet d'exécuter des transactions et des analyses sur une copie unique des données, en temps réel, sans les délais et les coûts supplémentaires liés au CDC ou au « mirroring ».
La base de données en tant que monolithe
La grande majorité des bases de données utilisées aujourd'hui dans le monde sont des monolithes. Cela inclut MySQL, Postgres et Oracle classique. Lakebase est basé sur Postgres (qui, soit dit en passant, est également né à Berkeley). Nous utiliserons donc Postgres comme exemple principal ici, mais la plupart des bases de données fonctionnent de manière similaire : vous provisionnez une machine qui exécute le moteur de base de données et le stockage. Dans ces systèmes de bases de données, deux éléments sur le disque sont particulièrement importants : le write ahead log (WAL) et les fichiers de données.
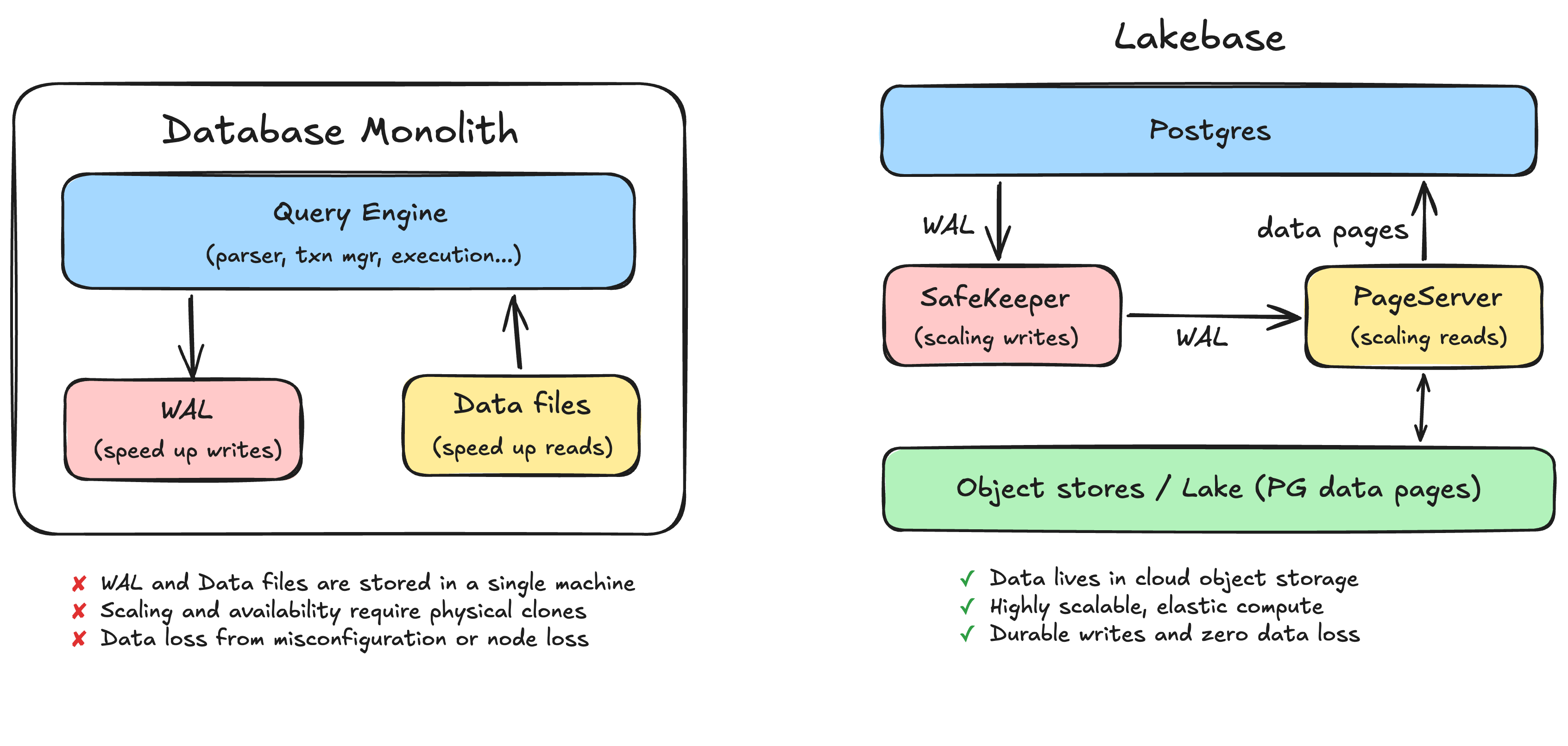
Lorsque vous validez (commit) une transaction, la base de données ne va pas immédiatement réécrire les fichiers de données. Ce processus serait lent, car les lignes que vous modifiez sont dispersées dans le fichier à des endroits qui nécessitent des I/O aléatoires. Au lieu de cela, la base de données commence par ajouter une description de la modification au WAL, qui est un journal séquentiel sur disque. Une transaction est considérée comme validée dès lors que cette entrée de journal est écrite de manière durable. Ce n'est que plus tard, de façon asynchrone, que la base de données met à jour les fichiers de données réels pour refléter le changement.
Pour simplifier : le WAL existe pour accélérer (et sécuriser) les écritures, et les fichiers de données existent pour accélérer les lectures. Le journal vous permet de valider une transaction avec un seul ajout séquentiel au lieu d'une multitude d'I/O aléatoires. Les fichiers de données vous permettent de répondre à une requête en lisant directement l'état actuel, plutôt qu'en rejouant tout l'historique de la base de données depuis le début. (Si vous souhaitez comprendre tous les détails complexes de cette conception, lisez le document ARIES de 69 pages. Soyez averti qu'il s'agit de l'un des articles les plus complexes de l'informatique.)
Bien que cette conception soit devenue le fondement de la quasi-totalité des bases de données existantes, l'architecture monolithique pose également de nombreux défis :
Perte de données due à une mauvaise configuration. Une validation n'est durable que si le vidage du disque (flush) qui la soutient l'est aussi. Si la base de données, le système d'exploitation ou la couche de stockage sont configurés de manière à ce qu'une écriture dans le WAL soit confirmée au client avant d'avoir réellement été vidée sur un support durable, alors une validation peut disparaître en cas de coupure de courant ou de kernel panic. Ces paramètres sont subtils, faciles à configurer de manière incorrecte, et la défaillance est souvent silencieuse. Le système d'exploitation peut même décider de vous mentir sur le vidage du cache !
Perte de données due à la perte d'un nœud. Même avec des vidages de cache correctement configurés, le WAL et les fichiers de données résident sur une seule machine. Si le disque de cette machine tombe en panne, les données qu'il contient sont également perdues. Notez que le stockage en réseau ou les techniques de redondance comme le RAID-1/RAID-10 peuvent améliorer la durabilité, mais ne résolvent pas fondamentalement ce problème. Si le point de montage de stockage tombe en panne, votre accès aux données disparaît également.
La mise à l'échelle des lectures nécessite un clone physique. Lorsqu'un serveur ne peut plus gérer votre trafic, la réponse standard consiste à ajouter un réplica en lecture. En effet, un réplica en lecture est une copie physique complète de l'intégralité de la base de données, qui reçoit le flux du WAL depuis le nœud principal et le rejoue. En provisionner un implique de copier l'ensemble du jeu de données, puis de rattraper le retard du journal. Pour une grande base de données, cette opération n'est pas rapide et peut même provoquer l'arrêt de la base de données.
La haute disponibilité nécessite également un clone physique. Survivre à la perte du nœud principal implique d'exécuter au moins un nœud de secours (standby) supplémentaire, qui est lui-même une copie physique complète de la base de données maintenue synchronisée à partir du WAL. Vous payez pour au moins deux fois plus d'infrastructures, vous attendez longtemps pour mettre un nœud de secours en ligne, et vous devez configurer une réplication synchrone pour éviter de perdre des données en cas de panne du nœud principal. (En pratique, beaucoup recommandent 3 nœuds ou plus.)
Les analyses entrent en concurrence avec votre trafic transactionnel. Une requête analytique lourde s'exécute sur les mêmes ressources matérielles que votre charge de travail transactionnelle sensible à la latence. Une seule grande requête de rapport ou un nettoyage GDPR peut dégrader vos requêtes OLTP principales. Vous pouvez exécuter les requêtes analytiques sur un réplica distinct, mais vous finissez par payer pour ce réplica sans pour autant obtenir des performances optimales en raison de la nature orientée lignes du stockage OLTP (l'analyse nécessite un stockage orienté colonnes pour de hautes performances).
Presque chacun de ces problèmes remonte à la même cause racine de l'architecture monolithique : le WAL et les fichiers de données sont stockés dans une seule machine. La durabilité est liée au disque de cette machine. La mise à l'échelle et la disponibilité nécessitent de cloner physiquement cette machine. Les charges de travail interfèrent car elles partagent cette même machine.
Architecture de Lakebase
Si vous deviez reconcevoir une base de données OLTP aujourd'hui, vous commenceriez par les composants du cloud moderne : un stockage d'objets cloud économique et hautement durable, associé à du calcul élastique. C'est la voie choisie par l'équipe Neon et le fondement de ce qui est devenu Lakebase.
L'étape essentielle consiste à rendre les instances de calcul Postgres sans état (stateless). Pour ce faire, nous externalisons le WAL et les fichiers de données des disques locaux vers des services dédiés et évolutifs de manière indépendante. La couche de calcul devient un moteur Postgres sans état qui peut être démarré, arrêté et répliqué librement, car il ne possède plus les données.
Voyons comment ces deux services de stockage peuvent collaborer pour résoudre les défis mentionnés ci-dessus sans sacrifier les performances.
Mise à l'échelle des écritures : le WAL devient SafeKeeper
Dans un monolithe, une écriture est rendue durable par son vidage (flush) sur le disque local. Dans Lakebase, le WAL est externalisé vers un service de stockage distribué appelé SafeKeeper. Au lieu de s'appuyer sur le vidage du disque pour la durabilité, une validation (commit) est rendue durable en répliquant l'enregistrement du journal sur un quorum de nœuds SafeKeeper à l'aide d'une réplication réseau basée sur Paxos. Il n'y a plus de disque dont la panne entraînerait la perte de vos données, et il n'y a plus de vidage mal configuré compromettant discrètement votre garantie de durabilité.
Il est naturel de se demander à ce stade : le fait de déplacer les validations du WAL sur disque local vers le WAL sur SafeKeeper augmente-t-il la latence d'écriture en raison du saut réseau supplémentaire ? La réponse est non. Pour tout déploiement Postgres sérieux soucieux de durabilité et de disponibilité, vous devriez configurer une réplication synchrone qui nécessite ce saut réseau supplémentaire. Ainsi, l'externalisation du WAL dans SafeKeeper n'entraîne pas de surcoût. En réalité, en raison du fonctionnement interne de Postgres, la combinaison de SafeKeeper et de PageServer peut permettre d'obtenir un débit d'écriture 5 fois plus rapide et une latence de lecture 2 fois plus faible.
Mise à l'échelle des lectures : les fichiers de données deviennent PageServer
Les fichiers de données sont déplacés vers un autre service de stockage distribué appelé PageServer. Le WAL est transmis en continu depuis le SafeKeeper vers le PageServer, et le PageServer applique de manière asynchrone ces modifications à sa version des données, matérialisant les pages dans un stockage d'objets cloud économique (le lake). Vous pouvez considérer le PageServer comme un cache write-through pour le stockage d'objets sous-jacent.
C'est similaire à la relation WAL-puis-fichiers-de-données du monolithe, sauf que les deux parties résident désormais dans des services distincts, évolutifs de manière indépendante et connectés par le réseau, au lieu de se trouver sur le même disque. Lorsqu'une page est demandée au PageServer, et si le PageServer ne dispose pas encore de la dernière version (gardez à l'esprit que les modifications sont d'abord écrites dans le SafeKeeper avant de parvenir au PageServer), le PageServer applique les journaux du SafeKeeper pour reconstruire le dernier état.
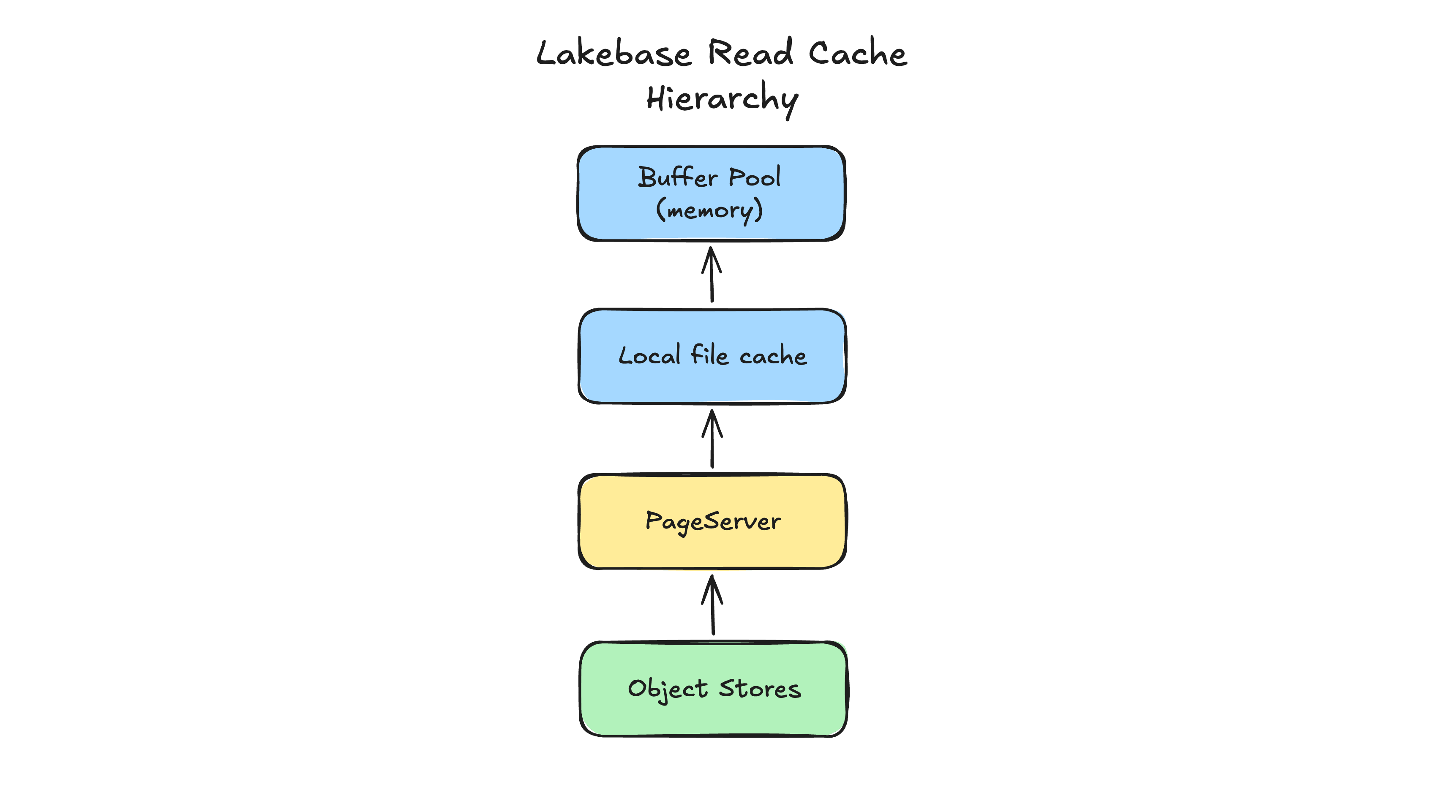
Une question similaire se pose : le déplacement des fichiers de données des disques locaux vers le PageServer augmente-t-il la latence de lecture en raison du saut réseau supplémentaire ? La réponse est également non dans la pratique. Le système est conçu pour isoler et minimiser l'impact sur la latence grâce à une mise en cache agressive et multicouche. Pour récupérer une page, Postgres recherche d'abord dans son buffer pool, qui se trouve dans la mémoire locale du nœud. Lorsque la page n'est pas présente, il interroge un cache de disque local. Il n'a besoin de s'adresser au PageServer qu'en cas de défaut de cache. Comme un nœud de calcul peut être configuré avec des capacités de mémoire locale et de disque identiques à celles d'une configuration monolithique, votre taux de réussite du cache local reste inchangé. Pour la grande majorité des opérations, la latence de lecture est impossible à distinguer de celle d'un monolithe, mais vous bénéficiez d'un stockage découplé et virtuellement infini.
Ce que cela permet de réaliser
Une fois que le WAL réside dans le SafeKeeper et les fichiers de données dans le PageServer, une longue liste de fonctionnalités qui étaient difficiles, voire impossibles à réaliser avec le monolithe, découlent naturellement de cette architecture. Les fonctionnalités suivantes sont déjà largement disponibles dans le cadre du produit Lakebase sur Databricks et Neon :
Toujours Postgres. Il s'agit du vrai Postgres, donc le protocole réseau, le SQL, les pilotes et les extensions fonctionnent tous tels quels.
Stockage illimité. Les données résident dans un stockage d'objets cloud plutôt que sur un disque local provisionné. Vous n'avez plus besoin de dimensionner une machine en fonction d'une limite de capacité. Le stockage est, dans la pratique, infini.
Calcul serverless et élastique. Le calcul étant sans état (stateless), il peut s'adapter instantanément à la charge et redescendre jusqu'à zéro en cas d'inactivité. Vous ne payez plus pour une grande machine qui attend passivement du trafic.
Écritures durables et zéro perte de données. Un commit est durable une fois qu'il est répliqué sur les nœuds SafeKeeper via Paxos, et non lorsqu'un seul disque local prétend l'avoir vidé (flushed). La perte d'un nœud individuel n'entraîne pas la perte des données validées.
Haute disponibilité plus simple. Dans le monolithe, la HA signifiait maintenir un second clone physique complet, payer deux fois, et risquer tout de même une perte de données lors du basculement. Ici, l'état durable réside déjà dans une couche de stockage répliquée qui est indépendante de toute instance de calcul unique. Le basculement ne consiste plus à promouvoir une copie physique distincte de la base de données en espérant que le dernier segment du journal ait été transmis.
Création de branches, clonage et restauration instantanés. C'est mon option préférée. Pour le code, la création d'une branche est une copie entièrement isolée de l'ensemble de la base de code qui prend moins d'une seconde, et nous le faisons des dizaines de fois par jour sans y penser. Pour une base de données monolithique, le clonage consiste à copier physiquement l'ensemble du jeu de données, ce qui est lent, coûteux et risqué pour le système de production. Lorsque les données résident dans une couche de stockage externalisée et versionnée, une branche ou un clone est une opération de métadonnées plutôt qu'une copie physique. Vous pouvez créer une branche d'une grande base de données de production en quelques secondes, y exécuter une expérience ou une migration risquée, puis la supprimer. La restauration à un instant précis (point-in-time recovery) fonctionne de la même manière. La base de données évolue enfin aussi vite que votre code.
Séparer le calcul du stockage n'est pas nouveau en soi. Le post précédent abordait les bases de données cloud de génération 2 qui l'avaient fait. Cependant, l'élément clé avec Lakebase est que nous stockons les données opérationnelles sur du stockage d'objets standard dans un format ouvert. Grâce à cela, nous offrons la possibilité à d'autres moteurs de les lire directement, ce qui mène à l'LTAP.
LTAP : une seule copie pour les transactions et les analyses
Tout ce qui a été présenté jusqu'ici visait à améliorer une base de données opérationnelle unique : plus durable, plus élastique, moins coûteuse à exploiter, plus rapide à brancher. Mais une fois que les données résident dans une couche de stockage externalisée, quelque chose de plus intéressant devient possible. Nous pouvons cesser de traiter la base de données transactionnelle et le système analytique comme deux mondes distincts.
Revenons un instant au PageServer. Il prend déjà le flux de modifications du WAL et matérialise de manière asynchrone les pages dans le stockage d'objets. Cette étape de matérialisation, le moment où les données arrivent dans le lake, s'avère être exactement l'endroit idéal pour résoudre un problème bien plus ancien…
Même avec un Lakebase, les données dans le stockage d'objets étaient toujours écrites dans le format de page natif de Postgres, disposées ligne par ligne. Ce format est excellent pour les transactions mais peu adapté aux analyses. Ainsi, tout moteur analytique souhaitant les lire devait soit payer un coût de conversion à chaque lecture, soit, plus couramment, s'appuyer sur une copie distincte des données maintenue synchronisée par un pipeline. Le pipeline peut �être fragile, et les deux copies des données peuvent devenir un cauchemar de gouvernance avec des autorisations divergentes.
Nous avons récemment annoncé LTAP, pour Lake Transactional/Analytical Processing, qui élimine le problème des deux copies de données. L'idée clé est d'unifier les deux mondes au niveau de la couche de stockage plutôt qu'au niveau de la couche de moteur. Nous n'essayons pas de concevoir un moteur unique qui serait performant à la fois pour les transactions et les analyses. Nous conservons le meilleur outil pour chaque tâche : Postgres, avec une sémantique ACID complète pour les transactions, et les moteurs Lakehouse pour les analyses. Ce qui change, ce sont les données sous-jacentes. Au lieu de deux copies dans deux formats différents, il y a une seule copie durable, dans des formats colonnaires ouverts comme Delta et Iceberg, stockée sous forme de Parquet, que les deux parties lisent (avec différents niveaux de caches pour de meilleures performances).
Matérialisation sous forme colonnaire
Remarque : cette section nécessite plus de connaissances internes sur Postgres pour être comprise que les autres sections.
À mesure que le PageServer matérialise les pages dans le stockage d'objets, il transcode les données Postgres d'un format en lignes vers la disposition colonnaire de Parquet lorsqu'elles arrivent dans le lake. Nous préservons la représentation Postgres exacte de chaque valeur, jusqu'au niveau des bits, afin que tout moteur compatible avec Postgres puisse la réinterpréter sans perte d'informations. Cela diffère d'une approche basée sur le CDC, car le CDC envoie un flux d'événements de modification logique dans un schéma externe et abandonne la sémantique physique et transactionnelle de Postgres ; ici, nous la conservons. Grâce à un moteur hyper-optimisé, le CPU disponible dans la couche PageServer effectue le transcodage de ligne à colonnaire dans le cadre de la matérialisation des données dans le stockage d'objets, de sorte qu'il n'ajoute aucune charge au calcul Postgres qui gère vos transactions. Pour servir efficacement les lectures transactionnelles, le PageServer matérialise toujours les pages traditionnelles basées sur les lignes dans un cache local, mais il s'agit strictement d'un cache de performance. Le stockage durable sous-jacent reste unifié dans le lake, accessible par les deux parties.
La préservation de la sémantique Postgres sous forme colonnaire repose sur deux éléments : le système de types et le multi-versionnage.
Système de types. La majorité des types Postgres s'associent directement aux types natifs de Parquet. Les quelques valeurs sans équivalent colonnaire sans perte (par exemple, NaN et ±Infinity, les types NUMERIC au-delà de la plage décimale, les types exotiques ou d'extension) ne sont ni supprimées ni contraintes. Elles sont transportées aux côtés des colonnes d'origine dans un champ de dépassement (overflow) structuré au sein de la même table, contenant le texte Postgres canonique pour ces valeurs. Ce champ est à la fois directement interrogeable par n'importe quel moteur et suffisant pour reconstruire exactement les octets Postgres d'origine au retour.
Multi-versionnage. Dans Postgres, chaque version de ligne qu'une transaction pourrait observer est conservée, ce qui permet précisément l'isolation des instantanés (snapshots) et la restauration à un instant précis (PITR). En revanche, les formats de table ouverts exposent des instantanés cohérents à l'échelle de la table sans aucune version de ligne intermédiaire. Nous bénéficions des avantages des deux approches en séparant la durabilité de la visibilité. Chaque ligne matérialisée sous forme colonnaire porte son adresse physique de tas (heap) (bloc et décalage), de sorte que les pages de tas restent entièrement reconstructibles. La page de tas Postgres classique devient un cache qui accélère les lectures ponctuelles, tandis que la source de vérité durable réside dans les fichiers colonnaires du stockage d'objets. Les index Postgres ne sont pas transcodés en colonnes ; ils sont servis et reconstruits à partir de ce niveau de cache chaud. Les versions de lignes intermédiaires sont conservées pour préserver la sémantique MVCC de Postgres et le PITR, mais elles ne sont pas visibles pour les lecteurs Iceberg/Delta et sont finalement nettoyées par le garbage collector. Résultat net : les moteurs analytiques voient des tables propres et cohérentes au niveau des instantanés, tandis que le système Postgres sous-jacent voit toujours un historique complet des versions permettant le voyage dans le temps (time-travel).
Il y a également un effet secondaire positif. Les données colonnaires se compressent beaucoup mieux que les données en ligne, souvent plus de dix fois mieux. Ainsi, la conversion vers un stockage colonnaire réduit considérablement le volume de données traversant le réseau entre la couche de mise en cache et le stockage d'objets, au point que cela devient souvent négligeable. Le format qui accélère les analyses rend également le chemin de stockage plus économique. Nous en profitons même pour effectuer une double écriture au format ligne et au format colonnaire dans les stockages d'objets pour la vérification des données pendant la phase de déploiement transitoire de LTAP (car nous voulons être extrêmement prudents avec les modifications de stockage).
Lire les dernières données sans affecter Postgres
L'un des grands défis est la fraîcheur des données. Si les analyses lisent à partir d'une copie dans le lac, comment voient-elles les données validées il y a un instant et qui n'ont pas encore été matérialisées dans le stockage d'objets ? C'est la question qui fait échouer la plupart des conceptions de type « il suffit de pointer les analyses vers le lac ». Il est donc utile de détailler comment LTAP y répond.
Lorsqu'une requête analytique démarre (par exemple, à partir du produit Lakehouse//RT que nous venons d'annoncer), elle demande d'abord à Postgres le LSN actuel, le numéro de séquence de journal (log sequence number) qui marque la position exacte dans le WAL à partir de laquelle lire. Il s'agit d'une recherche de métadonnées peu coûteuse. Avec ce LSN, le moteur analytique lit la grande majorité des données, y compris tout ce qui est déjà matérialisé jusqu'à ce point, directement depuis le stockage d'objets. Le seul reste est le petit ensemble de modifications très récentes qui n'ont pas encore été matérialisées dans le lac, qu'il récupère auprès du PageServer et fusionne par-dessus.
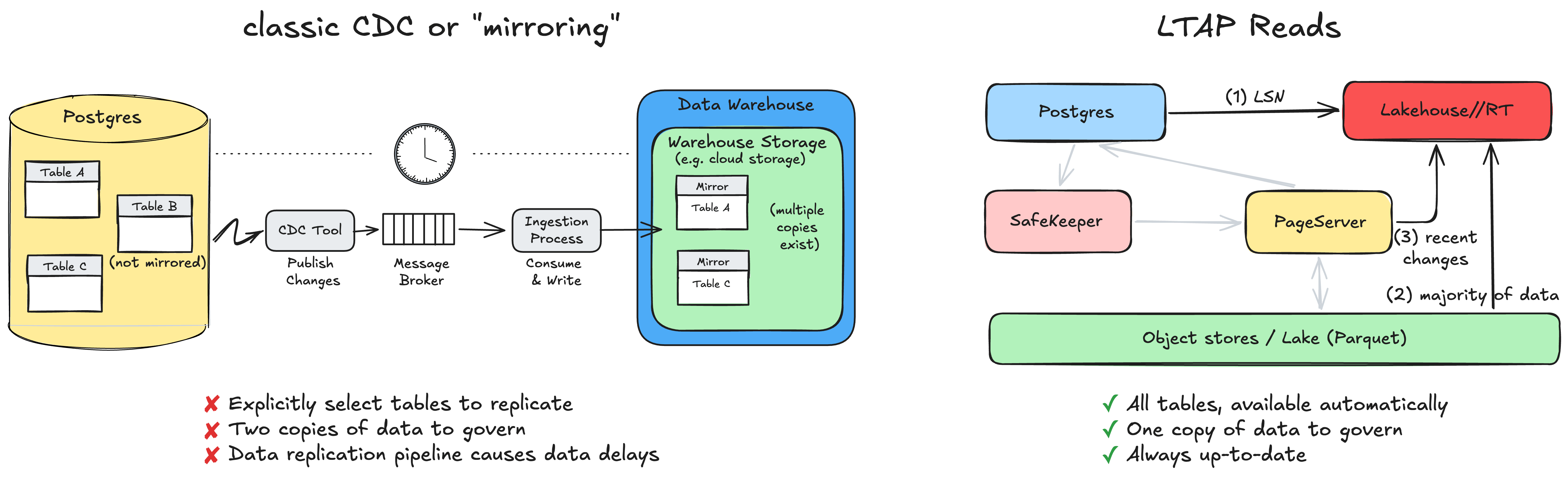
Le résultat est une lecture cohérente et entièrement à jour de vos données à la date de ce LSN. Presque tout le travail repose sur un stockage d'objets économique et évolutif. De plus, Postgres lui-même ne gère aucun trafic de lecture analytique, si ce n'est le retour d'un numéro unique (LSN). Votre charge de travail transactionnelle ne ralentit pas parce que quelqu'un a lancé une requête analytique volumineuse.
Il y a une optimisation pratique qui mérite d'être mentionnée ici : pour les très petites tables, celles qui ne contiennent qu'une poignée de lignes, nous ne prenons pas la peine de les convertir au format colonnaire ni de créer les métadonnées Iceberg associées. La gestion administrative coûterait plus cher qu'elle ne rapporterait, et une table aussi petite n'a aucun effet mesurable sur les performances analytiques, quelle que soit sa disposition. Ces tables sont toujours présentes et peuvent toujours être interrogées dans le cadre de la copie unique.
Chaque table, automatiquement
En raison de l'importance de ce problème, le marché a beaucoup parlé de l'intégration de l'OLTP et de l'analyse. Une approche classique est la CDC, qui consiste à répliquer les données du stockage OLTP vers un niveau de stockage analytique distinct. Vous en avez peut-être entendu parler sous d'autres noms tels que « mirroring », « zero CDC » ou « zero ETL ».
Dans le cas de la CDC ou du « mirroring », comme le pipeline de réplication des données a un coût, il ne peut pas être appliqué à toutes les tables. Vous devez sélectionner explicitement les tables qui vous intéressent, et cette réplication s'accompagne généralement d'un délai.
Avec LTAP, il n'y a rien à activer. Une table existante est, par construction, déjà dans le lac et déjà interrogeable. Il n'y a pas de liste de tables répliquées ou mises en miroir, car il n'y a pas de réplication. Il existe une copie unique et gouvernée des données dans des formats ouverts, sans aucun pipeline ETL à créer, surveiller ou réparer (que ce soit par nos clients ou par nous-mêmes). Les moteurs transactionnels et analytiques évoluent indépendamment, chacun étant dimensionné pour sa propre charge de travail. Et comme il n'y a pas de mouvement de données ni de seconde copie, les deux vues ne peuvent jamais diverger : l'analyse lit toujours les mêmes données que l'application vient d'écrire.
Pour voir de plus près comment LTAP s'articule, découvrez cette démo du Data and AI Summit.
Qu'en est-il de HTAP ?
Si vous connaissez le domaine, vous avez déjà remarqué que LTAP est un clin d'œil délibéré à HTAP : hybrid transactional/analytical processing. HTAP est le Saint Graal de l'ingénierie des bases de données, visant à créer un moteur unique capable de gérer à la fois les charges de travail transactionnelles et analytiques.
En pratique, il n'existe pas de système de base de données HTAP largement adopté. Pourquoi en est-il ainsi ? À mon avis, les systèmes HTAP souffrent d'un ou plusieurs des défauts suivants :
Ensemble de fonctionnalités incomplet. Concevoir un nouveau moteur propriétaire à partir de zéro pour effectuer une seule tâche est un investissement de plusieurs années. Essayer de construire un moteur unique capable de faire le travail de plusieurs moteurs multiplie l'investissement nécessaire pour atteindre l'ensemble de fonctionnalités que les ingénieurs considèrent comme acquises dans une base de données mature. Ces systèmes sont souvent en retard sur des éléments que l'on suppose toujours présents, de l'étendue de la prise en charge de SQL (par exemple, la prise en charge des clés étrangères) à la maturité de l'optimiseur de requêtes.
Aucun écosystème. Postgres et Spark se trouvent chacun au centre d'un vaste écosystème : pilotes, extensions, outils et décennies de connaissances opérationnelles accumulées. Un tout nouveau moteur démarre en dehors de tout cela, et un moteur n'est utile que dans la mesure où l'écosystème sur lequel une équipe peut réellement s'appuyer l'est aussi.
Pas d'isolation des performances. De nombreux systèmes HTAP exécutent les transactions et les analyses sur le même matériel, de sorte que les deux charges de travail se disputent les mêmes ressources CPU et mémoire. C'est le même échec que celui que nous avons connu avec le monolithe, où une requête analytique prive de ressources la charge de travail transactionnelle.
Ces trois problèmes découlent de la même décision d'unifier les deux charges de travail au sein d'un seul moteur. Lakebase et LTAP contournent ces défis en unifiant au niveau de la couche de stockage, tout en utilisant différents moteurs de calcul pour les différentes charges de travail, tirant ainsi parti de l'ensemble de leurs fonctionnalités et du support de leur écosystème, avec une isolation complète des performances.
Le mot de la fin
Lorsque nous avons proposé l'architecture Lakebase pour la première fois l'année dernière, nous savions déjà qu'elle permettrait de débloquer un stockage illimité, un calcul élastique, des écritures durables, une HA simplifiée et un branchement instantané, d'après ce que nous avions vu avec la plateforme Neon. Tout cela a suivi presque mécaniquement une fois que le WAL a résidé dans le SafeKeeper et les fichiers de données dans le PageServer.
L'idée de LTAP est venue plus tard, après que les équipes de Neon et Databricks se sont associées pour résoudre le problème de longue date consistant à exécuter des analyses sur les données transactionnelles les plus fraîches. À mesure que nous finalisons LTAP et que nous le déployons dans les mois à venir, toutes vos tables Lakebase seront simplement disponibles pour des analyses aussi performantes que les données du Lakehouse.
Ce qui m'enthousiasme le plus, c'est ce qui nous attend. Bien que LTAP soit une étape suivante naturelle, cette même conception ouvre également de nombreuses opportunités d'optimisation pour séparer d'autres opérations de maintenance lourdes des charges de travail transactionnelles de base. Nous commençons à peine à explorer ce que cette architecture rend possible, et nous avons hâte de partager la suite avec vous.
Remerciements : Je tiens à remercier l'équipe Lakebase pour avoir concrétisé tout ce dont nous avons parlé dans ce blog, pour avoir relu cet article et pour m'avoir aidé à rester rigoureux sur les détails techniques.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.