Du Lakehouse à l'esprit numérique : bâtir un écosystème d'IA multi-agent sur Databricks Agent Bricks
Découvrez comment Edmunds a réinventé son data lakehouse en une plateforme AI multi-agent intelligente avec Agent Bricks pour l'activation, l'automatisation et l'innovation continue.
par Gregory Rokita
- Edmunds a développé un écosystème multi-agent natif AI sur Databricks Agent Bricks, passant d'un stockage de données passif à une automatisation intelligente et en temps réel pour l'ensemble des fonctionnalités d'achat de véhicules.
- Des agents spécialisés comme DataDave atteignent une précision de 95 % dans les analyses complexes, tandis que les offres marketing bénéficient de meilleurs taux de conversion grâce aux insights du lakehouse unifié.
- Cette architecture permet une automatisation évolutive, la collaboration entre agents et des expériences proactives et personnalisées, tant pour les équipes internes que pour les acheteurs de voitures.
Dans l'entreprise d'aujourd'hui, disposer d'un data lakehouse vaste et unifié est essentiel pour activer les données. Avec un lakehouse, les organisations peuvent transformer un référentiel passif en un moteur dynamique et intelligent qui anticipe les besoins, automatise les connaissances spécialisées et permet de prendre des décisions plus éclairées. Chez Edmunds, cette priorité a conduit au lancement d'Edmunds Mind, notre initiative visant à concevoir un écosystème AI multi-agent sophistiqué directement sur la plateforme Databricks Data Intelligence.
Cette évolution architecturale est alimentée par un moment charnière dans l'industrie automobile. Trois tendances clés ont convergé :
- L'essor des grands modèles de langage (LLM) en tant que puissants moteurs de raisonnement
- L'évolutivité et la gouvernance de plateformes comme Databricks en tant que fondation sécurisée
- L'émergence de frameworks agentiques robustes pour orchestrer l'automatisation. Ces facteurs permettent de créer des systèmes qui auraient semblé inimaginables il y a quelques années à peine
Cette transformation ne consiste pas seulement à ajouter un autre outil AI, mais également à repenser fondamentalement notre organisation pour qu'elle fonctionne de manière nativement AI. Les principes, composants et stratégies qui sous-tendent ce cœur intelligent sont détaillés dans notre plan d'architecture ci-dessous.
« Databricks nous offre une fondation sécurisée et gouvernée pour exécuter plusieurs modèles tels que GPT-4o, Claude et Llama, et changer de fournisseur au fil de l'évolution de nos besoins, tout en maîtrisant les coûts. Cette flexibilité nous permet d'automatiser la modération des avis et d'améliorer plus rapidement la qualité du contenu, afin que les acheteurs de voitures obtiennent plus vite des informations fiables. »—Gregory Rokita, VP de la technologie, Edmunds
Passer d'une culture riche en données à une approche axée sur les insights
Notre vision est d'évoluer d'une entreprise riche en données vers une organisation axée sur les insights. Nous exploitons l'AI pour concevoir l'expérience d'achat de voiture la plus fiable, personnalisée et prédictive du secteur.
Cela se concrétise à travers quatre piliers stratégiques clés :
- Activer les données à l'échelle : Passer de tableaux de bord statiques à une interaction conversationnelle et dynamique avec les données.
- Automatiser l'expertise : Codifier la logique inestimable de nos experts du domaine dans des agents autonomes et réutilisables.
- Accélérer l'innovation produit : Fournir à nos équipes une boîte à outils d'agents intelligents pour concevoir des fonctionnalités de nouvelle génération.
- Optimiser les opérations internes : Réaliser des gains d'efficacité significatifs en automatisant les workflows internes complexes.
Au cœur de cette vision se trouve notre avantage concurrentiel le plus important : le Data Moat d'Edmunds. Cette base puissante de données automobiles s'appuie sur notre inventaire de véhicules d'occasion leader du secteur, l'ensemble le plus complet d'avis d'experts et une intelligence des prix de premier ordre, complétée par de nombreux avis de consommateurs et des annonces de véhicules neufs. L'ensemble de cet écosystème est unifié et géré au sein de notre environnement Databricks, créant ainsi un actif unique et puissant. Edmunds Mind est le moteur que nous avons conçu pour libérer tout son potentiel.
Au cœur du framework d'agents digitaux
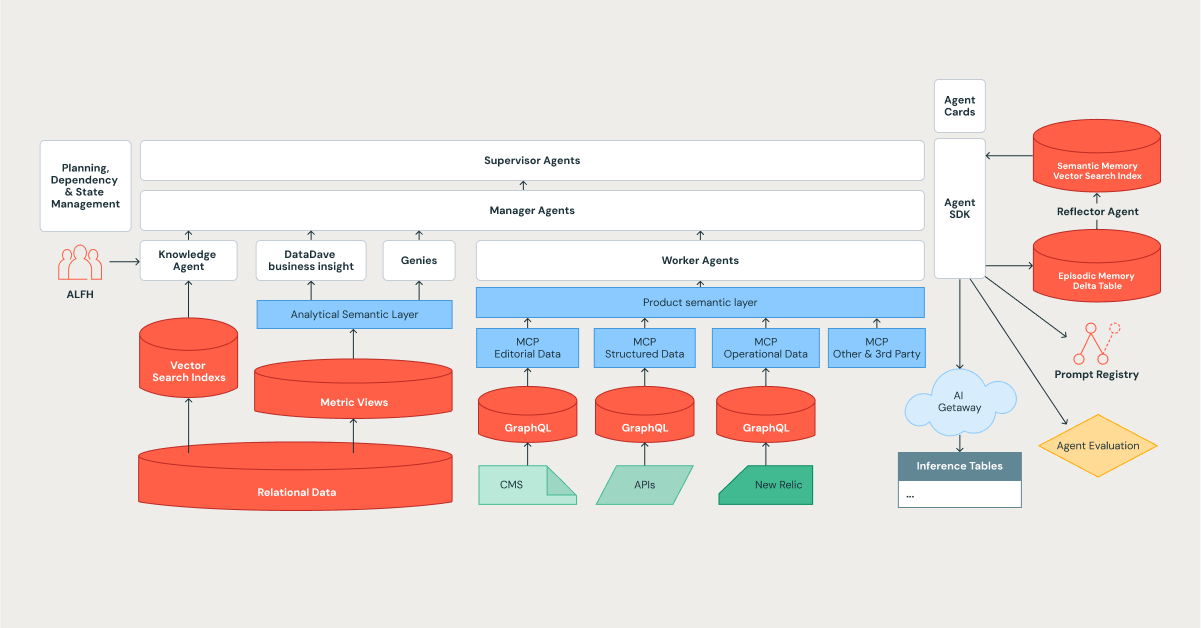
L'architecture d'Edmunds Mind est un système cognitif hiérarchique conçu pour la complexité, l'apprentissage et l'échelle, avec la plateforme Databricks comme fondation.
La hiérarchie des agents : une organisation de spécialistes digitaux
Nous avons conçu notre système pour refléter une organisation efficace, en utilisant une structure à plusieurs niveaux où les tâches sont décomposées et déléguées. Cela s'aligne parfaitement avec les modèles d'orchestrateurs des frameworks modernes, tels que Databricks Agent Bricks.
- Agents superviseurs : Les leaders stratégiques. Ils s'occupent de la planification à long terme, gèrent les dépendances et orchestrent des tâches complexes à plusieurs étapes.
- Agents managers : Les chefs d'équipe. Ils coordonnent une équipe d'agents spécialisés pour atteindre un objectif spécifique et bien défini.
- Agents exécutants et spécialisés : Ce sont les contributeurs individuels qui apportent leur expertise spécialisée. Véritables piliers du système, ils comprennent une liste croissante de spécialistes, tels que le Knowledge Assistant, DataDave et divers Genies.
La communication entre agents est régie par un protocole standardisé, garantissant que les délégations de tâches et les transferts de données sont structurés, typés et auditables, ce qui est essentiel pour maintenir la fiabilité à l'échelle.
La hiérarchie est également conçue pour gérer les pannes en douceur (graceful failure). Lorsqu'un agent manager détermine que son équipe de spécialistes ne peut pas résoudre une tâche, il remonte l'intégralité du contexte de la tâche au superviseur, y compris les tentatives infructueuses stockées dans sa mémoire épisodique. Le superviseur peut alors replanifier avec une stratégie différente ou, de manière cruciale, signaler cela comme un nouveau problème nécessitant une intervention humaine pour développer une nouvelle capacité. Cela rend le système robuste et en fait un outil d'apprentissage qui nous aide à identifier les limites de sa compétence.
Analyse approfondie 1 : Workflow d'enrichissement automatisé des données
Historiquement, la résolution des inexactitudes dans les données des véhicules, comme des couleurs incorrectes sur une page de détails du véhicule (Vehicle Detail Page), était un processus laborieux qui nécessitait une coordination manuelle entre plusieurs équipes. Aujourd'hui, l'écosystème AI d'Edmunds Mind automatise et résout ces défis en quasi-temps réel. Cette efficacité opérationnelle est rendue possible par notre Model Serving centralisé, qui regroupe les diverses capacités de nos agents AI dans un environnement unique et cohérent qui s'adapte automatiquement à la demande. Cette architecture libère nos équipes des tâches opérationnelles superflues, leur permettant de se concentrer sur la création rapide de valeur pour nos utilisateurs.
Le processus de résolution est exécuté via un workflow multi-agent gouverné. Lorsqu'un utilisateur ou un système de surveillance automatisé signale une divergence potentielle dans les données, un agent superviseur trie immédiatement l'événement. Il évalue le problème, l'oriente vers l'équipe spécialisée appropriée et valide les autorisations de tâche via Unity Catalog pour une gouvernance robuste des données. Un agent manager dédié orchestre ensuite une séquence d'agents exécutants spécialisés pour effectuer des tâches allant du décodage du VIN et de la récupération d'images à l'analyse des couleurs optimisée par l'AI et aux mises à jour finales de la base de données. Les gestionnaires de données humains (data stewards) restent essentiels pour l'examen critique, déplaçant leur attention de l'intervention manuelle vers l'étape d'approbation à haute valeur ajoutée. Chaque interaction et décision est systématiquement enregistrée, constituant ainsi une base complète pour l'apprentissage continu et l'optimisation future des processus.
Cet exemple illustre comment l'ensemble de l'écosystème gère une tâche réelle de qualité et d'enrichissement des données de bout en bout.
- Déclencheur d'événement : Une plainte d'utilisateur ou un système de surveillance automatisé signale un problème potentiel de qualité des données (par exemple, une couleur de véhicule incorrecte) sur une page de description du véhicule.
- Tri et orchestration : Un agent superviseur prend en charge l'événement, crée une tâche traçable et évalue sa priorité en fonction de règles métier prédéfinies.
- Délégation au manager : Le superviseur délègue la tâche à l'agent manager des données de véhicules après avoir confirmé ses autorisations d'accès et de modification des données de véhicules dans Unity Catalog.
- Exécution coordonnée des tâches : L'agent manager orchestre une séquence d'agents exécutants spécialisés pour résoudre le problème : un agent de décodage du VIN, un agent de récupération d'images pour extraire des photos de notre bibliothèque multimédia, un agent d'analyse des couleurs optimisé par l'AI pour déterminer la bonne couleur à partir des images, et un agent de correction des données pour mettre à jour la base de données de construction du véhicule.
- Examen avec intervention humaine (Human-in-the-Loop) : Avant que la modification ne soit publiée, l'agent manager signale le changement automatisé et en informe un gestionnaire de données humain via une intégration Slack pour validation finale.
- Apprentissage et clôture : Une fois que le gestionnaire approuve la tâche, le superviseur la marque comme terminée. L'ensemble de l'interaction, y compris l'approbation humaine finale, est tracé et enregistré dans la mémoire à long terme pour un apprentissage et un audit futurs.
Analyse approfondie 2 : Knowledge Assistant : des réponses en temps réel, une voix de marque fiable
Là où les clients devaient auparavant naviguer sur plusieurs tableaux de bord Edmunds ou contacter le support Edmunds pour obtenir des réponses, le Knowledge Assistant fournit désormais des réponses conversationnelles instantanées en s'appuyant sur l'ensemble des données d'Edmunds. Cet agent RAG est adapté à la voix de la marque Edmunds, combinant les insights des avis d'experts et de consommateurs, les spécifications des véhicules, les médias et les tarifs en temps réel. En conséquence, les clients bénéficient d'interactions plus rapides et plus satisfaisantes, et le personnel de support passe moins de temps à répondre aux demandes de base.
Les principales capacités comprennent :
- Personnification de la voix de la marque : l'agent est méticuleusement ajusté pour communiquer avec la voix dynamique, utile et fiable que les clients d'Edmunds connaissent depuis des décennies.
- Synthèse des données en temps réel : en une seule requête, l'Assistant peut récupérer, synthétiser et présenter des informations provenant de nos différentes sources de données en temps réel, notamment les avis d'experts et de consommateurs, les caractéristiques des véhicules, les transcriptions de vidéos, ainsi que les derniers tarifs et offres promotionnelles.
- Capacités RAG avancées : nous travaillons activement avec Databricks en utilisant AI Search pour repousser les limites de notre implémentation RAG. Nous nous concentrons sur l'amélioration de la priorisation de la fraîcheur du contenu et sur un filtrage sophistiqué des métadonnées afin de garantir que les informations les plus pertinentes et les plus récentes soient toujours présentées en premier.
Analyse approfondie 3 : le flux de travail « Générer et critiquer » de DataDave
DataDave gère désormais des analyses complexes qui nécessitaient auparavant un travail manuel fastidieux. Cet agent orchestre un flux de travail rigoureux, dont chaque étape est critiquée par un agent spécialisé, afin d'atteindre une précision de 95 % sur les requêtes les plus complexes. DataDave peut identifier de manière proactive des opportunités (comme le ciblage de concessions mal desservies pour l'équipe commerciale d'Edmunds) en synthétisant le trafic du site web et les données démographiques. Cela permet aux dirigeants d'Edmunds de passer en toute confiance du simple rapport sur « ce qui s'est passé » à la prise de décision sur « ce que nous devrions faire ensuite ».
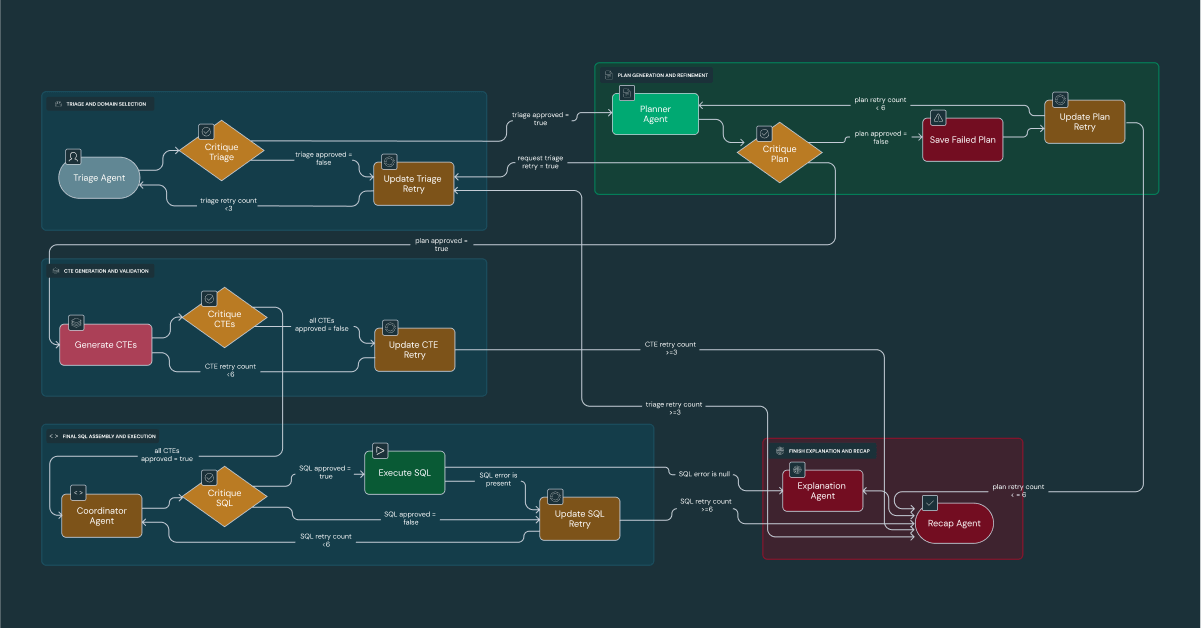
Le flux de travail interne est un processus en cinq phases (triage, planification, génération de code, exécution et synthèse), avec un agent de critique dédié qui valide le résultat de chaque phase. Au-delà de la simple analyse des métriques internes, la véritable force de DataDave réside dans sa capacité à synthétiser nos données propriétaires avec des connaissances générales sur le monde afin de générer des recommandations stratégiques. Par exemple, en corrélant les données de trafic du site web d'Edmunds avec des données géographiques et démographiques, DataDave peut identifier les concessions situées dans des zones mal desservies et les recommander de manière proactive à notre équipe commerciale comme des opportunités faciles à saisir.
Analyse approfondie 4 : spécialisation dans la tarification
Chez Edmunds, nous fonctionnons selon un principe fondamental : un prix n'est pas seulement un chiffre, c'est une conclusion qui nécessite du contexte et des justifications pour être crédible. En nous appuyant sur notre réputation de tarification la plus précise du marché américain, l'architecture de nos agents est conçue pour offrir cette confiance à grande échelle.
Notre expérience de transition d'un « expert en tarification » monolithique vers une équipe coordonnée de spécialistes illustre ce principe. Cette équipe — orchestrée par un agent gestionnaire et comprenant des experts tels qu'un agent True Market Value, un agent de dépréciation et un agent d'évaluation des offres — produit bien plus qu'un simple prix catalogue. Le résultat final est une histoire tarifaire complète et contextualisée qui explique pourquoi un véhicule est évalué d'une certaine manière.
Cela transforme le rôle de nos analystes tarifaires, qui passent de l'agrégation manuelle de données à une supervision et une orientation stratégiques. En exploitant les Agent Bricks de Databricks, nos statisticiens de tarification peuvent configurer ces équipes d'agents hiérarchiques avec un minimum de code, ce qui augmente considérablement leur productivité et réduit les coûts de maintenance. Cela leur permet de se concentrer sur ce qui compte vraiment : le « pourquoi » derrière les chiffres.
Le cœur cognitif : une architecture pour une intelligence cumulative
Notre parcours vers un écosystème d'IA véritablement intelligent a commencé par un défi pratique. Lors du déploiement d'agents spécialisés comme DataDave pour les analyses commerciales, nous avons découvert qu'ils mettaient au jour des vérités commerciales cruciales et urgentes qui restaient cloisonnées dans leur contexte opérationnel. For exemple, un agent peut détecter une tendance à la baisse anormale dans un canal marketing clé, mais cette information essentielle doit être communiquée efficacement à d'autres entités, tant aux agents qu'aux humains, pour déclencher une réponse coordonnée. Cela a mis en évidence un besoin fondamental : un système de mémoire partagée capable de capturer ces apprentissages émergents et de les rendre accessibles en tant que données d'entrée pour l'ensemble du système d'agents. Nous avons imaginé une couche cognitive où ces connaissances pourraient s'accumuler, se développer et être exploitées pour rendre notre écosystème de plus en plus intelligent. Par conséquent, notre réflexion et notre conception les plus récentes sont les suivantes.
- Mémoire épisodique (« ce qui s'est passé ») : un journal haute fidélité de chaque action et observation d'agent, servant de vérité de terrain pour le système.
- Mémoire sémantique (« ce qui a été appris ») : un index vectoriel contenant des informations généralisées et des stratégies réussies synthétisées à partir d'événements épisodiques. Il s'agira de la bibliothèque de connaissances exploitables.
- Consolidation automatisée de la mémoire : un agent « réflecteur » en arrière-plan examine périodiquement la mémoire épisodique pour identifier et consolider les apprentissages clés dans la mémoire sémantique.
- Accès hiérarchique à la mémoire : les agents de niveau supérieur peuvent accéder aux mémoires de leurs subordonnés, permettant à un agent gestionnaire d'analyser les performances de l'équipe et d'optimiser les stratégies futures. Cette boucle de rétroaction est au cœur de l'antifragilité de notre système ; chaque nouvelle défaillance remontée par la hiérarchie n'est pas seulement un problème à résoudre, mais un signal qui entraîne l'ensemble de l'écosystème, le rendant progressivement plus intelligent et résilient.
Implémentation : mem0 + Databricks
Notre implémentation sera propulsée par Databricks AI Search à l'aide d'un Delta Sync Index, entièrement compatible avec l'interface mem0. Étant donné que mem0 interagit with vector databases, nous allons innover en stockant les mémoires épisodiques et sémantiques dans un backend unique et puissant. Les événements bruts non résumés (« ce qui s'est passé ») et les apprentissages synthétisés (« ce qui a été appris ») coexisteront en tant que types de vecteurs distincts au sein de la même table Delta source, qui alimentera ensuite de manière transparente et automatique l'index AI Search.
Cette architecture unifiée crée un flux de travail efficace. L'agent réflecteur peut interroger l'index pour trouver des entrées épisodiques récentes, effectuer sa synthèse et réécrire les nouveaux vecteurs sémantiques généralisés dans la table Delta source. Le Delta Sync Index ingère ensuite automatiquement ces nouveaux apprentissages, les rendant disponibles pour les requêtes. En exploitant la table Delta source comme point d'entrée unique, nous éliminons la complexité des pipelines de données et obtenons la base évolutive, sans serveur et à faible latence requise pour un système d'agents véritablement intelligent.
Exemple de flux de travail avec Edmunds Pulse
- Journalisation : l'agent « DataDave » détecte une anomalie de vente et enregistre l'événement dans sa mémoire épisodique via l'API mem0. Cette action écrit une nouvelle entrée vectorielle dans notre table Delta source.
- Synthèse : l'agent réflecteur traite cet év�énement, génère une analyse généralisée (par exemple, « les ventes du produit X chutent le week-end ») et la convertit en un plongement vectoriel.
- Indexation : la nouvelle analyse est réécrite dans la table Delta source, mais signalée comme un apprentissage synthétisé. Databricks AI Search synchronise automatiquement cette nouvelle entrée, en l'indexant dans la mémoire sémantique.
- Transmission : enfin, un agent Edmunds Pulse dédié, qui surveille en permanence la mémoire sémantique pour y détecter des informations hautement prioritaires, transmet de manière proactive ce résultat synthétisé à une partie prenante humaine. En faisant un parallèle avec la version ChatGPT Pulse, qui vise à fournir un assistant IA plus ambiant et conscient, notre Edmunds Pulse agira comme le « pouls » en direct de l'entreprise, garantissant que les informations critiques ne soient pas seulement stockées, mais activement communiquées pour déclencher des actions rapides et intelligentes.
La couche de données et de connaissances : un socle de vérité gouverné
Les agents d'IA dépendent de la qualité de leurs données. La couche de données d'Edmunds est conçue sur mesure pour garantir la cohérence, la gouvernance et la flexibilité, Unity Catalog servant de pierre angulaire pour s'assurer que toutes les informations restent précises et bien gérées.
Analyse approfondie 5 : accès aux données GraphQL et modèles d'interactivité
Le framework Model Context Protocol (MCP) d'Edmunds connecte en toute sécurité les agents d'IA au contexte en temps réel de toutes les sources de données principales, telles que les caractéristiques des véhicules, les avis, les stocks et les métriques opérationnelles de systèmes comme New Relic. Cela est rendu possible grâce à une passerelle API GraphQL unifiée, qui masque la complexité sous-jacente et propose un schéma fortement typé et auto-documenté.
Au lieu que les agents ou les ingénieurs se débattent avec des données fragmentées, des schémas incompatibles ou un dépannage lent, le système prend désormais en charge trois modèles d'interactivité principaux, chacun étant adapté à un cas d'usage différent :
- Introspection dynamique de schéma : Les agents peuvent explorer de manière dynamique des requêtes nouvelles ou inconnues en introspectant le schéma GraphQL lui-même. Lorsqu'un client pose une question unique, par exemple si la valeur d'une voiture est affectée par des rappels de sécurité récents, l'agent peut découvrir de nouveaux types de données à la volée et concevoir des requêtes précises pour obtenir les réponses pertinentes. Cette flexibilité permet à l'entreprise de s'adapter rapidement aux nouvelles exigences métier sans nécessiter de modifications manuelles de l'API.
- Outils mappés granulaires : Chaque outil d'agent est directement mappé à une requête ou mutation GraphQL spécifique pour les opérations de routine. Par exemple, la mise à jour de la couleur d'un véhicule est aussi simple que l'extraction du VIN et de la nouvelle couleur, l'agent se chargeant de la mutation. Cette approche augmente la fiabilité et réduit les interventions manuelles, simplifiant ainsi les tâches quotidiennes de l'équipe.
- Requêtes persistantes : Les fonctions à fort trafic et critiques pour les performances, telles que les tableaux de bord d'inventaire en temps réel, exploitent des requêtes pré-enregistrées pour une efficacité maximale. L'agent envoie un hachage léger et des variables, et le système renvoie instantanément les résultats avec une bande passante réduite et une sécurité renforcée.
Edmunds a considérablement amélioré la rapidité, la flexibilité et la fiabilité des opérations sur les données pour les fonctions produit et support en offrant aux agents d'IA un accès structuré à toutes les données de l'entreprise via une couche API unique et robuste. Les tâches qui nécessitaient auparavant un développement personnalisé ou un débogage inter-équipes sont désormais traitées en temps réel, ce qui permet aux clients et aux équipes internes de bénéficier d'insights plus riches et de réponses plus agiles.
Analyse approfondie 6 : Les couches sémantiques et de connaissances
Cette couche cruciale sert de pont entre les données brutes et la compréhension de l'agent. Elle masque la complexité des magasins de données sous-jacents. Elle enrichit les données avec le contexte métier, garantissant que les agents opèrent sur une vue cohérente, gouvernée et compréhensible de l'univers Edmunds.
- Unity Catalog : l'épine dorsale de la gouvernance : Au cœur de notre écosystème de données, Unity Catalog fournit une gouvernance, une sécurité et une traçabilité centralisées pour tous les actifs de données et d'IA. Il garantit que chaque donnée consultée par un agent est soumise à des contrôles d'accès précis et que son parcours est entièrement auditable, constituant ainsi la base non négociable d'une plateforme d'IA sécurisée et conforme.
- Couche sémantique produit : contexte métier en temps réel : Cette couche fournit aux agents une vue orientée objet et en temps réel de nos entités de produits clés (par exemple, les véhicules, les concessionnaires, les avis). De manière cruciale, elle provient directement des mêmes schémas GraphQL qui alimentent le site Web d'Edmunds. Cela garantit une cohérence absolue ; lorsqu'un agent parle d'un « véhicule », il fait référence au même modèle de données et à la même logique métier qu'un consommateur voit sur le site Web, éliminant ainsi tout risque de dérive des données entre nos produits externes et notre IA interne.
- Couche sémantique analytique : la source unique de vérité pour les KPI : Cette couche fournit une vue cohérente et fiable de toutes les métriques de performance de l'entreprise. Elle provient directement de nos vues de métriques Delta, qui constituent la même source que celle qui alimente tous les tableaux de bord exécutifs et opérationnels. Cet alignement garantit que lorsque DataDave ou d'autres agents rendent compte des KPI de l'entreprise (comme le trafic des sessions, les leads ou les taux d'évaluation), they utilisent des définitions et des sources de données identiques à celles de nos outils de business intelligence établis, assurant ainsi une source unique de vérité dans toute l'organisation.
- Databricks AI Search - Le moteur pour le RAG : Ce composant est le moteur de recherche haute performance pour nos données non structurées et semi-structurées. En convertissant notre vaste corpus d'avis, d'articles et de contenus transcrits en embeddings vectoriels, nous permettons à des agents comme le Knowledge Assistant d'effectuer des recherches sémantiques ultra-rapides, récupérant le contexte le plus pertinent pour répondre aux requêtes des utilisateurs selon un modèle de génération augmentée par récupération (RAG).
Du centre de coûts au moteur de valeur : mesurer le ROI de notre IA
Une architecture visionnaire ne vaut que par son exécution. Notre approche repose sur une feuille de route progressive et un engagement profond à traiter notre écosystème d'IA comme un moteur central de création de valeur. Nous y parvenons en liant directement notre cadre technique d'observabilité, de gouvernance et d'éthique aux résultats clés de l'entreprise. Notre objectif n'est pas seulement de concevoir une IA puissante, mais de quantifier son impact sur nos résultats financiers.
Accélérer la vélocité de l'entreprise
Nous avons mis en place un système holistique pour mesurer les deux aspects de l'équation du ROI. Du côté des retours, notre cadre relie directement les performances de l'IA aux KPI de l'entreprise. Par exemple :
- Notre agent DataDave fournit des analyses complexes et exploitables en quelques minutes, une tâche qui prenait auparavant des heures aux analystes humains d'Edmunds. Cela accélère considérablement la prise de décision basée sur les données.
- Nos agents de tarification répondent instantanément aux demandes, éliminant ainsi des heures de recherche manuelle et libérant nos équipes pour qu'elles se concentrent sur un travail stratégique à forte valeur ajoutée.
Bien que nous soyons encore en train de quantifier l'impact précis sur des métriques telles que les taux de conversion des campagnes, ce cadre fournit les données en temps réel nécessaires pour établir ces corrélations.
Optimiser les coûts
Nous pratiquons une gouvernance économique intelligente grâce à notre AI Gateway. Les agents aux enjeux importants comme DataDave sont orientés vers nos modèles les plus puissants pour garantir la précision, tandis que les tâches de routine sont automatiquement attribuées à des modèles plus rentables. Cette stratégie de hiérarchisation des modèles nous permet de gérer précisément nos dépenses en LLM et en calcul, garantissant que chaque dollar investi est aligné sur la valeur métier qu'il crée.
« Databricks nous permet d'exécuter le bon modèle pour la bonne tâche, de manière sécurisée et à grande échelle. Cette flexibilité alimente nos agents et offre des expériences d'achat de voitures plus intelligentes. » —Greg Rokita, VP of Technology, Edmunds
Habilitation organisationnelle : autonomiser chaque employé
Pour donner vie à cette vision, nous favorisons une culture de l'innovation au sein d'Edmunds. Notre objectif est de prendre en charge tout le spectre de l'interaction homme-IA, des tâches entièrement autonomes aux examens avec intervention humaine (human-in-the-loop) et à la résolution collaborative de problèmes.
Pour y parvenir, nous fournissons un SDK d'agent robuste aux ingénieurs et soutenons un mouvement de « Citizen Developers » via notre plateforme Agent Bricks. Cette initiative a été lancée lors de notre conférence technique interne « AI Agents @ Edmunds » et est animée par une guilde active d'agents LLM, garantissant que chaque employé dispose des outils et du soutien nécessaires pour contribuer à notre avenir axé sur l'IA.
La voie à suivre : de l'intelligence proactive à la véritable autonomie
Notre parcours pour devenir une organisation véritablement native de l'IA est un marathon, pas un sprint. L'architecture « Edmunds Mind » sert de modèle pour ce parcours, et sa prochaine étape d'évolution consiste à développer des agents proactifs qui non seulement répondent aux questions, mais anticipent également les besoins de l'entreprise. Nous envisageons un avenir où nos agents identifieront les opportunités de marché à partir de flux de données en temps réel et fourniront des insights stratégiques aux parties prenantes avant même qu'elles ne les demandent.
À terme, notre feuille de route mène à un système où les agents peuvent s'auto-optimiser, en proposant de nouveaux outils, en affinant les mécanismes de critique et même en suggérant des améliorations architecturales. Cela marque la transition d'un système que nous exploitons simplement vers un véritable partenaire cognitif, faisant évoluer nos rôles d'opérateurs vers ceux de superviseurs, d'éthiciens et de stratèges d'une nouvelle main-d'œuvre intelligente.
Découvrez comment Edmunds conçoit une expérience d'achat de voiture basée sur l'IA avec l'aide de Databricks.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.