Qu'est-ce que la génération augmentée par récupération (RAG) ?
Technique améliorant les réponses des LLM en récupérant des informations pertinentes dans des bases de connaissances externes avant la génération, ancrant les résultats dans des faits
- La génération augmentée par récupération est un modèle d'AI qui améliore les réponses des grands modèles de langage en récupérant d'abord des documents pertinents à partir de sources de données externes, puis en injectant ce contexte dans le modèle.
- Le RAG aide à réduire les hallucinations, à maintenir les réponses à jour et à adapter les résultats au contenu propre d'une organisation sans réentraîner le modèle sous-jacent.
- Les cas d'usage courants du RAG incluent les chatbots de support client, la recherche de connaissances internes et les expériences de recherche augmentée qui répondent aux questions directement à partir des documents de l'entreprise.
Qu'est-ce que la génération augmentée par récupération, ou RAG ?
La génération augmentée par récupération (RAG) est un framework AI hybride qui renforce les grands modèles de langage (LLM) en les combinant avec des sources de données externes et à jour. Au lieu de s'appuyer uniquement sur des données d'entraînement statiques, la RAG récupère les documents pertinents au moment de la requête et les fournit au modèle en tant que contexte. En intégrant des données nouvelles et sensibles au contexte, l'AI peut générer des réponses plus précises, actuelles et spécifiques à un domaine.
La RAG devient rapidement l'architecture de référence pour créer des applications AI d'entreprise. Selon des enquêtes récentes, plus de 60 % des organisations développent des outils de récupération alimentés par l'AI pour améliorer la fiabilité, réduire les hallucinations et personnaliser les résultats à l'aide de données internes.
Alors que l'generative AI s'étend aux fonctions de l'entreprise telles que le service client, la gestion interne des connaissances et la conformité, la capacité de la RAG à combler le fossé entre l'AI générale et les connaissances spécifiques de l'organisation en fait un pilier essentiel pour des déploiements fiables et concrets.
Comment fonctionne la RAG
La RAG améliore les résultats d'un modèle de langage en y injectant des informations contextuelles et en temps réel récupérées à partir d'une source de données externe. Lorsqu'un utilisateur soumet une requête, le système sollicite d'abord le modèle de récupération, qui utilise une base de données vectorielle pour identifier et « récupérer » des documents, des bases de données ou d'autres sources sémantiquement similaires contenant des informations pertinentes. Une fois identifiés, il combine ces résultats avec le prompt d'origine et les envoie à un modèle d'AI générative, qui synthétise les nouvelles informations.
Cela permet au LLM de produire des réponses plus précises et adaptées au contexte, basées sur des données spécifiques à l'entreprise ou à jour, plutôt que de s'appuyer simplement sur le modèle sur lequel il a été entraîné.
Les pipelines RAG comportent généralement quatre étapes : la préparation et le découpage des documents (chunking), l'indexation vectorielle, la récupération et l'augmentation du prompt. Ce flux de processus aide les développeurs à mettre à jour les sources de données sans réentraîner le modèle, faisant de la RAG une solution évolutive et rentable pour créer des applications LLM dans des domaines tels que le support client, les bases de connaissances et la recherche interne.
Quels défis l'approche de génération augmentée par récupération permet-elle de résoudre ?
Problème 1 : Les modèles LLM ne connaissent pas vos données
Les LLM utilisent des modèles de deep learning et s'entraînent sur des ensembles de données massifs pour comprendre, résumer et générer du contenu inédit. La plupart des LLM sont entraînés sur un large éventail de données publiques afin qu'un seul modèle puisse répondre à de nombreux types de tâches ou de questions. Une fois entraînés, de nombreux LLM n'ont pas la capacité d'accéder à des données au-delà de la date limite de leurs données d'entraînement. Cela rend les LLM statiques et peut les amener à répondre de manière incorrecte, à donner des réponses obsolètes ou à halluciner lorsqu'on leur pose des questions sur des données sur lesquelles ils n'ont pas été entraînés.
Problème 2 : Les applications AI doivent exploiter des données personnalisées pour être efficaces
Pour que les LLM fournissent des réponses pertinentes et spécifiques, les organisations ont besoin que le modèle comprenne leur domaine et fournisse des réponses à partir de leurs propres données, plutôt que de donner des réponses larges et généralisées. For exemple, les organisations créent des bots de support client avec des LLM, et ces solutions doivent fournir des réponses spécifiques à l'entreprise aux questions des clients. D'autres construisent des bots de Q&A internes qui doivent répondre aux questions des employés sur les données HR internes. Comment les entreprises peuvent-elles concevoir de telles solutions sans réentraîner ces modèles ?
Solution : L'augmentation par récupération est désormais un standard de l'industrie
Un moyen simple et populaire d'utiliser vos propres données consiste à les fournir dans le cadre du prompt avec lequel vous interrogez le modèle LLM. C'est ce qu'on appelle la génération augmentée par récupération (RAG), car vous récupérez les données pertinentes et les utilisez comme contexte augmenté pour le LLM. Au lieu de s'appuyer uniquement sur les connaissances issues des données d'entraînement, un workflow RAG extrait les informations pertinentes et connecte les LLM statiques à la récupération de données en temps réel.
Avec l'architecture RAG, organisations peuvent déployer n'importe quel modèle LLM et l'augmenter pour renvoyer des résultats pertinents pour leur organisation en lui fournissant une petite quantité de leurs données, sans les coûts et le temps liés au fine-tuning ou au pré-entraînement du modèle.
Quels sont les cas d'usage de la RAG ?
Il existe de nombreux cas d'usage différents pour la RAG. Les plus courants sont :
Chatbots de questions-réponses : L'intégration de LLM aux chatbots leur permet d'obtenir automatiquement des réponses plus précises à partir des documents et des bases de connaissances de l'entreprise. Les chatbots sont utilisés pour automatiser le support client et le suivi des prospects sur le site Web afin de répondre aux questions et de résoudre rapidement les problèmes.
Par exemple, Experian, une entreprise multinationale de courtage de données et d'évaluation du crédit à la consommation, souhaitait créer un chatbot pour répondre à des besoins internes et externes. Ils ont rapidement réalisé que leurs technologies de chatbot actuelles avaient du mal à évoluer pour répondre à la demande. En construisant leur chatbot GenAI — Latte — sur la Databricks Data Intelligence Platform, Experian a pu améliorer la gestion des prompts et la précision des modèles, ce qui a donné à ses équipes une plus grande flexibilité pour expérimenter différents prompts, affiner les résultats et s'adapter rapidement aux évolutions de la technologie GenAI.
- Augmentation de la recherche : L'intégration de LLM aux moteurs de recherche qui augmentent les résultats de recherche avec des réponses générées par LLM permet de mieux répondre aux requêtes d'information et facilite la recherche d'informations nécessaires aux utilisateurs pour effectuer leur travail.
Moteur de connaissances : Posez des questions sur vos données (par exemple, documents HR, conformité) : Les données de l'entreprise peuvent être utilisées comme contexte pour les LLM et permettre aux employés d'obtenir facilement des réponses à leurs questions, y compris les questions HR liées aux avantages sociaux et aux politiques, ainsi que les questions de sécurité et de conformité.
C'est notamment le cas chez Cycle & Carriage, un groupe automobile de premier plan en Asie du Sud-Est. Ils se sont tournés vers Databricks pour développer un chatbot RAG qui améliore la productivité et l'engagement des clients en exploitant leurs bases de connaissances propriétaires, telles que les manuels techniques, les transcriptions du support client et les documents de processus métier. Cela a permis aux employés de rechercher plus facilement des informations via des requêtes en langage naturel qui fournissent des réponses contextuelles et en temps réel.
Quels sont les avantages de la RAG ?
L'approche RAG présente plusieurs avantages clés, notamment :
- Fournir des réponses à jour et précises : La RAG garantit que la réponse d'un LLM ne repose pas uniquement sur des données d'entraînement statiques et obsolètes. Le modèle utilise plutôt des sources de données externes à jour pour fournir des réponses.
- Réduire les réponses inexactes, ou hallucinations : En basant les résultats du modèle LLM sur des connaissances externes pertinentes, la RAG tente d'atténuer le risque de répondre avec des informations incorrectes ou inventées (également appelées hallucinations). Les résultats peuvent inclure des citations de sources originales, permettant une vérification humaine.
- Fournir des réponses pertinentes et spécifiques à un domaine : Grâce à la RAG, le LLM sera en mesure de fournir des réponses contextuellement pertinentes, adaptées aux données propriétaires ou spécifiques au domaine d'une organisation.
- Être efficace et rentable : Par rapport à d'autres approches de personnalisation des LLM avec des données spécifiques à un domaine, la RAG est simple et rentable. Les organisations peuvent déployer la RAG sans avoir besoin de personnaliser le modèle. Cela est particulièrement avantageux lorsque les modèles doivent être mis à jour fréquemment avec de nouvelles données.
Quand dois-je utiliser la RAG et quand dois-je faire du fine-tuning sur le modèle ?
La RAG est le bon point de départ, car elle est simple et peut s'avérer tout à fait suffisante pour certains cas d'usage. Le fine-tuning est plus approprié dans une situation différente, lorsque l'on souhaite modifier le comportement du LLM ou lui faire apprendre un « langage » différent. Ces approches ne s'excluent pas mutuellement. À l'avenir, il est possible d'envisager le fine-tuning d'un modèle pour mieux comprendre le langage du domaine et la forme de sortie souhaitée, tout en utilisant également la RAG pour améliorer la qualité et la pertinence de la réponse.
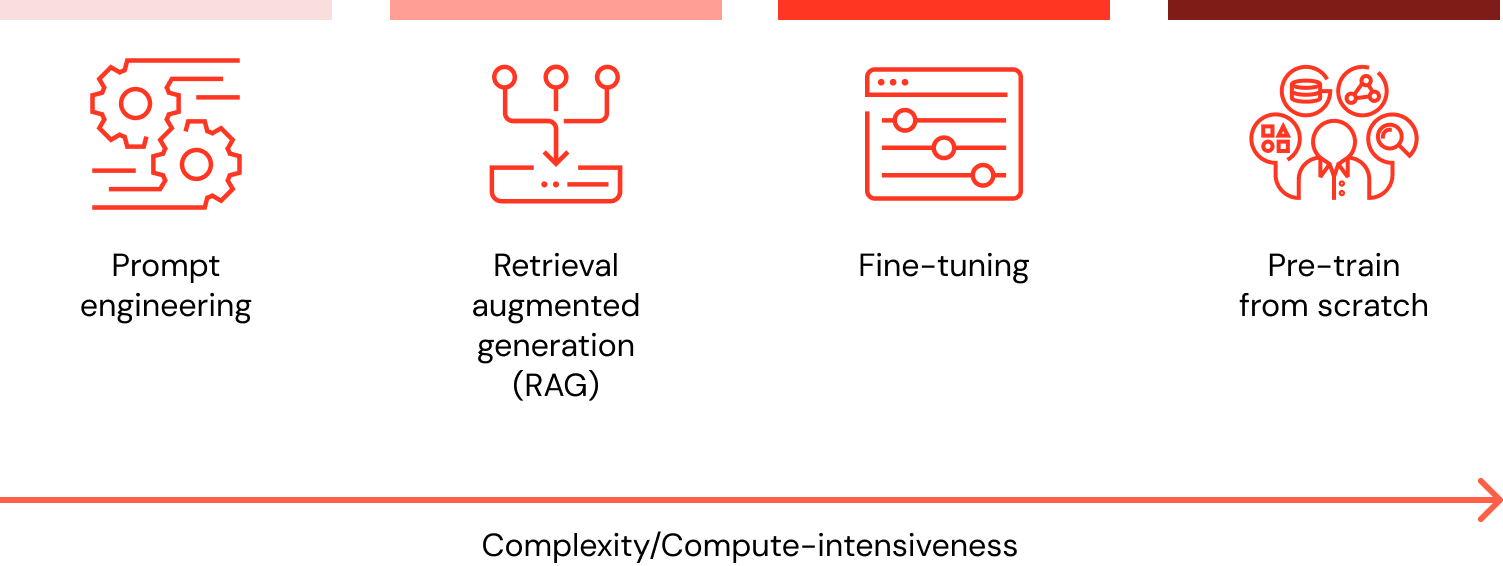
Lorsque je souhaite personnaliser mon LLM avec des données, quelles sont toutes les options et quelle méthode est la meilleure (prompt engineering vs RAG vs fine-tuning vs pré-entraînement) ?
Il existe quatre modèles d'architecture à prendre en compte lors de la personnalisation d'une application LLM avec les données de votre organisation. Ces techniques sont présentées ci-dessous et ne s'excluent pas mutuellement. Au contraire, elles peuvent (et doivent) être combinées pour tirer parti des forces de chacune.
| Méthode | Définition | Cas d'usage principal | Exigences en matière de données | Avantages | Considérations |
|---|---|---|---|---|---|
Prompt engineering | Création de prompts spécialisés pour guider le comportement du LLM | Guidage rapide et à la volée du modèle | Aucun | Rapide, rentable, aucun entraînement requis | Moins de contrôle que le fine-tuning |
Génération augmentée par récupération (RAG) | Combinaison d'un LLM avec la récupération de connaissances externes | Jeux de données dynamiques et connaissances externes | Base de connaissances ou base de données externe (par ex., base de données vectorielle) | Contexte mis à jour de manière dynamique, précision accrue | Augmente la longueur du prompt et le calcul d'inférence |
Fine-tuning | Adaptation d'un LLM pré-entraîné à des jeux de données ou des domaines spécifiques | Spécialisation par domaine ou par tâche | Des milliers d'exemples spécifiques à un domaine ou d'instructions | Contrôle granulaire, spécialisation élevée | Nécessite des données étiquetées, coût de calcul |
Pré-entraînement | Entraînement d'un LLM à partir de zéro | Tâches uniques ou organisation spécifique à un domaine | Grands jeux de données (de milliards à des milliers de milliards de tokens) | Contrôle maximal, adapté aux besoins spécifiques | Extrêmement gourmand en ressources |

Quelle que soit la technique choisie, concevoir une solution de manière bien structurée et modulaire garantit que les organisations seront prêtes à s'adapter et à évoluer. Découvrez-en plus sur cette approche et bien d'autres dans The Big Book of MLOps.
Défis courants dans la mise en œuvre du RAG
La mise en œuvre du RAG à grande échelle présente plusieurs défis techniques et opérationnels.
- Qualité de la récupération. Même les LLM les plus puissants peuvent générer de mauvaises réponses s'ils récupèrent des documents non pertinents ou de piètre qualité. Par conséquent, il est crucial de développer un pipeline de récupération efficace qui comprend une sélection rigoureuse des modèles d'embedding, des métriques de similitude et des stratégies de classement.
- Limites de la fenêtre de contexte. Avec l'ensemble de la documentation mondiale à portée de main, le risque peut être d'injecter trop de contenu dans le modèle, ce qui entraîne des sources tronquées ou des réponses diluées. Les stratégies de découpage (chunking) doivent équilibrer la cohérence sémantique et l'efficacité des tokens.
- Fraîcheur des données. L'avantage du RAG résise dans sa capacité à recueillir des informations à jour. Cependant, les index de documents peuvent rapidement devenir obsolètes sans tâches d'ingestion planifiées ou mises à jour automatisées. En veillant à ce que vos données soient fraîches, vous pouvez éviter les hallucinations ou les réponses obsolètes.
- Latence. Lors du traitement de grands jeux de données ou d'API externes, la latence peut interférer avec la récupération, le classement et la génération.
- Évaluation du RAG. En raison de la nature hybride du RAG, les modèles d'évaluation d'AI traditionnels s'avèrent insuffisants. L'évaluation de la précision des résultats nécessite une combinaison de jugement humain, de notation de la pertinence et de vérifications de l'ancrage (groundedness) pour évaluer la qualité des réponses.
Qu'est-ce qu'une architecture de référence pour les applications RAG ?
Il existe de nombreuses façons de mettre en œuvre un système de génération augmentée par récupération, en fonction des besoins spécifiques et des nuances des données. Vous trouverez ci-dessous un flux de travail couramment adopté pour fournir une compréhension fondamentale du processus.
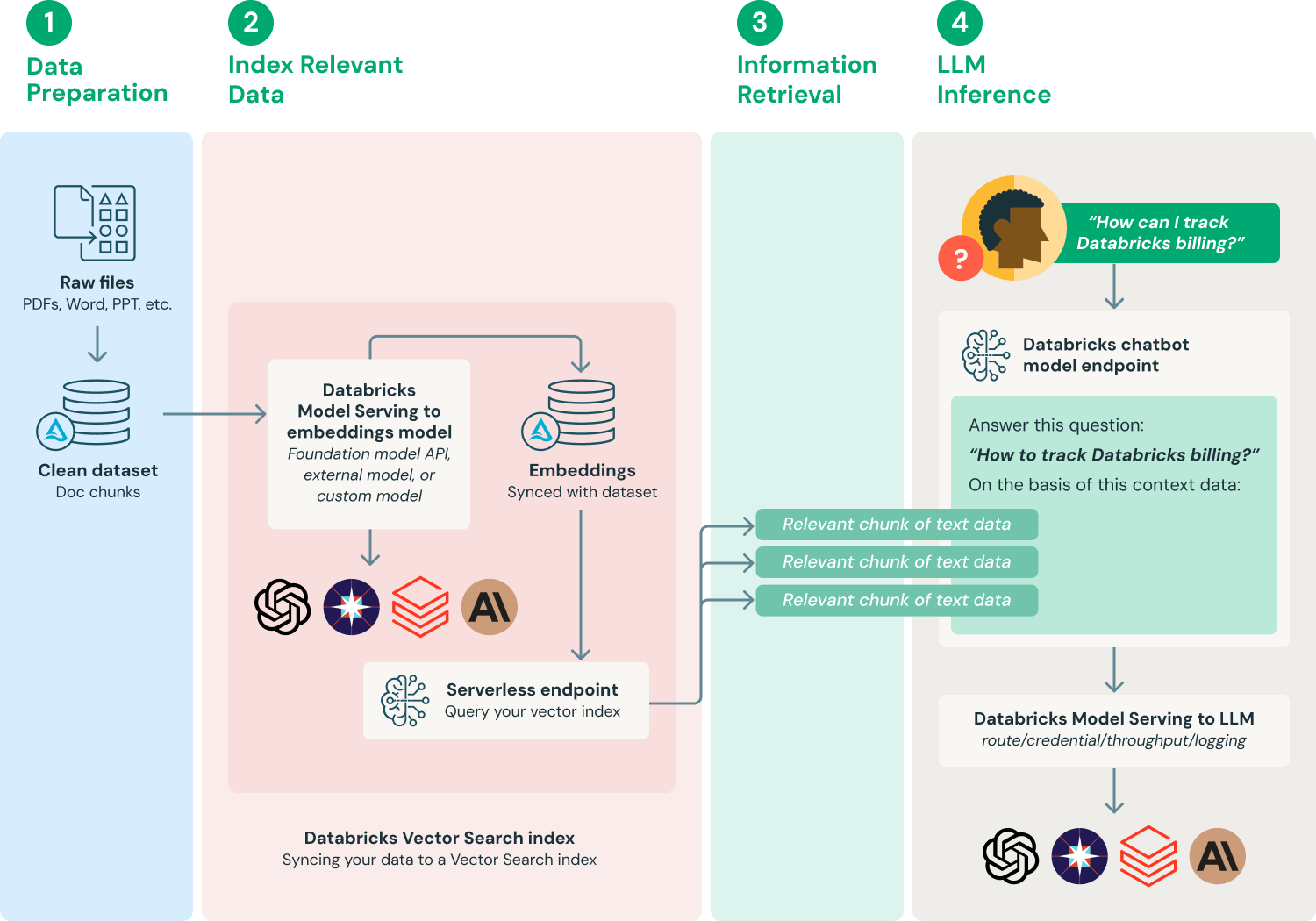
- Préparer les données : Les données des documents sont rassemblées avec les métadonnées et soumises à un prétraitement initial — par exemple, la gestion des PII (détection, filtrage, masquage, substitution). Pour être utilisés dans les applications RAG, les documents doivent être découpés en longueurs appropriées en fonction du choix du modèle d'embedding et de l'application LLM en aval qui utilise ces documents comme contexte.
- Indexer les données pertinentes : Générez des embeddings de documents et alimentez un index AI Search avec ces données.
- Récupérer les données pertinentes : Récupération des parties de vos données qui sont pertinentes pour la requête d'un utilisateur. Ces données textuelles sont ensuite fournies dans le cadre du prompt utilisé pour le LLM.
- Créer des applications LLM : Encapsulez les composants d'augmentation de prompt et de requête du LLM dans un point de terminaison. Ce point de terminaison peut ensuite être exposé à des applications telles que des chatbots de Q&A via une simple API REST.
Databricks recommande également certains éléments architecturaux clés d'une architecture RAG :
- Base de données vectorielle : Certaines applications LLM (mais pas toutes) utilisent des bases de données vectorielles pour des recherches de similitude rapides, le plus souvent pour fournir un contexte ou des connaissances de domaine dans les requêtes LLM. Pour garantir que le modèle de langage déployé a accès à des informations à jour, les mises à jour régulières de la base de données vectorielle peuvent être planifiées en tant que tâche (job). Notez que la logique permettant de récupérer des données à partir de la base de données vectorielle et d'injecter des informations dans le contexte du LLM peut être packagée dans l'artefact de modèle enregistré dans MLflow à l'aide des types de modèles MLflow LangChain ou PyFunc.
- MLflow LLM Deployments ou Model Serving : Dans les applications basées sur les LLM où une API LLM tierce est utilisée, la prise en charge des modèles externes par MLflow LLM Deployments ou Model Serving peut être utilisée comme une interface standardisée pour acheminer les requêtes provenant de fournisseurs tels qu'OpenAI et Anthropic. En plus de fournir une passerelle API de niveau entreprise, MLflow LLM Deployments ou Model Serving centralise la gestion des clés API et offre la possibilité d'appliquer des contrôles de coûts.
- Model Serving : Dans le cas d'un RAG utilisant une API tierce, un changement architectural clé est que le pipeline LLM effectuera des appels d'API externes, depuis le point de terminaison Model Serving vers des API LLM internes ou tierces. Il convient de noter que cela ajoute de la complexité, une latence potentielle et un autre niveau de gestion des identifiants. En revanche, dans l'exemple du modèle fine-tuné, le modèle et son environnement de modèle seront déployés.
Ressources
- Articles de blog Databricks
- Démo Databricks
- E-book Databricks — The Big Book of MLOps
Clients Databricks utilisant le RAG
JetBlue
JetBlue a déployé « BlueBot », un chatbot qui utilise des modèles d'AI générative open source complétés par des données d'entreprise, propulsé par Databricks. Ce chatbot peut être utilisé par toutes les équipes de JetBlue pour accéder à des données régies par des rôles. Par exemple, l'équipe financière peut voir les données de SAP et les rapports réglementaires, tandis que l'équipe des opérations ne verra que les informations de maintenance.
Lisez également cet article.
Chevron Phillips
Chevron Phillips Chemical utilise Databricks pour soutenir ses initiatives d'AI générative, y compris l'automatisation du traitement des documents.
Thrivent Financial
Thrivent Financial s'intéresse à l'AI générative pour améliorer la recherche, produire des insights mieux synthétisés et plus accessibles, et améliorer la productivité de l'ingénierie.
Où puis-je trouver plus d'informations sur la génération augmentée de récupération (RAG) ?
De nombreuses ressources sont disponibles pour en savoir plus sur la RAG, notamment :
Blogs
- Créer des applications RAG de haute qualité avec Databricks
- Aperçu public de Databricks AI Search
- Améliorer la qualité des réponses de votre application RAG avec des données structurées en temps réel
- Créer des applications d'AI générative plus rapidement grâce aux nouvelles capacités des modèles de fondation
- Meilleures pratiques pour l'évaluation par LLM des applications RAG
- Utiliser MLflow AI Gateway et Llama 2 pour créer des applications d'AI générative (Obtenez une plus grande précision en utilisant la génération augmentée de récupération (RAG) avec vos propres données)
E-books
Demos
Contactez Databricks pour planifier une démo et discuter de vos projets de LLM et de génération augmentée de récupération (RAG)
Le guide pratique de l'IA agentique pour l'entreprise

L'avenir de la technologie RAG
La RAG évolue rapidement, passant d'une solution de contournement de fortune à un composant fondamental de l'architecture d'AI d'entreprise. À mesure que les LLM deviennent plus performants, le rôle de la RAG évolue. Elle passe du simple comblement des lacunes de connaissances à des systèmes structurés, modulaires et plus intelligents.
L'un des axes de développement de la RAG réside dans les architectures hybrides, où la RAG est combinée avec des outils, des bases de données structurées et des agents d'appel de fonctions. Dans ces systèmes, la RAG fournit un ancrage non structuré tandis que les données structurées ou les API gèrent des tâches plus précises. Ces architectures multimodales offrent aux entreprises une automatisation de bout en bout plus fiable.
Un autre développement majeur est le co-entraînement extracteur-générateur. Il s'agit d'un modèle dans lequel l'extracteur RAG et le générateur sont entraînés conjointement pour optimiser mutuellement la qualité de leurs réponses. Cela peut réduire le besoin d'ingénierie de prompt manuelle ou de fine-tuning, et conduit à des éléments tels que l'apprentissage adaptatif, la réduction des hallucinations et une meilleure performance globale des extracteurs et des générateurs.
À mesure que les architectures de LLM mûrissent, la RAG deviendra probablement plus fluide et contextuelle. Dépassant les stocks limités de mémoire et d'informations, ces nouveaux systèmes seront capables de gérer des flux de données en temps réel, du raisonnement multi-documents et une mémoire persistante, ce qui en fera des assistants compétents et fiables.
Foire aux questions (FAQ)
Qu'est-ce que la génération augmentée de récupération (RAG) ?
La RAG est une architecture d'AI qui renforce les LLM en récupérant des documents pertinents et en les injectant dans le prompt. Cela permet d'obtenir des réponses plus précises, à jour et spécifiques à un domaine, sans perdre de temps à réentraîner le modèle.
Quand dois-je utiliser la RAG plutôt que le fine-tuning ?
Utilisez la RAG lorsque vous souhaitez intégrer des données dynamiques sans le coût ou la complexité du fine-tuning. Elle est idéale pour les cas d'usage nécessitant des informations précises et opportunes.
La RAG réduit-elle les hallucinations dans les LLM ?
Oui. En ancrant la réponse du modèle dans un contenu récupéré et à jour, la RAG réduit la probabilité d'hallucinations. C'est particulièrement le cas dans les domaines qui exigent une grande précision, comme la santé, le secteur juridique ou le support d'entreprise.
De quel type de données la RAG a-t-elle besoin ?
La RAG utilise des données textuelles non structurées (comme des PDF, des e-mails et des documents internes) stockées dans un format récupérable. Celles-ci sont généralement stockées dans une base de données vectorielle, et les données doivent être indexées et régulièrement mises à jour pour maintenir leur pertinence.
Comment évalue-t-on un système RAG ?
Les systèmes RAG sont évalués à l'aide d'une combinaison de scores de pertinence, de vérifications d'ancrage, d'évaluations humaines et de mesures de performance spécifiques aux tâches. Mais comme nous l'avons vu, les possibilités de co-entraînement extracteur-générateur pourraient faciliter l'évaluation régulière à mesure que les modèles apprennent les uns des autres et s'entraînent mutuellement.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.