Créer des applications RAG de haute qualité avec Databricks
Une nouvelle suite d'outils pour mettre en production des applications d'IA générative
par Patrick Wendell et Hanlin Tang
La Génération Augmentée par Récupération (RAG) s'est rapidement imposée comme un moyen puissant pour intégrer des données propriétaires et des données en temps réel dans les applications de Grands Modèles de Langage (LLM). Aujourd'hui, nous sommes ravis de lancer une suite d'outils RAG pour aider les utilisateurs de Databricks à créer des applications LLM de haute qualité et prêtes pour la production, en utilisant les données de leur entreprise.
Les LLM ont offert une avancée majeure dans la capacité à prototyper rapidement de nouvelles applications. Mais après avoir travaillé avec des milliers d'entreprises qui développent des applications RAG, nous avons constaté que leur plus grand défi est d'amener ces applications à une qualité de production. Pour atteindre les niveaux de qualité requis par les applications en contact avec les clients, les résultats produits par l'IA doivent être précis et à jour, tenir compte du contexte de votre entreprise et ne présenter aucun danger.
Pour obtenir une qualité élevée avec les applications RAG, les développeurs ont besoin d'outils riches pour comprendre la qualité de leurs données et des sorties du modèle, ainsi que d'une plateforme sous-jacente qui leur permet de combiner et d'optimiser tous les aspects du processus RAG. La RAG implique de nombreux composants tels que la préparation des données, les modèles de récupération, les modèles de langage (SaaS ou open source), les pipelines de classement et de post-traitement, l'ingénierie des prompts et l'entraînement de modèles sur des données d'entreprise personnalisées. Databricks s'est toujours attaché à combiner vos données avec des techniques de ML de pointe. Avec la version d'aujourd'hui, nous étendons cette philosophie pour permettre aux clients d'exploiter leurs données afin de créer des applications d'IA de haute qualité.
La version d'aujourd'hui inclut la préversion publique de :
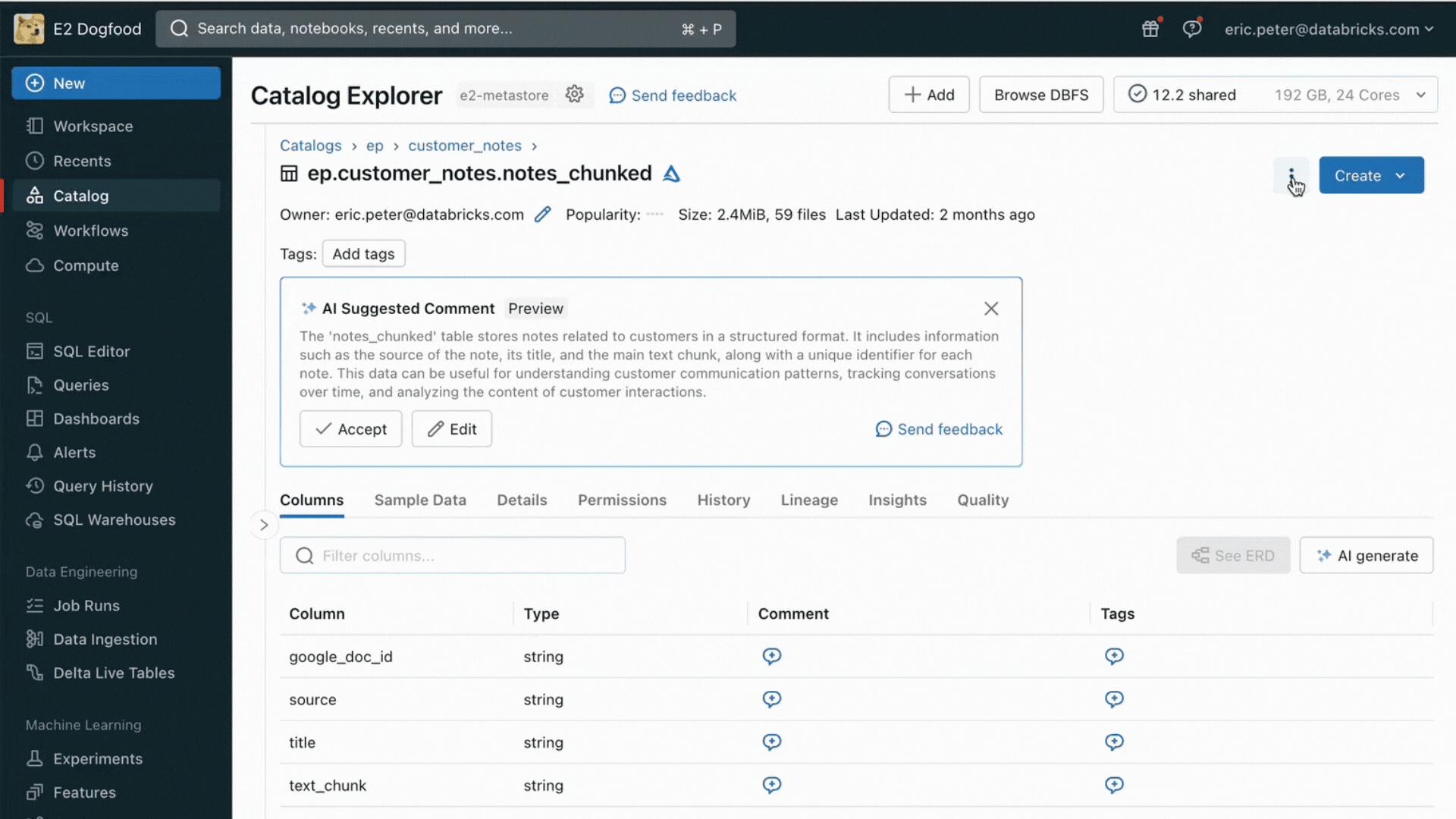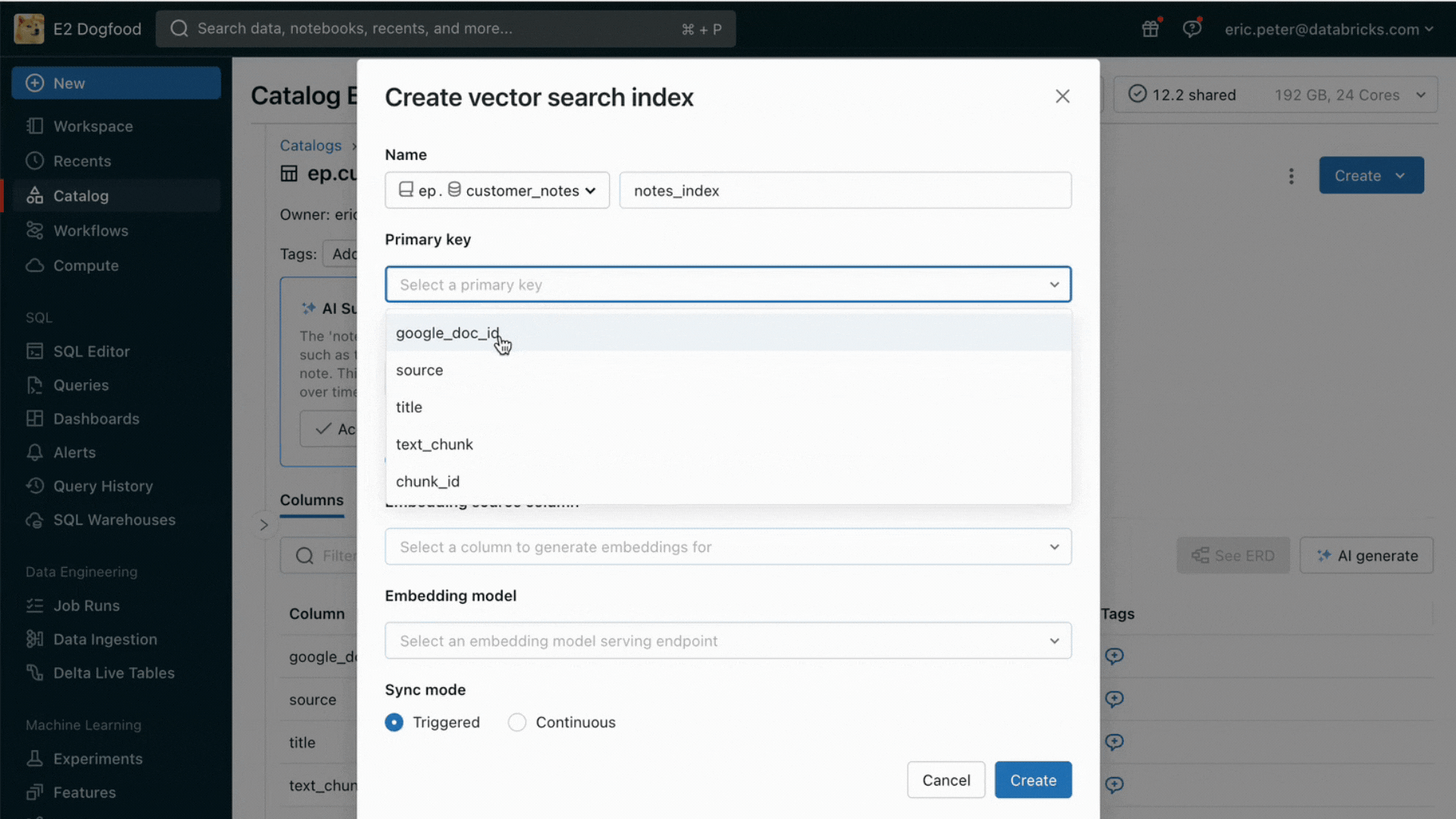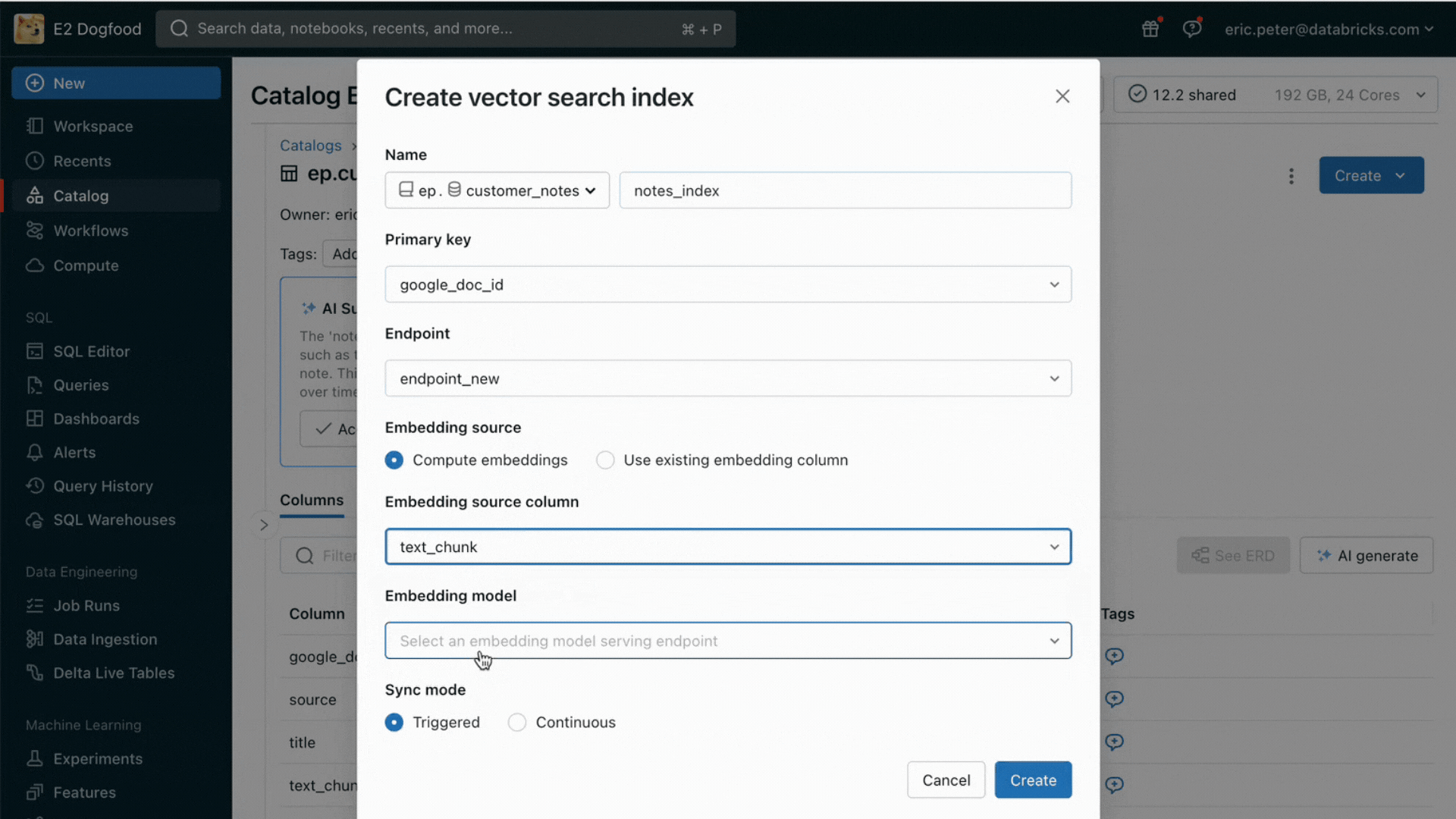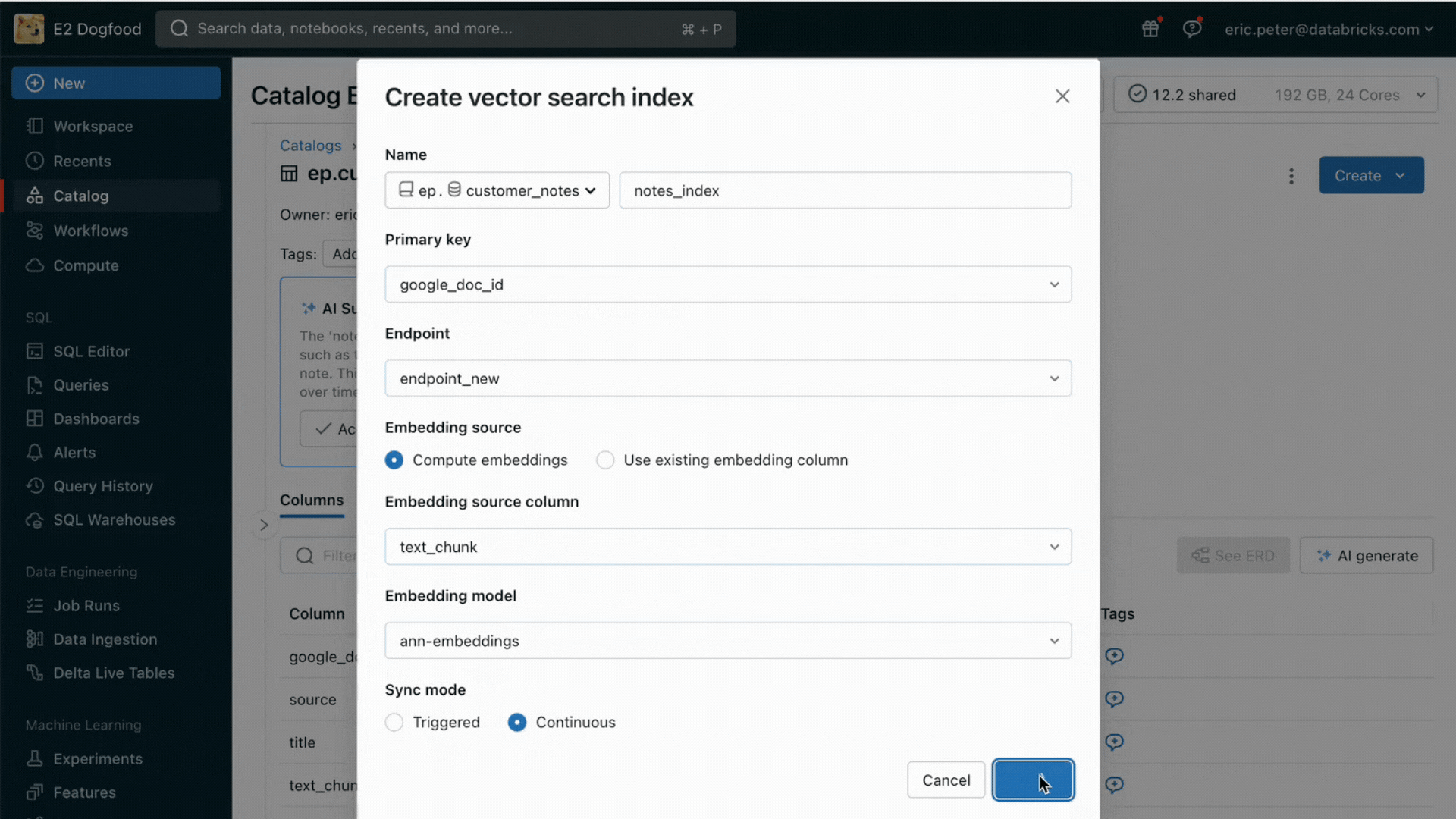
- Un service de recherche vectorielle pour alimenter la recherche sémantique sur les tables existantes de votre lakehouse.
- Service en ligne de fonctionnalités et de fonctions pour mettre un contexte structuré à la disposition des applications RAG.
- Des modèles de fondation entièrement managés proposant des LLM de base avec paiement au jeton.
- Une interface de monitoring de la qualité flexible pour observer les performances en production des applications RAG.
- Un ensemble d'outils de développement de LLM pour comparer et évaluer différents LLM.
Ces fonctionnalités sont conçues pour relever les trois défis majeurs que nous avons observés lors de la création d'applications RAG en production :
Défi n° 1 - Mise à disposition de données en temps réel pour votre application RAG
Les applications RAG combinent vos données structurées et non structurées les plus récentes pour générer des réponses de la plus haute qualité et les plus personnalisées. Mais la maintenance d'une infrastructure de service de données en ligne peut s'avérer très difficile, et les entreprises ont toujours dû assembler plusieurs systèmes et maintenir des pipelines de données complexes pour charger les données des data lakes centraux dans des couches de service sur mesure. La sécurisation des datasets importants est également très difficile lorsque les copies sont réparties sur différentes piles d'infrastructure.
Avec cette nouvelle version, Databricks prend en charge en mode natif le service et l'indexation de vos données pour la récupération en ligne. Pour les données non structurées (texte, images et vidéo), la Recherche vectorielle indexera et servira automatiquement les données des tables Delta, les rendant accessibles via une recherche par similarité sémantique pour les applications RAG. En arrière-plan, AI Search gère les échecs et les nouvelles tentatives, et optimise la taille des batchs pour vous offrir les meilleures performances, le meilleur throughput et le meilleur coût. Pour les données structurées, Feature and Function Serving fournit des requêtes à l'échelle de la milliseconde sur des données contextuelles telles que des données d'utilisateur ou de compte, que les entreprises souhaitent souvent injecter dans des prompts afin de les personnaliser en fonction des informations de l'utilisateur.
Unity Catalog suit automatiquement le lignage entre les copies hors ligne et en ligne des jeux de données servis, ce qui facilite grandement le debugging des problèmes de qualité des données. Il applique également de manière cohérente les paramètres de contrôle d'accès entre les datasets en ligne et hors ligne, ce qui signifie que les entreprises peuvent mieux auditer et contrôler qui consulte les informations propriétaires sensibles.
Défi n°2 - Comparer, ajuster et servir les modèles de fondation
Un déterminant majeur de la qualité d'une application RAG est le choix du modèle LLM de base. La comparaison des modèles peut être difficile, car ils varient selon plusieurs dimensions, telles que la capacité de raisonnement, la propension à l'hallucination, la taille de la fenêtre de contexte et le coût de service. Certains modèles peuvent également être affinés pour des applications spécifiques, ce qui peut améliorer davantage les performances et potentiellement réduire les coûts. Avec de nouveaux modèles publiés presque chaque semaine, comparer les permutations des modèles de base pour trouver le meilleur choix pour une application particulière peut être extrêmement fastidieux. Pour compliquer encore les choses, les fournisseurs de modèles ont souvent des API disparates, ce qui rend très difficile la comparaison rapide ou la pérennisation des applications RAG.
Avec cette nouvelle version, Databricks propose désormais un environnement unifié pour le développement et l'évaluation des LLM, fournissant un ensemble cohérent d'outils pour toutes les familles de modèles sur une plateforme indépendante du cloud. Les utilisateurs de Databricks peuvent accéder aux principaux modèles d'Azure OpenAI Service, d'AWS Bedrock et d'Anthropic, à des modèles open source tels que Llama 2 et MPT, ou aux modèles affinés et entièrement personnalisés des clients. Le nouvel AI Playground interactif permet de discuter facilement avec ces modèles, tandis que notre chaîne d'outils intégrée à MLflow permet des comparaisons riches en suivant des métriques clés comme la toxicité, la latence et le nombre de jetons. La comparaison de modèles côte à côte dans Playground ou MLflow permet aux clients d'identifier le meilleur modèle candidat pour chaque cas d'utilisation, et prend même en charge l'évaluation du composant Retriever.
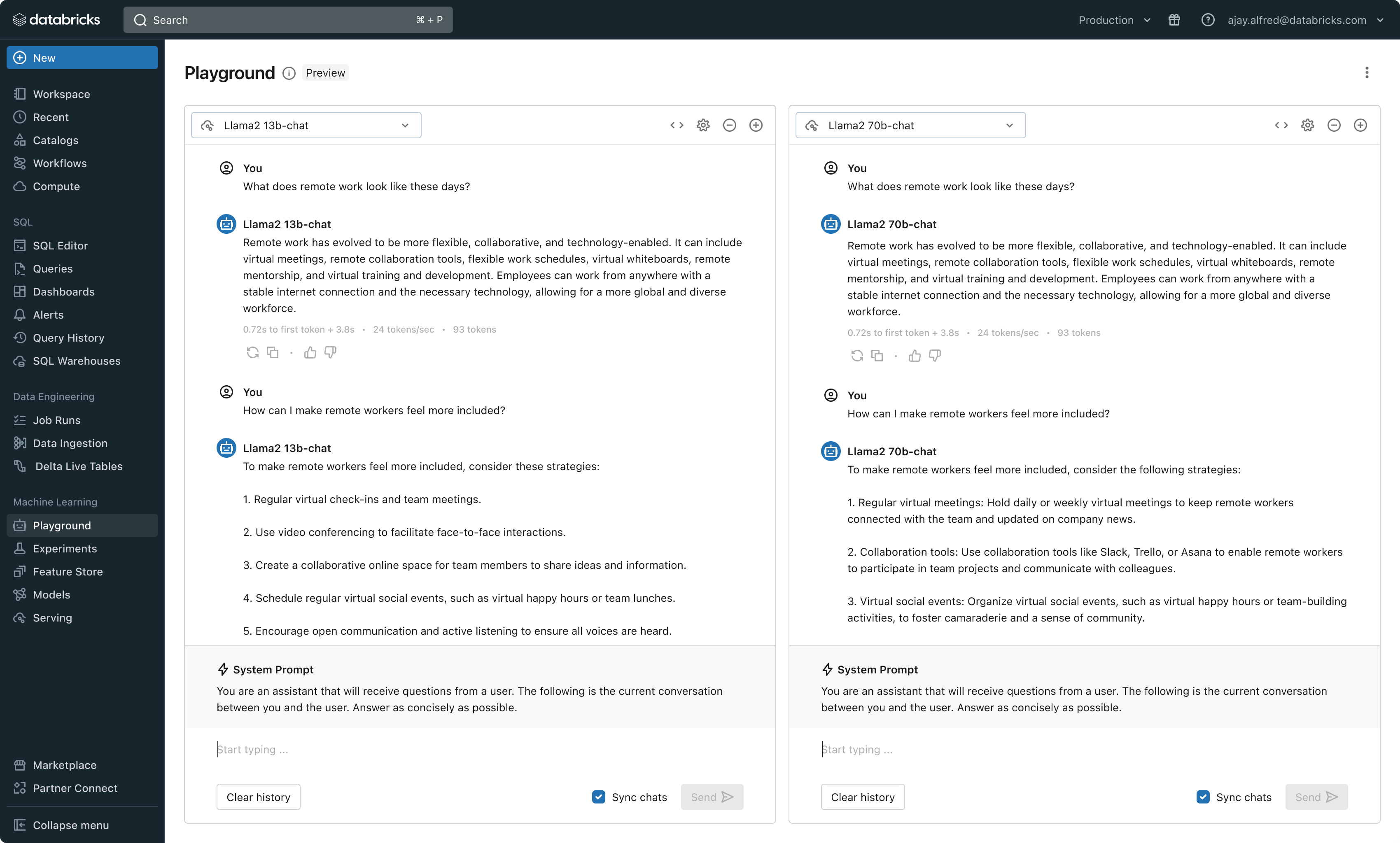
Databricks publie également les API de modèles de fondation, un ensemble de modèles LLM entièrement managé incluant les familles de modèles populaires Llama et MPT. Les API de modèles de fondation peuvent être utilisées sur la base d'un paiement par jeton, ce qui réduit considérablement les coûts et augmente la flexibilité. Comme les API de modèles de fondation sont servies depuis l'infrastructure Databricks, les données sensibles n'ont pas besoin de transiter vers des services tiers.
En pratique, pour atteindre une qualité élevée, il faut souvent combiner différents modèles de base en fonction des exigences spécifiques de chaque application. L'architecture Model Serving de Databricks fournit désormais une interface unifiée pour déployer, gouverner et interroger tout type de LLM, qu'il s'agisse d'un modèle entièrement personnalisé, d'un modèle géré par Databricks ou d'un modèle de fondation tiers. Cette flexibilité permet aux clients de choisir le bon modèle pour le bon job et d'assurer la pérennité de leurs solutions face aux futures avancées de l'ensemble des modèles disponibles.
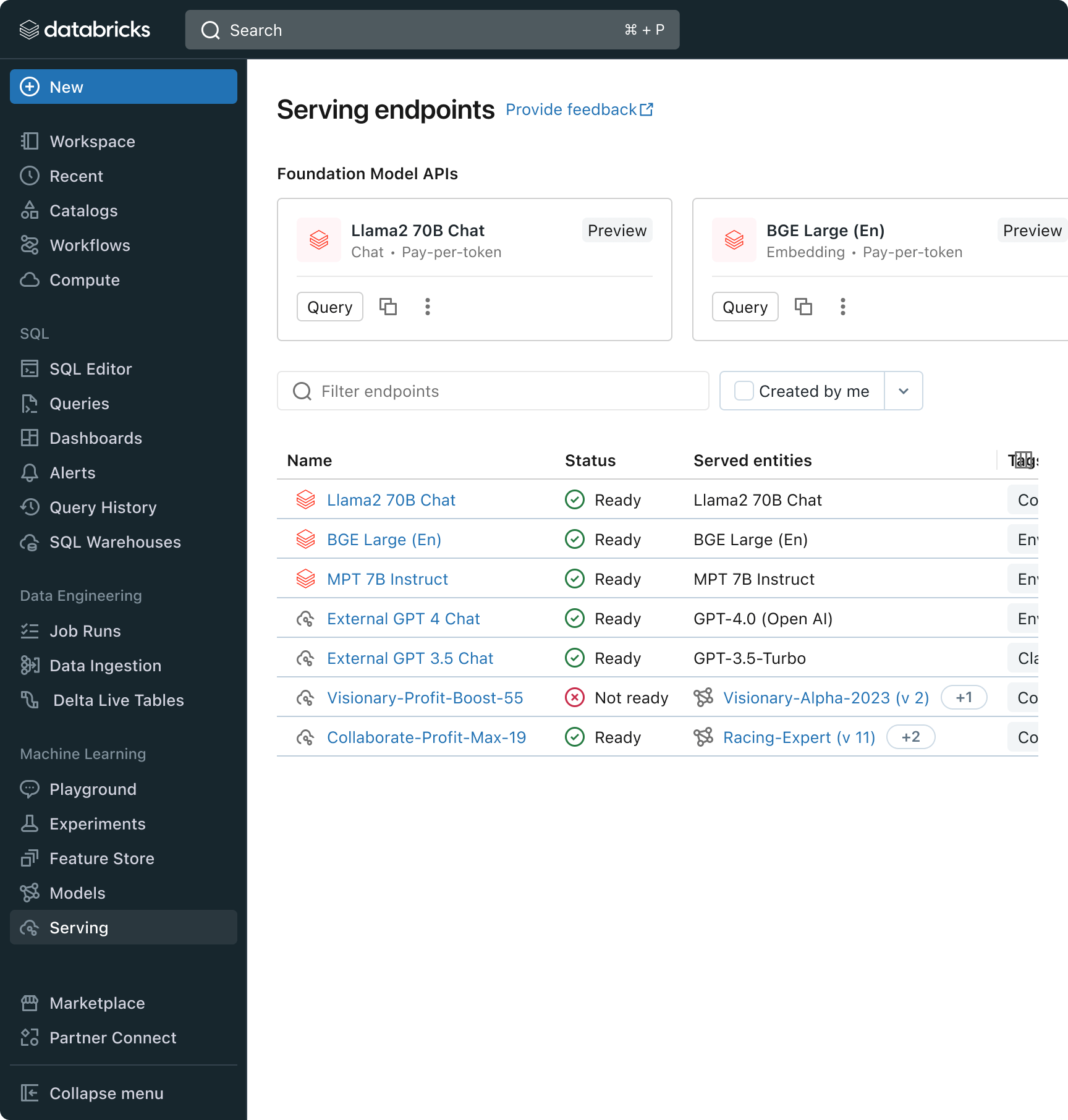
Défi n°3 - Garantir la qualité et la sécurité en production
Une fois qu'une application LLM est déployée, il peut être difficile de savoir si elle fonctionne bien. Contrairement aux outils traditionnels, les applications basées sur le langage n'ont pas de réponse unique correcte ni de conditions d'« erreur » évidentes. Cela signifie que la compréhension de la qualité (est-ce que cela fonctionne bien ?) ou de ce qui constitue un résultat anormal, dangereux ou toxique (est-ce que c'est sûr ?) n'est pas une mince affaire. Chez Databricks, nous avons vu de nombreux clients hésiter à déployer des applications RAG, car ils ne savent pas si la qualité observée dans un petit prototype interne se retrouvera au sein de leur base d'utilisateurs à grande échelle.
Inclus dans cette version, Lakehouse Monitoring fournit une solution de monitoring de la qualité entièrement managée pour les applications RAG. Lakehouse Monitoring parcourt automatiquement les résultats de l'application pour détecter les contenus toxiques et dangereux, ainsi que les hallucinations. Ces données peuvent ensuite alimenter des tableaux de bord, des alertes ou d'autres pipelines de données en aval. Comme le monitoring est intégré au lignage des datasets et des modèles, les développeurs peuvent rapidement diagnostiquer les erreurs liées, par exemple, à pipelines de données obsolètes ou modèles dont le comportement a changé de manière inattendue.
Le monitoring ne concerne pas seulement la sécurité, mais aussi la qualité. Lakehouse Monitoring peut intégrer des concepts au niveau de l'application, comme les commentaires des utilisateurs de type “pouce levé/pouce baissé”, ou même des métriques dérivées telles que le “taux d'acceptation par l'utilisateur” (fréquence à laquelle un utilisateur final accepte les recommandations générées par l'IA). D'après notre expérience, la mesure des métriques utilisateur de bout en bout renforce considérablement la confiance des entreprises quant au bon fonctionnement des applications RAG en conditions réelles. Les pipelines de monitoring sont également entièrement managés par Databricks, afin que les développeurs puissent consacrer leur temps à leurs applications plutôt qu'à la gestion de l'infrastructure d'observabilité.
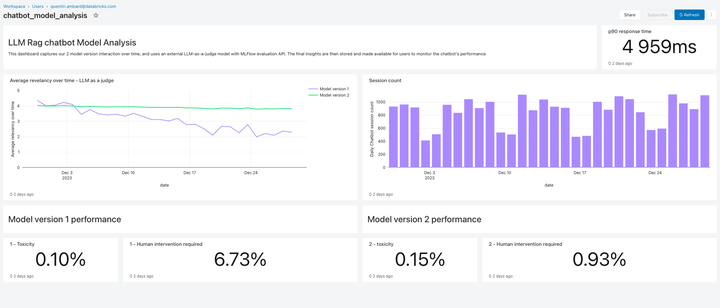
Les fonctionnalités de monitoring de cette version ne sont qu'un début. De nombreuses nouveautés sont à venir !
Étapes suivantes
Cette semaine et la semaine prochaine, nous publierons des articles de blog approfondis qui détailleront les bonnes pratiques de mise en œuvre. Alors, revenez sur notre blog Databricks, explorez nos produits grâce à la nouvelle démo RAG, visionnez le Webinaire sur l'IA générative à la demande de Databricks, suivez une formation sur l'IA générative avec notre Parcours d'apprentissage Ingénieur en IA générative, et consultez une brève démonstration vidéo de la suite d'outils RAG en action :
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.