Mise à disposition de modèles
Unifier le déploiement et la gouvernance pour tous les modèles et agents d'IA


Introduction
Databricks Model Serving offre aux entreprises une solution robuste pour déployer des modèles ML classiques, des modèles d'IA générative et des agents IA. Il prend en charge les modèles propriétaires tels qu'Azure OpenAI, AWS Bedrock et Anthropic, mais aussi des modèles open source comme Llama et Mistral. Les clients ont aussi la possibilité d'utiliser des modèles open source affinés ou des modèles ML classiques, entraînés sur leurs propres données. Les modèles servis sont facilement exploitables comme points de terminaison dans les workflows des clients, en particulier pour l'inférence par batch à grande échelle et les applications en temps réel. Model Serving s'accompagne en outre de fonctions intégrées de gouvernance, de traçabilité et de supervision pour garantir des résultats de haute qualité.
Témoignages de clients
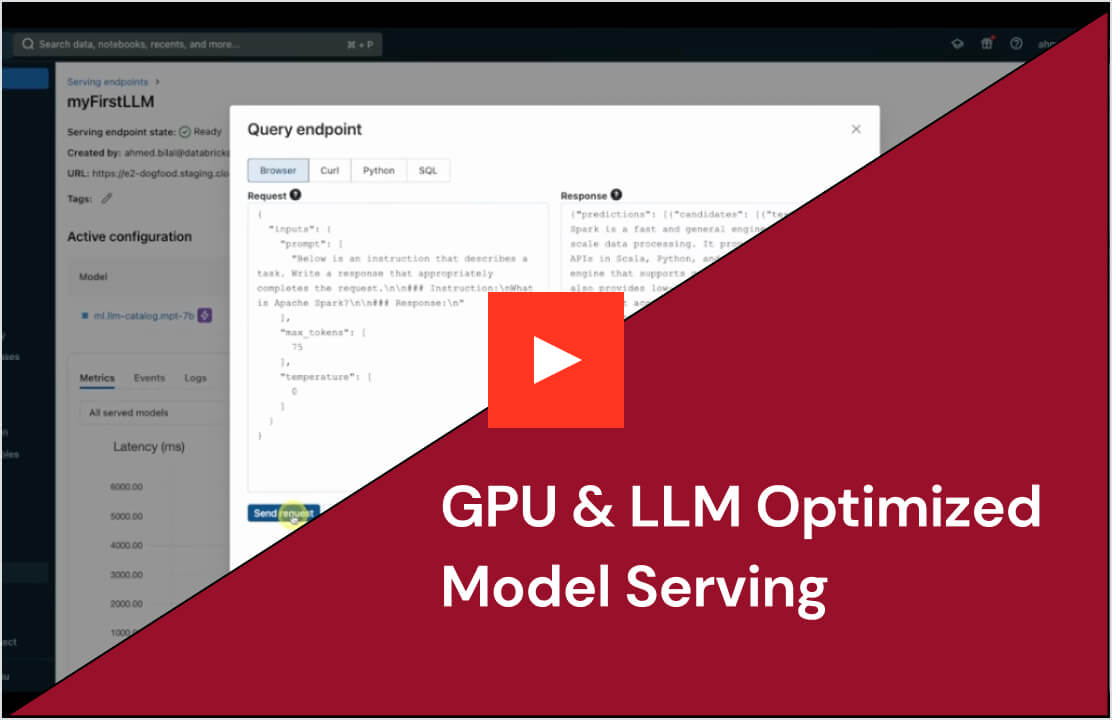
Déploiement simplifié pour tous les modèles et agents d'IA
Déployez tout type de modèle, qu'il s'agisse de modèles open source pré-entraînés ou de modèles personnalisés créés à partir de vos propres données, sur des CPU et des GPU. La gestion automatisée de la création de conteneurs et de l'infrastructure réduit les frais de maintenance et accélère le déploiement. Vous pouvez ainsi vous consacrer pleinement à vos systèmes d'agents IA et accélérer la création de valeur pour votre entreprise.
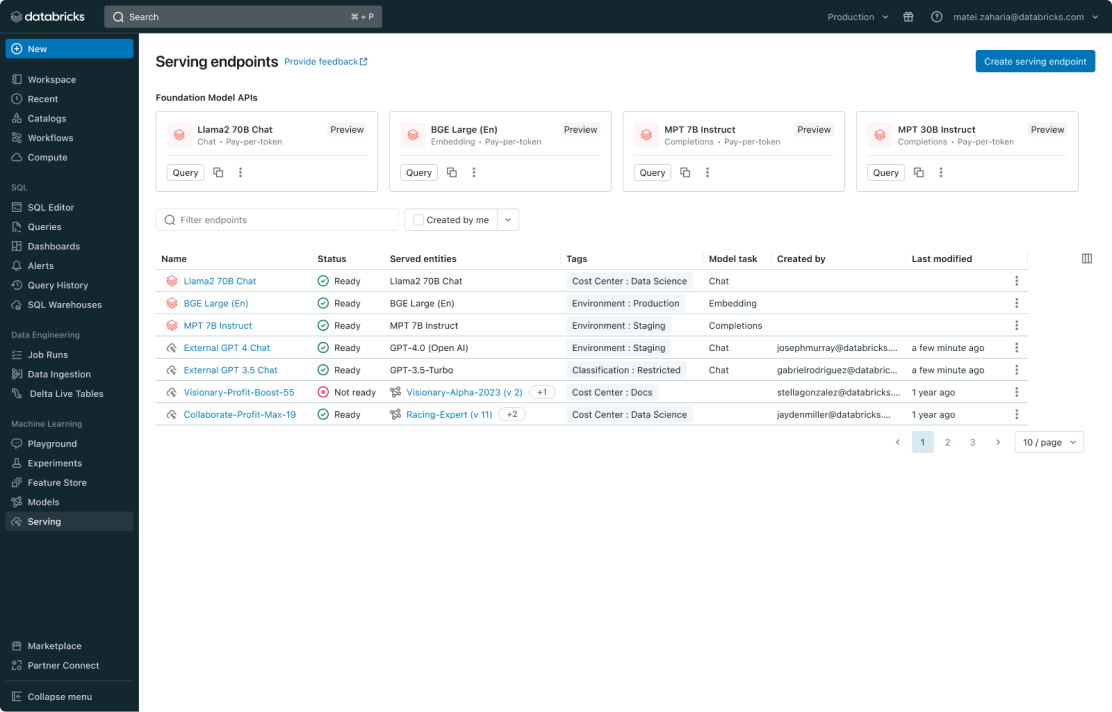
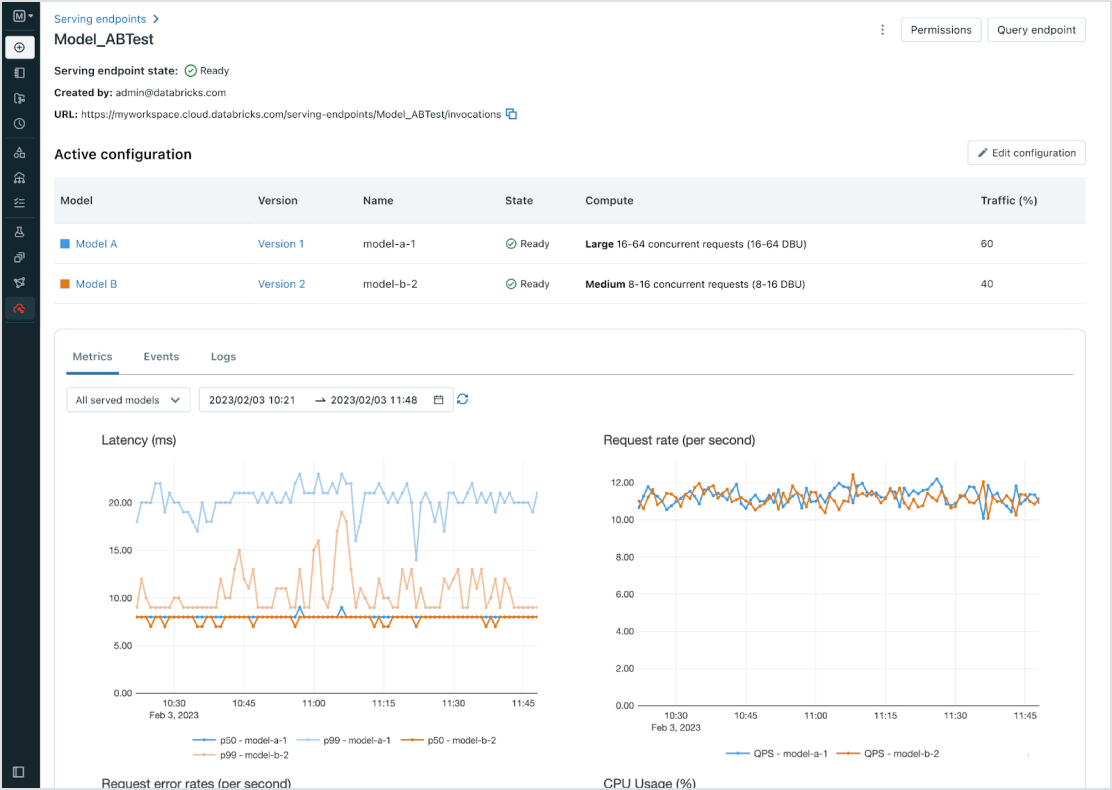
Gestion unifiée pour tous les modèles
Gérez tous les types de modèles : les modèles ML personnalisés comme PyFunc, scikit-learn et LangChain, et les modèles de fondation (FM), qu'ils soient hébergés par Databricks comme Llama 3, MPT et BGE, ou ailleurs, comme ChatGPT, Claude 3, Cohere et Stable Diffusion. Model Serving donne accès à tous les modèles au sein d'une interface utilisateur et d'une API unifiées couvrant aussi bien les modèles hébergés par Databricks que sur Azure ou AWS.
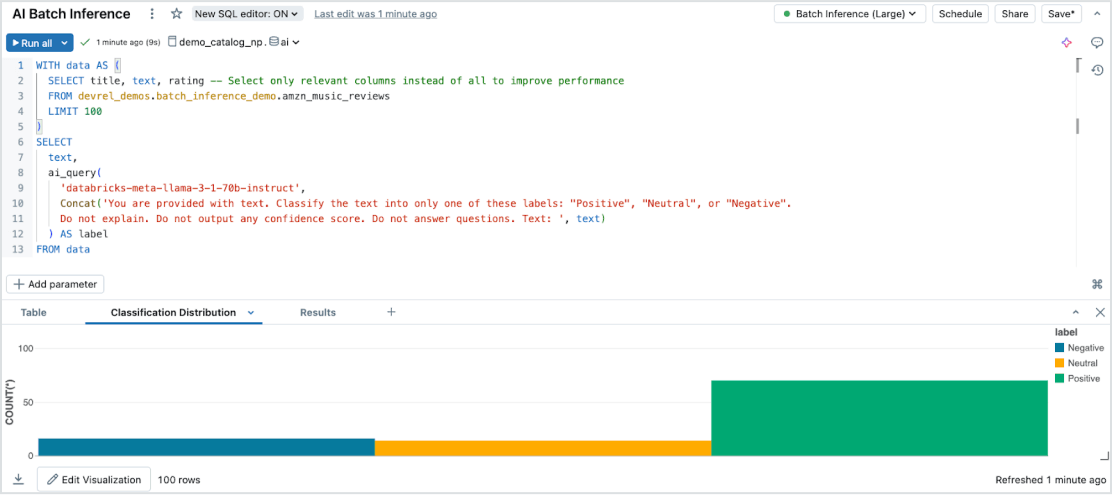
L'inférence par batch en toute simplicité
Model Serving offre un moyen efficace de réaliser de l'inférence IA serverless sur de grands datasets, et couvre tous les types de données et de modèles. Il s'intègre parfaitement avec Databricks SQL, Notebooks et Workflows pour exploiter l'IA à grande échelle. Avec AI Functions, exécutez instantanément des opérations d'inférence par lots à grande échelle pour combiner vitesse, évolutivité et gouvernance sans avoir à gérer l'infrastructure.
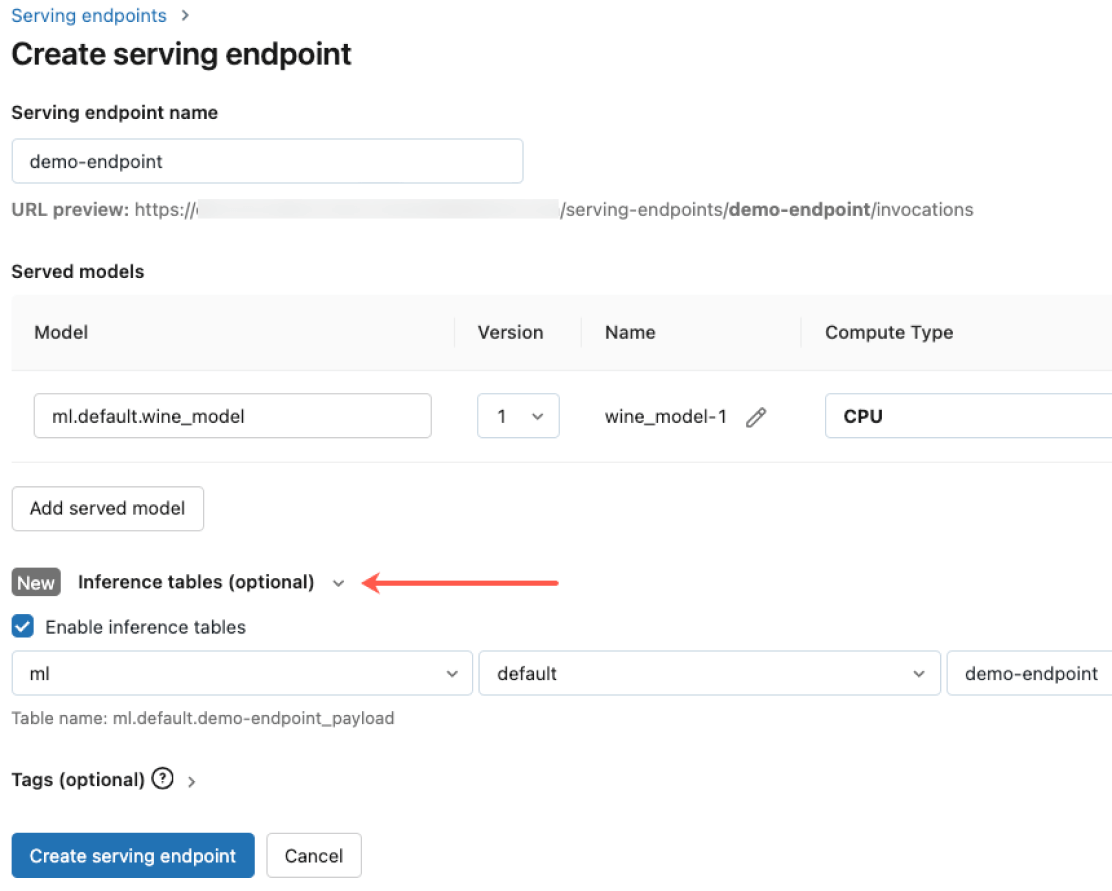
Gouvernance intégrée
Intégrez Agent Bricks AI Gateway pour respecter vos obligations de sécurité et de gouvernance, aussi strictes et complexes soient-elles. Appliquez des autorisations adaptées, supervisez la qualité des modèles, définissez des limites de débit et suivez le lineage de tous les modèles, hébergés par Databricks ou ailleurs.
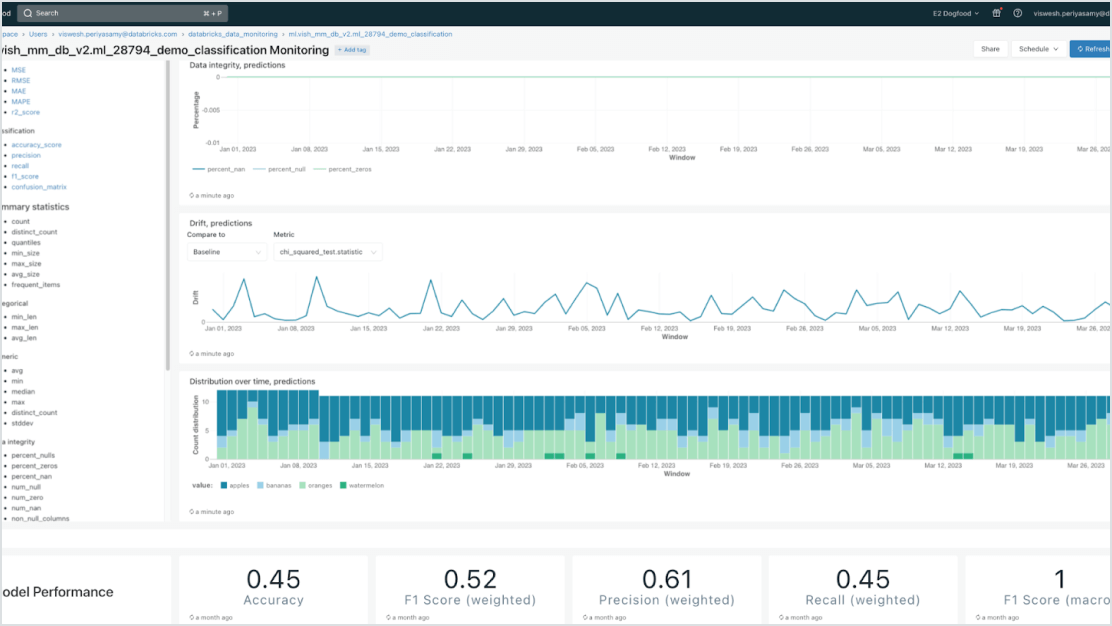
Modèles centrés sur les données
Accélérez les déploiements en réduisant le nombre d'erreurs grâce à une intégration en profondeur avec la plateforme de Data Intelligence. Hébergez facilement différents modèles de ML classique et d'IA générative, augmentés (RAG) ou ajustés (fine-tuning) à l'aide de données d'entreprise. Model Serving fournit des recherches automatisées, ainsi que des outils de supervision et de gouvernance pour l'ensemble du cycle de vie de l'IA.
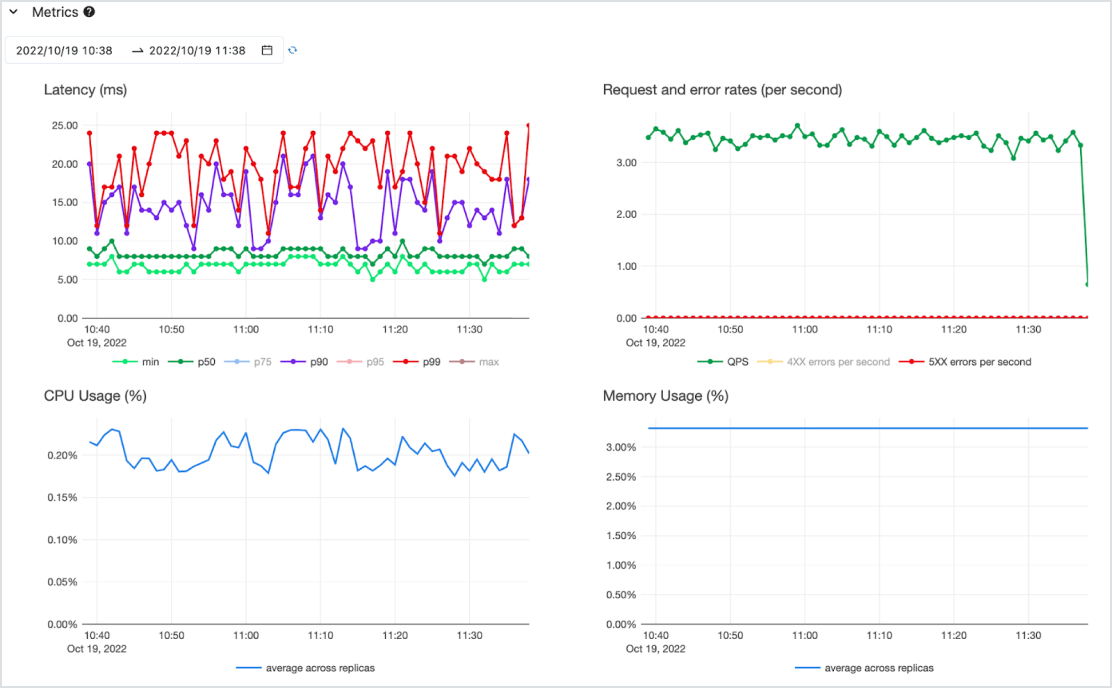
Rentable
Les modèles sont servis sous la forme d'une API à faible latence sur un service serverless hautement disponible, prenant en charge à la fois les CPU et les GPU. Montez en charge sans effort pour répondre à vos besoins les plus pressants, et rétrogradez en fonction de l'évolution des exigences. Démarrez rapidement en misant sur un ou plusieurs modèles pré-déployés et choisissez le paiement par jeton (sur demande, sans engagement) ou le paiement par calcul provisionn�é pour un débit garanti. Databricks assure la gestion de l'infrastructure et les frais de maintenance afin que vous puissiez vous concentrer entièrement sur la création de valeur commerciale.