Mlflow administré
Gérez en mode natif les modèles d'IA, les agents et les applications avec MLflow dans Databricks


Qu'est-ce que Managed MLflow ?
Managed MLflow sur Databricks offre un suivi des expériences, une observabilité, une évaluation des performances et une gestion des modèles de pointe pour l'ensemble du spectre du machine learning et de l'IA, des modèles classiques et du deep learning aux applications d'IA générative et aux agents, le tout en mode natif au sein de la Databricks Data Intelligence Platform. Managed MLflow repose sur la base flexible de MLflow open source et est renforcé par une fiabilité, une sécurité et une scalabilité de niveau entreprise. Cela permet aux entreprises de créer en toute confiance des modèles et des agents de haute qualité à l'aide de leurs outils préférés dans l'ensemble de l'écosystème de l'IA et du ML, tout en garantissant que leurs actifs de données et d'IA sont régis et protégés.
Avantages
Cycle de vie unifié du ML et de Gen AI
Managed MLflow unifie le développement du ML classique, du deep learning et de la GenAI au sein d'un workflow unique et optimisé. Du suivi des expérimentations au déploiement, il assure un versioning, une gestion des prompts et un packaging cohérents pour les modèles et les agents, éliminant ainsi la nécessité d'assembler des outils distincts.
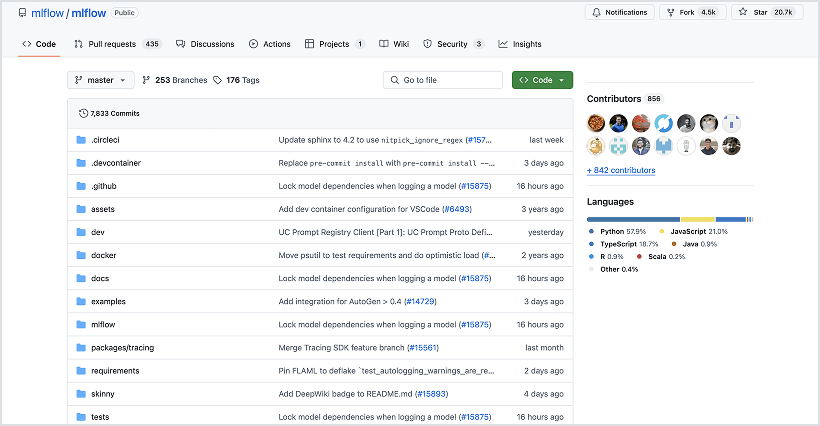
Flexible et open source
Évitez la dépendance vis-à-vis d'un fournisseur et conservez une flexibilité totale sur l'ensemble de votre stack. Basé sur MLflow open source — avec plus de 800 contributeurs de la communauté, plus de 25 millions de téléchargements de packages par mois et la confiance de plus de 5 000 organisations dans le monde — Managed MLflow prend en charge de manière transparente votre choix de frameworks, de langages et d'outils. Vous bénéficiez de toute la liberté et de la fiabilité de l'open source, ainsi que de la simplicité d'une expérience entièrement managée.
Observabilité et gouvernance de niveau entreprise
Profondément intégré à la plateforme Databricks, Managed MLflow offre une traçabilité complète, un monitoring en temps réel et une gouvernance unifiée pour l'ensemble de vos workflows d'IA. Avec Unity Catalog, vous pouvez appliquer automatiquement les contrôles d'accès, suivre la traçabilité des données et garantir la conformité de vos modèles, données et agents.
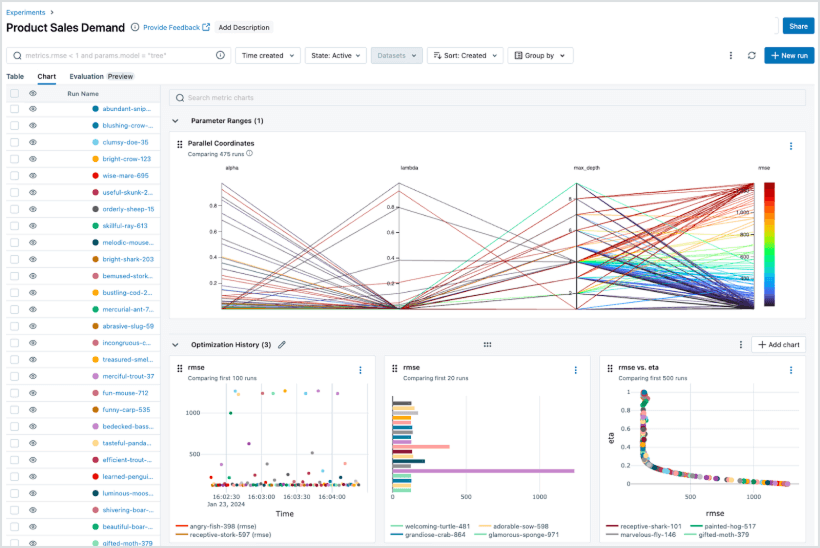
Puissantes performances analytiques
Analysez, comparez et visualisez les performances dans les environnements de développement, de préproduction et de production, le tout depuis un seul et même endroit. Grâce au modèle de données unifié de MLflow et à son intégration avec les outils Databricks AI/BI et SQL, les data scientists peuvent découvrir des tendances, identifier les régressions et générer un impact commercial en utilisant la même plateforme que celle qu'ils utilisent pour créer et déployer.
Nouvelles fonctionnalités GenAI
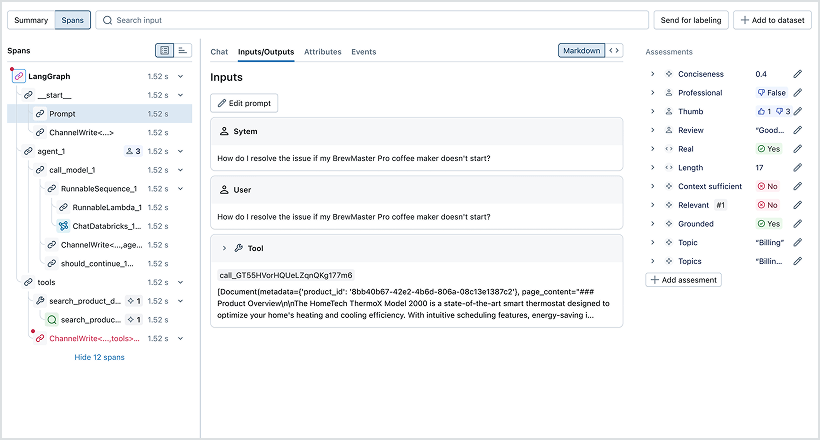
Traçage
Capturez les entrées, les sorties et l'exécution pas à pas, y compris les prompts, les extractions et les appels d'outils, grâce au traçage open source et compatible avec OpenTelemetry de MLflow. Instrumentez automatiquement les bibliothèques GenAI populaires ou ingérez directement les traces. Déboguez et itérez plus rapidement grâce à des vues chronologiques interactives, des comparaisons côte à côte et l'absence de dépendance vis-à-vis d'un fournisseur.
Évaluation de l'IA générative
Évaluez les agents GenAI à l'aide de LLM-as-a-judge et des retours humains, directement dans l'interface utilisateur de MLflow. Créez des datasets à partir des traces de production, comparez les résultats entre les versions et évaluez la qualité à l'aide de métriques prédéfinies ou personnalisées telles que l'hallucination ou la pertinence. Intégrez les retours d'experts via des interfaces utilisateur web ou des APIs d'application pour vous aligner sur le jugement humain et améliorer continuellement les résultats.
Registre de prompts et versionnement de l'agent
Gérez les versions des prompts, des agents et du code d'application en un seul endroit avec MLflow. Link les traces, les évaluations et les données de performance à des versions spécifiques pour un lignage complet du cycle de vie. Réutilisez et comparez les prompts entre les workflows, gérez les versions des agents avec les métriques et les paramètres associés, et intégrez avec Git et CI/CD pour accélérer les itérations gouvernées.
Monitoring et alertes de l'IA générative
Surveillez la qualité de la GenAI en temps réel avec les tableaux de bord de MLflow, les explorateurs de traces et les alertes automatisées. Suivez les problèmes tels que les fuites de PII, les pics de latence ou les réponses non pertinentes à l'aide des évaluations LLM-judge et de métriques personnalisées. Configurez les évaluations en ligne et agissez rapidement, avant que les utilisateurs ne soient affectés.
Fonctionnalités principales
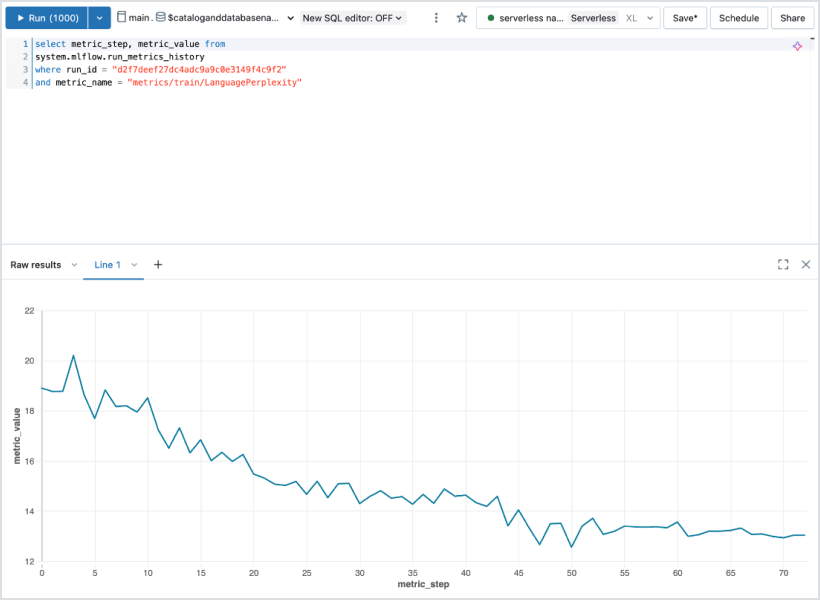
Suivi des tests
Suivez automatiquement les paramètres, les métriques, les artefacts et les modèles de n'importe quel framework de ML ou de deep learning. MLflow vous offre une piste d'audit complète et prend en charge des comparaisons approfondies entre les architectures, les points de contrôle et les workflows d'entraînement, à grande échelle.
Évaluation de modèles pour le ML et le DL
Enregistrez automatiquement les métriques intégrées et personnalisées pour des tâches telles que la classification ou la régression. Comparez les résultats par rapport à des références, enregistrez des artefacts comme les courbes ROC et validez les modèles sur de nouveaux jeux de données avant leur mise en production.
Gestion et gouvernance des modèles simplifiées
Découvrez, partagez et gérez les modèles de manière centralisée avec le MLflow Model Registry, intégré à Unity Catalog pour une gouvernance de bout en bout. Suivez l'état du déploiement et collaborez entre les équipes avec une visibilité complète sur les performances des modèles dans tous les environnements.
Déploiement à grande échelle
Déployez des modèles avec un format de packaging reproductible qui inclut l'ensemble du code, des dépendances et des poids. Servez-les en tant qu'API REST ou exécutez des inférences par batch à haut throughput avec ai_query, optimisé pour le CPU et le GPU via Databricks Model Serving.
Consultez les actus sur nos produits publiées sur Azure Databricks et AWS pour découvrir nos dernières fonctionnalités.
Comparaison des offres MLflow
MLflow | MLflow managé | |
|---|---|---|
Traçage et observabilité de l'IA | ||
APIs de traçage | ||
Intégration du debugging des Notebook | ||
Traçage pour les applications de production | ||
Tableaux de bord d'observabilité personnalisables | ||
Interrogez les données de trace avec des outils SQL et d'AI/BI | ||
Monitoring en production | ||
Évaluation de l'IA générative | ||
APIs d'évaluation | ||
UI et APIs de feedback humain | ||
Juges LLM de haute qualité | ||
Jeux de données d'évaluation versionnés | ||
Gestion des prompts | ||
MLflow Prompt Registry | ||
Interface de l'éditeur de prompts | ||
Suivi des tests | ||
API de suivi MLflow | ||
Riches tableaux de bord de performances & de comparaison | ||
Interrogez les données d'expérimentation avec SQL et les outils AI/BI | ||
Serveur de suivi MLflow | Auto-hébergé | Entièrement géré |
Intégration des notebooks | ||
Intégration des workflows | ||
Gestion de modèles | ||
MLflow Model Registry | ||
Contrôle de versions des modèles | ||
Workflows d'approbation basés sur les rôles | ||
Intégrations de workflows CI/CD | ||
Déploiements flexibles | ||
Packaging de modèle | ||
Inférence par batch à grande échelle | ||
Déploiement en temps réel à faible latence | ||
Analyses en streaming intégrées | ||
Sécurité et gestion | ||
Gouvernance d'entreprise | ||
Haute disponibilité | ||
Mises à jour automatiques |
Ressources
Documentation
Tutoriels
Blogs
VIDÉOS
Ebooks
Webinaires
Questions fréquemment posées
Prêt à vous lancer ?