Détection des biais dans les données à l'aide de SHAP et du Machine Learning
Ce que le Machine Learning et SHAP peuvent nous apprendre sur la relation entre les salaires des développeurs et l'écart de rémunération entre les genres
par Sean Owen
Essayez le Notebook Détecter les biais dans les données à l'aide de SHAP pour reproduire les étapes décrites ci-dessous et regardez notre webinar à la demande pour en savoir plus.
L'enquête annuelle auprès des développeurs de StackOverflow s'est terminée plus tôt cette année, et ils ont gracieusement publié les résultats (anonymisés) de 2019 à des fins d'analyse. Ils offrent un aperçu riche de l'expérience des développeurs de logiciels dans le monde entier -- quel est leur éditeur préféré ? combien d'années d'expérience ? tabulations ou espaces? et, point crucial, le salaire. Les salaires des ingénieurs logiciels sont bons, et parfois à la fois mirobolants et dignes de faire la une.
Le secteur d'activité de la technologie est également douloureusement conscient qu'il n'est pas toujours à la hauteur de ses prétendus idéaux méritocratiques. La rémunération n'est pas une fonction pure du mérite, et de nombreux témoignages nous indiquent que des facteurs tels que la renommée de l'école, l'âge, l'origine et le genre ont un effet sur les résultats comme le salaire.
Le machine learning peut-il faire plus que prédire des choses ? Peut-il expliquer les salaires et ainsi mettre en évidence les cas où ces facteurs pourraient entraîner des écarts de rémunération indésirables ? Cet exemple expliquera comment les modèles standard peuvent être complétés par SHAP (SHapley Additive exPlanations) pour détecter les instances individuelles dont les prédictions peuvent être préoccupantes, puis approfondira les raisons spécifiques pour lesquelles les données mènent à ces prédictions.
Biais du modèle ou biais dans les données ?
Bien que ce sujet soit souvent qualifié de détection du "biais du modèle", un modèle n'est qu'un miroir des données sur lesquelles il a été entraîné. Si le modèle est « biaisé », il l'a appris à partir des faits historiques des données. Les modèles ne sont pas le problème en soi ; ils sont l'occasion d'analyser les données pour y déceler des signes de biais.
L'explicabilité des modèles n'est pas une nouveauté, et la plupart des bibliothèques peuvent évaluer l'importance relative des entrées d'un modèle. Ce sont des vues agrégées des effets des entrées. Cependant, le résultat de certains Modèles de machine learning a des effets très individuels : votre prêt est-il approuvé ? Recevrez-vous une aide financière ? Êtes-vous un voyageur suspect ?
En effet, StackOverflow propose un calculateur pratique pour estimer son salaire attendu, sur la base de son enquête. Nous ne pouvons que spéculer sur la précision globale des prédictions, mais ce qui intéresse particulièrement un développeur, ce sont ses propres perspectives.
La bonne question n'est peut-être pas : les données suggèrent-elles un biais global ? mais plutôt, les données montrent-elles des cas individuels de biais ?
Analyse des données de l'enquête StackOverflow
Les données de 2019 sont, heureusement, propres et ne présentent aucun problème de données. Elles contiennent les réponses à 85 questions provenant d'environ 88 000 développeurs.
Cet exemple se concentre uniquement sur les développeurs à temps plein. Le jeu de données contient de nombreuses informations pertinentes, comme les années d'expérience, le niveau d'études, le rôle et les informations démographiques. Notamment, ce jeu de données ne contient pas d'informations sur les bonus et la participation au capital, seulement sur le salaire.
Il contient également des réponses à des questions très variées sur les opinions concernant la blockchain, le fizz buzz et l'enquête elle-même. Celles-ci sont exclues ici car il est peu probable qu'elles reflètent l'expérience et les compétences qui, vraisemblablement, devraient déterminer la rémunération. De même, par souci de simplicité, il se concentrera également uniquement sur les développeurs basés aux États-Unis.
Les données nécessitent un peu plus de transformation avant la modélisation. Plusieurs questions autorisent des réponses multiples, comme "Quels sont vos plus grands défis en matière de productivité en tant que développeur ?" Ces questions uniques génèrent plusieurs réponses par oui/non et doivent être décomposées en plusieurs caractéristiques oui/non.
Certaines questions à choix multiples comme « Combien de personnes sont employées approximativement par l'entreprise ou l'organisation pour laquelle vous travaillez ? » offrent des réponses comme « 2 à 9 employés ». Il s'agit en fait de valeurs continues regroupées par classes (binned), et il peut être utile de les mapper à nouveau à des valeurs continues déduites comme « 2 » afin que le modèle puisse prendre en compte leur ordre et leur magnitude relative. Cette traduction est malheureusement manuelle et implique une part de jugement.
Le code Apache Spark qui permet d'accomplir cela se trouve dans le notebook associé, pour les personnes intéressées.
Sélection de modèle avec Apache Spark
Maintenant que les données sont dans un format plus adapté au machine learning, la prochaine étape consiste à ajuster un modèle de régression qui prédit le salaire à partir de ces caractéristiques. L'ensemble de données lui-même, après filtrage et transformation avec Spark, ne fait que 4 Mo, contenant 206 caractéristiques provenant d'environ 12 600 développeurs, et pourrait facilement tenir en mémoire en tant que DataFrame sur votre montre, sans parler d'un serveur.
xgboost, un package populaire d'arbres à gradient renforcé, peut ajuster un modèle à ces données en quelques minutes sur une seule machine, sans Spark. xgboost propose de nombreux "hyperparamètres" réglables qui affectent la qualité du modèle : profondeur maximale, taux d'apprentissage, régularisation, etc. Plutôt que de deviner, la pratique standard consiste à essayer de nombreux réglages de ces valeurs et à choisir la combinaison qui aboutit au modèle le plus précis.
Heureusement, c'est là que Spark intervient. Il peut créer des centaines de ces modèles en parallèle et collecter les résultats de chacun. Comme l'ensemble de données est petit, il est simple de le diffuser aux Workers, de créer de nombreuses combinaisons de ces hyperparamètres à tester et d'utiliser Spark pour appliquer le même code xgboost simple non distribué qui pourrait construire un modèle localement sur les données avec chaque combinaison.
Cela créera beaucoup de modèles. Pour suivre et évaluer les résultats, mlflow peut journaliser chacun d'eux avec ses métriques et ses hyperparamètres, et les consulter dans l'expérimentation du Notebook. Ici, un hyperparamètre sur de nombreuses exécutions est comparé à la précision qui en résulte (erreur absolue moyenne) :
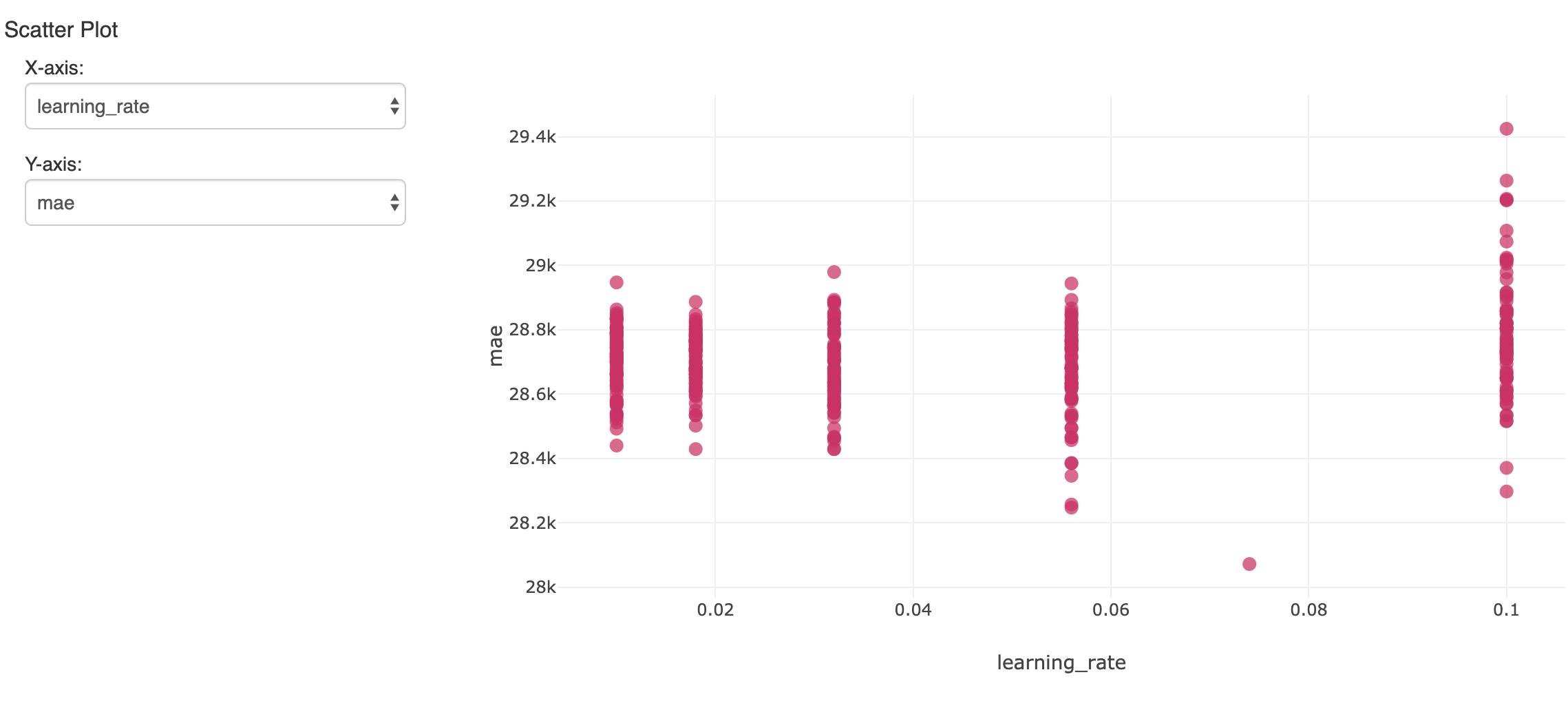
Le modèle unique qui a affiché l'erreur la plus faible sur l'ensemble de données de validation non utilisé est intéressant. Il a produit une erreur absolue moyenne d'environ 28 000 $ sur des salaires s'élevant en moyenne à environ 119 000 $. Ce n'est pas si mal, mais il faut savoir que le modèle ne peut expliquer que la majeure partie de la variation du salaire.
Interprétation du modèle xgboost
Bien que le modèle puisse être utilisé pour prédire les salaires futurs, la question est plutôt de savoir ce que le modèle nous apprend sur les données. Quelles caractéristiques semblent être les plus importantes pour prédire le salaire avec précision ? Le modèle xgboost lui-même calcule une notion d'importance des caractéristiques :
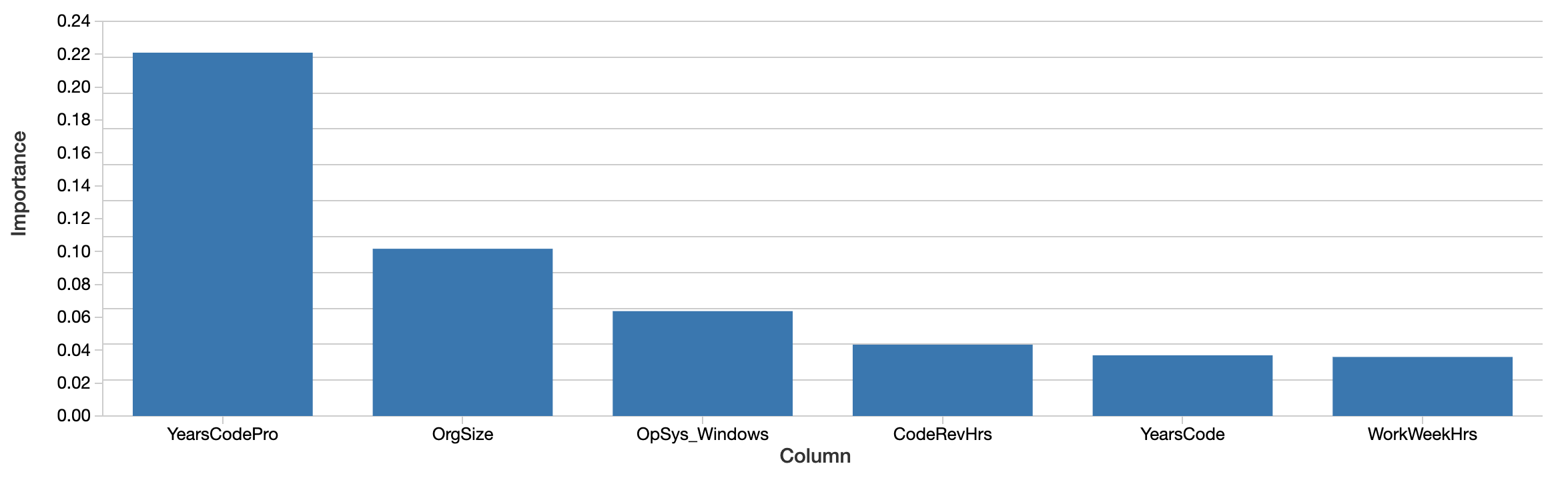
Des facteurs tels que les années d'expérience en codage professionnel, la taille de l'organisation et l'utilisation de Windows sont les plus "importants". C'est intéressant, mais difficile à interpréter. Les valeurs reflètent une importance relative et non absolue. Autrement dit, l'effet n'est pas mesuré en dollars. La définition de l'importance ici (gain total) est également spécifique à la manière dont les arbres de décision sont construits et est difficile à transposer en une interprétation intuitive. Les caractéristiques importantes ne sont pas non plus nécessairement corrélées positivement avec le salaire.
Plus important encore, il s'agit d'une vue « globale » de l'importance globale des caractéristiques. Des facteurs comme le genre et l'ethnicité n'apparaissent que plus loin dans cette liste. Cela ne signifie pas que ces facteurs ne sont plus significatifs. D'une part, les caractéristiques peuvent être corrélées ou interagir. Il est possible que des facteurs comme le genre soient corrélés avec d'autres caractéristiques que les arbres ont sélectionnées à la place, et que cela masque dans une certaine mesure leur effet.
La question la plus intéressante n'est pas tant de savoir si ces facteurs ont une importance globale (il est possible que leur effet moyen soit relativement faible), mais plutôt s'ils ont un effet significatif dans certains cas individuels. Ce sont les cas où le modèle nous dit quelque chose d'important sur l'expérience des individus, et pour ces individus, c'est cette expérience qui compte.
Application du package SHAP pour des explications au niveau du développeur
Heureusement, un ensemble de techniques pour une interprétation de modèle plus solide sur le plan théorique au niveau de la prédiction individuelle a vu le jour au cours des cinq dernières années environ. Elles sont collectivement appelées "Shapley Additive Explanations" (Explications additives de Shapley), et, commodément, sont implémentées dans le package Python shap.
Pour un modèle donné, cette bibliothèque calcule des « valeurs SHAP » à partir du modèle. Ces valeurs sont facilement interprétables, car chaque valeur correspond à l'effet d'une caractéristique sur la prédiction, dans ses unités. Une valeur SHAP de 1 000 signifie ici « a expliqué +1 000 $ du salaire prédit ». Les valeurs SHAP sont également computées de manière à tenter d'isoler la corrélation et l'interaction.
Les valeurs SHAP sont également calculées pour chaque entrée, et non pour le modèle dans son ensemble, ces explications sont donc disponibles individuellement pour chaque entrée. Il peut également estimer l'effet des interactions entre les caractéristiques séparément de l'effet principal de chaque caractéristique, pour chaque prédiction.
IA explicable : Découvrir les effets globaux des fonctionnalités
Les explications au niveau du développeur peuvent être agrégées en explications des effets des caractéristiques sur le salaire sur l'ensemble du jeu de données en faisant simplement la moyenne de leurs valeurs absolues. L'évaluation par SHAP des caractéristiques globalement les plus importantes est similaire :
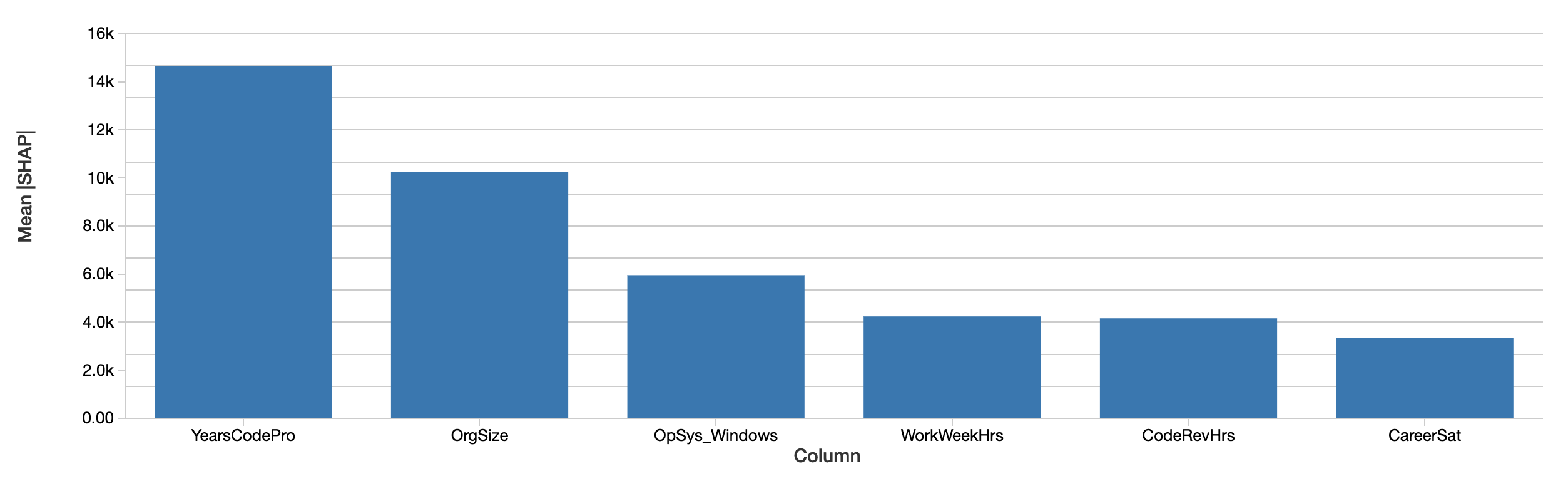
Les valeurs SHAP indiquent la même chose. Premièrement, SHAP est capable de quantifier l'effet sur le salaire en dollars, ce qui améliore considérablement l'interprétation des résultats. Le graphique ci-dessus représente l'effet absolu de chaque caractéristique sur le salaire prédit, moyenné sur l'ensemble des développeurs. Les années d'expérience en codage professionnel dominent toujours, expliquant en moyenne un effet de près de 15 000 $ sur le salaire.
Examen des effets du genre avec les valeurs SHAP
Nous avons spécifiquement examiné les effets du genre, de l'origine ethnique et d'autres facteurs qui ne devraient vraisemblablement pas être prédictifs en soi du salaire. Cet exemple examinera l'effet du genre, bien que cela ne suggère en aucun cas qu'il s'agisse du seul ou du plus important type de biais à rechercher.
Le genre n'est pas binaire, et l'enquête reconnaît les réponses "Homme", "Femme" et "Non-binaire, genderqueer ou non-conforme au genre" ainsi que "Trans" séparément. (Notez que bien que l'enquête enregistre également séparément les réponses concernant la sexualité, celles-ci ne sont pas prises en compte ici.) SHAP compute l'effet sur le salaire prédit pour chacun de ces éléments. Pour un développeur homme (s'identifiant uniquement comme un homme), l'effet du genre n'est pas seulement l'effet d'être un homme, mais de ne pas s'identifier comme une femme, une personne transgenre, etc.
Les valeurs SHAP nous permettent de lire la somme de ces effets pour les développeurs s'identifiant à chacune des quatre catégories :

Alors que le sexe des développeurs masculins explique une modeste variation de -230 $ à +890 $ avec une moyenne d'environ 225 $, pour les femmes, la fourchette est plus large, allant d'environ -4 260 $ à -690 $ avec une moyenne de -1 320 $. Les résultats pour les développeurs transgenres et non binaires sont similaires, bien que légèrement moins négatifs.
En évaluant ce que cela signifie ci-dessous, il est important de rappeler les limites des données et du modèle ici :
- Corrélation n'est pas causalité ; 'expliquer' le salaire prédit est suggestif, mais ne prouve pas qu'une caractéristique a directement entraîné un salaire plus élevé ou plus bas
- Le modèle n'est pas parfaitement précis
- Il ne s'agit que d'une année de données, et uniquement de développeurs américains.
- Cela ne reflète que le salaire de base, et non les bonus ou les actions, qui peuvent varier plus largement
Utiliser SHAP pour visualiser les caractéristiques qui interagissent avec le genre
La bibliothèque SHAP propose des visualisations intéressantes qui tirent parti de sa capacité à isoler l'effet des interactions entre les caractéristiques. Par exemple, les valeurs ci-dessus suggèrent que les développeurs qui s'identifient comme étant de sexe masculin gagneraient, selon les prédictions, un salaire légèrement plus élevé que les autres, mais est-ce tout ? Un graphique de dépendance comme celui-ci peut aider :
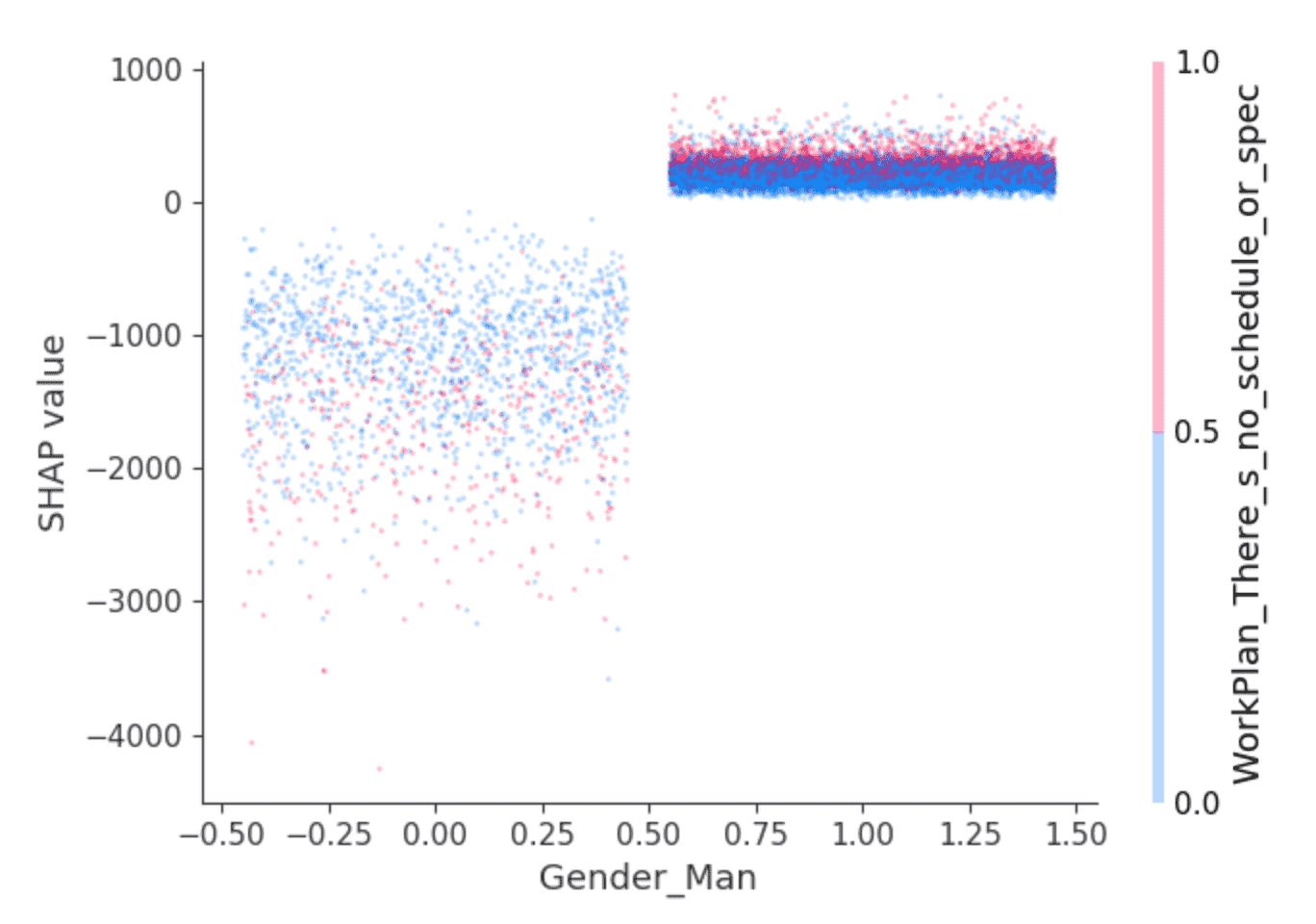
Les points représentent des développeurs. Les développeurs à gauche sont ceux qui ne s'identifient pas comme étant de sexe masculin, et à droite, ceux qui le font, qui sont principalement ceux s'identifiant uniquement comme étant de sexe masculin. (Les points sont répartis horizontalement de manière aléatoire pour plus de clarté.) L'axe des y représente la valeur SHAP, ou ce que le fait de s'identifier ou non comme étant de sexe masculin explique sur le salaire prédit pour chaque développeur. Comme ci-dessus, ceux qui ne s'identifient pas comme étant de sexe masculin présentent des valeurs SHAP globalement négatives et qui varient considérablement, tandis que les autres présentent systématiquement une petite valeur SHAP positive.
Qu'y a-t-il derrière cette variance ? SHAP peut sélectionner une deuxième caractéristique dont l'effet varie le plus selon que la personne s'identifie comme un homme ou non. Elle sélectionne la réponse "Je travaille sur ce qui semble le plus important ou urgent" à la question "À quel point votre travail est-il structuré ou planifié ?" Parmi les développeurs s'identifiant comme des hommes, ceux qui ont répondu de cette manière (points rouges) semblent avoir des valeurs SHAP légèrement plus élevées. Parmi les autres, l'effet est plus mitigé mais semble avoir des valeurs SHAP généralement plus faibles.
L'interprétation est laissée au lecteur, mais peut-être que les développeurs masculins qui se sentent valorisés dans ce sens bénéficient également de salaires légèrement plus élevés, tandis que d'autres développeurs en bénéficient lorsque cela va de pair avec des postes moins bien rémunérés ?
Explorer les instances ayant des effets de genre démesurés
Et si nous examinions le cas du développeur dont le salaire est le plus négativement affecté ? Tout comme il est possible d'examiner l'effet global des caractéristiques liées au sexe, il est possible de rechercher le développeur dont les caractéristiques liées au sexe ont eu le plus grand impact sur le salaire prédit. Cette personne est une femme, et l'effet est négatif. Selon le modèle, il est prédit qu'elle gagnera environ 4 260 $ de moins par an en raison de son sexe :

Le salaire prédit, d'un peu plus de 157 000 $, s'avère précis dans ce cas, puisque son salaire réel déclaré est de 150 000 $.
Les trois caractéristiques les plus positives et négatives qui influencent le salaire prédit sont qu'elle :
- A un diplôme universitaire (uniquement) (+18 200 $)
- A 10 ans d'expérience professionnelle (+9 400 $)
- S'identifie comme Asiatique de l'Est (+9 100 $)
- ...
- Travaille 40 heures par semaine (-4 000 $)
- Ne s'identifie pas comme un homme (-4 250 $)
- Travaille dans une organisation de taille moyenne comptant de 100 à 499 employés (-9 700 $)
Étant donné l'ampleur de l'effet sur le salaire prédit du fait de ne pas s'identifier comme un homme, nous pourrions nous arrêter ici et examiner les détails de ce cas hors ligne pour mieux comprendre le contexte entourant cette développeuse et déterminer si son expérience, son salaire, ou les deux, nécessitent un changement.
Expliquer les interactions à l'aide des valeurs SHAP
Plus de détails sont disponibles concernant ces -4 260 $. SHAP peut décomposer les effets de ces caractéristiques en interactions. L'effet total de s'identifier comme femme sur la prédiction peut être décomposé en l'effet de s'identifier comme femme et d'être responsable de Data Engineering, et de travailler avec Windows, etc.
L'effet sur le salaire prédit expliqué par les facteurs de genre en soi ne s'élève qu'à environ -630 $. Au contraire, SHAP attribue la plupart des effets du genre à des interactions avec d'autres caractéristiques :
S'identifier comme femme et travailler avec PostgreSQL affecte légèrement positivement le salaire prédit, tandis que s'identifier également comme Asiatique de l'Est l'affecte plus négativement. L'interprétation de ces valeurs à ce niveau de granularité est difficile dans ce contexte, mais ce niveau d'explication supplémentaire est disponible.
Appliquer SHAP avec Apache Spark
Les valeurs SHAP sont computées indépendamment pour chaque ligne, compte tenu du modèle, et cela aurait donc pu également être fait en parallèle avec Spark. L'exemple suivant calcule les valeurs SHAP en parallèle et localise de la même manière les développeurs avec des valeurs SHAP démesurées liées au genre :
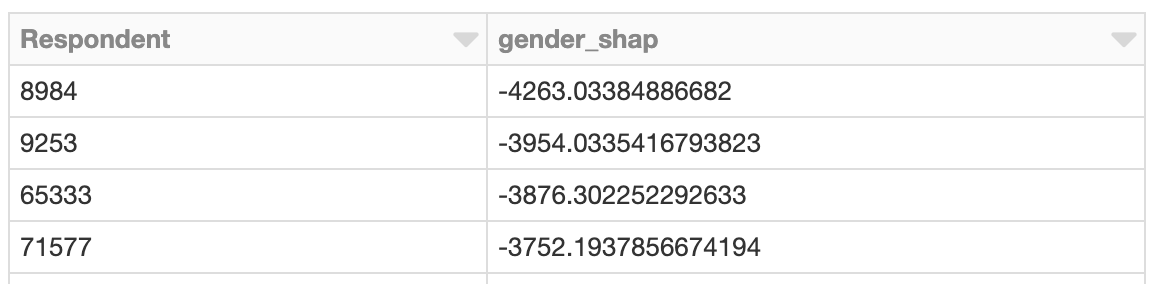
Regroupement des valeurs SHAP
L'application de Spark est avantageuse lorsqu'il y a un grand nombre de prédictions à évaluer avec SHAP. Étant donné ce résultat, il est également possible d'utiliser Spark pour regrouper les résultats avec, par exemple, bisecting k-means:
Le cluster dont les effets SHAP totaux liés au genre sont les plus négatifs pourrait mériter une investigation plus approfondie. Quelles sont les valeurs SHAP de ces répondants dans le cluster ? À quoi ressemblent les membres du cluster par rapport à l'ensemble de la population des développeurs ?
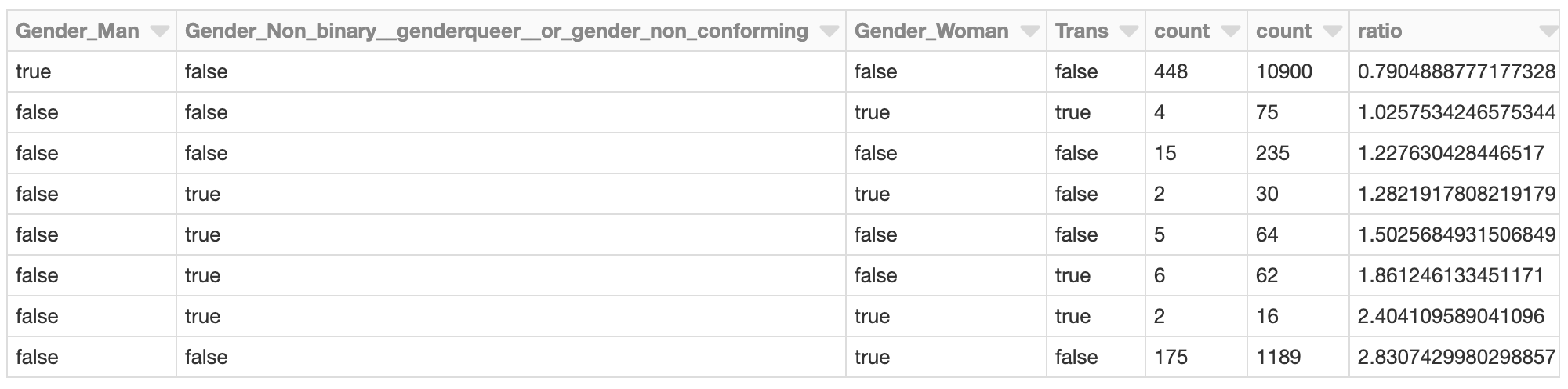
Les développeurs s'identifiant comme des femmes (uniquement) sont représentés dans ce cluster à un taux près de 2,8 fois supérieur à celui de la population globale de développeurs, par exemple. Ce n'est pas surprenant compte tenu de l'analyse précédente. Ce cluster pourrait faire l'objet d'une enquête plus approfondie pour évaluer d'autres facteurs spécifiques à ce groupe qui contribuent à un salaire prédit globalement plus faible.
Conclusion
Ce type d'analyse avec SHAP peut être exécuté pour n'importe quel modèle, et également à grande échelle. En tant qu'outil d'analyse, il transforme les modèles en détectives de données, pour faire remonter des instances individuelles dont les prédictions suggèrent qu'elles méritent un examen plus approfondi. Le résultat de SHAP est facilement interprétable et produit des graphiques intuitifs, qui peuvent être évalués au cas par cas par les utilisateurs professionnels.
Bien sûr, cette analyse ne se limite pas à l'examen des questions de biais liés au genre, à l'âge ou à la race. Plus prosaïquement, elle pourrait être appliquée aux modèles de churn client. Dans ce cas, la question n'est pas seulement "ce client va-t-il churner ?" mais "pourquoi le client churn-t-il ?" Un client qui annule son abonnement en raison du prix peut se voir proposer une réduction, tandis qu'un client qui annule en raison d'une utilisation limitée pourrait avoir besoin d'une montée en gamme.
Enfin, cette analyse peut être exécutée dans le cadre d'un processus de validation, apportant une plus grande transparence au modèle de machine learning dans son ensemble. La validation de modèle se concentre souvent sur la précision globale d'un modèle. Elle devrait également se concentrer sur le « raisonnement » du modèle, ou sur les caractéristiques qui ont le plus contribué aux prédictions. Avec SHAP, elle peut également aider à détecter lorsque trop d'explications de prédictions individuelles sont en contradiction avec l'importance globale des caractéristiques.
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.