Agents d'IA de production
Une plateforme unifiée pour créer et gouverner des agents d'IA qui s'améliorent continuellement.
Maîtrisez la prolifération des agents. Développez des agents en toute confiance.
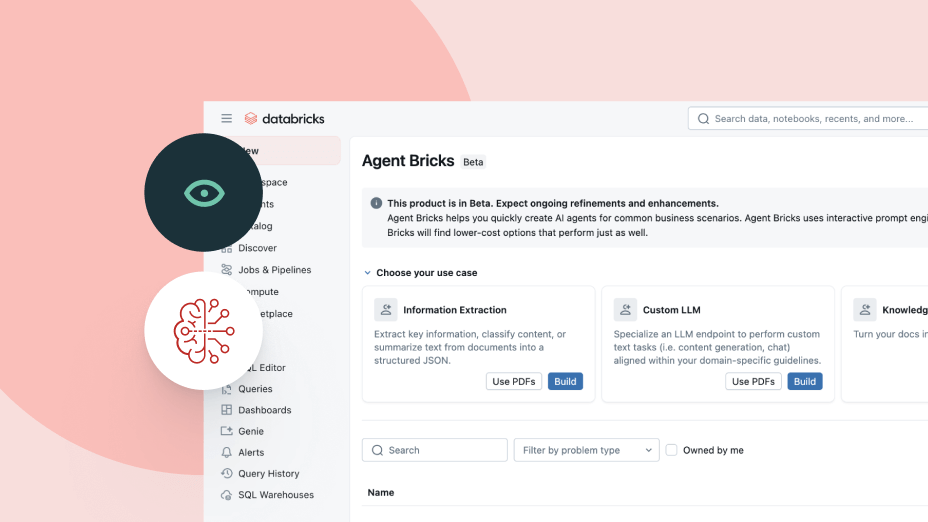
Unifiez le développement, la gestion et la gouvernance des agents d'IA d'entreprise.Des agents qui connaissent vos données
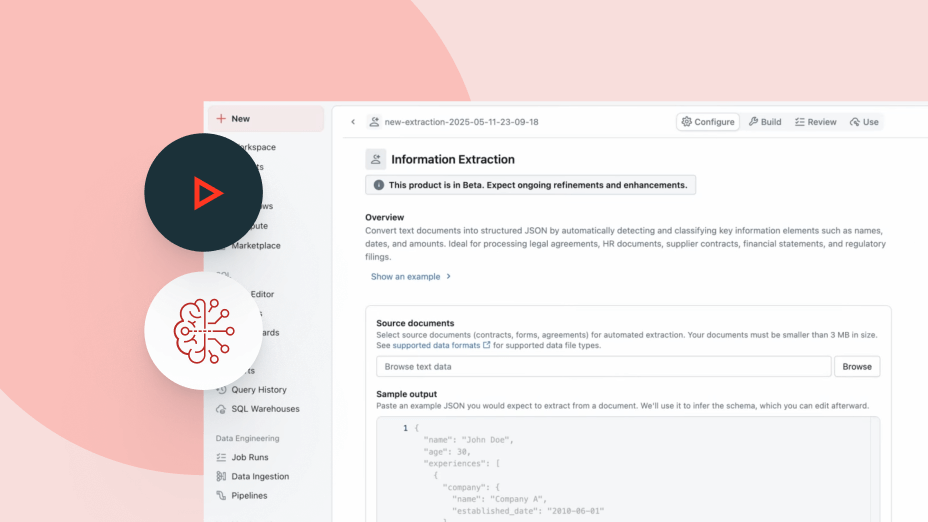
Agent Bricks utilise le contexte de votre entreprise (schémas, définitions métier et sémantiques personnalisées) pour prendre des décisions plus intelligentes quant au choix des outils et des tables à utiliser, à la jonction des données et et à l'élaboration de réponses précises et cohérentes.
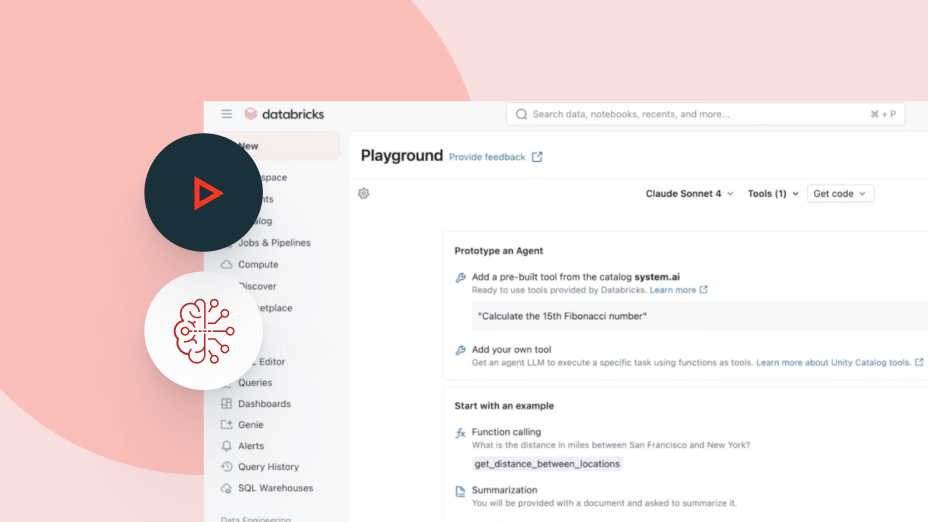
Une plateforme ouverte et Multi-IA
Accédez à tous les grands modèles d'IA open source ou commerciaux (OpenAI, Anthropic et Google) via une même plateforme. Agent Bricks vous permet de changer instantanément de modèle pour optimiser les coûts, la qualité et les performances de vos systèmes sans avoir à réorganiser votre environnement.
Gouvernance unifiée
Databricks est la seule plateforme qui régit l'ensemble de la pile, des données aux modèles d'IA, dans un système d'enregistrement unique. Suivez chaque agent, serveur MCP, modèle et outil avec des responsabilités clairement établies et des autorisations appliquées d'un bout à l'autre pour que les agents ne quittent jamais leur périmètre autorisé.

LES MEILLEURES ÉQUIPES RÉUSSISSENT AVEC AGENT BRICKS
Tout ce dont vous avez besoin pour développer, gouverner et déployer des agents à grande échelle
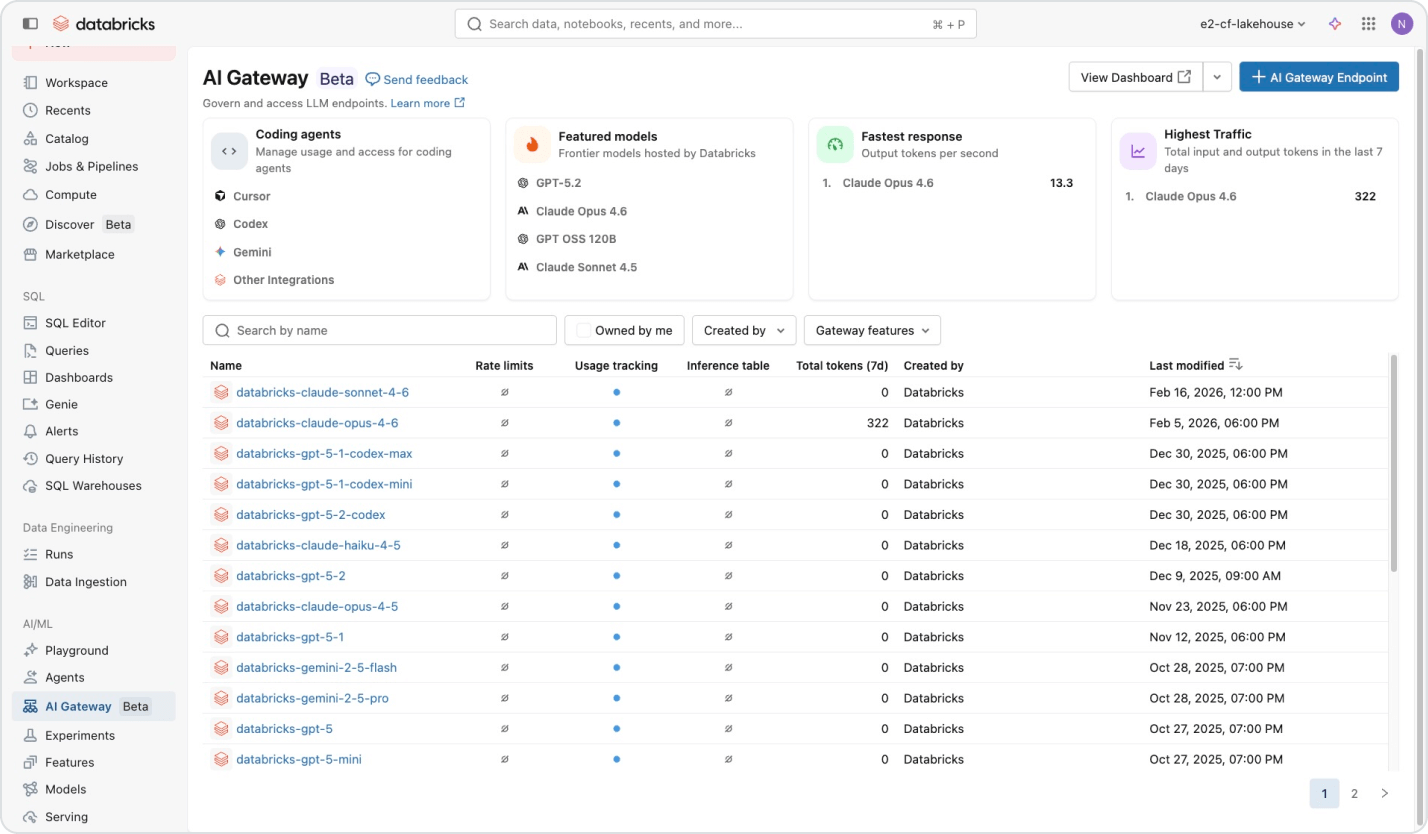
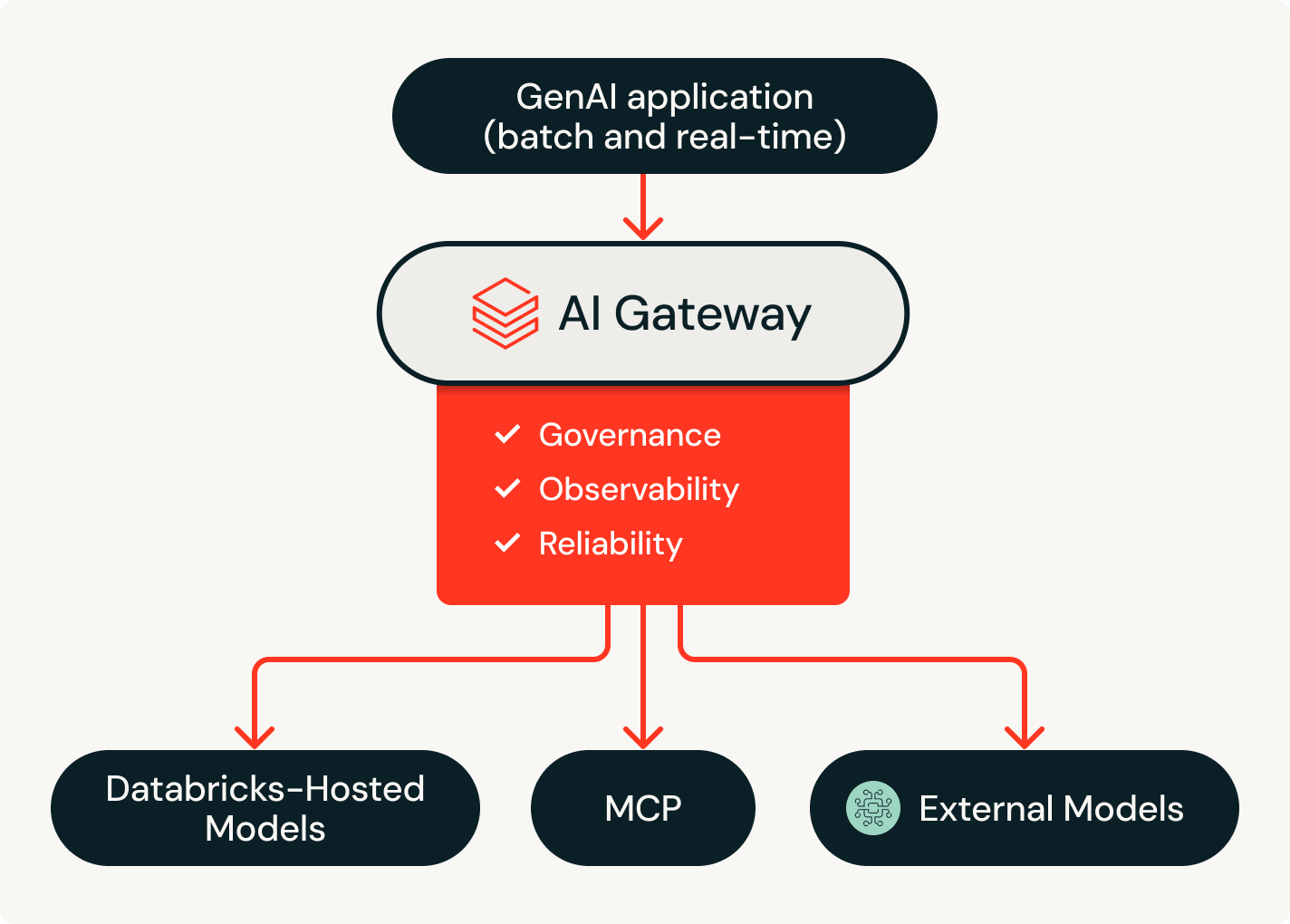
Tous les modèles que vous voulez, avec un contrat unique sans engagement
Accédez aux modèles d'IA d'OpenAI, d'Anthropic, de Google, de Meta et bien d'autres via une plateforme unique. Le routage intelligent et les fallbacks automatiques assurent la continuité du fonctionnement des agents, même en cas de panne des fournisseurs. Unity Catalog applique des autorisations granulaires et des limites de débit par utilisateur ou par équipe, pour vous permettre d'élargir l'accès aux modèles sans perdre le contrôle.
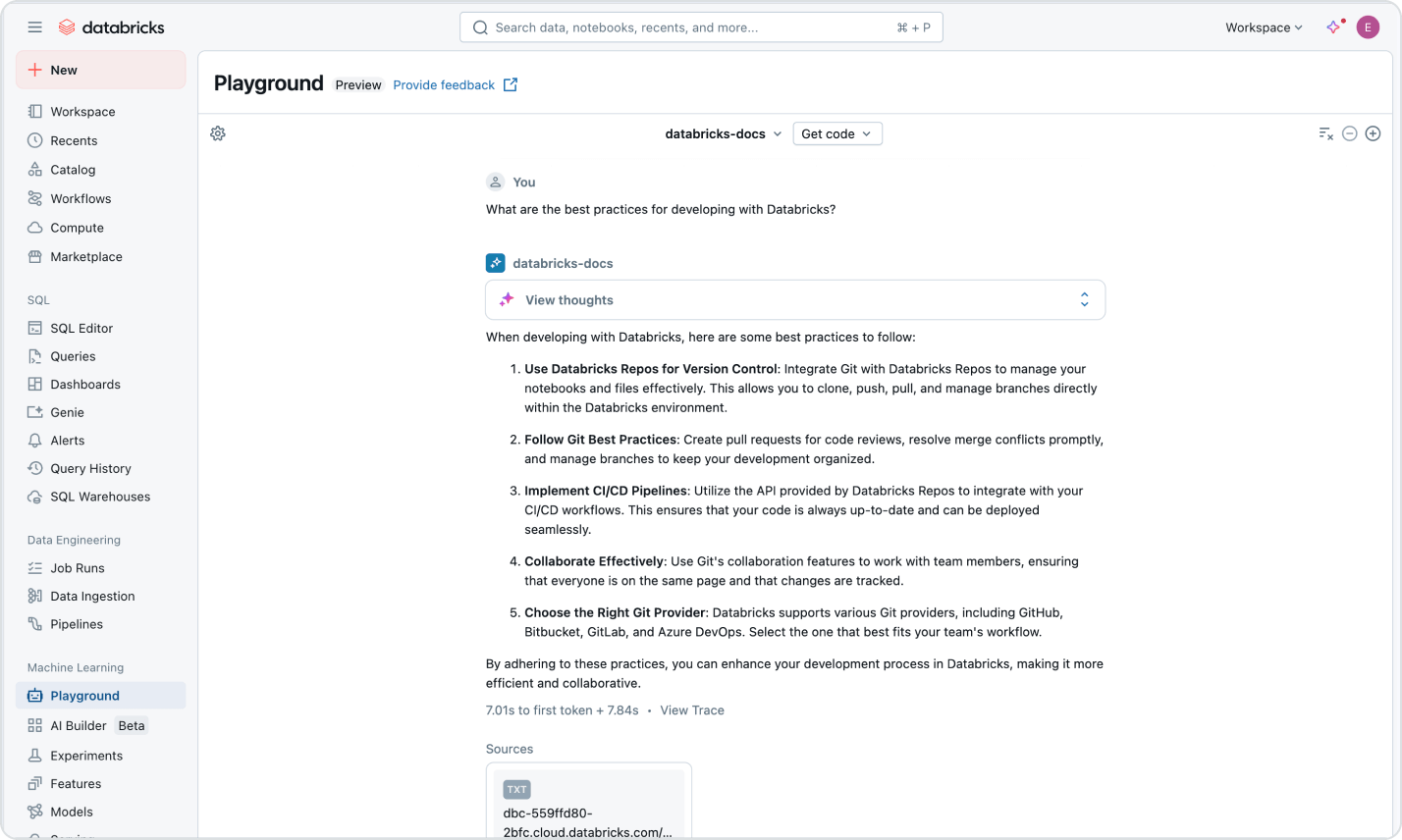



Les tarifs basés sur l'utilisation permettent de maîtriser les dépenses
Ne payez que les produits que vous utilisez, à la seconde près.En savoir plus
Découvrez comment la Databricks Data Intelligence Platform donne du pouvoir à vos équipes sur l'ensemble de vos charges de travail de données et d'IA.
Genie
Obtenez des insights à partir des données, tout simplement en posant des questions en langage naturel.

Databricks Apps
Transformez les agents personnalisés en applications d'IA sécurisées et orientées utilisateurs sur Databricks. Créez des expériences complètes basées sur des données et des modèles gouvernés, avec une infrastructure serverless et une évolutivité intégrée.

Mise à disposition de modèles
Déployez et gouvernez n'importe quel modèle ou agent d'IA en production grâce à l'intégration de l'observabilité, de l'évolutivité et des contrôles d'entreprise.

AI Search
Alimentez des applications d'IA en temps réel grâce à une base de données vectorielle haute performance qui synchronise vos données sources en continu.

Unity Catalog
Gérez facilement des données structurées et non structurées, des modèles de ML, des notebooks, des tableaux de bord et des fichiers répartis sur différents clouds et plateformes.

Intelligence artificielle
Découvrez la suite complète d'outils Databricks AI pour des systèmes d'agents IA de bout en bout.

La plateforme de Data Intelligence de Databricks
Explorez tout l'éventail des outils disponibles sur la plateforme Databricks pour intégrer les données et l'IA de toute votre organisation de façon fluide et transparente.
Passez à l'étape suivante




FAQ Agent Bricks
Prêts à devenir une entreprise axée sur les données et l'IA ?
Faites le premier pas de votre transformation data