Bonnes pratiques pour l'évaluation des applications RAG à destination des LLM
Une étude de cas sur le bot de documentation de Databricks
par Quinn Leng, Kasey Uhlenhuth et Alkis Polyzotis
Les chatbots sont le cas d'usage le plus largement adopté pour exploiter les puissantes capacités de conversation et de raisonnement des grands modèles de langage (LLM). L'architecture de génération augmentée par récupération (RAG) est en passe de devenir la norme du secteur pour le développement de chatbots, car elle combine les avantages d'une base de connaissances (via une banque de vecteurs) et de modèles génératifs (p. ex. GPT-3.5 et GPT-4) afin de réduire les hallucinations, de conserver des informations à jour et d'exploiter des connaissances spécifiques à un domaine. Cependant, l'évaluation de la qualité des réponses des chatbots reste aujourd'hui un problème non résolu. En l'absence de normes sectorielles définies, les entreprises ont recours à la notation humaine (étiquetage), ce qui prend du temps et est difficile à monter en charge.
Nous avons appliqué la théorie à la pratique pour aider à établir les meilleures pratiques pour l'évaluation automatisée des LLM afin que vous puissiez déployer des applications RAG en production rapidement et en toute confiance. Cet article de blog est le premier d'une série d'études que nous menons chez Databricks pour fournir des enseignements sur l'évaluation des LLM. Toutes les recherches présentées dans cet article ont été menées par Quinn Leng, ingénieur logiciel senior chez Databricks et créateur de l'assistant IA pour la documentation Databricks.
Défis de l'auto-évaluation en pratique
Récemment, la communauté LLM a exploré l'utilisation de « LLM en tant que juges » pour l'évaluation automatisée. Nombreux sont ceux qui utilisent des LLM puissants, tels que GPT-4, pour évaluer les résultats de leurs LLM. Le document de recherche du groupe lmsys explore la faisabilité et les avantages/inconvénients de l'utilisation de divers LLM (GPT-4, ClaudeV1, GPT-3.5) en tant que juges pour des tâches d'écriture, de mathématiques et de connaissance du monde.
Malgré toutes ces recherches de qualité, de nombreuses questions subsistent quant à la manière d'appliquer les LLM juges en pratique :
- Alignement avec la notation humaine: plus précisément pour un chatbot de Q&A sur documents, dans quelle mesure la notation d'un juge LLM reflète-t-elle la préférence humaine réelle en termes de justesse, de lisibilité et d'exhaustivité des réponses ?
- Précision grâce aux exemples: quelle est l'efficacité de la fourniture de quelques exemples de notation au LLM juge et dans quelle mesure cela augmente-t-il la fiabilité et la réutilisabilité du LLM juge sur différentes métriques ?
- Échelles de notation appropriées: quelle échelle de notation est recommandée, car différents frameworks utilisent différentes échelles (p. ex., AzureML utilise une échelle de 0 à 100, tandis que langchain utilise des échelles binaires) ?
- Applicabilité aux différents cas d'usage: Avec la même métrique d'évaluation (par ex. l'exactitude), dans quelle mesure la métrique d'évaluation peut-elle être réutilisée pour différents cas d'usage (par ex. discussion informelle, résumé de contenu, génération augmentée par récupération) ?
Application d'une auto-évaluation efficace pour les applications RAG
Nous avons exploré les options possibles pour les questions décrites ci-dessus dans le contexte de notre propre application de chatbot chez Databricks. Nous pensons que nos conclusions peuvent être généralisées et peuvent donc aider votre équipe à évaluer efficacement les chatbots basés sur RAG à moindre coût et plus rapidement :
- Un LLM-as-a-judge concorde avec la notation humaine sur plus de 80 % des jugements. L'utilisation de LLM-as-a-judge pour l'évaluation de notre chatbot basé sur des documents s'est avérée aussi efficace que celle des juges humains, correspondant au score exact dans plus de 80 % des jugements et se situant à une distance d'un point (sur une échelle de 0 à 3) dans plus de 95 % des jugements.
- Réduisez les coûts en utilisant GPT-3.5 avec des exemples. GPT-3.5 peut être utilisé comme un LLM juge si vous fournissez des exemples pour chaque note. En raison de la limite de la taille du contexte, il est uniquement pratique d'utiliser une échelle de notation de faible précision. L'utilisation de GPT-3.5 avec des exemples au lieu de GPT-4 réduit de 10 fois le coût du LLM juge et multiplie la vitesse par plus de 3.
- Utilisez des échelles de notation à faible précision pour une interprétation plus facile. Nous avons constaté que les scores de notation à faible précision comme 0, 1, 2, 3 ou même binaires (0, 1) peuvent largement conserver la précision par rapport aux échelles à plus haute précision comme 0 à 10,0 ou 0 à 100,0, tout en facilitant considérablement la fourniture de grilles d'évaluation aux annotateurs humains et aux juges LLM. L'utilisation d'une échelle à plus faible précision permet également d'assurer la cohérence des échelles de notation entre les différents juges LLM (par ex. entre GPT-4 et claude2).
- Les applications RAG nécessitent leurs propres benchmarks. Un modèle peut avoir de bonnes performances sur un benchmark spécialisé publié (p. ex. conversation informelle, mathématiques ou écriture créative), mais cela ne garantit pas de bonnes performances sur d'autres tâches (p. ex. répondre à des questions à partir d'un contexte donné). Les benchmarks ne doivent être utilisés que si le cas d'usage correspond, c'est-à-dire qu'une application RAG ne doit être évaluée qu'avec un benchmark RAG.
D'après nos recherches, nous recommandons la procédure suivante lors de l'utilisation d'un LLM juge :
- Utiliser une échelle de notation de 1 à 5
- Utiliser GPT-4 comme LLM juge sans exemples pour comprendre les règles de notation
- Passez votre juge LLM à GPT-3.5 avec un exemple par score
Notre méthodologie pour établir les meilleures pratiques
La suite de cet article vous présentera la série d'expériences que nous avons menées pour élaborer ces meilleures pratiques.
Configuration de l'Experimentation
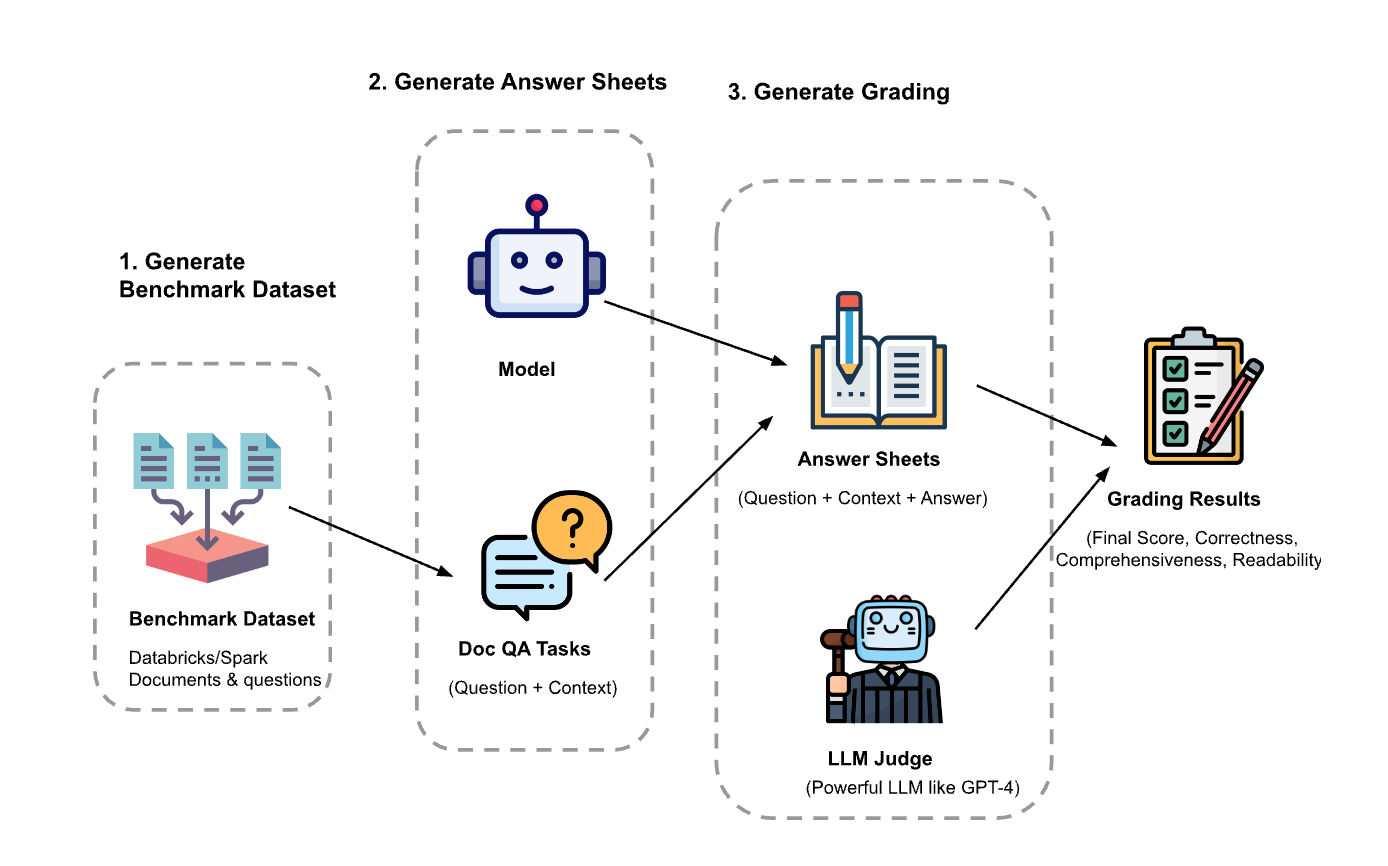
L'expérimentation s'est déroulée en trois étapes :
Génération du dataset d'évaluation: Nous avons créé un dataset à partir de 100 questions et du contexte des documents Databricks. Le contexte représente des (fragments de) documents pertinents pour la question.

- Générer des feuilles de réponses: en utilisant le dataset d'évaluation, nous avons invité différents modèles de langage à générer des réponses et avons stocké les paires question-contexte-réponse dans un dataset appelé « feuilles de réponses ». Dans cette étude, nous avons utilisé GPT-4, GPT-3.5, Claude-v1, Llama2-70b-chat, Vicuna-33b et mpt-30b-chat.
- Générer des notes: à partir des feuilles de réponses, nous avons utilisé divers LLM pour générer des notes et leur justification. Les notes sont un score composite d'Exactitude (pondération : 60 %), d'Exhaustivité (pondération : 20 %) et de Lisibilité (pondération : 20 %). Nous avons choisi ce système de pondération pour refléter notre préférence pour l'Exactitude dans les réponses générées. D'autres applications peuvent ajuster ces pondérations différemment, mais nous nous attendons à ce que l'Exactitude reste un facteur dominant.
De plus, les techniques suivantes ont été utilisées pour éviter le biais de position et améliorer la fiabilité :
- Basse température (température de 0,1) pour garantir la reproductibilité.
- Notation à réponse unique au lieu d'une comparaison par paires.
- Chaîne de pensées pour permettre au LLM de raisonner sur le processus de notation avant de donner la note finale.
- Génération few-shot où le LLM reçoit plusieurs exemples dans la grille de notation pour chaque valeur de score sur chaque facteur (Exactitude, Exhaustivité, Lisibilité).
Experimentation 1 : Alignement avec la notation humaine
Pour confirmer le niveau de concordance entre les annotateurs humains et les LLM juges, nous avons envoyé des fiches de réponses (échelle de notation de 0 à 3) de gpt-3.5-turbo et vicuna-33b à une entreprise d'étiquetage afin de collecter des étiquettes humaines, puis nous avons comparé le résultat avec la sortie de notation de GPT-4. Voici les conclusions :
Les juges humains et GPT-4 peuvent atteindre un niveau de concordance supérieur à 80 % sur le score d'exactitude et de lisibilité. Et si nous abaissons l'exigence à une différence de score inférieure ou égale à 1, le niveau de concordance peut atteindre plus de 95 %.
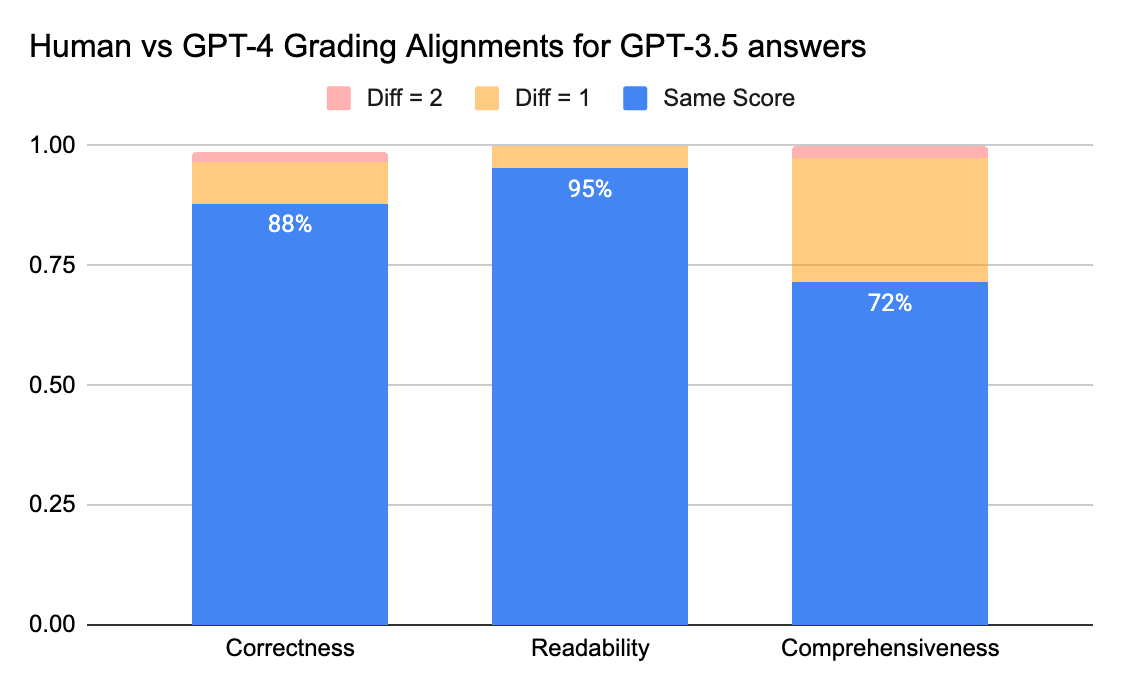
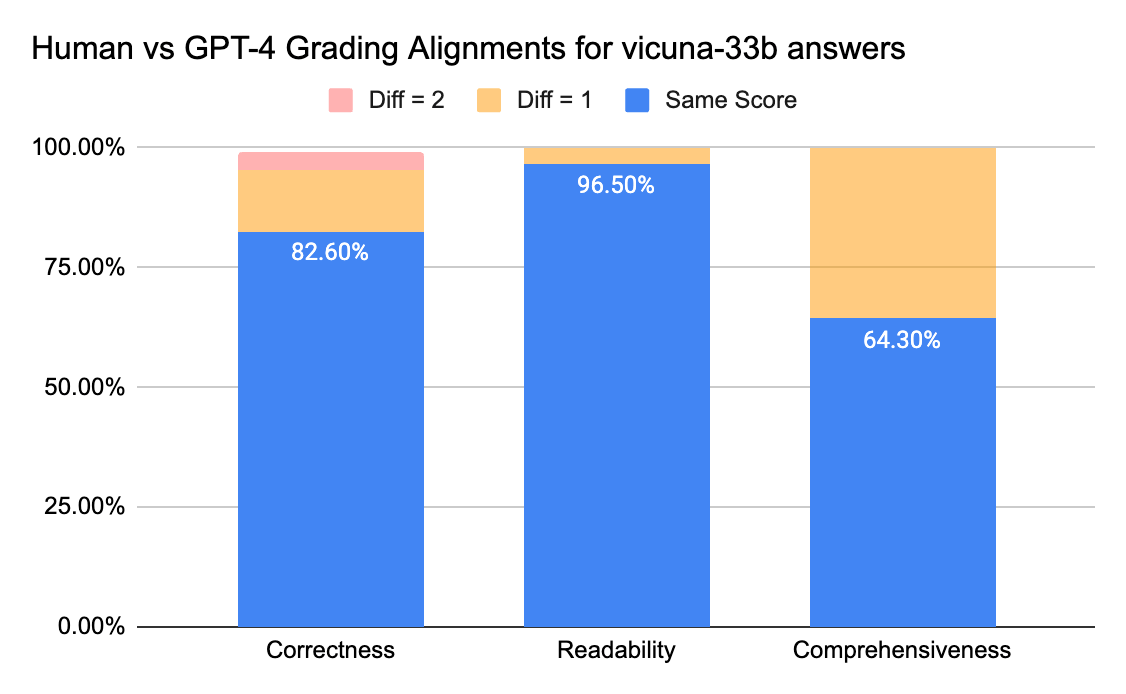
La métrique d'Exhaustivité présente moins d'alignement, ce qui correspond à ce que nous ont rapporté les parties prenantes commerciales, qui ont indiqué que le terme « exhaustif » semble plus subjectif que des métriques comme l'Exactitude ou la Lisibilité.
Experimentation 2 : Précision par les exemples
Le document lmsys utilise ce prompt pour demander au juge LLM d'évaluer la réponse en fonction de son utilité, de sa pertinence, de son exactitude, de sa profondeur, de sa créativité et de son niveau de détail. Cependant, l'article ne donne pas de détails sur la grille de notation. D'après nos recherches, nous avons constaté que de nombreux facteurs peuvent affecter de manière significative le score final, par exemple :
- L'importance des différents facteurs : Utilité, Pertinence, Précision, Profondeur, Créativité
- L'interprétation de facteurs tels que l'Utilité est ambiguë
- Si différents facteurs sont en conflit les uns avec les autres, lorsqu'une réponse est utile, mais n'est pas exacte
Nous avons développé une grille d'évaluation pour donner des instructions à un LLM juge pour une échelle de notation donnée, en essayant ce qui suit :
- Prompt d'origine: Vous trouverez ci-dessous le prompt d'origine utilisé dans l'article de lmsys :
|
Nous avons adapté le prompt de l'article lmsys original pour émettre nos métriques sur l'exactitude, l'exhaustivité et la lisibilité, et également pour inviter le juge à fournir une justification d'une ligne avant de donner chaque score (afin de bénéficier du raisonnement en chaîne de pensée). Vous trouverez ci-dessous la version zero-shot du prompt qui ne fournit aucun exemple, et la version few-shot du prompt qui fournit un exemple pour chaque score. Nous avons ensuite utilisé les mêmes feuilles de réponses en entrée et comparé les résultats notés des deux types de prompts.
- Apprentissage zero-shot: exiger du juge LLM qu'il fournisse nos métriques sur la justesse, l'exhaustivité et la lisibilité, et l'inviter à fournir une justification d'une ligne pour chaque note.
- Apprentissage few-shot: nous avons adapté le prompt zero-shot pour fournir des exemples explicites pour chaque note sur l'échelle. Le nouveau prompt :
Cette Experimentation nous a appris plusieurs choses :
- L'utilisation du prompt few-shot avec GPT-4 n'a pas fait de différence évidente dans la cohérence des résultats. Lorsque nous avons inclus la grille d'évaluation détaillée avec des exemples, nous n'avons pas constaté d'amélioration notable dans les résultats d'évaluation de GPT-4 sur différents modèles LLM. Il est intéressant de noter que cela a provoqué une légère variance dans la plage des scores.
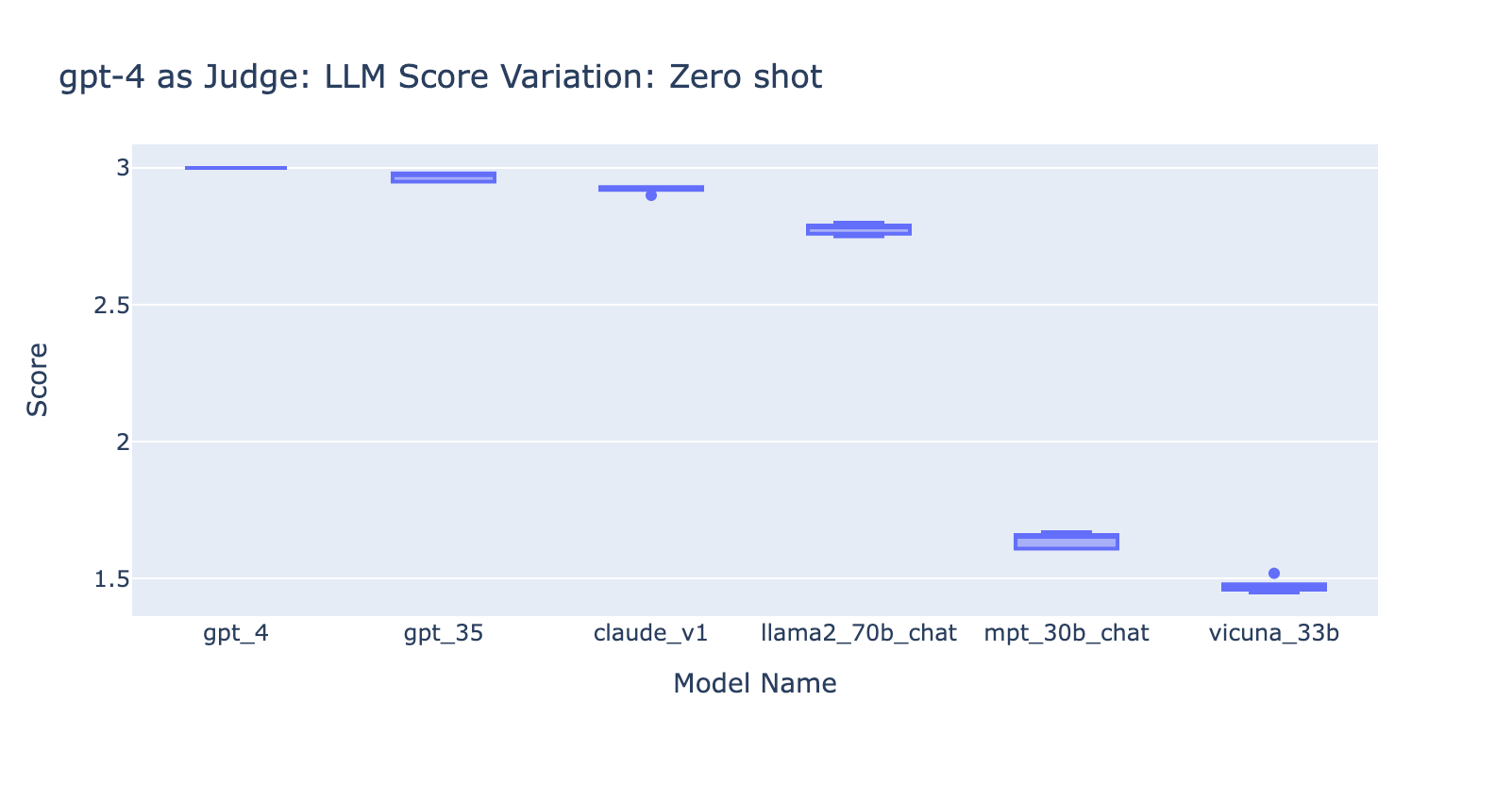
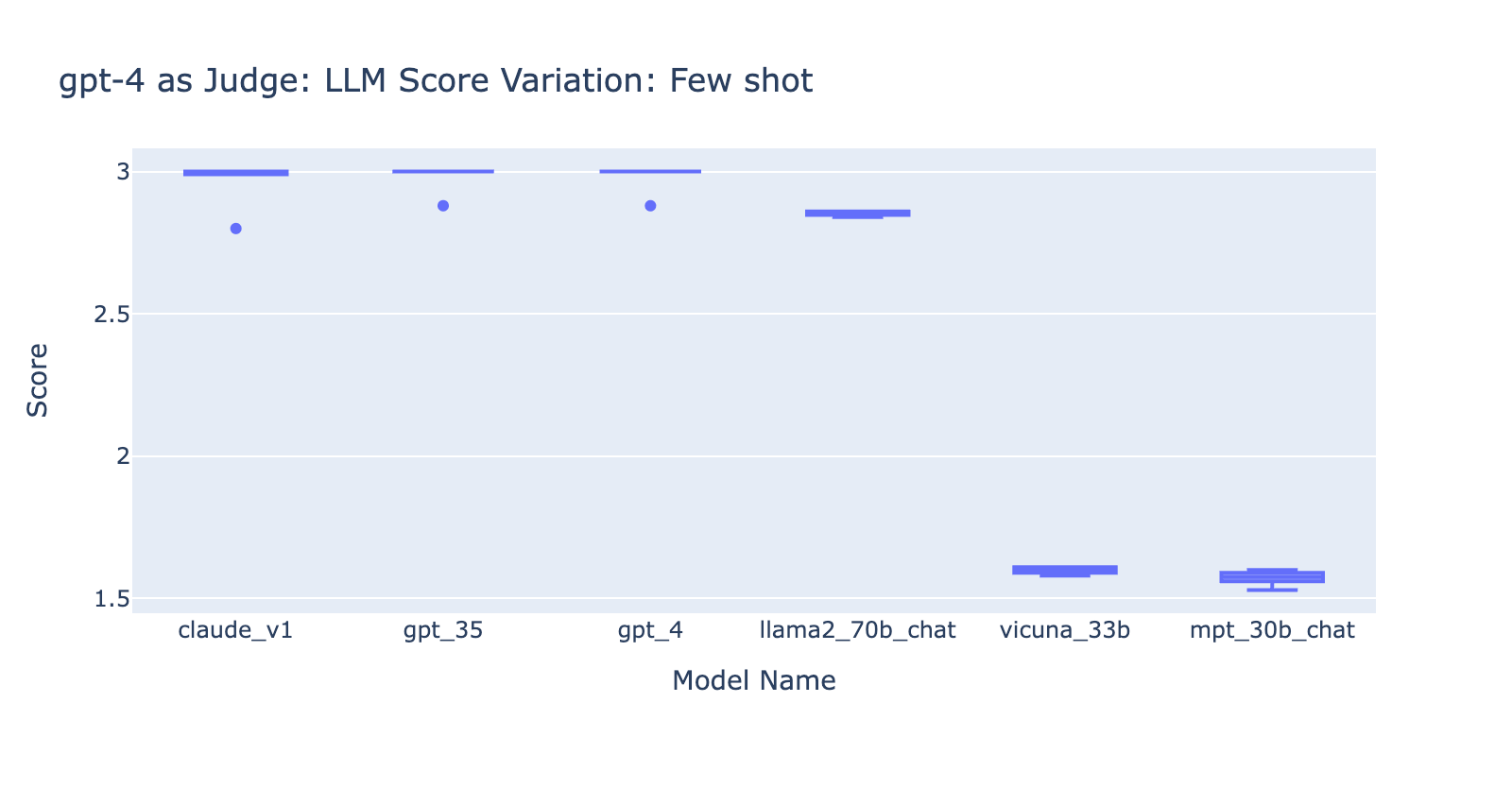
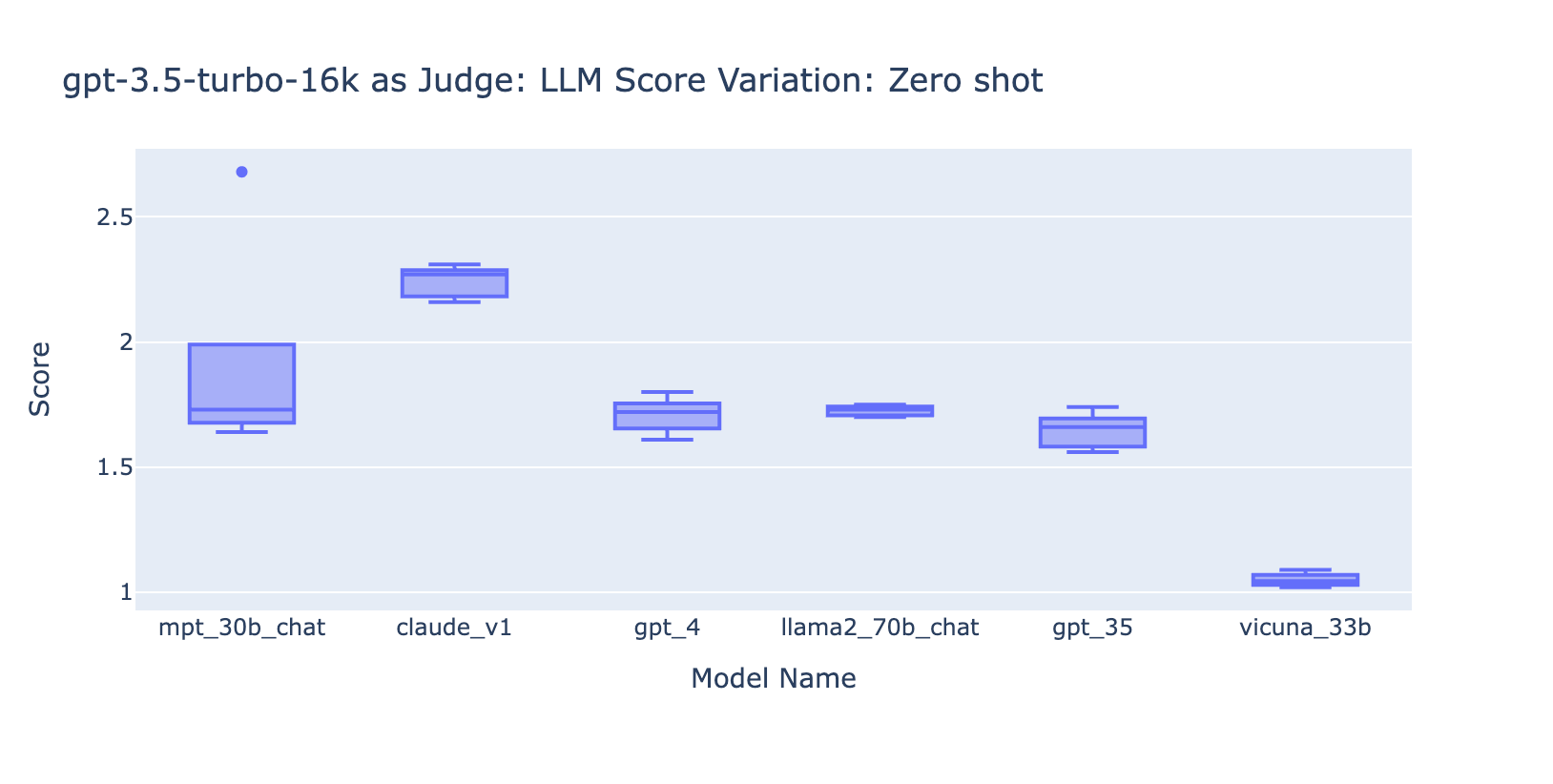
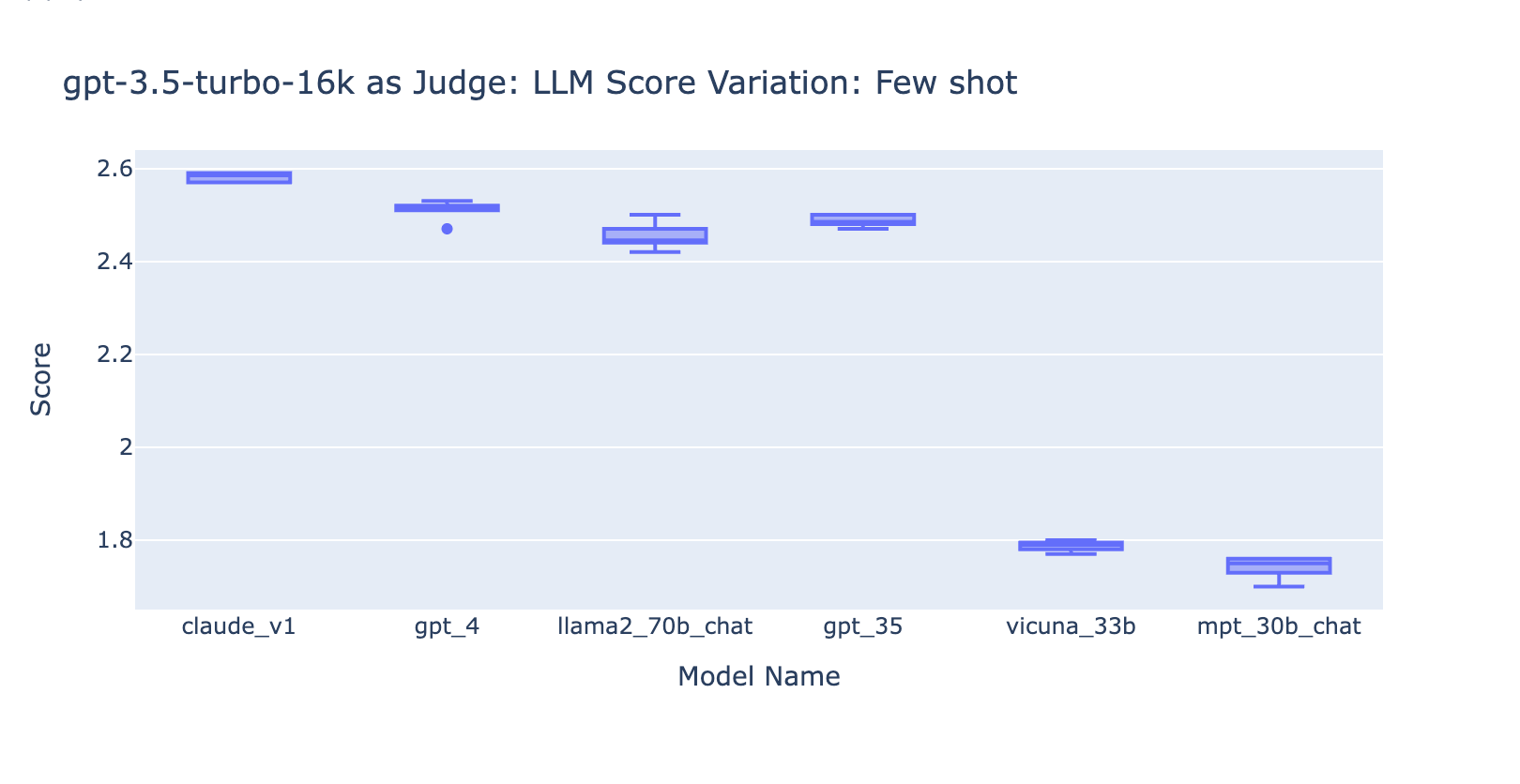
- L'inclusion de quelques exemples pour GPT-3.5-turbo-16k améliore considérablement la cohérence des scores et rend le résultat utilisable. L'inclusion d'une grille d'évaluation détaillée/d'exemples améliore très nettement le résultat de la notation de GPT-3.5 (graphique à droite). Bien que la valeur réelle du score moyen soit légèrement différente entre GPT-4 et GPT-3.5 (score 3,0 contre score 2,6), le classement et la précision restent assez cohérents
- Au contraire, (capture d'écran à gauche) l'utilisation de GPT-3.5 sans grille de notation donne des résultats très incohérents et est totalement inutilisable
- Notez que nous utilisons GPT-3.5-turbo-16k au lieu de GPT-3.5-turbo car le prompt peut dépasser 4 000 tokens.
Experimentation 3 : Échelles de notation appropriées
L'article sur le LLM en tant que juge utilise une échelle non entière de 0 à 10 (c.-à-d. un flottant) pour l'échelle de notation ; en d'autres termes, il utilise une grille de haute précision pour le score final. Nous avons constaté que ces échelles de haute précision causaient des problèmes en aval avec les éléments suivants :
- Cohérence: Les évaluateurs, qu'ils soient humains ou LLM, ont eu du mal à maintenir le même standard pour le même score lors de la notation sur une échelle de haute précision. Par conséquent, nous avons constaté que les scores de sortie sont moins cohérents entre les juges si vous passez d'échelles à faible précision à des échelles à haute précision.
- Explicabilité: De plus, si nous voulons effectuer une validation croisée des résultats évalués par le LLM avec les résultats évalués par des humains, nous devons fournir des instructions sur la façon de noter les réponses. Il est très difficile de fournir des instructions précises pour chaque « score » dans une échelle de notation de haute précision – par exemple, quel est un bon exemple pour une réponse notée 5,1 par rapport à 5,6 ?
Nous avons expérimenté plusieurs échelles de notation de faible précision pour fournir des conseils sur la « meilleure » à utiliser. Finalement, nous recommandons une échelle d'entiers de 0 à 3 ou de 0 à 4 (si vous souhaitez vous en tenir à l'échelle de Likert). Nous avons essayé les échelles 0-10, 1-5, 0-3 et 0-1 et avons appris ce qui suit :
- La notation binaire fonctionne pour des métriques simples comme l'« utilisabilité » ou « bon/mauvais ».
- Pour les échelles de 0 à 10, il est difficile de trouver des critères de distinction entre tous les scores.
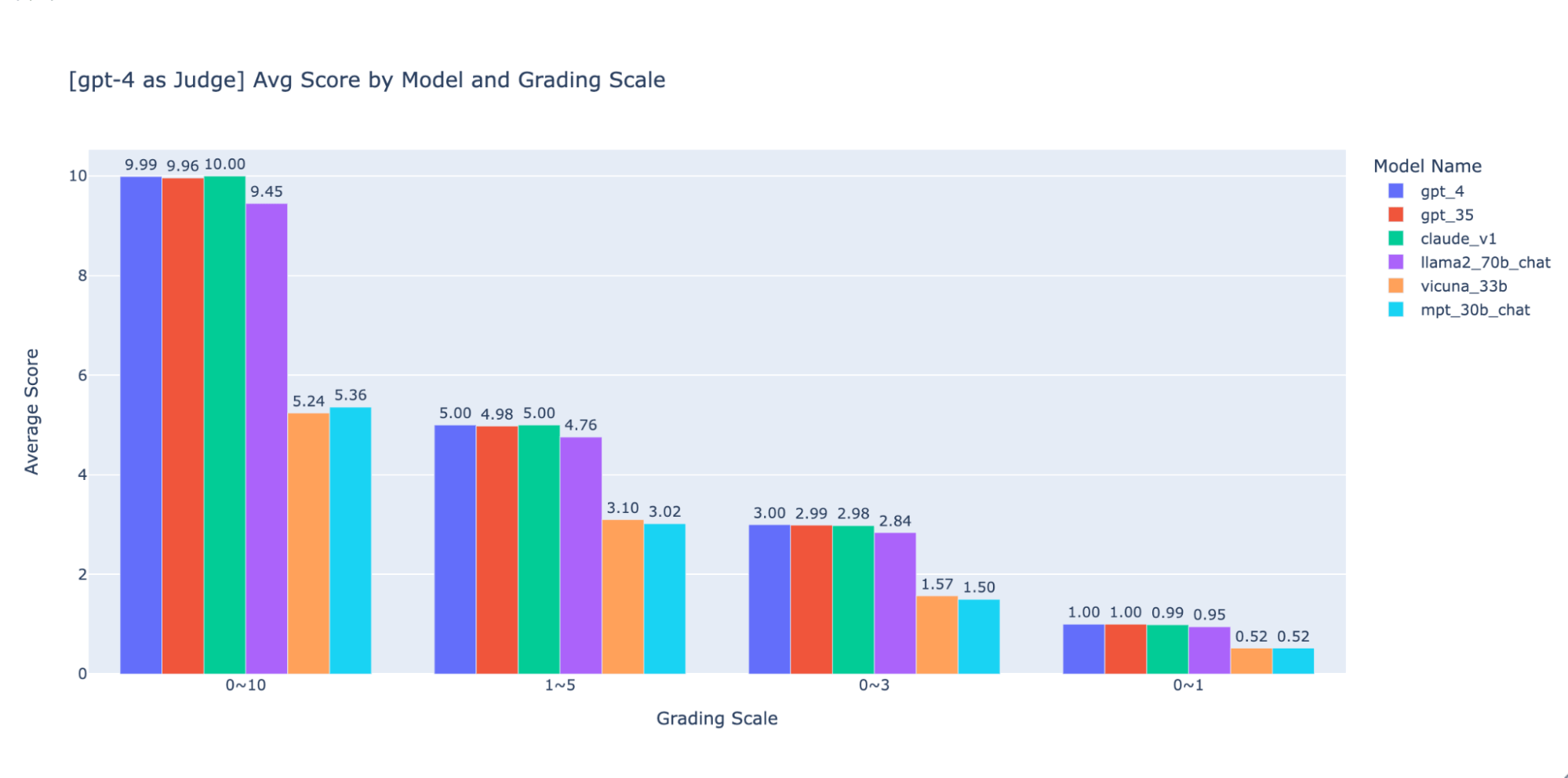
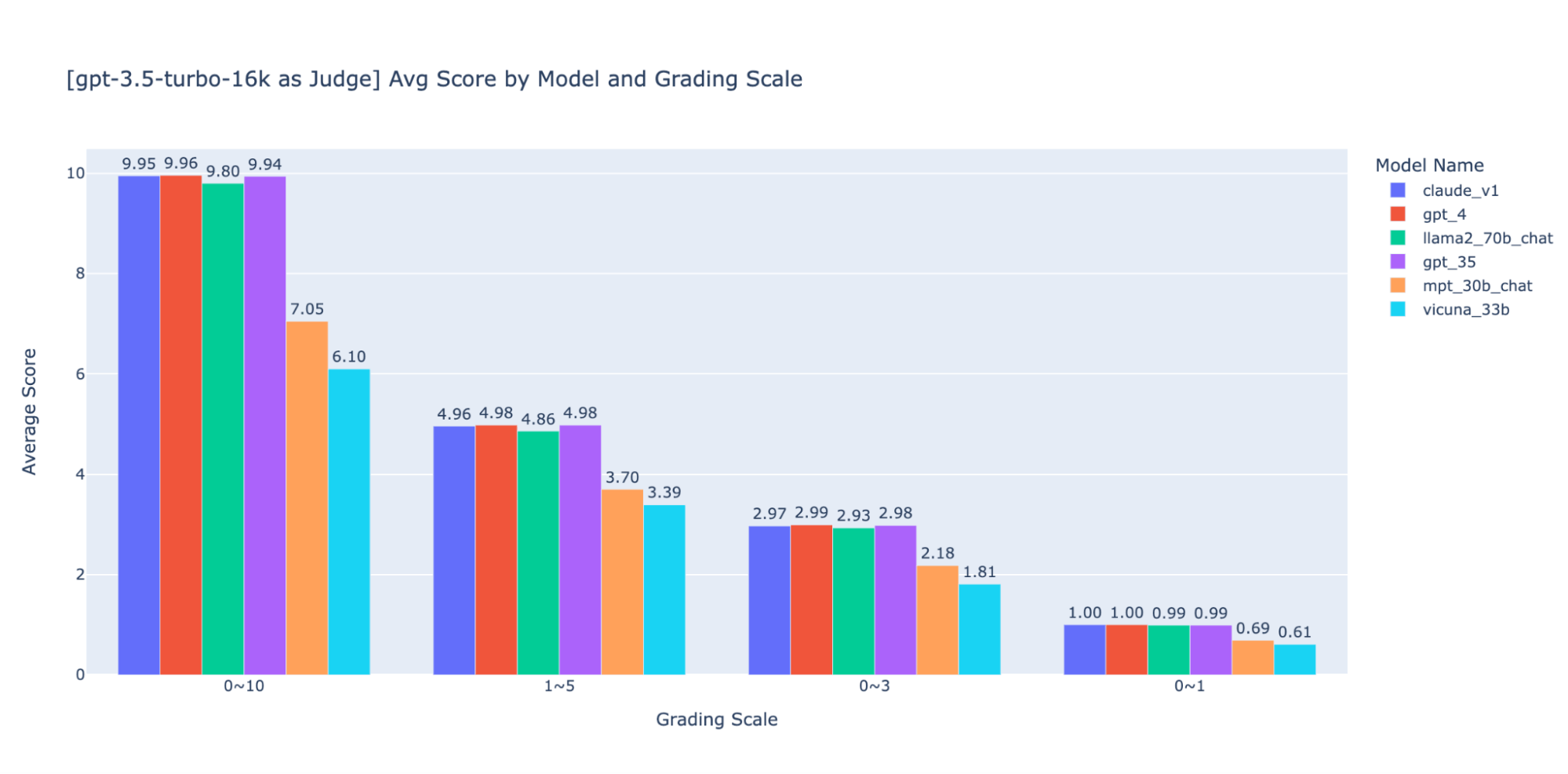
Comme le montrent les graphiques ci-dessus, GPT-4 et GPT-3.5 peuvent tous deux conserver un classement cohérent des résultats en utilisant différentes échelles de notation de faible précision. Ainsi, l'utilisation d'une échelle de notation inférieure comme 0~3 ou 1~5 permet d'équilibrer la précision et l'explicabilité)
Nous recommandons donc une échelle de notation de 0 à 3 ou de 1 à 5 pour faciliter l'alignement avec les étiquettes humaines, raisonner sur les critères de notation et fournir des exemples pour chaque score de la plage.
Experimentation 4 : Applicabilité à travers les cas d'utilisation
L'article LLM-as-judge (LLM en tant que juge) montre que le jugement du LLM et le jugement humain classent tous deux le modèle Vicuna-13B comme un concurrent proche de GPT-3.5 :
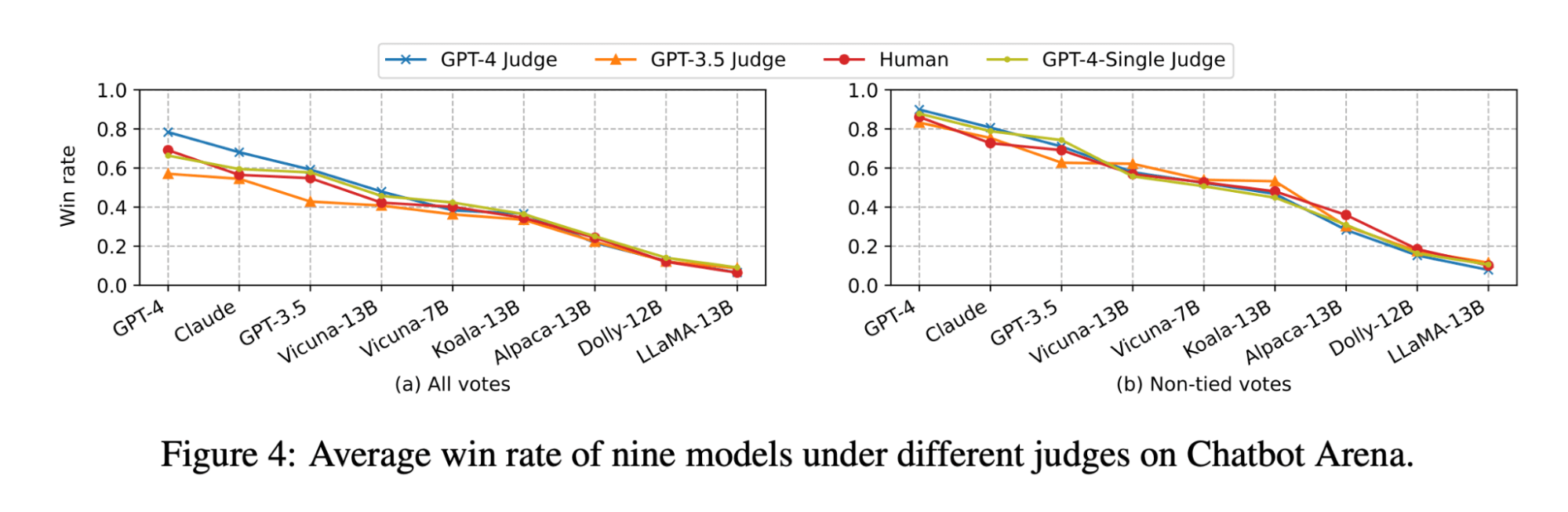
(La figure provient de la figure 4 de l'article sur LLM-as-judge : https://arxiv.org/pdf/2306.05685.pdf )
Cependant, lorsque nous avons évalué l'ensemble des modèles pour nos cas d'usage de questions-réponses (Q&A) sur des documents, nous avons constaté que même le modèle Vicuna-33B, beaucoup plus grand, a des performances nettement moins bonnes que GPT-3.5 pour répondre à des questions basées sur un contexte. Ces résultats sont également confirmés par GPT-4, GPT-3.5 et des juges humains (comme mentionné dans l'Expérimentation 1) qui s'accordent tous à dire que Vicuna-33B est moins performant que GPT-3.5.
Nous avons examiné de plus près le dataset de référence proposé par l'article et avons constaté que les 3 catégories de tâches (rédaction, mathématiques, connaissances) ne reflètent pas directement ou ne contribuent pas à la capacité du modèle à synthétiser une réponse en fonction d'un contexte. Au lieu de cela, intuitivement, les cas d'utilisation de questions-réponses sur des documents nécessitent des benchmarks sur la compréhension de texte et le suivi d'instructions. Ainsi, les résultats d'évaluation ne peuvent pas être transférés d'un cas d'utilisation à l'autre et nous devons créer des benchmarks spécifiques aux cas d'utilisation afin d'évaluer correctement dans quelle mesure un modèle peut répondre aux besoins des clients.
Utilisez MLflow pour tirer parti de nos meilleures pratiques
Grâce aux expérimentations ci-dessus, nous avons exploré comment différents facteurs peuvent affecter de manière significative l'évaluation d'un chatbot et avons confirmé qu'un LLM en tant que juge peut largement refléter les préférences humaines pour le cas d'utilisation des Q&A sur des documents. Chez Databricks, nous faisons évoluer l'API d'évaluation MLflow pour aider votre équipe à évaluer efficacement vos applications LLM sur la base de ces résultats. MLflow 2.4 a introduit l'API d'évaluation pour les LLM afin de comparer côte à côte les sorties de texte de différents modèles, MLflow 2.6 a introduit des métriques basées sur les LLM pour l'évaluation, comme la toxicité et la perplexité, et nous nous efforçons de prendre en charge le LLM-as-a-judge dans un avenir proche !
En attendant, nous avons compilé ci-dessous la liste des ressources que nous avons utilisées dans nos recherches :
- repository Doc_qa
- Le code et les données que nous avons utilisés pour mener les expérimentations
- Article de recherche LLM-as-Judge du groupe lmsys
- Cet article est la première recherche sur l'utilisation de LLM comme juge pour les cas d'usage de conversation informelle. Il a exploré en profondeur la faisabilité, ainsi que les avantages et les inconvénients de l'utilisation de LLM (GPT-4, ClaudeV1, GPT-3.5) comme juge pour des tâches d'écriture, de mathématiques et de connaissances générales.
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.