Améliorez la qualité de réponse de votre application RAG avec des données structurées en temps réel
par Mani Parkhe, Aakrati Talati, Sue Ann Hong, Craig Wiley, Chenen Liang et Mingyang Ge
La Génération Augmentée par Récupération (RAG) est un mécanisme efficace pour fournir des données pertinentes en tant que contexte dans les applications de Gen AI. La plupart des applications RAG utilisent généralement des index vectoriels pour rechercher un contexte pertinent à partir de données non structurées telles que la documentation, les wikis et les tickets de support. Hier, nous avons annoncé la préversion publique de Databricks AI Search, qui répond précisément à ce besoin. Cependant, la qualité des réponses de Gen AI peut être améliorée en enrichissant ces contextes textuels avec des données structurées pertinentes et personnalisées. Imaginez un outil de Gen AI sur un site de e-commerce où les clients demandent : "Où est ma dernière commande ?" Cette IA doit comprendre que la query concerne un achat spécifique, puis collecter des informations d'expédition à jour pour les articles commandés, avant d'utiliser les LLM pour générer une réponse. Le développement de ces applications évolutives exige un travail considérable, intégrant des Technologies pour traiter à la fois les données structurées et non structurées avec les capacités de Gen AI.
Nous sommes ravis d'annoncer la préversion publique de Databricks Feature & Function Serving, un service en temps réel à faible latence conçu pour servir des données structurées depuis la Databricks Data Intelligence Platform. Vous pouvez accéder instantanément à des fonctionnalités de ML précalculées et effectuer des transformations de données en temps réel en servant n'importe quelle fonction Python à partir de Unity Catalog. Les données récupérées peuvent ensuite être utilisées dans des moteurs de règles en temps réel, le ML classique et les applications Gen AI.
L'utilisation du Serving de fonctionnalités et de fonctions (AWS)(Azure) pour les données structurées, en coordination avec Databricks AI Search (AWS)(Azure) pour les données non structurées, simplifie considérablement la mise en production des applications de Gen AI. Les utilisateurs peuvent créer et déployer ces applications directement dans Databricks et s'appuyer sur les pipelines de données, la gouvernance et les autres fonctionnalités d'entreprise existants. Les clients de Databricks de divers Secteurs d'activité utilisent ces technologies ainsi que des frameworks open source pour créer de puissantes applications Gen AI telles que celles décrites dans le tableau ci-dessous.
| Secteur | Cas d'usage |
| Vente au détail |
|
| Éducation |
|
| Services financiers |
|
| Voyage et tourisme |
|
| Santé et sciences du vivant |
|
| Assurance |
|
| Technologie et fabrication |
|
| Médias et divertissement |
|
Serving de données structurées pour les applications RAG
Pour démontrer comment les données structurées peuvent aider à améliorer la qualité d'une application Gen AI, nous utilisons l'exemple suivant pour un chatbot de planification de voyage. L'exemple montre comment les préférences de l'utilisateur (par exemple : "vue sur l'océan" ou "adapté aux familles") peuvent être associées à des informations non structurées sur les hôtels pour rechercher des hôtels correspondants. Généralement, les prix des hôtels changent de manière dynamique en fonction de la demande et de la saisonnalité. Un calculateur de prix intégré à l'application Gen AI garantit que les recommandations respectent le budget de l'utilisateur. L'application d'IA générative qui alimente le bot utilise Databricks AI Search et Databricks Feature and Function Serving comme blocs de construction pour servir les préférences utilisateur personnalisées, le budget et les informations sur les hôtels nécessaires à l'aide de l'API des agents de LangChain.
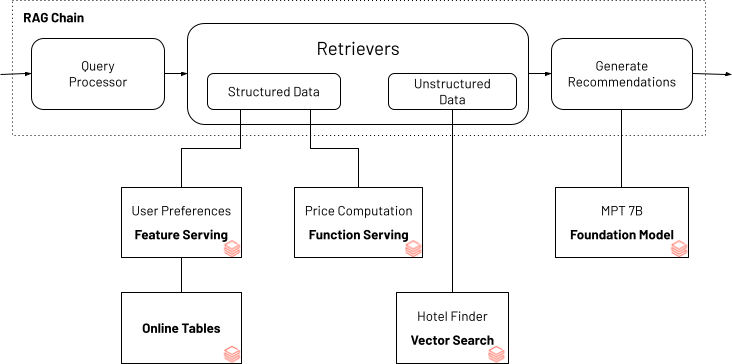
*Bot de planification de voyage qui prend en compte les préférences et le budget de l'utilisateur*
Vous pouvez trouver le notebook complet pour cette application RAG Chain, comme illustré ci-dessus. Cette application peut être exécutée localement dans le Notebook ou déployée en tant qu'endpoint accessible par une interface utilisateur de chatbot.
Accédez à vos données et fonctions en tant que points de terminaison en temps réel
Avec Feature Engineering dans Unity Catalog, vous pouvez déjà utiliser n'importe quelle table dotée d'une clé primaire pour servir des fonctionnalités pour l'entraînement et la mise en service. Databricks Model Serving prend en charge l'utilisation de fonctions Python pour calculer des fonctionnalités à la demande. Conçus à l'aide de la même Technologie disponible en arrière-plan pour Databricks Model Serving, les endpoints de fonctionnalités et de fonctions peuvent être utilisés pour accéder à n'importe quelle fonctionnalité précalculée ou pour la compute à la demande. Avec une syntaxe simple, vous pouvez définir une fonction de spécification de fonctionnalité dans Unity Catalog qui peut encoder le Graphe orienté acyclique pour compute et servir des fonctionnalités en tant que REST endpoint.
Cette fonction de spécification de feature peut être servie en temps réel en tant qu'endpoint REST. Tous les Endpoints sont accessibles dans le tab de navigation de gauche « Serving », y compris les features, les fonctions, les modèles entraînés personnalisés et les modèles de fondation. Provisionnez l'endpoint à l'aide de cette API
L'endpoint peut également être créé à l'aide d'un workflow d'interface utilisateur, comme indiqué ci-dessous
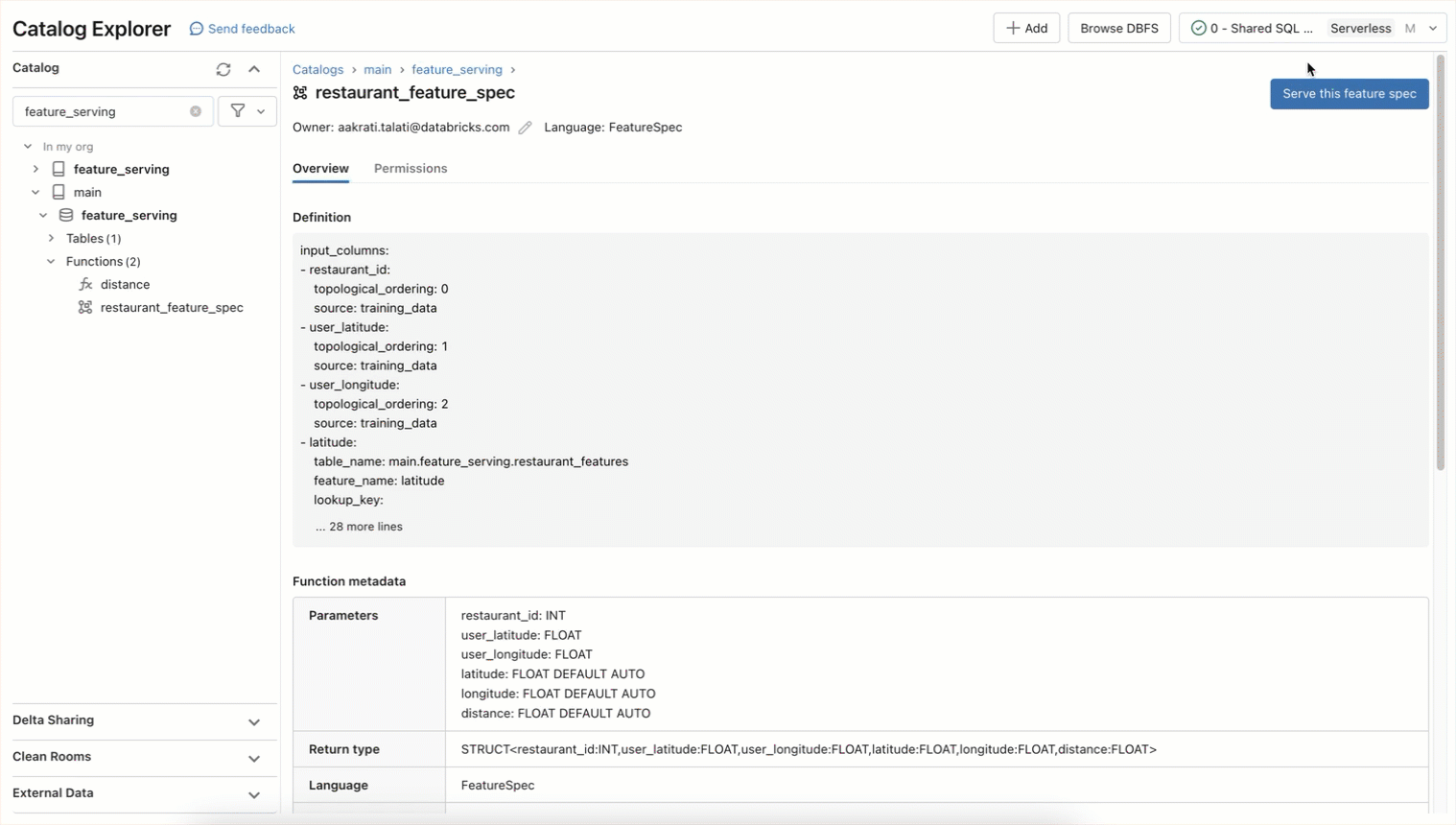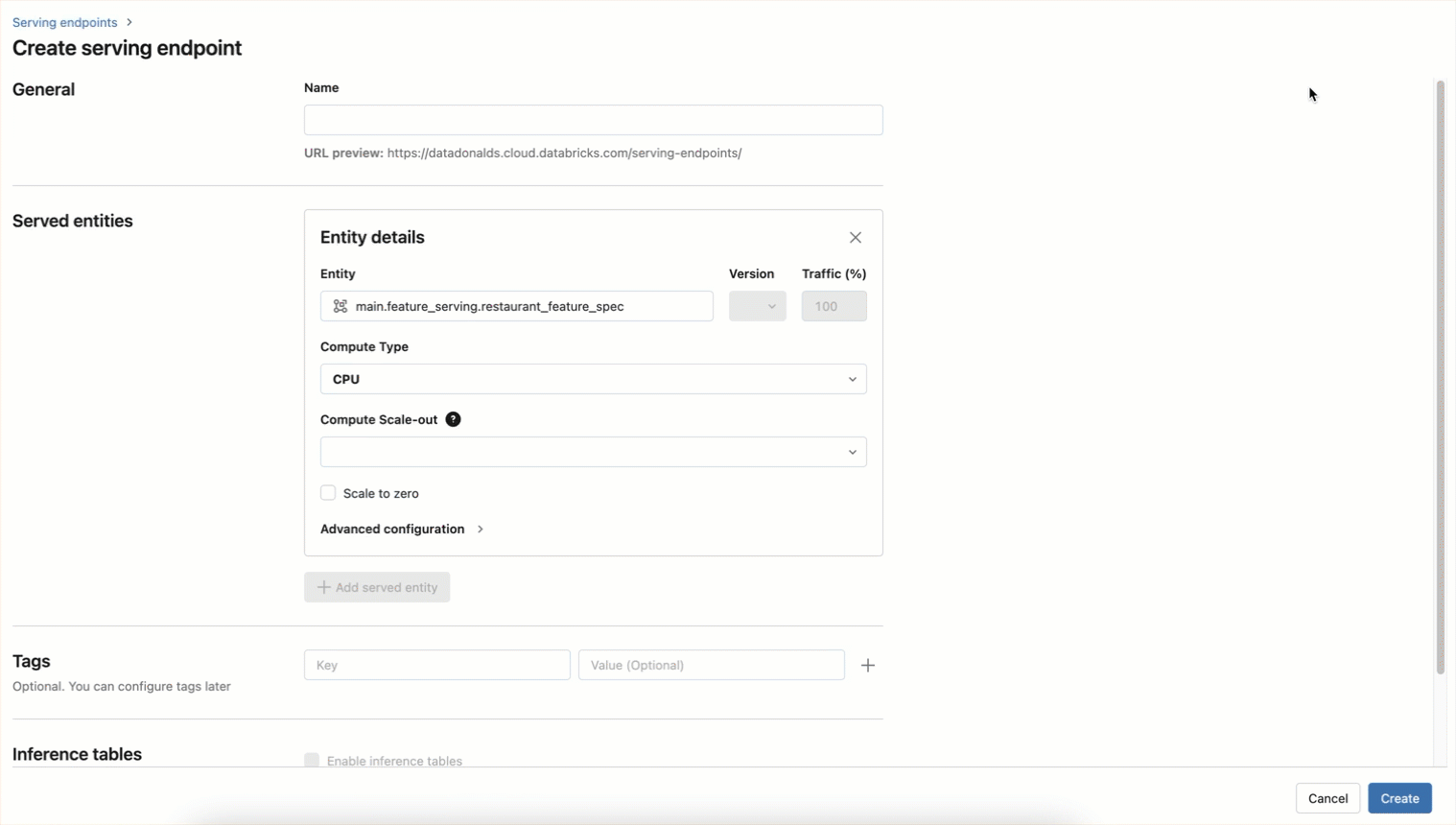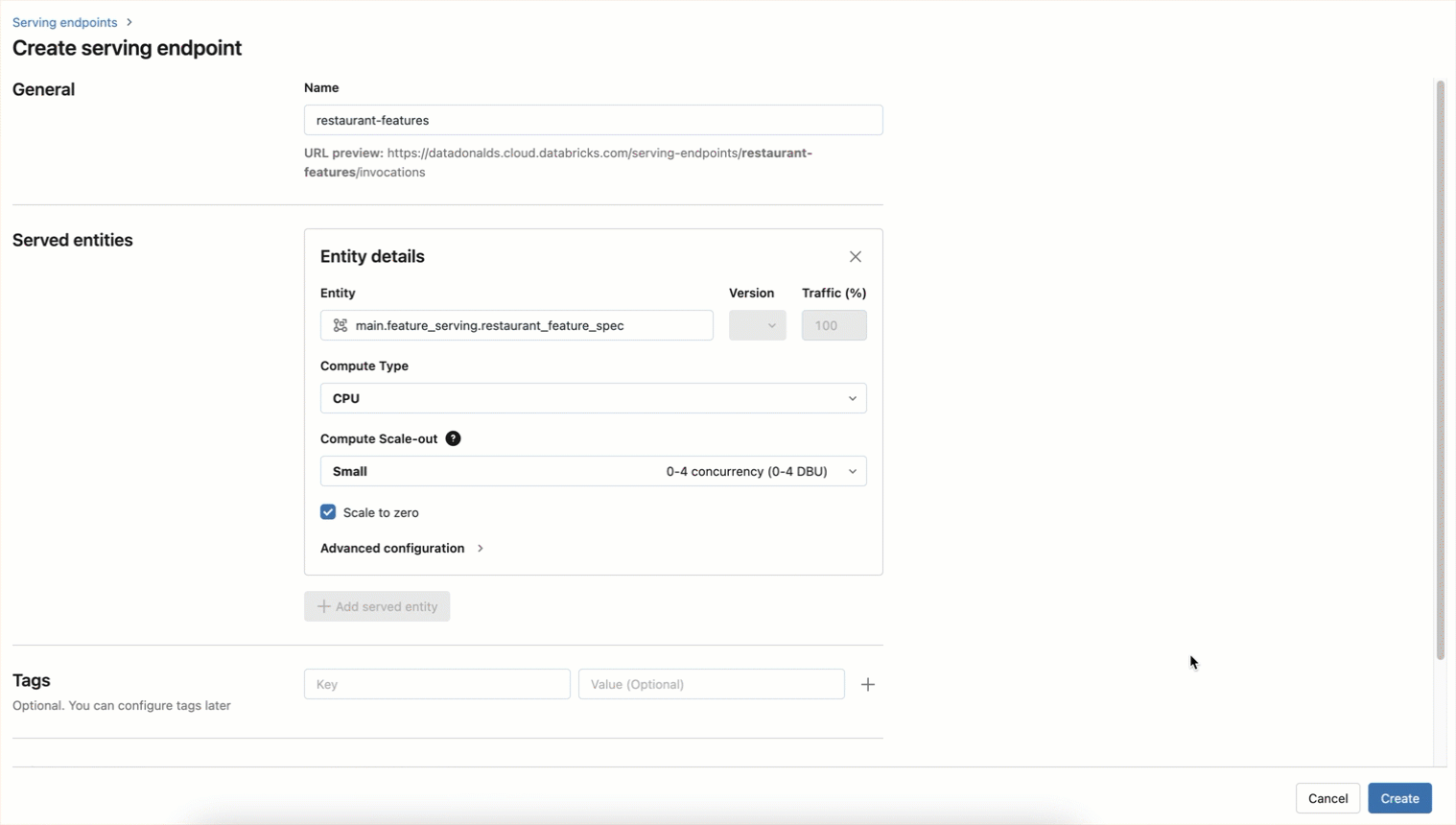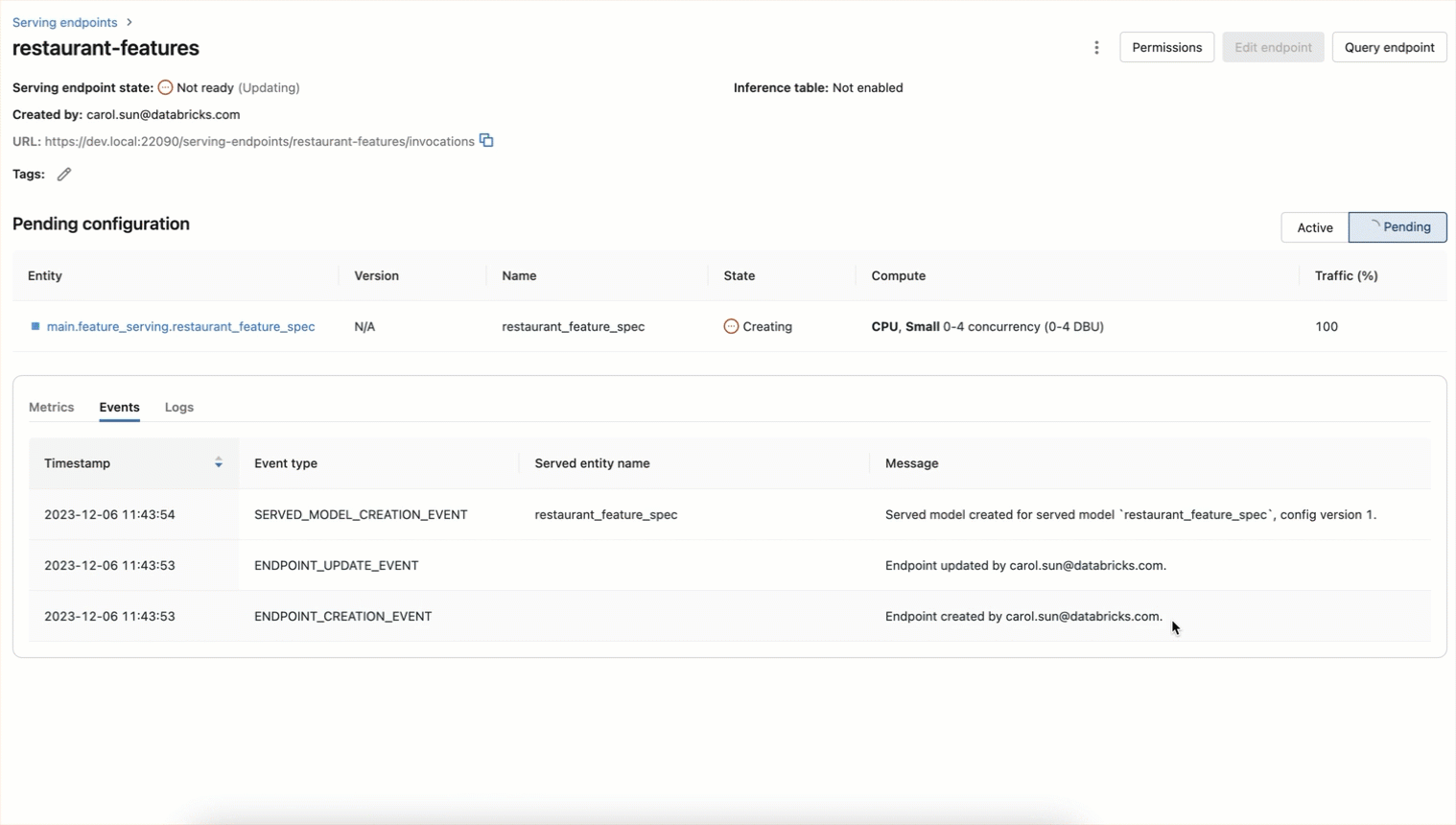
Les features peuvent désormais être consultées en temps réel en interrogeant le endpoint :
Pour fournir des données structurées à des applications d'IA en temps réel, les données précalculées doivent être déployées sur des bases de données opérationnelles. Les utilisateurs peuvent déjà utiliser des magasins en ligne externes comme source de fonctionnalités précalculées ; par exemple, DynamoDB et Cosmos DB sont couramment utilisés pour servir des fonctionnalités dans Databricks Model Serving. Les Online Tables de Databricks (AWS)(Azure) ajoutent une nouvelle fonctionnalité qui simplifie la synchronisation des fonctionnalités précalculées vers un format de données optimisé pour les recherches de données à faible latence. Vous pouvez synchroniser n'importe quelle table dotée d'une clé primaire en tant que table en ligne et le système mettra en place un pipeline automatique pour garantir la fraîcheur des données.
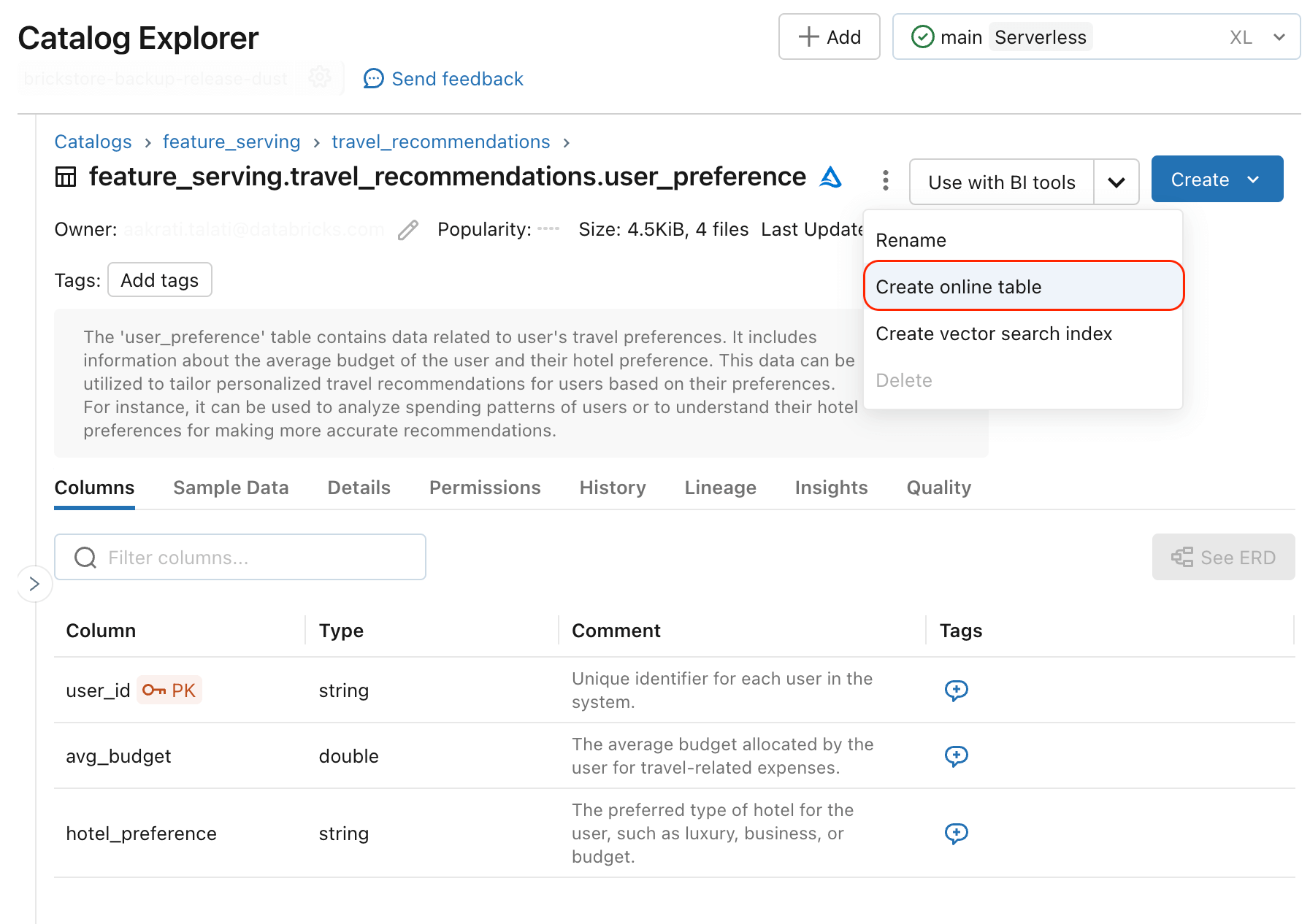
Toute table Unity Catalog avec des clés primaires peut être utilisée pour fournir des caractéristiques dans les applications Gen AI à l'aide des Databricks Online Tables.
Étapes suivantes
Utilisez cet exemple de notebook illustré ci-dessus pour personnaliser vos applications RAG
Inscrivez-vous à un webinar sur l'IA générative de Databricks disponible à la demande
Le service de fonctionnalités et de fonctions (AWS)(Azure) est disponible en préversion publique. Consultez la documentation de l'API et des exemples supplémentaires.
Les tables en ligne Databricks(AWS)(Azure) sont disponibles en tant que Gated Public Preview. Utilisez ce formulaire pour vous inscrire au programme d'habilitation.
Lisez le résumé des annonces (sur la création d'applications RAG de haute qualité) publiées plus tôt cette semaine.
Parcours d'apprentissage d'ingénieur en IA générative: suivez des cours à votre rythme, à la demande et avec instructeur sur l'IA générative
Vous souhaitez résoudre des cas d'usage d'IA générative ? Participez au Hackathon sur l'IA générative de Databricks & AWS ! Inscrivez-vous ici.
Tu as un cas d'utilisation que tu aimerais partager avec Databricks ? Contacte-nous à l'adresse suivante : feature-serving@databricks.com
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.