Présentation de Databricks Recherche vectorielle Aperçu public
par Akhil Gupta, Sergei Tsarev et Eric Peter
Suite à l’annonce que nous avons faite hier concernant la Génération Augmentée de Récupération (RAG), aujourd’hui, nous sommes ravis d’annoncer l’aperçu public de la recherche vectorielle Databricks. Nous avons annoncé l’aperçu privé à un nombre limité de clients lors du Data + AI Summit en juin, désormais disponible pour tous nos clients. Databricks La recherche vectorielle permet aux développeurs d’améliorer la précision de leurs applications de génération augmentée de récupération (RAG) et d’IA générative grâce à la recherche de similarité sur des documents non structurés tels que PDF, documents Office, Wikis, et bien d’autres. La recherche vectorielle fait partie de la Databricks Data Intelligence Platform, facilitant l'RAG utilisation rapide et sécurisée des données propriétaires stockées dans votre Lakehouse et pour fournir des réponses précises.
Nous avons conçu Databricks AI Search pour qu’il soit rapide, sécurisé et facile à utiliser.
- Rapide avec faible TCO - la recherche vectorielle est conçue pour offrir de hautes performances à un TCO plus faible, avec jusqu’à 5 fois une latence inférieure à celle des autres fournisseurs
- Expérience développeur simple et rapide - La recherche vectorielle permet de synchroniser n’importe quelle table Delta en un index vectoriel en un clic - sans besoin d’un pipeline complexe et personnalisé d’ingestion/synchronisation de données.
- Gouvernance unifiée - AI Search utilise les mêmes outils de sécurité et de gouvernance des données basés sur Unity Catalogqui alimentent déjà votre plateforme Data Intelligence, ce qui signifie que vous n’avez pas à construire et maintenir un ensemble distinct de politiques de gouvernance des données pour vos données non structurées
- Serverless Scaling - Notre infrastructure Serverless se retrouve automatiquement en charge à vos flux de travail sans avoir besoin de configurer les instances et types de serveurs.
Qu’est-ce que la recherche vectorielle ?
La recherche vectorielle est une méthode utilisée dans les applications de récupération de information et de génération augmentée (RAG) pour trouver des documents ou des enregistrements en fonction de leur similarité avec un query. La recherche vectorielle explique pourquoi vous pouvez taper un query en langage clair comme « chaussures bleues bonnes pour vendredi soir » et obtenir des résultats pertinents.
Les géants de la tech utilisent la recherche vectorielle depuis des années pour alimenter leurs expériences de produits – avec l’avènement de l’IA générative, ces capacités sont enfin démocratisées dans toutes les organisations.
Voici un aperçu du fonctionnement de la recherche vectorielle :
Embeddings: Dans la recherche vectorielle, les données et les requêtes sont représentées comme des vecteurs dans un espace multidimensionnel appelés embeddings issus d’un modèle d’IA générative.
Prenons un exemple simple où nous voulons utiliser la recherche vectorielle pour trouver des mots sémantiquement similaires dans un grand corpus de mots. Donc, si vous query le corpus avec le mot « chien », vous voulez que des mots comme « chiot » soient rendus. Mais, si vous cherchez « voiture », vous voulez retrouver des mots comme « van ». Dans la recherche traditionnelle, vous devrez tenir une liste de synonymes ou de « mots similaires » qui sont difficiles à générer ou Monter en charge. Pour utiliser la recherche vectoriel, vous pouvez utiliser un modèle d’IA générative pour convertir ces mots en vecteurs dans un espace n-dimensionnel appelé embeddings. Ces vecteurs auront la propriété que des mots sémantiquement similaires comme « chien » et « chiot » seront plus proches l’un de l’autre dans l’espace n-dimensionnel que les mots « chien » et « voiture ».
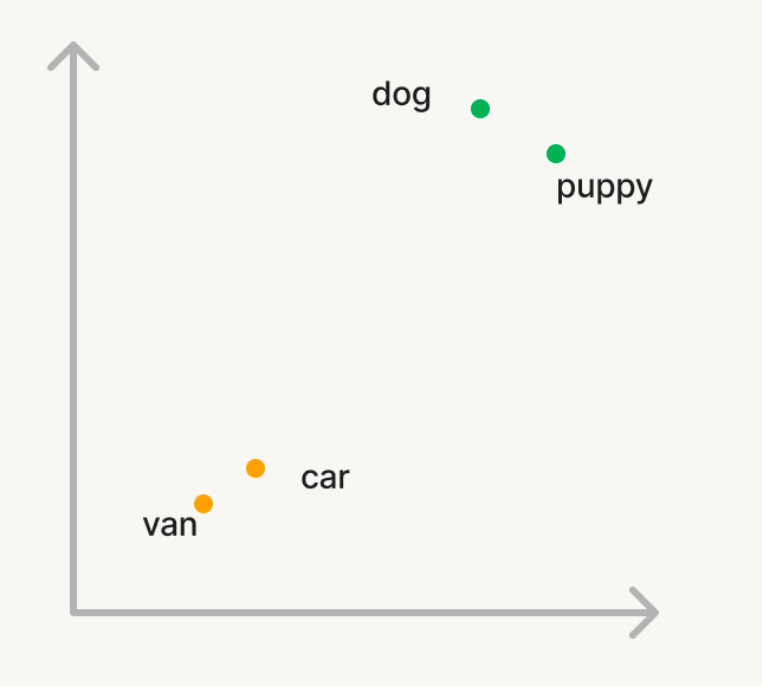
Calcul de similarité: Pour trouver des documents pertinents pour un query, la similarité entre le vecteur query et chaque vecteur document est calculée pour mesurer leur proximité dans l’espace n-dimensionnel. Cela se fait généralement en utilisant la similarité cosinus, qui mesure le cosinus de l’angle entre les deux vecteurs. Plusieurs algorithmes sont utilisés pour trouver des vecteurs similaires de manière efficace, les algorithmes basés sur HNSW étant systématiquement les meilleurs en classe.
Applications: La recherche vectorielle comporte de nombreux cas d’utilisation :
- Recommandations - recommandations personnalisées et contextuelles destinées aux utilisateurs
- RAG - livraison de documents non structurés pertinents pour aider une application RAG à répondre aux questions des utilisateurs
- Recherche sémantique - activation d’une requête de recherche en langage clair qui fournit des résultats pertinents
- Document clustering - comprendre les similitudes et les différences entre les données
Pourquoi les clients aiment-ils la recherche vectorielle Databricks ?
« Nous sommes ravis de mettre à profit Databrickssolutions puissantes pour transformer le soutien de nos clients chez Lippert. Gérer un centre d’appels dynamique pour une entreprise de notre taille, le défi de mettre les nouveaux agents à jour au milieu du churback typique est important. Databricks fournit la clé de nos solutions – en mettant en place une expérience d’assistance aux agents propulsée par AI Search, nous pouvons permettre à nos agents de trouver rapidement des réponses aux demandes des clients. En intégrant du contenu provenant de manuels de produits, de vidéos YouTube et de dossiers de support dans notre recherche vectorielle, Databricks garantit que nos agents disposent des connaissances dont ils ont besoin à portée de main. Cette approche innovante est une véritable révolution pour Lippert, améliorant l’efficacité et améliorant l’expérience de support client. »-Chris Nishnick, Intelligence artificielle, Lippert
Ingestion automatisée des données
Avant qu’une base de données vectorielle puisse stocker information, elle nécessite un pipeline d’ingestion de données où les données brutes et non traitées provenant de diverses sources doivent être nettoyées, traitées (analysées/fragmentées) et intégrées dans un modèle d’IA avant d’être stockées comme vecteurs dans la base de données. Ce processus pour construire et maintenir un autre ensemble de pipeline d’ingestion de données est coûteux et chronophage, nécessitant des ressources précieuses en ingénierie des données. Databricks recherche vectorielle est entièrement intégrée au Databricks Data Intelligence Platform, ce qui lui permet de récupérer automatiquement les données et de les intégrer sans avoir à construire et maintenir de nouveaux pipelines de données.
Notre Delta Sync APIs synchronise automatiquement les données sources avec les index vectoriels. À mesure que les données sources sont ajoutées, mises à jour ou supprimées, nous mettons automatiquement à jour l’indice vectoriel correspondant pour correspondre. Sous le capot, la recherche vectorielle gère les échecs, gère les essais et optimise Batch tailles pour vous offrir les meilleures performances et throughput sans aucun travail ni intervention. Ces optimisations réduisent votre coût total de possession grâce à une utilisation accrue de votre modèle d’embarquement Endpoint.
Voyons un exemple où nous créons un indice vectoriel en trois étapes simples. Toutes les fonctionnalités de recherche vectorielle sont disponibles via REST APIs, notre Python SDKou dans l’interface Databricks .
Étape 1. Créez un Endpoint de recherche vectorielle qui servira à créer et query un index vectoriel en utilisant l’interface utilisateur ou notre REST API/SDK.
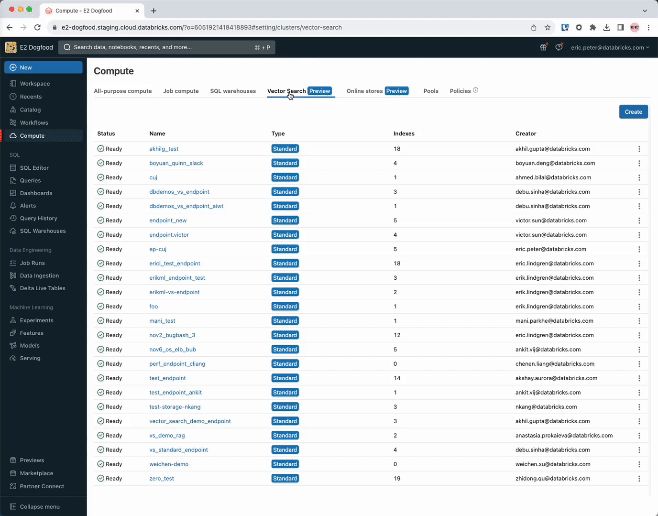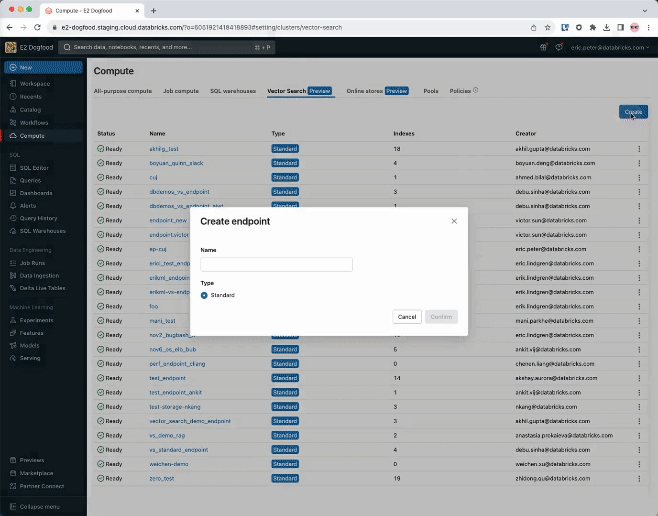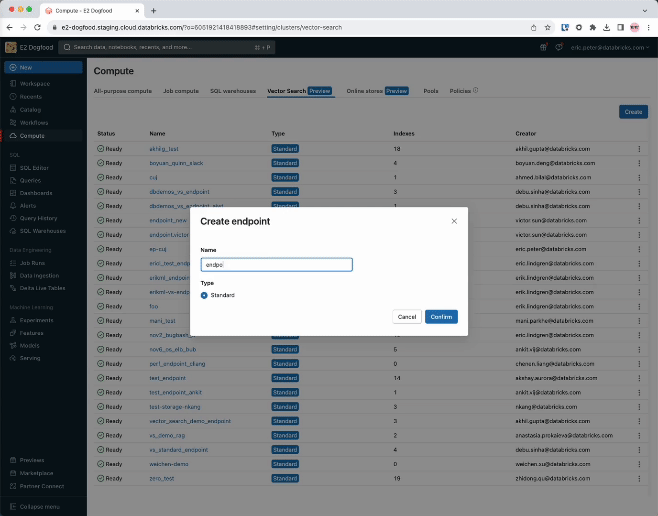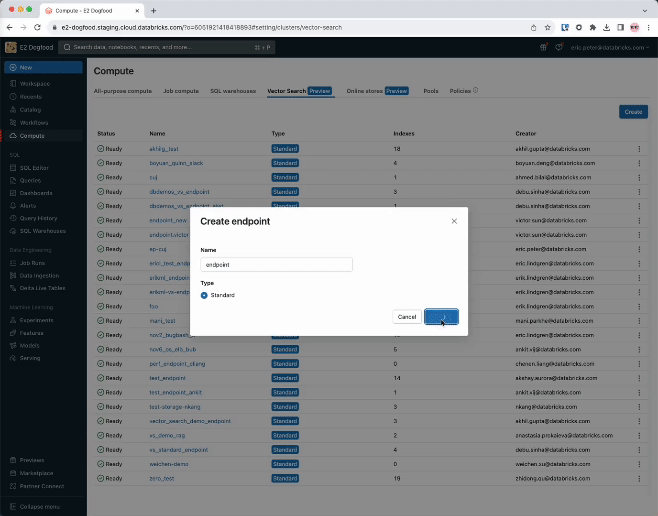
Étape 2. Après avoir créé une Delta Table avec vos données sources, vous sélectionnez une colonne dans la Delta Table à intégrer, puis sélectionnez un Model Serving Endpoint qui sert à générer des embeddings pour les données.
Le modèle d’immersion peut être :
- Un modèle que vous avez peaufiné
- Un modèle open source prêt à l’emploi (comme E5, BGE, InstructorXL, etc.)
- Un modèle d’embarquage propriétaire disponible via API (comme OpenAI, Cohere, Anthropic, etc.)
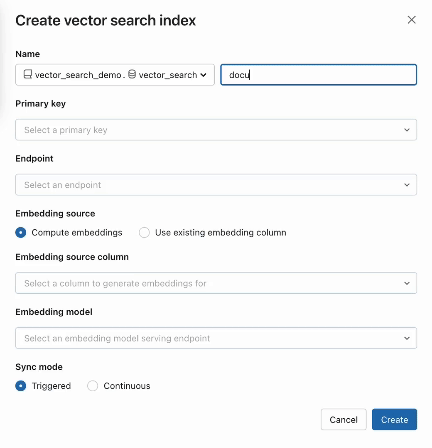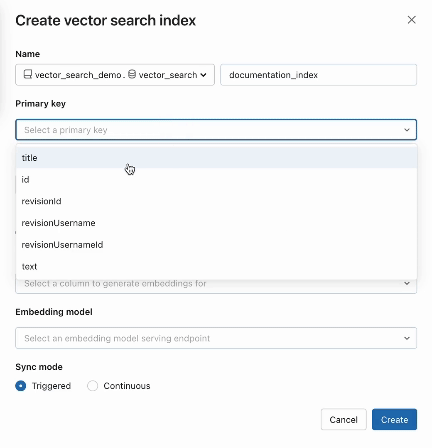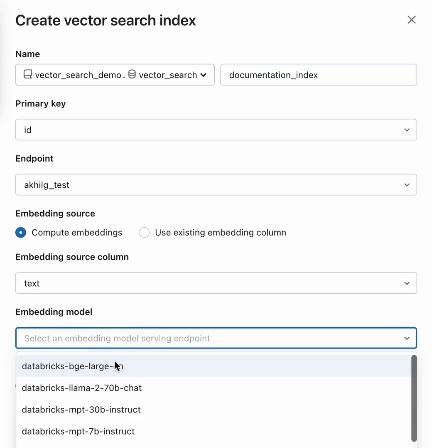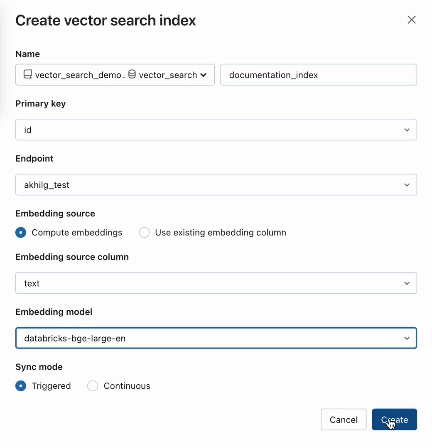
La recherche vectorielle propose également des modes avancés pour les clients qui préfèrent gérer leurs embeddings dans une Delta Table ou créer un pipeline d’ingestion de données en utilisant REST APIs. Pour des exemples, veuillez consulter la documentation AI Search.
Étape 3. Une fois l’index prêt, vous pouvez effectuer des requêtes pour trouver des vecteurs pertinents pour votre query. Ces résultats peuvent ensuite être envoyés à votre application de génération augmentée par récupération (RAG ).
« Ce produit est facile à utiliser, et nous avons commencé en marche en quelques heures. Toutes nos données sont déjà dans Delta, donc l’expérience intégrée et gérée de la recherche vectorielle avec la synchronisation delta est impressionnante. » —- Alex Dalla Piazza (EQT Corporation) »
Gouvernance intégrée
Les entreprises exigent des contrôles stricts de sécurité et d’accès sur leurs données afin que les utilisateurs ne puissent pas utiliser des modèles d’IA générative pour leur fournir des données confidentielles auxquelles ils ne devraient pas avoir accès. Cependant, les bases de données Vector actuelles ne disposent soit pas de contrôles de sécurité et d’accès robustes, soit exigent que les organisations construisent et maintiennent un ensemble distinct de politiques de sécurité distinctes de leur plateforme de données. Disposer de plusieurs ensembles de sécurité et de gouvernance ajoute des coûts et de la complexité, et est sujet aux erreurs à maintenir de manière fiable.
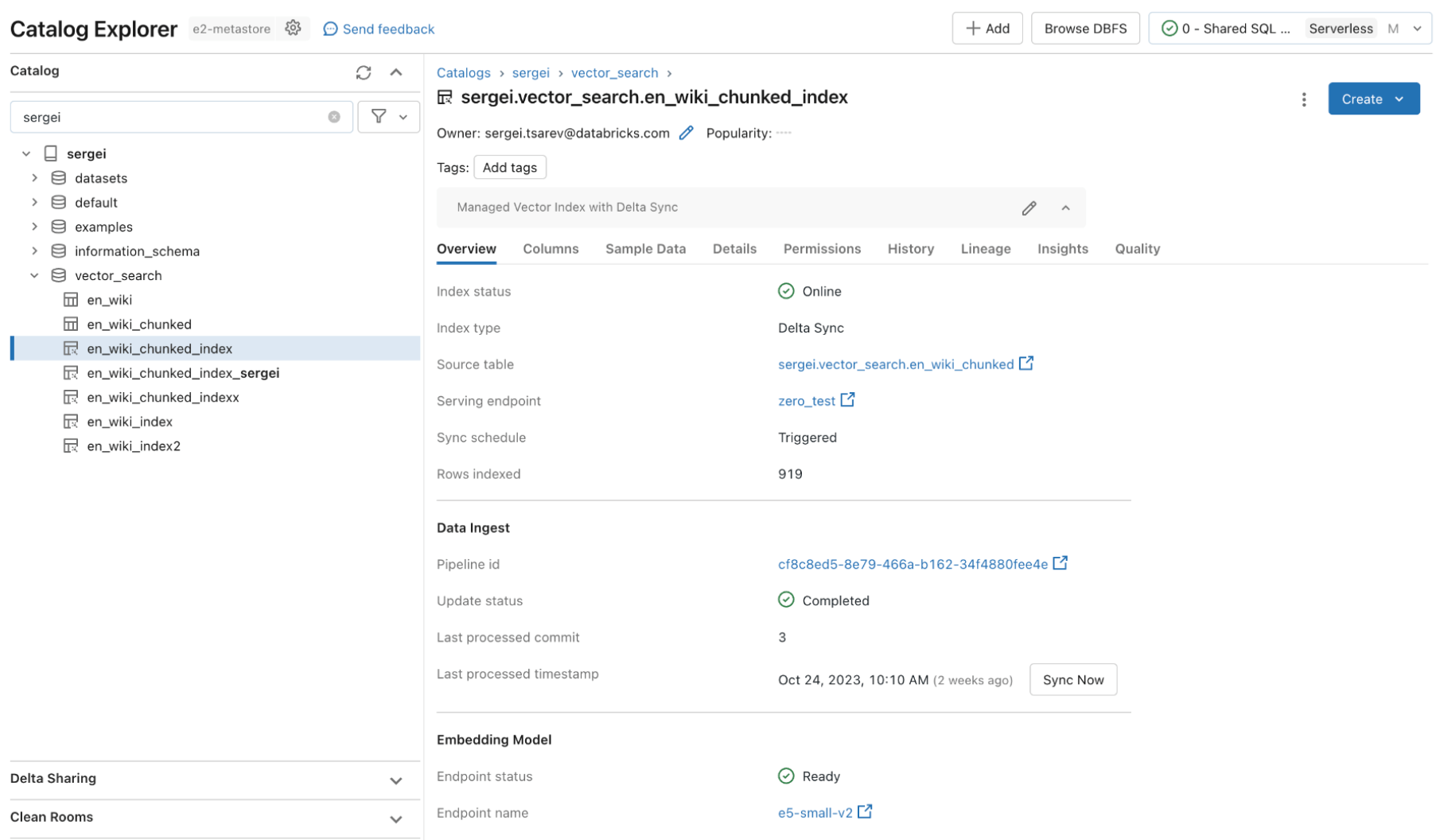
Databricks AI Search exploite les mêmes contrôles de sécurité et la gouvernance des données qui protègent déjà le reste de la Data Intelligence Platform, rendue possible grâce à l’intégration avec Unity Catalog. Les index vectoriels sont stockés comme des entités dans votre Unity Catalog et utilisent la même interface unifiée pour définir des politiques sur les données, avec un contrôle précis sur les embeddings.
Performance rapide des requêtes
En raison de la maturité du marché, de nombreuses bases de données vectorielles montrent de bons résultats en Proof-of-Concepts (POCs) avec de petites quantités de données. Cependant, ils manquent souvent en termes de performances ou de scalabilité pour les déploiements en production. Avec de mauvaises performances dès l’usée, les utilisateurs devront apprendre à régler et à charger les index de recherche, ce qui est long et difficile à bien réaliser. Ils sont obligés de comprendre leur charge de travail et de faire des choix difficiles sur les compute instances à choisir, ainsi que sur la configuration à utiliser.
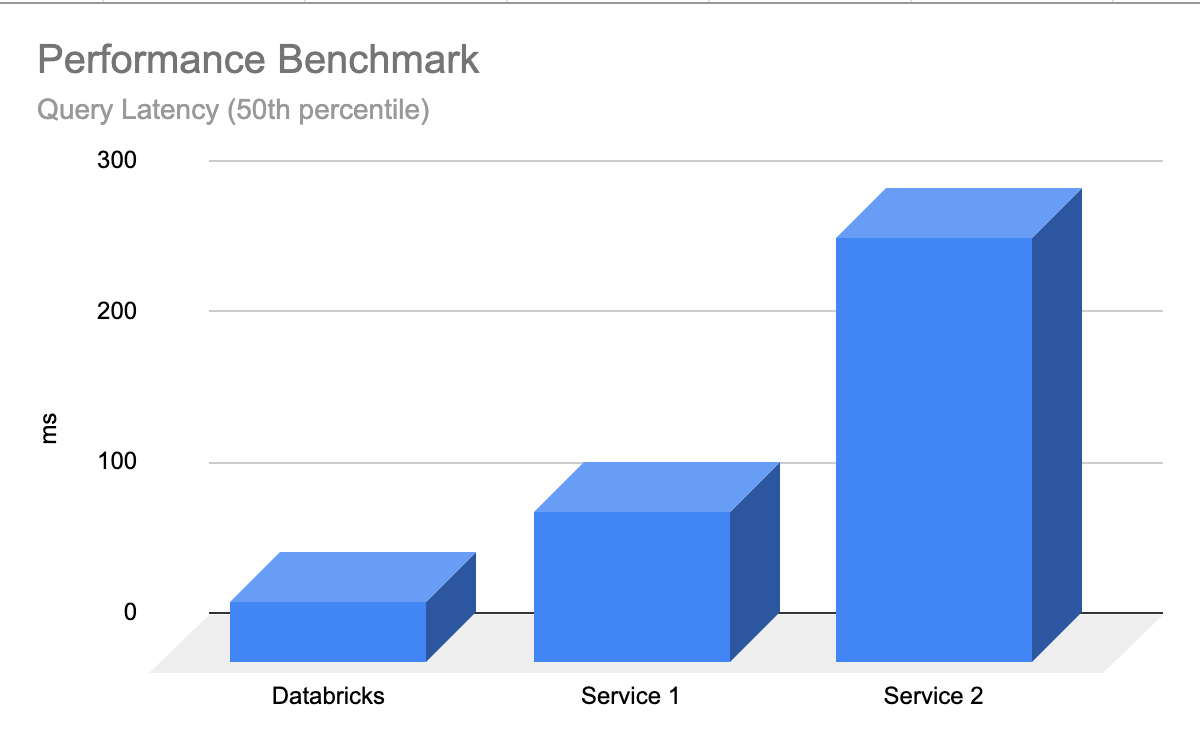
Databricks recherche vectorielle est performante dès l’emploi, où les LLM renvoient rapidement les résultats pertinents avec une latence minimale et aucun travail nécessaire pour ajuster et charger la base de données avec Monter. La recherche vectorielle est conçue pour être extrêmement rapide pour les requêtes avec ou sans filtrage. Il affiche des performances jusqu’à 5 fois supérieures à certaines autres bases de données vectorielles principales. C’est facile à configurer : vous nous informez simplement de la taille attendue de votre charge de travail (par exemple, requête par seconde), la latence requise et le nombre attendu d’embeddings – nous nous occupons du reste. Vous n’avez pas besoin de vous soucier des types d’instances, de la RAM/CPU, ou de comprendre le fonctionnement interne des bases de données vectorielles.
Nous avons consacré beaucoup d’efforts à personnaliser la recherche vectorielle de Databricks pour supporter des charges de travail IA que des milliers de nos clients utilisent déjà sur Databricks. Les optimisations comprenaient le benchmarking et l’identification du meilleur matériel adapté à la recherche sémantique, l’optimisation de l’algorithme de recherche sous-jacent et de la surcharge réseau afin d’offrir les meilleures performances à Monter en charge.
Prochaines étapes
Obtenez start en lisant notre documentation et en créant spécifiquement un index de recherche vectorielle
En savoir plus sur les tarifsde recherche vectorielle
Commencer à déployer votre propre application RAG (démo)
Inscrivez-vous à un webinaire Databricks sur l’IA générative
Vous souhaitez résoudre des cas d’utilisation de l’IA générative ? Participez au hackathon Databricks & AWS Generative AI ! Inscrivez-vous ici
Parcours d’apprentissage pour ingénieur en IA générative : suivez des cours auto-rythmés, à la demande et dirigés par un instructeur sur l’IA générative
Lisez les annonces résumées faites plus tôt cette semaine
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.