LogSentinel : comment Databricks utilise Databricks pour la détection et la gouvernance des PII basées sur les LLM
Plongée au cœur de LogSentinel : comment nous utilisons les LLM en interne pour automatiser la découverte et la gouvernance des PII
- Nous utilisons des LLM sur Databricks pour détecter et classifier automatiquement les données sensibles dans les logs et les bases de données.
- Notre système LogSentinel applique une classification hiérarchique, multi-modèle et tenant compte de la résidence des données pour un étiquetage précis. Ces techniques sont intégrées directement dans le produit Data Classification.
- En pré-étiquetant les colonnes et en détectant continuellement la dérive d'étiquetage, LogSentinel permet une détection fiable des PII, une application automatisée des politiques et des flux de travail de conformité beaucoup plus rapides à grande échelle.
Databricks opère à une échelle où nos logs et datasets internes changent constamment : les schémas évoluent, de nouvelles colonnes apparaissent et la sémantique des données drift. Cet article de blog explique comment nous utilisons Databricks en interne chez Databricks pour que les PII et autres données sensibles restent correctement étiquetées à mesure que notre plateforme évolue.
Pour ce faire, nous avons développé LogSentinel, un système de classification de données basé sur un LLM sur Databricks qui suit l'évolution des schémas, détecte la dérive d'étiquetage et fournit des étiquettes de haute qualité à nos contrôles de gouvernance et de sécurité. Nous utilisons MLflow pour suivre les expériences et surveiller les performances dans le temps, et nous intégrons les meilleures idées de LogSentinel dans le produit Databricks Data Classification afin que les clients puissent bénéficier de la même approche.
Pourquoi ce système est important
Ce système est conçu pour agir sur trois leviers commerciaux concrets pour les équipes en charge de la plateforme, des données et de la sécurité :
- Cycles de conformité plus courts: les tâches de révision récurrentes qui prenaient auparavant des semaines de travail aux analystes sont désormais terminées en quelques heures, car les colonnes sont pré-étiquetées et pré-triées avant qu'un humain ne les examine.
- Réduction du risque opérationnel: le système détecte en continu le drift d'étiquetage et les modifications de schéma, de sorte que les champs sensibles sont moins susceptibles de passer inaperçus avec des balises incorrectes ou manquantes.
- Application plus stricte des politiques: des étiquettes fiables pilotent désormais directement les règles de masquage, de contrôle d'accès, de conservation et de résidence, transformant ce qui était auparavant une « gouvernance au mieux » en politique exécutable.
En pratique, les équipes peuvent intégrer de nouvelles tables dans un pipeline standard, surveiller les métriques de drift et les exceptions, et s'appuyer sur le système pour appliquer les contraintes relatives aux PII et à la résidence des données sans avoir à créer un classifieur sur mesure pour chaque domaine.
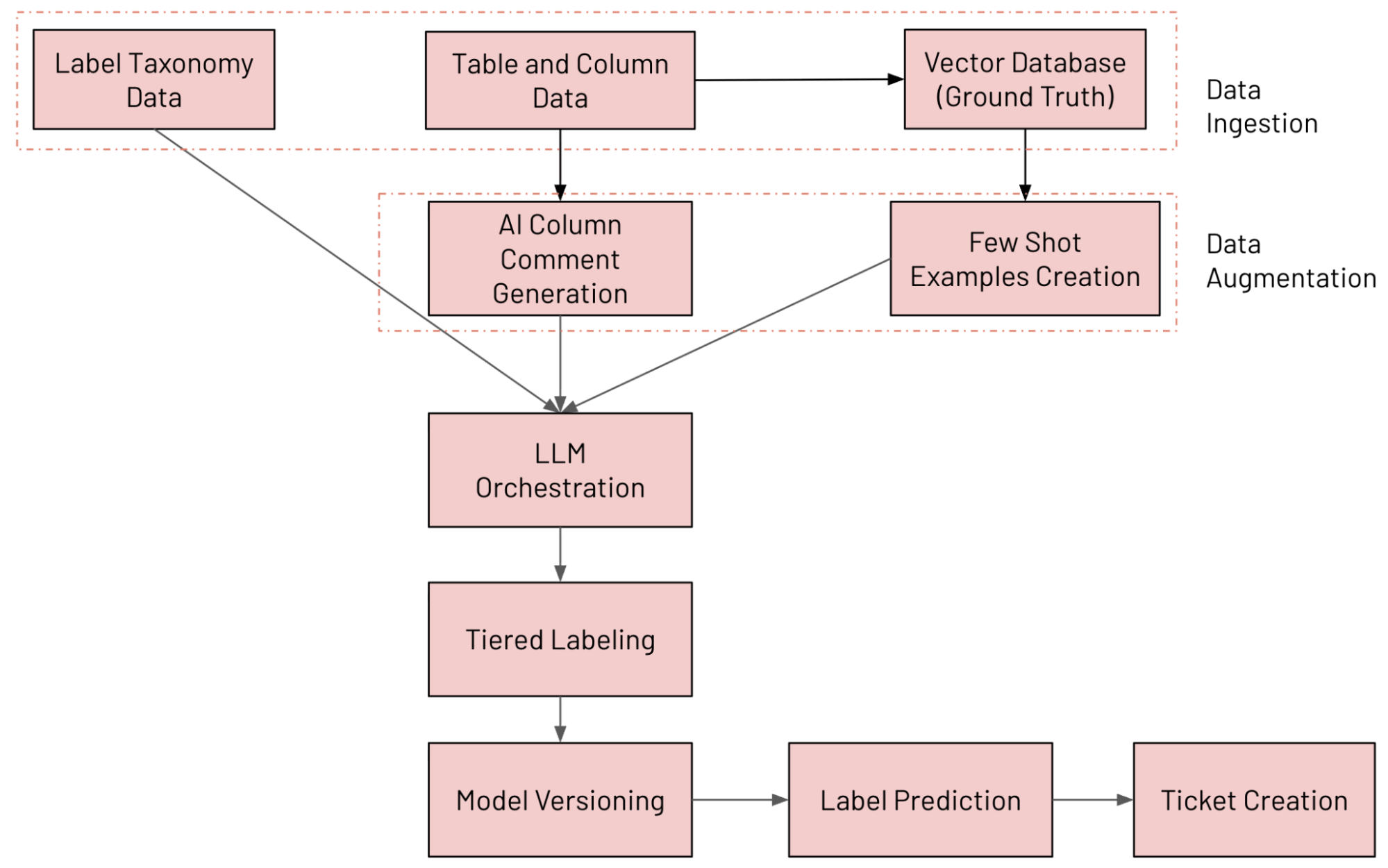
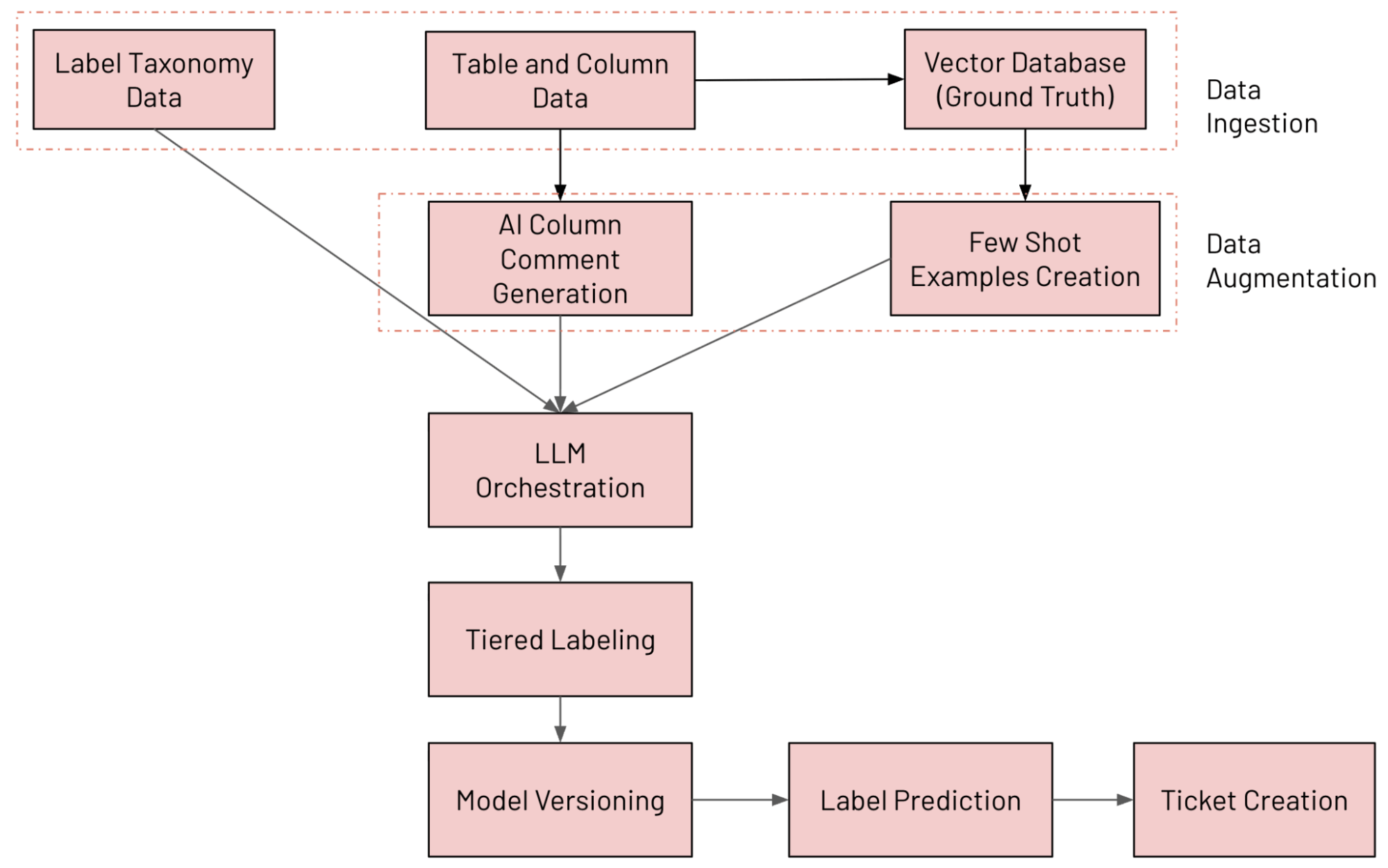
Architecture du système en un coup d'œil
Nous avons développé sur Databricks un système de classification de colonnes basé sur un LLM qui annote en continu les tables à l'aide de notre taxonomie de données interne, détecte la dérive de l'étiquetage et ouvre des tickets de correction lorsqu'une anomalie est détectée. Les différents composants du système sont décrits ci-dessous (suivis et évalués à l'aide de MLFlow) :
- Ingestion de données : ingestion de diverses sources de données (y compris les données de colonnes Unity Catalog, les données de taxonomie d'étiquettes et les données de vérité terrain)
- Augmentation des données : augmentation des données à l'aide de Databricks AI Search et de la génération de commentaires par l'IA
- Orchestration de LLM
- Système d'étiquetage à plusieurs niveaux
- Versionnage de modèle : exécution de plusieurs modèles en parallèle
- Prédiction des étiquettes : prédiction de l'étiquette finale à l'aide de l'approche Mixture of Experts (MoE)
- Création de tickets : détection des violations et génération de tickets JIRA
Le workflow de bout en bout est présenté dans la figure ci-dessous.
{kind=link}
Ingestion des données
Pour chaque type de log ou dataset à annoter, nous échantillonnons aléatoirement des valeurs de chaque colonne et envoyons les métadonnées suivantes dans le système : nom de la table, nom de la colonne, type, commentaire existant et un petit échantillon de valeurs. Pour réduire le coût du LLM et améliorer le throughput, plusieurs colonnes de la même table sont regroupées dans une seule requête.
Notre taxonomie est définie à l'aide de Protocol Buffers et inclut actuellement plus de 100 étiquettes de données hiérarchiques, avec la possibilité d'extensions personnalisées lorsque les équipes ont besoin de catégories supplémentaires. Cela offre aux parties prenantes de la gouvernance et de la plateforme un contrat partagé sur la signification de « PII » et « sensible », au-delà d'une poignée de regex.
Augmentation de données
Deux stratégies d'augmentation améliorent considérablement la qualité de la classification :
- Génération de commentaires de colonne par l'IA : lorsque des commentaires sont manquants, nous utilisons des commentaires générés par l'IA de Databricks pour synthétiser des descriptions concises et lisibles par l'homme qui aident à la fois le LLM et les futurs consommateurs de la table.
- Génération d'exemples few-shot : nous maintenons un dataset de référence et utilisons des exemples statiques et dynamiques récupérés via AI Search ; pour chaque colonne, nous construisons un embedding à partir du nom, du type, du commentaire et du contexte, puis nous récupérons les K colonnes étiquetées les plus similaires à inclure dans le prompt.
Le prompting statique est idéal aux premiers stades ou lorsque les données étiquetées sont limitées, car il offre cohérence et reproductibilité. Le prompting dynamique est plus efficace dans les systèmes matures, utilisant la recherche vectorielle pour extraire des exemples similaires et s'adapter aux nouveaux schémas et domaines de données dans de grands datasets variés.
Orchestration de LLM
Au cœur du système se trouve une couche d'orchestration légère qui gère les appels LLM à l'échelle de la production.
Les fonctionnalités clés incluent :
- Routage multi-modèle sur des LLM hébergés en interne (par exemple, les modèles Llama, Claude et basés sur GPT) avec fallback automatique lorsqu'un modèle est indisponible.
- Logique de nouvelle tentative pour les échecs transitoires et les limites de débit avec un backoff exponentiel.
- Des hooks de validation qui détectent les étiquettes vides, invalides ou hallucinées et réexécutent ces cas avec des modèles de secours.
- Traitement batch qui annote plusieurs colonnes à la fois pour optimiser l'utilisation des jetons sans perte de contexte.
Système d'étiquetage à plusieurs niveaux
Nous prédisons trois types d'étiquettes par colonne :
- Étiquettes granulaires, issues d'un ensemble de plus de 100 options détaillées qui permettent le masquage, l'anonymisation et des contrôles d'accès stricts.
- Les étiquettes hiérarchiques, qui regroupent des étiquettes granulaires connexes en catégories plus larges adaptées au suivi et au monitoring.
- Les étiquettes de résidence, qui indiquent si les données doivent rester dans la région ou peuvent être déplacées entre les régions, alimentant directement les politiques de déplacement des données.
Pour garantir la cohérence des prédictions et réduire les hallucinations, nous utilisons un flux en deux étapes : une étape de classification générale attribue une catégorie de haut niveau, puis une étape d'affinement choisit l'étiquette exacte au sein de cette catégorie. Cela reflète la manière dont un examinateur humain déciderait d'abord qu'il s'agit de « données de l'espace de travail », puis choisirait l'étiquette d'identification d'espace de travail spécifique.
Versionnage des modèles et prédiction des étiquettes
Au lieu de s'appuyer sur une seule configuration « optimale », chaque configuration de modèle est traitée comme un expert qui entre en compétition pour étiqueter une colonne.
Plusieurs versions de modèles s'exécutent en parallèle avec des différences au niveau de :
- Choix de LLM principaux et fallback.
- Utilisation des commentaires générés par rapport aux métadonnées brutes.
- Stratégie de prompting (few-shot statique ou dynamique).
- Granularité des étiquettes et sous-ensembles de la taxonomie.
Chaque expert produit une étiquette et un score de confiance compris entre 0 et 100. Le système sélectionne ensuite l'étiquette de l'expert qui a la confiance la plus élevée, une approche de type Mélange d'experts qui améliore la précision et réduit l'impact des mauvaises prédictions occasionnelles d'une configuration donnée.
Cette conception permet d'expérimenter en toute sécurité : de nouveaux modèles ou de nouvelles stratégies de prompt peuvent être introduits, exécutés parallèlement aux modèles existants, et évalués à la fois sur les métriques et sur le volume de tickets en aval avant de devenir la solution par défaut.
Création de ticket
Le pipeline compare en continu les annotations de schéma actuelles avec les prédictions du LLM pour faire apparaître les écarts significatifs.
Les cas typiques incluent :
- De nouvelles colonnes ajoutées sans aucune annotation.
- Des annotations existantes qui ne correspondent plus au contenu de la colonne.
- Des colonnes contenant des valeurs sensibles qui ont été étiquetées comme pouvant être déplacées entre les régions.
Lorsque le système détecte une violation, il crée une entrée de règle et ouvre un ticket JIRA pour l'équipe propriétaire avec des informations sur la table, la colonne, le libellé proposé et le niveau de confiance. Cela transforme les problèmes de classification des données en un flux de travail continu que les équipes peuvent suivre et résoudre de la même manière qu'elles suivent les autres incidents de production.
Impact et évaluation
Le système a été évalué sur 2 258 échantillons étiquetés, dont 1 010 contenaient des PII et 1 248 n'en contenaient pas. Sur ce dataset, il a atteint jusqu'à 92 % de précision et 95 % de rappel pour la détection de PII.
Plus important encore pour les parties prenantes, le déploiement a produit les résultats opérationnels nécessaires :
- Le temps de révision manuelle est passé de plusieurs semaines à quelques heures pour chaque cycle d'audit à grande échelle, car les réviseurs partent d'étiquettes suggérées de haute qualité plutôt que de schémas bruts.
- La dérive d'étiquetage est désormais détectée en continu à mesure que les schémas évoluent, au lieu d'être découverte lors d'un examen annuel.
- Les alertes sur les données sensibles mal étiquetées comme sûres sont plus ciblées, ce qui permet aux équipes de sécurité d'agir rapidement plutôt que de trier les résultats de scanners bruyants basés sur des règles.
- Les politiques de masquage et de résidence des données sont appliquées à grande échelle à l'aide de la même taxonomie d'étiquettes qui alimente l'analytique et le reporting.
La précision et le rappel servent de garde-fous, mais le système est optimisé en fonction de résultats tels que le temps de révision, la latence de détection de drift et le volume de tickets exploitables produits par semaine.
Conclusion
En combinant un étiquetage basé sur la taxonomie et un cadre d'évaluation de type MoE, nous avons activé les workflows de Data Engineering et de gouvernance existants chez Databricks, les Experimentation et les déploiements étant gérés à l'aide de MLflow. Il maintient les étiquettes à jour à mesure que les schémas évoluent, accélère et cible mieux les examens de conformité, et fournit les hooks d'application nécessaires pour appliquer les règles de masquage et de résidence de manière cohérente sur l'ensemble de la plateforme.
La partie la plus passionnante de ce travail consiste à intégrer nos apprentissages internes directement dans le produit Data Classification. À mesure que nous opérationnalisons et validons ces techniques au sein de LogSentinel, nous les intégrons directement dans Databricks Data Classification.
Le même modèle—ingérer les métadonnées et les échantillons, augmenter le contexte, orchestrer plusieurs LLM et intégrer les prédictions dans les systèmes de politiques et de tickets—peut être réutilisé partout où une compréhension fiable et évolutive des données est requise. En intégrant ces insights à notre offre de produits principale, nous permettons à chaque organisation d'exploiter son intelligence des données pour la conformité et la gouvernance avec la même précision et à la même échelle que nous le faisons chez Databricks.
Remerciements
Ce projet a été rendu possible grâce à la collaboration de plusieurs équipes d'ingénieurs. Merci à Anirudh Kondaveeti, Sittichai Jiampojamarn, Zefan Xu, Li Yang, Xiaohui Sun, Dibyendu Karmakar, Chenen Liang, Viswesh Periyasamy, Chengzu Ou, Evion Kim, Matthew Hayes, Benjamin Ebanks, Sudeep Srivastava pour leur soutien et leurs contributions.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.