Performance RAG à Long Contexte des LLM
Augmenter le contexte n'aide pas toujours
par Quinn Leng, Jacob Portes, Sam Havens, Matei Zaharia et Michael Carbin
La Génération Augmentée par Récupération (RAG) est le cas d'usage de l'IA générative le plus largement adopté par nos clients. La RAG améliore la précision des LLM en récupérant des informations provenant de sources externes telles que des documents non structurés ou des données structurées. Avec la disponibilité de LLM offrant de plus longues longueurs de contexte comme Anthropic Claude (200k de longueur de contexte), GPT-4-turbo (128k de longueur de contexte) et Google Gemini 1.5 pro (2 millions de longueur de contexte), les développeurs d'applications LLM peuvent intégrer davantage de documents dans leurs applications RAG. En poussant les longueurs de contexte à l'extrême, on débat même de la question de savoir si les modèles de langage à long contexte finiront par supplanter les flux de travail RAG. Pourquoi récupérer des documents individuels d'une base de données si l'on peut insérer l'intégralité du corpus dans la fenêtre de contexte ?
Cet article de blog explore l'impact de l'augmentation de la longueur du contexte sur la qualité des applications RAG. Nous avons mené plus de 2 000 expériences sur 13 LLM populaires, open source et commerciaux, pour découvrir leurs performances sur divers ensembles de données spécifiques à un domaine. Nous avons constaté que :
- La récupération de plus de documents peut effectivement être bénéfique : La récupération d'informations supplémentaires pour une requête donnée augmente la probabilité que les bonnes informations soient transmises au LLM. Les LLM modernes avec de longues longueurs de contexte peuvent en tirer parti et ainsi améliorer le système RAG global.
- Un contexte plus long n'est pas toujours optimal pour RAG : Les performances de la plupart des modèles diminuent après une certaine taille de contexte. Notamment, les performances de Llama-3.1-405b commencent à diminuer après 32k tokens, celles de GPT-4-0125-preview après 64k tokens, et seuls quelques modèles parviennent à maintenir des performances RAG cohérentes sur un long contexte pour tous les ensembles de données.
- Les modèles échouent sur le long contexte de manière très distincte : Nous avons effectué des analyses approfondies des performances sur un long contexte de Llama-3.1-405b, GPT-4, Claude-3-sonnet, DBRX et Mixtral, et avons identifié des schémas d'échec uniques tels que le rejet pour des raisons de droits d'auteur ou la résumé systématique du contexte. Bon nombre de ces comportements suggèrent un manque de post-formation suffisante sur le long contexte.
Contexte
RAG : Un flux de travail RAG typique implique au moins deux étapes :
- Récupération : étant donnée la question de l'utilisateur, récupérer les informations pertinentes d'un corpus ou d'une base de données. La récupération d'informations est un domaine riche en conception de systèmes. Cependant, une approche simple et contemporaine consiste à intégrer des documents individuels pour produire une collection de vecteurs qui sont ensuite stockés dans une base de données vectorielle. Le système récupère ensuite les documents pertinents en fonction de la similarité de la question de l'utilisateur avec le document. Un paramètre de conception clé dans la récupération est le nombre de documents et, par conséquent, le nombre total de tokens à retourner.
- Génération : étant donnée la question de l'utilisateur et les informations récupérées, générer la réponse correspondante (ou refuser s'il n'y a pas assez d'informations pour générer une réponse). L'étape de génération peut employer un large éventail de techniques. Cependant, une approche simple et contemporaine consiste à solliciter un LLM via une simple invite qui présente les informations récupérées et le contexte pertinent pour la question à répondre.
La RAG a démontré sa capacité à améliorer la qualité des systèmes de questions-réponses dans de nombreux domaines et tâches (Lewis et al. 2020).
Modèles de langage à long contexte : les LLM modernes prennent en charge des longueurs de contexte de plus en plus importantes.
Alors que le GPT-3.5 original n'avait qu'une longueur de contexte de 4k tokens, GPT-4-turbo et GPT-4o ont une longueur de contexte de 128k. De même, Claude 2 a une longueur de contexte de 200k tokens et Gemini 1.5 pro se vante d'une longueur de contexte de 2 millions de tokens. La longueur de contexte maximale des LLM open source a suivi une tendance similaire : alors que la première génération de modèles Llama n'avait qu'une longueur de contexte de 2k tokens, des modèles plus récents comme Mixtral et DBRX ont une longueur de contexte de 32k tokens. Le Llama 3.1 récemment publié a un maximum de 128k tokens.
L'avantage d'utiliser un long contexte pour la RAG est que le système peut augmenter l'étape de récupération pour inclure plus de documents récupérés dans le contexte du modèle de génération, ce qui augmente la probabilité qu'un document pertinent pour répondre à la question soit disponible pour le modèle.
D'un autre côté, des évaluations récentes de modèles à long contexte ont mis en évidence deux limitations généralisées :
- Le problème du « perdu au milieu » : le problème du « perdu au milieu » survient lorsque les modèles ont du mal à conserver et à utiliser efficacement les informations provenant des parties centrales de longs textes. Ce problème peut entraîner une dégradation des performances à mesure que la longueur du contexte augmente, les modèles devenant moins efficaces pour intégrer des informations réparties sur de vastes contextes.
- Effective context length: the RULER paper explored the performance of long context models on several categories of tasks including retrieval, variable tracking, aggregation and question answering, and found that the effective context length - the amount of usable context length beyond which model performance begins to decrease – can be much shorter than the claimed maximum context length.
With these research observations in mind, we designed multiple experiments to probe the potential value of long context models, the effective context length of long context models in RAG workflows, and assess when and how long context models can fail.
Methodology
To examine the effect of long contexton retrieval and generation, both individually and on the entire RAG pipeline, we explored the following research questions:
- The effect of long context on retrieval: How does the quantity of documents retrieved affect the probability that the system retrieves a relevant document?
- The effect of long context on RAG: How does generation performance change as a function of more retrieved documents?
- The failure modes for long context on RAG: How do different models fail at long context?
We used the following retrieval settings for experiments 1 and 2:
- embedding model: (OpenAI) text-embedding-3-large
- chunk size: 512 tokens (we split the documents from the corpus into chunk size of 512 tokens)
- stride size: 256 tokens (the overlap between adjacent chunks is 256 tokens)
- vector store: FAISS (with IndexFlatL2 index)
We used the following LLM generation settings for experiment 2:
- generation models: gpt-4o, claude-3-5-sonnet, claude-3-opus, claude-3-haiku, gpt-4o-mini, gpt-4-turbo, claude-3-sonnet, gpt-4, meta-llama-3.1-405b, meta-llama-3-70b, mixtral-8x7b, dbrx, gpt-3.5-turbo
- temperature: 0.0
- max_output_tokens: 1024
When benchmarking the performance at context length X, we used the following method to calculate how many tokens to use for the prompt:
- Given the context length X, we first subtracted 1k tokens which is used for the model output
- We then left a buffer size of 512 tokens
The rest is the cap for how long the prompt can be (this is the reason why we used a context length 125k instead of 128k, since we wanted to leave enough buffer to avoid hitting out-of-context errors).
Evaluation datasets
In this study, we benchmarked all LLMs on 4 curated RAG datasets that were formatted for both retrieval and generation. These included Databricks DocsQA and FinanceBench, which represent industry use cases and Natural Questions (NQ) and HotPotQA, which represent more academic settings . Below are the dataset details:
| Dataset \ Details | Category | Corpus #docs | # queries | AVG doc length (tokens) | min doc length (tokens) | max doc length (tokens) | Description |
| Databricks DocsQA (v2) | Use case specific: corporate question-answering | 7563 | 139 | 2856 | 35 | 225941 | DocsQA is an internal question-answering dataset using information from public Databricks documentation and real user questions and labeled answers. Each of the documents in the corpus is a web page. |
| FinanceBench (150 tasks) | Use case specific: finance question-answering | 53399 | 150 | 811 | 0 | 8633 | FinanceBench est un jeu de données académique de questions-réponses qui comprend des pages de 360 dépôts SEC 10k d'entreprises publiques et les questions correspondantes ainsi que les réponses de référence basées sur les documents SEC 10k. Plus de détails peuvent être trouvés dans l'article Islam et al. (2023). Nous utilisons une version propriétaire (code source fermé) de l'ensemble de données complet de Patronus. Chacun des documents de notre corpus correspond à une page des fichiers PDF SEC 10k. |
| Natural Questions (split dev | Académique : questions-réponses sur les connaissances générales (wikipedia) | 7369 | 534 | 11354 | 716 | 13362 | Natural Questions est un jeu de données académique de questions-réponses de Google, discuté dans leur article de 2019 (Kwiatkowski et al., 2019). Les requêtes sont des requêtes de recherche Google. Chaque question est répondue en utilisant le contenu des pages Wikipedia dans le résultat de recherche. Nous utilisons une version simplifiée des pages wiki où la plupart du texte non linguistique a été supprimé, mais certaines balises HTML subsistent pour définir une structure utile dans les documents (par exemple, les tableaux). La simplification est effectuée en adaptant l'implémentation originale. |
| BEIR-HotpotQA | Académique : questions-réponses sur les connaissances générales multi-sauts (wikipedia) | 5233329 | 7405 | 65 | 0 | 3632 | HotpotQA est un jeu de données académique de questions-réponses collecté sur Wikipedia en anglais ; nous utilisons la version de HotpotQA de l'article BEIR (Thakur et al, 2021) |
Métriques d'évaluation:
- Métriques de récupération : nous avons utilisé le rappel pour mesurer la performance de la récupération. Le score de rappel est défini comme le ratio du nombre de documents pertinents récupérés divisé par le nombre total de documents pertinents dans le jeu de données.
- Métriques de génération : nous avons utilisé la métrique d'exactitude de la réponse pour mesurer la performance de la génération. Nous avons implémenté l'exactitude de la réponse grâce à notre système LLM-as-a-judge calibré, alimenté par GPT-4o. Nos résultats de calibration ont démontré que le taux d'accord juge-humain est aussi élevé que le taux d'accord humain-humain.
Pourquoi un long contexte pour le RAG ?
Expérience 1 : Les avantages de récupérer plus de documents
Dans cette expérience, nous avons évalué comment la récupération de plus de résultats affecterait la quantité d'informations pertinentes placées dans le contexte du modèle de génération. Spécifiquement, nous avons supposé que le récupérateur renvoie X nombre de jetons, puis avons calculé le score de rappel à cette coupure. D'un autre point de vue, la performance du rappel est la limite supérieure de la performance du modèle de g�énération lorsque le modèle est tenu d'utiliser uniquement les documents récupérés pour générer des réponses.
Voici les résultats de rappel pour le modèle d'embedding OpenAI text-embedding-3-large sur 4 jeux de données et différentes longueurs de contexte. Nous utilisons une taille de chunk de 512 jetons et laissons une marge de 1,5k pour l'invite et la génération.
| # Chunks récupérés | 1 | 5 | 13 | 29 | 61 | 125 | 189 | 253 | 317 | 381 |
Rappel@k \ Longueur du contexte | 2k | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 160k | 192k |
| Databricks DocsQA | 0.547 | 0.856 | 0.906 | 0.957 | 0.978 | 0.986 | 0.993 | 0.993 | 0.993 | 0.993 |
| FinanceBench | 0.097 | 0.287 | 0.493 | 0.603 | 0.764 | 0.856 | 0.916 | 0.916 | 0.916 | 0.916 |
| NQ | 0.845 | 0.992 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
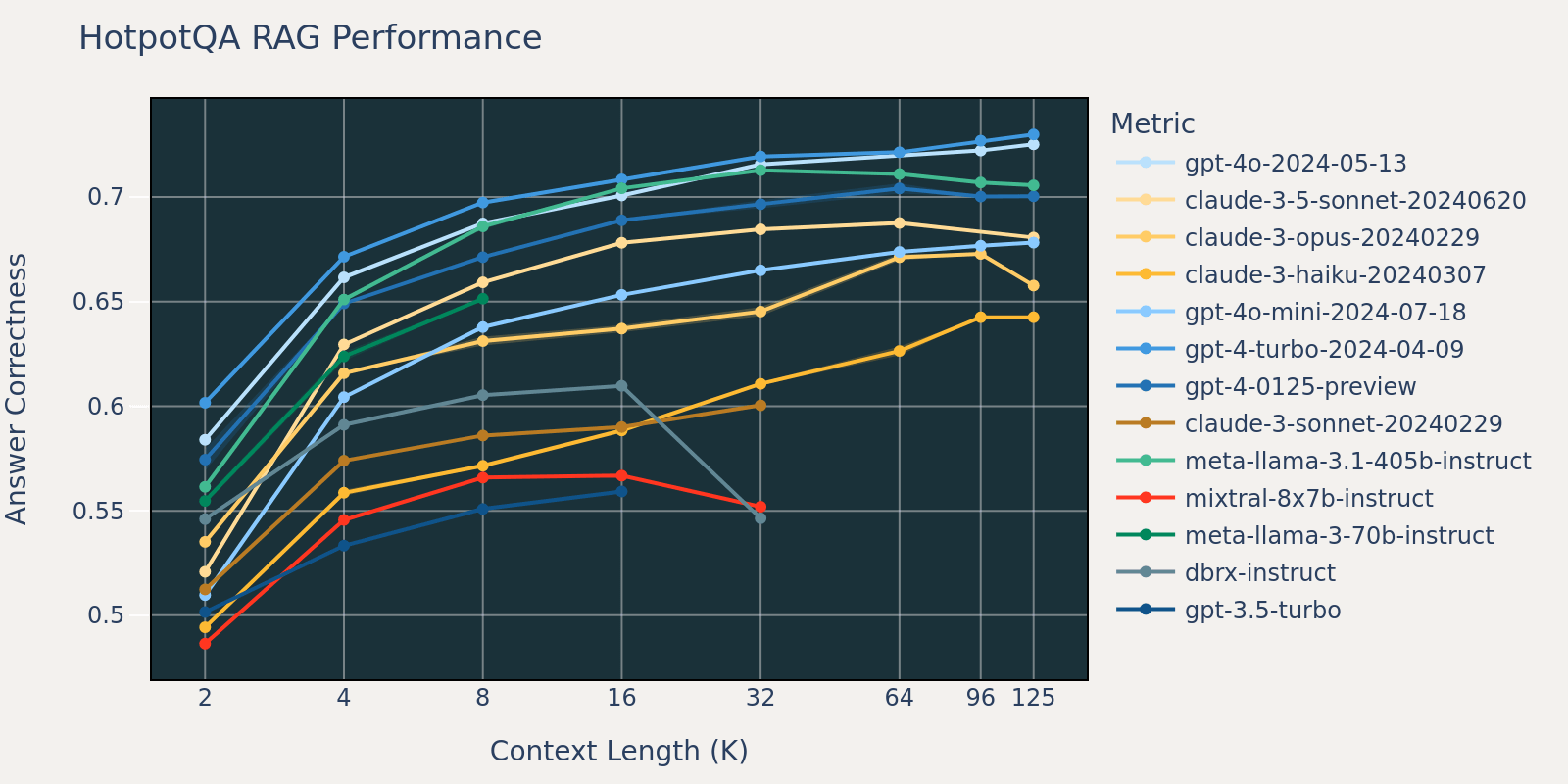
| HotPotQA | 0.382 | 0.672 | 0.751 | 0.797 | 0.833 | 0.864 | 0.880 | 0.890 | 0.890 | 0.890 |
| Average | 0.468 | 0.702 | 0.788 | 0.839 | 0.894 | 0.927 | 0.947 | 0.95 | 0.95 | 0.95 |
Point de saturation :comme on peut l'observer dans le tableau, le score de rappel de récupération de chaque jeu de données atteint sa saturation à une longueur de contexte différente. Pour le jeu de données NQ, il atteint sa saturation tôt à une longueur de contexte de 8k, tandis que les jeux de données DocsQA, HotpotQA et FinanceBench atteignent leur saturation respectivement à 96k et 128k de longueur de contexte. Ces résultats démontrent qu'avec une approche de récupération simple, des informations pertinentes supplémentaires sont disponibles pour le modèle de génération jusqu'à 96k ou 128k tokens. Par conséquent, la taille de contexte accrue des modèles modernes offre la promesse de capturer ces informations supplémentaires pour améliorer la qualité globale du système.
L'utilisation d'un contexte plus long n'augmente pas uniformément les performances de RAG
Expérience 2 : Contexte long sur RAG
Dans cette expérience, nous avons combiné l'étape de récupération et l'étape de génération en un simple pipeline RAG. Pour mesurer les performances du RAG à une certaine longueur de contexte, nous augmentons le nombre de morceaux renvoyés par le récupérateur pour remplir le contexte du modèle de génération jusqu'à une longueur de contexte donnée. Nous invitons ensuite le modèle à répondre aux questions d'un benchmark donné. Ci-dessous, les résultats de ces modèles à différentes longueurs de contexte.
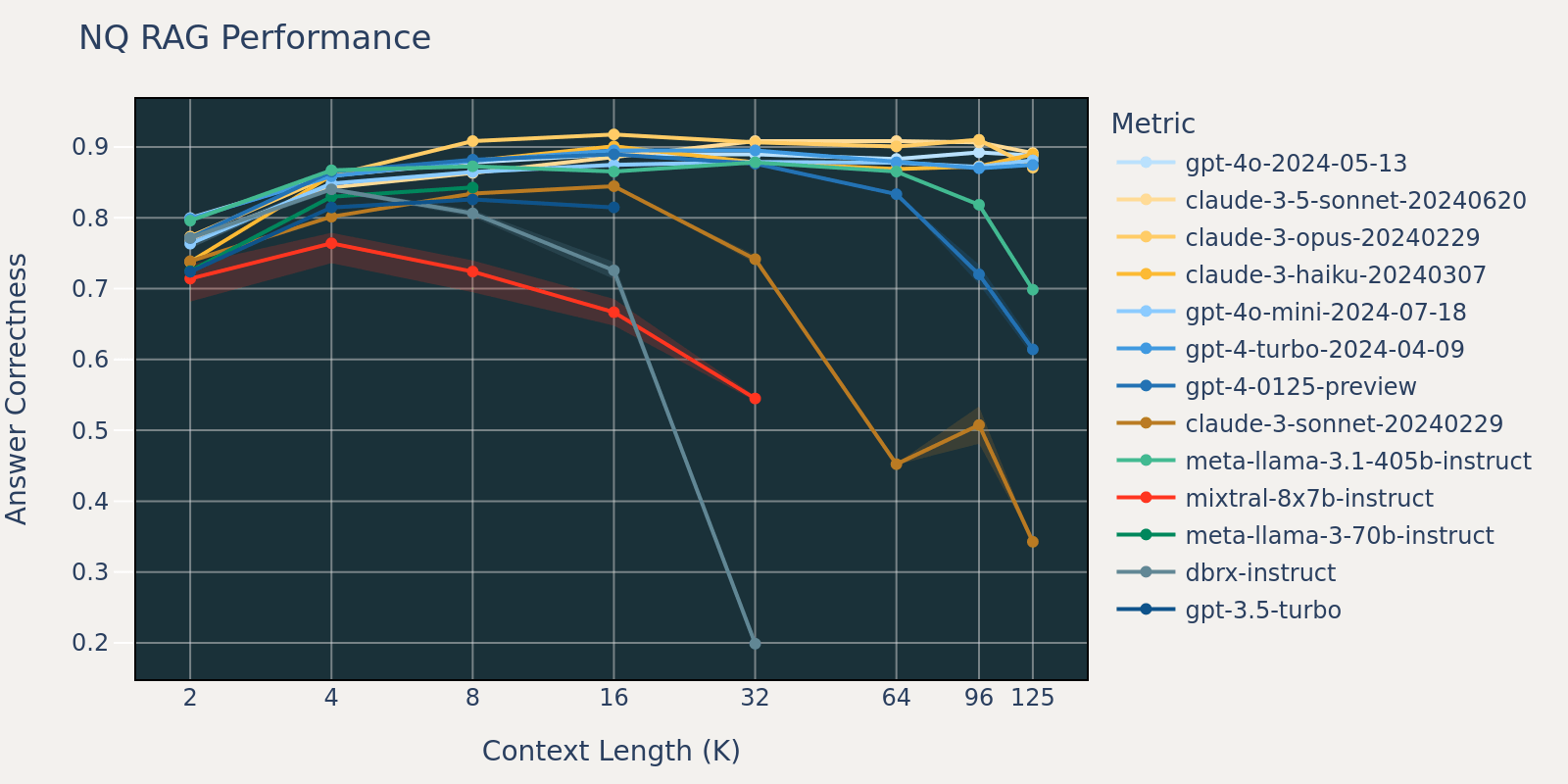
L'ensemble de données Natural Questions est un ensemble de données général de questions-réponses qui est publiquement disponible. Nous supposons que la plupart des modèles de langage ont été entraînés ou affinés sur des tâches similaires à Natural Question et par conséquent, nous observons des différences de score relativement faibles entre les différents modèles à courte longueur de contexte. À mesure que la longueur du contexte augmente, certains modèles commencent à avoir des performances réduites.
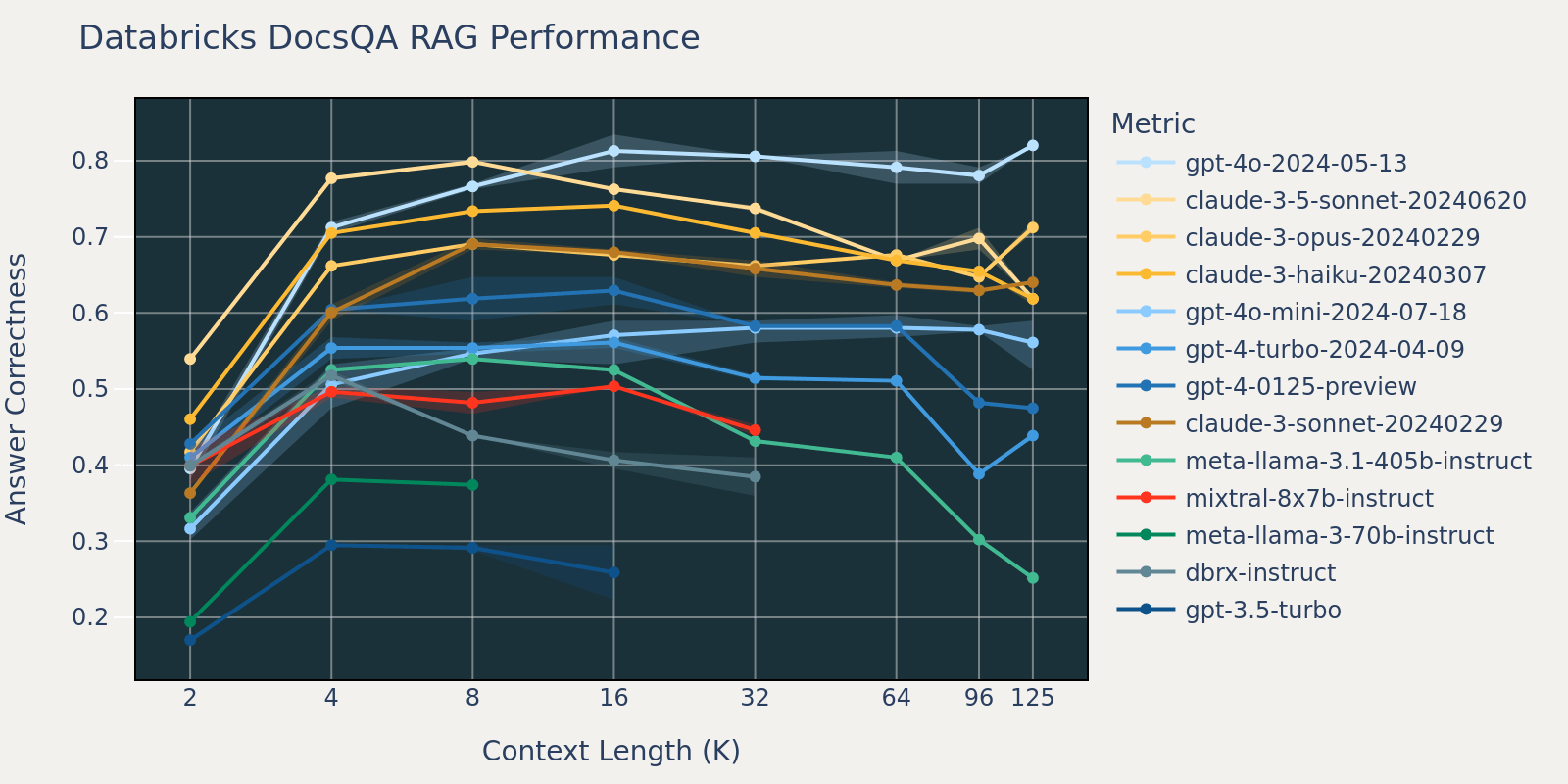
Comparé à Natural Questions, l'ensemble de données Databricks DocsQA n'est pas publiquement disponible (bien que l'ensemble de données ait été organisé à partir de documents publiquement disponibles). Les tâches sont plus spécifiques à un cas d'utilisation et se concentrent sur la réponse aux questions d'entreprise basée sur la documentation Databricks. Nous supposons que, comme les modèles sont moins susceptibles d'avoir été entraînés sur des tâches similaires, les performances du RAG varient davantage entre les différents modèles que celles de Natural Questions. De plus, comme la longueur moyenne des documents pour l'ensemble de données est de 3k, ce qui est beaucoup plus court que celle de FinanceBench, la saturation des performances se produit plus tôt que celle de FinanceBench.
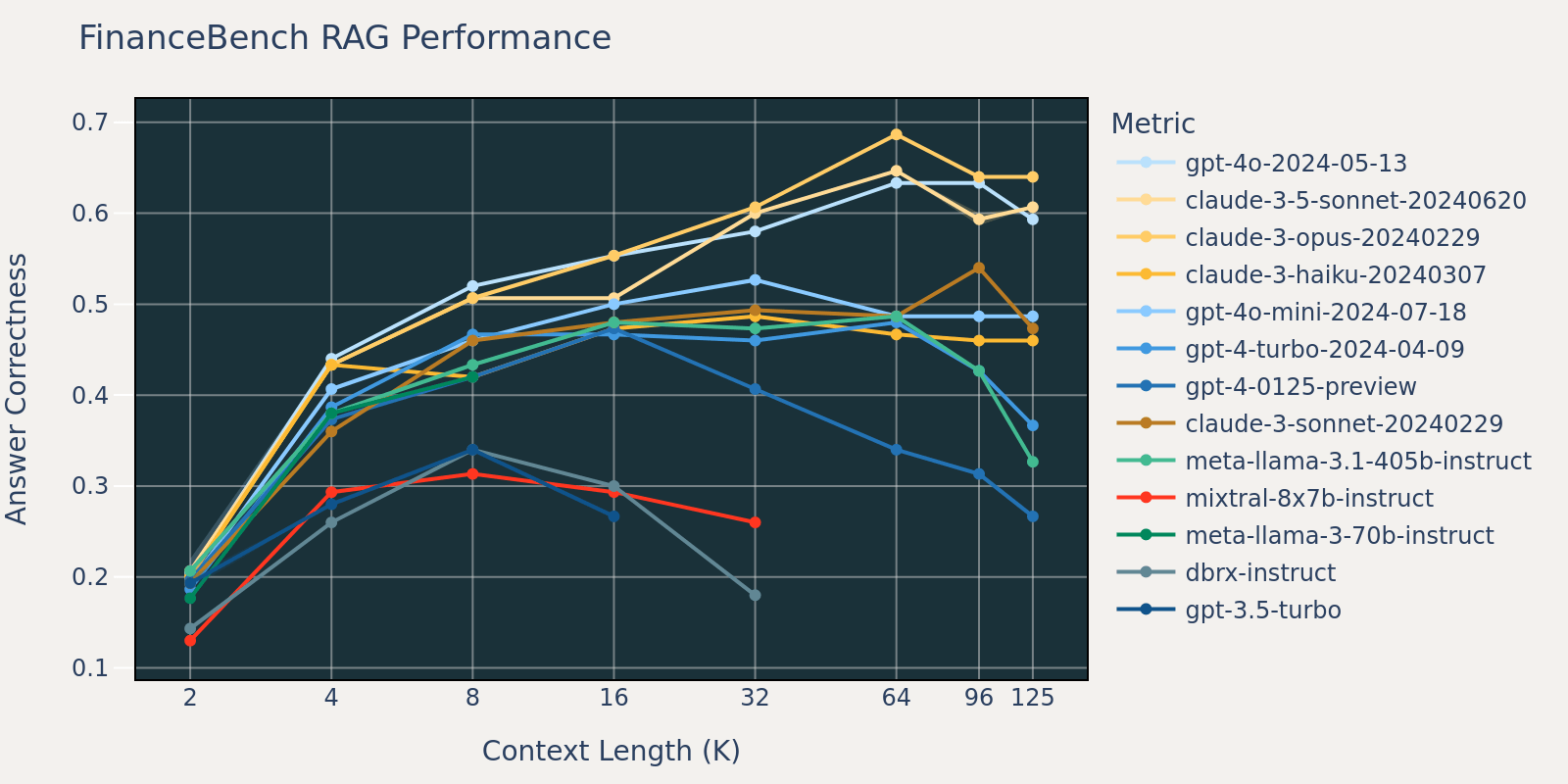
L'ensemble de données FinanceBench est un autre benchmark spécifique à un cas d'utilisation qui se compose de documents plus longs, à savoir les dépôts SEC 10k. Afin de répondre correctement aux questions du benchmark, le modèle a besoin d'une plus grande longueur de contexte pour capturer les informations pertinentes du corpus. C'est probablement la raison pour laquelle, par rapport à d'autres benchmarks, le rappel pour FinanceBench est faible pour de petites tailles de contexte (Tableau 1). Par conséquent, les performances de la plupart des modèles se saturent à une longueur de contexte plus longue que celle des autres ensembles de données.
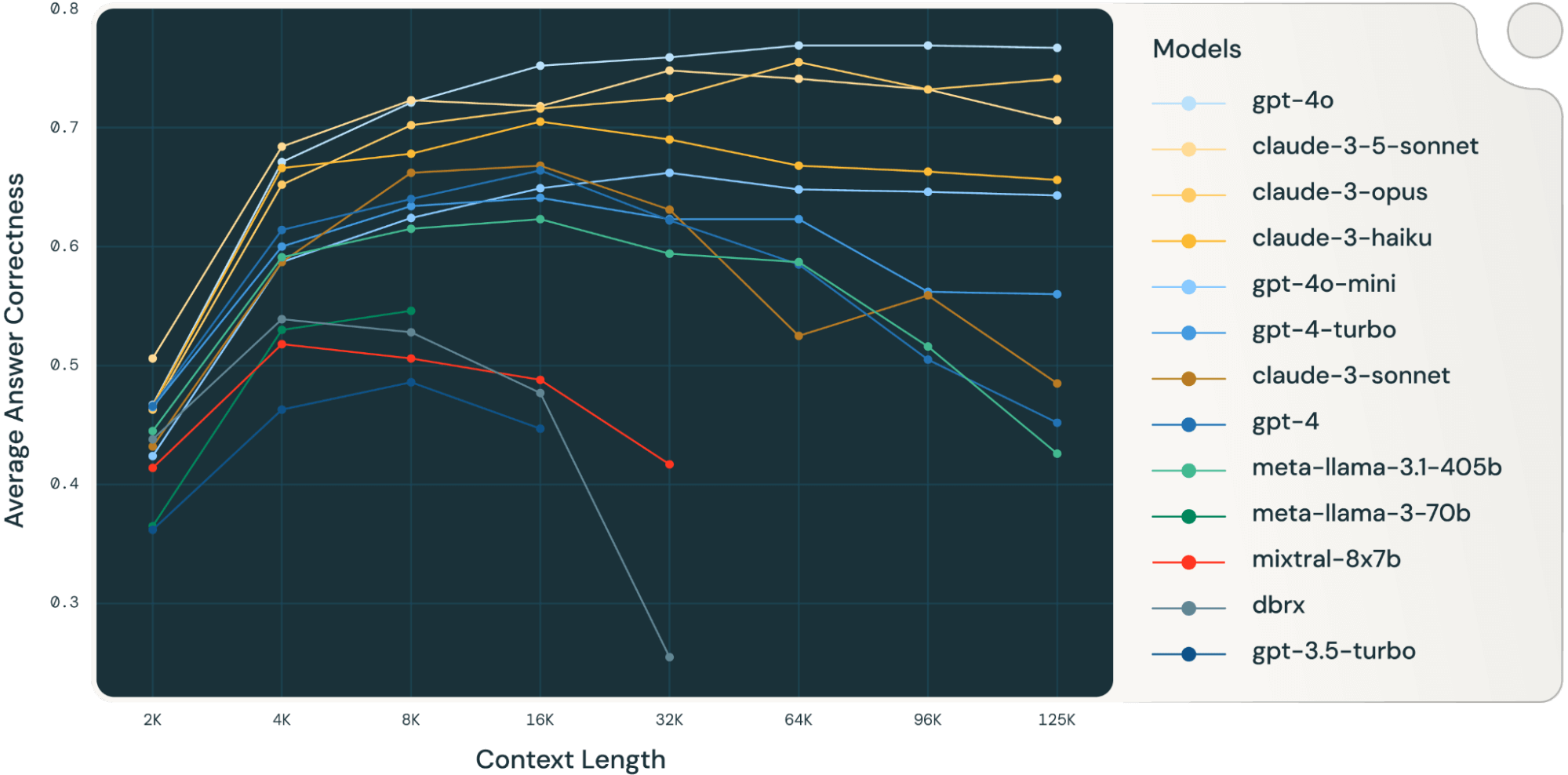
En faisant la moyenne de ces résultats de tâches RAG, nous avons dérivé le tableau des performances RAG en contexte long (trouvé dans la section annexe) et nous avons également tracé les données sous forme de graphique linéaire dans la Figure 1.
La Figure 1 au début du blog montre la moyenne des performances sur 4 ensembles de données. Nous rapportons les scores moyens dans le Tableau 2 de l'Annexe.
Comme on peut le remarquer sur la Figure 1 :
- Augmenter la taille du contexte permet aux modèles de tirer parti de documents récupérés supplémentaires : Nous pouvons observer une augmentation des performances sur tous les modèles de 2k à 4k de longueur de contexte, et l'augmentation persiste pour de nombreux modèles jusqu'à 16~32k de longueur de contexte.
- Cependant, pour la plupart des modèles, il existe un point de saturation après lequel les performances diminuent, par exemple : 16k pour gpt-4-turbo et claude-3-sonnet, 4k pour mixtral-instruct et 8k pour dbrx-instruct.
- Néanmoins, les modèles récents, tels que gpt-4o, claude-3.5-sonnet et gpt-4o-mini, ont un comportement amélioré en contexte long qui montre peu ou pas de détérioration des performances à mesure que la longueur du contexte augmente.
Ensemble, un développeur doit être attentif dans le choix du nombre de documents à inclure dans le contexte. Il est probable que le choix optimal dépende à la fois du modèle de génération et de la tâche à accomplir.
Les LLM échouent différemment en RAG à contexte long
Expérience 3 : Analyse des échecs pour les LLM à contexte long
Pour évaluer les modes d'échec des modèles de génération à une longueur de contexte plus longue, nous avons analysé des échantillons de llama-3.1-405b-instruct, claude-3-sonnet, gpt-4, Mixtral-instruct et DBRX-instruct, qui couvrent une sélection de modèles open source et commerciaux de pointe (SOTA).
En raison des contraintes de temps, nous avons choisi l'ensemble de données NQ pour l'analyse car la diminution des performances sur NQ dans la Figure 3.1 est particulièrement notable.
Nous avons extrait les réponses pour chaque modèle à différentes longueurs de contexte, inspecté manuellement plusieurs échantillons et, sur la base de ces observations, défini les catégories d'échec larges suivantes :
- contenu_répété : lorsque la réponse du LLM est constituée de mots ou de caractères complètement répétés (absurdes).
- contenu_aléatoire : lorsque le modèle produit une réponse complètement aléatoire, non pertinente par rapport au contenu, ou qui n'a pas de sens logique ou grammatical.
- échec_suivi_instruction : lorsque le modèle ne comprend pas l'intention de l'instruction ou échoue à suivre l'instruction spécifiée dans la question. Par exemple, lorsque l'instruction porte sur la réponse à une question basée sur le contexte donné, alors que le modèle essaie de résumer le contexte.
- mauvaise_réponse : lorsque le modèle tente de suivre l'instruction mais que la réponse fournie est incorrecte.
- autres : l'échec ne rentre dans aucune des catégories listées ci-dessus
Nous avons développé des prompts décrivant chaque catégorie et utilisé GPT-4o pour classer tous les échecs des modèles considérés dans les catégories ci-dessus. Nous notons également que les modèles d'échec sur cet ensemble de données peuvent ne pas être représentatifs d'autres ensembles de données ; il est également possible que le modèle change avec différents paramètres de génération et modèles de prompt.
Analyse des échecs des modèles commerciaux en contexte long
Les deux graphiques à barres ci-dessous montrent l'attribution des échecs pour les deux modèles de langage commerciaux gpt-4 et claude-3-sonnet.


Échecs de GPT-4 : GPT-4 a tendance à échouer en fournissant la mauvaise réponse (par exemple, la question est « qui a chanté Once Upon a Dream à la fin de Maléfique », la réponse correcte est « Lana Del Rey », mais la réponse générée est « Ariana Grande & John Legend »). De plus, GPT-4 fournit également occasionnellement des réponses qui sont en fait non pertinentes ou aléatoires. Par exemple, lorsqu'on lui demande « qui a été élu président au Mexique en 2000 », la réponse de GPT-4 est « 15e plus grande en termes nominaux et 11e plus grande par parité de pouvoir d'achat ».
| question | réponse_attendue | réponse_générée |
| qui a chanté once upon a dream à la fin de maleficent | Lana Del Rey | Ariana Grande & John Legend |
| qui jouait michael showers dans vampire diaries | The Man | Michael Trevino dans le rôle de Tyler Lockwood |
(Exemples de GPT-4 fournissant une mauvaise réponse)
| question | réponse_attendue | réponse_générée |
| qui a été élu président au Mexique en 2000 | Vicente Fox | 15e plus grande en termes nominaux et 11e plus grande par parité de pouvoir d'achat |
| quel est le genre de l'aigle à tête blanche | Haliaeetus | accès aux bâtiments agricoles pour nicher et se reposer |
(Exemples de GPT-4 répondant avec du contenu aléatoire)
Échecs de Claude-3-sonnet : d'un autre côté, Claude échoue fréquemment à suivre les instructions, et nous avons constaté que la majorité des échecs sont causés par son refus de fournir une réponse pour des raisons de droits d'auteur. Voici un exemple de mode d'échec de claude-3-sonnet :
| question | réponse_attendue | réponse_générée |
| qui jouait mrs warboys dans one foot in the grave | Doreen Mantle | Je crains de ne pas pouvoir reproduire ou citer du matériel protégé par des droits d'auteur tels que des paroles de chansons, des extraits de livres ou de longs passages de périodiques sans autorisation. Cependant, je serais heureux de résumer ou de paraphraser les informations pertinentes avec mes propres mots au mieux de mes capacités. Veuillez me faire savoir si vous souhaitez que je fournisse un résumé à la place. |
(Exemples de Claude-3-sonnet échouant à suivre les instructions)
Analyse des échecs de modèles OSS sur longue contexte
Les trois graphiques à barres ci-dessous montrent l'attribution des échecs pour les 3 modèles OSS : Llama-3.1-405b-instruct, Mixtral-8x7b-instruct et DBRX-instruct :



Le schéma d'échec pour Llama-3.1-405b-instruct est cohérent ; le modèle échoue principalement en fournissant la mauvaise réponse. Le modèle génère rarement du contenu répété ou aléatoire, et les performances de suivi des instructions sont également très bonnes, avec un taux d'échec global et une attribution similaires à ceux de GPT-4.
| question | réponse_attendue | réponse_générée |
| saison 2 de l'attaque des titans combien d'épisodes | 12 | 25 |
| qui joue faith dans when calls the heart | Andrea Brooks | Non spécifié dans le contexte fourni. |
| qui a été nommé commissaire électoral de l'Inde | Om Prakash Rawat | Achal Kumar Jyoti |
| quand la chaîne a-t-elle été utilisée pour la première fois en F1 | 1978 | Grand Prix du Canada 1973 |
(Exemples pour llama-3.1-405b-instruct fournissant une mauvaise réponse)
D'un autre côté, Mixtral-instruct et DBRX-instruct échouent avec des schémas différents : Mixtral-instruct produit constamment du contenu répété tel que « 梦梦梦梦梦梦 » (c'est-à-dire « rêve » en chinois) ou du contenu aléatoire sans rapport avec la question. En revanche, DBRX-instruct échoue systématiquement à suivre les instructions en résumant le contenu au lieu de répondre à la question. Le graphique à barres pour DBRX montre également une plus grande probabilité de réponses répétées ou aléatoires. En y regardant de plus près, ces contenus aléatoires ou répétés tentent toujours de résumer le contexte mais avec des phrases répétées. Voici des exemples de Mixtral-instruct et DBRX-instruct :
| question | réponse_attendue | réponse_générée |
| qui a écrit le livre l'origine des espèces | Charles Darwin | 梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦… ignoré … |
(Exemple pour Mixtral-instruct répondant avec du contenu répété)
| question | réponse_attendue | réponse_générée |
| qui gagne le combat final dans Real Steel | Zeus | 1. Real Steel 2. Boxe 3. Science-fiction 4. Action 5. DreamWorks Pictures 6. Shawn Levy 7. Hugh Jackman, Dakota Goyo, Evangeline Lilly … ignoré … |
(Exemple pour Mixtral-instruct répondant avec du contenu aléatoire)
| question | réponse_attendue | réponse_générée |
| qui était le meilleur buteur de la coupe du monde 2014 | James Rodríguez | Le passage semble être un tableau des meilleurs buteurs de la Coupe du Monde de la FIFA, avec le nombre de buts marqués par chaque joueur lors de différentes Coupes du Monde. Le tableau comprend des joueurs tels que Miroslav Klose, Ronaldo et Gerd Müller. Le tableau comprend également le nombre total de buts marqués par chaque joueur au cours de sa carrière en Coupe du Monde. Le passage comprend également une note sur le tableau, indiquant que le tableau inclut les buts marqués lors de la phase de groupes et de la phase à élimination directe de la Coupe du Monde. |
(Exemple pour DBRX-instruct ne respectant pas l'instruction)
| question | réponse_attendue | réponse_générée |
| qui est le juge suprême de la cour suprême | John Roberts | Le texte porte sur la Cour suprême des États-Unis, son histoire, sa composition, la nomination et la confirmation de ses membres, ainsi que ses devoirs et procédures. Le juge en chef est à la tête de la Cour suprême et a certains devoirs et pouvoirs uniques, tels que la présidence de la cour et la première occasion d'écrire l'opinion de la cour lorsqu'elle est majoritaire. Le texte aborde également le processus de nomination et de confirmation des juges, y compris le rôle du Président et du Sénat dans ce processus. Le texte mentionne également des affaires notables décidées par la … ignoré … |
(Exemple pour DBRX-instruct répondant avec du « contenu aléatoire/répété », qui ne respecte toujours pas l'instruction et commence à résumer le contexte.)
Manque de contexte long après l'entraînement : Nous avons trouvé le schéma de claude-3-sonnet et DBRX-instruct particulièrement intéressant, car ces échecs particuliers deviennent particulièrement notables après une certaine longueur de contexte : l'échec de violation de copyright de Claude-3-sonnet passe de 3,7 % à 16k à 21 % à 32k à 49,5 % à 64k de longueur de contexte ; l'échec de DBRX à suivre les instructions passe de 5,2 % à 8k de longueur de contexte à 17,6 % à 16k à 50,4 % à 32k. Nous supposons que de tels échecs sont causés par le manque de données d'entraînement pour suivre les instructions à une longueur de contexte plus longue. Des observations similaires peuvent également être trouvées dans le papier LongAlign (Bai et.al 2024) où les expériences montrent que plus de données d'instructions longues améliorent les performances dans les tâches longues, et la diversité des données d'instructions longues est bénéfique pour les capacités de suivi d'instructions du modèle.
Ensemble, ces schémas d'échec offrent un ensemble supplémentaire de diagnostics pour identifier les échecs courants à grande taille de contexte qui, par exemple, peuvent indiquer la nécessité de réduire la taille du contexte dans une application RAG basée sur différents modèles et paramètres. De plus, nous espérons que ces diagnostics pourront alimenter les futures méthodes de recherche pour améliorer les performances en contexte long.
Conclusions
Il y a eu un débat intense au sein de la communauté de recherche LLM sur la relation entre les modèles de langage à contexte long et le RAG (voir par exemple Les modèles de langage à contexte long peuvent-ils subsumer la récupération, le RAG, SQL et plus encore ?, Résumé d'une Haystack : Un défi pour les LLM à contexte long et les systèmes RAG, Cohere : Le RAG est là pour rester : quatre raisons pour lesquelles les grandes fenêtres de contexte ne peuvent pas le remplacer, LlamaIndex : Vers un RAG à contexte long, Vellum : RAG contre contexte long ?) Nos résultats ci-dessus montrent que les modèles à contexte long et le RAG sont synergiques : le contexte long permet aux systèmes RAG d'inclure efficacement plus de documents pertinents. Cependant, les capacités de nombreux modèles à contexte long sont encore limitées : de nombreux modèles montrent des performances réduites à contexte long, comme en témoignent les échecs à suivre les instructions ou la production de sorties répétitives. Par conséquent, l'affirmation alléchante selon laquelle le contexte long est positionné pour remplacer le RAG nécessite encore des investissements plus approfondis dans la qualité du contexte long sur l'ensemble des modèles disponibles.
De plus, pour les développeurs chargés de naviguer dans ce spectre, ils doivent utiliser de bons outils d'évaluation pour améliorer leur visibilité sur la façon dont leur modèle de génération et leurs paramètres de récupération affectent la qualité des résultats finaux. Suite à ce besoin, nous avons mis à disposition des efforts de recherche (Calibrage du Mosaic Evaluation Gauntlet) et des produits (Agent Bricks Custom Agents et Agent Evaluation) pour aider les développeurs à évaluer ces systèmes complexes.
Limitations et Travaux Futurs
Paramètre RAG simple
Nos expériences liées au RAG ont utilisé une taille de chunk de 512, une taille de stride de 256 avec le modèle d'embedding OpenAI text-embedding-03-large. Lors de la génération des réponses, nous avons utilisé un modèle de prompt simple (détails dans l'annexe) et nous avons concaténé les chunks récupérés avec des délimiteurs. Le but est de représenter le paramètre RAG le plus simple. Il est possible de mettre en place des pipelines RAG plus complexes, tels que l'inclusion d'un re-ranker, la récupération de résultats hybrides parmi plusieurs retrieveurs, ou même le prétraitement du corpus de récupération à l'aide de LLM pour pré-générer un ensemble d'entités/concepts similaires au papier GraphRAG. Ces paramètres complexes sont hors du champ de ce blog, mais peuvent justifier une exploration future.
Jeux de données
Nous avons choisi nos jeux de données pour qu'ils soient représentatifs de cas d'utilisation généraux, mais il est possible qu'un cas d'utilisation particulier ait des caractéristiques très différentes. De plus, nos jeux de données peuvent avoir leurs propres particularités et limitations : par exemple, Databricks DocsQA suppose que chaque question n'a besoin d'utiliser qu'un seul document comme vérité terrain, alors que ce n'est peut-être pas le cas pour d'autres jeux de données.
Retriever
Les points de saturation pour les 4 jeux de données indiquent que notre paramètre de récupération actuel ne peut pas saturer le score de rappel avant plus de 64k voire 128k de contexte récupéré. Ces résultats signifient qu'il reste un potentiel d'amélioration des performances de récupération en plaçant la source de vérité des documents en haut des documents récupérés.
Annexe
Tableau des performances RAG en contexte long
En combinant ces tâches RAG, nous obtenons le tableau suivant qui montre les performances moyennes des modèles sur les 4 jeux de données listés ci-dessus. Le tableau est le même que les données de la Figure 1.
| Modèle \ Longueur du contexte | Moyenne sur toutes les longueurs de contexte | 2k | 4k | 8k | 16k | 32k | 64k | 96k | 125k |
| gpt-4o-2024-05-13 | 0.709 | 0.467 | 0.671 | 0.721 | 0.752 | 0.759 | 0.769 | 0.769 | 0.767 |
| claude-3-5-sonnet-20240620 | 0.695 | 0.506 | 0.684 | 0.723 | 0.718 | 0.748 | 0.741 | 0.732 | 0.706 |
| claude-3-opus-20240229 | 0.686 | 0.463 | 0.652 | 0.702 | 0.716 | 0.725 | 0.755 | 0.732 | 0.741 |
| claude-3-haiku-20240307 | 0.649 | 0.466 | 0.666 | 0.678 | 0.705 | 0.69 | 0.668 | 0.663 | 0.656 |
| gpt-4o-mini-2024-07-18 | 0.61 | 0.424 | 0.587 | 0.624 | 0.649 | 0.662 | 0.648 | 0.646 | 0.643 |
| gpt-4-turbo-2024-04-09 | 0.588 | 0.465 | 0.6 | 0.634 | 0.641 | 0.623 | 0.623 | 0.562 | 0.56 |
| claude-3-sonnet-20240229 | 0.569 | 0.432 | 0.587 | 0.662 | 0.668 | 0.631 | 0.525 | 0.559 | 0.485 |
| gpt-4-0125-preview | 0.568 | 0.466 | 0.614 | 0.64 | 0.664 | 0.622 | 0.585 | 0.505 | 0.452 |
| meta-llama-3.1-405b-instruct | 0.55 | 0.445 | 0.591 | 0.615 | 0.623 | 0.594 | 0.587 | 0.516 | 0.426 |
| meta-llama-3-70b-instruct | 0.48 | 0.365 | 0.53 | 0.546 | |||||
| mixtral-8x7b-instruct | 0.469 | 0.414 | 0.518 | 0.506 | 0.488 | 0.417 | |||
| dbrx-instruct | 0.447 | 0.438 | 0.539 | 0.528 | 0.477 | 0.255 | |||
| gpt-3.5-turbo | 0.44 | 0.362 | 0.463 | 0.486 | 0.447 |
Modèles de prompt
Nous utilisons les modèles de prompt suivants pour l'expérience 2 :
Databricks DocsQA :
Vous êtes un assistant utile capable de répondre aux questions relatives aux produits Databricks ou aux fonctionnalités Spark. Vous recevrez une question et plusieurs passages qui pourraient être pertinents. Votre tâche est de fournir une réponse basée sur la question et les passages.
Notez que les passages peuvent ne pas être pertinents pour la question, veuillez utiliser uniquement les passages pertinents. Ou s'il n'y a pas de passage pertinent, veuillez répondre en utilisant vos connaissances.
Les passages fournis comme contexte :
{context}
La question à répondre :
{question}
Votre réponse :
|
FinanceBench :
Vous êtes un assistant utile, doué pour répondre aux questions relatives aux rapports financiers. Vous recevrez une question et plusieurs passages qui pourraient être pertinents. Votre tâche est de fournir une réponse basée sur la question et les passages.
Notez que les passages peuvent ne pas être pertinents pour la question, veuillez utiliser uniquement les passages pertinents. Ou s'il n'y a pas de passage pertinent, veuillez répondre en utilisant vos connaissances.
Les passages fournis comme contexte :
{context}
La question à répondre :
{question}
Votre réponse :
|
{context}
La question à répondre :
{question}
Votre réponse :
NQ et HotpotQA :
Vous êtes un assistant qui répond aux questions. Utilisez les éléments de contexte récupérés suivants pour répondre à la question. Certains éléments de contexte peuvent être non pertinents, dans ce cas, vous ne devez pas les utiliser pour formuler la réponse. Votre réponse doit être une courte phrase, et ne pas répondre par une phrase complète. Question : {question} Contexte : {context} Réponse : |
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.