Découvrez KARL : Un agent plus rapide pour la connaissance d'entreprise, optimisé par le RL personnalisé
Apprentissage par renforcement pour les agents d'entreprise
Pour consulter le rapport technique complet, cliquez ici. Vous souhaitez essayer le RL personnalisé de Databricks sur votre agent d'entreprise ? Cliquez ici.
L'amélioration des capacités de raisonnement des modèles actuels a entraîné une explosion du nombre d'agents déployés pour le travail intellectuel, comme l'écriture de code, la formulation de questions sur les données d'entreprise et l'automatisation des workflows courants. Bien que les modèles utilisés pour les tâches d'entreprise soient très puissants, ils sont également extrêmement coûteux, et les coûts d'inférence ont commencé à augmenter de manière insoutenable pour de nombreux cas d'usage. Dans cet article et le rapport technique correspondant, nous décrivons notre expérience de l'utilisation de l'apprentissage par renforcement (RL) pour créer des modèles personnalisés afin d'alimenter des cas d'usage qui sont un élément clé de notre produit Agent Bricks. Cet exemple démontre que, pour des coûts relativement bas, il est possible de créer des modèles personnalisés qui surpassent nettement les modèles de pointe sur les trois dimensions critiques : le coût d'inférence, la latence et la qualité. Nos conclusions sont cohérentes avec d'autres observations du secteur, comme le modèle Composer de Cursor, où la personnalisation basée sur le RL a permis d'améliorer considérablement la vitesse et la qualité par rapport aux alternatives.
KARL : Un agent de connaissance plus rapide, plus performant et moins cher pour les utilisateurs de Databricks
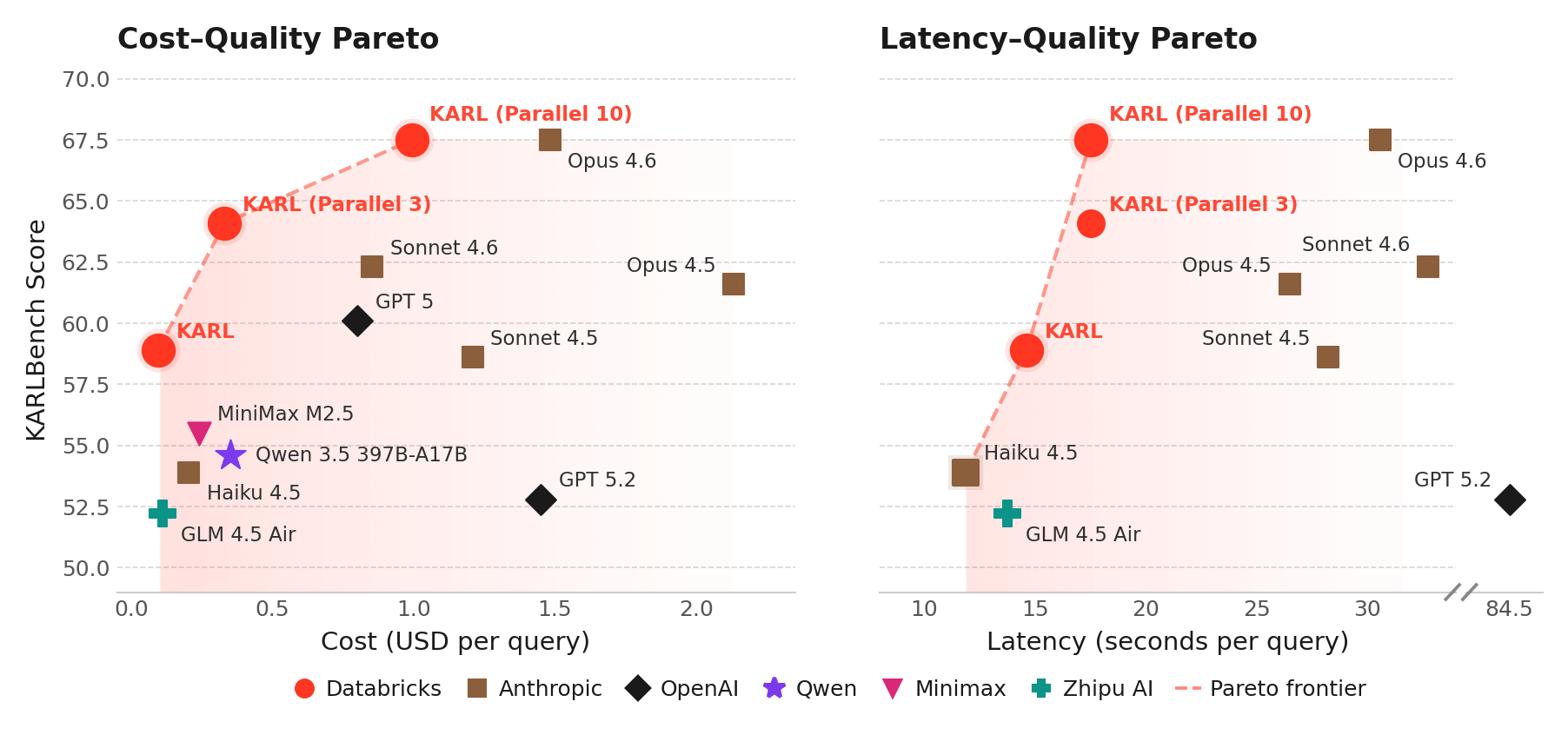
Le modèle que nous avons entraîné, que nous appelons KARL, répond à une capacité d'entreprise essentielle, le raisonnement ancré: répondre à des questions en recherchant des documents, en trouvant des faits, en recoupant des informations et en raisonnant sur des dizaines ou des centaines d'étapes. Le raisonnement ancré est requis pour plusieurs produits Databricks, tels que l'Agent Bricks Knowledge Assistant. Contrairement aux mathématiques et au codage, les tâches de raisonnement ancré sont difficiles à vérifier : il n'y a souvent pas une seule bonne réponse. Dans de telles situations, il est particulièrement difficile de guider l'apprentissage par renforcement vers une bonne solution.
Grâce aux techniques d'RL et à l'infrastructure développées chez Databricks, KARL égale les performances des modèles propriétaires les plus puissants au monde pour une fraction du coût de service et de la latence, y compris sur de nouvelles tâches de raisonnement ancré qu'il n'avait jamais vues. (Consultez le rapport technique pour plus de détails.) Nous y sommes parvenus avec seulement quelques milliers d'heures-GPU d'entraînement et des données entièrement synthétiques.
Lors de tests internes avec des utilisateurs humains, KARL a fourni des réponses de meilleure qualité et plus complètes que nos produits existants et les derniers modèles de pointe. Cette recherche est en cours d'intégration dans les agents Databricks que vous utilisez aujourd'hui, comme Agent Bricks, en ancrant les réponses dans vos données non structurées et structurées du Databricks Lakehouse.
Un pipeline de RL réutilisable pour les clients Databricks
Nous sommes ravis d'annoncer que les mêmes pipelines et infrastructures de RL que nous avons utilisés pour créer KARL (et d'autres agents dont nous parlerons bientôt) sont désormais disponibles pour les clients Databricks qui cherchent à améliorer les performances de leurs modèles et à réduire les coûts pour leurs workloads d'agents à haut volume. Presque toutes les tâches d'entreprise du monde réel sont difficiles à vérifier, KARL ouvre donc la voie – non seulement �à une meilleure expérience pour les utilisateurs de Databricks – mais aussi à la possibilité pour nos clients de créer leurs propres modèles de RL personnalisés pour leurs agents les plus populaires. Notre preview privée du RL personnalisé, soutenue par le AI Runtime, vous permet d'utiliser l'infrastructure KARL pour construire une version plus efficace et spécifique à votre domaine de votre agent. Si vous avez un agent IA qui évolue rapidement et que vous souhaitez l'optimiser avec le RL, inscrivez-vous ici pour manifester votre intérêt pour cette preview.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.