De mois en minutes : Créer des pipelines de données cliniques en temps réel avec le langage naturel
Databricks et Redox permettent aux équipes de soins de santé de créer des pipelines de données cliniques en temps réel à l'aide du langage naturel, de diffuser des données dans des environnements cloud avec une latence inférieure à la seconde et de...
- De quelques mois à quelques minutes — La création de pipelines de données EHR prenait auparavant des semaines de travail d'intégration spécialisé. Le partenariat Databricks + Redox permet aux équipes de mettre en place des pipelines de données cliniques en temps réel à l'aide d'invites en langage naturel, sans nécessiter d'experts HL7.
- Temps réel signifie vraiment temps réel — Zerobus de Redox diffuse les données cliniques directement dans Databricks Unity Catalog avec une latence inférieure à la seconde, éliminant les couches de stockage intermédiaires qui transforment le « temps réel » en « retard ».
- Des données qui agissent, pas seulement qui informent — Les sorties d'IA peuvent être réécrites dans le dossier médical électronique (DME) en temps réel, bouclant la boucle entre l'information et l'intervention — transformant Databricks d'un système d'analyse en une couche opérationnelle au point de soins.
Ce billet a été co-écrit par Assunta Carey-Saylor (Senior Product Marketing chez Redox), Tim Kessler (Field Chief Technology Officer chez Redox) et Matt Giglia (Forward Deployed Engineer pour les Sciences de la Santé et de la Vie chez Databricks)
La plupart des équipes de données de santé passent des mois à construire et à maintenir des pipelines pour déplacer les données des systèmes EHR vers leur environnement d'analyse. Même après que ce travail soit terminé, les données sont souvent acheminées via des couches de stockage intermédiaires avant de pouvoir être traitées, introduisant une latence qui limite les cas d'utilisation en temps réel.
Le résultat est un système complexe à maintenir et trop lent pour agir.
Databricks et Redox se sont associés pour changer ce modèle, en éliminant deux obstacles majeurs :
- La complexité de la création d'intégrations de données de santé
- La latence de l'acheminement des données vers l'environnement d'analyse
Désormais, les équipes peuvent mettre en place des pipelines de données cliniques en temps réel en utilisant des invites en langage naturel directement dans Databricks, simplifiant ainsi la manière dont les données sont accessibles et exploitées.
En bref : Databricks et Redox permettent aux équipes de santé de construire des pipelines de données cliniques en temps réel en utilisant le langage naturel, de diffuser des données dans des environnements cloud avec une latence inférieure à la seconde, et de renvoyer les sorties d'IA dans l'EHR pour agir au point de soins.
Le Problème : La Stratégie IA est Ralentie par l'Intégration + la Latence
Les organisations de santé subissent la pression d'opérationnaliser l'IA, mais l'exécution est constamment ralentie par l'intégration des données cliniques.
Avant que tout modèle ou flux de travail puisse être déployé, les équipes doivent s'intégrer aux systèmes EHR, normaliser les formats comme HL7, CCD et X12, et construire des pipelines ETL. Ce travail prend beaucoup de temps et nécessite une expertise spécialisée.
Même une fois les pipelines en place, les données transitent souvent par des couches de stockage intermédiaires avant d'atteindre Databricks, ajoutant de la latence et des frais opérationnels. Ce qui est étiqueté comme « temps réel » devient retardé, et les équipes d'ingénierie restent concentrées sur l'infrastructure au lieu de fournir des insights.
En conséquence, les initiatives d'IA stagnent et le temps de compréhension s'étend de semaines à des mois.
Une Nouvelle Approche
Le Zerobus Ingest de Databricks et le MCP Server de Redox introduisent une approche différente pour construire et opérer des pipelines de données cliniques dans Databricks.
Le Redox MCP Server permet aux équipes de construire et gérer des intégrations en utilisant le langage naturel, réduisant le temps et la complexité liés à la création de nouveaux pipelines de données. Zerobus diffuse les données cliniques directement dans les tables gérées par Databricks Unity Catalog avec une latence inférieure à la seconde, éliminant le besoin de couches de stockage intermédiaires ou de flux de travail pour charger les fichiers en vue de leur traitement.
Ensemble, ils modifient à la fois la manière dont les pipelines sont construits et la rapidité avec laquelle les données deviennent utilisables. L'intégration est définie par des invites plutôt que par du code, et les données sont disponibles pour le traitement dès qu'elles sont générées. Cela signifie que les équipes peuvent se connecter aux systèmes EHR, diffuser des données cliniques et activer des flux de travail directement dans Databricks.
Ce que cela donne en pratique
Dans la plateforme Databricks, un utilisateur se connecte au Redox MCP Server et commence par une invite. En quelques interactions :
- Le système identifie les environnements et les jeux de données disponibles
- Suggère les prochaines étapes pour compléter le flux de travail
- Exécute les tâches d'intégration sur les systèmes
- Affiche des signaux de validation tels que des journaux et des résumés de performance
En coulisses, Zerobus gère la livraison directe des données en streaming dans Databricks, éliminant le besoin de couches de staging ou d'ingestion par lots. Cela permet à chaque étape du flux de travail d'opérer sur des données en direct au fur et à mesure de leur arrivée.
Dans un exemple, le système a récupéré une admission récente de patient et a renvoyé à la fois des données structurées et un résumé en langage clair. Les données cliniques complexes sont devenues immédiatement utilisables pour l'analyse et la prise de décision en aval.
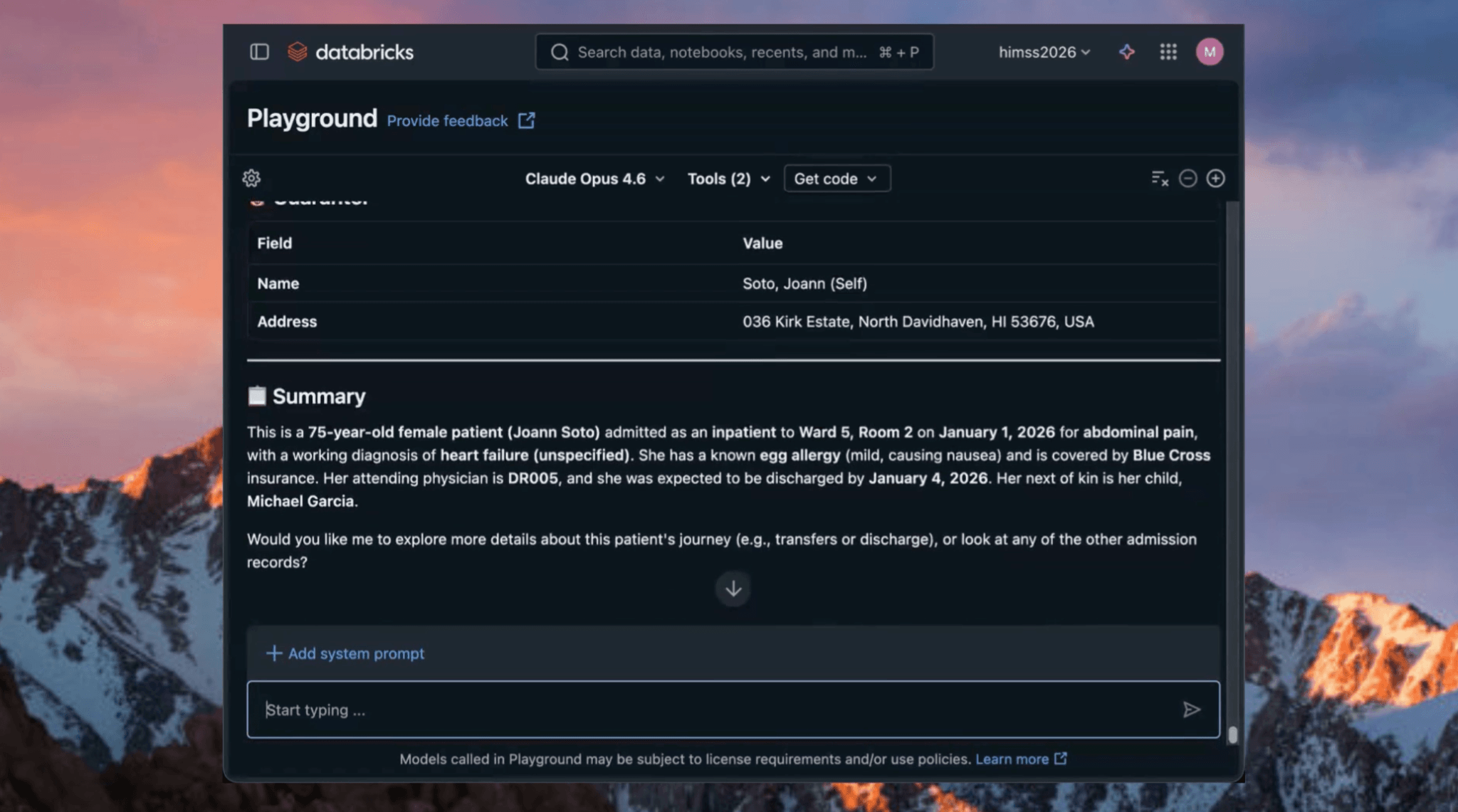
Figure 1. Le système a résumé une admission récente de patient en langage clair.
De mois en minutes : Accélérer le Temps de Compréhension
Ce qui nécessitait auparavant des semaines ou des mois de travail d'intégration peut maintenant être initié en quelques minutes, le tout en utilisant le langage naturel sans quitter Databricks.
En éliminant les étapes intermédiaires de réception des données avec Zerobus et en simplifiant la création de pipelines grâce à des invites en langage naturel, les organisations peuvent réduire considérablement la latence et le temps de développement. Cela permet aux équipes de valider plus rapidement les cas d'utilisation de l'IA, de raccourcir les cycles de développement et de passer plus rapidement de l'expérimentation à la production.
L'intégration n'est plus le facteur limitant, et la latence des données n'est plus la contrainte limitante.
Réduire la Dépendance à l'Expertise Spécialisée
L'intégration dans le domaine de la santé a traditionnellement nécessité une expertise approfondie en HL7, API et orchestration de données.
Avec le Redox MCP Server, une grande partie de cette complexité est abstraite. Les organisations peuvent réduire leur dépendance aux experts HL7 et aux spécialistes de l'intégration, permettant à des équipes plus larges de travailler avec des données cliniques.
Les data scientists et les ingénieurs ML peuvent se concentrer sur la construction de modèles et la génération d'insights au lieu de gérer des pipelines ETL. Les équipes d'ingénierie peuvent passer de la maintenance des intégrations à l'activation de nouvelles capacités.
L'objectif passe de « comment obtenons-nous les données » à « comment utilisons-nous les données ».
Activer l'Intelligence Clinique en Temps Réel
Avec Zerobus, les données cliniques arrivent dans Databricks avec une latence inférieure à la seconde, sans couches de stockage intermédiaires ni traitement par lots. Cela permet de traiter le FHIR comme il a toujours été censé l'être – comme transactionnel et envoyé à des points d'accès API REST. Par exemple, une organisation de régime d'assurance maladie ou un fournisseur peut envoyer des bundles spécifiques d'autorisation préalable via Redox directement à un point d'accès API REST dédié où il doit se trouver dans Databricks, au lieu de d'abord atterrir dans un FHIR Store ou en tant que fichier JSON FHIR matérialisé.
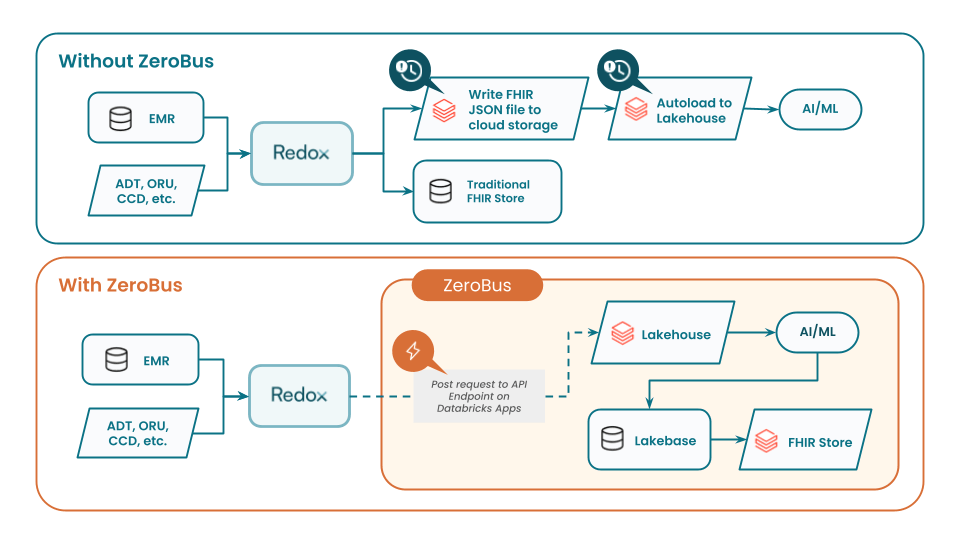
Cela permet aux frameworks d'agents ML et IA de traiter les demandes et les réponses d'autorisation préalable instantanément. En évitant le besoin de tirages de données supplémentaires ou de l'ETL complexe requis pour analyser les fichiers JSON FHIR bruts, ces systèmes peuvent capturer et agir sur le parcours du patient au fur et à mesure qu'il se déroule, et non après coup.
Associées aux capacités d'écriture dans l'EHR de Redox, ces insights peuvent être opérationnalisés directement dans les flux de travail cliniques. Les sorties générées par l'IA peuvent être renvoyées dans l'EHR en temps réel, bouclant ainsi la boucle entre les données, l'intelligence et l'action au point de soins. Cela transforme Databricks d'un simple système d'analyse en une couche d'application pour les opérations de santé, où les pipelines de données et les modèles d'IA n'informent pas seulement les décisions, mais pilotent activement les interventions au sein des systèmes cliniques centraux.
Cela débloque une nouvelle classe de cas d'utilisation en temps réel :
Suivre l'état du patient en temps réel
Mettre à jour en continu les admissions, les transferts, les sorties et les événements cliniques au fur et à mesure qu'ils se produisentOptimiser la capacité à mesure que les conditions changent
Utiliser les signaux de mouvement et de recensement des patients en direct pour améliorer la gestion des lits, la dotation en personnel et le débitDéclencher des interventions au bon moment
Engager les patients, les équipes de soins ou les systèmes en fonction de signaux cliniques en direct plutôt que de rapports retardésDétecter le risque au fur et à mesure qu'il apparaît
Identifier la détérioration, les lacunes dans les soins ou les goulots d'étranglement opérationnels tant qu'il est encore temps de réagir
Adapter dynamiquement les parcours de soins et de sortie
Ajustez les prochaines étapes en fonction de l'état actuel du patient plutôt que d'instantanés statiques
Synchroniser les flux de travail cliniques et financiers
Capturez les événements au fur et à mesure pour améliorer la précision du codage, de la facturation et du cycle de revenus
Désormais, les organisations de soins de santé peuvent fonctionner avec une plus grande agilité et réactivité, en alignant leurs flux de données sur le rythme de la prestation des soins aux patients.
Pourquoi cela fonctionne : une base de confiance sur laquelle l'IA peut agir
Cette capacité repose sur une base de données cliniques fiable et standardisée. Redox fournit la couche standardisée pour l'échange de données de santé entre les DME et les autres systèmes en aval via une plateforme et une API uniques.
Zerobus garantit que ces données arrivent dans Databricks sans délai. Le serveur MCP de Redox rend ces données accessibles et exploitables en langage naturel en traduisant l'intention en exécution tout en appliquant des contrôles de sécurité, de conformité et opérationnels de niveau entreprise.
Ensemble, ils créent une couche d'exécution en temps réel pour les données cliniques et les flux de travail d'IA.
Au-delà des pipelines : construire l'"Agent Redox"
Et nous ne nous arrêtons pas à l'ingestion de données. Comme le serveur MCP de Redox se trouve à côté des espaces Genie de Databricks au-dessus des données cliniques, les équipes d'IA peuvent désormais créer des agents Redox sur Databricks.
Ces agents spécialisés sont capables de :
- Examiner les journaux de la plateforme Redox pour dépanner ou auditer les flux de données en temps réel.
- Répondre à des questions sur les données cliniques envoyées par Redox en langage naturel.
- Intégrer l'intelligence directement dans les applications cliniques tout en maintenant la gouvernance, la sécurité et la traçabilité strictes requises par les soins de santé d'entreprise.
En combinant la puissance du MCP de Redox et de Genie, les équipes peuvent passer de la simple déplacement de données à la création d'interfaces conversationnelles et intelligentes qui s'intègrent directement dans le flux de travail existant du fournisseur.
Voyez-le en action
Lors d'un prochain webinaire Redox et Databricks le 30 avril, nous présenterons comment Zerobus et le serveur MCP fonctionnent ensemble pour fournir des pipelines de données en temps réel dans Databricks.
Vous verrez comment les équipes peuvent passer de l'intention à l'exécution en utilisant le langage naturel, tout en opérant sur des données en direct avec une latence inférieure à la seconde.
Inscrivez-vous ici pour explorer comment cette approche s'applique à votre organisation.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.