Intégration de données multimodales : Architectures de production pour l'IA dans le domaine de la santé
La plupart des efforts d'IA multimodale dans le domaine de la santé stagnent avant la production. Voici un plan pratique pour unifier la génomique, l'imagerie, les notes cliniques et les dispositifs portables avec une gouvernance, des pipelines et des...
par Maks Khomutskyi
- Construisez une base multimodale gouvernée : Intégrez des flux de génomique, d'imagerie, d'entités de notes cliniques et de dispositifs portables dans Delta avec des contrôles d'accès, une auditabilité, une lignée et des balises gouvernées via Unity Catalog.
- Choisissez une fusion qui résiste à la réalité de la production : Utilisez une fusion précoce/intermédiaire/tardive/basée sur l'attention en fonction de la disponibilité des modalités, de la dimensionnalité et du temps — conçue pour les modalités manquantes, pas pour les cohortes parfaites.
- Opérationnalisez de bout en bout : Utilisez Lakeflow SDP pour le streaming + les fenêtres de caractéristiques, la recherche vectorielle pour la similarité/le cohortage, et des pipelines reproductibles (versionnement/voyage dans le temps + CI/CD + MLflow) pour passer du POC à la production.
Les cas d'utilisation les plus précieux de l'IA dans le domaine de la santé résident rarement dans un seul jeu de données. L'intégration multimodale des données — combinant la génomique, l'imagerie, les notes cliniques et les données des objets connectés — est essentielle pour l'oncologie de précision et la détection précoce, pourtant de nombreuses initiatives échouent avant la production.
L'oncologie de précision nécessite de comprendre à la fois les moteurs moléculaires issus du profilage génomique et le contexte anatomique issu de l'imagerie. La détection précoce s'améliore lorsque les signaux de risque héréditaire rencontrent les données longitudinales des objets connectés. Et bon nombre des détails du « pourquoi » — symptômes, réponse, raisonnement — résident encore dans les notes cliniques.
Malgré des progrès réels dans la recherche, de nombreuses initiatives multimodales échouent avant la production — non pas parce que la modélisation est impossible, mais parce que les données et le modèle opérationnel ne sont pas prêts pour la réalité clinique. La contrainte n'est pas la sophistication du modèle, mais l'architecture : des piles séparées par modalité créent des pipelines fragiles, une gouvernance dupliquée et des mouvements de données coûteux qui échouent face aux besoins de déploiement clinique.
Ce billet présente un modèle de lakehouse orienté production pour la médecine de précision multimodale : comment intégrer chaque modalité dans des tables Delta gouvernées, créer des caractéristiques intermodales et choisir des stratégies de fusion qui survivent aux données manquantes du monde réel.
Architecture de référence
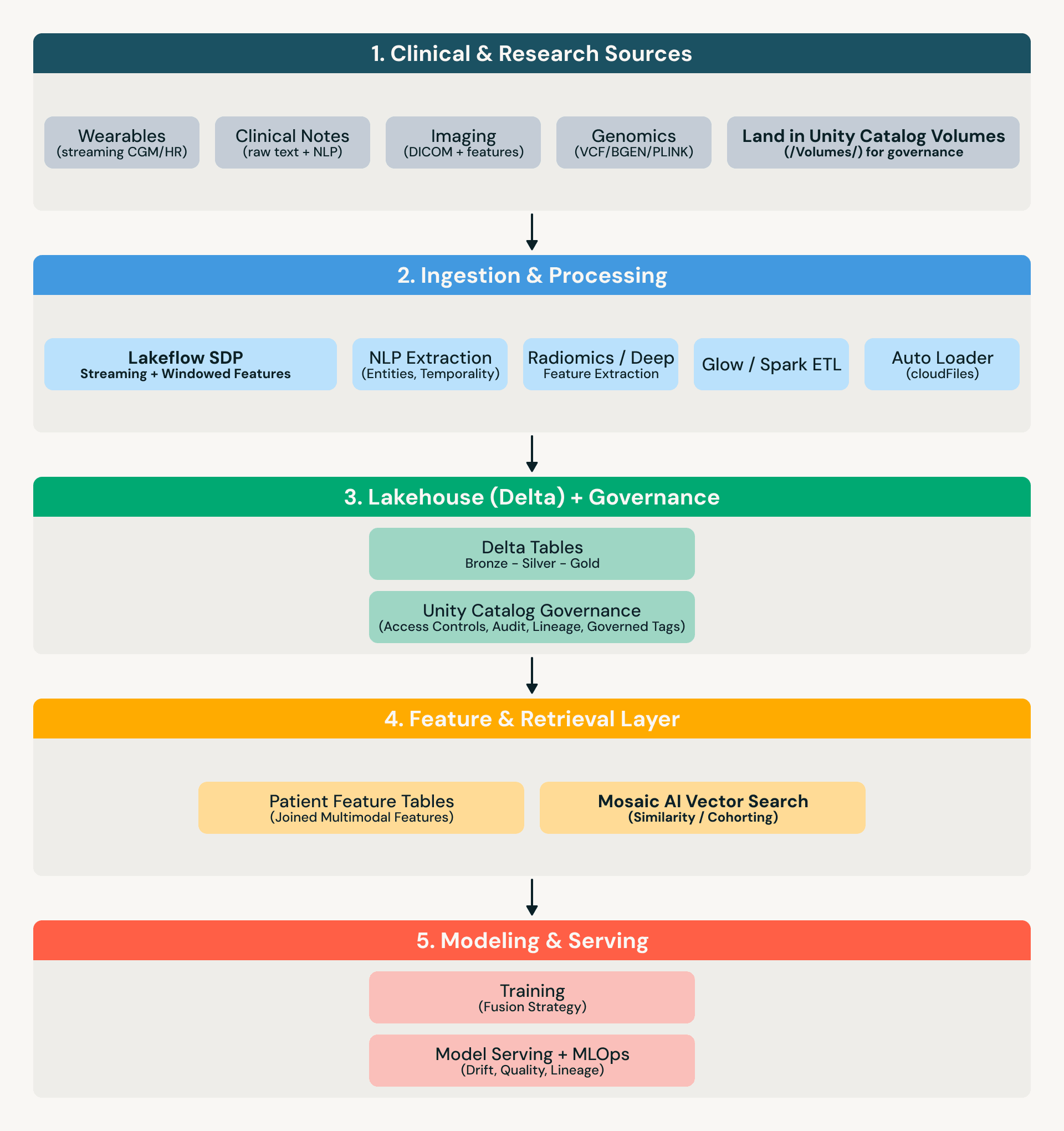
Ce que « gouverné » signifie en pratique
Tout au long de ce billet, « tables gouvernées » signifie que les données sont sécurisées et opérationnalisées à l'aide d'Unity Catalog (ou de contrôles équivalents), y compris :
Classification des données avec des balises gouvernées : PHI/PII/28 CFR Part 202/StudyID/…
- Contrôles d'accès granulaires : permissions sur le catalogue/schéma/table/volume, plus des contrôles au niveau des lignes/colonnes si nécessaire pour les PHI.
- Auditabilité : qui a accédé à quoi, quand (critique pour les environnements réglementés).
- Lignage : traçabilité des caractéristiques et des entrées du modèle jusqu'aux jeux de données sources.
- Partage contrôlé : limites de politique cohérentes entre les équipes et les outils.
Reproductibilité : versionnement et voyage dans le temps pour les jeux de données, CI/CD pour les pipelines/tâches, et MLflow pour le suivi des expériences et des versions de modèles.
Cela relie l'architecture technique aux résultats commerciaux : moins de copies de données sensibles, une analyse reproductible et des approbations plus rapides pour la mise en production.
Pourquoi le multimodal devient la norme
Les modèles unimodaux atteignent leurs limites dans des environnements cliniques complexes. L'imagerie peut être puissante, mais de nombreuses prédictions complexes bénéficient d'un contexte moléculaire + longitudinal. La génomique capture les moteurs, mais pas le phénotype, l'environnement ou la physiologie quotidienne. Les notes et les objets connectés ajoutent les signaux « entre les lignes » que les données structurées omettent souvent.
La réalité du volume compte : Databricks note qu'environ 80 % des données médicales sont non structurées (par exemple, texte et images). C'est pourquoi l'intégration de données multimodales doit gérer les notes non structurées et l'imagerie à grande échelle, et pas seulement les champs structurés des DSE.
La conclusion pratique : chaque modalité est incomplète en soi. Les systèmes multimodaux fonctionnent lorsqu'ils sont conçus pour :
- Préserver le signal spécifique à la modalité.
- Rester robustes lorsque certaines entrées sont manquantes.
Quatre stratégies de fusion (et quand chacune survit à la production)
Le choix de la fusion est rarement la seule raison de l'échec des équipes, mais il explique souvent pourquoi les pilotes ne se traduisent pas : les données sont rares, les modalités arrivent à des moments différents et les exigences de gouvernance diffèrent selon le type de données.
1) Fusion précoce (Concaténer les entrées brutes avant l'entraînement.)
- Utiliser lorsque : cohortes petites et étroitement contrôlées avec une disponibilité constante des modalités.
- Compromis : mauvaise évolutivité avec la génomique de haute dimension et les grands ensembles de caractéristiques.
2) Fusion intermédiaire (Encoder chaque modalité séparément, puis fusionner les représentations cachées.)
- Utiliser lorsque : combinaison d'omics de haute dimension avec des caractéristiques EHR/cliniques de plus faible dimension.
- Compromis : nécessite un apprentissage de représentation soigné par modalité et une évaluation disciplinée.
3) Fusion tardive (Entraîner des modèles par modalité, puis combiner les prédictions.)
- Utiliser lorsque : déploiements en production où les modalités manquantes sont courantes.
- Avantage : se dégrade gracieusement lorsqu'une ou plusieurs modalités sont absentes.
4) Fusion basée sur l'attention (Apprendre une pondération dynamique entre les modalités et le temps.)
- Utiliser lorsque : le temps est important (objets connectés + notes longitudinales, imagerie répétée) et les interactions sont complexes.
- Compromis : plus difficile à valider ; nécessite des contrôles minutieux pour éviter les corrélations fallacieuses.
Cadre de décision : faire correspondre la fusion à votre réalité de déploiement : modèles de disponibilité des modalités, équilibre de la dimensionnalité et dynamique temporelle.
Le lakehouse comme substrat multimodal
Une approche lakehouse réduit les mouvements de données entre les modalités : les tables de génomique, les métadonnées/caractéristiques d'imagerie, les entités dérivées du texte et les données des objets connectés en streaming peuvent être gouvernées et interrogées en un seul endroit, sans reconstruire les pipelines pour chaque équipe.
Traitement de la génomique (Glow + Delta)
Glow permet le traitement distribué de la génomique sur Spark sur des formats courants (par exemple, VCF/BGEN/PLINK), avec les sorties dérivées stockées sous forme de tables Delta qui peuvent être jointes aux caractéristiques cliniques.
Similarité d'images (caractéristiques dérivées + recherche vectorielle)
Pour l'imagerie, le schéma est le suivant : (1) dériver les caractéristiques/embeddings en amont (radiomique ou sorties de modèles profonds), (2) stocker les caractéristiques sous forme de tables Delta gouvernées (sécurisées via Unity Catalog), et (3) utiliser la recherche vectorielle pour les requêtes de similarité (par exemple, « trouver des phénotypes similaires au sein du glioblastome »).
Cela permet la découverte de cohortes et les comparaisons rétrospectives sans exporter les données vers des systèmes distincts.
Notes cliniques (NLP vers caractéristiques gouvernées)
Les notes contiennent souvent des contextes manquants — chronologies, symptômes, réponse, raisonnement. Une approche pratique consiste à extraire les entités + la temporalité dans des tables (changements de médicaments, symptômes, procédures, antécédents familiaux, chronologies), à conserver le texte brut sous une gouvernance stricte (Unity Catalog + contrôles d'accès), et à joindre les caractéristiques dérivées des notes à l'imagerie et aux omics pour la modélisation et la constitution de cohortes.
Données des objets connectés (Lakeflow SDP pour le streaming + fenêtres de caractéristiques)
Les flux de données des objets connectés introduisent des exigences opérationnelles : évolution des schémas, événements arrivant en retard et agrégation continue. Lakeflow Spark Declarative Pipelines (SDP) fournit un schéma d'ingestion vers caractéristiques robuste pour les tables de streaming et les vues matérialisées. Pour plus de lisibilité, nous y faisons référence sous le nom de Lakeflow SDP ci-dessous.
Note de syntaxe : Le module pyspark.pipelines (importé sous dp) avec les décorateurs @dp.table et @dp.materialized_view suit la sémantique Python actuelle de Databricks Lakeflow SDP.
Pourquoi le modèle de stockage + gouvernance unifié est important
Le gain opérationnel est la cohérence :
Un mode d'échec courant dans les déploiements cloud est une approche de « magasin spécialisé par modalité » (par exemple : un magasin FHIR, un magasin omics séparé, un magasin d'imagerie séparé, et un magasin de caractéristiques ou vectoriel séparé). En pratique, cela signifie souvent une gouvernance dupliquée et des pipelines inter-magasins fragiles, rendant le lignage, la reproductibilité et les jointures multimodales beaucoup plus difficiles à opérationnaliser.
- Reproductibilité : ACID + voyage dans le temps pour des ensembles d'entraînement cohérents et des réanalyses.
- Auditabilité : journaux d'accès + lignage (quelles données ont produit quelle caractéristique/modèle).
- Sécurité : limites de stratégie cohérentes entre les modalités (PHI-sûr par conception).
- Vitesse : moins de transferts et moins de copies de données entre les équipes.
C'est ce qui transforme un prototype multimodal en quelque chose que vous pouvez exécuter, surveiller et défendre en production.
Résoudre le problème de la modalité manquante
Les déploiements réels sont confrontés à des données incomplètes. Tous les patients ne reçoivent pas un profilage génomique complet. Les études d'imagerie peuvent ne pas être disponibles. Les appareils portables n'existent que pour les populations inscrites. Le manque n'est pas un cas extrême, c'est la norme.
Les conceptions de production doivent supposer la sparsité et planifier en conséquence :
- Masquage de modalité pendant l'entraînement : supprimez les entrées pendant le développement pour simuler la réalité du déploiement.
- Attention éparse / modèles conscients de la modalité : apprenez à utiliser ce qui est disponible sans trop vous fier à une seule modalité.
- Stratégies d'apprentissage par transfert : entraînez-vous sur des cohortes plus riches et adaptez-vous aux populations cliniques éparses avec une validation minutieuse.
Idée clé : les architectures qui supposent des données complètes ont tendance à échouer en production. Les architectures conçues pour la sparsité généralisent.
Modèle d'oncologie de précision : de l'architecture au flux de travail clinique
Un modèle pratique d'oncologie de précision ressemble à ceci :
- Profilage génomique -> tables moléculaires gouvernées (Unity Catalog). Stockez les variants, les biomarqueurs et les annotations sous forme de tables interrogeables avec lignage et accès contrôlé.
- Caractéristiques dérivées de l'imagerie -> similarité + cohortage. Indexez les vecteurs de caractéristiques d'imagerie pour « trouver des cas similaires » et les corrélations phénotype-génotype.
- Chronologies dérivées des notes -> éligibilité + contexte. Extrayez les entités conscientes du temps pour soutenir le dépistage des essais et une compréhension longitudinale cohérente.
- Couche de support du conseil de tumeurs (humain dans la boucle). Combinez les preuves multimodales dans une vue d'examen cohérente avec la provenance. L'objectif n'est pas d'automatiser les décisions, mais de réduire le temps de cycle et d'améliorer la cohérence de la collecte des preuves.
Impact commercial : ce qui change lorsque le multimodal devient opérationnel
La croissance du marché est une raison pour laquelle cela est important, mais le moteur immédiat est opérationnel :
- Assemblage et ré-analyse plus rapides des cohortes lorsque de nouvelles modalités arrivent.
- Moins de copies de données et moins de pipelines ponctuels.
- Cycles d'itération plus courts (semaines contre mois) pour les flux de travail translationnels.
L'analyse de la similarité des patients peut également permettre un raisonnement pratique « N=1 » en identifiant des correspondances historiques avec des profils multimodaux similaires, particulièrement précieux dans les populations de maladies rares et d'oncologie hétérogènes.
Démarrer : 30 premiers jours pragmatiques
- Choisissez une décision clinique (par exemple, mise en correspondance d'essais, stratification des risques) et définissez les métriques de succès.
- Inventoriez les modalités + le manque (qui a la génomique ? l'imagerie ? les appareils portables longitudinaux ?).
- Mettez en place des tables bronze/argent/or gouvernées et sécurisées via Unity Catalog.
- Choisissez une base de fusion qui tolère le manque (la fusion tardive est souvent un choix sûr).
- Opérationnalisez : lignage, vérifications de la qualité des données, surveillance de la dérive, ensembles d'entraînement reproductibles.
- Planifiez la validation : cohortes d'évaluation, vérifications des biais, points de contrôle du flux de travail des cliniciens.
Mots-clés : IA multimodale, médecine de précision, traitement génomique, IA d'imagerie médicale, intégration de données de santé, stratégies de fusion, architecture lakehouse
Haute priorité
Unity Catalog : https://www.databricks.com/product/unity-catalog
Santé et sciences de la vie : https://www.databricks.com/solutions/industries/healthcare-and-life-sciences
Plateforme d'intelligence de données pour la santé et les sciences de la vie : https://www.databricks.com/resources/guide/data-intelligence-platform-for-healthcare-and-life-sciences
Priorité moyenne
Documentation Databricks AI Search : https://docs.databricks.com/en/generative-ai/vector-search.html
Delta Lake sur Databricks : https://www.databricks.com/product/delta-lake-on-databricks
Data Lakehouse (glossaire) : https://www.databricks.com/glossary/data-lakehouse
Blogs connexes supplémentaires
Unifiez les données de vos patients avec RAG multimodal : https://www.databricks.com/blog/unite-your-patients-data-multi-modal-rag
Transformation de la gestion des données omiques sur la plateforme d'intelligence de données Databricks : https://www.databricks.com/blog/transforming-omics-data-management-databricks-data-intelligence-platform
Présentation de Glow (Génomique) : https://www.databricks.com/blog/2019/10/18/introducing-glow-an-open-source-toolkit-for-large-scale-genomic-analysis.html
Traitement des images DICOM à grande échelle avec databricks.pixels : https://www.databricks.com/blog/2023/03/16/building-lakehouse-healthcare-and-life-sciences-processing-dicom-images.html
Accélérateurs de solutions pour la santé et les sciences de la vie : https://www.databricks.com/solutions/accelerators
Prêt à faire passer l'IA multimodale dans le domaine de la santé des pilotes à la production ? Explorez les ressources Databricks pour les architectures HLS, la gouvernance avec Unity Catalog et les modèles d'implémentation de bout en bout.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.