Interactivité de niveau supérieur dans les tableaux de bord IA/BI
par Chris Eubank
Comme annoncé récemment à l'occasion du Data and AI Summit de cette année, Databricks AI/BI démocratise la business intelligence et l'analytique dans toute votre organisation grâce à des tableaux de bord AI/BI low-code hautement visuels et interactifs, et à une analyse conversationnelle no-code propulsée par AI/BI Genie. Dans ce blog, nous sommes ravis de présenter un certain nombre de nouvelles fonctionnalités qui améliorent les performances et l'interactivité des tableaux de bord AI/BI.
Les tableaux de bord de business intelligence hautement interactifs (ou cliquables) sont essentiels de nos jours. Ils sont indispensables car ils permettent aux utilisateurs des tableaux de bord d'explorer les données dynamiquement, en personnalisant les insights à chaque clic. Cela leur permet de poser des questions de suivi sur leurs données et de prendre des décisions plus éclairées beaucoup plus rapidement, contrairement aux tableaux de bord statiques qui limitent l'exploration et la résolution de problèmes grâce à l'analytique.
Les principales améliorations que nous aborderons dans ce blog comprennent :
- Filtrage croisé : Vous pouvez désormais cliquer sur des points de données intéressants dans une visualisation pour filtrer votre tableau de bord et voir l'impact sur d'autres métriques et visualisations clés. Cela vous aide à explorer vos données pour comprendre les relations et les corrélations qui révèlent de nouveaux insights.
- Paramètres de widget statiques : Créez plusieurs visualisations filtrées qui mettent en évidence différents aspects de vos données. Par exemple, créez deux graphiques axés sur les ventes, l'un pour l'année en cours et l'autre pour l'année précédente. Avec les paramètres de widget statiques, vous pouvez créer des visualisations à partir d'un seul jeu de données paramétré sans avoir besoin de créer un jeu de données personnalisé par visualisation.
- Valeurs par défaut du filtre : Concentrez les spectateurs sur des données ou un contexte spécifiques au sein d'un tableau de bord en définissant des valeurs de filtre par défaut qui s'appliquent au chargement initial.
- Performances améliorées : Personne n'aime les tableaux de bord qui se bloquent ou vous demandent « veuillez patienter » chaque fois que vous les ouvrez ou que vous cliquez sur un point de données intéressant. À cette fin, nous avons ajouté plusieurs améliorations de performance pour garantir que les utilisateurs obtiennent des tableaux de bord interactifs ultra-rapides afin qu'ils puissent poser des questions de suivi sur leurs données sans exécuter de requêtes SQL supplémentaires.
- Paramètres basés sur les requêtes : Les auteurs de tableaux de bord doivent être en mesure de créer des expériences expressives avec des filtres de champs et de paramètres. En permettant la combinaison de paramètres et de champs dans un seul filtre, nous avons activé de nouvelles capacités, telles que le remplissage dynamique d'une liste déroulante de paramètres avec les résultats de requêtes.
Filtrage croisé
Lors de l'exploration d'un tableau de bord, des points de données spécifiques dans une visualisation peuvent ressortir pour une enquête plus approfondie. Bien que certains filtres puissent déjà être en place, ils peuvent ne pas anticiper les besoins de chaque spectateur.
Avec le filtrage croisé, chaque graphique peut désormais être utilisé pour filtrer vos données. Cliquez simplement sur les visualisations pour filtrer le tableau de bord et explorer les données plus en profondeur. Le filtrage croisé est automatiquement activé pour toutes les visualisations qui partagent le même jeu de données, ce qui signifie que vous pouvez cliquer sur une partie d'une visualisation (comme une barre dans un diagramme en barres) pour filtrer les données dans toutes les visualisations associées du tableau de bord.
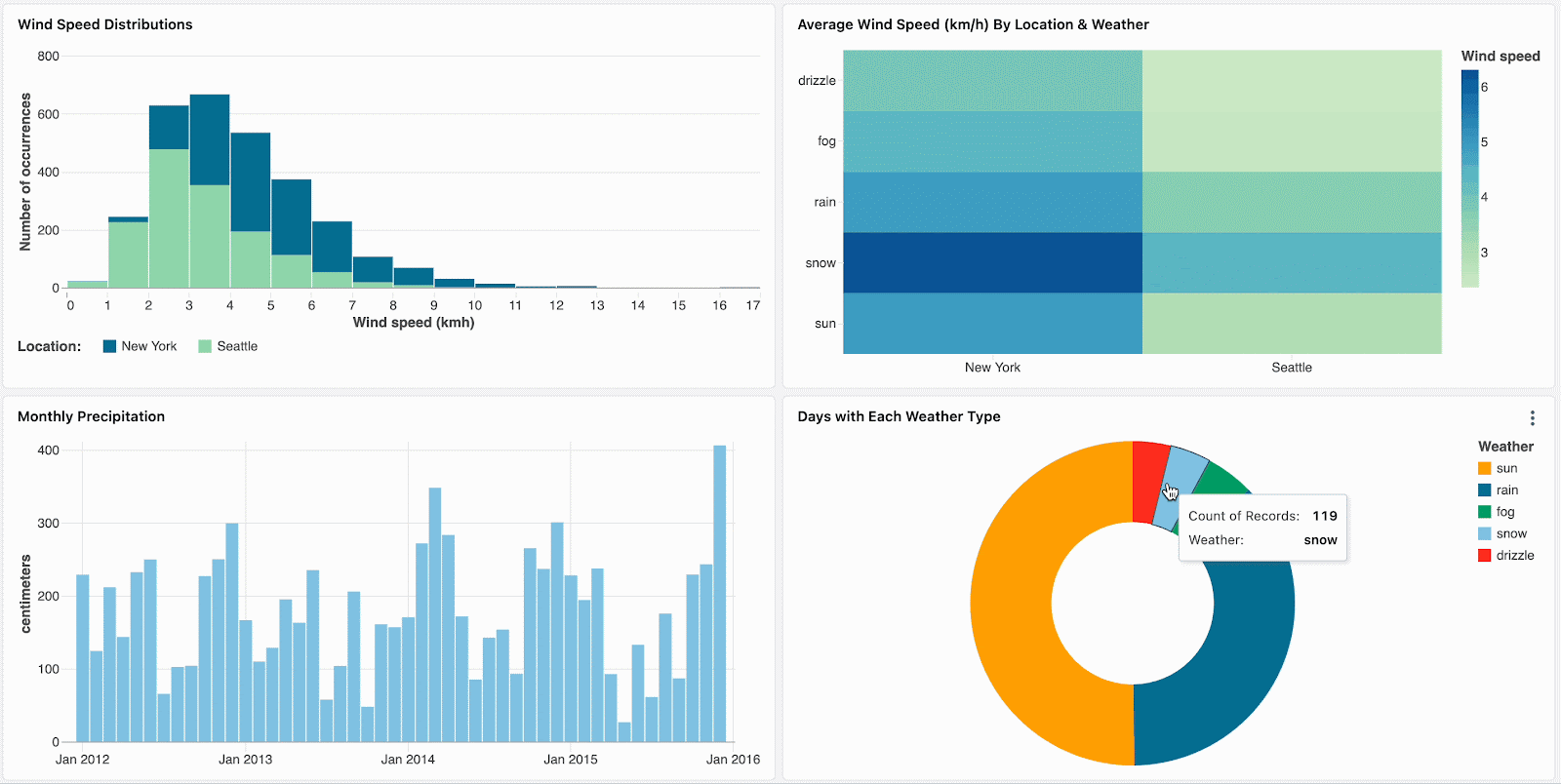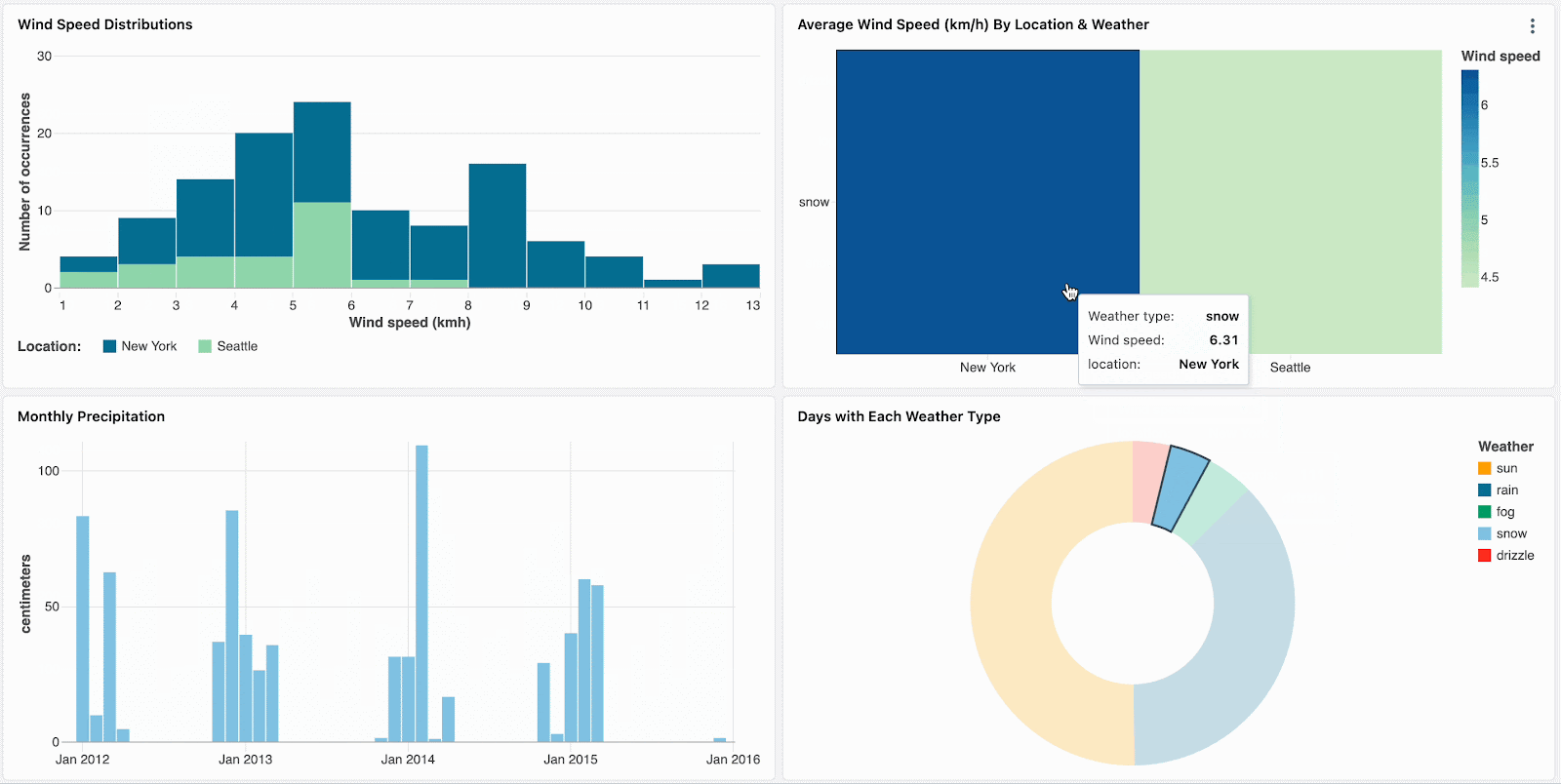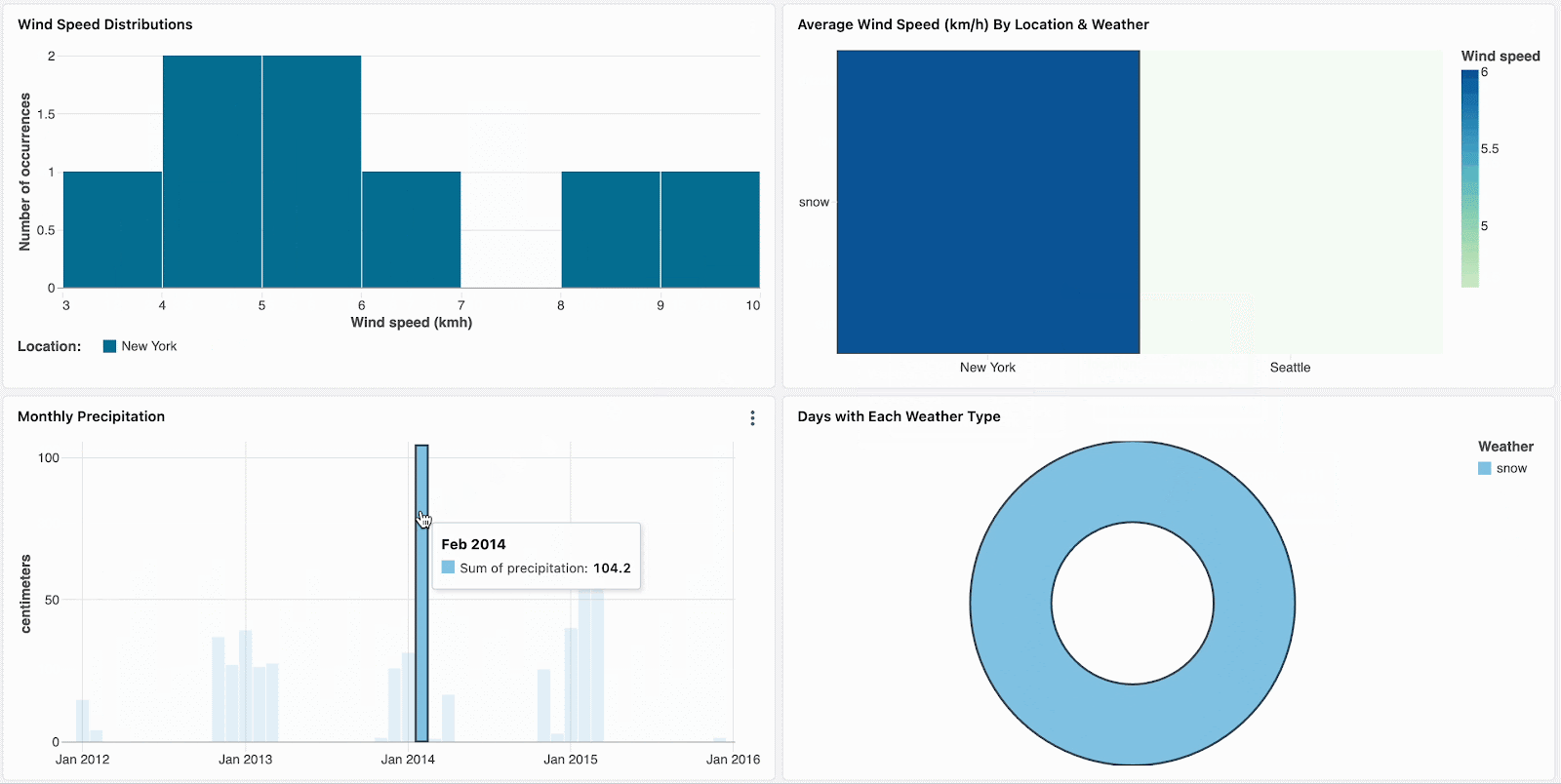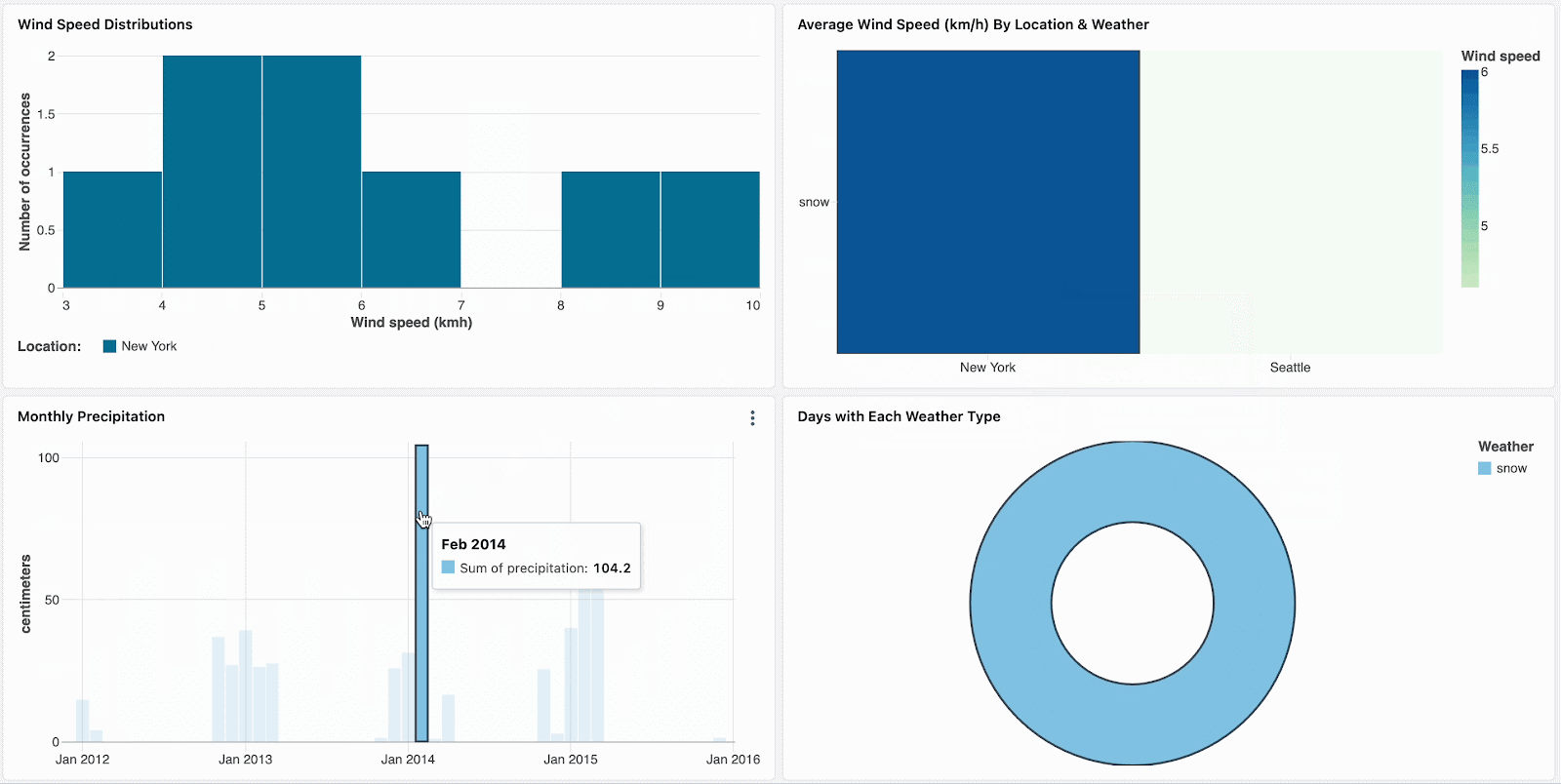
Triez vos données et concentrez votre analyse en cliquant sur les valeurs aberrantes, telles que les marques visuellement distinctes dans une carte thermique.
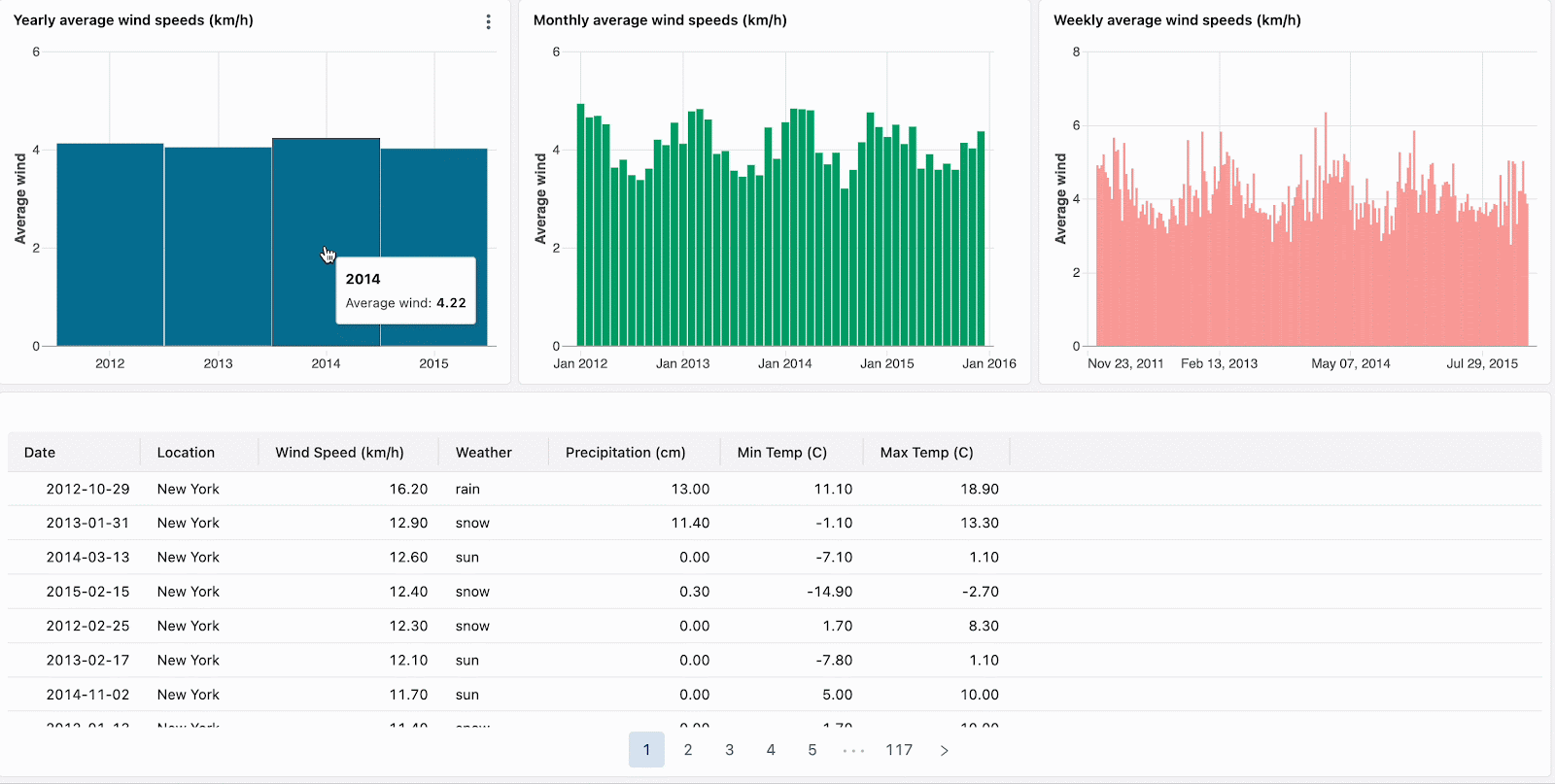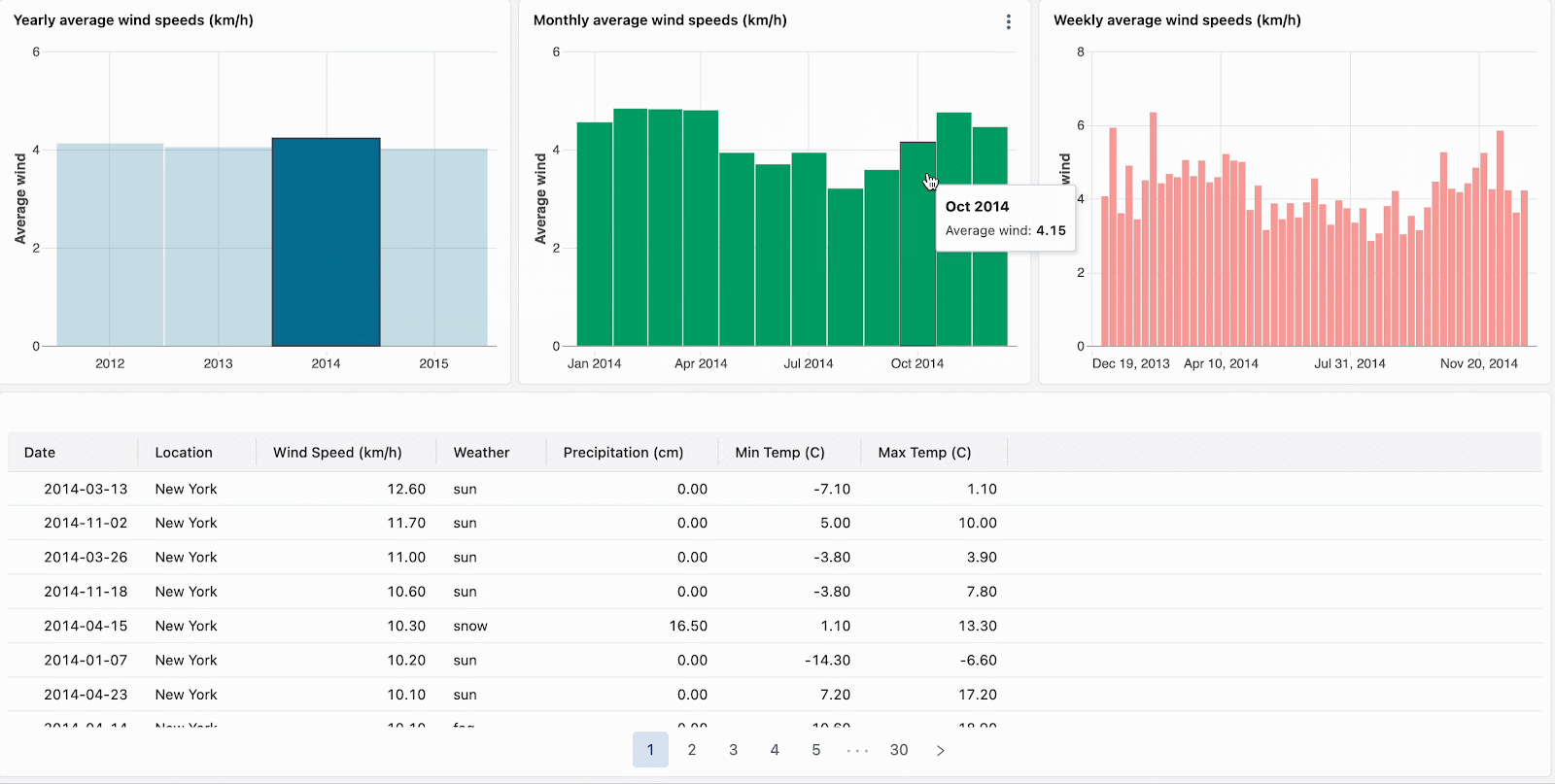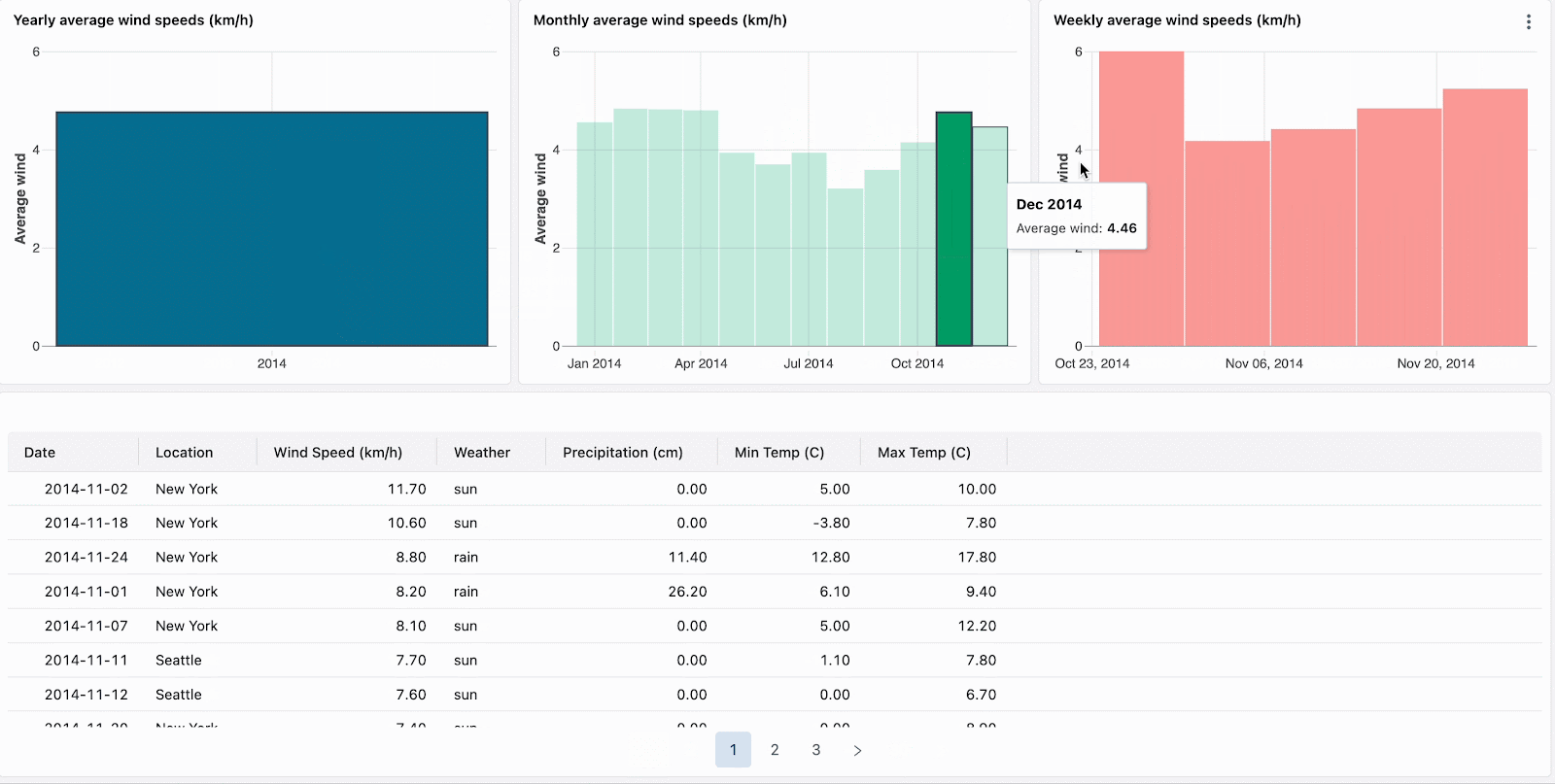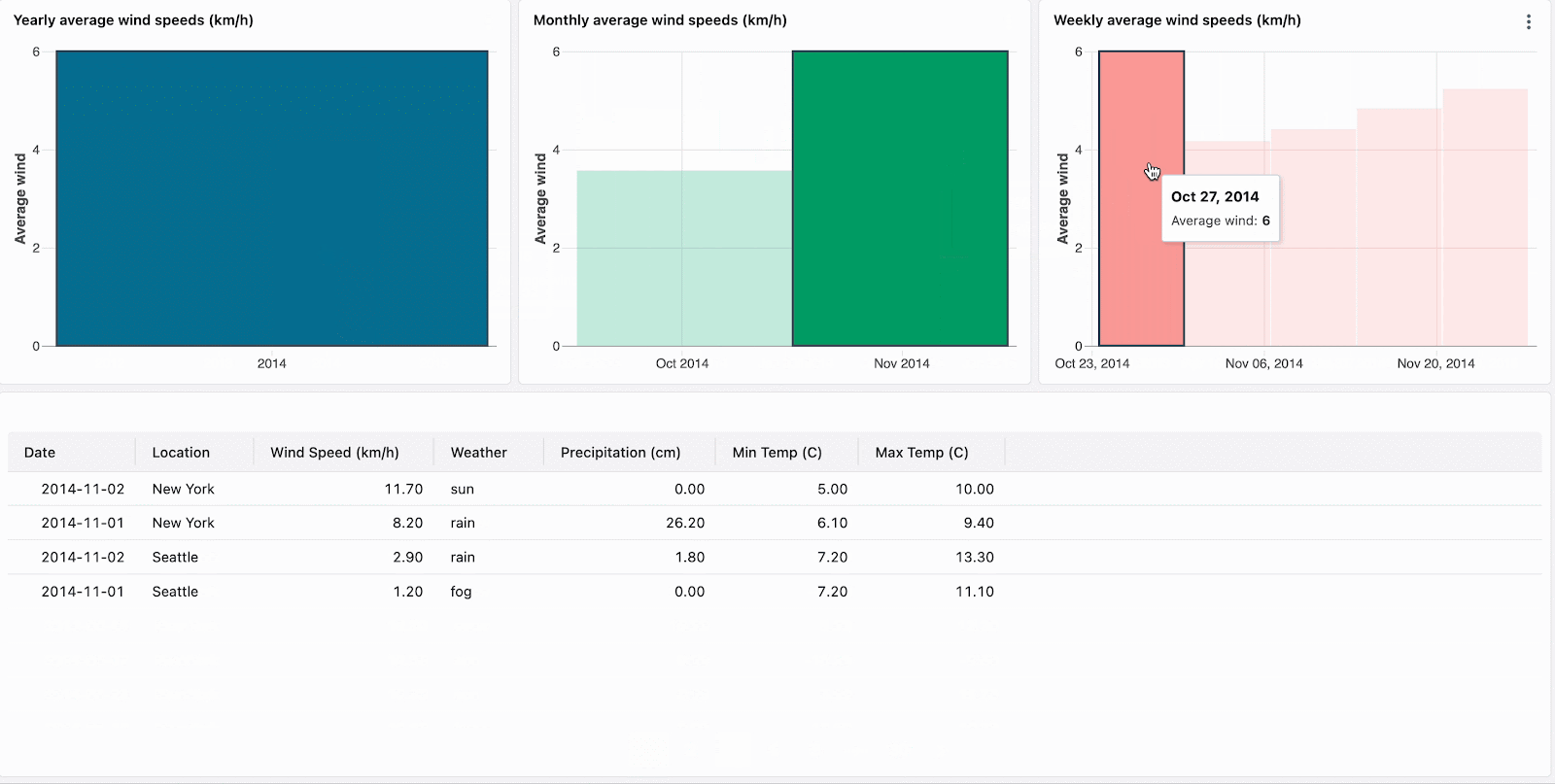
Naviguez dans les données hiérarchiques en descendant dans les visualisations agrégées. Par exemple, cliquez sur les données annuelles pour restreindre les autres graphiques aux données de cette année. Cliquez sur les barres dans les graphiques de niveau mensuel et hebdomadaire pour continuer à descendre.
Actuellement disponible pour les diagrammes en barres, les cartes thermiques, les diagrammes circulaires et les nuages de points, le filtrage croisé complète les filtres de champs et de paramètres existants. La prise en charge d'autres visualisations, notamment les histogrammes, les graphiques linéaires, les graphiques en aires, les graphiques combinés et la sélection de plusieurs valeurs, sera bientôt disponible.
Paramètres de widget statiques
La création de tableaux de bord est plus facile avec moins de jeux de données. Cloner un jeu de données juste pour ajouter un filtre ou un agrégat supplémentaire pour une visualisation spécifique introduit de l'encombrement et des frictions.
Les paramètres de widget statiques simplifient ce processus en vous permettant de personnaliser les filtres pour chaque visualisation sans créer de jeux de données filtrés distincts. Cette fonctionnalité complète la capacité existante de définir des agrégats et des regroupements par visualisation.
Par exemple, pour mettre en évidence les métriques de température pour différents endroits en utilisant un seul jeu de données, vous pouvez l'augmenter avec une condition telle que :
Ensuite, définissez simplement une valeur de paramètre statique différente pour chaque nouvelle visualisation. Dans l'exemple ci-dessous, vous pouvez voir trois graphiques : un pour tous les emplacements, un pour Seattle et un pour New York. Chaque graphique utilise le même jeu de données, mais des valeurs statiques différentes sont appliquées pour filtrer les données en conséquence.
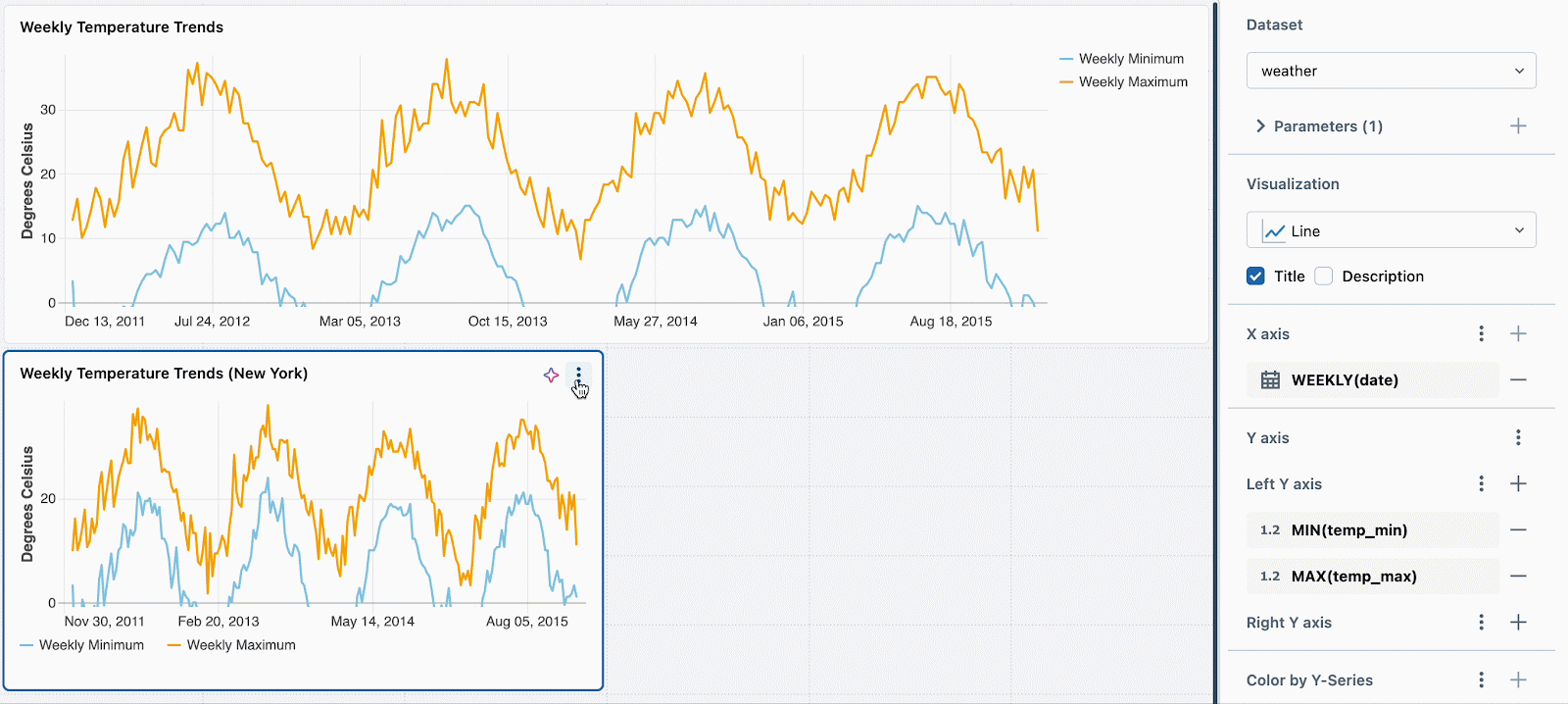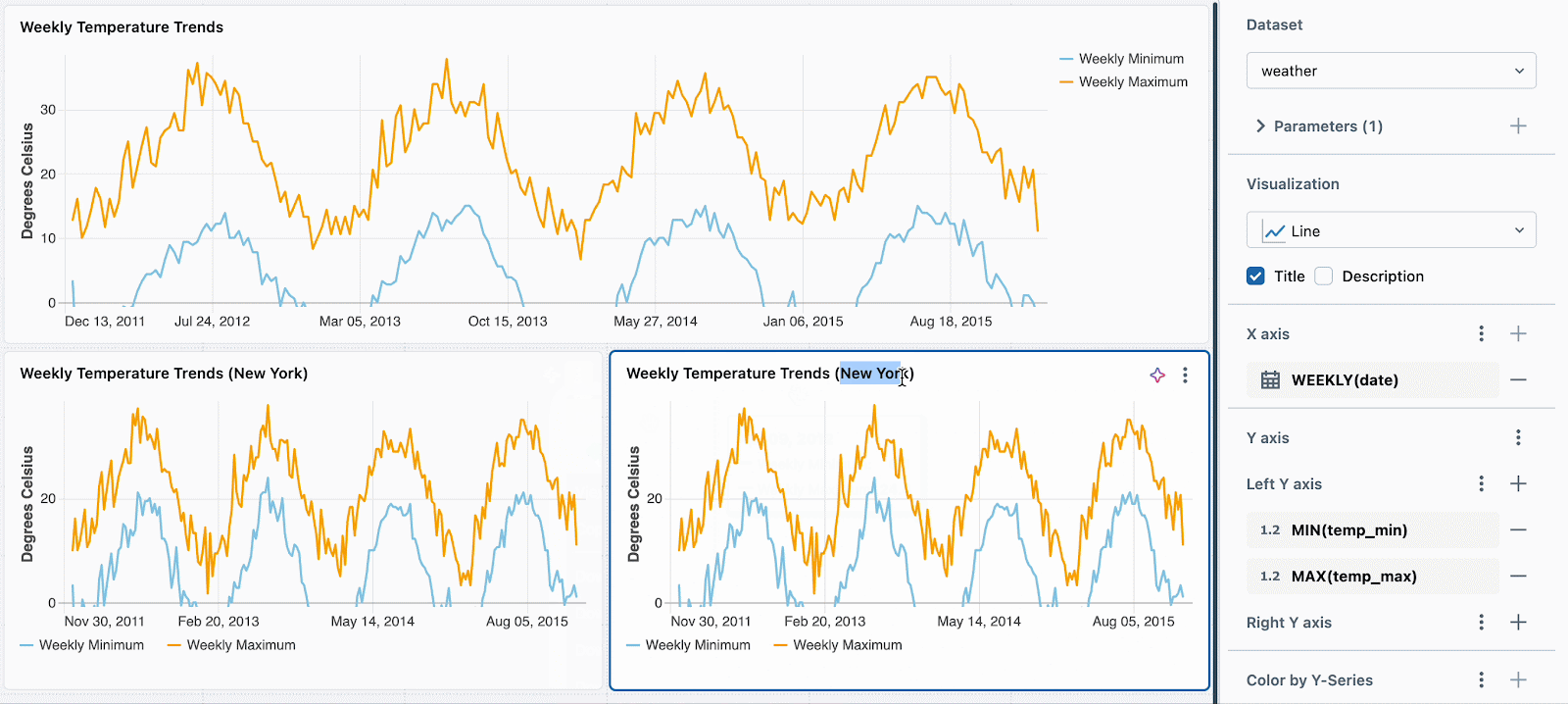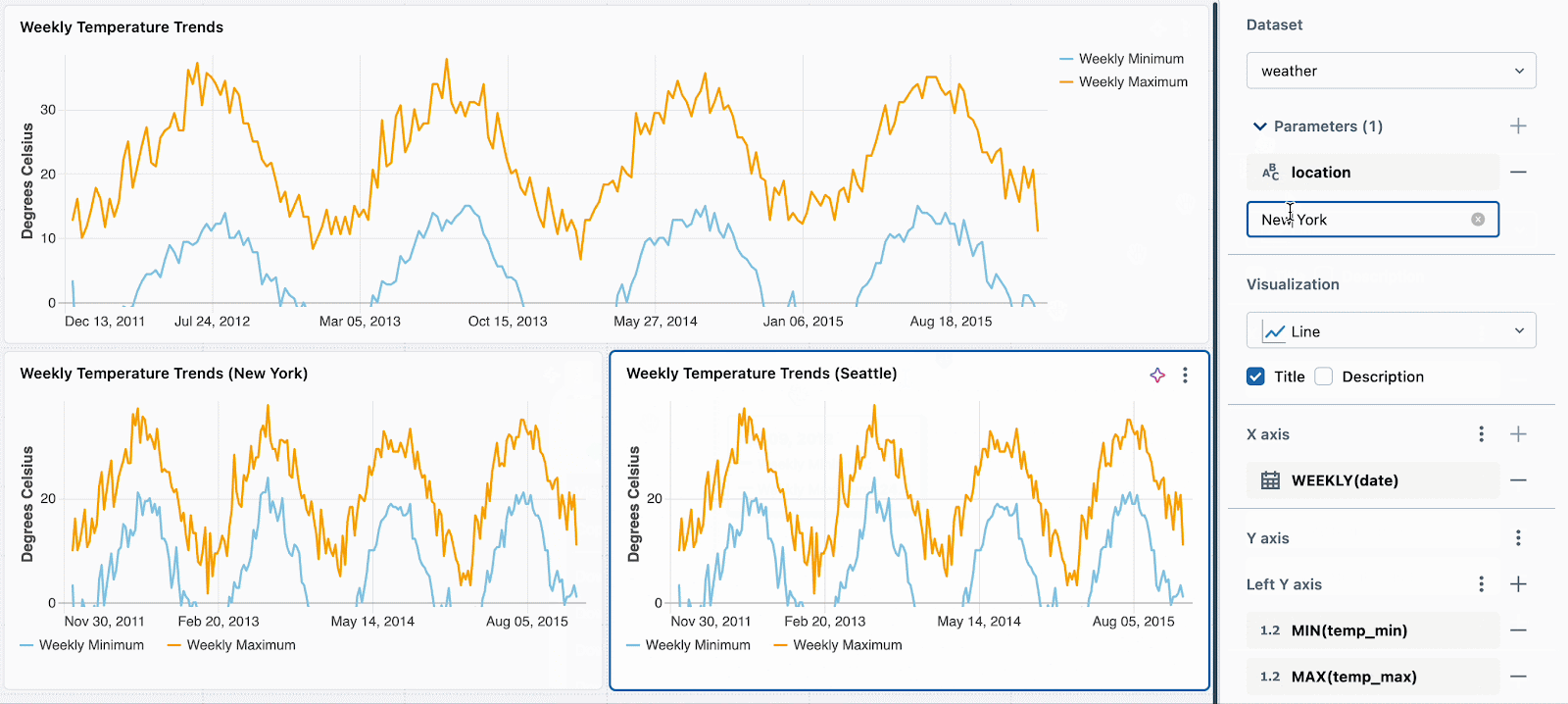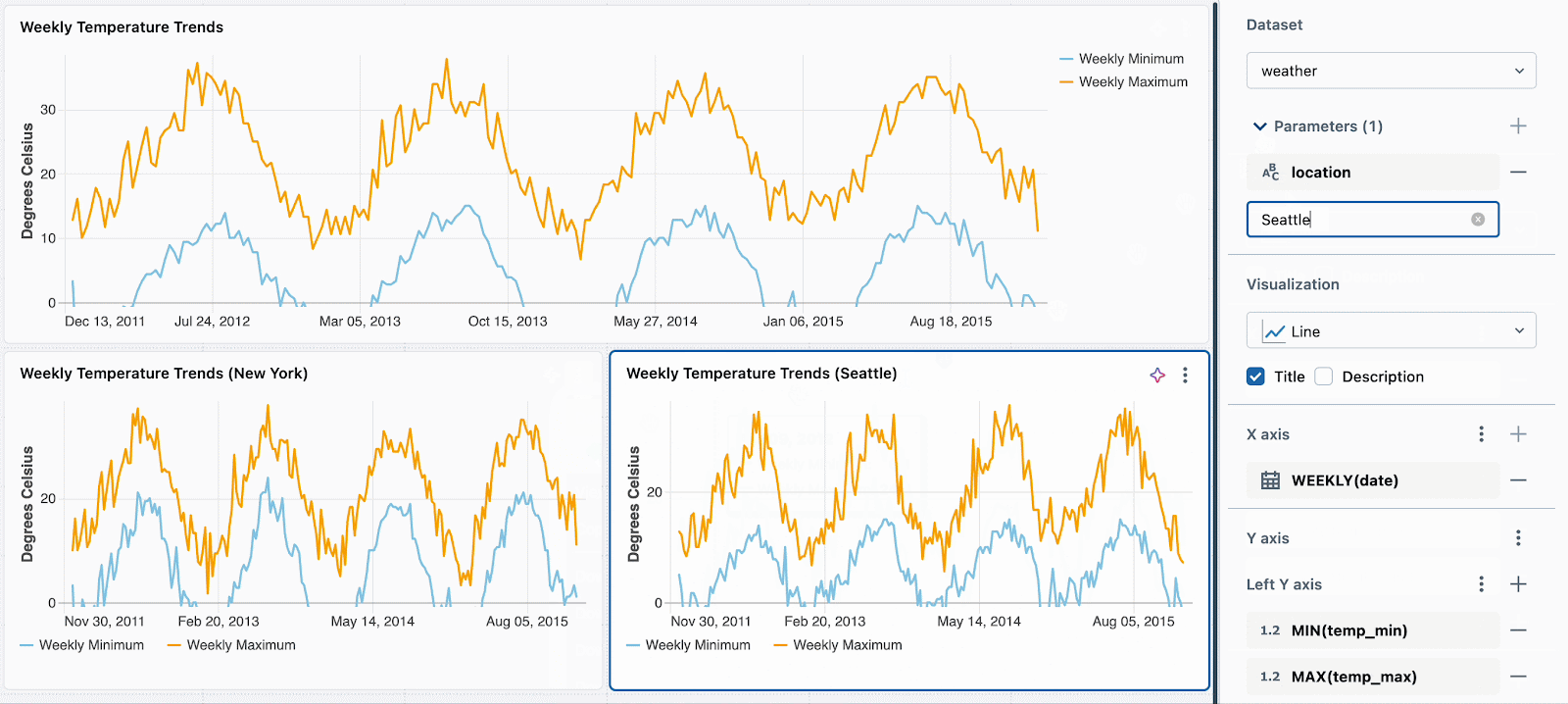
Nous travaillons à l'extension de cette fonctionnalité pour prendre en charge le filtrage par widget à l'aide de champs. Par exemple, vous pourriez filtrer chaque graphique sur le champ d'emplacement sans avoir besoin de paramétrer le jeu de données sous-jacent.
Valeurs par défaut
En tant qu'auteur de tableau de bord, vous pourriez vouloir guider les spectateurs vers une tranche de données spécifique, telle qu'une plage de dates ou un emplacement particulier.
Avec les valeurs par défaut, vous pouvez définir des valeurs de filtre spécifiques qui s'appliquent au chargement initial du tableau de bord ou lorsque les sélections sont réinitialisées. Cela garantit que les spectateurs se concentrent sur les points de données clés dès le départ. Les valeurs par défaut complètent la capacité existante de préserver les sélections de filtres de tableau de bord en partageant une URL de votre vue actuelle.
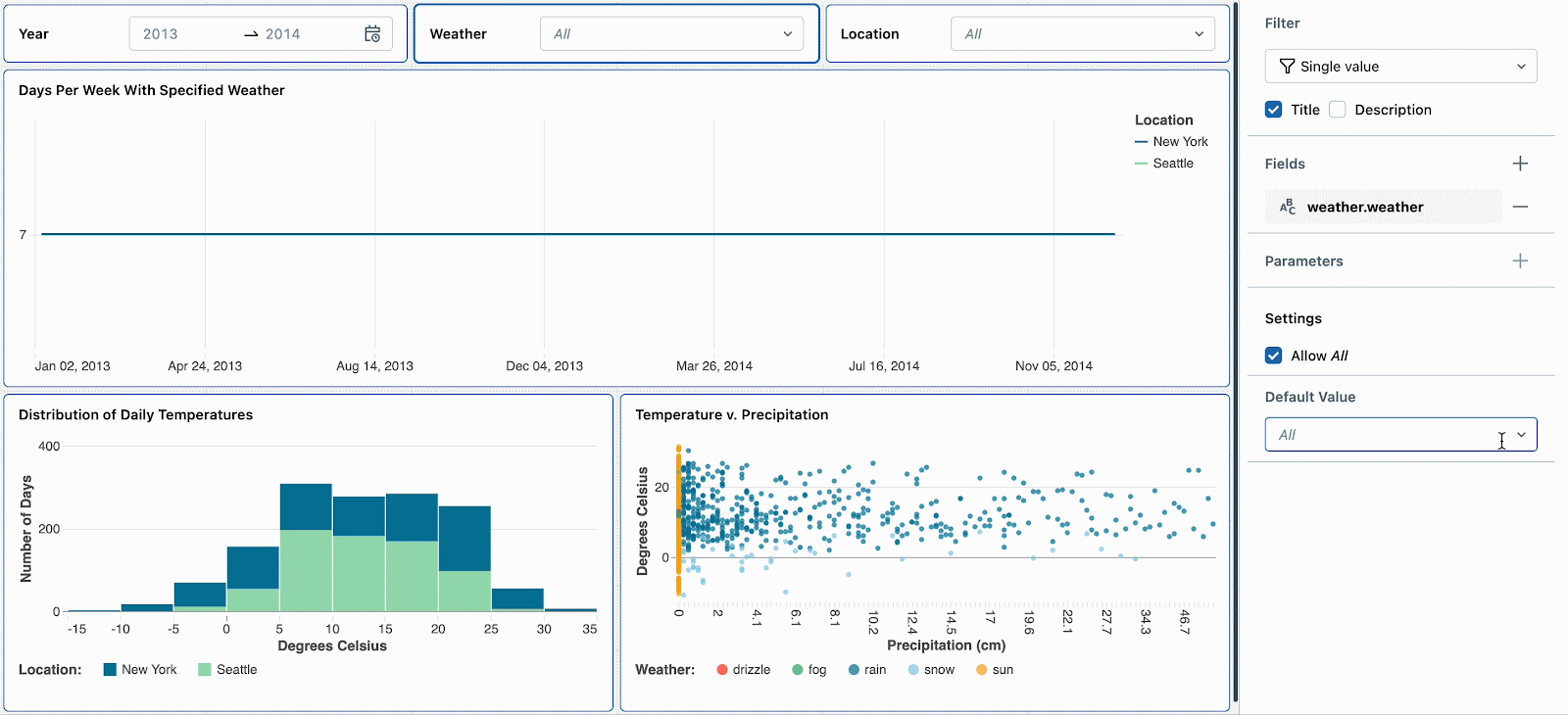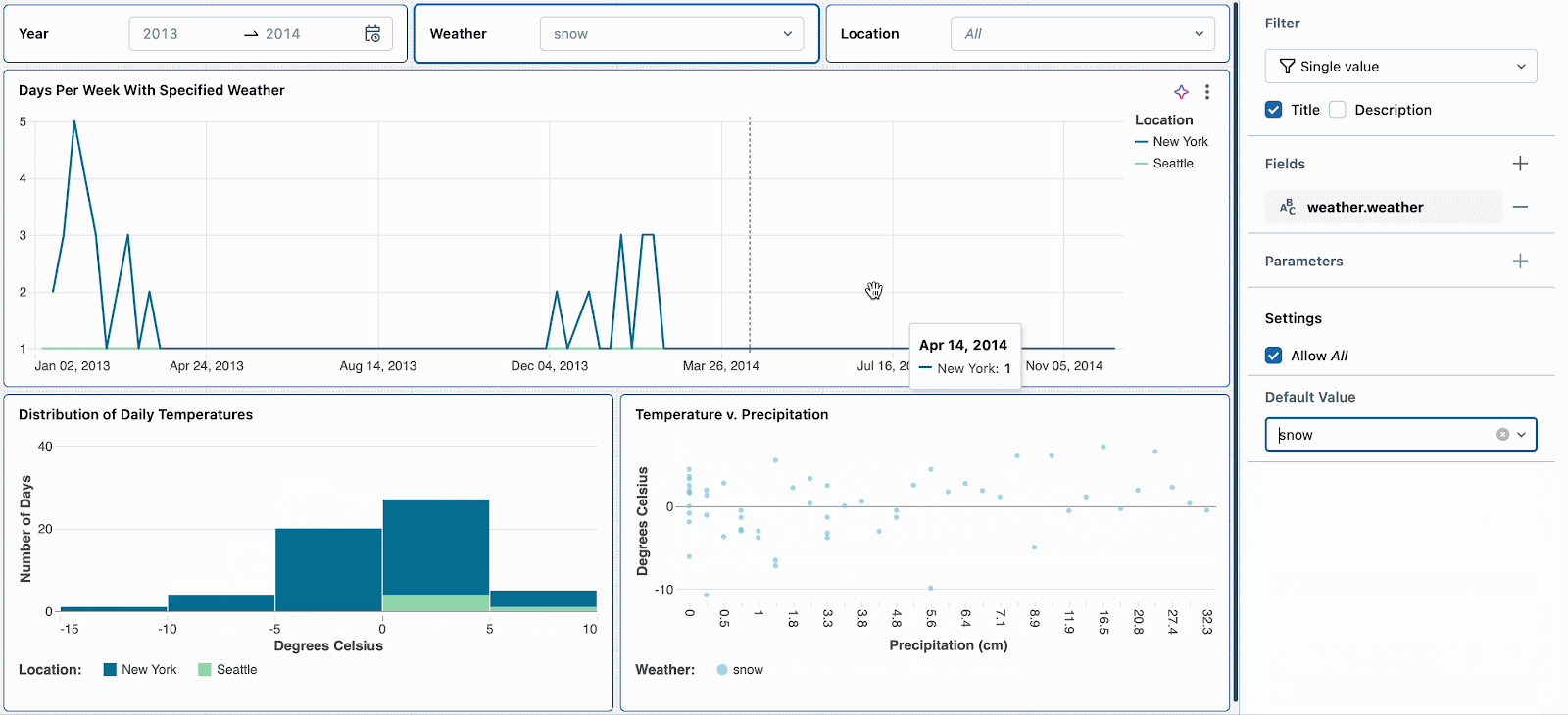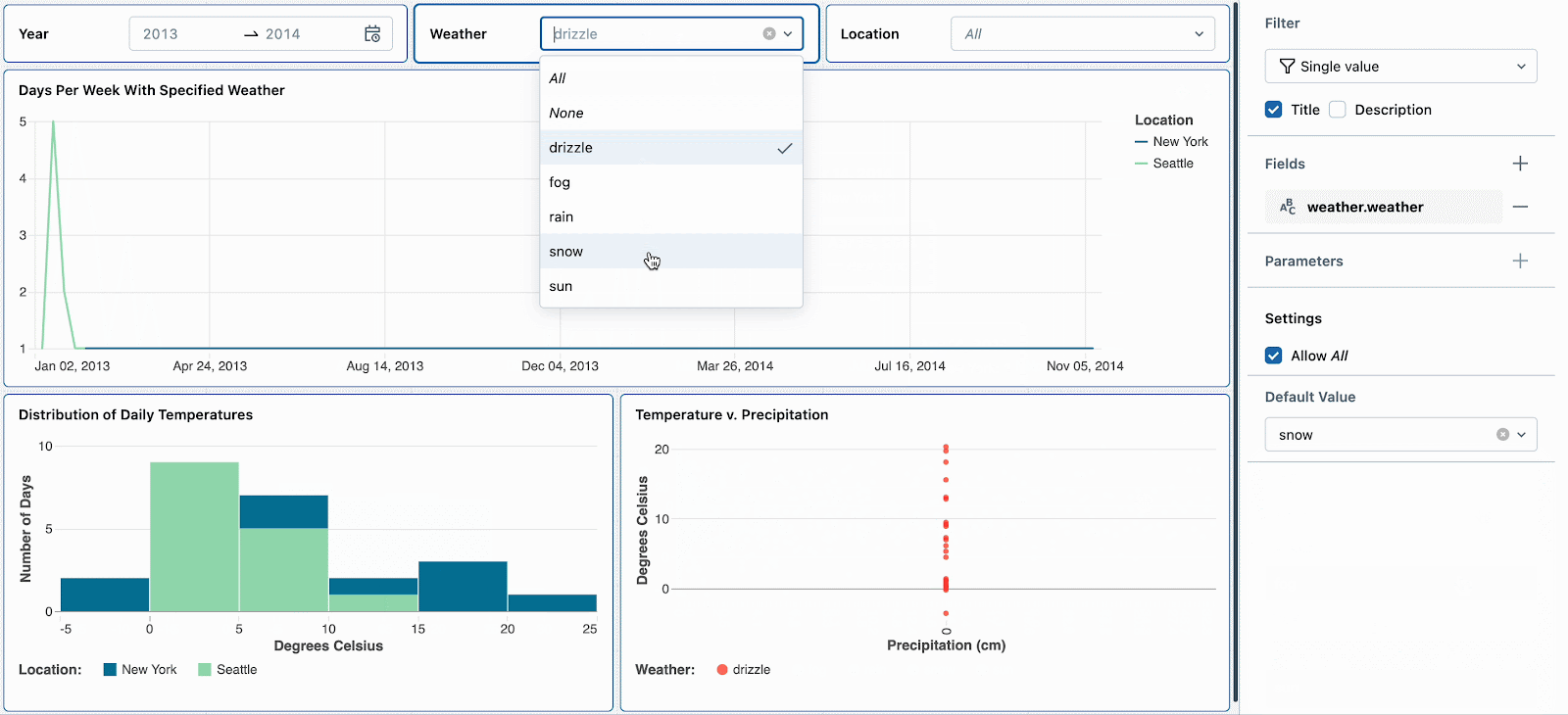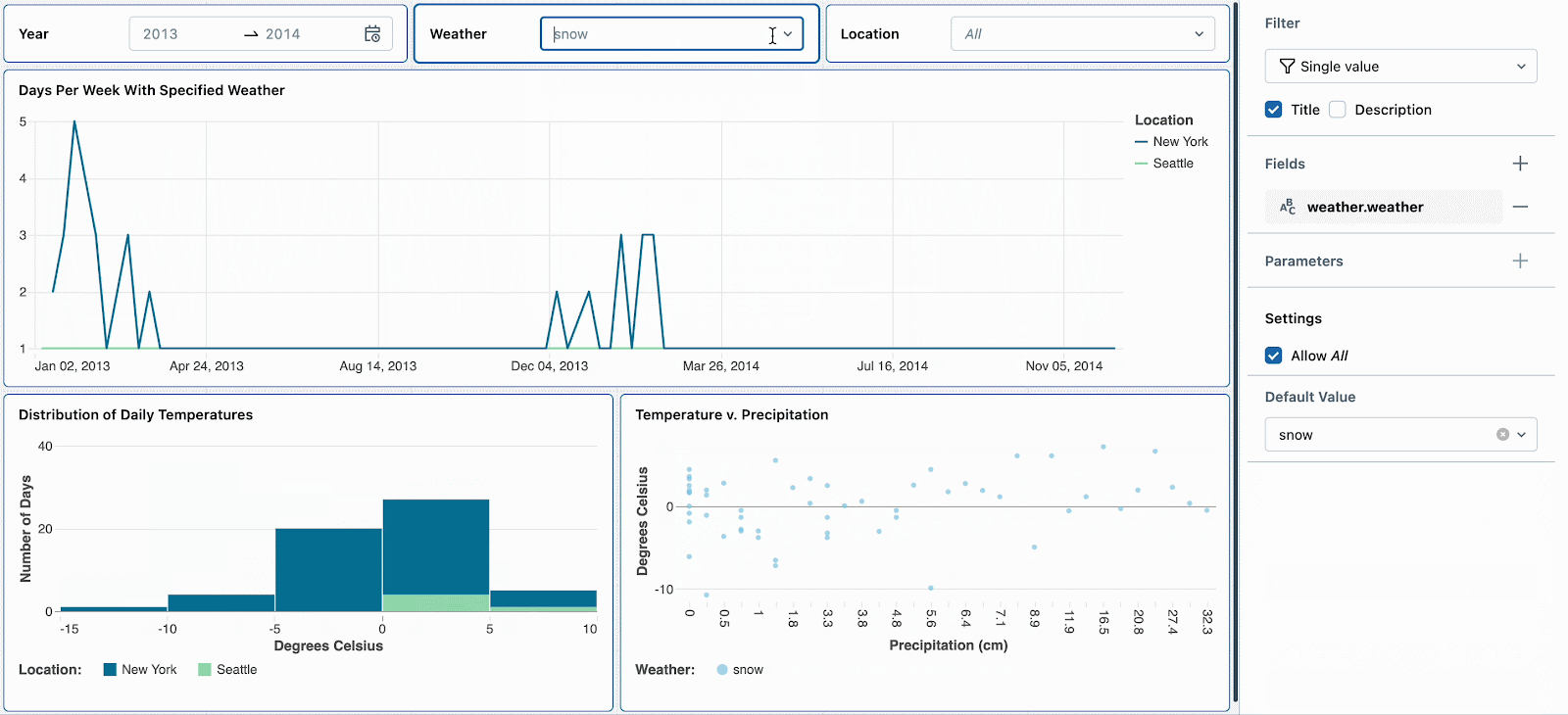
Par exemple, les jours de neige sont intéressants car ils ont des températures extrêmes et des précipitations élevées. Définir le filtre météorologique par défaut sur « neige » encouragera les nouveaux spectateurs du tableau de bord à explorer d'abord ce type de temps. Après avoir examiné d'autres tendances météorologiques, ils peuvent réinitialiser le filtre pour continuer leur analyse approfondie des jours de neige.
Performances améliorées
Pour qu'un tableau de bord interactif soit vraiment agréable, il doit être rapide. Attendre l'exécution des requêtes à chaque application de filtre peut perturber le flux de l'analyse.
Les tableaux de bord AI/BI sont optimisés pour des performances élevées, même avec de grandes quantités de données, grâce à des techniques telles que la mise en cache des requêtes et une intégration profonde de la plateforme. La mise en cache des requêtes stocke automatiquement les résultats des requêtes pendant 24 heures, garantissant des performances plus rapides en tirant parti des requêtes précédemment exécutées. Vous pouvez également pré-remplir proactivement le cache grâce à des planifications.
En plus de fournir un chargement initial rapide, les tableaux de bord AI/BI offrent une interactivité quasi instantanée pour les petits jeux de données en évaluant les filtres dans le navigateur plutôt qu'en réexécutant les requêtes �à chaque changement.
Nous avons récemment augmenté la limite d'évaluation des filtres côté client à 100 000 lignes. Cela signifie que pour les jeux de données dans cette limite, l'ensemble du jeu de données est interrogé une fois, et tous les filtrages ultérieurs sont gérés côté client, éliminant ainsi le besoin de requêtes côté serveur supplémentaires. Même avec de grandes tables, des techniques telles que la pré-agrégation avec des vues matérialisées peuvent créer des jeux de données plus petits et plus rapides à filtrer.
Nous recommandons généralement de filtrer sur des champs plutôt que sur des paramètres, qui nécessitent toujours des requêtes côté serveur. Les paramètres sont mieux adaptés aux cas que le filtrage sur les champs ne peut pas encore gérer, comme le filtrage dans les sous-requêtes ou la définition de jeux de données avec des agrégats complexes.
Nous continuons d'explorer des optimisations supplémentaires telles que l'augmentation de la limite de filtrage côté client. Les fonctionnalités à venir telles que les calculs au niveau de la visualisation augmenteront le nombre de cas d'utilisation qui peuvent être entièrement réalisés grâce au filtrage sur les champs.
Paramètres basés sur les requêtes
Les paramètres sont un outil puissant car ils peuvent être introduits n'importe où dans le SQL d'un jeu de données, offrant une flexibilité maximale lors de la définition des filtres. Bien que les paramètres soient des espaces réservés pour des littéraux en SQL, ils doivent agir comme n'importe quel autre champ, permettant aux auteurs de remplir des listes déroulantes et d'autres filtres utilisés pour configurer leurs valeurs.
En permettant le mélange de paramètres et de champs, nous avons ajouté la possibilité de remplir les filtres de paramètres avec des valeurs provenant d'autres jeux de données. Cette approche pour les valeurs de paramètres basées sur des requêtes débloque des capacités d'analyse avancées, telles que la modification dynamique des granularités de date.
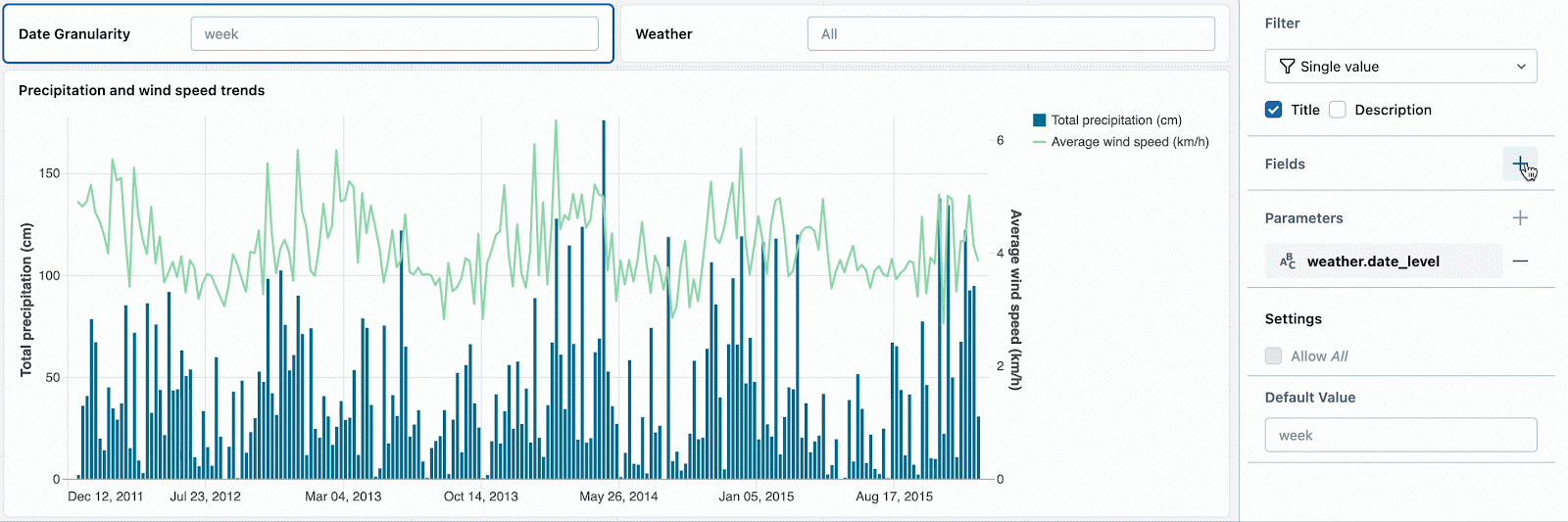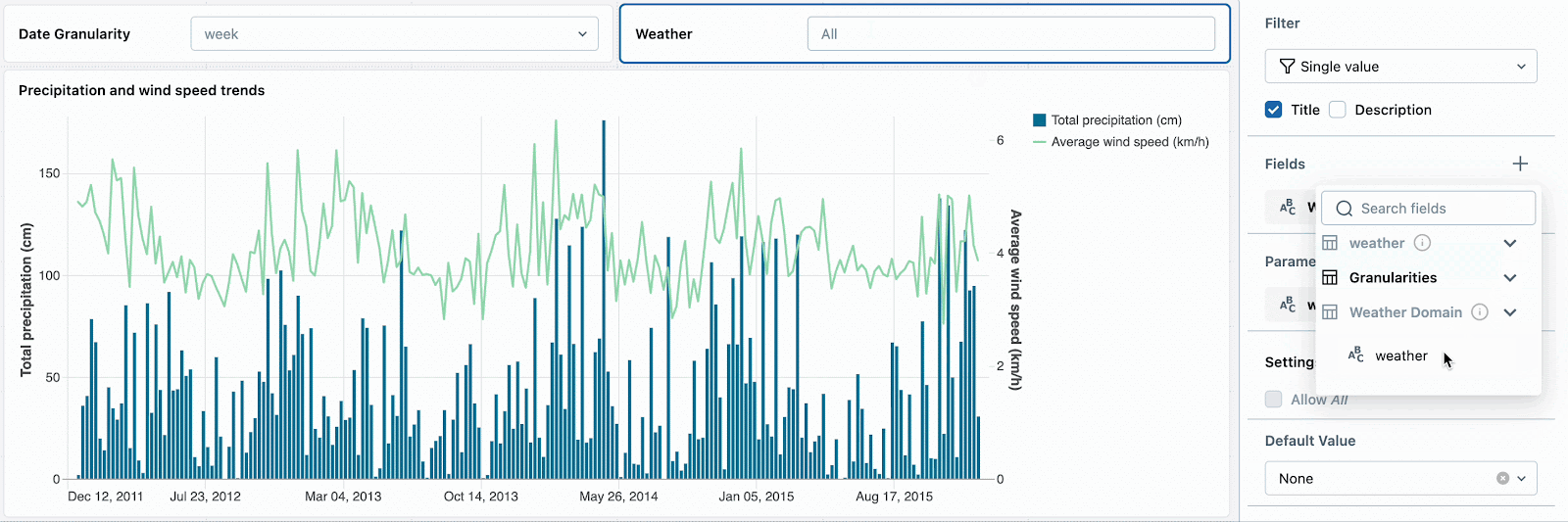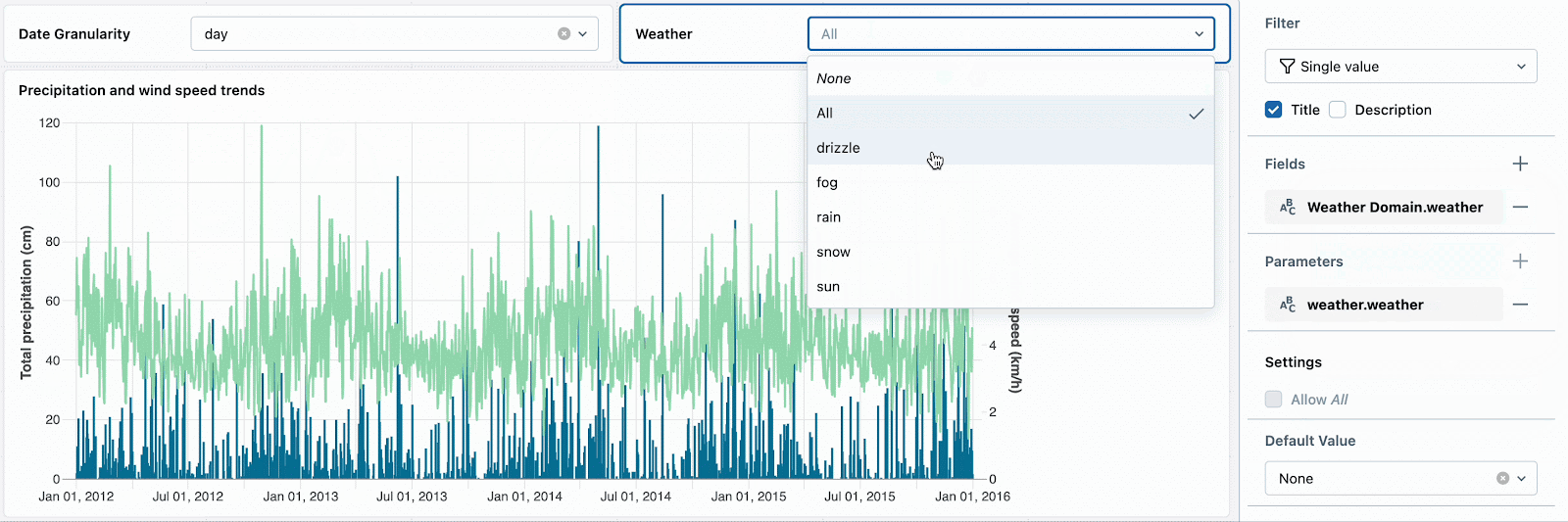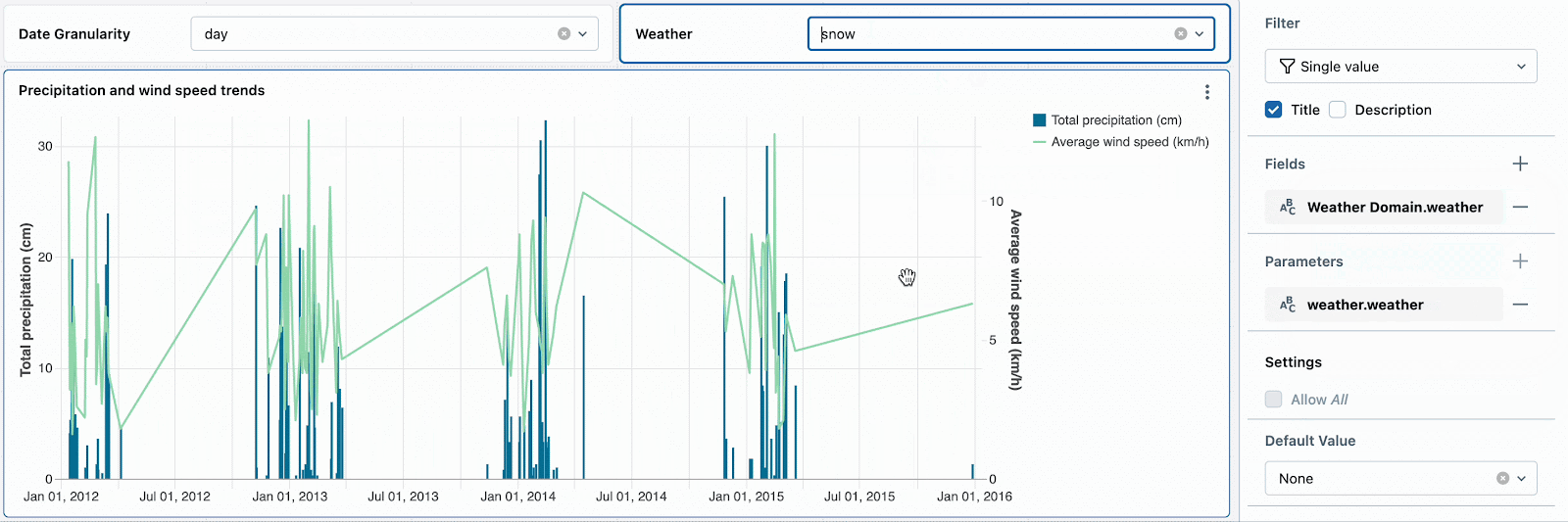
Par exemple, vous pouvez activer le forage dans différentes granularités de date en paramétrant la fonction DATE_TRUNC utilisée pour l'agrégation. Le jeu de données et les métriques résultants sont agrégés, ce qui signifie que l'ajout d'un filtre météorologique supplémentaire nécessite également de paramétrer la requête.
Les spectateurs du tableau de bord devraient pouvoir choisir facilement les valeurs valides dans leurs listes déroulantes de filtres. Par exemple, ils ne devraient pas avoir à deviner si « YEAR » ou « YEARLY » est la bonne chaîne littérale pour la troncature de date. Pour remplir correctement les listes déroulantes, créez les deux jeux de données suivants
Modifiez les filtres de paramètres de granularité de date et de météo pour référencer les champs de ces jeux de données afin de remplir les listes déroulantes et de commencer à explorer les dates.
La combinaison de champs et de paramètres dans un seul widget vous permet également d'utiliser un filtre pour contrôler plusieurs jeux de données, que ces jeux de données utilisent des paramètres ou des filtres de champs.
Nous sommes impatients de fournir encore plus de flexibilité dans le filtrage des champs et des paramètres avec des fonctionnalités à venir telles que les paramètres de plage de dates et les paramètres à valeurs multiples.
En savoir plus sur les tableaux de bord IA/BI
Comme nous l'avons démontré, les tableaux de bord IA/BI sont un domaine d'investissement important pour Databricks, l'interactivité étant un axe clé. Nous vous encourageons à explorer ces nouvelles fonctionnalités et à voir comment elles peuvent améliorer vos propres tableaux de bord. Consultez la documentation Databricks sur les tableaux de bord IA/BI Dashboards, y compris des analyses approfondies sur les paramètres et les filtres.
Vos commentaires sont précieux alors que nous continuons à affiner et à étendre nos tableaux de bord IA/BI. Nous sommes impatients d'entendre vos réflexions et suggestions !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.