Open Sourcing Unity Catalog
Création du seul catalogue universel de l'industrie pour les données et l'IA
par Matei Zaharia, Ali Ghodsi, Reynold Xin, Arsalan Tavakoli-Shiraji et Patrick Wendell
Nous sommes ravis d'annoncer que nous rendons Unity Catalog open source, le premier catalogue open source de l'industrie pour la gouvernance des données et de l'IA dans tous les clouds, formats de données et plateformes de données. Voici les piliers les plus importants de la vision Unity Catalog :
- API et implémentation open source : Il est construit sur la spécification OpenAPI et une implémentation de serveur open source sous licence Apache 2.0. Il est également compatible avec l'API metastore d'Apache Hive et l'API REST catalog d'Apache Iceberg.
- Prise en charge de plusieurs formats : Il est extensible et prend en charge Delta Lake, Apache Iceberg via UniForm, Apache Parquet, CSV et tous les formats existants.
- Prise en charge de plusieurs moteurs : Grâce à ses API ouvertes, les données cataloguées dans Unity peuvent être lues par pratiquement tous les moteurs de calcul.
- Multimodal : Il prend en charge tous vos actifs de données et d'IA, y compris les tables, les fichiers, les fonctions, les modèles d'IA.
- Écosystème dynamique : Il s'agit d'un effort communautaire et nous sommes extrêmement ravis d'être soutenus par Amazon Web Services, Microsoft Azure, Google Cloud, Nvidia, Salesforce, DuckDB, LangChain, dbt Labs, Fivetran, Confluent, Unstructured, Onehouse, Immuta, Informatica et bien d'autres.
Le projet est disponible sur GitHub dès aujourd'hui, première étape de notre parcours vers la mise à disposition de la vision Unity en open source. Unity Catalog est hébergé chez LF AI & Data, une fondation parapluie de la Linux Foundation qui soutient l'innovation open source dans l'intelligence artificielle (IA) et les données, où nous sommes ravis de travailler avec les communautés open source dans les années à venir pour réaliser cette vision.
Pourquoi open source ?
Avec l'adoption généralisée d'Unity Catalog, vous pourriez vous demander pourquoi nous le rendons open source et pourquoi maintenant. C'est parce que nous avons constamment entendu des organisations qu'elles avaient besoin d'une base ouverte pour leurs applications de données et d'IA, non seulement pour aujourd'hui, mais pour les innovations des décennies à venir.
Malheureusement, la plupart des plateformes de données actuelles sont des jardins clos. De nombreux entrepôts de données cloud utilisent des "tables natives" qui ne sont pas dans des formats ouverts. D'autres plateformes exigent des clients qu'ils paient pour un calcul toujours actif, même lors de la lecture de données à partir de moteurs externes. Et de nombreuses plateformes restreignent les formats de données et les clients qu'elles prennent en charge.
Il en résulte des données cloisonnées et une gouvernance fragmentée entre les actifs. Et sans une interface multimodale pour les données tabulaires, sans parler des actifs d'IA, les organisations doivent assembler plusieurs solutions disjointes. Databricks a déjà pris une position forte dans l'industrie en étant la seule plateforme majeure où toutes les tables sont par défaut dans des formats ouverts, et en ouvrant les tables Delta aux clients Iceberg avec UniForm l'année dernière. En rendant Unity Catalog open source, nous donnons aux organisations une base ouverte pour leurs charges de travail actuelles et futures.
Pourquoi un catalogue de données et d'IA multimodal ?
À l'ère des avancées rapides de l'IA, toutes les entreprises ont réalisé qu'elles devront gouverner conjointement les données et les actifs d'IA – qu'il s'agisse de gérer des données non structurées pour des systèmes d'IA complexes ou de construire un catalogue d'outils pour des applications LLM agentiques. Chez Databricks, nous avons rapidement identifié ce besoin d'une infrastructure de données et d'IA intégrée, et avons lancé Unity Catalog il y a trois ans pour réunir ces deux mondes dans un modèle de gouvernance cohérent. Aujourd'hui, nous constatons que des milliers de clients bénéficient de la gouvernance unifiée, notamment :
- Un espace de noms unique pour organiser et partager des tables, des données non structurées et des actifs d'IA
- Journaux d'audit centralisés de toutes les activités de données et d'IA
- Lignage unifié à travers les charges de travail de données et d'IA
- Collaboration inter-organisations via le protocole open source Delta Sharing.
Nos dernières innovations en IA, telles que le concept de catalogues d'outils pour les agents d'IA générative, sont également conçues pour s'intégrer dans ce modèle de gouvernance unifiée.
Version 0.1 d'Unity Catalog
Aujourd'hui, nous publions la version 0.1 d'Unity Catalog open source. Bien que certaines de nos API et fonctionnalités soient encore en évolution, cette version présente plusieurs capacités importantes d'Unity Catalog :
- Les tables, les volumes (données non structurées) et les outils/fonctions d'IA peuvent être gérés ensemble.
- Les tables peuvent être dans plusieurs formats, y compris Delta Lake, Iceberg via UniForm, Parquet, CSV et JSON.
- Unity Catalog implémente l'API Iceberg REST Catalog pour l'accès depuis l'écosystème du moteur Iceberg, en s'appuyant sur l'expertise de Tabular.
- L'API prend en charge la distribution de jetons d'authentification pour contrôler l'accès des clients au stockage cloud sous-jacent pour les tables et les volumes, centralisant ainsi la gouvernance dans le serveur de catalogue.
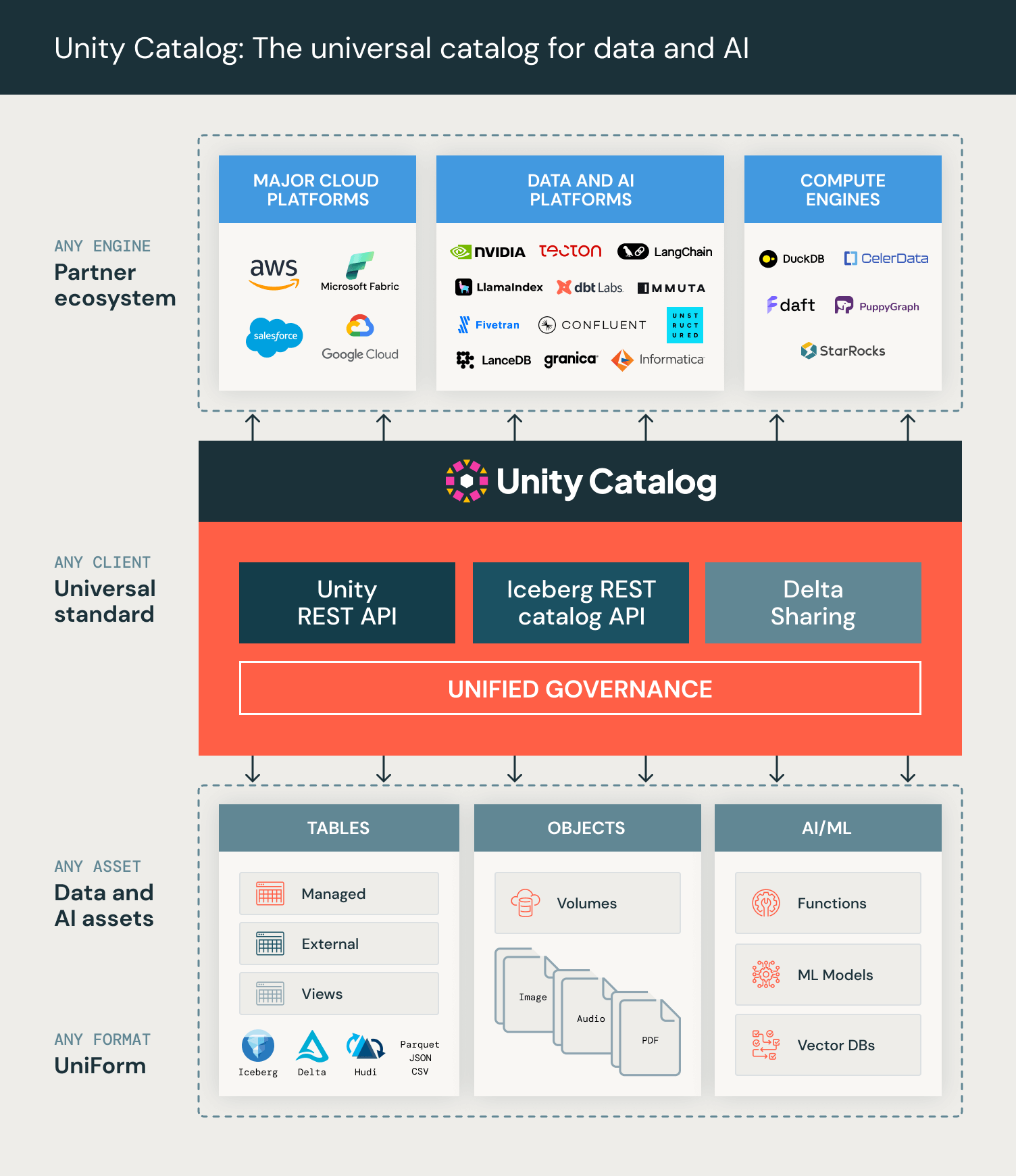
Ce que cela signifie pour les clients Databricks
Si vous êtes déjà client Databricks, vous n'avez rien à changer. Les déploiements Unity Catalog existants des clients implémentent les mêmes API ouvertes, permettant aux clients externes de lire toutes les tables (y compris les tables gérées et externes), les volumes et les fonctions dans Unity Catalog hébergé dès le premier jour, avec vos contrôles d'accès existants en place. Ce changement signifie simplement qu'un écosystème plus large de clients fonctionnera avec votre catalogue existant.
Les API REST Unity permettent à nos partenaires et à la communauté open source de créer des intégrations puissantes qui permettront aux clients de travailler sur leurs tables, leurs données non structurées et leurs outils/fonctions d'IA à partir de diverses applications, sans frais d'accès externes.
"AT&T s'engage à rendre nos données interopérables avec nos plateformes. Avec l'annonce de la mise en open source d'Unity Catalog, nous sommes encouragés par l'initiative de Databricks pour rendre la gouvernance du lakehouse et la gestion des métadonnées possibles grâce à des normes ouvertes. La flexibilité d'utiliser des outils interopérables avec nos actifs de données et d'IA, avec une gouvernance cohérente, est au cœur de la stratégie de la plateforme de données d'AT&T."
— Matt Dugan, Vice President Data Platforms, AT&T
![]()
"Nasdaq est fier d'utiliser Unity Catalog de Databricks dans le cadre de notre stratégie globale de gestion des données. La décision de Databricks de rendre Unity Catalog open source fournit une solution qui aide à éliminer les silos de données, et nous sommes impatients de continuer à faire évoluer notre plateforme, d'améliorer notre gouvernance et de moderniser nos applications de données tout en continuant à servir nos clients."
— Lenny Rosenfeld, Vice President, Capital Access Platforms, Nasdaq
![]()
"Chez Rivian, l'adoption de la plateforme Databricks nous a permis d'utiliser les données et l'IA dans la construction de nos EAV de nouvelle génération. Nous sommes enthousiasmés par la mise en open source d'Unity Catalog par Databricks et la publication d'API ouvertes pour apporter l'interopérabilité à travers notre paysage de données sans aucune crainte de dépendance vis-à-vis d'un fournisseur. Combiné à la prise en charge de tous nos actifs de données – données structurées et non structurées, modèles ML et outils d'IA générative – ce fut une décision facile de standardiser sur Unity Catalog."
— Jason Shiverick, Director of AI Platforms, Rivian
![]()
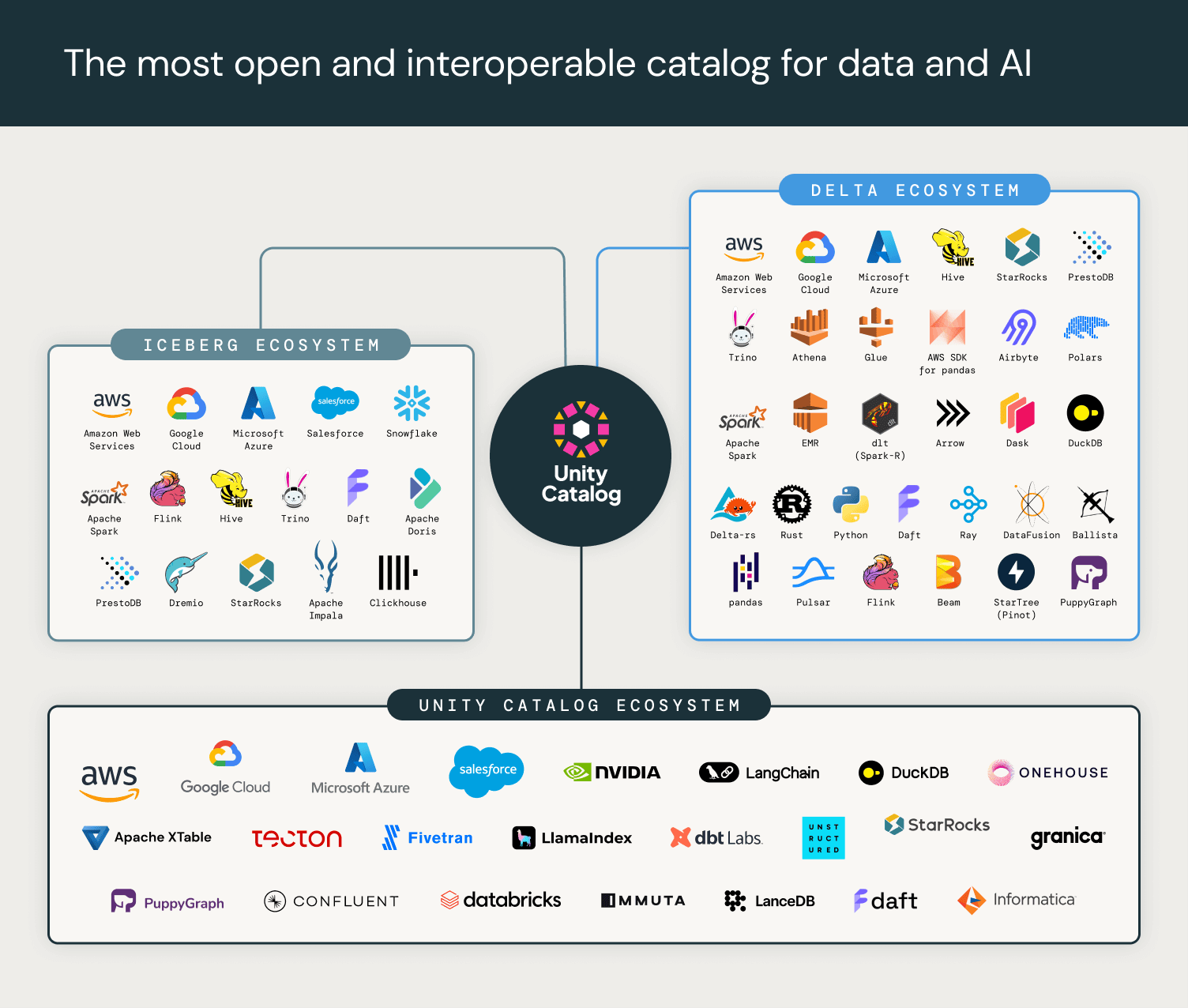
Écosystème open source
Nous sommes ravis de nous associer aux principaux fournisseurs de cloud, plateformes de données et d'IA, et moteurs de calcul pour faire progresser la norme Unity Catalog dans les mois à venir. Ils comprennent des éditeurs de logiciels de premier plan et des projets open source dans les domaines de l'IA, de l'analyse de données, des données non structurées et de la gouvernance, qui pourront facilement se connecter aux serveurs open source Unity Catalog et à Databricks.
"AWS se félicite de la décision de Databricks de rendre Unity Catalog open source. AWS s'engage à travailler avec l'industrie sur des solutions open source qui offrent choix et interopérabilité aux clients."
— Chris Grusz, Managing Director of Technology Partnerships, AWS
![]()
"Microsoft s'engage auprès de la communauté open source et donne aux clients le pouvoir de choisir. Databricks est un partenaire stratégique depuis des années et il est formidable de voir qu'ils rendent Unity Catalog open source. Nous pensons que des normes véritablement ouvertes avec une large participation de l'industrie sont dans le meilleur intérêt des clients. Notre collaboration avec Databricks continue d'élever Microsoft Azure comme le meilleur choix pour les charges de travail de données et d'IA."
— Jessica Hawk, CVP Data, AI and Digital Applications, Microsoft
![]()
"Google s'engage à proposer des solutions ouvertes et flexibles qui permettent aux clients de maximiser la valeur de leurs données. La stratégie de Databricks visant à ouvrir la norme Unity Catalog pour les données et l'IA s'aligne très bien avec notre stratégie."
— Ritika Suri, Director, Data and AI Technology Partnerships, Google Cloud
![]()
Feuille de route
Ceci n'est que le point de départ du projet open source Unity Catalog. Unity Catalog sert des milliers de clients en production et est le fruit d'années d'ingénierie. Nous portons donc cette fonctionnalité au projet open source par étapes, en priorisant l'accès et l'interopérabilité des clients pour commencer.
Dans les mois à venir, nous ajouterons une prise en charge améliorée des API essentielles à vos charges de travail de données et d'IA, notamment :
- API d'écriture de tables indépendantes du format
- Vues
- Delta Sharing
- Modèles (avec intégration MLflow)
- Fonctions distantes
- API de contrôle d'accès
- Et plus encore
Commencez dès aujourd'hui
Vous pouvez rejoindre la communauté open source Unity Catalog sur unitycatalog.io. Pour les clients Databricks, restez à l'écoute pour l'écosystème en évolution rapide d'outils de données et d'IA s'intégrant à Unity Catalog.
"Salesforce Data Cloud est construit à partir de zéro sur des standards ouverts avec Apache Parquet et Apache Iceberg. Nos innovations en matière de copie zéro permettent aux clients de débloquer des données, d'en tirer des insights et d'orchestrer des actions sur le Customer 360. L'adoption par Databricks d'Apache Iceberg via UniForm et Unity Catalog répond aux défis clés d'interopérabilité entre Delta Lake et Iceberg. Nous sommes ravis d'avoir Databricks comme membre de notre réseau de partenaires Zero Copy et nous nous réjouissons des innovations conjointes avec le nouveau Unity Catalog open source, offrant une valeur client convaincante dans les données structurées, les données non structurées et les modèles d'IA."
— Ravi Loganathan, Vice-président exécutif de l'ingénierie logicielle, Salesforce
![]()
"Les données d'entreprise sont essentielles au développement d'applications d'IA générative précises. NVIDIA travaille en étroite collaboration avec notre écosystème de partenaires pour soutenir les offres open source comme Unity Catalog, qui peut aider les clients à organiser des pipelines de développement efficaces et puissants."
— Pat Lee, VP des partenariats stratégiques d'entreprise, NVIDIA
![]()
"Delta Kernel a grandement simplifié la création de l'extension DuckDB Delta, permettant un accès facile à Delta Lake depuis DuckDB. Nous sommes ravis de nous associer à Databricks sur Delta Kernel et le standard ouvert Unity Catalog pour les données et l'IA. Cette collaboration représente une étape importante dans l'innovation open source et le développement de data lakehouses ouverts."
— Hannes Mühleisen, PDG, DuckDB Labs
![]()
"La décision de Databricks d'ouvrir Unity Catalog est une évolution passionnante pour la communauté des données et de l'IA. Nous sommes ravis de nous associer à Databricks pour intégrer Unity Catalog à LangChain, ce qui permet à nos utilisateurs communs de créer des agents avancés en utilisant les fonctions de Unity Catalog comme outils."
— Harrison Chase, PDG et fondateur, LangChain
![]()
"Unstructured est la solution ETL de données non structurées leader pour les LLM, aidant les organisations à transformer leurs données de brutes à prêtes pour le RAG. Notre intégration avec Unity Catalog a parfaitement de sens, car nous brisons les silos de données et accélérons le développement IA/ML dans les entreprises. Nous sommes ravis de nous associer à Databricks pour développer ce standard ouvert pour les cas d'utilisation de l'IA et pour standardiser les métadonnées des données non structurées, aidant nos clients à opérer à la pointe de l'IA."
— Brian Raymond, PDG et fondateur, UnstructuredIO
![]()
"Chez Eventual, nous avons construit Daft, le moteur de requête distribué open source leader pour les données multimodales. Nous pensons que l'unification du calcul pour les données tabulaires et non structurées ne suffit pas et qu'un catalogue multimodal est crucial pour construire des data lakehouses GenAI. Nous sommes ravis de nous associer à Databricks et à d'autres innovateurs de l'IA pour développer le standard ouvert Unity Catalog pour les charges de travail modernes de données+IA."
— Sammy Sidhu, PDG et fondateur, Eventual Computing
![]()
"Chez Granica, nous prônons la démocratisation des données et la liberté de ne pas être lié à un fournisseur. Notre technologie Safe Room assure la confidentialité, la confiance et la sécurité dans les flux de travail d'IA générative tout en prenant en charge les standards ouverts comme Unity Catalog, Delta Lake et Apache Iceberg. L'architecture neutre de Unity Catalog et ses solutions de gouvernance robustes s'alignent sur notre vision de fournir aux clients flexibilité et contrôle sur leurs données. Nous sommes ravis de contribuer à cet écosystème ouvert, moteur d'innovation et permettant aux clients de travailler de manière transparente avec leurs données sur les meilleures plateformes."
— Rahul Ponnala, PDG et co-fondateur, Granica
![]()
"L'ouverture de Unity Catalog est une étape cruciale vers un écosystème de données plus collaboratif et innovant. En rendant cette technologie accessible, Databricks favorise un environnement où toute la communauté peut contribuer et bénéficier de capacités de gouvernance et de gestion de données améliorées. Cette démarche s'aligne sur notre vision chez Onehouse et Apache XTable (Incubating) de soutenir l'interopérabilité des formats ouverts qui stimule le progrès et l'innovation pour tous."
— Vinoth Chandar, PDG et co-fondateur, Onehouse
![]()
"La mission de Confluent est de mettre les données en mouvement et de permettre aux organisations de les exploiter partout. Nous sommes ravis de voir Databricks apporter une contribution significative à un écosystème de données ouvert avec l'open sourcing de Unity Catalog. Tableflow sur Confluent Cloud permettra une livraison facile de données en temps réel vers des destinations comme un data lake en transformant les flux de données en tables Iceberg en un seul clic. En combinant nos capacités de streaming leaders de l'industrie avec les solutions robustes de gestion de données de Databricks, les clients pourront exploiter leurs données plus efficacement que jamais."
— Shaun Clowes, CPO, Confluent
![]()
"Ensemble, Databricks et dbt Cloud aident les utilisateurs à briser les silos de données pour collaborer efficacement, simplifier l'ETL pour réduire le TCO avec Delta Lake, et unifier la gouvernance avec Unity Catalog. Nous sommes ravis d'annoncer notre prise en charge de Unity Catalog et des API ouvertes. Ce partenariat souligne notre engagement à fournir une expérience de données unifiée, permettant à notre communauté d'obtenir des insights plus approfondis et de stimuler l'innovation."
— Mark Porter, CTO dbt Labs
![]()
"Nous sommes ravis de voir Databricks rendre Unity Catalog open source en tant que standard ouvert pour les données et l'IA. Cette démarche offrira à nos clients plus de choix et de flexibilité dans leur écosystème de données, assurant une intégration transparente et maximisant l'interopérabilité avec la plateforme Fivetran lors de l'ingestion de données critiques vers Databricks."
— Anjan Kundavaram, CPO, Fivetran
![]()
"L'exposition des modèles d'accès natifs au sein de Unity Catalog a transformé la manière dont notre entreprise est capable de rationaliser l'accès aux données et d'appliquer des règles de gouvernance à grande échelle, sans impact sur les performances. L'investissement continu de Databricks dans une communauté pour accélérer les services visant à faciliter la création de contrôles de données permet à nos clients de gouverner plus facilement et de gérer le volume massif de nouveaux consommateurs de données intégrés à l'ère de l'IA."
— Matthew Carroll, PDG, Immuta
![]()
"Nous sommes ravis de l'opportunité pour nos clients communs alors que Databricks rend Unity Catalog open source en tant que standard ouvert pour les données et l'IA. Avec Unity Catalog et l'Informatica Intelligent Data Management Cloud, les clients peuvent gagner en choix, en flexibilité et en interopérabilité dans leurs écosystèmes de données."
— Brett Roscoe, GM et SVP Cloud Data Governance et Cloud Operations, Informatica
![]()
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.