PDFs vers la production : Annonce d'une intelligence documentaire de pointe sur Databricks
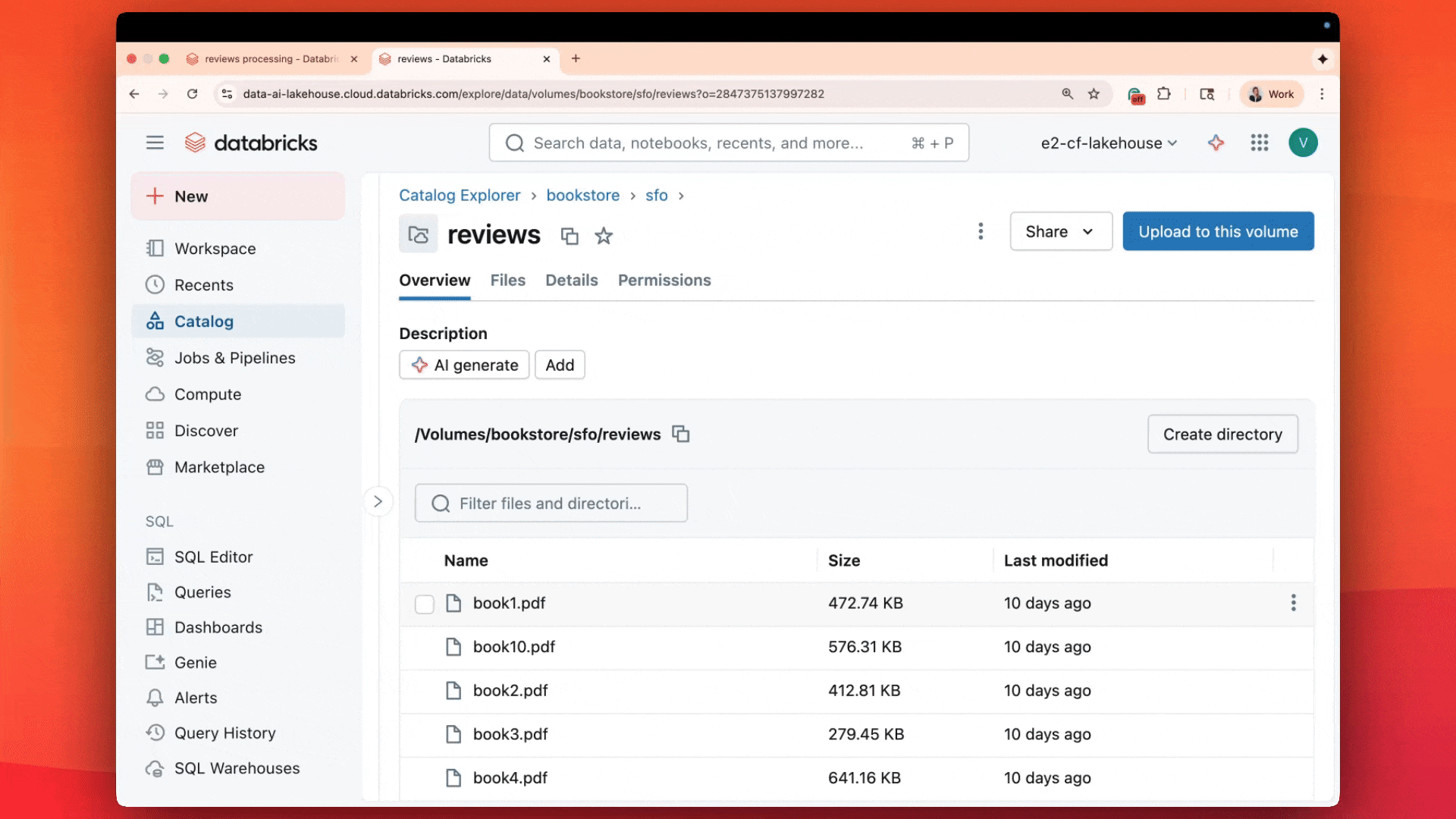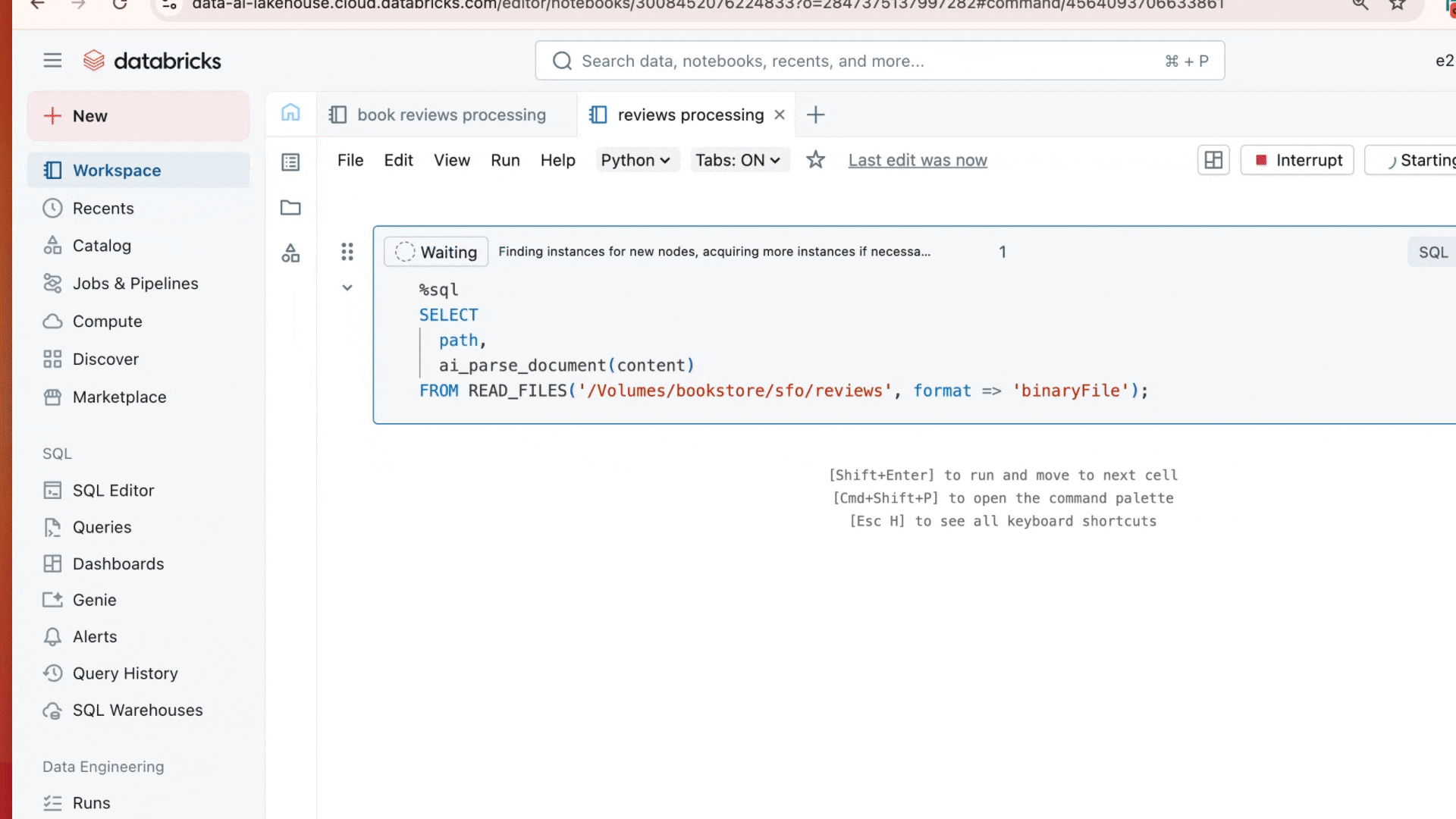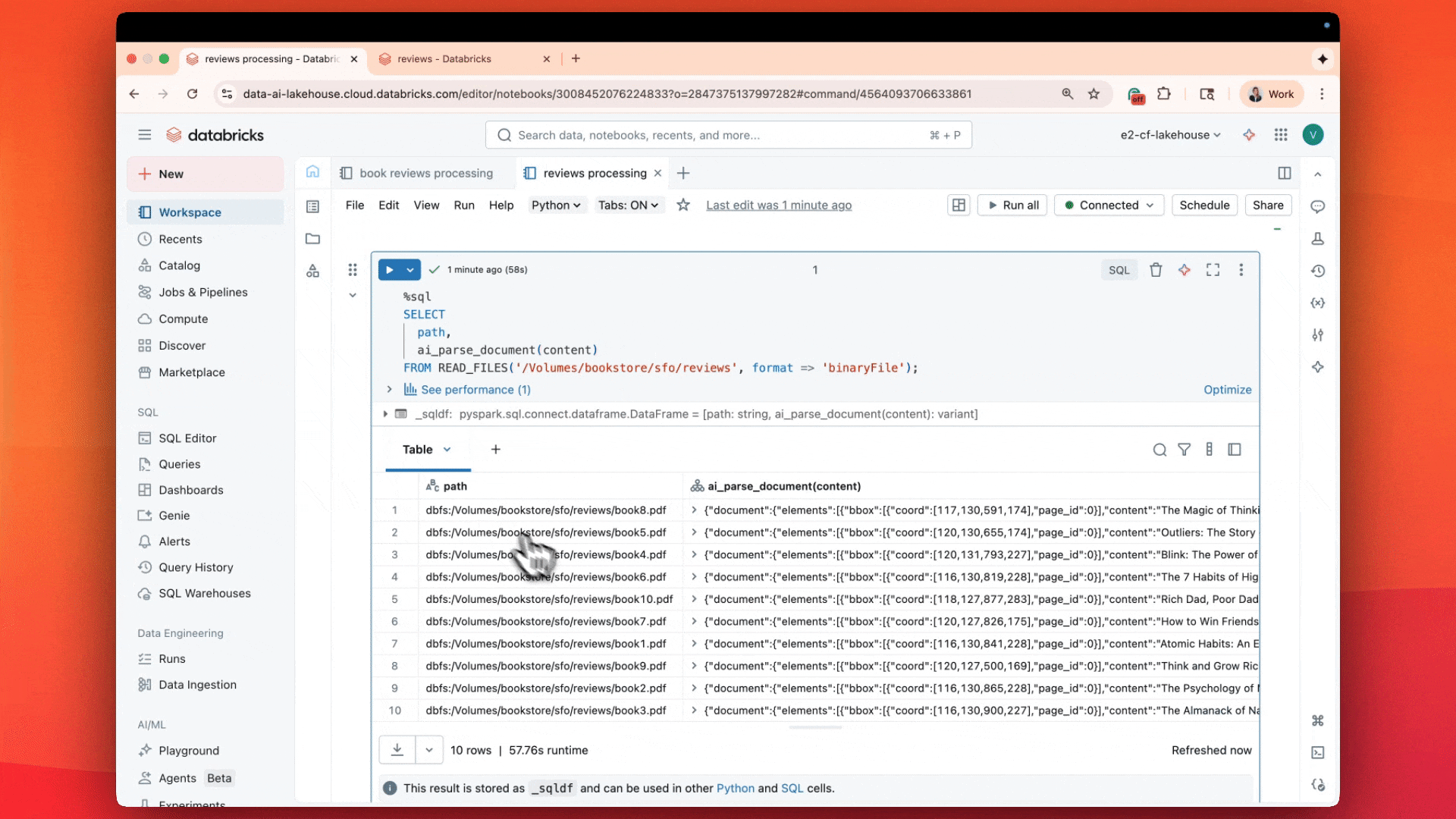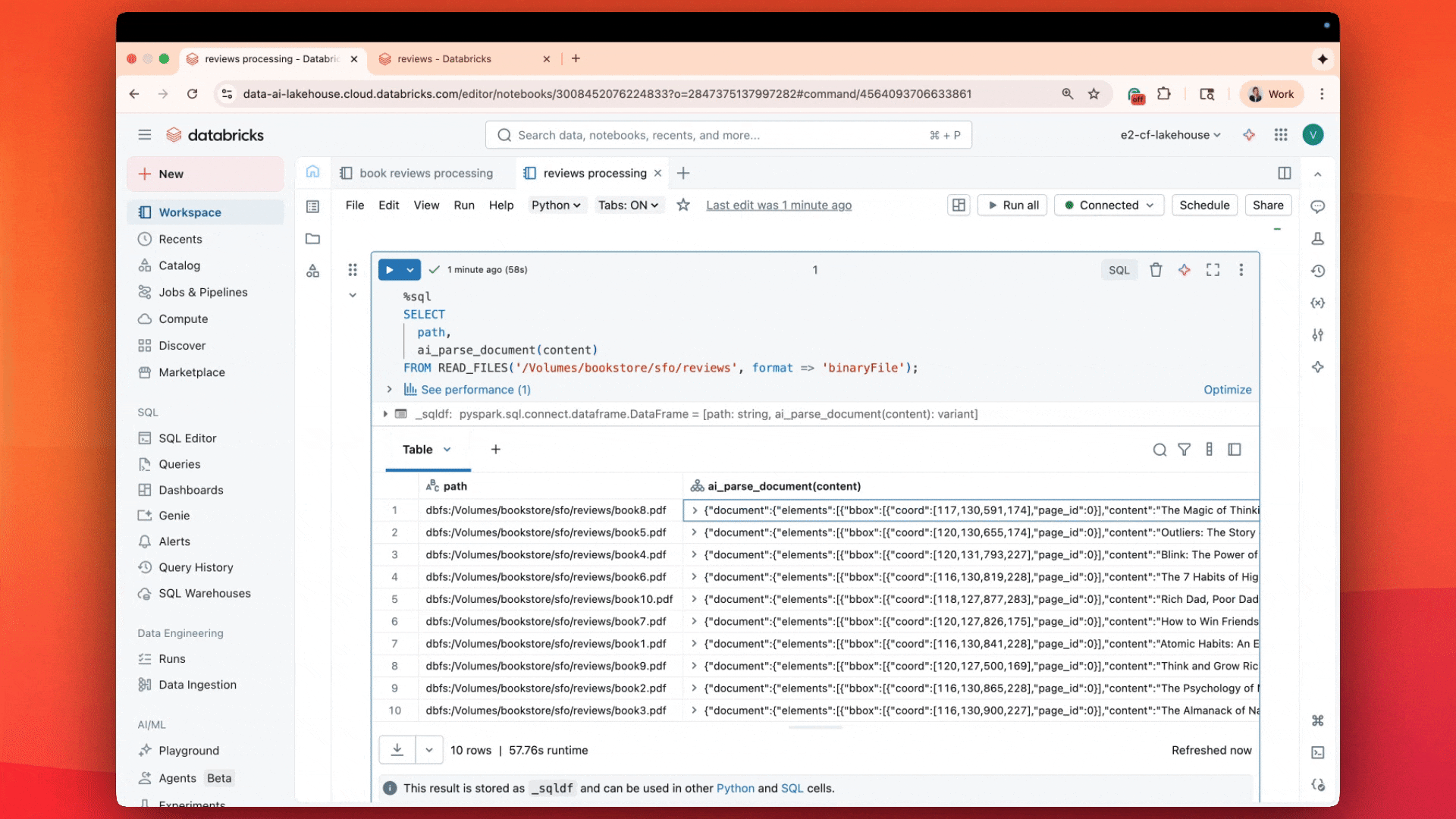
Avec ai_parse_document, analysez et comprenez les PDF directement en SQL avec une qualité de premier plan à un coût 3 à 5 fois inférieur
- Aujourd'hui, nous introduisons le dernier ajout à Agent Bricks : ai_parse_document (Aperçu public) : propulsé par le système d'agents de notre équipe de recherche pour la compréhension multimodale à grande échelle.
- Débloquez 80 % de vos données d'entreprise grâce au traitement intelligent de documents de pointe : Traitez des millions de documents complexes — tableaux, figures, diagrammes — avec la puissance de la recherche fondamentale en IA dans une seule fonction SQL.
- Qualité et coût de premier plan : Nous avons développé un système d'intelligence documentaire dont la qualité est compétitive par rapport aux meilleures offres concurrentes, mais à un coût 3 à 5 fois inférieur.
- Intégration complète de la plateforme : Traitement incrémental automatique avec Spark Declarative Pipelines, gouvernance avec Unity Catalog, et utilisation transparente dans Agent Bricks, AI Search et AIBI.
Durant la Semaine des Agents, nous étendons Agent Bricks, la plateforme Databricks pour la création d'agents d'IA gouvernés et prêts pour la production, qui raisonnent avec précision sur vos données. L'un des plus grands défis auxquels les entreprises sont confrontées lors de la mise à l'échelle des agents est l'accès aux données non structurées. Près de 80 % des connaissances d'une entreprise sont piégées dans des PDF, des rapports et des diagrammes que les agents ne peuvent pas lire, comprendre ou sur lesquels ils ne peuvent pas raisonner. Ces documents contiennent un contexte essentiel, pourtant la plupart des agents d'IA ne pouvaient pas les lire — jusqu'à maintenant.
Les outils d'analyse existants s'arrêtent à l'extraction de texte. Ils omettent les mises en page, les éléments visuels et les relations qui véhiculent du sens dans les documents réels. Les équipes passent des mois à écrire du code personnalisé fragile qui échoue toujours sur des données du monde réel. ai_parse_document élimine cette complexité. Il apporte une compréhension complète des documents directement dans la plateforme Databricks Data Intelligence, donnant à chaque agent accès à la pleine fidélité de votre contexte métier — avec précision, sécurité et à l'échelle.
Avec une seule commande SQL, les organisations peuvent transformer des documents en données structurées, gouvernées et interrogeables:
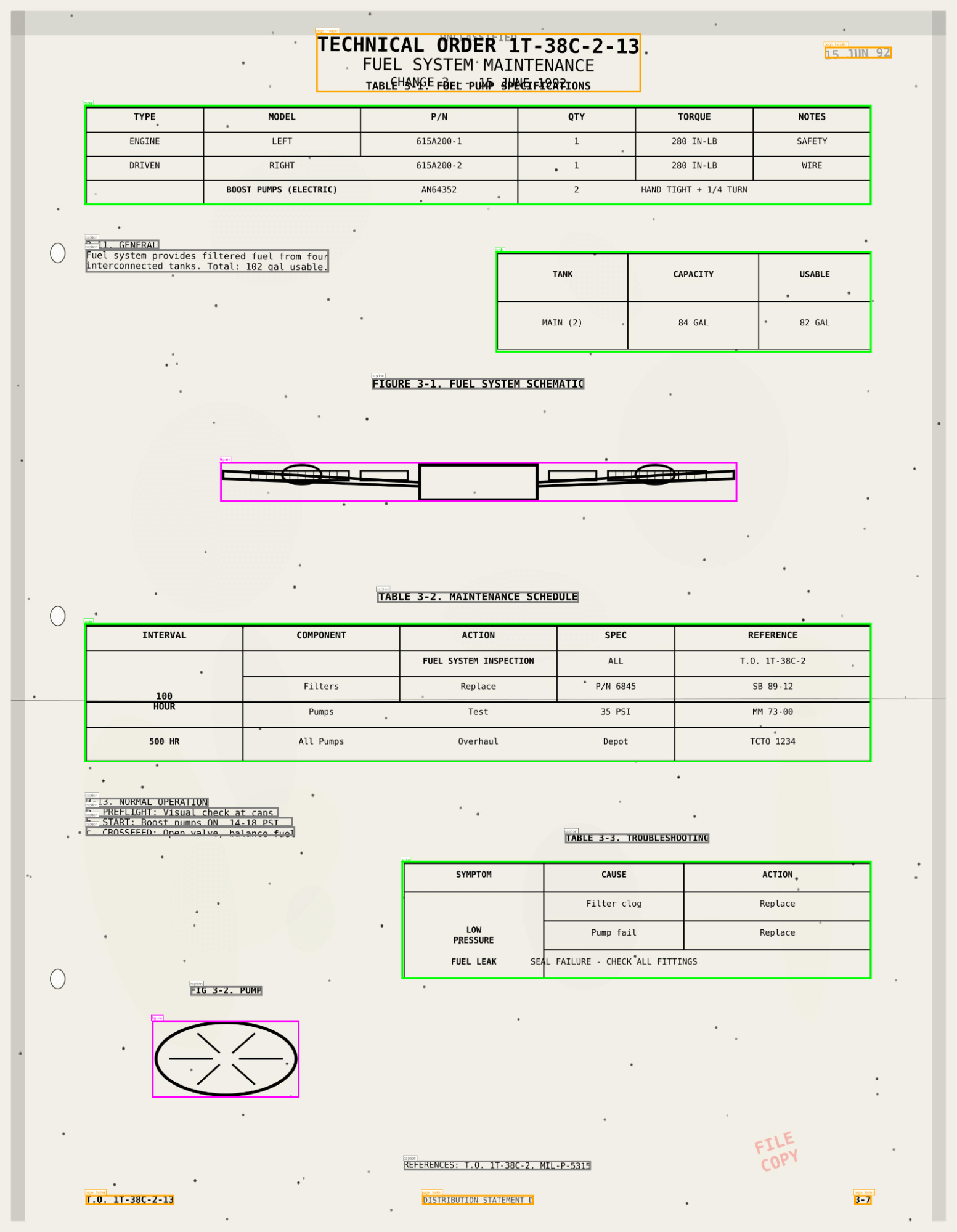
Le résultat n'est pas seulement le texte du PDF, mais aussi des informations sur la mise en page, des tableaux analysés, des boîtes englobantes, des figures et des images avec leurs légendes — une description complète du document, sous forme d'informations structurées.
« ai_parse_document de Databricks réduit la surcharge de configuration, permettant aux data scientists de passer moins de temps sur la configuration et plus de temps à faire progresser des solutions complexes axées sur le client. »—Meiling He, Sr. Data Science Manager, Rockwell Automation
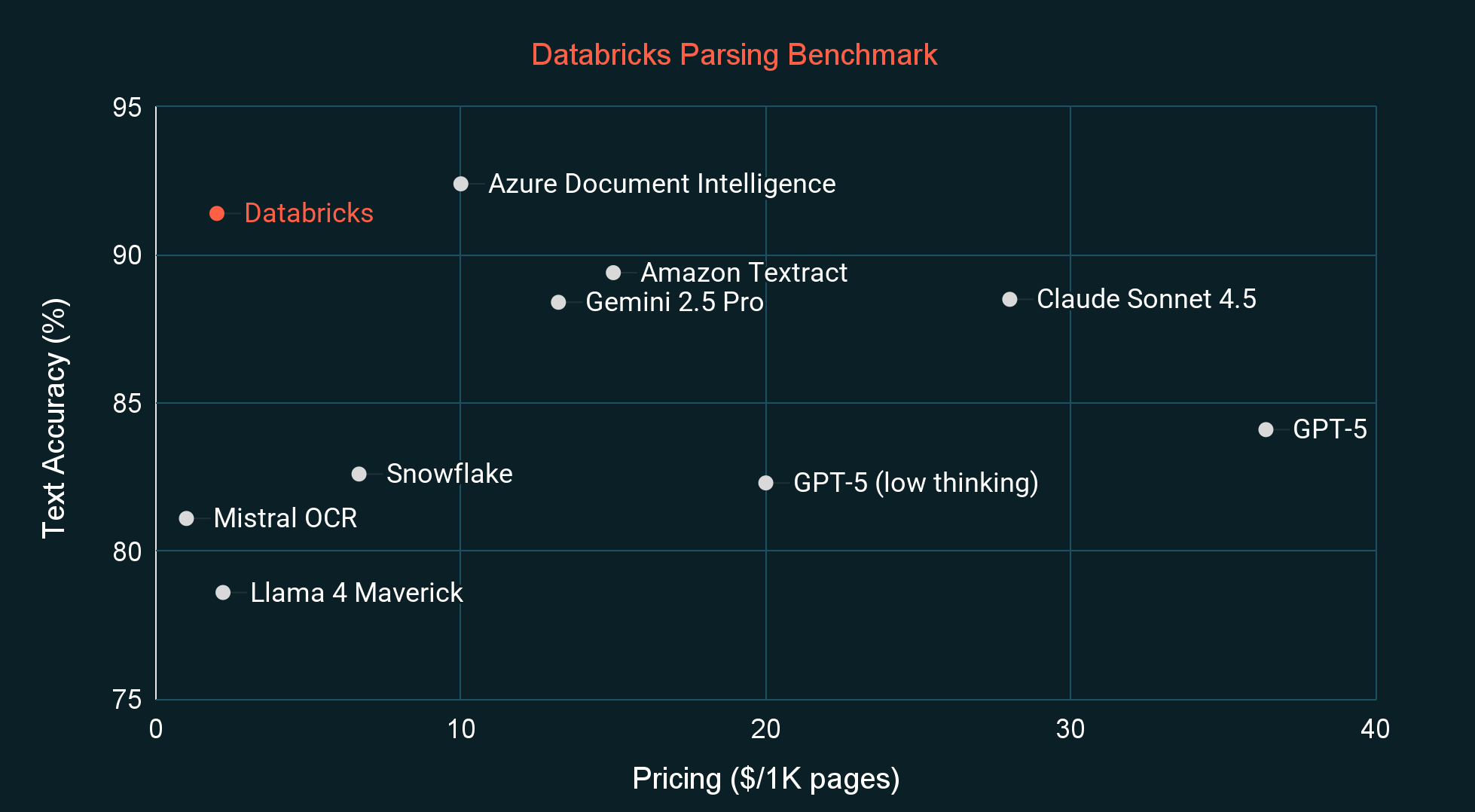
Meilleur rapport Prix-Performance
Lorsqu'il est comparé à d'autres systèmes d'analyse de pointe et modèles de langage visuel (VLM), ai_parse_document offre la meilleure qualité pour sa catégorie de prix, mesurée à la fois par un benchmark externe courant (OmniOCR) et par notre benchmark interne privé (voir les figures ci-dessous). Le benchmark interne est plus aligné sur la distribution des documents que nous avons observés chez les clients et il est également peu probable qu'il fasse partie des données d'entraînement de tout modèle. Dans les semaines à venir, nous publierons également nos nouvelles étiquettes OmniOCR, qui corrigent certaines erreurs d'étiquetage et introduisent des boîtes englobantes et des informations hiérarchiques.

Comment ça marche
ai_parse_document extrait les tableaux, les figures et les diagrammes avec des descriptions générées par l'IA et des métadonnées spatiales, en stockant les résultats dans Unity Catalog. Vos documents se comportent désormais comme des tableaux, interrogeables via AI Search et exploitables dans les flux de travail Agent Bricks.
« L'extraction de tableaux, de textes et de métadonnées à partir de PDF ou d'images était auparavant un processus complexe nécessitant beaucoup de code. Databricks l'a condensé en une seule fonction SQL, ai_parse_document, simplifiant radicalement le traitement des données non structurées à grande échelle et le mettant entre les mains de chaque équipe de données, pas seulement des data scientists. »—Rajesh Balakrishnan, Principal Data Scientist, TE Connectivity
Avec une seule instruction SQL, les clients traitent déjà des millions de documents en parallèle :
Chaque résultat comprend :
- Les tableaux sont conservés tels quels, y compris les cellules fusionnées et les structures imbriquées.
- Les figures et diagrammes sont décrits automatiquement avec des légendes générées par l'IA.
- Métadonnées spatiales et zones englobantes pour les citations et la validation.
- Sorties d'images optionnelles stockées dans les volumes Unity Catalog pour la recherche multimodale ou la visualisation.
Comme tout reste dans Databricks, vous conservez une gouvernance, une lignée et une observabilité cohérentes.
Remplacez votre pile d'analyseurs externes par une seule fonction SQL qui fonctionne comme toute autre opération Databricks. Alors que les équipes exportent généralement des documents vers des services OCR, des API de détection de mise en page et des outils de légende de figures,ai_parse_document les traite sans quitter votre environnement Databricks :
—Hunter Johnson, Lead Data Scientist, Emerson Electric Co.
De l'analyse à l'action avec Agent Bricks
Une fois analysées, les données des documents circulent naturellement dans le reste de l'écosystème Agent Bricks:
- AI Search indexe chaque élément pour des applications RAG multimodales qui comprennent le texte et les visuels.
- Agents Déclaratifs optimisent l'extraction, la classification et la synthèse avec le langage naturel pour obtenir un meilleur débit et des coûts réduits
- AI Functions extraient des entités, classifient du contenu et résument du texte, le tout avec SQL.
- Supervisor Agent coordonne les agents d'analyse de documents avec d'autres agents spécialisés, permettant des flux de travail complexes et multi-étapes.
- Tableaux de bord IA/BI et Spark Declarative Pipelines utilisent les mêmes données analysées pour l'analytique et le traitement continu.
Ensemble, ces capacités font des données non structurées une partie entièrement intégrée de la plateforme Agent Bricks.
Conçu pour l'échelle et la fiabilité en production
De nombreuses entreprises disposent de millions de documents non structurés à analyser, certaines en reçoivent même des millions par jour. Il est essentiel de disposer d'une solution capable de traiter ces données de manière fiable et évolutive sans y consacrer des jours. Databricks intègre ai_parse_document avec Spark Declarative Pipelines, offrant un traitement automatique et incrémental des documents à grande échelle. Lorsque de nouveaux documents arrivent, que ce soit depuis SharePoint, S3 ou ADLS, ils sont analysés automatiquement. Lakeflow gère les nouvelles tentatives, le checkpointing et la mise à l'échelle, vous n'avez donc jamais besoin de retraiter des données existantes ou d'écrire du code d'orchestration personnalisé.
Tout est géré via Unity Catalog, vous permettant de gérer les autorisations, d'auditer l'accès et de suivre la lignée du contenu analysé, tout comme vous le faites pour les données structurées.
Débloquez les données non structurées avec Agent Bricks
ai_parse_document est le dernier ajout aux Fonctions IA Agent Bricks, rejoignant des capacités telles que ai_extract, ai_classify, ai_summarize et ai_query. Ensemble, ces fonctions permettent à chaque équipe de raisonner sur toutes les données de l'entreprise directement dans la plateforme Databricks. En combinant l'intelligence documentaire avec la gouvernance, l'observabilité et l'orchestration intégrées, Databricks permet aux entreprises de créer des agents IA qui comprennent véritablement leur contexte métier et agissent en toute confiance.
Prêt à exploiter la valeur de vos données non structurées ?
- Lisez la documentation pour commencer à utiliser ai_parse_document dès aujourd'hui
Auteurs de la recherche (contribution égale) : Ziyi Yang, Jasmine Collins, Adyasha Maharana, Cory Stephenson, Erich Elsen, Adam Gurary, Ethan Tang
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.