PipelineIQ : une intelligence commerciale prospective qui suscite l'action
Comment nous utilisons l'IA pour améliorer les opérations de vente en éliminant le bruit et en se concentrant sur l'action
par Sam Le Corre, Dael Williamson et Luis Herrera
- Passe de la prévision à l'action prescriptive : PipelineIQ est une solution d'IA qui va au-delà des prévisions rétrospectives traditionnelles (qui échouent souvent en raison de données désordonnées) en fournissant des « prochaines meilleures actions » (NBA) immédiates, prospectives et prescriptives pour les commerciaux et les managers.
- Conçu pour des données CRM imparfaites : Il est conçu pour fonctionner avec la réalité de données CRM incomplètes et incohérentes, en extrayant des signaux prospectifs tels que la force du champion et les blocages d'approvisionnement, et en ajustant son score de confiance plutôt qu'en échouant lorsque des données sont manquantes.
- Fournit des résultats clairs : Il simplifie la gestion du pipeline en trois recommandations claires pour chaque opportunité : Walk (dé-prioriser), Pivot (changer de stratégie) ou Accelerate (accélérer), chacune avec une justification claire et un plan d'action spécifique au rôle.
Résumé
Les données de ventes et de gestion de la relation client (CRM) sont désordonnées. Pendant des décennies, nous avons tenté de forcer l'assainissement des données de ventes dans le système d'enregistrement (par exemple, Salesforce), mais les données restent désordonnées. Dans un monde de CRM basé sur la consommation, le problème des données CRM désordonnées représente une lourde charge administrative (>20 % de productivité), impactant considérablement la prévisibilité des prévisions (et des revenus).
PipelineIQ transforme les données CRM désordonnées en actions claires : quels contrats abandonner, lesquels pivoter et lesquels accélérer. Contrairement aux prévisions traditionnelles qui regardent en arrière et supposent des données propres, PipelineIQ utilise l'IA pour extraire des signaux prospectifs de votre pipeline réel — champs incomplets, mises à jour retardées, et tout le reste — puis indique à votre équipe exactement quoi faire ensuite.
PipelineIQ est une histoire de Databricks sur Databricks. Notre organisation de vente sur le terrain a été confrontée au même défi de gestion de pipeline que toute équipe de vente B2B connaît : des heures passées à examiner manuellement des données CRM incomplètes, incohérentes et rétrospectives. Nous avons donc construit PipelineIQ sur Databricks – en utilisant les API de modèles fondamentaux, Unity Catalog, Delta Lake et les tableaux de bord IA/BI – pour transformer nos propres données de pipeline de ventes désordonnées en un moteur d'action prospectif qui élimine le bruit. Nous avons construit quelque chose pour aider les gens à rester concentrés et permettre aux responsables des ventes de diagnostiquer les problèmes de ventes afin d'optimiser l'exécution. Cet article explique comment nous avons appliqué l'IA en pratique, et pas seulement pourquoi vous devriez l'utiliser.
Pourquoi la plupart des articles sur "l'IA dans les ventes" manquent le coche
La plupart des contenus sur l'IA dans les ventes promettent des "informations" vagues ou des "décisions basées sur les données". Ils abordent également tout avec une philosophie axée sur la rétrospective : basé sur ce qui s'est passé, que pourrait-il se passer ? Inversez cela et vous obtenez des analyses prescriptives : basé sur ce que nous savons maintenant, que devrions-nous faire ensuite ?
Nous parlerons de pourquoi nous nous sommes concentrés sur l'action et le risque plutôt que sur les prévisions. Comment nous avons utilisé les forces naturelles de l'IA à notre avantage. Se concentrer sur les questions est la clé pour construire une solution. Affiner vos invites est essentiel pour une action significative.
La vélocité était la clé. Le garder simple et construire, plutôt qu'acheter, était le secret. Cette approche nous permet de construire un outil qui respecte le fonctionnement réel de votre entreprise, et pas seulement la façon dont votre fournisseur de logiciel CRM dit qu'il devrait fonctionner.
Pourquoi n'avons-nous pas construit une autre solution de prévision ?
De nombreuses solutions d'IA dans le domaine des ventes vendent le rêve de prévisions parfaites ou le rendent accessible à tous. C'est généralement absurde pour plusieurs raisons. Elles omettent d'expliquer pourquoi c'est difficile. Ce n'est pas un article sur les prévisions, nous expliquerons donc pourquoi nous avons adopté une approche différente.
Alors, pourquoi les solutions de prévision échouent-elles généralement ? Franchement ? Parce que la prévision est une science, et personne n'a le temps pour ça. Voici deux considérations clés que vous devez soit bien faire, soit prendre en compte pour garantir une prévision efficace.
Les données historiques semblent complètes car la vente est déjà terminée
Votre modèle de prévision utilise des données historiques propres et complètes et suppose que les transactions actives apparaissent de la même manière. Ce n'est pas le cas. Les transactions gagnantes ont tous les champs remplis parce qu'elles devaient l'être ; le processus de vente est terminé, les formalités administratives sont faites, le parcours est documenté. Mais les transactions en cours ? Les commerciaux remplissent le CRM quand ils ont le temps ou quand ils y sont obligés lors des revues de pipeline. Les champs restent vides avec une note mentale de "je le ferai plus tard". Des informations critiques (telles que les dates des prochaines étapes, les contacts clés et les informations sur la concurrence) sont manquantes ou obsolètes de plusieurs semaines.
Les prévisions traditionnelles supposent que vous pouvez reconstruire le parcours de vente à partir de ce qui se trouve dans votre CRM aujourd'hui. En réalité, à moins que vous n'ayez capturé des données complètes chaque jour (ce que vous n'avez pas fait), vous construisez des modèles sur des instantanés incomplets. Votre prévision ne prédit pas l'avenir, elle devine sur la base de la fiction.
Les prévisions nécessitent un modèle de travail du système qu'elles essaient de prédire
Dans les ventes, le 'système' est plus ou moins le monde entier.
Même avec des données complètes, les prévisions échouent lorsque votre modèle ne peut pas capturer la réalité. Vous devez modéliser vos humains : les étapes mises à jour chaque semaine, pas chaque jour, les commerciaux qui minimisent ou exagèrent leurs performances, et le problème de la boucle de rétroaction, où si une prévision prédit une baisse, une armée de personnes se précipite pour la "corriger", invalidant ainsi la prédiction. C'est fou et compliqué.
Vous devez modéliser votre entreprise : les gammes de produits, les méthodes de vente, les définitions d'étapes, les hiérarchies organisationnelles et la dynamique d'équipe créent de la complexité. Vous devez choisir la bonne échelle : quotidienne, hebdomadaire, mensuelle, trimestrielle ? Par division, gamme de produits, région ou unité commerciale ? Chaque dimension multiplie la difficulté.
Enfin, vous devez modéliser le marché, qui est souvent perturbé par des pandémies, des cyberattaques et des pannes d'infrastructure qui peuvent réécrire les règles du jour au lendemain.
Tout cela correctement ? C'est une équipe de science des données à temps plein. La plupart des organisations de vente n'en ont pas, et celles qui en ont sont déjà très occupées.
Trois principes qui différencient PipelineIQ des prévisions traditionnelles
Action plutôt qu'analyse. Fini les "informations intéressantes" qui nécessitent une traduction. PipelineIQ fournit des actions optimales en une ligne pour les commerciaux et les managers — exécutables immédiatement.
Signaux prospectifs plutôt qu'historique. Au lieu de projeter les taux de clôture passés, PipelineIQ extrait ce qui change actuellement : la force du champion qui évolue, le blocage des achats, et l'accélération du multithreading.
Conçu pour des données imparfaites. Lorsque les champs sont manquants ou que les signaux sont contradictoires, PipelineIQ ne plante pas — il ajuste les scores de confiance et vous indique où se situent les lacunes.
Présentation de PipelineIQ
Qu'est-ce que c'est ?
PipelineIQ est une solution d'IA que nous avons construite par-dessus les données brutes de notre CRM. Elle analyse nos opportunités et transforme les signaux prospectifs en actions immédiates. Au lieu de prévoir ce qui pourrait se conclure en fonction de l'historique, elle vous dit quoi faire aujourd'hui pour améliorer ce qui se conclura demain. Elle est conçue pour la réalité des opérations de vente : données imparfaites, conditions changeantes et équipes qui ont besoin de priorités.
Qu'avons-nous fait différemment ?
PipelineIQ apporte l'analyse prescriptive au pipeline de ventes B2B SaaS, transformant les signaux de votre CRM en recommandations quotidiennes basées sur les données qui aident les équipes de compte à avancer plus rapidement et les managers à coacher plus intelligemment. En prescrivant ce que chaque rôle doit faire ensuite, et en expliquant pourquoi, elle fournit la couche d'exécution manquante dans les ventes B2B SaaS.
Nous n'avons pas essayé de construire un modèle parfait du monde. Au lieu de cela, nous avons exploité ce pour quoi les LLM sont naturellement doués : synthétiser des informations incomplètes, repérer des modèles dans des données désordonnées et transformer ces modèles en recommandations claires.
Donnez à un LLM une question ciblée, comme "Ce contrat est-il à risque ?" et il peut combiner les journaux d'activité, les champs manquants, le ton des e-mails et l'engagement des parties prenantes pour produire une réponse raisonnée, même lorsque la moitié des données sont manquantes. Le modèle peut juger quand il devine et quand il est confiant. Il résume, compare et s'adapte en temps réel à mesure que de nouvelles informations arrivent.
Voici un exemple concret. Notre scoreur de confiance transmet les champs CRM de chaque cas d'utilisation (notes BDR, liste des parties prenantes, informations sur la concurrence, nombre de blocages) à `ai_query()` sur un modèle Gemma 3 12B hébergé via les API de modèles fondamentaux. L'invite demande au modèle de noter huit dimensions MEDDPICC (Douleur, Champion, Plan de mise en œuvre, Processus de décision, Urgence, Connaissance de la concurrence, Impact mesurable, Obstacles majeurs) sur une échelle de 0 à 10, strictement basée sur les preuves disponibles. Les champs manquants obtiennent un score ≤3 plutôt que d'être halluciné. Le composite pondéré devient le score de confiance du cas d'utilisation. Si un cas d'utilisation a plus de trois blocages actifs, le score est remplacé par Faible, quels que soient les autres signaux. Cette conception "anti-échec" signifie que PipelineIQ se dégrade gracieusement lorsque les données sont désordonnées, plutôt que de produire une fausse confiance.
Chaque cas d'utilisation reçoit un score de confiance dynamique, actualisé quotidiennement. Basé sur la fraîcheur des données, la profondeur des parties prenantes et la dynamique de la transaction. Chaque score est accompagné d'une explication claire et d'une action recommandée pour le commercial et le manager, bouclant la boucle entre le signal et l'exécution. Itération rapide, invites ciblées et respect de la réalité plutôt que de la perfection.
Les tableaux de bord ne se contentent pas de visualiser la santé du pipeline, ils la prescrivent. Pour les managers, cela signifie des résumés rapides et des phrases courtes pour rendre le coaching rapide et fondé. Pour les commerciaux, cela signifie se réveiller chaque jour avec une liste de tâches claire et priorisée alimentée par l'analyse.
Aujourd'hui, PipelineIQ enrichit chaque cas d'utilisation qualifiant de notre organisation de vente sur le terrain quotidiennement, produisant un score de confiance actualisé, une action optimale, une évaluation du glissement et une recommandation d'accélération pour chacun. Ce qui nécessitait auparavant des heures d'examen manuel du CRM par session de pipeline est maintenant livré automatiquement avant le début de la journée de travail. C'est ainsi que PipelineIQ élimine le bruit.

Comment nous l'avons construit et ce que nous avons appris
Des questions ciblées et des invites ciblées produisent des résultats ciblés. Évitez d'essayer de résoudre tous les défis de vente en une seule invite. Une approche ciblée permet une itération rapide car chaque invite a un objectif bien défini.
Une approche structurée améliore considérablement les résultats. En effectuant d'abord une analyse qualitative, les données sont enrichies pour les étapes ultérieures. Cette première étape capture et signale les données désordonnées ou manquantes dans les résumés, et aide à régulariser les données sur toutes les ventes, ce qui facilite l'application des étapes d'IA ou d'apprentissage automatique ultérieures pour identifier les tendances dans vos données de ventes.
La modularité améliore l'agilité. Notre pipeline qualitatif → quantitatif → actions recommandées nous permet d'identifier et d'améliorer rapidement l'étape qui nécessite un raffinement. Sans cette approche par étapes, l'obtention de résultats significativement cohérents était une lutte.
Nous avons esquissé une architecture simplifiée ci-dessous qui met en évidence certaines des fonctionnalités que nous ajoutons en cours de route.
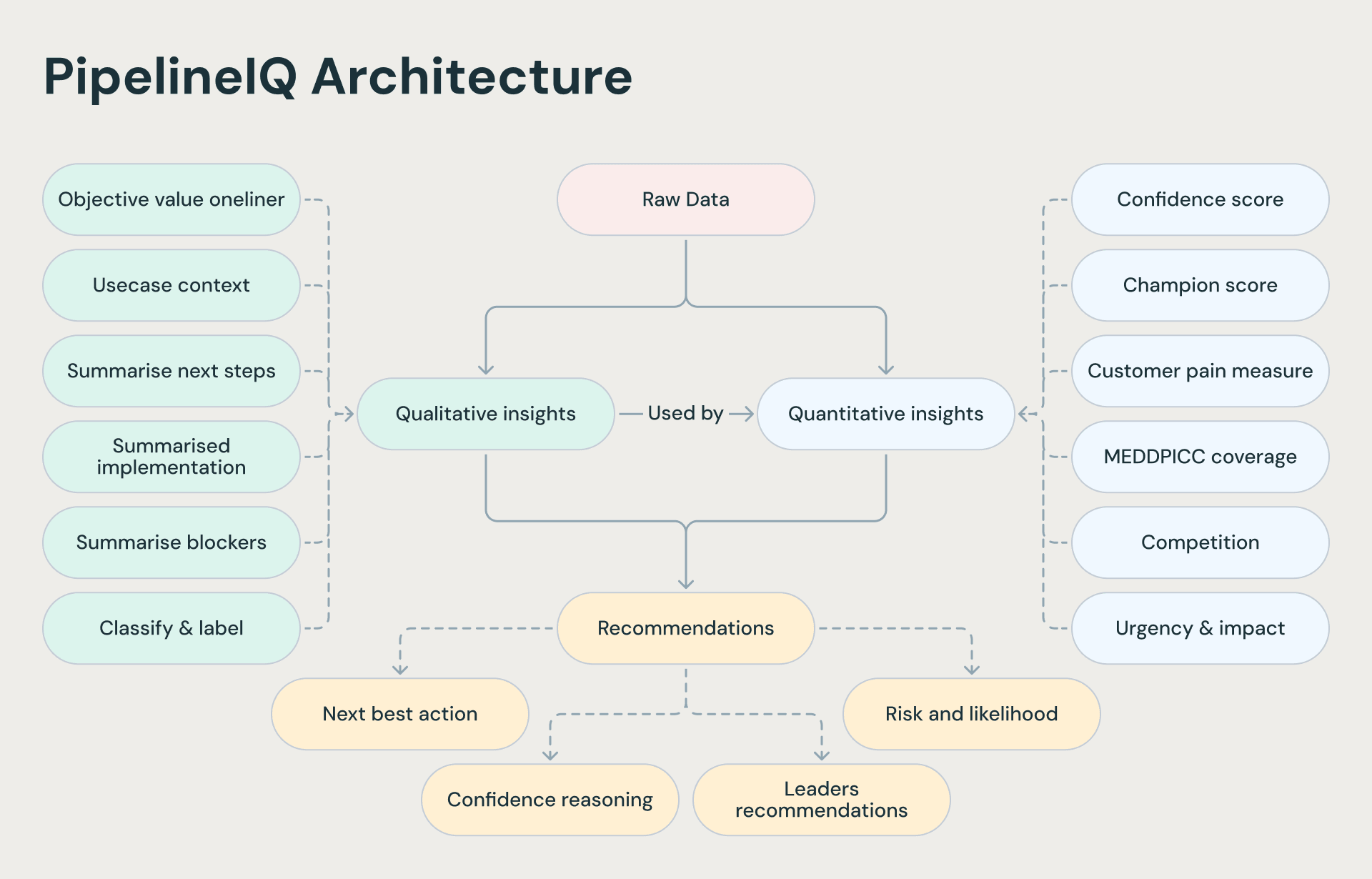
L'implémentation Databricks
PipelineIQ s'exécute en tant que Databricks Workflow quotidien : un DAG de notebook en quatre tâches qui orchestre le cycle d'enrichissement complet. Les données sources circulent de Salesforce vers des tables Delta Lake régies par Unity Catalog, en utilisant un espace de noms partagé à trois niveaux (catalogue.schéma.table) afin que les environnements de développement et de production restent clairement séparés.
Le notebook principal utilise un modèle de diffusion/jointure. Onze vues SQL temporaires sont créées en parallèle, chacune appelant une seule fonction d'API de modèle fondamental (ai_query(), ai_summarize(), ai_classify(), ou ai_gen()) pour enrichir une dimension de chaque cas d'utilisation. Ces vues sont ensuite jointes et fusionnées de manière incrémentielle dans la table Delta cible à l'aide d'un filigrane : seuls les enregistrements qui ont changé depuis la dernière exécution sont ré-enrichis, ce qui maintient les coûts et la latence bas.
Trois modèles alimentent les enrichissements, tous servis via des API de modèles fondamentaux : un modèle GPT de 20 milliards de paramètres gère les résumés, les actions suivantes et l'analyse des blocages ; Gemma 3 12B pilote la notation de confiance MEDDPICC et la classification des cas d'utilisation métier ; et Claude gère l'extraction structurée des prochaines étapes à partir de notes de représentant semi-structurées.
Les résultats apparaissent via deux tableaux de bord (IA/BI) :
- un pour les responsables de terrain montrant des informations au niveau du portefeuille,
- et un pour les responsables des ventes avec des regroupements au niveau de l'équipe.
L'ensemble de la pile, du stockage des données à l'enrichissement par IA en passant par les tableaux de bord, se déploie en tant que Databricks Asset Bundle avec des cibles de développement et de production paramétrées, ce qui le rend entièrement reproductible via CI/CD.
Les résultats
Que pouvons-nous apprendre de PipelineIQ ? Son moteur prescriptif produit trois résultats clairs : Marcher, Pivoter ou Accélérer. Ceux-ci sont basés sur des signaux de confiance en direct plutôt que sur des étapes CRM statiques.
Recommandations générales
Marcher : Ce cas d'utilisation est mal qualifié, car il manque des parties prenantes clés, un faible alignement de la valeur ou une faible urgence de l'acheteur. Déprioriser ou se désengager pour libérer du temps pour de meilleures opportunités.
Pivoter : Le cas d'utilisation est viable, mais votre approche actuelle ne fonctionne pas. Ajustez votre stratégie de partie prenante, affinez votre proposition de valeur ou modifiez votre séquence d'engagement pour optimiser les résultats.
Accélérer : Les conditions sont favorables — solide champion, urgence et multithreading en place. Investissez avec des ressources, une couverture exécutive ou une accélération du calendrier pour maximiser la probabilité de gain.
Accélération : Où investir et quoi faire
Les conseils d'accélération vont au-delà du signalement des bonnes affaires ; ils décodent pourquoi elles s'accélèrent et comment en tirer parti.
Cas d'utilisation que nous pouvons accélérer
Une liste priorisée d'opportunités avec une justification spécifique : « Cette affaire a un solide champion et un calendrier urgent, envisagez d'ajouter un sponsor exécutif pour conclure avant la fin du mois. » ou « L'acheteur est engagé mais la chaîne d'approvisionnement n'est pas impliquée, ajoutez un contact commercial pour éviter les retards. »
Prochaine meilleure action (NBA)
Actions d'une ligne, spécifiques au rôle. Pour les représentants : « Planifiez un appel avec le directeur financier pour discuter des préoccupations budgétaires. » Pour les responsables : « Attribuez un support d'ingénieur pour finaliser la victoire technique. » Aucune interprétation requise — faites-le simplement.
Principaux moteurs d'accélération
Quels thèmes stimulent le succès dans votre pipeline ? PipelineIQ consolide les facteurs communs — force du multithreading, engagement du champion et élan du déplacement concurrentiel — afin que vous sachiez où investir dans l'ensemble, pas seulement affaire par affaire.
Retard : Qu'est-ce qui est en jeu et quoi faire
En analysant les modèles de retard, tels que les dates de prochaine étape dormantes ou l'absence d'activité du champion, PipelineIQ apprend à repérer les retards des mois à l'avance. Il transforme le reporting descriptif des risques en plans de récupération prescriptifs.
Cas d'utilisation et opportunités en jeu
Une vue classée des affaires susceptibles de ne pas respecter les dates de clôture prévues, avec le propriétaire, l'étape et l'impact potentiel sur vos objectifs. Adaptez-les à votre tâche en modifiant les classements : le ARR global ou la probabilité de retard vous donnent une vue d'ensemble, tandis que le classement régional et par propriétaire vous donne les zones à risque dans la zone, tandis que le classement par étape ou par produit vous permet de créer des stratégies d'exécution personnalisées.
Pourquoi ils sont en jeu (et la probabilité de retard)
Explications concises et basées sur des preuves : « Acheteur économique manquant — dernier contact il y a 18 jours » ou « Aucune prochaine étape définie — l'activité a stagné pendant 2 semaines. » PipelineIQ met également en évidence les lacunes des données : « Champs critiques manquants — la confiance dans cette évaluation est de 60 %. »
Que faire à ce sujet
Étapes de remédiation actionnables mappées au type de risque : Si le champion est faible, introduisez un sponsor senior. Si la chaîne d'approvisionnement est bloquée, ajoutez un contact commercial. Si l'alignement de la valeur n'est pas clair, effectuez une preuve de concept ou une session de découverte.
Causes et catégories communes
Thèmes de retard agrégés par région, segment ou produit. « Les affaires EMEA stagnent dans la chaîne d'approvisionnement 40 % plus souvent qu'aux États-Unis » ou « Le segment d'entreprise manque de multithreading dans 65 % des affaires à risque. » Cela permet aux dirigeants de résoudre les problèmes systémiques, pas seulement de lutter contre les opportunités individuelles.
Chaque recommandation inclut un score de confiance basé sur la qualité des données, la force du signal et l'accord du modèle. Haute confiance ? Agissez de manière décisive. Faible confiance ? PipelineIQ met en évidence les champs manquants ou les signaux contradictoires, vous permettant de combler les lacunes ou d'approfondir.
Améliorer l'exécution des ventes
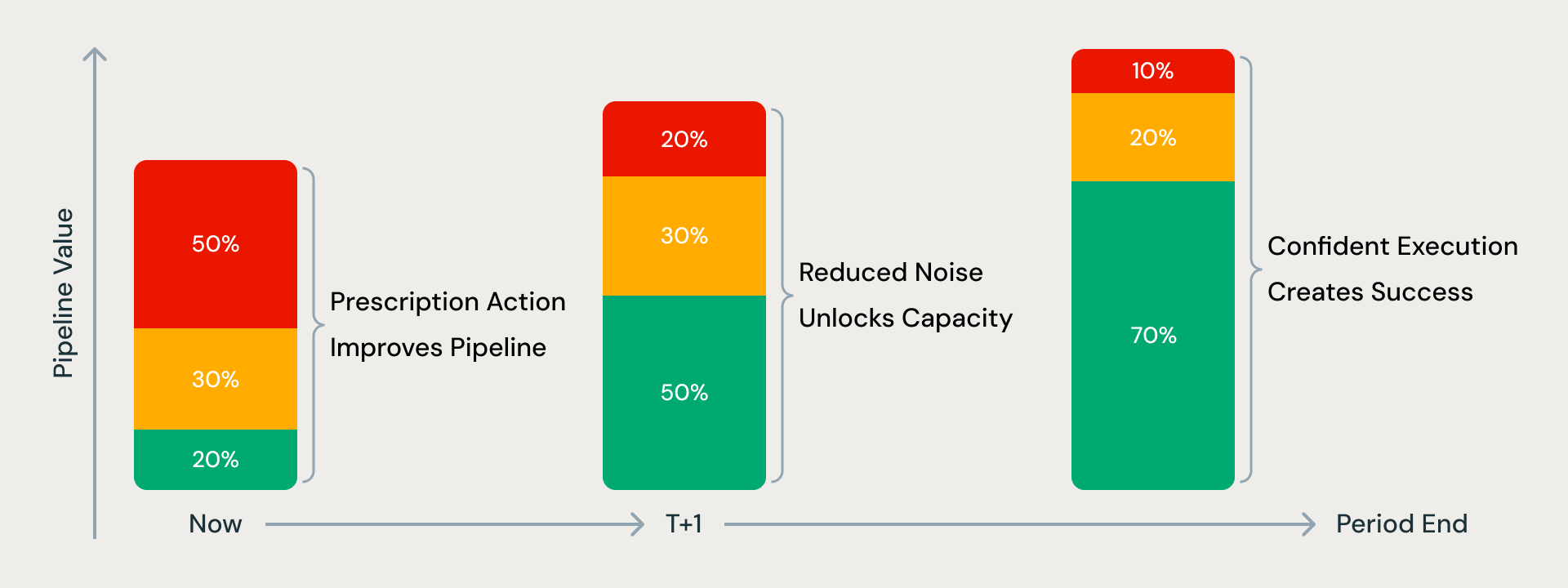
Nous avons donc un excellent outil, mais comment l'utiliser ?
Vue du responsable : Informations au niveau du portefeuille
Candidats à l'accélération classés par impact, risques de retard systémiques par catégorie (région, segment, produit) et moteurs au niveau de l'équipe avec des analyses détaillées des transactions individuelles. Les responsables voient où allouer les ressources et quels modèles nécessitent un coaching, comme quelles équipes pourraient bénéficier d'une formation sur l'engagement exécutif.
Vue du représentant : Actions personnalisées
Actions suivantes personnalisées pour chaque opportunité, affaires à risque avec des étapes de remédiation claires et des gains rapides pour atteindre les objectifs à court terme. Les représentants ouvrent PipelineIQ et savent exactement quoi faire aujourd'hui.
Vue de l'exécutif : Rapports stratégiques
Regroupements par région, segment et produit. Deltas de prévision pondérés par la confiance montrant où la qualité du pipeline est forte ou faible. Suggestions d'allocation des ressources : « Votre équipe EMEA a besoin d'une expertise en chaîne d'approvisionnement » ou « Les affaires d'entreprise nécessitent plus d'engagement exécutif. »
Interface conversationnelle : Posez n'importe quelle question à PipelineIQ
Au-delà des tableaux de bord, les données enrichies de PipelineIQ sont interrogeables via le Génie IA/BI de Databricks. Cela permet aux responsables de poser des questions en langage naturel directement sur le pipeline enrichi, sans avoir besoin de SQL. Genie renvoie des réponses raisonnées et citées, basées sur les tables Delta sous-jacentes.
Exemples d'invites :
- « Quelles sont les 5 principales opportunités sur lesquelles je devrais me concentrer au quatrième trimestre pour dépasser mes objectifs de croissance ? »
- « Quels sont les 5 plus grands risques dans ma région ? »
- « Quelles équipes bénéficieraient le plus d'une formation sur l'engagement exécutif ? »
PipelineIQ s'adresse aux responsables des ventes qui en ont assez des « informations » qui ne mènent pas à l'action. Si vous gérez une équipe qui se noie dans le bruit du pipeline, qui lutte avec des données CRM désordonnées, ou qui passe des heures administratives à préparer des revues de pipeline qui produisent plus de questions que de réponses, PipelineIQ vous apporte clarté et concentration, et vous permet de passer plus de temps devant votre client, à établir des relations.
Les prévisions ne réparent pas les pipelines, les actions le font. Voyez votre entonnoir de ventes à travers une lentille prescriptive. Commencez un pilote de 4 semaines et découvrez comment la notation de confiance quotidienne et les actions suivantes changent votre rythme d'exécution.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.