PipelineIQ: Forward‑Looking Sales Intelligence That Drives Action
How we use AI to improve sales operations by cutting through the noise and focusing on action
by Sam Le Corre, Dael Williamson and Luis Herrera
- Shifts Focus from Forecasting to Prescriptive Action: PipelineIQ is an AI solution that moves beyond traditional retrospective forecasting (which often fails due to messy data) by providing immediate, forward-looking, and prescriptive "Next Best Actions" (NBA) for sales reps and managers.
- Built for Imperfect CRM Data: It's designed to work with the reality of incomplete and inconsistent CRM data, extracting forward signals like champion strength and procurement stalls, and adjusting its confidence score rather than breaking when data is missing.
- Delivers Clear Outcomes: It simplifies pipeline management into three clear recommendations for every opportunity: Walk (de-prioritize), Pivot (change strategy), or Accelerate (lean in), each with a clear rationale and role-specific action plan.
Summary
Sales and Customer Relationship Management (CRM) data is messy. For decades, we have attempted to brute force sales data hygiene within the system of record (e.g., Salesforce), yet the data still remains messy. In a Consumption CRM world, the messy CRM data problem poses a significant administrative drain (>20% productivity), significantly impacting forecast (and revenue) predictability.
PipelineIQ transforms messy CRM data into clear actions: which deals to walk away from, which to pivot, and which to accelerate. Unlike traditional forecasting that looks backwards and assumes clean data, PipelineIQ uses AI to extract forward-looking signals from your actual pipeline—incomplete fields, delayed updates, and all—then tells your team exactly what to do next.
PipelineIQ is a Databricks-on-Databricks story. Our field sales organisation faced the same pipeline management challenge every B2B sales team knows: hours spent manually reviewing CRM data that's incomplete, inconsistent, and backward-looking. So we built PipelineIQ on Databricks – using Foundation Model APIs, Unity Catalog, Delta Lake, and AI/BI Dashboards – to turn our own messy sales pipeline data into a forward-looking action engine that cuts out the noise. We built something to help keep people focused and let sales leaders diagnose problems in sales to optimize execution. This post discusses how we applied AI in practice, and not just why you should use it.
Why most "AI in sales" posts miss the point
Most AI-in-sales content promises vague "insights" or "data-driven decisions." They also approach everything with a retrospective-first philosophy: based on what happened, what might happen? Flip this on its head and you have prescriptive analytics: based on what we know now, what should we do next?
We'll talk about why we focused on action and risk rather than forecasting. How we used the natural strengths of AI to our advantage. Focusing on the questions is key to building a solution. Refining your prompts is critical for meaningful action.
Velocity was key. Keeping it simple and build, not buy, was the secret sauce. This approach lets us build a tool that respects how your business actually works, and not just how your CRM software vendor says it should work.
Why didn't we build yet another forecasting solution?
Many AI solutions in the sales space sell the dream of perfect forecasting or making it accessible to everyone. This is usually nonsense for a few reasons. They skip out on why it's hard. This isn't a post about forecasting, so we'll explain why we took a different approach.
So why do forecasting solutions typically fail? Honestly? Because forecasting is a science, and nobody has time for that. Here are two key considerations you need to either get right or account for to ensure a forecast works effectively.
Historical data looks complete because the sale is already over
Your forecasting model uses clean, complete historical data and assumes that active deals appear the same. They don't. Won deals have every field filled in because they had to; the sales process is finished, paperwork is done, the journey is documented. But in-flight deals? Reps fill in the CRM when they have time or when they're required to during pipeline reviews. Fields stay blank with a mental note of "I'll do that later." Critical information (such as next-step dates, champion contacts, and competitive intel) is either missing or weeks out of date.
Traditional forecasting assumes you can reconstruct the sales journey from whatever's in your CRM today. In reality, unless you captured complete data every single day (you didn't), you're building models on incomplete snapshots. Your forecast isn't predicting the future—it's guessing based on fiction.
Forecasts need a working model of the system they're trying to predict
In sales, the 'system' is more or less the entire world.
Even with complete data, forecasting breaks when your model can't capture reality. You need to model your humans: stages updated weekly, not daily, reps sandbagging or overselling, and the feedback loop problem, where if a forecast predicts a dip, an army of people swarm to "fix" it, invalidating the prediction. This is crazy and complicated.
You need to model your business: product lines, sales motions, stage definitions, org hierarchies and team dynamics all create complexity. You need to pick the right scale: daily, weekly, monthly, quarterly? By division, product line, region, or business unit? Each dimension multiplies the difficulty.
Finally, you need to model the market, which is often disrupted by pandemics, cyberattacks, and infrastructure outages that can rewrite the rules overnight.
Getting all of that right? That's a full-time data science team. Most sales orgs don't have one, and those that do are hard-pressed to keep up.
Three principles that separate PipelineIQ from traditional forecasting
Action over analysis. No more "interesting insights" that require translation. PipelineIQ delivers one-line next best actions for reps and managers—immediately executable.
Forward signals over history. Instead of projecting past win rates, PipelineIQ extracts what's changing right now: champion strength shifting, procurement stalling, and multithreading accelerating.
Built for imperfect data. When fields are missing or signals conflict, PipelineIQ doesn't break—it adjusts confidence scores and tells you where the gaps are.
Introducing PipelineIQ
What is it?
PipelineIQ is an AI solution we built on top of the raw garbage data in our CRM. It analyses our opportunities and turns forward-looking signals into immediate actions. Instead of forecasting what might close based on history, it tells you what to do today to improve what will close tomorrow. It's built for the reality of sales operations: imperfect data, changing conditions, and teams that need priorities.
What did we do differently?
PipelineIQ brings prescriptive analytics to the B2B SaaS sales funnel, turning signals from your CRM into daily, data-backed recommendations that help account teams move faster and managers coach smarter. By prescribing what each role should do next, and explaining why, it provides the missing execution layer in B2B SaaS sales.
We didn't try to build a perfect model of the world. Instead, we leveraged what LLMs are naturally good at: synthesising incomplete information, spotting patterns across messy data, and turning those patterns into clear recommendations.
Give an LLM a focused question, such as "Is this deal at risk?" and it can combine activity logs, missing fields, email tone, and stakeholder engagement to produce a reasoned answer, even when half the data is missing. The model can judge when it's guessing and when it's confident. It summarises, compares, and adapts in real-time as new information arrives.
Here's a concrete example. Our confidence scorer passes each use case's CRM fields (BDR notes, stakeholder list, competition intel, blocker count) to ai_query() on a Gemma 3 12B model hosted via Foundation Model APIs. The prompt asks the model to score eight MEDDPICC dimensions (Pain, Champion, Implementation Plan, Decision Process, Urgency, Competition Awareness, Measurable Impact, Major Blockers) on a 0–10 scale, strictly grounded in available evidence. Missing fields score ≤3 rather than being hallucinated. The weighted composite becomes the use case's confidence score. If a use case has more than three active blockers, the score is overridden to Low regardless of other signals. This "fail-safe" design means PipelineIQ degrades gracefully when data is messy, rather than producing false confidence.
Every use case receives a dynamic confidence score, refreshed daily. Based on data freshness, stakeholder depth, and deal momentum. Each score comes with a clear rationale and a recommended next action for both the rep and the manager, closing the loop between signal and execution. Fast iteration, focused prompts, and respecting reality over perfection.
The dashboards don’t just visualise pipeline health, they prescribe it. For managers, this means quick summaries and one-liners to make coaching fast and grounded. For reps, it means waking up every day to a clear, prioritised to-do list powered by analytics.
Today, PipelineIQ enriches every qualifying use case across our field sales organisation daily, producing a refreshed confidence score, next-best-action, slippage assessment, and acceleration recommendation for each. What previously required hours of manual CRM review per pipeline session is now delivered automatically before the working day begins. That's how PipelineIQ cuts through the noise.

How we built it and what we learned
Focused questions and focused prompts produce focused results. Avoid trying to solve all sales challenges in one prompt. A focused approach allows for rapid iteration because each prompt has a well-defined purpose.
A structured approach significantly improves outcomes. By performing qualitative analysis first, the data is enriched for subsequent steps. This initial stage captures and calls out messy or missing data in summaries, and helps to regularise the data across all the sales, making it easier to apply subsequent AI or ML steps to identify patterns in your sales data.
Modularity improves agility. Our qualitative → quantitative → recommended actions pipeline allows us to quickly pinpoint and improve the stage that needs refinement. Without this staged approach, achieving meaningfully consistent outcomes was a struggle.
We’ve drawn a simplified architecture below that highlights some of the features we add along the way.
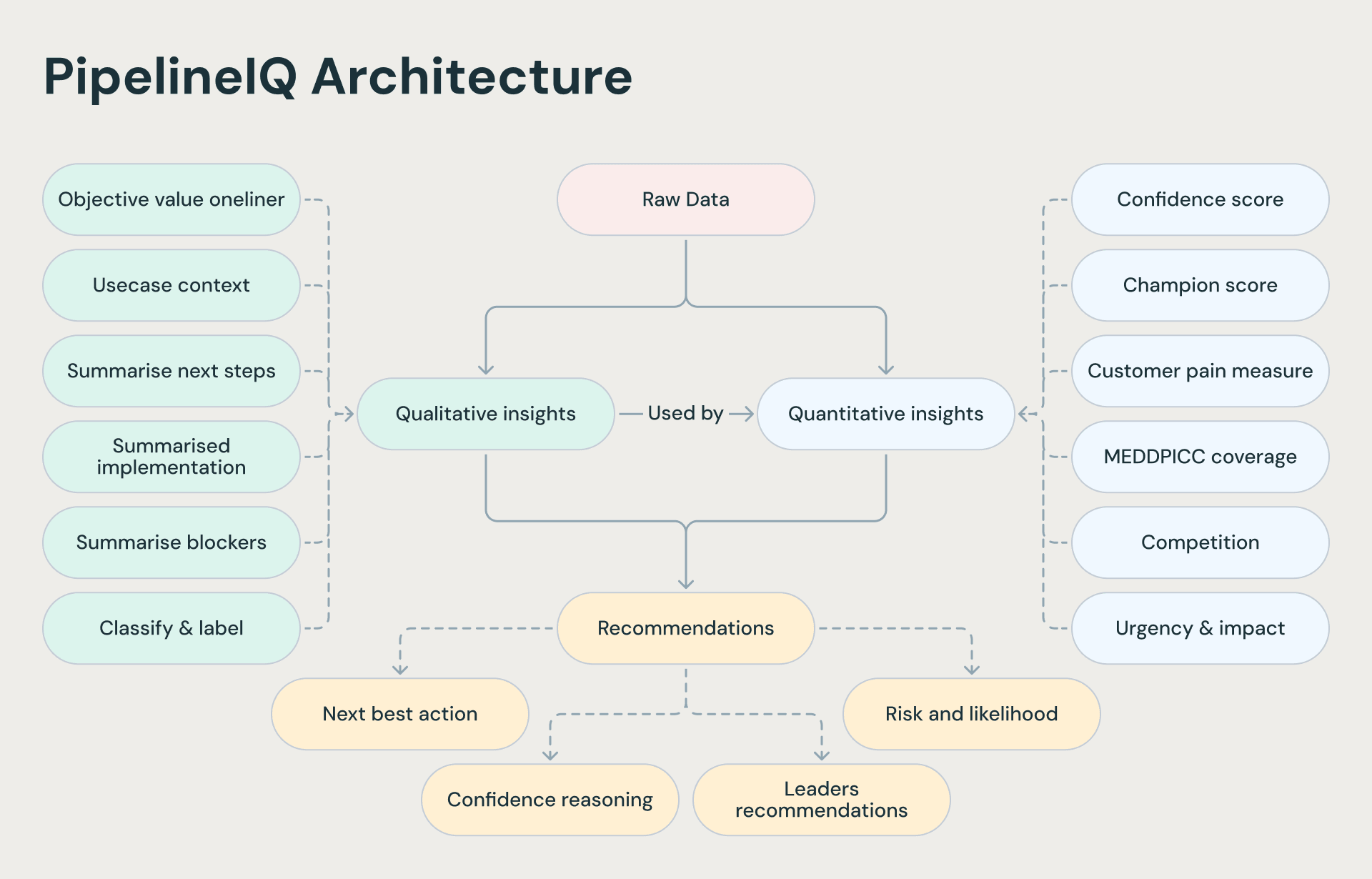
The Databricks implementation
PipelineIQ runs as a daily Databricks Workflow: a four-task notebook DAG that orchestrates the full enrichment cycle. Source data flows from Salesforce into Delta Lake tables governed by Unity Catalog, using a shared three-level namespace (catalog.schema.table) so that dev and prod environments stay cleanly separated.
The core notebook uses a fan-out/join pattern. Eleven temporary SQL views are created in parallel, each calling a single Foundation Model API function (ai_query(), ai_summarize(), ai_classify(), or ai_gen()) to enrich one dimension of every use case. These views are then joined back together and merged incrementally into the target Delta table using a watermark: only records that changed since the last run are re-enriched, keeping cost and latency low.
Three models power the enrichments, all served via Foundation Model APIs: a 20B-parameter GPT model handles summaries, next-best-actions, and blocker analysis; Gemma 3 12B drives MEDDPICC confidence scoring and business use case classification; and Claude handles structured extraction of next steps from semi-structured rep notes.
The results surface through two (AI/BI) Dashboards:
- one for field managers showing portfolio-level insights,
- and one for sales managers with team-level rollups.
The entire stack, from data storage through AI enrichment to dashboards, deploys as a Databricks Asset Bundle with parameterised dev and prod targets, making it fully reproducible via CI/CD.
The outputs
What can we learn from PipelineIQ? Its prescriptive engine produces three clear outcomes: Walk, Pivot, or Accelerate. These are based on live confidence signals rather than static CRM stages.
Overall recommendations
Walk: This use case is poorly qualified, as it lacks key stakeholders, weak value alignment, or low buyer urgency. De-prioritise or disengage to free up time for better opportunities.
Pivot: The use case is viable, but your current approach isn't working. Adjust your stakeholder strategy, refine your value proposition, or modify your engagement sequence to optimise results.
Accelerate: Conditions are favourable—strong champion, urgency, and multithreading in place. Lean in with resources, executive air cover, or timeline pull-in to maximise win probability.
Acceleration: Where to invest and what to do
Acceleration guidance goes beyond flagging good deals; it decodes why they’re accelerating and how to capitalise on them.
Use cases we can accelerate
A prioritized list of opportunities with specific rationale: "This deal has a strong champion and urgent timeline, consider adding an exec sponsor to close by month-end." or "Buyer is engaged but procurement isn't looped, add a commercial contact to avoid slippage."
Next best action (NBA)
One-line, role-specific actions. For reps: "Schedule a call with the CFO to address budget concerns." For managers: "Assign engineer support to finalise the technical win." No interpretation required—just do it.
Key acceleration drivers
What themes are driving success across your pipeline? PipelineIQ consolidates the common factors—multithreading strength, champion engagement, and competitive displacement momentum—so you know where to invest across the board, not just deal by deal.
Slippage: What's at risk and what to do about it
By analyzing delay patterns, like dormant next-step dates or missing champion activity, PipelineIQ learns to spot slippage months in advance. It turns descriptive risk reporting into prescriptive recovery playbooks.
Use cases and opportunities at risk
A ranked view of deals likely to miss target close dates, with owner, stage, and potential impact to your targets. Tailor these to your task by changing the rankings: overall ARR or slip likelihood gives you a 30,000-foot view, while regional and owner give you risky areas in the patch, while ranking by stage or product areas lets you create customised execution strategies.
Why they're at risk (and likelihood of slip)
Concise, evidence-based explanations: "Missing economic buyer—last contact was 18 days ago" or "No next steps defined—activity has stalled for 2 weeks." PipelineIQ also surfaces data gaps: "Critical fields missing—confidence in this assessment is 60%."
What to do about it
Actionable remediation steps mapped to risk type: If the champion is weak, introduce a senior sponsor. If procurement is stalling, add a commercial contact. If value alignment is unclear, run a proof-point or discovery session.
Common causes and categories
Aggregated slippage themes by region, segment, or product. "EMEA deals stall in procurement 40% more often than U.S." or "Enterprise segment lacks multithreading in 65% of at-risk deals." This allows leaders to address systemic issues, not just firefight on single opportunities.
Every recommendation includes a confidence score based on data quality, signal strength, and model agreement. High confidence? Act decisively. Low confidence? PipelineIQ highlights which fields are missing or signals are contradictory, allowing you to fill gaps or investigate further.
Improving sales execution
So we have a great tool, but how do we use it?
Manager view: Portfolio-level insights
Acceleration candidates ranked by impact, systemic slippage risks by category (region, segment, product), and team-level drivers with drill-downs into individual deals. Managers see where to allocate resources, and which patterns need coaching, such as which teams could benefit from executive engagement training.
Rep view: Personalised actions
Personalised Next Best Actions for each opportunity, at-risk deals with clear remediation steps, and quick wins to hit near-term targets. Reps open PipelineIQ and know exactly what to do today.
Executive view: Strategic rollups
Roll-ups by region, segment, and product. Confidence-weighted forecast deltas showing where pipeline quality is strong or weak. Resource allocation suggestions: "Your EMEA team needs procurement expertise" or "Enterprise deals need more exec engagement."
Conversational interface: Ask PipelineIQ anything
Beyond dashboards, PipelineIQ's enriched data is queryable through Databricks' AI/BI Genie. This allows managers to ask natural-language questions directly against the enriched pipeline, with no SQL required. Genie returns reasoned, cited answers grounded in the underlying Delta tables.
Example prompts:
- "What are the top 5 opportunities I should focus on in Q4 to beat my growth targets?"
- "What are the 5 biggest risks in my region?"
- "Which teams would benefit most from executive engagement training?"
PipelineIQ is for sales leaders who are tired of "insights" that don't drive action. If you're managing a team that's drowning in pipeline noise, struggling with messy CRM data, or spending hours of administrative time prepping for pipeline reviews that produce more questions than answers, PipelineIQ gives you clarity and focus, and lets you spend more time in front of your customer, building relationships.
Forecasts don’t fix pipelines, actions do. See your sales funnel through a prescriptive lens. Start a 4-week pilot and experience how daily confidence scoring and next-best-actions change your execution rhythm.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.