Le guide ultime du praticien pour la journalisation évolutive
Standardisez et structurez la journalisation de production pour les tâches Spark sur Databricks, et tirez le meilleur parti de vos journaux en centralisant les journaux de cluster pour l'ingestion et l'analyse.
par Zach King
- Meilleures pratiques de niveau production pour une journalisation structurée et pratique dans les tâches Databricks.
- Centralisation du stockage des journaux qui s'adapte et simplifie le traitement.
- Création d'un tableau de bord IA/BI pour analyser les journaux.
Introduction : La journalisation est importante, voici pourquoi
Passer de quelques dizaines de tâches à des centaines est un défi pour plusieurs raisons, dont l'observabilité. L'observabilité est la capacité de comprendre le système en analysant des composants tels que les journaux, les métriques et les traces. Ceci est tout aussi pertinent pour les petites �équipes de données avec seulement quelques pipelines à surveiller, et les moteurs de calcul distribué comme Spark peuvent être difficiles à surveiller, déboguer de manière fiable et à créer des procédures d'escalade matures.
La journalisation est sans doute la plus simple et la plus percutante de ces composantes d'observabilité. Cliquer et faire défiler les journaux, une exécution de tâche à la fois, n'est pas évolutif. Cela peut prendre du temps, être difficile à analyser et nécessite souvent une expertise du domaine du flux de travail. Sans intégrer des normes de journalisation matures dans vos pipelines de données, le dépannage des erreurs ou des échecs de tâches prend beaucoup plus de temps, entraînant des interruptions coûteuses, des niveaux d'escalade inefficaces et une fatigue des alertes.
Dans ce blog, nous allons vous guider à travers :
- Les étapes pour s'éloigner des instructions d'impression de base et mettre en place un cadre de journalisation approprié.
- Quand configurer les journaux log4j de Spark pour utiliser le format JSON.
- Pourquoi centraliser le stockage des journaux de cluster pour une analyse et une requête faciles.
- Comment créer un tableau de bord central d'IA/BI dans Databricks que vous pouvez configurer dans votre propre espace de travail pour une analyse de journaux plus personnalisée.
Considérations architecturales clés
Les considérations suivantes sont importantes à garder à l'esprit pour adapter ces recommandations de journalisation à votre organisation :
Bibliothèques de journalisation
- Plusieurs bibliothèques de journalisation existent pour Python et Scala. Nos exemples utilisent Log4j et le module standard Python logging.
- La configuration des bibliothèques ou des frameworks de journalisation sera différente, et vous devriez consulter leur documentation respective si vous utilisez un outil non standard.
Types de cluster
- Les exemples de ce blog se concentreront principalement sur le calcul suivant :
- Au moment de la rédaction, les types de calcul suivants ont moins de support pour la livraison de journaux, bien que les recommandations pour les frameworks de journalisation s'appliquent toujours :
- Lakeflow Declarative Pipelines (anciennement DLT) : ne prend en charge que les journaux d'événements
- Tâches sans serveur : ne prend pas en charge la livraison de journaux
- Notebooks sans serveur : ne prend pas en charge la livraison de journaux
Gouvernance des données
- La gouvernance des données doit s'étendre aux journaux de cluster, car les journaux peuvent accidentellement exposer des données sensibles. Par exemple, lorsque vous écrivez des journaux dans une table, vous devriez considérer quels utilisateurs ont accès à la table et utiliser une conception d'accès au moindre privilège.
- Nous montrerons comment livrer les journaux de cluster aux volumes Unity Catalog pour un contrôle d'accès et une lignée plus simples. La livraison de journaux aux volumes est en aperçu public et n'est prise en charge que sur les calculs activés pour Unity Catalog avec le mode d'accès Standard ou le mode d'accès Dédié attribué à un utilisateur.
- Cette fonctionnalité n'est pas prise en charge sur les calculs avec le mode d'accès Dédié attribué à un groupe.
Répartition technique de la solution
La standardisation est la clé de l'observabilité des journaux de niveau production. Idéalement, la solution devrait accueillir des centaines, voire des milliers de tâches/pipelines/clusters.
Pour l'implémentation complète de cette solution, veuillez visiter ce dépôt ici : https://github.com/databricks-industry-solutions/watchtower
Création d'un volume pour la livraison centralisée des journaux
Tout d'abord, nous pouvons créer un Volume Unity Catalog pour qu'il serve de stockage de fichiers central pour les journaux. Nous ne recommandons pas DBFS car il ne fournit pas le même niveau de gouvernance des données. Nous recommandons de séparer les journaux pour chaque environnement (par exemple, dev, stage, prod) dans différents répertoires ou volumes afin que l'accès puisse être contrôlé de manière plus granulaire.
Vous pouvez le créer dans l'interface utilisateur, dans un Databricks Asset Bundle (AWS | Azure | GCP), ou dans notre cas, avec Terraform :
Veuillez vous assurer d'avoir les autorisations READ VOLUME et WRITE VOLUME sur le volume (AWS | Azure | GCP).
Configurer la livraison des journaux de cluster
Maintenant que nous avons un endroit central pour placer nos journaux, nous devons configurer les clusters pour qu'ils livrent leurs journaux dans cette destination. Pour ce faire, configurez la livraison des journaux de calcul (AWS | Azure | GCP) sur le cluster.
Encore une fois, utilisez l'interface utilisateur, Terraform ou une autre méthode préférée ; nous utiliserons Databricks Asset Bundles (YAML) :
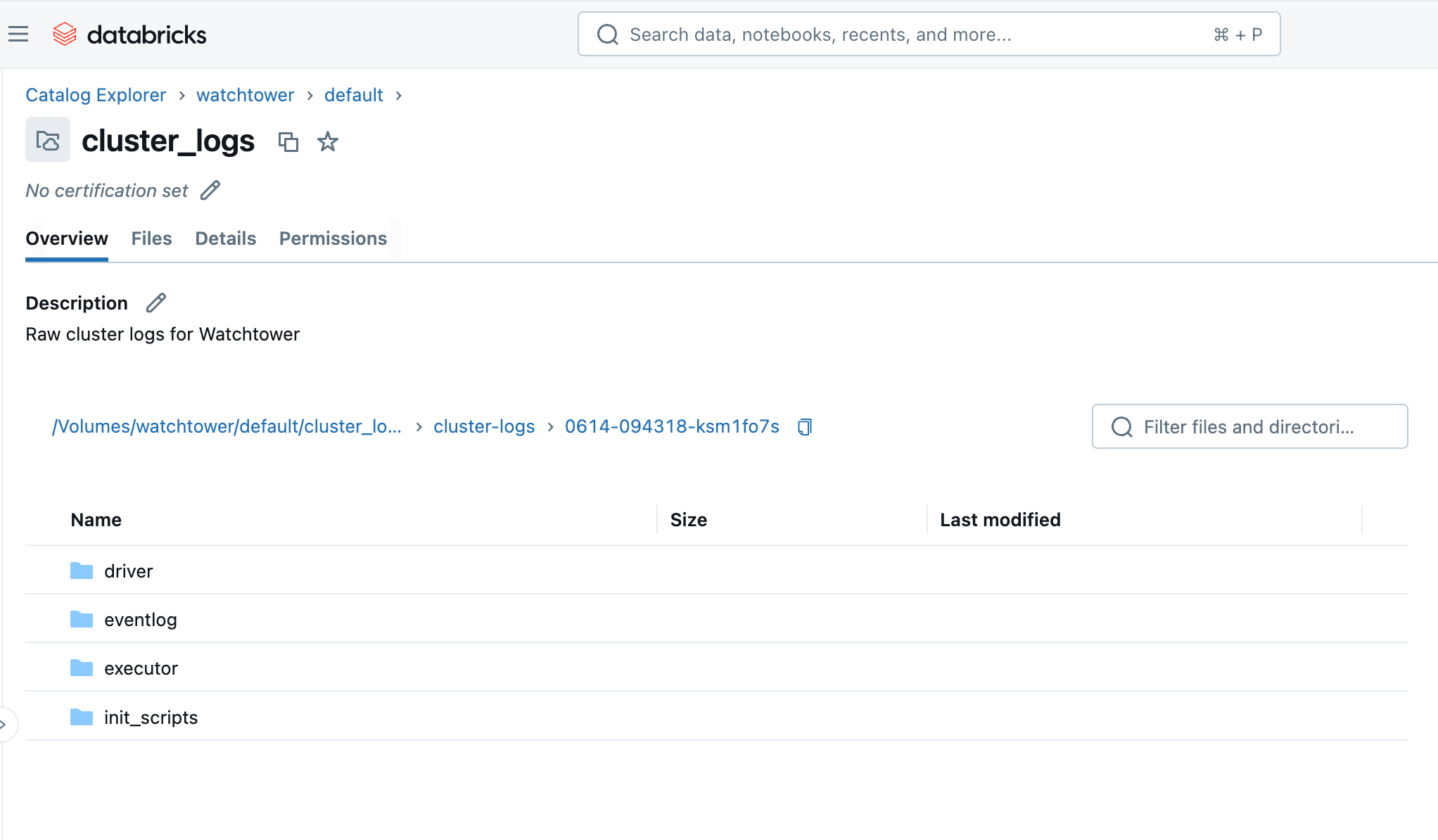
Après avoir exécuté le cluster ou la tâche, en quelques minutes, nous pouvons parcourir le volume dans le Catalog Explorer et voir les fichiers arriver. Vous verrez un dossier avec l'ID du cluster (par exemple, 0614-174319-rbzrs7rq), puis des dossiers pour chaque groupe de journaux :
- driver : Journaux du nœud Driver, qui nous intéressent le plus.
- executor : Journaux de chaque exécuteur Spark dans le cluster.
- eventlog : journaux d'événements que vous pouvez trouver dans l'onglet « Journal des événements » du cluster, tels que le démarrage du cluster, l'arrêt du cluster, le redimensionnement, etc.
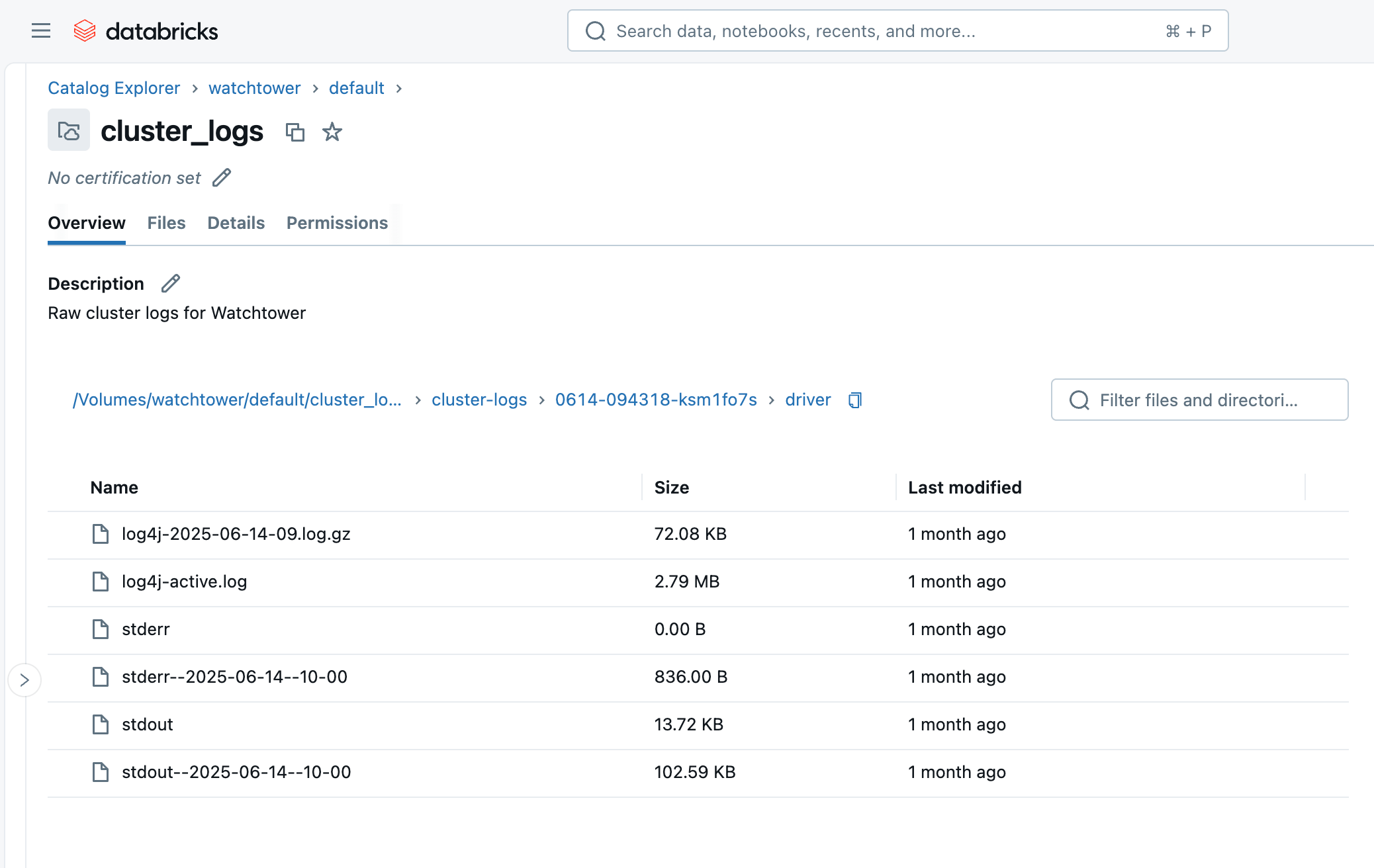
- init_scripts : Ce dossier est généré si le cluster a des scripts d'initialisation, comme le nôtre. Des sous-dossiers sont créés pour chaque nœud du cluster, puis les journaux stdout et stderr peuvent être trouvés pour chaque script d'initialisation qui a été exécuté sur le nœud.
Application des normes : Stratégie de cluster
Les administrateurs d'espace de travail doivent appliquer des configurations standard dans la mesure du possible. Cela signifie restreindre l'accès à la création de clusters et donner aux utilisateurs une Stratégie de cluster (AWS | Azure | GCP) avec la configuration des journaux de cluster définie sur des valeurs fixes comme indiqué ci-dessous :
En définissant ces attributs sur une valeur « fixe », on configure automatiquement la bonne destination de Volume et on évite que les utilisateurs oublient ou modifient la propriété.
Désormais, au lieu de configurer explicitement le cluster_log_conf dans votre fichier YAML d'asset bundle, il vous suffit de spécifier l'ID de la politique de cluster à utiliser :
Plus qu'une simple instruction print()
Bien que les instructions `print()` puissent être utiles pour un débogage rapide pendant le développement, elles sont insuffisantes dans les environnements de production pour plusieurs raisons :
- Manque de structure : Les instructions `print()` produisent du texte non structuré, ce qui rend difficile l'analyse, l'interrogation et le traitement des logs à grande échelle.
- Contexte limité : Elles manquent souvent d'informations contextuelles essentielles comme les horodatages, les niveaux de log (par exemple, INFO, WARNING, ERROR), le module d'origine ou l'ID du job, qui sont cruciaux pour un dépannage efficace.
- Surcharge de performance : Des instructions `print()` excessives peuvent introduire une surcharge de performance car elles déclenchent une évaluation dans Spark. Les instructions `print()` écrivent également directement dans la sortie standard (stdout) sans mise en mémoire tampon ni traitement optimisé.
- Aucun contrôle sur la verbosité : Il n'existe aucun mécanisme intégré pour contrôler la verbosité des instructions `print()`, ce qui entraîne des logs trop verbeux ou insuffisants en détail.
Les frameworks de logging appropriés, tels que Log4j pour Scala/Java (JVM) ou le module logging intégré pour Python, résolvent tous ces problèmes et sont préférés en production. Ces frameworks nous permettent de définir des niveaux de log ou une verbosité, de produire des formats lisibles par machine comme JSON et de définir des destinations flexibles.
Veuillez également noter la différence entre stdout, stderr et log4j dans les logs du driver Spark :
- stdout : Buffer de sortie standard du JVM du nœud driver. C'est là que les instructions `print()` et la sortie générale sont écrites par défaut.
- stderr : Buffer d'erreur standard du JVM du nœud driver. C'est généralement là que les exceptions/traces de pile sont écrites, et de nombreuses bibliothèques de logging utilisent également stderr par défaut.
- log4j : Spécifiquement filtré pour les messages de log écrits avec un logger log4j. Vous pouvez également voir ces messages dans stderr.
Python
En Python, cela implique d'importer le module de logging standard, de définir un format JSON et de définir votre niveau de log.
À partir de Spark 4, ou Databricks Runtime 17.0+, un logger structuré simplifié est intégré à PySpark : https://spark.apache.org/docs/latest/api/python/development/logger.html. L'exemple suivant peut être adapté à PySpark 4 en remplaçant l'instance de logger par une instance de `pyspark.logger.PySparkLogger`.
Une grande partie de ce code sert uniquement à formater nos messages de log Python en JSON. Le JSON est semi-structuré et facile à lire pour les humains comme pour les machines, ce que nous apprécierons lors de l'ingestion et de l'interrogation de ces logs plus tard dans ce blog. Si nous ignorions cette étape, nous pourrions nous retrouver à utiliser des expressions régulières complexes et inefficaces pour deviner quelle partie du message correspond au niveau de log, à l'horodatage, au message, etc.
Bien sûr, c'est assez verbeux à inclure dans chaque notebook ou package Python. Pour éviter la duplication, ce code de base peut être regroupé dans un module utilitaire et chargé dans vos jobs de plusieurs manières :
- Placez le code de base dans un module Python sur l'espace de travail et utilisez les importations de fichiers d'espace de travail (AWS | Azure | GCP) pour exécuter le code au début de vos notebooks principaux.
- Intégrez le code de base dans un fichier wheel Python et chargez-le sur les clusters en tant que bibliothèque (AWS | Azure | GCP).
Scala
Les mêmes principes s'appliquent à Scala, mais nous utiliserons Log4j à la place, ou plus spécifiquement, l'abstraction SLF4j :
Lorsque nous visualisons les logs du driver dans l'interface utilisateur, nous trouvons nos messages de log INFO et WARN sous Log4j. En effet, le niveau de log par défaut est INFO, donc les messages DEBUG et TRACE ne sont pas écrits.

Les logs Log4j ne sont cependant pas au format JSON ! Nous verrons comment résoudre ce problème ensuite.
Logging pour Spark Structured Streaming
Pour capturer des informations utiles pour les jobs de streaming, telles que les métriques des sources et des sinks de streaming et la progression des requêtes, nous pouvons également implémenter le `StreamingQueryListener` de Spark.
Enregistrez ensuite le listener de logging avec votre session Spark :
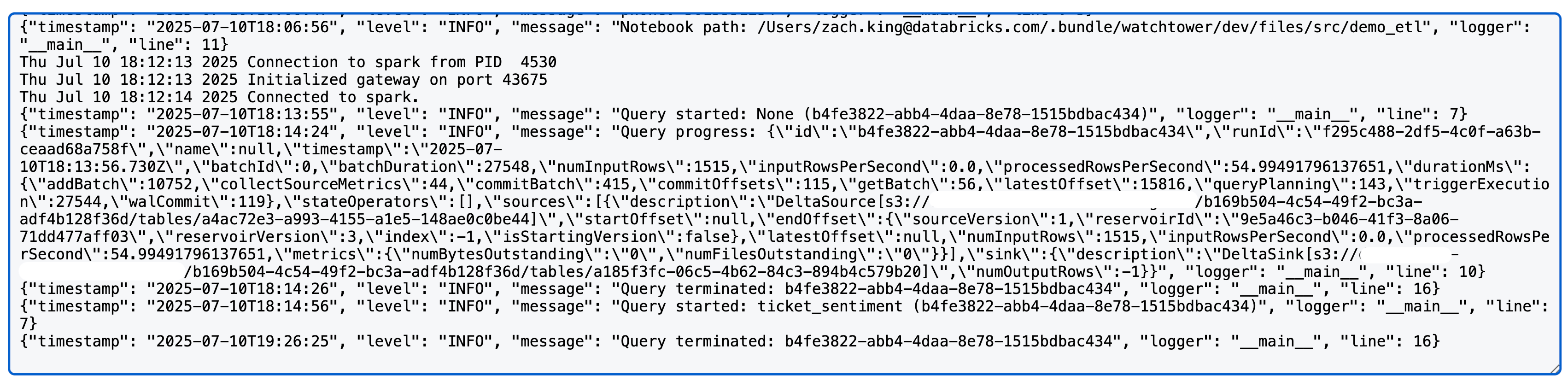
Après avoir exécuté une requête Spark structured streaming, vous verrez quelque chose comme suit dans les logs log4j (remarque : nous utilisons ici une source et un sink Delta ; les métriques détaillées peuvent varier selon la source/le sink) :
Configuration des logs Log4j de Spark
Jusqu'à présent, nous n'avons affecté que le logging de notre propre code. Cependant, en examinant les logs du driver du cluster, nous constatons que de nombreux autres logs – la majorité, en fait – proviennent des internes de Spark. Lorsque nous créons des loggers Python ou Scala dans notre code, cela n'influence pas les logs internes de Spark.
Nous allons maintenant examiner comment configurer les logs Spark pour le nœud driver afin qu'ils utilisent un format JSON standard que nous pouvons facilement analyser.
Log4j utilise un fichier de configuration local pour contrôler le formatage et les niveaux de log, et nous pouvons modifier cette configuration à l'aide d'un script d'initialisation de cluster (AWS | Azure | GCP). Veuillez noter qu'avant DBR 11.0, Log4j v1.x était utilisé, qui utilise un fichier Java Properties (log4j.properties). DBR 11.0+ utilise Log4j v2.x qui utilise un fichier XML (log4j2.xml) à la place.
Le fichier log4j2.xml par défaut sur les nœuds driver Databricks utilise un `PatternLayout` pour un format de log de base :
Nous allons remplacer ceci par le JsonTemplateLayout en utilisant le script d'initialisation suivant :
Ce script d'initialisation remplace simplement le PatternLayout par le JsonTemplateLayout. Notez que les scripts d'initialisation s'exécutent sur tous les nœuds du cluster, y compris les nœuds worker ; dans cet exemple, nous configurons uniquement les logs du pilote par souci de verbosité et parce que nous n'allons ingérer que les logs du pilote plus tard. Cependant, le fichier de configuration peut également être trouvé sur les nœuds worker à l'adresse /home/ubuntu/databricks/spark/dbconf/log4j/executor/log4j.properties.
Vous pouvez ajouter à ce script selon vos besoins, ou utiliser cat $LOG4J2_PATH pour voir le contenu complet du fichier original afin de faciliter les modifications.
Ensuite, nous allons téléverser ce script d'initialisation dans le volume Unity Catalog. Pour l'organisation, nous allons créer un volume séparé plutôt que de réutiliser notre volume de logs bruts de tout à l'heure, et cela peut être réalisé dans Terraform comme suit :
Cela créera le volume et téléversera automatiquement le script d'initialisation.
Mais nous devons encore configurer notre cluster pour utiliser ce script d'initialisation. Auparavant, nous avons utilisé une politique de cluster pour imposer la destination de livraison des logs, et nous pouvons faire le même type d'application pour ce script d'initialisation afin de garantir que nos logs Spark aient toujours le format JSON structuré. Nous allons modifier le JSON de la politique précédente en ajoutant ce qui suit :
Encore une fois, l'utilisation d'une valeur fixe garantit que le script d'initialisation sera toujours défini sur le cluster.
Maintenant, si nous réexécutons notre code Spark précédent, nous pouvons voir tous les logs du pilote dans la section Log4j joliment formatés en JSON !
Ingestion des logs
À ce stade, nous avons abandonné les instructions `print` de base pour la journalisation structurée, nous l'avons unifiée avec les logs Spark et nous avons acheminé nos logs vers un volume central. C'est déjà utile pour parcourir et télécharger les fichiers de logs en utilisant le Catalog Explorer ou le Databricks CLI : databricks fs cp dbfs:/Volumes/watchtower/default/cluster_logs/cluster-logs/$CLUSTER_ID . --recursive.
Cependant, la véritable valeur de ce hub de journalisation se voit lorsque nous ingérons les logs dans une table Unity Catalog. Cela boucle la boucle et nous donne une table sur laquelle nous pouvons écrire des requêtes expressives, effectuer des agrégations et même détecter des problèmes de performance courants. Tout cela, nous allons y arriver sous peu !
L'ingestion des logs est facile grâce aux pipelines déclaratifs Lakeflow, et nous allons employer une architecture médaillon avec Auto Loader pour charger les données de manière incrémentielle.
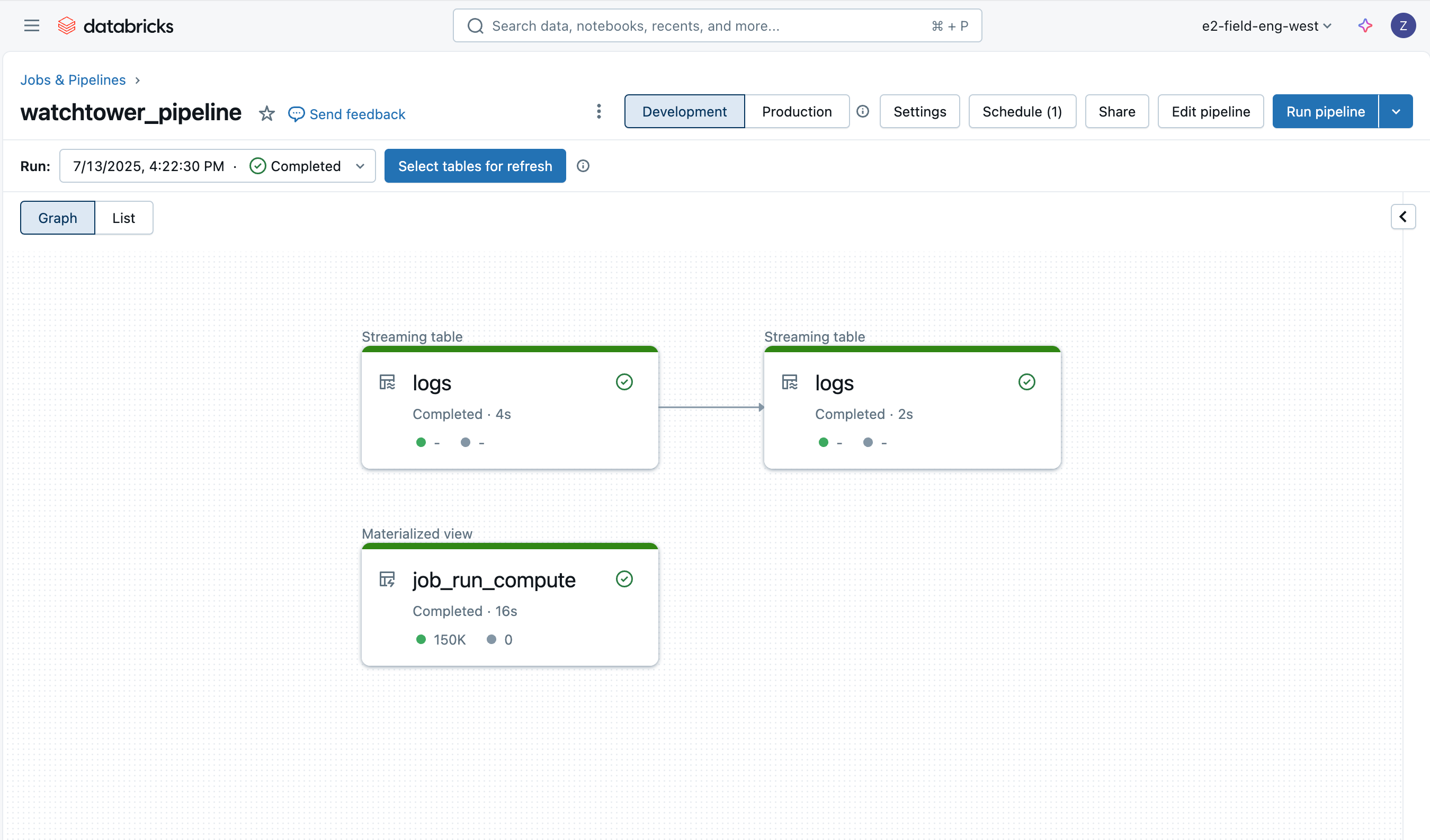
Logs Bronze
La première table est simplement une table bronze pour charger les données brutes des logs du pilote, en ajoutant des colonnes supplémentaires telles que le nom du fichier, la taille, le chemin et l'heure de dernière modification.
En utilisant les attentes des pipelines déclaratifs Lakeflow (AWS | Azure | GCP), nous obtenons également une surveillance native de la qualité des données. Nous verrons d'autres vérifications de qualité des données sur les autres tables.
Logs Silver
La table suivante (silver) est plus critique ; nous souhaitons analyser chaque ligne de texte des logs, en extrayant des informations telles que le niveau de log, l'horodatage du log, l'ID du cluster et la source du log (stdout/stderr/log4j).
Remarque : bien que nous ayons configuré la journalisation JSON autant que possible, nous aurons toujours un certain degré de texte brut sous forme non structurée provenant d'autres outils lancés au démarrage. La plupart d'entre eux seront dans stdout, et notre transformation silver démontre une façon de garder l'analyse flexible, en essayant d'analyser le message en tant que JSON et en revenant à regex uniquement lorsque nécessaire.
IDs de calcul
La dernière table de notre pipeline est une vue matérialisée construite sur les tables système Databricks. Elle stockera les IDs de calcul utilisés par chaque exécution de tâche et simplifiera les jointures futures lorsque nous souhaiterons récupérer l'ID de la tâche qui a produit certains logs. Notez qu'une seule tâche peut avoir plusieurs clusters, ainsi que des tâches SQL qui s'exécutent sur un entrepôt plutôt que sur un cluster de tâches, d'où l'utilité de précalculer cette référence.
Déploiement du pipeline
Le pipeline peut être déployé via l'interface utilisateur, Terraform ou dans notre bundle d'actifs. Nous utiliserons le bundle d'actifs et fournirons le YAML de ressource suivant :
Analyser les journaux avec un tableau de bord IA/BI
Enfin, nous pouvons interroger les données de journalisation sur les jobs, les exécutions de jobs, les clusters et les espaces de travail. Grâce aux optimisations des tables gérées par Unity Catalog, ces requêtes seront également rapides et évolutives. Voyons quelques exemples.
Top N Erreurs
Cette requête trouve les erreurs les plus courantes rencontrées, aidant à prioriser et à améliorer la gestion des erreurs. Elle peut également être un indicateur utile pour rédiger des runbooks couvrant les problèmes les plus fréquents.
Top N Jobs par Erreurs
Cette requête classe les jobs par nombre d'erreurs observées, aidant à identifier les jobs les plus problématiques.
Tableau de bord IA/BI
Si nous intégrons ces requêtes dans un tableau de bord IA/BI Databricks, nous avons maintenant une interface centrale pour rechercher et filtrer tous les journaux, détecter les problèmes courants et dépanner.
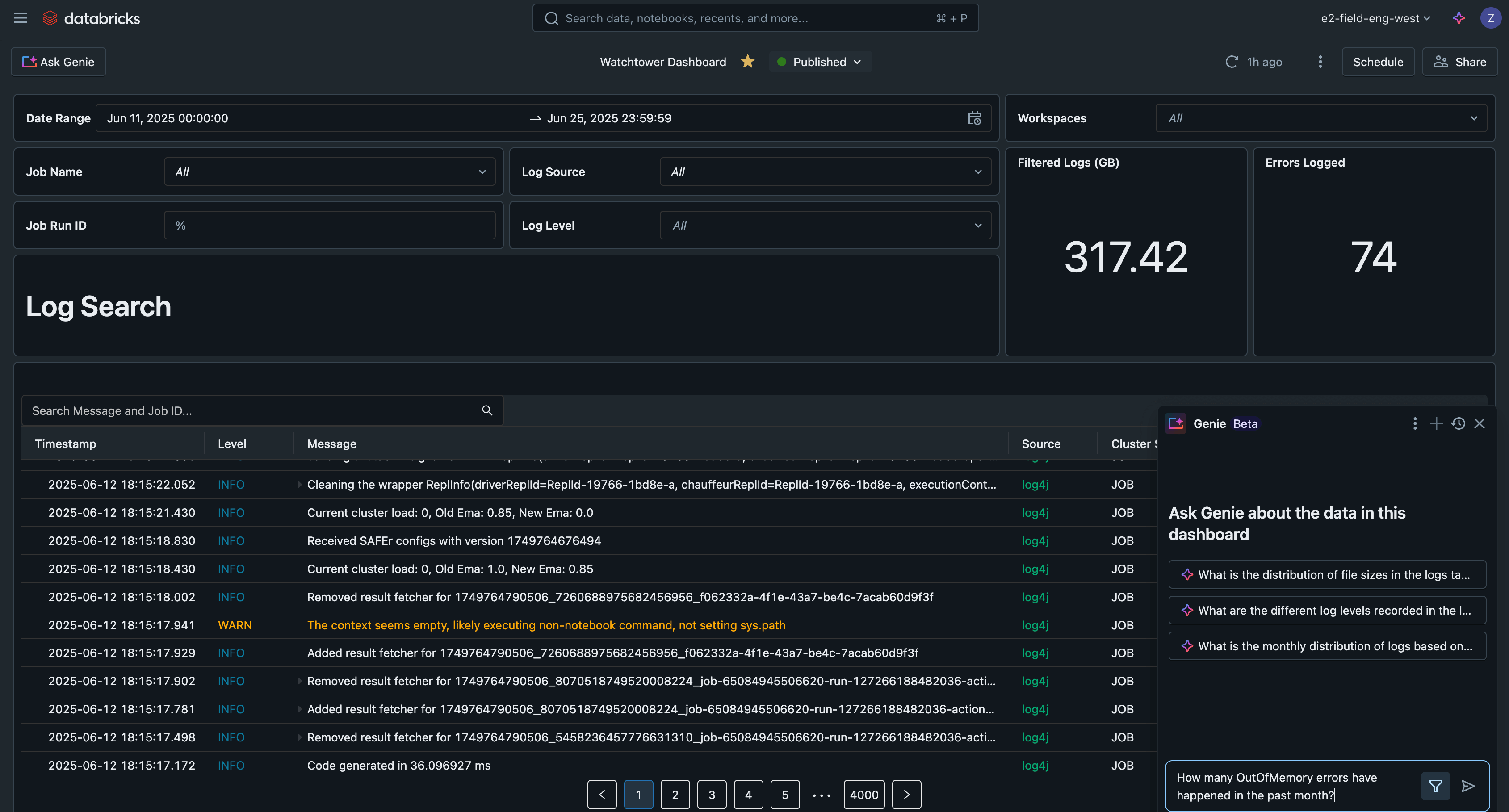
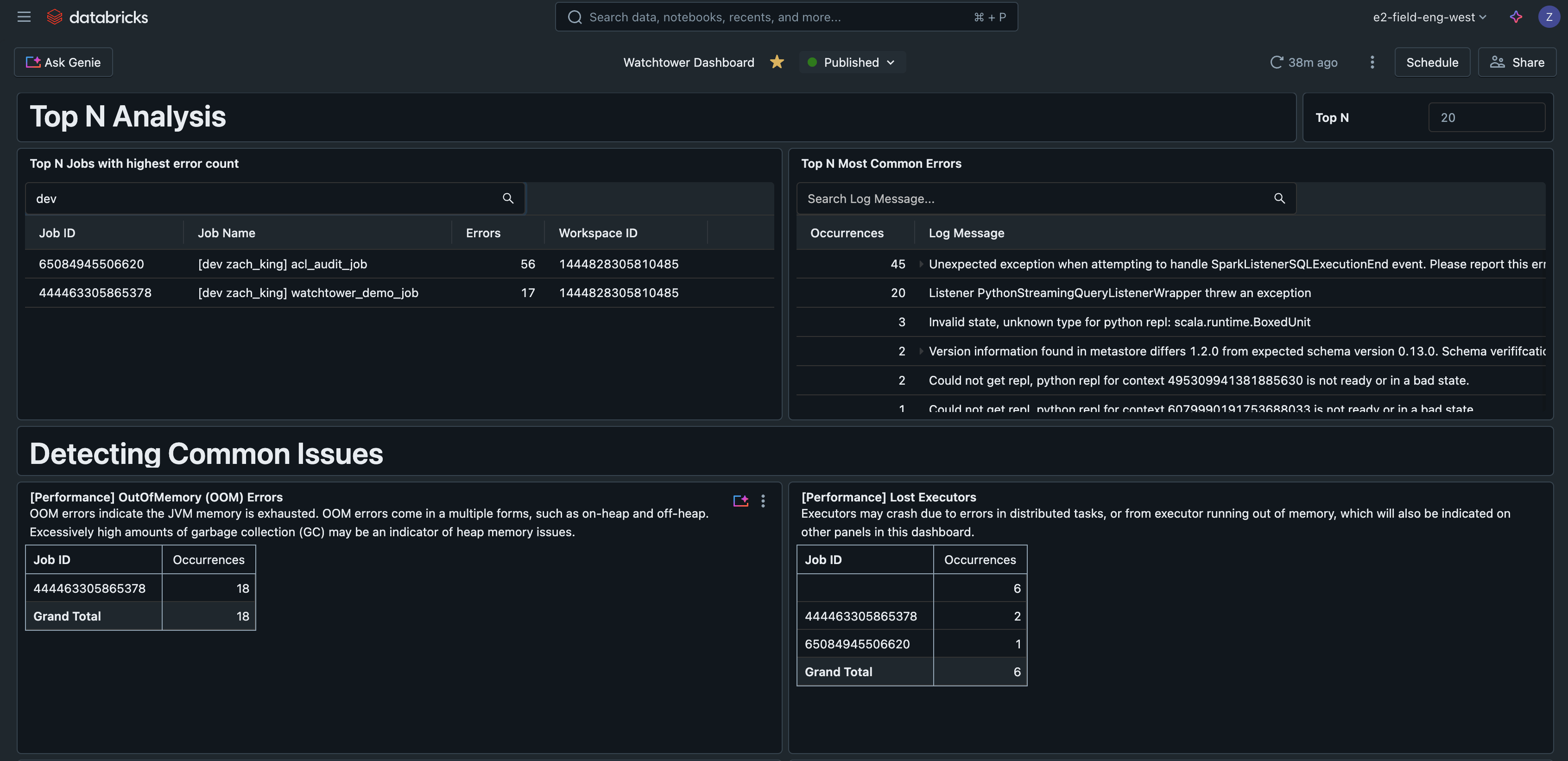
Ce tableau de bord IA/BI d'exemple est disponible avec tout le code de cette solution sur GitHub.
Scénarios du monde réel
Comme nous l'avons démontré dans le tableau de bord de référence, il existe de nombreux cas d'utilisation pratiques qu'une solution de journalisation comme celle-ci prend en charge, tels que :
- Rechercher des journaux dans toutes les exécutions d'un seul job
- Rechercher des journaux dans tous les jobs
- Analyser les journaux pour les erreurs les plus courantes
- Trouver les jobs avec le plus grand nombre d'erreurs
- Surveiller les problèmes de performance ou les avertissements :
- Dépassement de la mémoire du GC (Garbage Collection)
- Débordement Spark (Spark spill)
- Détecter les PII (Informations Personnellement Identifiables) dans les journaux
Dans un scénario réaliste, les praticiens naviguent manuellement d'une exécution de job à l'autre pour comprendre les erreurs et ne savent pas comment prioriser les alertes. En établissant non seulement des journaux robustes mais aussi une table standard pour les stocker, les praticiens peuvent simplement interroger les journaux pour l'erreur la plus courante à prioriser. Supposons qu'il y ait 1 exécution de job échouée en raison d'une erreur OutOfMemory, tandis qu'il y a 10 jobs échoués en raison d'une erreur de permission soudaine lorsque SELECT a été révoqué involontairement du principal de service ; votre équipe d'astreinte est normalement fatiguée par la vague d'alertes, mais est maintenant capable de réaliser rapidement que l'erreur de permission est une priorité plus élevée et commence à travailler pour résoudre le problème afin de rétablir les 10 jobs.
De même, les praticiens doivent souvent vérifier les journaux de plusieurs exécutions du même job pour faire des comparaisons. Un exemple concret est de corréler les horodatages d'un message de journal spécifique de chaque exécution par lots du job, avec une autre métrique ou un graphique (par exemple, quand « batch completed » a été enregistré par rapport à un graphique de débit de requêtes sur une API que vous avez appelée). L'ingestion des journaux simplifie cela, nous pouvons donc interroger la table et filtrer par l'ID du job, et éventuellement une liste d'ID d'exécution de job, sans avoir à cliquer sur chaque exécution une par une.
Considérations opérationnelles
- Les journaux de cluster sont livrés toutes les cinq minutes et compressés (gzipped) chaque heure dans la destination de votre choix.
- N'oubliez pas d'utiliser les tables gérées par Unity Catalog avec Predictive Optimization et Liquid Clustering pour obtenir les meilleures performances sur les tables.
- Les journaux bruts n'ont pas besoin d'être stockés indéfiniment, ce qui est le comportement par défaut lorsque la livraison de journaux de cluster est utilisée. Dans notre pipeline Declarative Pipelines, utilisez l'option Auto Loader
cloudFiles.cleanSourcepour supprimer les fichiers après une période de rétention spécifiée, également définie commecloudFiles.cleanSource.retentionDuration. Vous pouvez également utiliser les règles de cycle de vie du stockage cloud. - Les journaux des exécuteurs peuvent également être configurés et ingérés, mais ils ne sont généralement pas nécessaires car la plupart des erreurs sont de toute façon propagées au pilote.
- Envisagez d'ajouter des alertes Databricks SQL (AWS | Azure | GCP) pour une alerte automatisée basée sur la table de journaux ingérée.
- Les pipelines déclaratifs Lakeflow ont leurs propres journaux d'événements, que vous pouvez utiliser pour surveiller et inspecter l'activité du pipeline. Ce journal d'événements peut également être écrit dans Unity Catalog.
Intégration et tâches à réaliser
Les clients peuvent également souhaiter intégrer leurs journaux avec des outils de journalisation populaires tels que Loki, Logstash, ou AWS CloudWatch. Bien que chacun ait ses propres exigences en matière d'authentification, de configuration et de connectivité, toutes suivraient un schéma très similaire en utilisant le script d'initialisation du cluster pour configurer et souvent exécuter un agent de transfert de journaux.
Points clés à retenir
Pour récapituler, les leçons clés sont :
- Utilisez des frameworks de journalisation standardisés, pas des instructions print, en production.
- Utilisez des scripts d'initialisation à l'échelle du cluster pour personnaliser la configuration Log4j.
- Configurez la livraison des journaux du cluster pour centraliser les journaux.
- Utilisez les tables gérées par Unity Catalog avec Predictive Optimization et Liquid Clustering pour les meilleures performances des tables.
- Databricks vous permet d'ingérer et d'enrichir les journaux pour une analyse plus approfondie.
Prochaines étapes
Commencez à produire vos journaux dès aujourd'hui en consultant le dépôt GitHub pour cette solution complète ici : https://github.com/databricks-industry-solutions/watchtower !
Les Architectes de Solutions de Livraison (DSA) de Databricks accélèrent les initiatives de Données et d'IA dans les organisations. Ils fournissent un leadership architectural, optimisent les plateformes en termes de coût et de performance, améliorent l'expérience des développeurs et pilotent l'exécution réussie des projets. Les DSA comblent le fossé entre le déploiement initial et les solutions de qualité de production, en travaillant en étroite collaboration avec diverses équipes, y compris l'ingénierie des données, les responsables techniques, les dirigeants et d'autres parties prenantes pour assurer des solutions sur mesure et une valeur plus rapide. Pour bénéficier d'un plan d'exécution personnalisé, de conseils stratégiques et d'un soutien tout au long de votre parcours de données et d'IA de la part d'un DSA, veuillez contacter votre équipe de compte Databricks.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.