Les contraintes de clé primaire et de clé étrangère sont disponibles en GA et permettent désormais des requêtes plus rapides
par Xinyi Yu, Justin Talbot et Serge Rielau
Databricks est ravi d'annoncer la disponibilité générale (GA) des contraintes de clé primaire (PK) et de clé étrangère (FK), à partir de Databricks Runtime 15.2 et Databricks SQL 2024.30. Cette version fait suite à une préversion publique très réussie, adoptée par des centaines de clients actifs chaque semaine, et représente une étape importante dans l'amélioration de l'intégrité des données et de la gestion des données relationnelles au sein du Lakehouse.
De plus, Databricks peut désormais utiliser ces contraintes pour optimiser les requêtes et éliminer les opérations inutiles du plan de requête, offrant ainsi des performances beaucoup plus rapides.
Contraintes de clé primaire et de clé étrangère
Les clés primaires (PK) et les clés étrangères (FK) sont des éléments essentiels des bases de données relationnelles, servant de blocs de construction fondamentaux pour la modélisation des données. Elles fournissent des informations sur les relations de données dans le schéma aux utilisateurs, aux outils et aux applications ; et permettent des optimisations qui tirent parti des contraintes pour accélérer les requêtes. Les clés primaires et étrangères sont désormais généralement disponibles pour vos tables Delta Lake hébergées dans Unity Catalog.
Langage SQL
Vous pouvez définir des contraintes lors de la création d'une table :
Dans l'exemple ci-dessus, nous définissons une contrainte de clé primaire sur la colonne UserID. Databricks prend également en charge les contraintes sur des groupes de colonnes.
Vous pouvez également modifier des tables Delta existantes pour ajouter ou supprimer des contraintes :
Ici, nous créons la clé primaire nommée products_pk sur la colonne non nulle ProductID dans une table existante. Pour exécuter cette opération avec succès, vous devez être le propriétaire de la table. Notez que les noms de contraintes doivent être uniques dans le schéma.
La commande suivante supprime la clé primaire en spécifiant son nom.
Le même processus s'applique aux clés étrangères. La table suivante définit deux clés étrangères lors de la création de la table :
Veuillez vous référer à la documentation sur les instructions CREATE TABLE et ALTER TABLE pour plus de détails sur la syntaxe et les opérations relatives aux contraintes.
Les contraintes de clé primaire et de clé étrangère ne sont pas appliquées dans le moteur Databricks, mais elles peuvent être utiles pour indiquer une relation d'intégrité des données qui est censée être vraie. Databricks peut plutôt appliquer les contraintes de clé primaire en amont dans le cadre du pipeline d'ingestion. Voir Gérer la qualité des données avec Delta Live Tables pour plus d'informations sur les contraintes appliquées. Databricks prend également en charge les contraintes NOT NULL et CHECK appliquées (voir la documentation sur les contraintes pour plus d'informations).
Écosyst�ème des partenaires
Des outils et applications tels que les dernières versions de Tableau et PowerBI peuvent importer et utiliser automatiquement vos relations de clé primaire et de clé étrangère à partir de Databricks via les connecteurs JDBC et ODBC.
Afficher les contraintes
Il existe plusieurs façons d'afficher les contraintes de clé primaire et de clé étrangère définies dans la table. Vous pouvez également simplement utiliser des commandes SQL pour afficher les informations de contrainte avec la commande DESCRIBE TABLE EXTENDED :
Catalog Explorer et diagramme de relations d'entités
Vous pouvez également afficher les informations de contrainte via le Catalog Explorer :
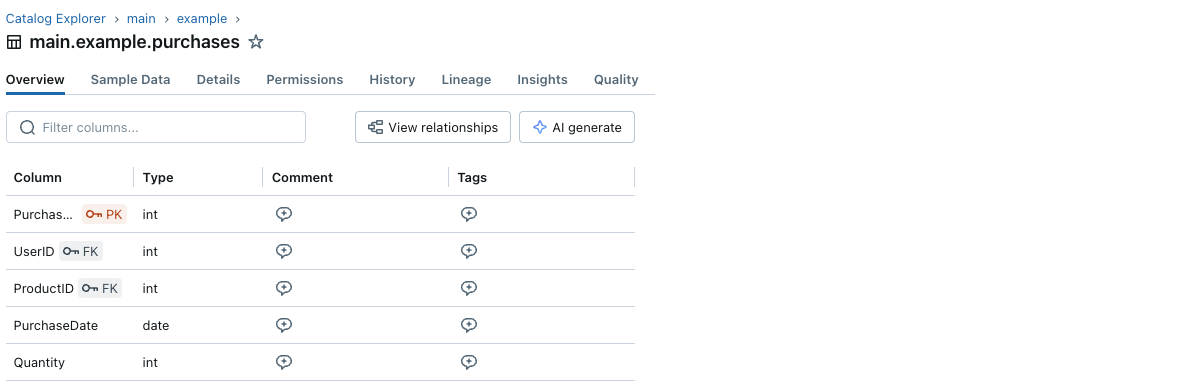
Chaque colonne de clé primaire et de clé étrangère a une petite icône de clé à côté de son nom.
Et vous pouvez visualiser les informations de clé primaire et étrangère ainsi que les relations entre les tables avec le diagramme de relations d'entités dans Catalog Explorer. Ci-dessous un exemple d'une table purchases référençant deux tables, users et products :

INFORMATION SCHEMA
Les tables INFORMATION_SCHEMA suivantes fournissent également des informations sur les contraintes :
TABLE_CONSTRAINTS: décrit les métadonnées de toutes les contraintes de clé primaire et de clé étrangère dans le catalogue.KEY_COLUMN_USAGE: liste les colonnes des contraintes de clé primaire ou étrangère dans le catalogue.CONSTRAINT_TABLE_USAGE: décrit les contraintes référençant les tables dans le catalogue.CONSTRAINT_COLUMN_USAGE: décrit les contraintes référençant les colonnes dans le catalogue.REFERENTIAL_CONSTRAINTS: décrit les contraintes référentielles (clés étrangères) définies dans le catalogue.
Utiliser l'option RELY pour activer les optimisations
Si vous savez que la contrainte de clé primaire est valide (par exemple, parce que votre pipeline de données ou votre travail ETL l'applique), vous pouvez activer les optimisations basées sur la contrainte en la spécifiant avec l'option RELY, comme ceci :
L'utilisation de l'option RELY permet à Databricks d'optimiser les requêtes d'une manière qui dépend de la validité de la contrainte, car vous garantissez que l'intégrité des données est maintenue. Soyez prudent ici, car si une contrainte est marquée comme RELY mais que les données violent la contrainte, vos requêtes peuvent renvoyer des résultats incorrects.
Lorsque vous ne spécifiez pas l'option RELY pour une contrainte, la valeur par défaut est NORELY. Dans ce cas, les contraintes peuvent toujours être utilisées à des fins d'information ou statistiques, mais les requêtes ne s'appuieront pas sur elles pour s'exécuter correctement.
L'option RELY et les optimisations qui l'utilisent sont actuellement disponibles pour les clés primaires, et seront également bientôt disponibles pour les clés étrangères.
Vous pouvez modifier la clé primaire d'une table pour changer si elle est RELY ou NORELY en utilisant ALTER TABLE, par exemple :
Accélérez vos requêtes en éliminant les agrégations inutiles
Une optimisation simple que nous pouvons faire avec les contraintes de clé primaire RELY est d'éliminer les agrégations inutiles. Par exemple, dans une requête qui applique une opération distincte sur une table avec une clé primaire utilisant RELY :
Nous pouvons supprimer l'opération DISTINCT inutile :
Comme vous pouvez le voir, cette requête repose sur la validité de la contrainte de clé primaire RELY - s'il y a des identifiants clients en double dans la table client, alors la requête transformée renverra des résultats dupliqués incorrects. Il vous incombe de garantir la validité de la contrainte si vous définissez l'option RELY.
Si la clé primaire est NORELY (par défaut), l'optimiseur ne supprimera pas l'opération DISTINCT de la requête. Elle peut alors s'exécuter plus lentement, mais renvoie toujours des résultats corrects, même en présence de doublons. Si la clé primaire est RELY, Databricks peut supprimer l'opération DISTINCT, ce qui peut considérablement accélérer la requête - environ 2 fois plus vite pour l'exemple ci-dessus.
Accélérez vos requêtes en éliminant les jointures inutiles
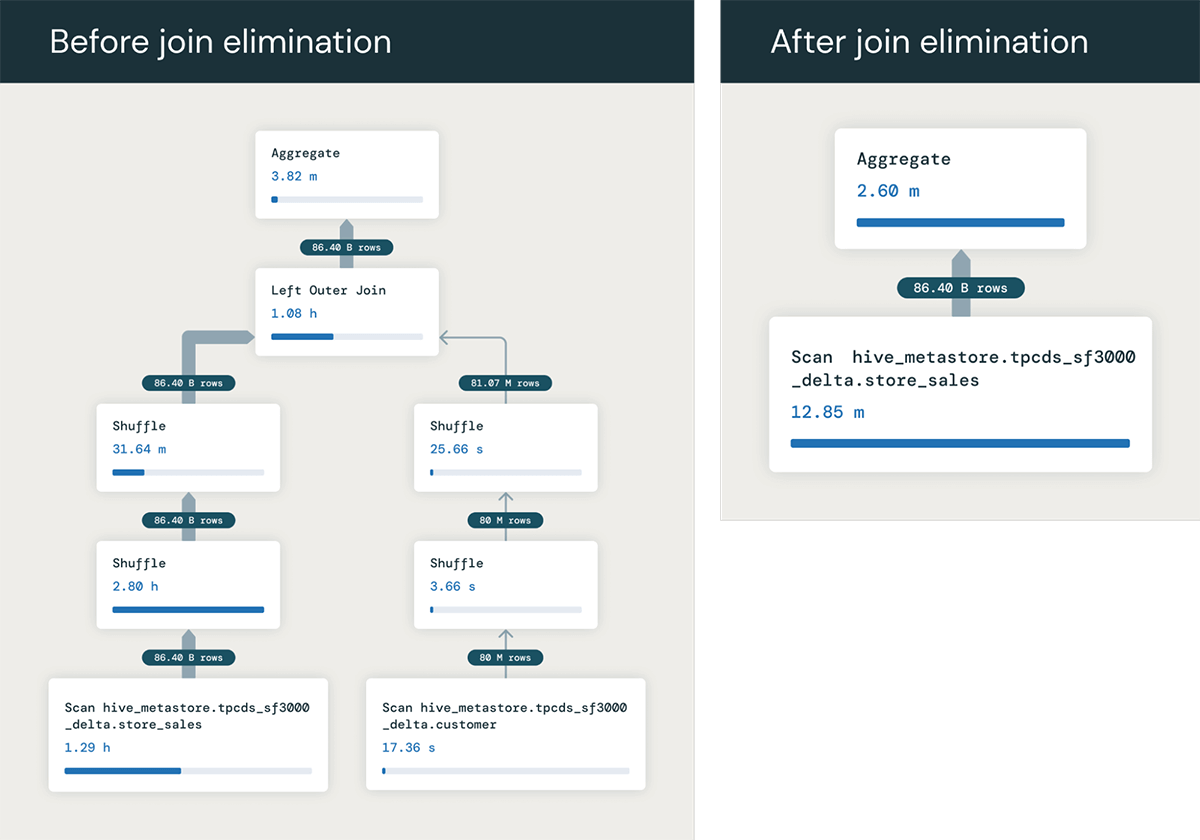
Une autre optimisation très utile que nous pouvons effectuer avec les clés primaires RELY est l'élimination des jointures inutiles. Si une requête joint une table qui n'est référencée nulle part sauf dans la condition de jointure, l'optimiseur peut déterminer que la jointure est inutile et la supprimer du plan de requête.
Pour donner un exemple, supposons que nous ayons une requête joignant deux tables, store_sales et customer, jointes sur la clé primaire de la table client PRIMARY KEY (c_customer_sk) RELY.
Si nous n'avions pas la clé primaire, chaque ligne de store_sales pourrait potentiellement correspondre à plusieurs lignes dans customer, et nous devrions exécuter la jointure pour calculer la valeur SUM correcte. Mais comme la table customer est jointe sur sa clé primaire, nous savons que la jointure produira une ligne pour chaque ligne de store_sales.
La requête n'a donc besoin que de la colonne ss_quantity de la table de faits store_sales. Par conséquent, l'optimiseur de requête peut éliminer entièrement la jointure de la requête, la transformant en :
Cela s'exécute beaucoup plus rapidement en évitant toute la jointure - dans cet exemple, nous observons que l'optimisation accélère la requête de 1,5 minute à 6 secondes !. Et les avantages peuvent être encore plus importants lorsque la jointure implique de nombreuses tables qui peuvent être éliminées !
Vous pourriez demander pourquoi quelqu'un exécuterait une requête comme celle-ci ? C'est en fait beaucoup plus courant que vous ne le pensez ! Une raison fréquente est que les utilisateurs créent des vues qui joignent plusieurs tables, comme joindre de nombreuses tables de faits et de dimensions. Ils écrivent des requêtes sur ces vues qui utilisent souvent des colonnes de certaines tables seulement, pas toutes - et ainsi l'optimiseur peut éliminer les jointures avec les tables qui ne sont pas nécessaires dans chaque requête. Ce modèle est également courant dans de nombreux outils de Business Intelligence (BI), qui génèrent souvent des requêtes joignant de nombreuses tables dans un schéma, même lorsqu'une requête n'utilise que des colonnes de certaines tables.
Conclusion
Depuis sa préversion publique, plus de 2600 clients Databricks ont utilisé les contraintes de clé primaire et de clé étrangère. Aujourd'hui, nous sommes ravis d'annoncer la disponibilité générale de cette fonctionnalité, marquant une nouvelle étape dans notre engagement à améliorer la gestion et l'intégrité des données dans Databricks.
De plus, Databricks tire désormais parti des contraintes de clé avec l'option RELY pour optimiser les requêtes, notamment en éliminant les agrégations et les jointures inutiles, ce qui se traduit par des performances de requête beaucoup plus rapides.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.