Publier sur plusieurs catalogues et schémas à partir d'un seul pipeline DLT
Simplifiez la syntaxe, optimisez les coûts et réduisez la complexité opérationnelle
par Zoé Durand, Jonathan Chang et Matt Jones
- Prise en charge multi-schéma et multi-catalogue : publiez sur plusieurs schémas et catalogues à partir d'un seul pipeline DLT.
- Syntaxe simplifiée et coûts réduits : éliminez le mot-clé LIVE et réduisez les frais d'infrastructure.
- Meilleure observabilité : publiez les journaux d'événements sur Unity Catalog et gérez les données à travers les emplacements avec SQL et Python.
DLT offre une plateforme robuste pour créer des pipelines de traitement de données fiables, maintenables et testables au sein de Databricks. En tirant parti de son cadre déclaratif et en provisionnant automatiquement une puissance de calcul serverless optimale, DLT simplifie les complexités du streaming, de la transformation et de la gestion des données, offrant ainsi évolutivité et efficacité pour les flux de travail de données modernes.
Nous sommes ravis d'annoncer une amélioration très attendue : la possibilité de publier des tables dans plusieurs schémas et catalogues au sein d'un même pipeline DLT. Cette capacité réduit la complexité opérationnelle, diminue les coûts et simplifie la gestion des données en vous permettant de consolider votre architecture médaillon (Bronze, Argent, Or) en un seul pipeline tout en respectant les meilleures pratiques organisationnelles et de gouvernance.
Avec cette amélioration, vous pouvez :
- Simplifier la syntaxe des pipelines – Plus besoin de syntaxe
LIVEpour indiquer les dépendances entre les tables. Les noms de tables entièrement et partiellement qualifiés sont pris en charge, ainsi que les commandesUSE SCHEMAetUSE CATALOG, tout comme en SQL standard. - Réduire la complexité opérationnelle – Traitez et publiez toutes les tables au sein d'un pipeline DLT unifié, éliminant ainsi le besoin de pipelines distincts par schéma ou catalogue.
- Réduire les coûts – Minimisez les frais d'infrastructure en consolidant plusieurs charges de travail dans un seul pipeline.
- Améliorer l'observabilité – Publiez votre journal d'événements sous forme de table standard dans le metastore Unity Catalog pour une surveillance et une gouvernance améliorées.
“La possibilité de publier dans plusieurs catalogues et schémas à partir d'un seul pipeline DLT - et ne nécessitant plus le mot-clé LIVE - nous a aidés à standardiser les meilleures pratiques de pipeline, à rationaliser nos efforts de développement et à faciliter la transition facile des équipes des charges de travail non-DLT vers DLT dans le cadre de notre adoption à grande échelle par l'entreprise de ces outils.” —Ron DeFreitas, Principal Data Engineer, HealthVerity

Comment démarrer
Créer un pipeline
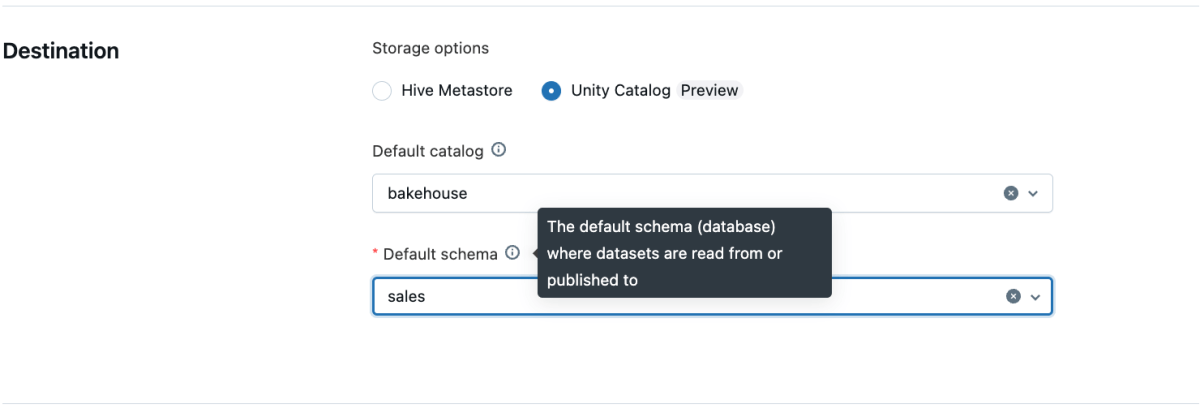
Tous les pipelines créés à partir de l'interface utilisateur prennent désormais en charge par défaut plusieurs catalogues et schémas. Vous pouvez définir un catalogue et un schéma par défaut au niveau du pipeline via l'interface utilisateur, l'API ou les Databricks Asset Bundles (DAB).
Depuis l'interface utilisateur :
- Créez un nouveau pipeline comme d'habitude.
- Définissez le catalogue et le schéma par défaut dans les paramètres du pipeline.
Depuis l'API :
Si vous créez un pipeline par programmation, vous pouvez activer cette fonctionnalité en spécifiant le champ schema dans PipelineSettings. Cela remplace le champ target existant, garantissant que les jeux de données peuvent être publiés dans plusieurs catalogues et schémas.
Pour créer un pipeline avec cette fonctionnalité via l'API, vous pouvez suivre cet exemple de code (Note : l'authentification par jeton d'accès personnel doit être activée pour l'espace de travail) :
En définissant le champ schema, le pipeline prendra automatiquement en charge la publication de tables dans plusieurs catalogues et schémas sans nécessiter le mot-clé LIVE.
Depuis le DAB
- Assurez-vous que votre CLI Databricks est de version v0.230.0 ou supérieure. Sinon, mettez à niveau la CLI en suivant la documentation.
- Configurez l'environnement Databricks Asset Bundle (DAB) en suivant le tutoriel. En suivant ces étapes, vous devriez avoir un répertoire DAB généré par la CLI Databricks contenant tous les fichiers de configuration et de code source.
- Trouvez le fichier YAML qui définit le pipeline DLT sous :
<votre dossier dab>/<ressource>/<nom du pipeline>_pipeline.yml - Définissez le champ
schemadans le fichier YAML du pipeline et supprimez le champtargets'il existe. - Exécutez “
databricks bundle validate“ pour valider la configuration du DAB. - Exécutez “
databricks bundle deploy -t <environment>“ pour déployer votre premier pipeline DPM !
“La fonctionnalité fonctionne exactement comme nous l'attendions ! J'ai pu diviser les différents jeux de données au sein de DLT dans nos schémas de staging, core et UDM (essentiellement une configuration bronze, silver, gold) au sein d'un seul pipeline.” —Florian Duhme, Expert Data Software Developer, Arvato

Publication de tables dans plusieurs catalogues et schémas
Une fois votre pipeline configuré, vous pouvez définir des tables en utilisant des noms entièrement ou partiellement qualifiés en SQL et en Python.
Exemple SQL
Exemple Python
Lecture des jeux de données
Vous pouvez référencer des jeux de données en utilisant des noms entièrement ou partiellement qualifiés, le mot-clé LIVE étant facultatif pour la compatibilité descendante.
Exemple SQL
Exemple Python
Modifications du comportement de l'API
Avec cette nouvelle fonctionnalité, les méthodes d'API clés ont été mises à jour pour prendre en charge plus facilement plusieurs catalogues et schémas :
dlt.read() et dlt.read_stream()
Auparavant, ces méthodes ne pouvaient référencer que des jeux de données définis dans le pipeline actuel. Désormais, elles peuvent référencer des jeux de données dans plusieurs catalogues et schémas, en suivant automatiquement les dépendances si nécessaire. Cela facilite la création de pipelines qui intègrent des données provenant de différents emplacements sans configuration manuelle supplémentaire.
spark.read() et spark.readStream()
Dans le passé, ces méthodes nécessitaient des références explicites à des jeux de données externes, ce qui rendait les requêtes inter-catalogues plus complexes. Avec la nouvelle mise à jour, les dépendances sont désormais suivies automatiquement, et le schéma LIVE n'est plus requis. Cela simplifie le processus de lecture de données à partir de plusieurs sources au sein d'un même pipeline.
Utilisation de USE CATALOG et USE SCHEMA
La syntaxe Databricks SQL prend désormais en charge la définition dynamique des catalogues et schémas actifs, ce qui facilite la gestion des données dans plusieurs emplacements.
Exemple SQL
Exemple Python
Gestion des journaux d'événements dans Unity Catalog
Cette fonctionnalité permet également aux propriétaires de pipelines de publier les journaux d'événements dans le metastore Unity Catalog pour une meilleure observabilité. Pour activer cette option, spécifiez le champ event_log dans le JSON des paramètres du pipeline. Par exemple :
Avec cela, vous pouvez désormais émettre des GRANTS sur la table des journaux d'événements comme sur une table ordinaire :
Vous pouvez également créer une vue sur la table des journaux d'événements :
En plus de tout ce qui précède, vous pouvez également streamer à partir de la table des journaux d'événements :
Et ensuite ?
À l'avenir, ces améliorations deviendront la norme pour tous les nouveaux pipelines créés, que ce soit via l'interface utilisateur, l'API ou les Databricks Asset Bundles. De plus, un outil de migration sera bientôt disponible pour aider à la transition des pipelines existants vers le nouveau modèle de publication.
En savoir plus dans la documentation ici.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.