Repousser les limites des agents de données avec Genie
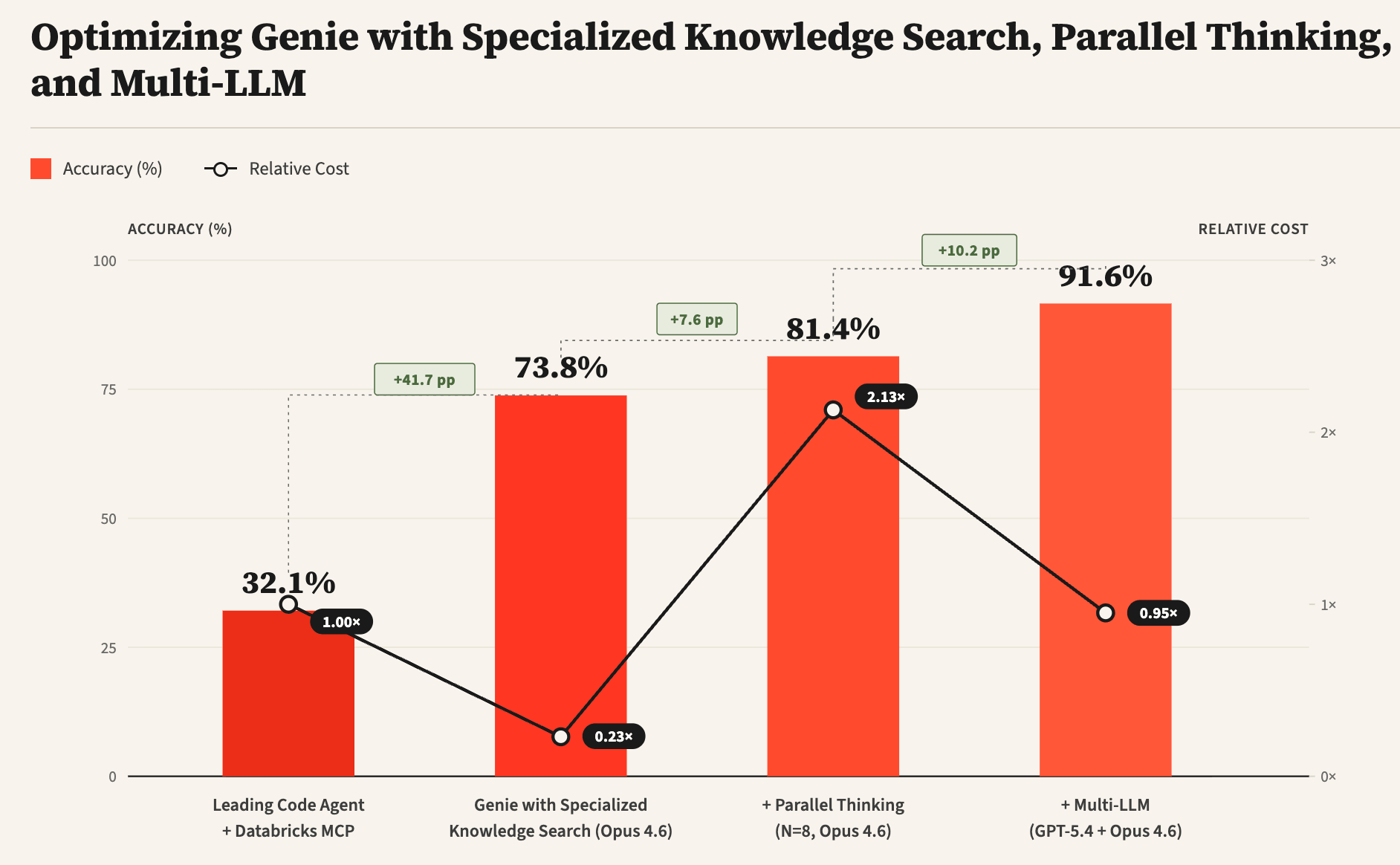
Genie est l'agent de données de pointe de Databricks, conçu pour répondre à des questions complexes sur les données d'entreprise, qu'elles soient structurées (tables, tableaux de bord, notebooks, etc.) ou non structurées (fichiers de l'espace de travail, Google Drive, Sharepoint, etc.). Ce blog décrit certains des défis uniques auxquels sont confrontés les agents de données et présente des techniques pour les aborder, notamment l'utilisation de la recherche de connaissances spécialisées, la pensée parallèle et les conceptions Multi-LLM. D'après nos expériences sur un benchmark interne de tâches d'analyse de données réelles, nous observons que ces techniques peuvent améliorer considérablement la précision globale de Genie par rapport à un agent de codage leader (de 32 % à plus de 90 %) tout en réduisant considérablement les coûts et la latence.
Défis clés pour les agents de données
Les agents de codage ont montré qu'un LLM puissant peut faire des choses incroyables de manière autonome lorsqu'il est équipé d'outils qui l'aident à comprendre le contexte du code. Alors que les agents de codage fonctionnent efficacement dans des environnements statiques et déterministes comme le système de fichiers d'un disque, les agents de données introduisent un paradigme entièrement nouveau. Les agents de données fonctionnent dans un lakehouse de données dynamique et en constante évolution qui englobe une richesse de contexte sémantique à travers des centaines de milliers de tables, de notebooks, de tableaux de bord et de documents.
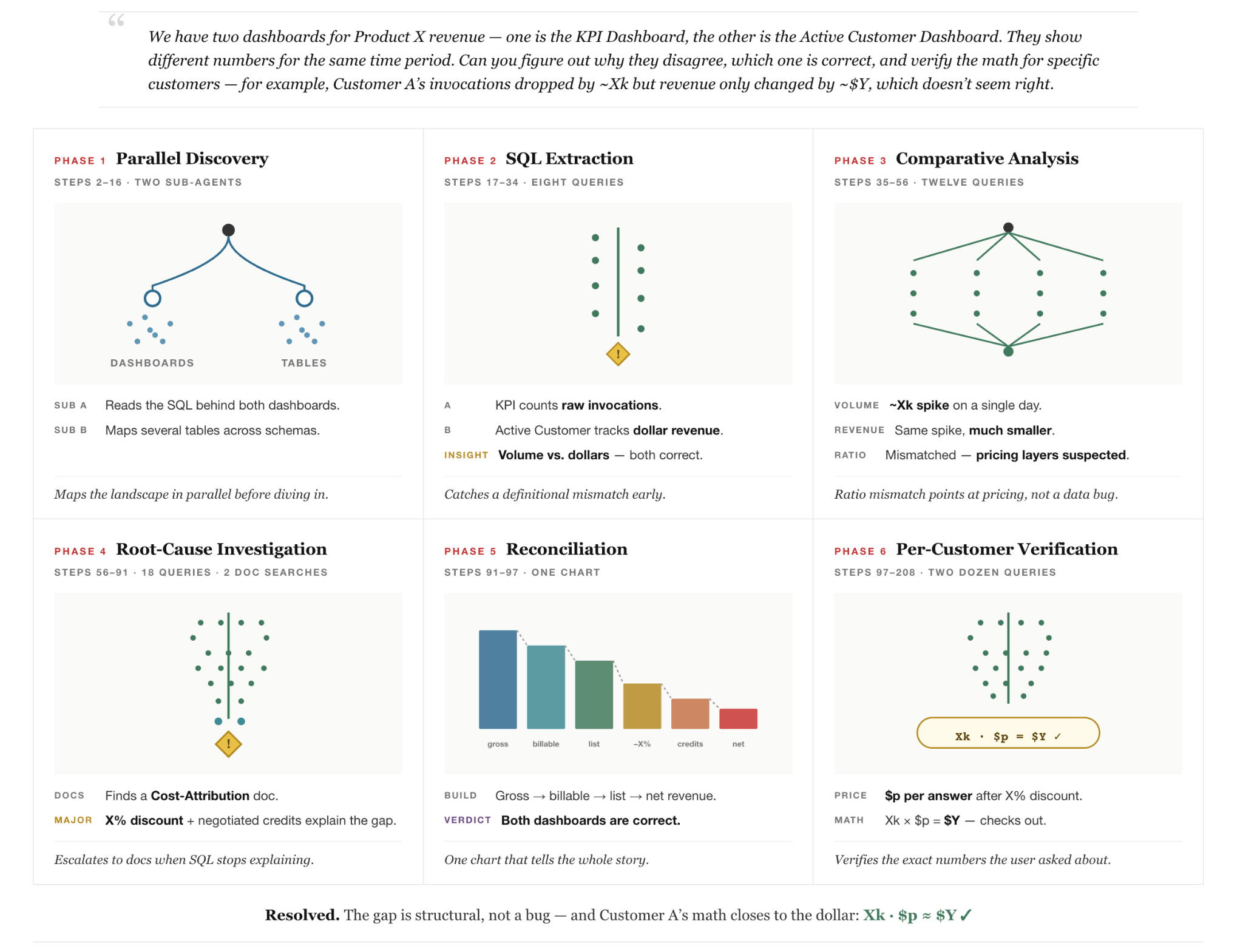
Par exemple, considérez une requête réelle (anonymisée) posée par un utilisateur interne dans la Figure 2 : l'utilisateur remarque que deux tableaux de bord d'entreprise rendant compte des revenus du même produit montrent des pics contradictoires à différentes dates et demande à l'agent d'expliquer pourquoi. Cette question raisonnable est trompeusement difficile car aucune source de données unique ne contient la réponse et la résolution de la question nécessite une découverte inter-systèmes à travers les tables, les documents internes et les tableaux de bord, ainsi qu'un raisonnement sur la façon dont les rapports multi-jours sont configurés. De plus, cela nécessite que l'agent examine les détails de tarification de l'entreprise pour trouver les tarifs contractuels. Enfin, cela nécessite que l'agent ait la capacité de se corriger automatiquement lorsque les calculs intermédiaires révèlent des hypothèses initiales incorrectes. La figure montre comment l'agent parvient à résoudre la tâche en procédant en différentes phases : (1) découverte parallèle de données multi-agents, (2) investigation des données, (3) boucle d'auto-correction et (4) vérification.
Comparé aux agents de codage, les agents de données présentent trois défis uniques clés :
- Échelle de la découverte de données : Trouver les bonnes sources de données pour répondre à la requête de l'utilisateur est l'un des plus grands défis, les clients d'entreprise disposant de millions de sources structurées et non structurées (telles que des tables, des tableaux de bord et des documents), une échelle qui brise les méthodes de recherche conventionnelles.
- Détermination des connaissances commerciales « source de vérité » : Répondre aux questions commerciales nécessite des connaissances approfondies et spécifiques tirées de nombreuses sources (par exemple, métadonnées de table, documents d'entreprise, messages internes) qui sont souvent obsolètes, contradictoires ou remplacées, obligeant l'agent à déterminer les informations les plus faisant autorité.
- Absence de tests vérifiables : Contrairement aux agents de codage qui peuvent utiliser des tests déterministes et vérifiables pour affiner itérativement le code, les agents de données n'ont pas de test correspondant car la « spécification » n'est que la requête utilisateur de haut niveau sans notion de la réponse correcte attendue. De plus, les requêtes peuvent ne pas toujours être répondables en raison de l'incomplétude des données, et il est important que les agents de données soient capables d'identifier de tels cas et de les signaler aux utilisateurs.
Avancées techniques clés
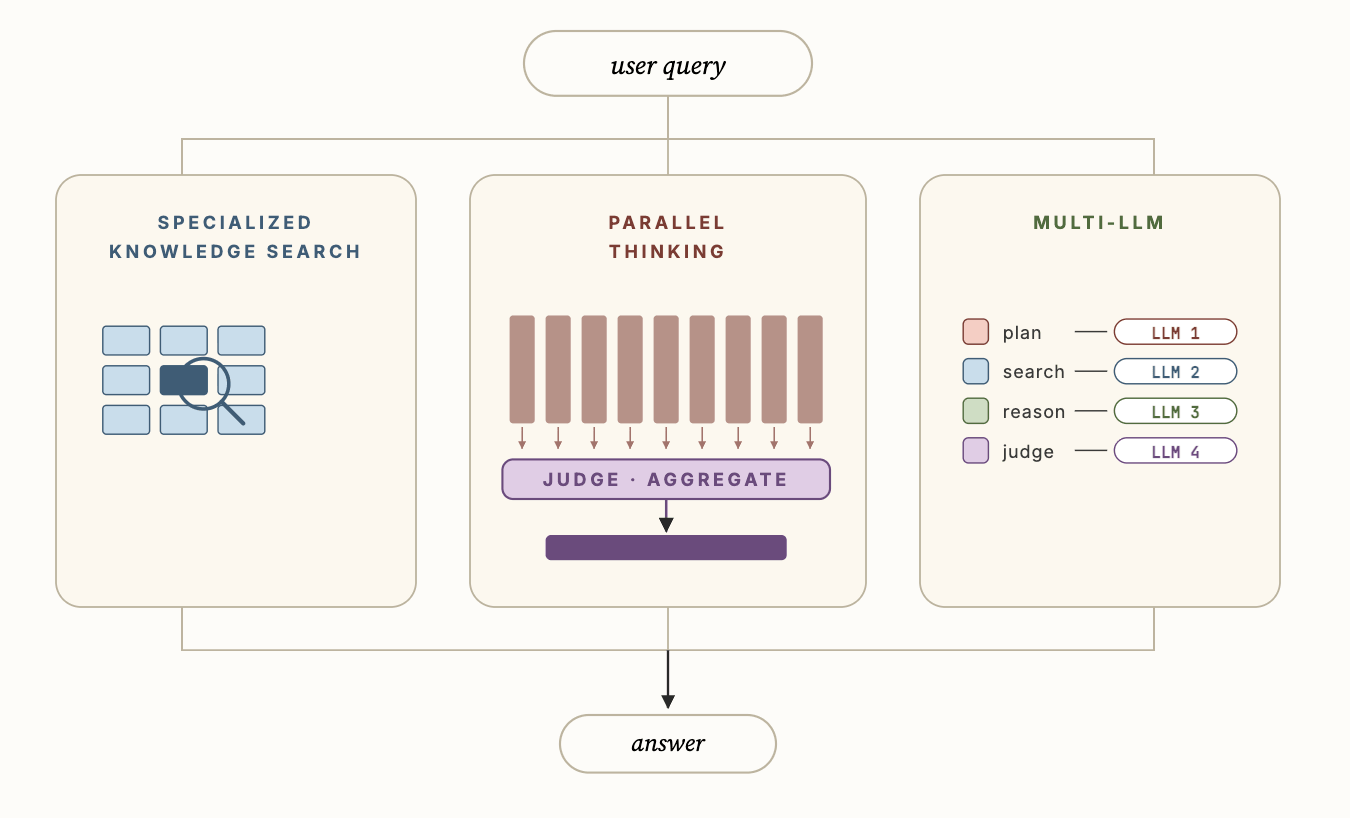
La figure 3 montre certaines des innovations techniques clés de Genie qui lui permettent de surpasser considérablement les agents de codage génériques, à savoir : i) la recherche de connaissances spécialisées, ii) la pensée parallèle et iii) le Multi-LLM. La recherche de connaissances spécialisées utilise des données contextuelles sémantiques pour ancrer les sous-agents de découverte d'actifs et améliorer considérablement la qualité de la recherche. La pensée parallèle permet à l'agent d'échantillonner plusieurs trajectoires différentes, puis d'agréger les résultats de ces trajectoires pour calculer la réponse finale. Enfin, Multi-LLM permet à l'agent d'utiliser différents LLM pour chacun des différents sous-agents, ainsi que leurs invites optimisées, afin d'améliorer encore la précision globale et la latence.
Recherche de connaissances spécialisées
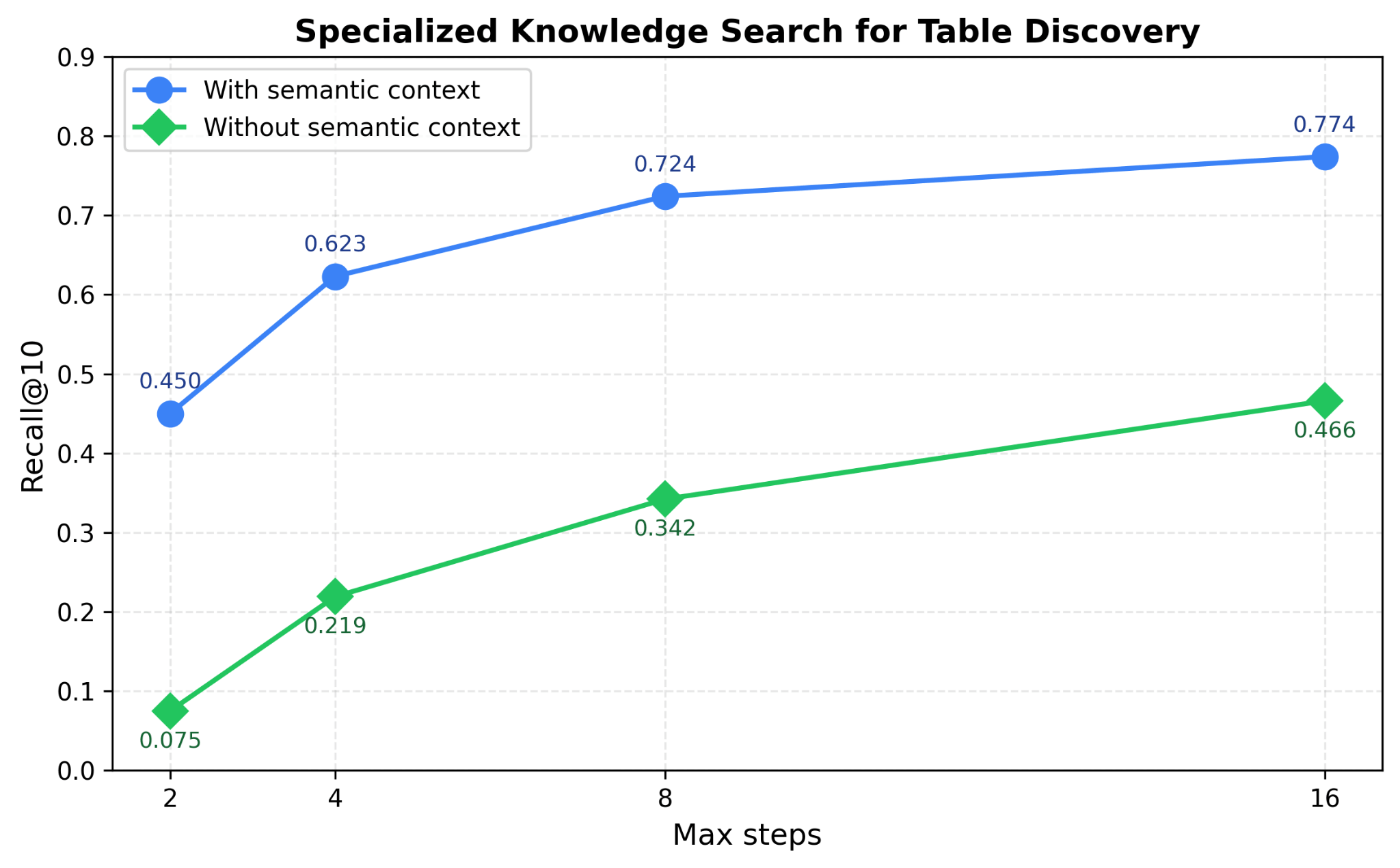
Genie utilise les actifs de données existants tels que les tables de l'espace de travail, les notebooks, les tableaux de bord, les documents et les fichiers pour dériver un riche contexte d'entreprise sémantique, puis utilise ce contexte pour construire un index de recherche. Il utilise plusieurs index de recherche en parallèle, ainsi que de riches signaux de métadonnées, pour découvrir efficacement les actifs les plus pertinents pour une requête utilisateur. La figure 4 démontre comment l'exploitation de la recherche de connaissances spécialisées aide Genie à améliorer les performances de recherche de tables jusqu'à 40 % sur nos benchmarks de découverte de tables.
Pensée parallèle
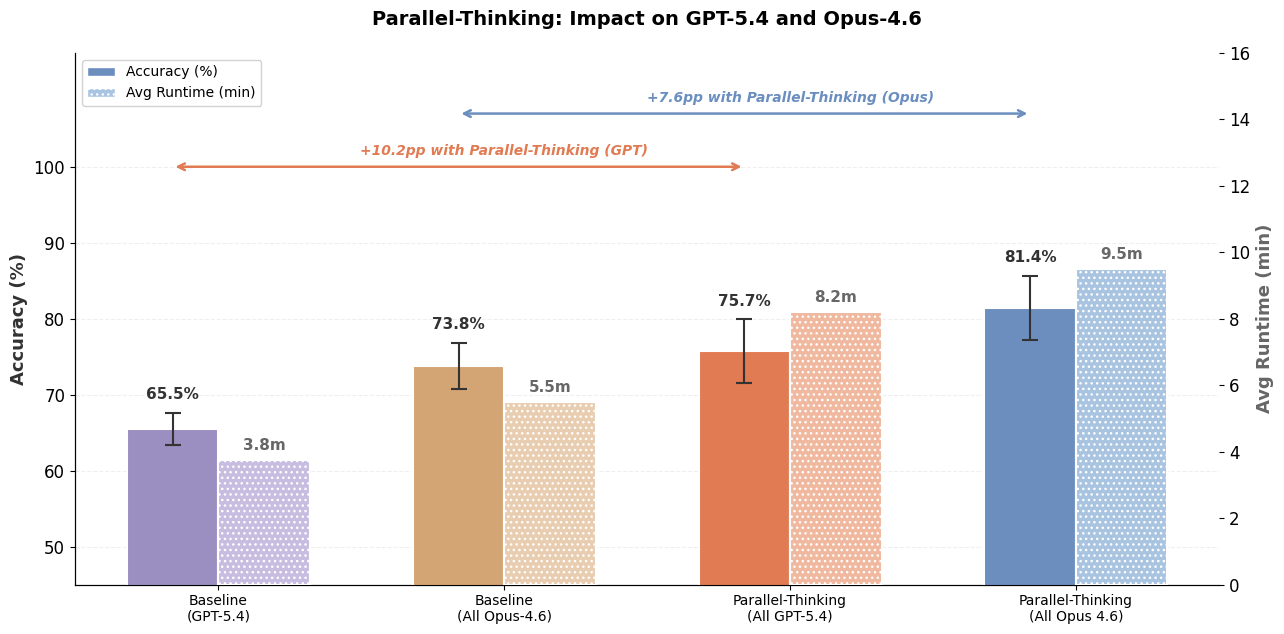
Contrairement aux tâches d'ingénierie logicielle, où les agents de codage peuvent d'abord écrire des tests pour vérifier la fonctionnalité souhaitée, puis itérer sur la génération de code jusqu'à ce que les tests réussissent, les requêtes de données ouvertes n'ont pas de tests unitaires correspondants. En l'absence de tests, il devient difficile pour les agents de données de savoir si la réponse générée est correcte ou nécessite plus d'affinage. Pour relever ce défi, nous utilisons la pensée parallèle en échantillonnant plusieurs trajectoires et en agrégeant les informations pertinentes à travers les trajectoires pour calculer la réponse finale. La figure 5 montre comment la pensée parallèle peut améliorer considérablement la précision de la réponse, bien qu'avec une latence et des coûts de jetons supplémentaires. De plus, comme le montre la figure 1, la combinaison de Multi-LLM et d'optimisations supplémentaires peut réduire encore considérablement les coûts et la latence.
Multi-LLM
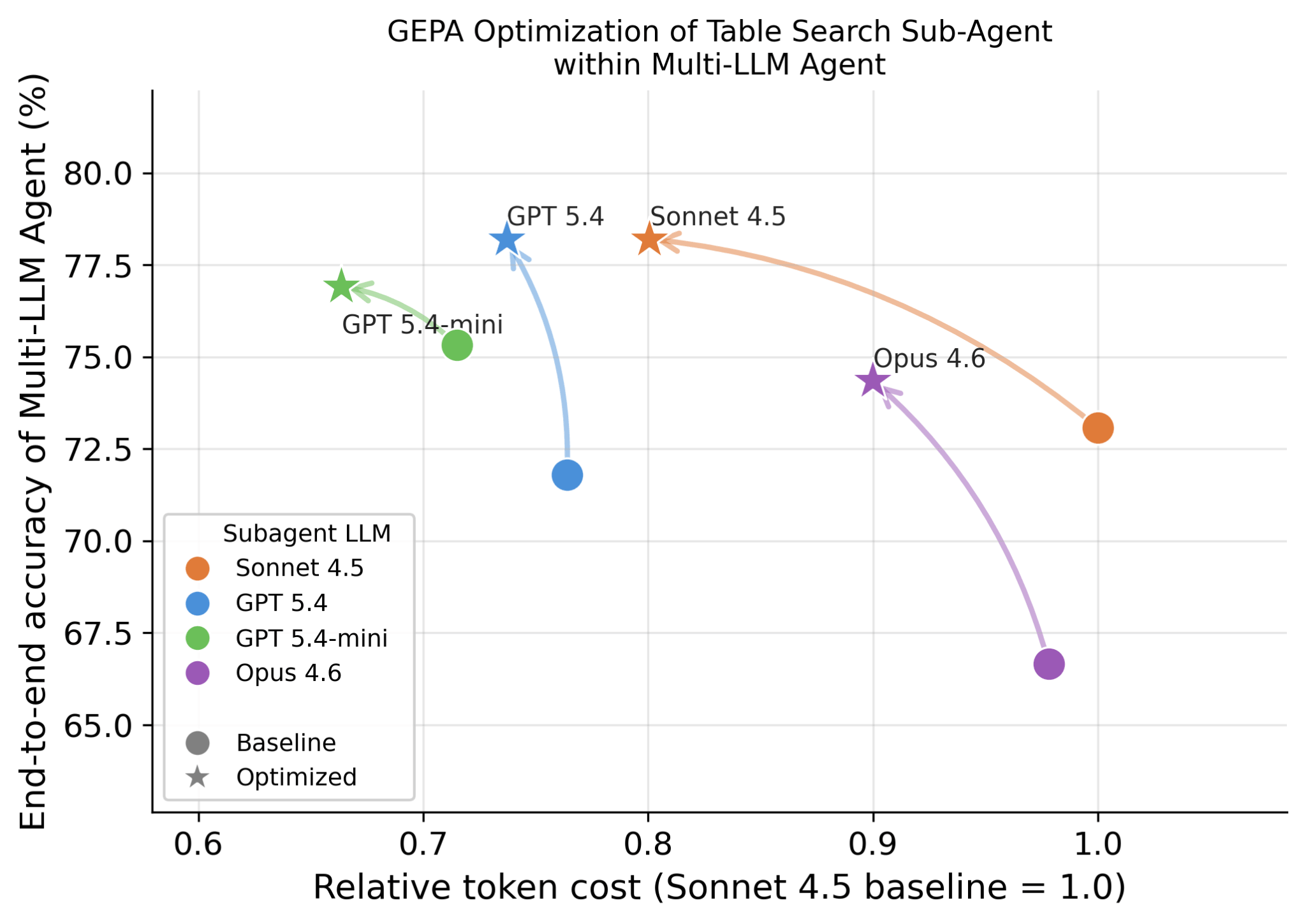
L'une des avancées techniques clés de Genie est la capacité à exploiter différents LLM pour différents sous-agents, car nous observons que différents LLM sont bons dans des capacités complémentaires. Par exemple, il peut utiliser un LLM différent pour la phase de planification, un LLM différent pour divers sous-agents de recherche, un autre pour la génération de code et les juges. Avec la plateforme Databricks, il est facile d'essayer n'importe lequel des modèles de pointe (y compris Opus, GPT et Gemini), les modèles open-source, ainsi que les modèles entraînés sur mesure. En plus de la précision, nous observons également que différents LLM entraînent des caractéristiques de latence et de coût très différentes. La figure 6 montre comment différents LLM se comportent sur des tâches de recherche de tables et comment la précision et le coût correspondants peuvent être optimisés davantage à l'aide de méthodes telles que GEPA.
Conclusion
Bien que le codage et l'analyse de données partagent de nombreuses similitudes conceptuelles, la nature dynamique des systèmes de données d'entreprise crée des défis uniques. Les agents de données doivent découvrir efficacement les bons actifs dans un grand contexte d'entreprise, déterminer la « vérité » dans un environnement ambigu et écrire du code et des requêtes efficaces pour répondre correctement aux questions des utilisateurs. Nous avons développé plusieurs approches novatrices pour résoudre ces problèmes, telles que la recherche spécialisée de connaissances pour exploiter des informations sémantiques riches et plusieurs signaux de métadonnées, le Multi-LLM pour exploiter différents LLM avec des invites optimisées à l'aide de GEPA, et la pensée parallèle pour améliorer encore la précision globale. L'ajout de ces approches à Genie lui permet de surpasser significativement les agents de codage leaders sur les tâches de référence. Il reste encore de nombreuses questions ouvertes difficiles à explorer, et il n'a jamais été aussi passionnant d'explorer la recherche dans ce domaine de la création d'agents de données de pointe pour les entreprises.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.